
Переосмысливаем классические стратегии (Часть VIII): Валютные рынки и драгоценные металлы в валютной паре USDCAD

В настоящей серии статей мы стремимся исследовать широкий спектр возможных применений искусственного интеллекта в торговых стратегиях. Наша цель - предоставить вам информацию, необходимую для принятия обоснованного решения, прежде чем начать инвестировать свой капитал в стратегию, основанную на искусственном интеллекте. Надеемся, что вы сможете определить стратегию, которая будет соответствовать вашим уровням толерантности к определенным рискам.
Обзор торговой стратегии
В ходе сегодняшней дискуссии мы попытаемся раскрыть взаимосвязь между рынками валюты и драгоценных металлов. Драгоценные металлы являются неотъемлемой частью любой современной экономики. Это связано с широким спектром их промышленного применения - от электроники до здравоохранения. Колебания цен на драгоценные металлы создают инфляцию для производителей готовой продукции, что может привести к снижению уровня внутреннего производства или, с другой стороны, к снижению уровня спроса в странах, экспортирующих эти металлы.
Золото является одной из основных статей экспорта полезных ископаемых как Канады, так и Америки. Природная стойкость золота к коррозии делает его востребованным как разработчиками чувствительного электронного оборудования, так и ювелирами. С другой стороны, палладий востребован во многих отраслях промышленности, особенно в автомобильной. В автомобиле имеется более 20 различных компонентов, для которых требуются каталитические преобразователи, наиболее широко известные из которых встроены в выхлопные трубы. Каждый из этих преобразователей, помимо прочего, содержит значительное количество палладия. Канада и Америка являются ведущими экспортерами транспортных средств. Следовательно, цены на эти драгоценные металлы будут оказывать определенное влияние на внутреннее производство в этих двух странах.
В прошлом корреляция между ценой на золото и курсом доллара была обратной. Всякий раз, когда доллар показывал плохие результаты, инвесторы, как правило, закрывали все свои позиции, в которых ставки сделаны на доллар, и вместо этого хеджировали свои деньги в золоте. Однако в дни количественного смягчения, которые сейчас наступают, корреляции уже не столь очевидны.
Обзор методологии
Мы бы хотели, чтобы наш компьютер сам обучился своей стратегии, исходя из цен на этих трех рынках. Естественно, у нас может быть определенная предубежденность верить в стратегии, которые призывают или имеют интуитивный смысл для нас, в отношении стратегий, которые проваливаются. Однако, алгоритмически обучаясь стратегии, наш компьютер может научиться распознавать взаимосвязи, на раскрытие которых у нас, возможно, ушла бы целая жизнь. Либо он также может выявить ограничения в точности нашей стратегии,чтобы оценить, насколько надежны рынки драгоценных металлов при прогнозировании валютных рынков. Мы попытались спрогнозировать обменный курс USDCAD, используя 3 группы предикторов:
- Котировки по валютной паре USDCAD
- Котировки по валютным парам XAUUSD и XPDUSD
- Набор из вышеперечисленного.
Мы извлекли все наши данные непосредственно из терминала MetaTrader 5 с помощью специального скрипта, написанного на MQL5. Мы записали данные в формат CSV и обработали их на Python. Более того, мы наблюдали значительные отрицательные уровни корреляции: -0,5 между XAUUSD и USDCAD и, наконец, -.66 между XPDUSD и USDCAD. Однако мы наблюдали лишь умеренный уровень корреляции непосредственно между двумя металлами, равный, 0,37.
Мы попытались визуализировать данные. Однако никаких заметных взаимосвязей, которые мы могли бы увидеть из полученных данных, обнаружено не было. Мы попытались отобразить данные в большем масштабе, используя трехмерную диаграмму рассеяния, но безрезультатно. Данные оказалось сложно разделить.
Исходя из этого, мы обучили несколько моделей прогнозированию обменного курса валютной пары USDCAD с использованием трех групп предикторов, которые мы описали ранее. Наиболее эффективной моделью была Линейная модель, использующая первую группу предикторов. Однако, поскольку линейная модель не имеет параметров, которые мы могли бы настроить, мы выбрали вторую по эффективности модель, а именно: линейный опорный векторный регрессор (Linear Support Vector Regressor, LSVR), в качестве нашей наиболее эффективной модели.
Мы успешно настроили гиперпараметры модели LSVR без перенастройки обучающего набора, о чем свидетельствует тот факт, что мы превзошли модель LSVR по умолчанию на невидимых данных. К сожалению, нам не удалось превзойти линейную модель на тех же данных проверки. Мы использовали среднее значение RMSE, рассчитанное путем 5-кратной перекрестной проверки временных рядов без случайной перетасовки для осуществления выбора модели как для обучения, так и для проверки.
После этого мы экспортировали нашу настроенную модель LSVR в формат ONNX и создали наш собственный советник с интегрированным искусственным интеллектом, используя MQL5.
Сбор данных
Я включил удобный скрипт, который вы можете использовать для извлечения данных из вашего терминала MetaTrader 5. Просто прикрепите скрипт к любому графику, который вы хотите проанализировать, и приступайте к работе.
