
Repensando estratégias clássicas (Parte X): A IA pode operar o MACD?

O cruzamento de médias móveis é provavelmente uma das estratégias de trading mais antigas que existem. O indicador de Convergência e Divergência de Médias Móveis (Moving Average Convergence Divergence (MACD)) é um indicador muito popular baseado no conceito de cruzamento de médias móveis. Nossa comunidade tem crescido com a chegada de muitos novos participantes, que talvez se interessem em saber sobre o poder preditivo do indicador MACD em sua busca por desenvolver a melhor estratégia de trading possível. Além disso, há analistas técnicos experientes que utilizam o MACD em suas estratégias e que podem ter a mesma dúvida em mente. Neste artigo, apresentaremos uma análise empírica da capacidade de previsão do indicador para o par EURUSD. Além disso, ensinaremos técnicas de modelagem que você poderá usar para aprimorar a análise técnica com ajuda da IA.
Visão geral da estratégia de trading
O indicador MACD é utilizado principalmente para identificar tendências de mercado e medir a força do movimento de uma tendência. Esse indicador foi criado na década de 1970 pelo falecido Gerald Appel (Gerrald Appel). Appel era gestor financeiro de clientes privados, e seu sucesso se devia à sua abordagem de trading baseada em análise técnica. Ele inventou o indicador MACD há cerca de 50 anos.

Figura 1: Gerald Appel, o criador do indicador MACD
Analistas técnicos utilizam o indicador para identificar pontos de entrada e saída de diversas maneiras. A Fig. 2 abaixo mostra uma captura de tela do indicador MACD aplicado ao par GBPUSD com as configurações padrão. O indicador já vem incluso na sua instalação padrão do MetaTrader 5. A linha vermelha, chamada de linha principal do MACD, é calculada como a diferença entre duas médias móveis, uma rápida e outra lenta. Sempre que a linha principal cruza para baixo da marca de 0, o mercado provavelmente está em tendência de baixa, e o contrário também é válido quando a linha cruza acima de 0.
De maneira semelhante, a própria linha principal também pode ser usada para avaliar a força do mercado. Somente o aumento nos níveis de preço levará a um aumento no valor da linha principal e, inversamente, uma queda nos níveis de preço fará com que a linha principal diminua. Assim, pontos de inflexão, quando a linha principal assume a forma semelhante a uma tigela, surgem como resultado de uma mudança na dinâmica do mercado. Diversas estratégias de trading foram desenvolvidas em torno do MACD. Estratégias mais sofisticadas e bem elaboradas são voltadas para a detecção de divergência no MACD.
A divergência do MACD ocorre quando os níveis de preço estão em um forte movimento de tendência, rompendo para novos extremos. Enquanto isso, por outro lado, o indicador MACD segue uma tendência que apenas enfraquece e começa a cair, o que contrasta fortemente com o movimento forte dos preços observado no gráfico. Em geral, a divergência do MACD é interpretada como um sinal de alerta precoce de reversão da tendência, permitindo que os traders fechem suas posições abertas antes que os mercados se tornem mais voláteis.
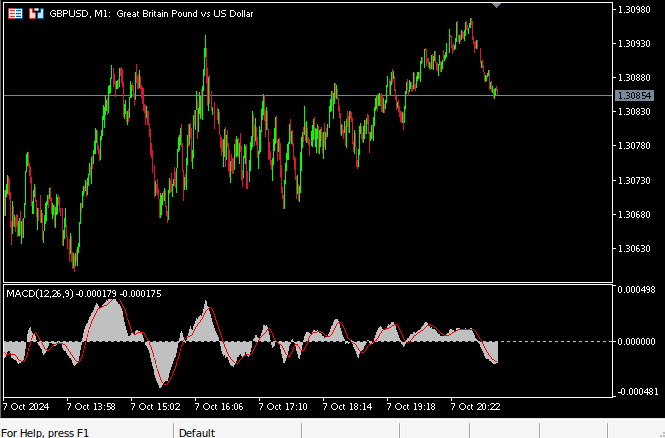
Figura 2: Indicador MACD com as configurações padrão no gráfico GBPUSD M1
Existem muitos céticos que questionam o uso do indicador MACD como um todo. Vamos começar abordando o elefante na sala. Todos os indicadores técnicos são agrupados como indicadores atrasados. Isso significa que os indicadores técnicos só mudam depois que os níveis de preço mudaram; eles não podem se alterar antes disso. Indicadores macroeconômicos, como o nível de inflação global, e notícias geopolíticas, como o início de uma guerra ou um desastre natural, podem impactar a oferta e a demanda. Esses são considerados indicadores antecedentes, pois podem se alterar rapidamente antes que os níveis de preço reflitam essa mudança.
Muitos traders acreditam que esses sinais atrasados provavelmente levam os traders a abrir posições quando o movimento do mercado já se esgotou. Além disso, normalmente ocorrem reversões de tendência que não foram precedidas por divergências no MACD. E, da mesma forma, pode-se observar uma divergência no MACD que não resulta em reversão de tendência.
Esses fatos nos levam a questionar a confiabilidade desse indicador e se ele realmente possui algum poder preditivo digno de atenção. Queremos avaliar se é possível superar a defasagem inerente ao indicador com o uso de IA. Se o indicador MACD mostrar ser robusto, implementaremos um modelo de IA que:
- Use os valores do indicador para prever níveis futuros de preço.
- Faça a previsão do próprio indicador MACD.
Dependendo de qual abordagem de modelagem apresentasse menor margem de erro. Caso contrário, se nossa análise indicar que o MACD pode não ter poder preditivo dentro da estratégia atual, escolheremos, em vez disso, o modelo mais eficaz para previsão dos níveis de preço.
Visão geral da metodologia
Nossa análise começou com a criação de um script específico escrito em MQL5 para extrair exatamente 100.000 linhas de cotações de mercado M1 do par EURUSD, juntamente com os respectivos sinais e valores principais do indicador MACD, em um arquivo CSV. A julgar por nossas visualizações dos dados, o indicador MACD aparentemente não define bem os níveis futuros de preço. As variações nos níveis de preço provavelmente são independentes dos valores do indicador, e além disso, o cálculo do indicador adicionou uma estrutura não linear e complexa aos dados, o que pode dificultar a modelagem.
Os dados que obtivemos do nosso terminal MetaTrader 5 foram divididos em 2 metades. Usamos a primeira metade para avaliar a precisão do nosso modelo por meio de uma validação cruzada com 5 divisões. Em seguida, criamos 3 modelos idênticos de redes neurais profundas e os treinamos em 3 subconjuntos diferentes dos nossos dados:
- Modelo de preço: Prevê os níveis de preço usando cotações OHLC do MetaTrader 5
- Modelo MACD: Prevê os valores do indicador MACD usando cotações OHLC e leituras do MACD
- Modelo completo: Prevê os níveis de preço usando cotações OHLC e o indicador MACD
A segunda metade da divisão foi usada para testar os modelos. O primeiro modelo apresentou a maior precisão no teste – 69%. Nossos algoritmos de seleção de características mostraram que as cotações de mercado obtidas no MetaTrader 5 eram mais informativas do que os valores do MACD.