Скрипт просто выберет столько баров, сколько вы укажете во входных данных, и запишет их в формат CSV. Указание времени очень важно, потому что мы будем использовать его позже, когда захотим объединить наши CSV-файлы в один объединенный фрейм данных на Python. Мы будем объединять наши данные только в те дни, которые являются общими для всех них.
Обратите внимание, что мы включаем свойство: “#property script_show_inputs” если вы не включите это свойство в свои скрипты, вы не сможете настроить входные данные скрипта.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //---Amount of data requested input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void OnStart() { //---File name string file_name = "Market Data " + Symbol() + ".csv"; //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i)); } } } //+------------------------------------------------------------------+
Теперь, когда наши данные готовы, мы можем приступить к очистке данных в Python.
Очистка данных
Сначала мы импортируем стандартные библиотеки, которые нам нужны.
#Import the libraries we need import pandas as pd import numpy as np
Это версия библиотеки, которую мы используем в данной демонстрации.
#Display library versions print(f"Pandas version {pd.__version__}") print(f"Numpy version {np.__version__}")
Numpy version 1.26.4
Теперь прочитаем данные в формате CSV, которые мы извлекли.
#Read in the data we need usdcad = pd.read_csv("\\home\\volatily\\.wine\\drive_c\\Program Files\\MetaTrader 5\\MQL5\\Files\\Market Data USDCAD.csv") usdcad = usdcad[::-1] xauusd = pd.read_csv("\\home\\volatily\\.wine\\drive_c\\Program Files\\MetaTrader 5\\MQL5\\Files\\Market Data XAUUSD.csv") xauusd = xauusd[::-1] xpdusd = pd.read_csv("\\home\\volatily\\.wine\\drive_c\\Program Files\\MetaTrader 5\\MQL5\\Files\\Market Data XPDUSD.csv") xpdusd = xpdusd[::-1]
Используем столбец времени в качестве индекса.
#Set the time column as the index usdcad.set_index("Time",inplace=True) xauusd.set_index("Time",inplace=True) xpdusd.set_index("Time",inplace=True)
Объединяем данные.
#Let's merge the data
merged_data = usdcad.merge(xauusd,suffixes=('',' XAU'),left_index=True,right_index=True)
merged_data = merged_data.merge(xpdusd,suffixes=('',' XPD'),left_index=True,right_index=True)
Вот как выглядят наши данные.
merged_data
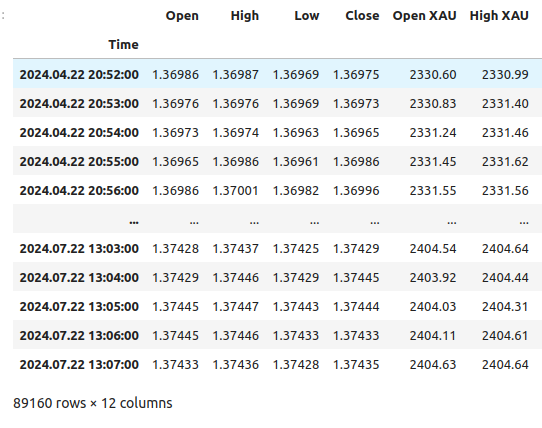
Рис 1: Наш объединенный фрейм данных
Определим, насколько далеко в будущее мы хотим заглянуть в нашем прогнозе.
#Define the forecast horizon look_ahead = 20
Определим 3 группы предикторов, которые мы хотим протестировать.
#Define the predictors and target ohlc_predictors = ['Open','High','Low','Close'] new_predictors = ['Open XAU','High XAU','Low XAU','Close XAU','Open XPD','High XPD','Low XPD','Close XPD'] predictors = ohlc_predictors + new_predictors
Маркировка данных.
#Let's add labels to the data merged_data["Target"] = merged_data["Close"].shift(-look_ahead)
Давайте также создадим метки, которые будут полезны при визуализации данных. Эти метки будут содержать краткую информацию об изменениях на каждом рынке.
#Let's also add labels to help us visualize the relationships merged_data["Binary Target"] = np.nan merged_data["XAU Target"] = np.nan merged_data["XPD Target"] = np.nan #Define the target values #Changes in the USDCAD Exchange rate merged_data.loc[merged_data["Close"] > merged_data["Target"],"Binary Target"] = 0 merged_data.loc[merged_data["Close"] < merged_data["Target"],"Binary Target"] = 1 #Changes in the price of Gold merged_data.loc[merged_data["Close XAU"] > merged_data["Close XAU"].shift(-look_ahead),"XAU Target"] = 0 merged_data.loc[merged_data["Close XAU"] < merged_data["Close XAU"].shift(-look_ahead),"XAU Target"] = 1 #Changes in the price of Palladium merged_data.loc[merged_data["Close XPD"] > merged_data["Close XPD"].shift(-look_ahead),"XPD Target"] = 0 merged_data.loc[merged_data["Close XPD"] < merged_data["Close XPD"].shift(-look_ahead),"XPD Target"] = 1 #Drop any NA values merged_data.dropna(inplace=True)
Разведочный анализ данных
Для визуализации наших данных сначала импортируем необходимые библиотеки.
#Explorartory data analysis import seaborn as sns import matplotlib.pyplot as plt
Отображение версий библиотек.