Com isso, passamos a otimizar o melhor modelo que tínhamos – um modelo de regressão para prever o preço futuro do par EURUSD. No entanto, logo encontramos dificuldades, pois detectamos ruído em nossos dados de treinamento. Infelizmente, não conseguimos superar os resultados de uma simples regressão linear no conjunto de teste. Portanto, substituímos o modelo superajustado pelo Método de Vetores de Suporte (SVM).
Posteriormente, exportamos nosso modelo SVM para o formato ONNX e criamos um EA usando uma abordagem combinada para prever tanto os níveis futuros de preço do EURUSD quanto o indicador MACD.
Obtendo os dados de que precisamos
Para dar o pontapé inicial, começamos utilizando o ambiente de desenvolvimento integrado (IDE) MetaEditor. Criamos o script descrito abaixo para extrair nossos dados de mercado diretamente do terminal MetaTrader 5. Solicitamos 100.000 linhas de dados históricos M1 e os exportamos em formato CSV. O script abaixo preencherá nosso arquivo CSV com os valores de Time, Open, High, Low, Close e dois valores do MACD. Basta arrastar o script para qualquer par que você queira analisar, caso deseje seguir conosco.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int indicator_handler; double indicator_buffer[]; double indicator_buffer_2[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator indicator_handler = iMACD(Symbol(),PERIOD_CURRENT,12,26,9,PRICE_CLOSE); CopyBuffer(indicator_handler,0,0,size,indicator_buffer); CopyBuffer(indicator_handler,1,0,size,indicator_buffer_2); ArraySetAsSeries(indicator_buffer,true); ArraySetAsSeries(indicator_buffer_2,true); //--- File name string file_name = "Market Data " + Symbol() +" MACD " + ".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","MACD Main","MACD Signal"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), indicator_buffer[i], indicator_buffer_2[i] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Pré-processamento de dados
Agora que exportamos nossos dados em formato CSV, vamos carregar os dados no nosso ambiente de trabalho Python. Primeiro, carregaremos as bibliotecas necessárias.
#Load libraries import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
Lendo os dados.
#Read in the data data = pd.read_csv("Market Data EURUSD MACD .csv")
Vamos definir quão longe no futuro devemos fazer as previsões.
#Forecast horizon look_ahead = 20
Adicionaremos alvos binários para indicar se o valor atual é maior do que nos 20 casos anteriores, tanto para o preço de fechamento do EURUSD quanto para a linha principal do MACD.
#Let's add labels data["Bull Bear"] = np.where(data["Close"] < data["Close"].shift(look_ahead),0,1) data["MACD Bull"] = np.where(data["MACD Main"] < data["MACD Main"].shift(look_ahead),0,1) data = data.loc[20:,:] data
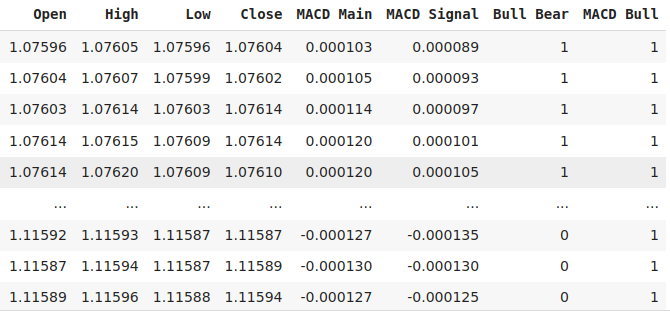
Figura 3: Algumas das colunas em nosso dataframe
Além disso, precisamos definir nossos indicadores-alvo.
data["MACD Target"] = data["MACD Main"].shift(-look_ahead) data["Price Target"] = data["Close"].shift(-look_ahead) data["MACD Binary Target"] = np.where(data["MACD Main"] < data["MACD Target"],1,0) data["Price Binary Target"] = np.where(data["Close"] < data["Price Target"],1,0) data = data.iloc[:-20,:]
Análise exploratória de dados
Os diagramas de dispersão nos ajudam a visualizar a relação entre variáveis dependentes e independentes. O gráfico abaixo mostra que definitivamente existe uma relação entre os níveis futuros de preço e o valor atual do MACD. O problema é que essa relação é não linear e, ao que parece, possui uma estrutura complexa. Não fica imediatamente claro quais mudanças no indicador MACD levam a um movimento de preço de alta ou de baixa.
sns.scatterplot(data=data,x="MACD Main",y="MACD Signal",hue="Price Binary Target")
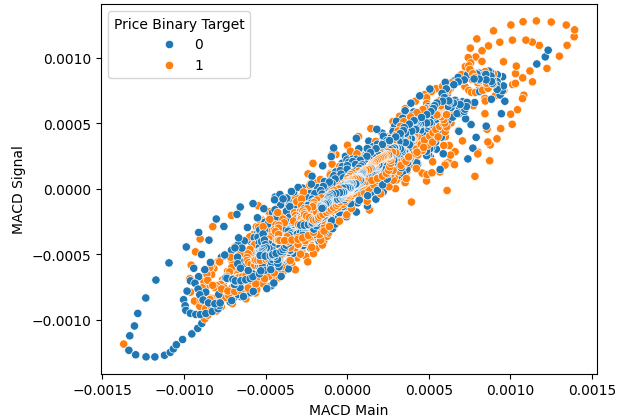
Figura 4: Visualização da relação entre o indicador MACD e os níveis de preço
Executar um gráfico 3D apenas reforça o quão confusa essa relação realmente é. Não há limites claros, por isso esperamos que os dados sejam difíceis de classificar. A única conclusão razoável que podemos tirar do nosso gráfico é que os mercados parecem retornar rapidamente ao centro após atingirem níveis extremos no MACD.
#Define the 3D Plot fig = plt.figure(figsize=(7,7)) ax = plt.axes(projection="3d") ax.scatter(data["MACD Main"],data["MACD Signal"],data["Close"],c=data["Price Binary Target"]) ax.set_xlabel("MACD Main") ax.set_ylabel("MACD Signal") ax.set_zlabel("EURUSD Close")
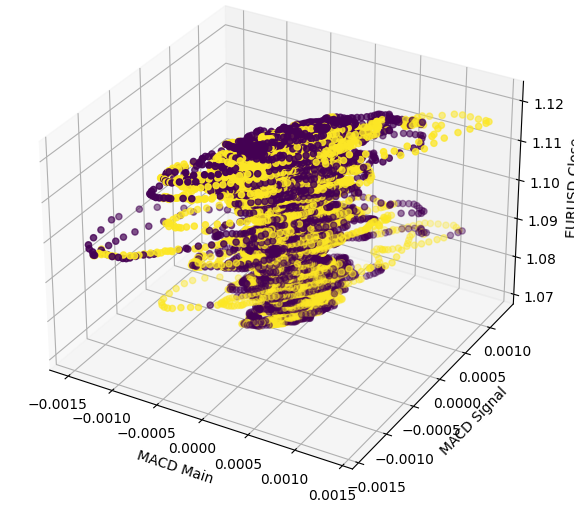
Figura 5: Visualização da interação entre o indicador MACD e o mercado EURUSD
Os gráficos Violin nos permitem visualizar simultaneamente a distribuição dos dados e comparar duas distribuições. A linha azul representa um resumo da distribuição observada dos níveis futuros de preço após uma alta ou baixa no MACD. Na figura 6 abaixo, precisávamos entender se o aumento ou a queda no indicador MACD estavam relacionados a distribuições diferentes em relação aos movimentos futuros de preço. Como se pode ver, essas duas distribuições parecem praticamente idênticas. Além disso, o núcleo de cada distribuição possui um gráfico de caixas. As médias nos dois gráficos de caixas parecem quase idênticas, independentemente de o indicador estar em uma condição de alta ou de baixa.