#Display library version print(f"Seaborn version: {sns.__version__}")
Сначала выполним сброс индекса нашего объединенного фрейма данных.
#Reset the index
merged_data.reset_index(inplace=True)
Теперь создадим карту корреляции. Как видно, между двумя драгоценными металлами и парой USDCAD существует значительно более сильные уровни корреляции. Это согласуется с нашим фундаментальным анализом роли, которую играют эти металлы в валовом внутреннем продукте обеих стран. К сожалению, это не привело к улучшению показателей при попытке спрогнозировать обменный курс валютной пары USDCAD.#Correlation heatmap fig , ax = plt.subplots(figsize=(7,7)) sns.heatmap(merged_data.loc[:,predictors].corr(),annot=True,ax=ax)

Рис 2: Наша карта корреляции
Мы создали два категориальных графика, суммирующих все случаи, когда цены на золото или палладий росли (столбец 1) или падали (столбец 2). После этого мы выделили цветом каждую из точек, чтобы указать, вырос ли обменный курс валютной пары USDCAD, обозначенный оранжевыми точками, или упал, обозначенный синими точками. Как мы видим, у нас есть смесь обоих результатов в обоих столбцах. Возможно, это говорит о том, что изменения обменного курса USDCAD не зависят от изменений цен на выбранные нами драгоценные металлы.
#Let's create categorical plots sns.catplot(data=merged_data,x="XAU Target",y="Close",hue="Binary Target")
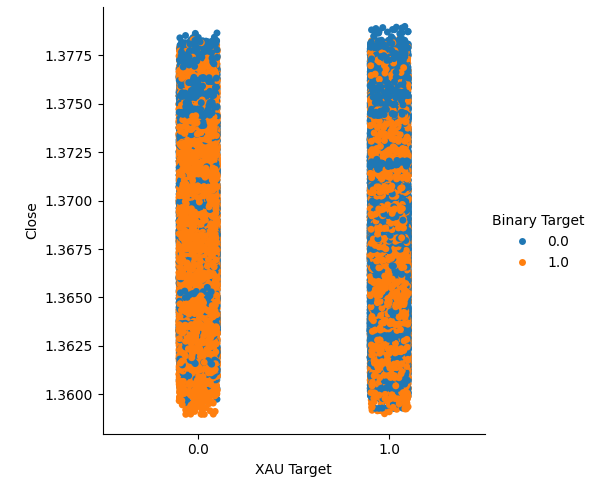
Рис. 3: Категориальный график цены на золото и цены закрытия валютной пары USDCAD
#Let's create categorical plots sns.catplot(data=merged_data,x="XPD Target",y="Close",hue="Binary Target")
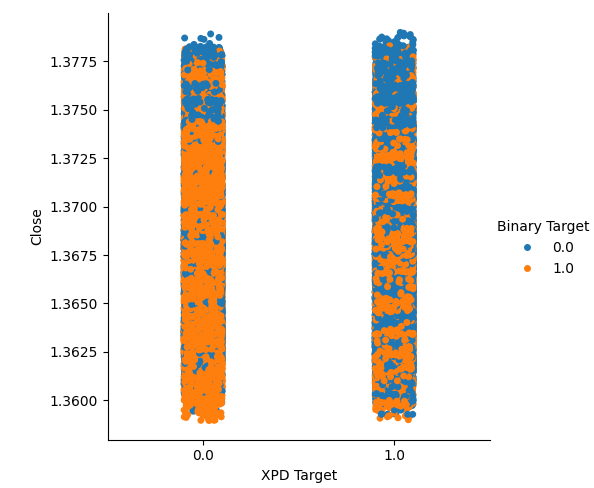
Рис. 4: Категориальный график зависимости цены на палладий от цены пары USDCAD
Впоследствии мы создали диаграммы рассеяния, чтобы наглядно представить разницу между ценой закрытия на рынке палладия и пары USDCAD. К сожалению, это не привело к какому-либо заметному отношению, которым можно было бы воспользоваться. Мы раскрасили каждую точку, используя ту же оранжевую и синюю цветовую схему, что и выше.
#Let's visualize scatter plots sns.scatterplot(data=merged_data,x="Close XPD",y="Close",hue="Binary Target")
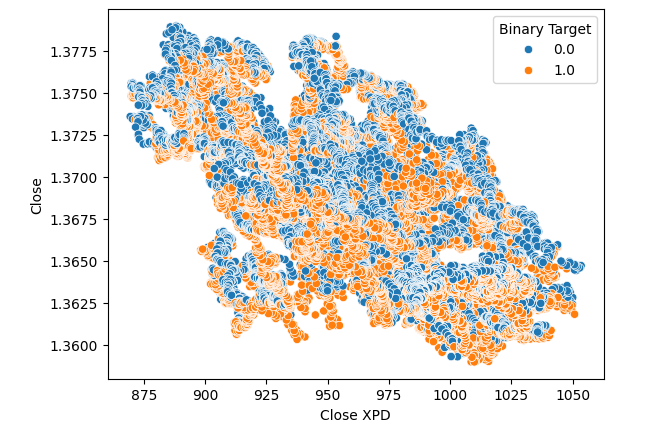
Рис. 5: Диаграмма рассеяния валютной пары XPDUSD по отношению к паре USDCAD
Никаких улучшений не произошло, когда мы заменили цену золота на цену палладия на диаграмме рассеяния.
#Let's visualize scatter plots sns.scatterplot(data=merged_data,x="Close XAU",y="Close",hue="Binary Target")
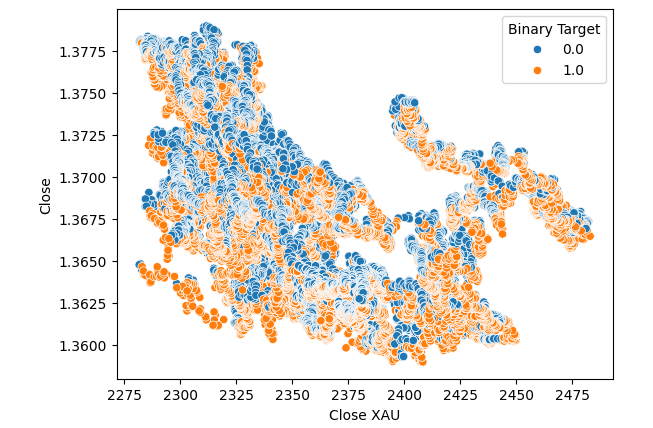
Рис. 6: Диаграмма рассеяния валютной пары XAUUSD по отношению к паре USDCAD на момент закрытия
Мы подумали о том, чтобы провести тестирование на связь между самими этими двумя металлами. Однако эта связь все еще не была для нас очевидна. Мы построили диаграмму рассеяния зависимости цены на золото от цены на палладий и использовали изменение пары USDCAD для раскрашивания каждой точки, но это не принесло никаких улучшений.
#Let's visualize scatter plots sns.scatterplot(data=merged_data,x="Close XPD",y="Close XAU",hue="Binary Target")
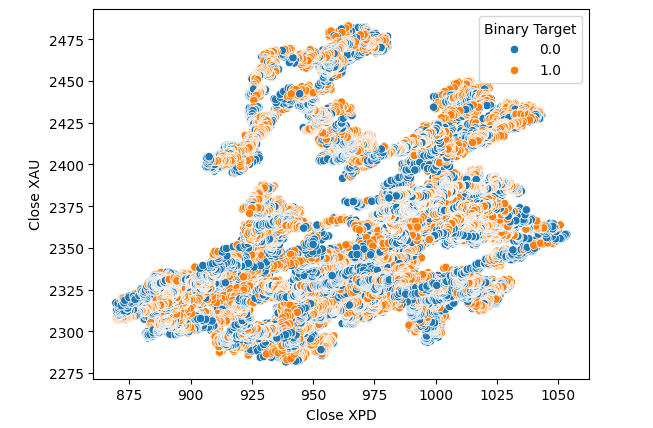
Рис. 7: Диаграмма рассеяния валютной пары XAUUSD по отношению к паре XPDUSD
Иногда взаимосвязи могут быть скрыты, поскольку мы одновременно просматриваем недостаточно переменных, чтобы увидеть эффект. Мы построили диаграмму рассеяния, используя цены закрытия на палладий, золото и валютную пару USDCAD. К сожалению, на полученном графике были выделены кластеры в данных с низким уровнем разделения, что, по сути, подтверждает то, что мы уже знали до сих пор.
#Visualizing 3D data fig = plt.figure(figsize=(7,7)) ax = fig.add_subplot(111,projection='3d') colors = ['blue' if movement == 0 else 'orange' for movement in merged_data.loc[0:1100,"Binary Target"]] ax.scatter(merged_data.loc[0:1100,"Close"],merged_data.loc[0:1100,"Close XAU"],merged_data.loc[0:1100,"Close XPD"],c=colors) #Set labels ax.set_xlabel('USDCAD') ax.set_ylabel('XAUUSD') ax.set_zlabel('XPDUSD')
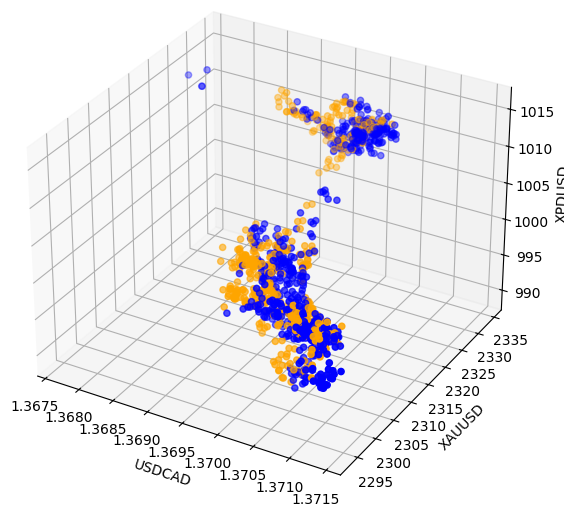
Рис. 8: Визуализация наших рыночных данных в 3D
Моделирование данных
Подготовимся к моделированию наших данных. Сначала мы импортируем стандартные библиотеки.
#Modelling the data
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import RobustScaler
Отображение версий библиотек.