sns.violinplot(data=data,x="MACD Bull",y="Close",hue="Price Binary Target",split=True,fill=False)
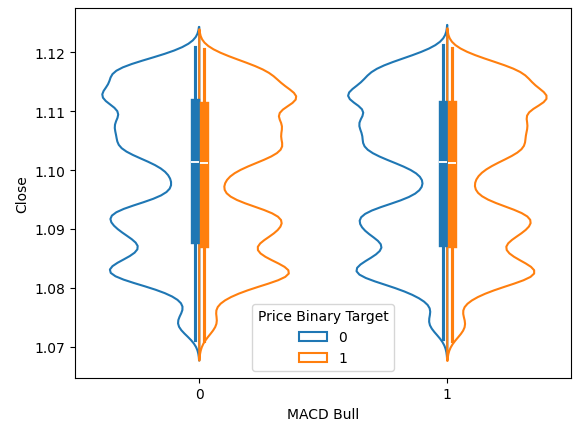
Figura 6: Visualização do impacto do indicador MACD nos níveis futuros de preço
Preparação para modelagem dos dados
Vamos agora iniciar a modelagem dos nossos dados; primeiro, precisamos importar nossas bibliotecas.
#Perform train test splits from sklearn.model_selection import train_test_split,TimeSeriesSplit from sklearn.metrics import accuracy_score train,test = train_test_split(data,test_size=0.5,shuffle=False)
Agora vamos definir os preditores e o alvo.
#Let's scale the data ohlc_predictors = ["Open","High","Low","Close","Bull Bear"] macd_predictors = ["MACD Main","MACD Signal","MACD Bull"] all_predictors = ohlc_predictors + macd_predictors cv_predictors = [ohlc_predictors,macd_predictors,all_predictors] #Define the targets cv_targets = ["MACD Binary Target","Price Binary Target","All"]
Escalonando os dados.
#Scaling the data
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(train[all_predictors])
train_scaled = pd.DataFrame(scaler.transform(train[all_predictors]),columns=all_predictors)
test_scaled = pd.DataFrame(scaler.transform(test[all_predictors]),columns=all_predictors) Vamos carregar as bibliotecas necessárias.
#Import the models we will evaluate
from sklearn.neural_network import MLPClassifier,MLPRegressor
from sklearn.linear_model import LinearRegression Criamos um objeto de separação para séries temporais.
tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead) Os índices do nosso dataframe serão mapeados para o conjunto de dados de entrada que estávamos avaliando.
err_indexes = ["MACD Train","Price Train","All Train","MACD Test","Price Test","All Test"]
Agora criaremos um dataframe que registrará nossas métricas de precisão do modelo à medida que modificamos nossos dados de entrada.
#Now let us define a table to store our error levels columns = ["Model Accuracy"] cv_err = pd.DataFrame(columns=columns,index=err_indexes)
Resetamos todos os nossos índices.
#Reset index
train = train.reset_index(drop=True)
test = test.reset_index(drop=True) Executamos a validação cruzada do modelo. Faremos a validação cruzada no conjunto de treinamento e, em seguida, registraremos sua precisão no conjunto de teste, sem aplicar a validação ao conjunto de teste.
#Initailize the model price_model = MLPClassifier(hidden_layer_sizes=(10,6)) macd_model = MLPClassifier(hidden_layer_sizes=(10,6)) all_model = MLPClassifier(hidden_layer_sizes=(10,6)) price_acc = [] macd_acc = [] all_acc = [] #Cross validate each model twice for j,(train_index,test_index) in enumerate(tscv.split(train_scaled)): #Fit the models price_model.fit(train_scaled.loc[train_index,ohlc_predictors],train.loc[train_index,"Price Binary Target"]) macd_model.fit(train_scaled.loc[train_index,all_predictors],train.loc[train_index,"MACD Binary Target"]) all_model.fit(train_scaled.loc[train_index,all_predictors],train.loc[train_index,"Price Binary Target"]) #Store the accuracy price_acc.append(accuracy_score(train.loc[test_index,"Price Binary Target"],price_model.predict(train_scaled.loc[test_index,ohlc_predictors]))) macd_acc.append(accuracy_score(train.loc[test_index,cv_targets[0]],macd_model.predict(train_scaled.loc[test_index,all_predictors]))) all_acc.append(accuracy_score(train.loc[test_index,cv_targets[1]],all_model.predict(train_scaled.loc[test_index,all_predictors]))) #Now we can store our estimates of the model's error cv_err.iloc[0,0] = np.mean(price_acc) cv_err.iloc[1,0] = np.mean(macd_acc) cv_err.iloc[2,0] = np.mean(all_acc) #Estimating test error cv_err.iloc[3,0] = accuracy_score(test[cv_targets[1]],price_model.predict(test_scaled[ohlc_predictors])) cv_err.iloc[4,0] = accuracy_score(test[cv_targets[0]],macd_model.predict(test_scaled[all_predictors])) cv_err.iloc[5,0] = accuracy_score(test[cv_targets[1]],all_model.predict(test_scaled[all_predictors]))
| Grupo de entrada | Precisão do modelo |
|---|---|
| MACD Train | 0.507129 |
| OHLC Train | 0.690267 |
| All Train | 0.504577 |
| MACD Test | 0.48669 |
| OHLC Test | 0.684069 |
| All Test | 0.487442 |
Importância das características
Agora tentaremos avaliar os níveis de importância das variáveis para nossa rede neural profunda. Vamos escolher a importância por permutação para interpretar nosso modelo. A importância por permutação determina a relevância de cada parâmetro de entrada, embaralhando os valores dessa coluna de entrada e, em seguida, avaliando a mudança na precisão do modelo. A ideia é que características importantes provoquem uma queda significativa na precisão, enquanto características irrelevantes resultem em alterações muito próximas de 0.
No entanto, alguns pontos precisam ser considerados. Primeiro, o algoritmo de importância por permutação embaralha aleatoriamente todos os dados de entrada do modelo. Isso significa que o algoritmo pode embaralhar aleatoriamente o preço de abertura e colocá-lo acima do preço máximo. Obviamente, isso não é possível no mundo real. Por isso, devemos interpretar os resultados do algoritmo com cautela. Pode-se argumentar que o algoritmo é tendencioso, já que ele avalia a importância das variáveis em condições simuladas que potencialmente nunca aconteceriam, penalizando o modelo desnecessariamente. Além disso, devido à natureza estocástica dos algoritmos de otimização usados para treinar redes neurais modernas, o treinamento das mesmas redes neurais com os mesmos dados pode gerar explicações completamente diferentes a cada execução.