#Print library version print(f"Sklearn version {sklearn.__version__}")
Sklearn version 1.4.1.post1
Прежде чем мы начнем обучать какие-либо модели, нам необходимо сначала масштабировать и стандартизировать данные.
#Scale the data
scaled_data = pd.DataFrame(RobustScaler().fit_transform(merged_data.loc[:,predictors]),columns=predictors)
Теперь разделим данные на две части: одну для обучения и оптимизации, а вторую для проверки и тестирования на предмет избыточного переобучения.
#Split the data train_X,test_X,train_y,test_y = train_test_split(scaled_data,merged_data.loc[:,"Target"],shuffle=False,test_size=0.5)
Теперь импортируем модели.
#Preparing to model the data from sklearn.model_selection import TimeSeriesSplit from sklearn.linear_model import LinearRegression from sklearn.ensemble import RandomForestRegressor , GradientBoostingRegressor , BaggingRegressor from sklearn.svm import LinearSVR from sklearn.neighbors import KNeighborsRegressor from sklearn.neural_network import MLPRegressor from sklearn.metrics import root_mean_squared_error
Создаём объект разделения временного ряда.
#Create the time series split object tscv = TimeSeriesSplit(gap=look_ahead,n_splits=5)
Сохраним модели в виде списка, чтобы можно было перебирать их.
#Create a list of models models = [ LinearRegression(), RandomForestRegressor(), GradientBoostingRegressor(), BaggingRegressor(), LinearSVR(), KNeighborsRegressor(), MLPRegressor(hidden_layer_sizes=(100,10)) ]
Создаем фрейм данных для хранения наших уровней точности.
#List of models columns = [ "Linear Regression", "Random Forest", "Gradient Boost", "Bagging", "Linear SVR", "K-Neighbors", "Neural Network" ] #Create a dataframe to store our error metrics ohlc_error = pd.DataFrame(columns=columns,index=np.arange(0,5)) new_error = pd.DataFrame(columns=columns,index=np.arange(0,5)) all_error = pd.DataFrame(columns=columns,index=np.arange(0,5))
Определяем предикторы для использования.
#Setting the current predictors
current_predictors = predictors
Выполняем кросс-валидацию каждой модели с использованием предикторов, определенных выше.
#Perform cross validation for j in np.arange(0,len(models)): model = models[j] for i,(train,test) in enumerate(tscv.split(train_X)): model.fit(train_X.loc[train[0]:train[-1],current_predictors],train_y.loc[train[0]:train[-1]]) all_error.iloc[i,j] = root_mean_squared_error(train_y.loc[test[0]:test[-1]],model.predict(train_X.loc[test[0]:test[-1],current_predictors]))
Давайте рассмотрим наши уровни ошибок, используя обычные данные OHLC. Из наших визуализаций и сводной статистики становится ясно, что модель линейной регрессии лучше всего справилась с этой задачей.
ohlc_error
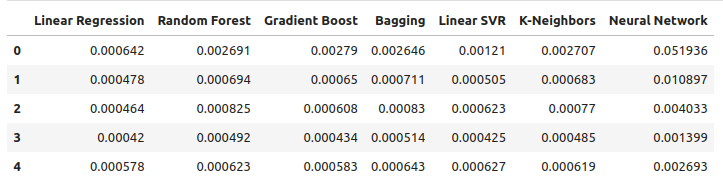
Рис. 9: Наши уровни ошибок при прогнозировании с использованием данных OHLC для пары USDCAD
Построение графика данных.
ohlc_error.plot()
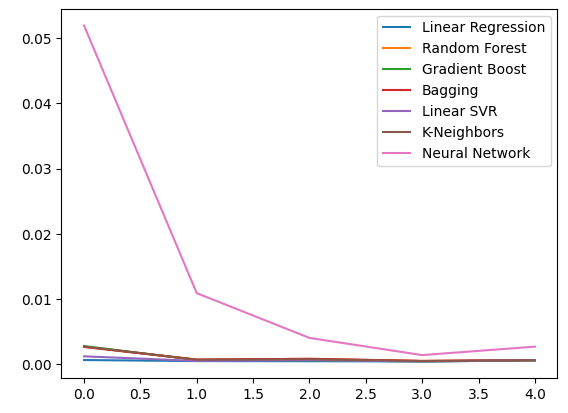
Рис. 10: Точность нашей модели при использовании первого набора предикторов
Создание блочных диаграмм.
fig = plt.figure(figsize=(5,5)) plt.boxplot(ohlc_error)
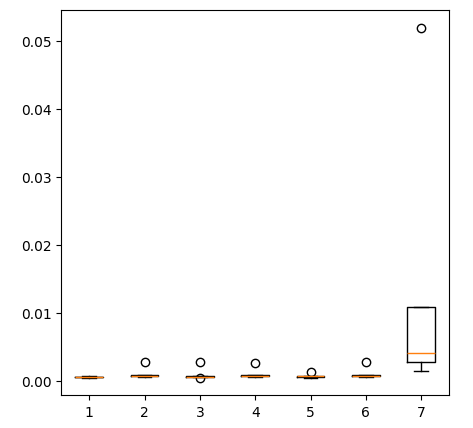
Рис. 11: Точность нашей модели при прогнозировании с помощью первого набора предикторов
Рассмотрим наши уровни ошибок при использовании драгоценных металлов для прогнозирования обменного курса в паре USDCAD. Линейная регрессия по-прежнему остается наиболее эффективной моделью, однако уже не с такой большой маржой.