#Let us try assess feature importance from sklearn.inspection import permutation_importance from sklearn.linear_model import RidgeClassifier
Agora vamos aplicar nosso objeto de importância por permutação ao nosso modelo treinado de rede neural profunda. Umas temos a opção de passar os dados de treinamento ou de teste para o embaralhamento. Optamos pelos dados de teste. Depois disso, organizamos os dados por ordem decrescente de precisão e plotamos os resultados. Na figura 7 abaixo mostra os resultados observados da importância por permutação. Podemos ver que os resultados do embaralhamento das variáveis relacionadas ao MACD ficam muito próximos de 0, o que significa que as colunas do MACD não são tão importantes para nosso modelo.
#Let us fit the model model = MLPClassifier(hidden_layer_sizes=(10,6)) model.fit(train_scaled.loc[:,all_predictors],train.loc[:,"Price Binary Target"]) #Calculate permutation importance scores pi = permutation_importance( model, test_scaled.loc[:,all_predictors], test.loc[:,"Price Binary Target"], n_repeats=10, random_state=42, n_jobs=-1 ) #Sort the importance scores sorted_importances_idx = pi.importances_mean.argsort() importances = pd.DataFrame( pi.importances[sorted_importances_idx].T, columns=test_scaled.columns[sorted_importances_idx], ) #Create the plot ax = importances.plot.box(vert=False, whis=10) ax.set_title("Permutation Importances (test set)") ax.axvline(x=0, color="k", linestyle="--") ax.set_xlabel("Decrease in accuracy score") ax.figure.tight_layout()
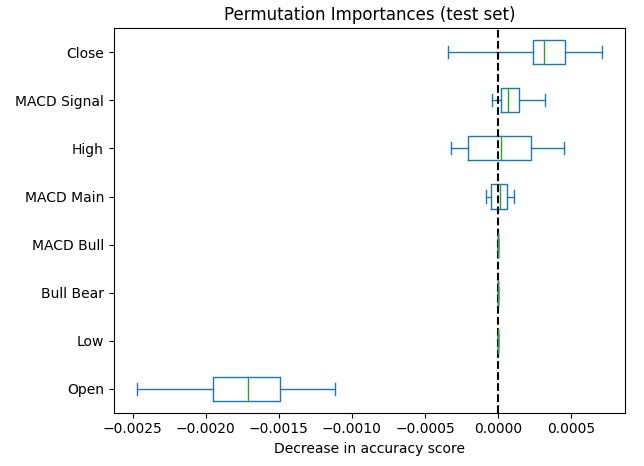
Figura 7: Nas nossas avaliações de importância por permutação, o preço de fechamento foi identificado como o recurso mais importante
Treinar um modelo mais simples também poderia nos fornecer uma noção dos níveis de importância dos dados brutos. O ridge classifier é um modelo linear que ajusta seus coeficientes cada vez mais próximos de 0 na direção que minimiza seu erro. Consequentemente, assumindo que seus dados foram padronizados e escalados, as variáveis irrelevantes terão os menores coeficientes. Caso você esteja curioso, o ridge classifier consegue isso expandindo o modelo linear tradicional e incluindo um termo de penalidade proporcional à soma dos quadrados dos coeficientes do modelo. Esse fenômeno é amplamente conhecido como regularização L2.
#Let us fit the model model = RidgeClassifier() model.fit(train_scaled.loc[:,all_predictors],train.loc[:,"Price Binary Target"])
Agora vamos construir um gráfico com os coeficientes do modelo.
ridge_importance = pd.DataFrame(model.coef_.tolist(),columns=all_predictors) #Prepare the plot fig,ax = plt.subplots(figsize=(10,5)) sns.barplot(ridge_importance,ax=ax)
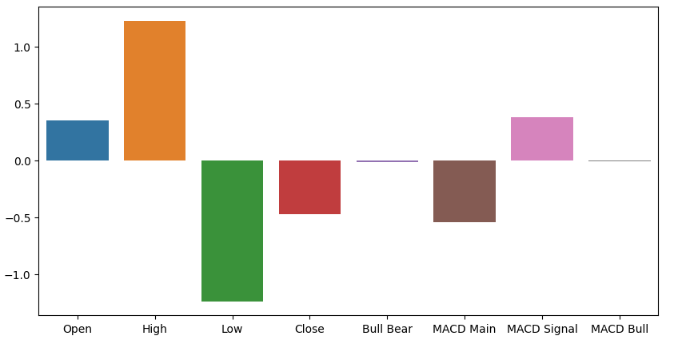
Figura 8: Os nossos coeficientes de ridge indicam que os preços alto e baixo são os recursos mais informativos que temos
Ajuste de parâmetros
Agora vamos tentar otimizar nosso modelo mais eficaz. No entanto, como já mencionamos anteriormente, nosso processo de otimização neste ponto não teve sucesso. Infelizmente, isso faz parte da natureza dos algoritmos de otimização, e não há garantia de que encontraremos soluções. Realizar a otimização de parâmetros não significa necessariamente que o modelo final será melhor. Estamos apenas tentando nos aproximar dos parâmetros ideais do modelo. Vamos carregar as bibliotecas necessárias.
#Let's tune our model further from sklearn.model_selection import RandomizedSearchCV
Definição do modelo.
#Reinitialize the model model = MLPRegressor(max_iter=200)
Agora vamos definir o objeto tuner. O objeto avaliará nosso modelo com diferentes configurações de inicialização e retornará um objeto contendo os dados de entrada mais eficazes encontrados.
#Define the tuner
tuner = RandomizedSearchCV(
model,
{
"activation" : ["relu","logistic","tanh","identity"],
"solver":["adam","sgd","lbfgs"],
"alpha":[0.1,0.01,0.001,0.0001,0.00001,0.00001,0.0000001],
"tol":[0.1,0.01,0.001,0.0001,0.00001,0.000001,0.0000001],
"learning_rate":['constant','adaptive','invscaling'],
"learning_rate_init":[0.1,0.01,0.001,0.0001,0.00001,0.000001,0.0000001],
"hidden_layer_sizes":[(2,4,8,2),(10,20),(5,10),(2,20),(6,8,10),(1,5),(20,10),(8,4),(2,4,8),(10,5)],
"early_stopping":[True,False],
"warm_start":[True,False],
"shuffle": [True,False]
},
n_iter=100,
cv=5,
n_jobs=-1,
scoring="neg_mean_squared_error"
) Treinamento do objeto tuner.
tuner.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) Os melhores parâmetros encontrados por nós:
tuner.best_params_
'tol': 0.01,
'solver': 'sgd',
'shuffle': False,
'learning_rate_init': 0.01,
'learning_rate': 'constant',
'hidden_layer_sizes': (20, 10),
'early_stopping': True,
'alpha': 1e-07,
'activation': 'identity'}
Otimização mais profunda
Podemos fazer uma busca ainda mais refinada por melhores configurações de entrada usando a biblioteca SciPy. Usaremos a biblioteca para avaliar os resultados de uma otimização global sobre parâmetros contínuos do modelo.#Deeper optimization from scipy.optimize import minimize from sklearn.metrics import mean_squared_error from sklearn.model_selection import TimeSeriesSplit
Vamos definir o objeto de separação para séries temporais.