new_error
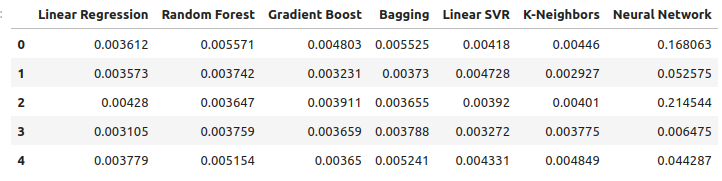
Рис. 12: Наши новые уровни ошибок
Строим график наших новых уровней ошибок.
new_error.plot()
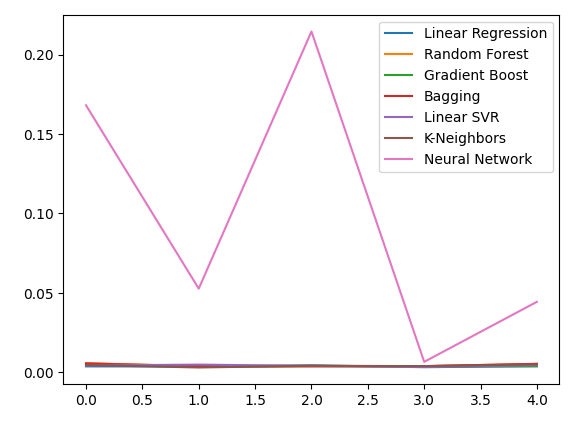
Рис. 13: Наши новые уровни ошибок
Строим блочную диаграмму новых результатов.
fig = plt.figure(figsize=(5,5)) plt.boxplot(new_error)
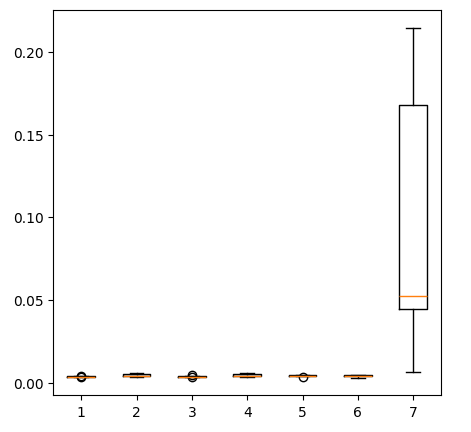
Рис. 14: Наши уровни ошибок при использовании данных о рынке драгоценных металлов
Теперь рассмотрим эффективность при использовании всех доступных данных. Мы по-прежнему наблюдаем, что линейная модель значительно опережает все остальные имеющиеся у нас модели. Давайте попробуем оптимизировать вторую по эффективности модель, а именно LinearSVR, чтобы превзойти линейную регрессию.
all_error
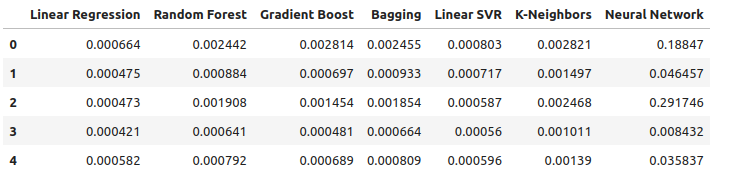
Рис. 15: Наша точность при использовании всех имеющихся данных.
Строим график уровней ошибок.
all_error.plot()
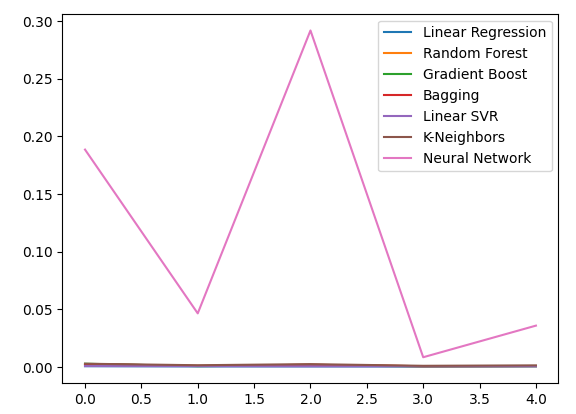
Рис. 16: Линейные графики нашей точности при использовании всех имеющихся у нас данных
Построение блочной диаграммы уровней ошибок, которые мы получили при использовании всех имеющихся у нас данных, показывает, что простая линейная регрессия по-прежнему является нашим лучшим выбором.
fig = plt.figure(figsize=(5,5)) plt.boxplot(all_error)
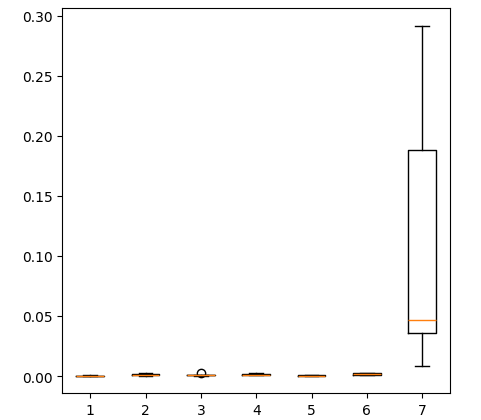
Рис. 17: Блочные диграммы нашей точности при использовании всех имеющихся данных
Средние уровни ошибок наших моделей во всех 5 валидационных наборах ясно показывают, что линейная модель на данный момент является нашим лучшим выбором. Однако, LinearSVR ненамного отстает.
all_error.mean()
Линейная регрессия 0.000523
Случайный лес 0.001333
Градиентный буст 0.001227
Бэггинг-регрессор 0.001343
Линейный SVR 0.000653
Метод k-ближайших соседей 0.001837
Нейросеть 0.114188
dtype: object
Значимость признаков
Прежде чем мы приступим к оптимизации нашей модели, давайте сначала оценим, какие функции кажутся нам важными. Надеемся, что наши данные, относящиеся к рынку драгоценных металлов, покажут свою ценность в этом тесте. Сначала протестируем уровни взаимной информации (mutual information, MI). MI - это показатель того, насколько вы уверены в значении цели, зная значение одного из предикторов. MI рассчитывается по логарифмической шкале, поэтому на практике редко можно встретить оценку MI выше 2.
Мы начинаем с импорта необходимых нам библиотек.
#Mutual information score
from sklearn.feature_selection import mutual_info_regression
Теперь вычисляем значение MI для каждого из наших предикторов.
#Prepare the data for plotting mi = mutual_info_regression(train_X,train_y) mi = mi.reshape(1,12) mi_scores = pd.DataFrame(mi,columns=predictors)
Построение графика наших показателей MI позволяет нам предположить, что данные с рынка пары USDCAD могут быть более информативными, чем все данные с рынка драгоценных металлов. Это подтверждается нашим тестом кросс-валидации, в ходе которого мы наблюдали, что линейная модель, использующая только котировки с рынка USDCAD, выдает наименьшую ошибку.
#Prepare the data for plotting mi = mutual_info_regression(train_X,train_y) mi = mi.reshape(1,12) mi_scores = pd.DataFrame(mi,columns=predictors) #Plot the scores mi_scores.plot.bar()
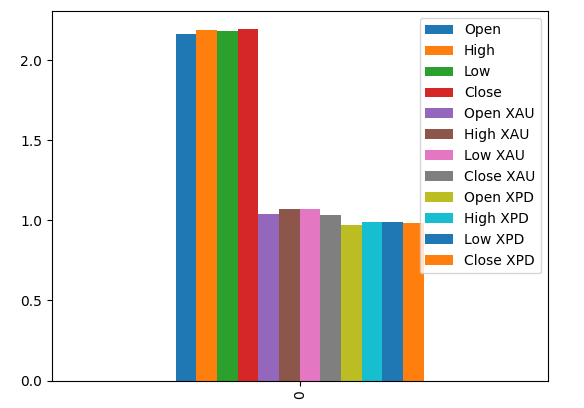
Рис. 18: Значения взаимной информации в наших 3 наборах данных
Далее выполним расчет значений SHAP. Значения SHAP - это "черные ящики", которые помогают нам определить глобальную важность функций в наших моделях машинного обучения.
Импортируем библиотеку SHAP.
#The Linear SVR appears to be performing second best
import shap
Инициализируем модель LSVR.
#Initialize the model
model = LinearSVR()
model.fit(train_X,train_y)
Расчитываем значения SHAP.
#Compute SHAP values
explainer = shap.Explainer(model,train_X)
explanations = explainer(train_X)
Демонстрация глобальной значимости признаков.
#Plot SHAP values
shap.plots.violin(explanations)
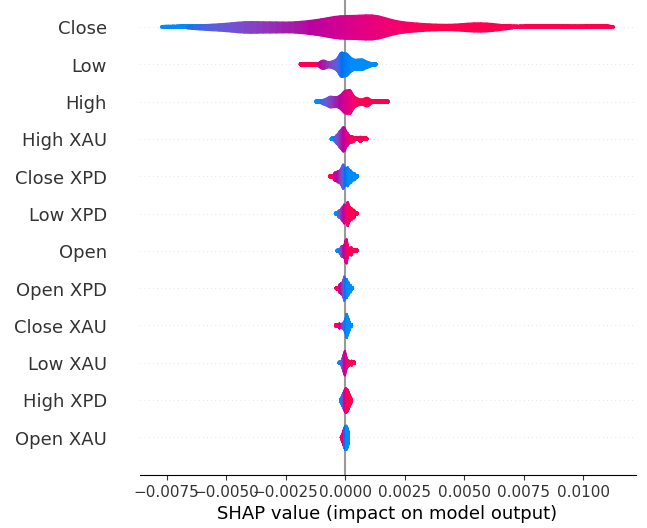
Рис. 19: Наши уровни важности SHAP
Наши объяснения SHAP расходятся с нашей оценкой взаимной информации. Мы подробно рассматривали проблему разногласий в предыдущих статьях, но лучшее, что можно сказать, - это то, что важность функции может быть сложной для оценки и к ней следует относиться со всей серьезностью. Однако оба объяснения предполагают, что на рынках драгоценных металлов содержится некоторая полезная информация.