#Define the time series split object tscv = TimeSeriesSplit(n_splits=5,gap=look_ahead)
Criamos estruturas de dados para armazenar nossos níveis de precisão.
#Create a dataframe to store our accuracy current_error_rate = pd.DataFrame(index = np.arange(0,5),columns=["Current Error"]) algorithm_progress = []
Nossa função de custo, que precisa ser minimizada, será o nível de erro do modelo sobre os dados de treinamento.
#Define the objective function def objective(x): #The parameter x represents a new value for our neural network's settings model = MLPRegressor(hidden_layer_sizes=tuner.best_params_["hidden_layer_sizes"], early_stopping=tuner.best_params_["early_stopping"], warm_start=tuner.best_params_["warm_start"], max_iter=500, activation=tuner.best_params_["activation"], learning_rate=tuner.best_params_["learning_rate"], solver=tuner.best_params_["solver"], shuffle=tuner.best_params_["shuffle"], alpha=x[0], tol=x[1], learning_rate_init=x[2] ) #Now we will cross validate the model for i,(train_index,test_index) in enumerate(tscv.split(train)): #Train the model model.fit(train.loc[train_index,ohlc_predictors],train.loc[train_index,"Price Target"]) #Measure the RMSE current_error_rate.iloc[i,0] = mean_squared_error(train.loc[test_index,"Price Target"],model.predict(train.loc[test_index,ohlc_predictors])) #Store the algorithm's progress algorithm_progress.append(current_error_rate.iloc[:,0].mean()) #Return the Mean CV RMSE return(current_error_rate.iloc[:,0].mean())
O SciPy espera que forneçamos valores iniciais para iniciar o processo de otimização.
#Define the starting point pt = [tuner.best_params_["alpha"],tuner.best_params_["tol"],tuner.best_params_["learning_rate_init"]] bnds = ((10.00 ** -100,10.00 ** 100), (10.00 ** -100,10.00 ** 100), (10.00 ** -100,10.00 ** 100))
Agora vamos tentar otimizar o modelo.
#Searching deeper for parameters result = minimize(objective,pt,method="L-BFGS-B",bounds=bnds)
Parece que o algoritmo conseguiu convergir. Isso significa que ele encontrou dados de entrada estáveis com baixa variância. Assim, ele concluiu que não existem soluções melhores, já que as variações no nível de erro estavam se aproximando de 0.
#The result of our optimization
result success: True
status: 0
fun: 3.730365831424036e-06
x: [ 9.939e-08 9.999e-03 9.999e-03]
nit: 3
jac: [-7.896e+01 -1.133e+02 1.439e+03]
nfev: 100
njev: 25
hess_inv: <3x3 LbfgsInvHessProduct with dtype=float64>
Vamos visualizar o procedimento.
#Store the optimal coefficients optimal_weights = result.x optima_y = min(algorithm_progress) optima_x = algorithm_progress.index(optima_y) inputs = np.arange(0,len(algorithm_progress)) #Plot the performance of our optimization procedure plt.scatter(inputs,algorithm_progress) plt.plot(optima_x,optima_y,'ro',color='r') plt.axvline(x=optima_x,ls='--',color='red') plt.axhline(y=optima_y,ls='--',color='red') plt.xlabel("Iterations") plt.ylabel("Training MSE") plt.title("Minimizing Training Error")
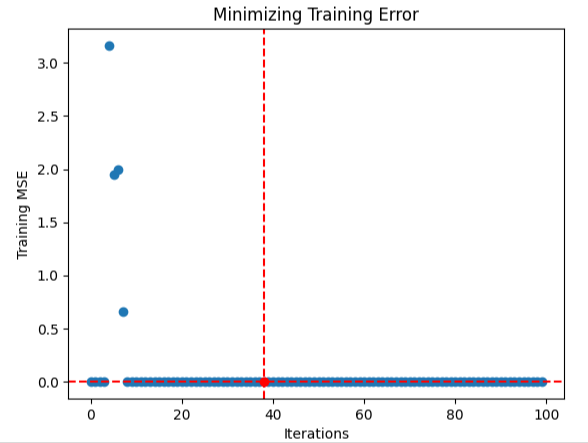
Figura 9: Visualização da otimização da rede neural profunda
Teste de sobreajuste
Sobreajuste é um efeito indesejado em que nosso modelo aprende padrões sem sentido a partir dos dados disponíveis. Isso é problemático, pois o modelo, nesse estado, apresentará baixos níveis de precisão. Podemos identificar se nosso modelo está sobreajustado ao compará-lo com modelos mais fracos, os chamados "alunos fracos", e com versões padrão de redes neurais semelhantes. Se nosso modelo estiver aprendendo apenas o ruído e não conseguir captar o sinal dos dados, os "alunos fracos" irão superá-lo. No entanto, mesmo que nosso modelo supere esses "alunos fracos", ainda há a possibilidade de sobreajuste.
#Testing for overfitting #Benchmark benchmark = LinearRegression() #Default default_nn = MLPRegressor(max_iter=500) #Randomized NN random_search_nn = MLPRegressor(hidden_layer_sizes=tuner.best_params_["hidden_layer_sizes"], early_stopping=tuner.best_params_["early_stopping"], warm_start=tuner.best_params_["warm_start"], max_iter=500, activation=tuner.best_params_["activation"], learning_rate=tuner.best_params_["learning_rate"], solver=tuner.best_params_["solver"], shuffle=tuner.best_params_["shuffle"], alpha=tuner.best_params_["alpha"], tol=tuner.best_params_["tol"], learning_rate_init=tuner.best_params_["learning_rate_init"] ) #LBFGS NN lbfgs_nn = MLPRegressor(hidden_layer_sizes=tuner.best_params_["hidden_layer_sizes"], early_stopping=tuner.best_params_["early_stopping"], warm_start=tuner.best_params_["warm_start"], max_iter=500, activation=tuner.best_params_["activation"], learning_rate=tuner.best_params_["learning_rate"], solver=tuner.best_params_["solver"], shuffle=tuner.best_params_["shuffle"], alpha=result.x[0], tol=result.x[1], learning_rate_init=result.x[2] )
Treinamos os modelos e avaliamos sua precisão. Podemos ver claramente a diferença de desempenho: o modelo de regressão linear superou todas as nossas redes neurais profundas. Em seguida, decidi tentar treinar uma SVM linear. Ela teve desempenho superior ao das redes neurais, mas não conseguiu superar a regressão linear.
#Fit the models on the training sets benchmark = LinearRegression() benchmark.fit(((train.loc[:,ohlc_predictors])),train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],benchmark.predict(((test.loc[:,ohlc_predictors])))) #Test the default default_nn.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],default_nn.predict(test.loc[:,ohlc_predictors])) #Test the random search random_search_nn.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],random_search_nn.predict(test.loc[:,ohlc_predictors])) #Test the lbfgs nn lbfgs_nn.fit(train.loc[:,ohlc_predictors],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],lbfgs_nn.predict(test.loc[:,ohlc_predictors])
| Regressão linear | Rede neural padrão | Busca aleatória | Rede neural LBFGS |
|---|---|---|---|
| 2.609826e-07 | 1.996431e-05 | 0.00051 | 0.000398 |
Vamos treinar nossa LinearSVR, que tem mais probabilidade de capturar interações não lineares nos nossos dados.
#From experience, I'll try LSVR from sklearn.svm import LinearSVR
Inicializamos o modelo e o ajustamos com todos os dados disponíveis. Observe que os níveis de erro da SVR são melhores que os da rede neural, mas ainda não superam a regressão linear.
#Initialize the model lsvr = LinearSVR() #Fit the Linear Support Vector lsvr.fit(train.loc[:,["Open","High","Low","Close"]],train.loc[:,"Price Target"]) mean_squared_error(test.loc[:,"Price Target"],lsvr.predict(test.loc[:,["Open","High","Low","Close"]]))
Exportação para ONNX
O Open Neural Network Exchange (ONNX) nos permite criar modelos de aprendizado de máquina em uma linguagem e depois transferi-los para qualquer outra linguagem que ofereça suporte à API ONNX. O protocolo ONNX está rapidamente ampliando o número de ambientes nos quais é possível usar aprendizado de máquina. O ONNX nos permite integrar IA facilmente ao nosso EA no MQL5.
#Let's export the LSVR to ONNX import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Criamos uma nova instância do modelo.
model = LinearSVR()
Ajustamos o modelo com todos os dados disponíveis.
model.fit(data.loc[:,["Open","High","Low","Close"]],data.loc[:,"Price Target"])
Definimos a forma de entrada do modelo.
#Define the input type initial_types = [("float_input",FloatTensorType([1,4]))]
Criamos a representação ONNX do modelo.
#Create the ONNX representation onnx_model = convert_sklearn(model,initial_types=initial_types,target_opset=12)
Salvamos o modelo ONNX.
# Save the ONNX model onnx.save_model(onnx_model,"EURUSD SVR M1.onnx")

Figura 10: Visualização da nossa modelo ONNX
Implementação com MQL5
Agora podemos começar a implementar nossa estratégia em MQL5. Precisamos criar uma aplicação que compre sempre que o preço estiver acima da média móvel e a inteligência artificial prever que os preços vão subir.
Para começar a trabalhar com nosso aplicativo, primeiro incluiremos o arquivo ONNX recém-criado no nosso EA.
//+--------------------------------------------------------------+ //| EURUSD AI | //+--------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://metaquotes.com/en/users/gamuchiraindawa" #property version "2.1" #property description "Supports M1" //+--------------------------------------------------------------+ //| Resources we need | //+--------------------------------------------------------------+ #resource "\\Files\\EURUSD SVR M1.onnx" as const uchar onnx_buffer[];
Agora vamos carregar a biblioteca de trading.
//+--------------------------------------------------------------+ //| Libraries | //+--------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade trade;
Definiremos algumas constantes, que agora poderão ser modificadas.
//+--------------------------------------------------------------+ //| Constants | //+--------------------------------------------------------------+ const double stop_percent = 1; const int ma_period_shift = 0;
Permitiremos que o usuário controle os parâmetros dos indicadores técnicos e o comportamento geral do programa.
//+--------------------------------------------------------------+ //| User inputs | //+--------------------------------------------------------------+ input group "TAs" input double atr_multiple =2.5; //How wide should the stop loss be? input int atr_period = 200; //ATR Period input int ma_period = 1000; //Moving average period input group "Risk" input double risk_percentage= 0.02; //Risk percentage (0.01 - 1) input double profit_target = 1.0; //Profit target
Agora definiremos todas as variáveis globais necessárias.
//+--------------------------------------------------------------+ //| Global variables | //+--------------------------------------------------------------+ double position_size = 2; int lot_multiplier = 1; bool buy_break_even_setup = false; bool sell_break_even_setup = false; double up_level = 0.03; double down_level = -0.03; double min_volume,max_volume_increase, volume_step, buy_stop_loss, sell_stop_loss,ask, bid,atr_stop,mid_point,risk_equity; double take_profit = 0; double close_price[3]; double moving_average_low_array[],close_average_reading[],moving_average_high_array[],atr_reading[]; long min_distance,login; int ma_high,ma_low,atr,close_average; bool authorized = false; double tick_value,average_market_move,margin,mid_point_height,channel_width,lot_step; string currency,server; bool all_closed =true; long onnx_model; vectorf onnx_output = vectorf::Zeros(1); ENUM_ACCOUNT_TRADE_MODE account_type;
Nosso EA primeiro verificará se o usuário permitiu que EAs operem na conta; em seguida, tentará carregar o modelo ONNX e, caso tenha sucesso, carregaremos nossos indicadores técnicos.
//+------------------------------------------------------------------+ //| On initialization | //+------------------------------------------------------------------+ int OnInit() { //--- Authorization if(!auth()) { return(INIT_FAILED); } //--- Load the ONNX model if(!load_onnx()) { return(INIT_FAILED); } //--- Everything went fine else { load(); return(INIT_SUCCEEDED); } }
Se nosso EA não estiver em uso, liberaremos a memória alocada para o modelo ONNX.
//+------------------------------------------------------------------+ //| On deinitialization | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { OnnxRelease(onnx_model); }Sempre que novas informações de preços forem recebidas, atualizamos nossas variáveis globais de mercado e, em seguida, verificamos se há sinais de entrada, caso não haja posições abertas. Caso contrário, atualizamos nosso trailing stop-loss.
//+------------------------------------------------------------------+ //| On every tick | //+------------------------------------------------------------------+ void OnTick() { //On Every Function Call update(); static datetime time_stamp; datetime time = iTime(_Symbol,PERIOD_CURRENT,0); Comment("AI Forecast: ",onnx_output[0]); //On Every Candle if(time_stamp != time) { //Mark the candle time_stamp = time; OrderCalcMargin(ORDER_TYPE_BUY,_Symbol,min_volume,ask,margin); calculate_lot_size(); if(PositionsTotal() == 0) { check_signal(); } } //--- If we have positions, manage them. if(PositionsTotal() > 0) { check_atr_stop(); check_profit(); } } //+------------------------------------------------------------------+ //| Check if we have any valid setups, and execute them | //+------------------------------------------------------------------+ void check_signal(void) { //--- Get a prediction from our model model_predict(); if(onnx_output[0] > iClose(Symbol(),PERIOD_CURRENT,0)) { if(above_channel()) { check_buy(); } } else if(below_channel()) { if(onnx_output[0] < iClose(Symbol(),PERIOD_CURRENT,0)) { check_sell(); } } }
Essa função é responsável por atualizar todas as nossas variáveis globais de mercado.