Настройка гиперпараметров
Настройка нашей модели даст нам возможность работать с невидимыми данными лучше, чем при использовании модели по умолчанию. Чтобы настроить нашу модель, давайте сначала импортируем нужные нам библиотеки.
#Parameter tuning
from sklearn.model_selection import RandomizedSearchCV
Теперь инициализируем модель.
#Reinitialize the model
model = LinearSVR()
Затем определяем наши параметры настройки. Мы передаем модель и словарь возможных значений параметров, за которыми следует общее количество циклов, которые мы хотим выполнить. Мы хотели бы провести 5-кратную кросс-валидацию, чтобы измерить отрицательную среднеквадратичную ошибку, это означает, что мы выберем модель с наименьшей ошибкой проверки. Наконец, установка значения n_jobs равным минус 1 позволяет выполнять поиск параллельно по всем доступным ядрам процессора.
#Define the tuner
tuner = RandomizedSearchCV(
model,
{
"epsilon" : [0,10,100,1000],
"tol":[0.01,0.001,0.0001,0.00001,0.0000001],
"C":[1,10,100,1000,10000],
"loss":['epsilon_insensitive', 'squared_epsilon_insensitive']
},
n_iter=1000,
cv=5,
n_jobs=-1,
scoring="neg_mean_squared_error"
)
Устанавливаем тюнер.
#Let's fit the tuner tuner_results = tuner.fit(train_X,train_y)
Лучшие параметры, обнаруженные нами.
#Let's see the best parameters we found tuner_results.best_params_
{'tol': 1e-05, 'loss': 'squared_epsilon_insensitive', 'epsilon': 0, 'C': 10000}
Тестирование на переобучение
Чтобы протестировать наши модели на предмет переобучения, сначала надо инициализировать их.#Testing for overfitting benchmark = LinearRegression() default_lsvr = LinearSVR() customized_lsvr = LinearSVR(tol=1e-05,loss='squared_epsilon_insensitive',epsilon=0,C=10000)
Теперь выполним сброс индексов таким образом, чтобы выполнить кросс-валидацию.
#Reset the indexes
test_y = test_y.reset_index()
test_X = test_X.reset_index()
Произведем форматирование данных.
#Format the data test_y = test_y.loc[:,"Target"] test_X = test_X.loc[:,predictors]
Создаем фрейм данных для хранения наших уровней ошибок.
#Create dataframes to store our error levels test_error = pd.DataFrame(columns=["Linear Regression","LSVR","Customized LSVR"],index=[0,1,2,3,4])
Обучение моделей на обучающей выборке.
#Fit the models on the training set
benchmark.fit(train_X,train_y)
default_lsvr.fit(train_X,train_y)
customized_lsvr.fit(train_X,train_y)
Сохраним модели в виде списка.
models = [benchmark,default_lsvr,customized_lsvr]
Выполним кросс-валидацию каждой модели на тестовом наборе.
for j in np.arange(0,len(models)): model = models[j] for i,(train,test) in enumerate(tscv.split(test_X)): model.fit(test_X.loc[train[0]:train[-1],:],test_y.loc[train[0]:train[-1]]) test_error.iloc[i,j] = root_mean_squared_error(test_y.loc[test[0]:test[-1]],model.predict(test_X.loc[test[0]:test[-1],:]))
Наша тестовая ошибка.
test_error
| Линейная регрессия | LSVR | Настраиваемый LSVR |
|---|---|---|
| 0.000598 | 0.000542 | 0.000743 |
| 0.000472 | 0.000573 | 0.000722 |
| 0.000318 | 0.000451 | 0.000333 |
| 0.000341 | 0.000366 | 0.000499 |
| 0.00043 | 0.000839 | 0.00043 |
Согласно нашим средним показателям эффективности во всех 5 папках, наша линейная модель по-прежнему оставалась самой эффективной. Однако нам удалось превзойти стандартную модель.
#Let's calculate our mean performances test_error.mean()
Линейная регрессия 0.000432
LSVR 0.000554
Настраиваемый LSVR 0.000545
dtype: object
Демонстрация нашей тестовой ошибки.
#Let's visualize our error test_error.plot()
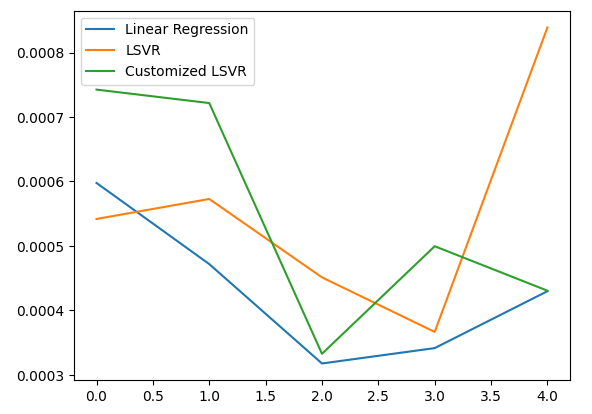
Рис. 20: Демонстрация нашей тестовой ошибки
Создаем блочную диаграмму частоты наших тестовых ошибок.
#Create a boxplot of the error
sns.boxplot(data=test_error)