//+------------------------------------------------------------------+ //| Update our global variables | //+------------------------------------------------------------------+ void update(void) { //--- Important details that need to be updated everytick ask = SymbolInfoDouble(_Symbol,SYMBOL_ASK); bid = SymbolInfoDouble(_Symbol,SYMBOL_BID); buy_stop_loss = 0; sell_stop_loss = 0; check_price(3); CopyBuffer(ma_high,0,0,1,moving_average_high_array); CopyBuffer(ma_low,0,0,1,moving_average_low_array); CopyBuffer(atr,0,0,1,atr_reading); ArraySetAsSeries(moving_average_high_array,true); ArraySetAsSeries(moving_average_low_array,true); ArraySetAsSeries(atr_reading,true); risk_equity = AccountInfoDouble(ACCOUNT_BALANCE) * risk_percentage; atr_stop = (((min_distance + (atr_reading[0]* 1e5) * atr_multiple) * _Point)); mid_point = (moving_average_high_array[0] + moving_average_low_array[0]) / 2; mid_point_height = close_price[0] - mid_point; channel_width = moving_average_high_array[0] - moving_average_low_array[0]; }
Agora devemos definir uma função que garanta a autorização para iniciar nosso aplicativo. Se ele não for iniciado, a função fornecerá instruções ao usuário sobre o que fazer e retornará o valor false, o que impedirá a inicialização.
//+------------------------------------------------------------------+ //| Check if the EA is allowed to be run | //+------------------------------------------------------------------+ bool auth(void) { if(!TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { Comment("Press Ctrl + E To Give The Robot Permission To Trade And Reload The Program"); return(false); } else if(!MQLInfoInteger(MQL_TRADE_ALLOWED)) { Comment("Reload The Program And Make Sure You Clicked Allow Algo Trading"); return(false); } return(true); }
Durante a inicialização, precisaremos de uma função responsável por carregar todos os nossos indicadores técnicos e obter informações importantes do mercado. A função `load` fará exatamente isso para nós, e como ela faz referência a variáveis globais, seu tipo de retorno será `void`.
//+---------------------------------------------------------------------+ //| Load our needed variables | //+---------------------------------------------------------------------+ void load(void) { //Account Info currency = AccountInfoString(ACCOUNT_CURRENCY); server = AccountInfoString(ACCOUNT_SERVER); login = AccountInfoInteger(ACCOUNT_LOGIN); //Indicators atr = iATR(_Symbol,PERIOD_CURRENT,atr_period); ma_high = iMA(_Symbol,PERIOD_CURRENT,ma_period,ma_period_shift,MODE_EMA,PRICE_HIGH); ma_low = iMA(_Symbol,PERIOD_CURRENT,ma_period,ma_period_shift,MODE_EMA,PRICE_LOW); //Market Information min_volume = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); max_volume_increase = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MAX) / SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); min_distance = SymbolInfoInteger(_Symbol,SYMBOL_TRADE_STOPS_LEVEL); tick_value = SymbolInfoDouble(_Symbol,SYMBOL_TRADE_TICK_VALUE_PROFIT) * min_volume; lot_step = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_STEP); average_market_move = NormalizeDouble(10000 * tick_value,_Digits); }
Por outro lado, nosso modelo ONNX será carregado por meio de uma chamada de função separada. A função criará nosso modelo ONNX a partir do buffer que definimos anteriormente e verificará a forma de entrada e saída.
//+------------------------------------------------------------------+ //| Load our ONNX model | //+------------------------------------------------------------------+ bool load_onnx(void) { onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); ulong onnx_input [] = {1,4}; ulong onnx_output[] = {1,1}; if(!OnnxSetInputShape(onnx_model,0,onnx_input)) { Comment("[INTERNAL ERROR] Failed to load AI modules. Relode the EA."); return(false); } if(!OnnxSetOutputShape(onnx_model,0,onnx_output)) { Comment("[INTERNAL ERROR] Failed to load AI modules. Relode the EA."); return(false); } return(true); }
Agora vamos definir a função que fará previsões a partir do nosso modelo.
//+------------------------------------------------------------------+ //| Get a prediction from our model | //+------------------------------------------------------------------+ void model_predict(void) { vectorf onnx_inputs = {iOpen(Symbol(),PERIOD_CURRENT,0),iHigh(Symbol(),PERIOD_CURRENT,0),iLow(Symbol(),PERIOD_CURRENT,0),iClose(Symbol(),PERIOD_CURRENT,0)}; OnnxRun(onnx_model,ONNX_DEFAULT,onnx_inputs,onnx_output); }
Nosso stop-loss será ajustado com base no valor do ATR. Dependendo se a negociação atual for uma compra ou venda, isso será o principal fator determinante para nos ajudar a decidir se devemos aumentar nosso stop-loss adicionando o valor atual do ATR ou reduzi-lo subtraindo o ATR. Também podemos usar um valor multiplicado pelo ATR atual para oferecer ao usuário um controle mais preciso sobre o nível de risco.
//+------------------------------------------------------------------+ //| Update the ATR stop loss | //+------------------------------------------------------------------+ void check_atr_stop() { for(int i = PositionsTotal() -1; i >= 0; i--) { string symbol = PositionGetSymbol(i); if(_Symbol == symbol) { ulong ticket = PositionGetInteger(POSITION_TICKET); double position_price = PositionGetDouble(POSITION_PRICE_OPEN); double type = PositionGetInteger(POSITION_TYPE); double current_stop_loss = PositionGetDouble(POSITION_SL); if(type == POSITION_TYPE_BUY) { double atr_stop_loss = (ask - (atr_stop)); double atr_take_profit = (ask + (atr_stop)); if((current_stop_loss < atr_stop_loss) || (current_stop_loss == 0)) { trade.PositionModify(ticket,atr_stop_loss,atr_take_profit); } } else if(type == POSITION_TYPE_SELL) { double atr_stop_loss = (bid + (atr_stop)); double atr_take_profit = (bid - (atr_stop)); if((current_stop_loss > atr_stop_loss) || (current_stop_loss == 0)) { trade.PositionModify(ticket,atr_stop_loss,atr_take_profit); } } } } }
Por fim, precisamos definir 2 funções responsáveis por abrir posições de compra e venda, além de suas respectivas funções complementares para fechamento das posições.
//+------------------------------------------------------------------+ //| Open buy positions | //+------------------------------------------------------------------+ void check_buy() { if(PositionsTotal() == 0) { for(int i=0; i < position_size;i++) { trade.Buy(min_volume * lot_multiplier,_Symbol,ask,buy_stop_loss,0,"BUY"); Print("Position: ",i," has been setup"); } } } //+------------------------------------------------------------------+ //| Open sell positions | //+------------------------------------------------------------------+ void check_sell() { if(PositionsTotal() == 0) { for(int i=0; i < position_size;i++) { trade.Sell(min_volume * lot_multiplier,_Symbol,bid,sell_stop_loss,0,"SELL"); Print("Position: ",i," has been setup"); } } } //+------------------------------------------------------------------+ //| Close all buy positions | //+------------------------------------------------------------------+ void close_buy() { ulong ticket; int type; if(PositionsTotal() > 0) { for(int i = 0; i < PositionsTotal();i++) { if(PositionGetSymbol(i) == _Symbol) { ticket = PositionGetTicket(i); type = (int)PositionGetInteger(POSITION_TYPE); if(type == POSITION_TYPE_BUY) { trade.PositionClose(ticket); } } } } } //+------------------------------------------------------------------+ //| Close all sell positions | //+------------------------------------------------------------------+ void close_sell() { ulong ticket; int type; if(PositionsTotal() > 0) { for(int i = 0; i < PositionsTotal();i++) { if(PositionGetSymbol(i) == _Symbol) { ticket = PositionGetTicket(i); type = (int)PositionGetInteger(POSITION_TYPE); if(type == POSITION_TYPE_SELL) { trade.PositionClose(ticket); } } } } }
Vamos observar os últimos 3 níveis de preço.
//+------------------------------------------------------------------+ //| Get the last 3 quotes | //+------------------------------------------------------------------+ void check_price(int candles) { for(int i = 0; i < candles;i++) { close_price[i] = iClose(_Symbol,PERIOD_CURRENT,i); } }
Essa verificação lógica retornará true se estivermos acima da média móvel.
//+------------------------------------------------------------------+ //| Are we completely above the MA? | //+------------------------------------------------------------------+ bool above_channel() { return (((close_price[0] - moving_average_high_array[0] > 0)) && ((close_price[0] - moving_average_low_array[0]) > 0)); }
Vamos verificar se estamos abaixo da média móvel.
//+------------------------------------------------------------------+ //| Are we completely below the MA? | //+------------------------------------------------------------------+ bool below_channel() { return(((close_price[0] - moving_average_high_array[0]) < 0) && ((close_price[0] - moving_average_low_array[0]) < 0)); }
Vamos fechar todas as posições que temos abertas.
//+------------------------------------------------------------------+ //| Close all positions we have | //+------------------------------------------------------------------+ void close_all() { if(PositionsTotal() > 0) { ulong ticket; for(int i =0;i < PositionsTotal();i++) { ticket = PositionGetTicket(i); trade.PositionClose(ticket); } } }
Calculamos o tamanho de lote ideal a ser utilizado, de modo que nossa margem corresponda ao valor de capital que estamos dispostos a arriscar.
//+------------------------------------------------------------------+ //| Calculate the lot size to be used | //+------------------------------------------------------------------+ void calculate_lot_size() { //--- This is the total percentage of the account we're willing to part with for margin, or to keep a position open in other words. Print("Risk Equity: ",risk_equity); //--- Now that we're ready to part with a discrete amount for margin, how many positions can we afford under the current lot size? //--- By default we always start from minimum lot position_size = risk_equity / margin; //--- We need to keep the number of positions lower than 10 if(position_size > 10) { //--- How many times is it greater than 10? int estimated_lot_size = (int) MathFloor(position_size / 10); position_size = risk_equity / (margin * estimated_lot_size); Print("Position Size After Dividing By margin at new estimated lot size: ",position_size); int estimated_position_size = position_size; //--- Can we increase the lot size this many times? if(estimated_lot_size < max_volume_increase) { Print("Est Lot Size: ",estimated_lot_size," Position Size: ",estimated_position_size); lot_multiplier = estimated_lot_size; position_size = estimated_position_size; } } }
Fechamos as posições abertas e verificamos se podemos voltar a operar.
//--- This function will help us keep track of which side we need to enter the market void close_all_and_enter() { if(PositionSelect(Symbol())) { // Determine the type of position check_signal(); } else { Print("No open position found."); } }
Se atingirmos nossa meta de lucro, fechamos todas as posições que tivermos para realizar os ganhos e, em seguida, verificamos se podemos abrir novas posições.
//+------------------------------------------------------------------+ //| Chekc if we have reached our profit target | //+------------------------------------------------------------------+ void check_profit() { double current_profit = (AccountInfoDouble(ACCOUNT_EQUITY) - AccountInfoDouble(ACCOUNT_BALANCE)) / PositionsTotal(); if(current_profit > profit_target) { close_all_and_enter(); } if((current_profit * PositionsTotal()) < (risk_equity * -1)) { Comment("We've breached our risk equity, consider closing all positions"); } }
Por fim, precisamos de uma função que feche todas as nossas operações com prejuízo.
//+------------------------------------------------------------------+ //| Close all losing trades | //+------------------------------------------------------------------+ void close_profitable_trades() { for(int i=PositionsTotal()-1; i>=0; i--) { if(PositionSelectByTicket(PositionGetTicket(i))) { if(PositionGetDouble(POSITION_PROFIT)>profit_target) { ulong ticket; ticket = PositionGetTicket(i); trade.PositionClose(ticket); } } } } //+------------------------------------------------------------------+
Figura 11: Nosso EA
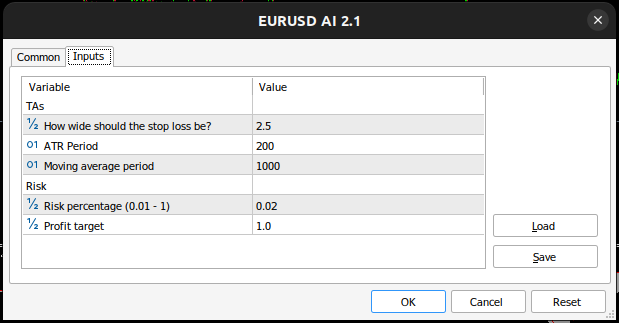
Figura 12: Parâmetros que utilizamos para testar o aplicativo
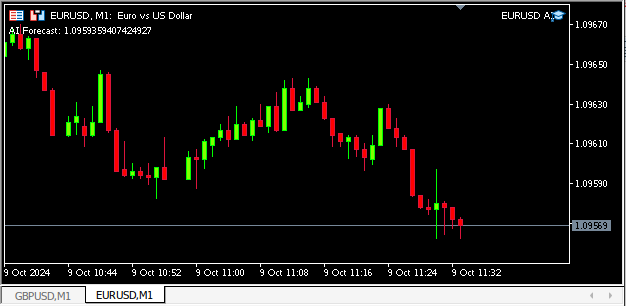
Figura 13: Nosso aplicativo em ação
Considerações finais
Embora nossos resultados não tenham sido encorajadores, eles estão longe de serem conclusivos. Existem outras formas de interpretar o indicador MACD que podem merecer uma avaliação. Por exemplo, durante uma tendência de alta, a linha de sinal do MACD cruza acima da linha principal, e durante uma tendência de baixa, ela cruza para baixo da linha principal. Observar o indicador sob essa perspectiva pode gerar métricas de erro diferentes. Não podemos simplesmente assumir que todas as estratégias de interpretação do MACD apresentarão os mesmos níveis de erro. Antes de formarmos uma opinião sobre a eficácia do indicador, seria sensato avaliar o desempenho de várias estratégias baseadas no MACD.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/16066
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso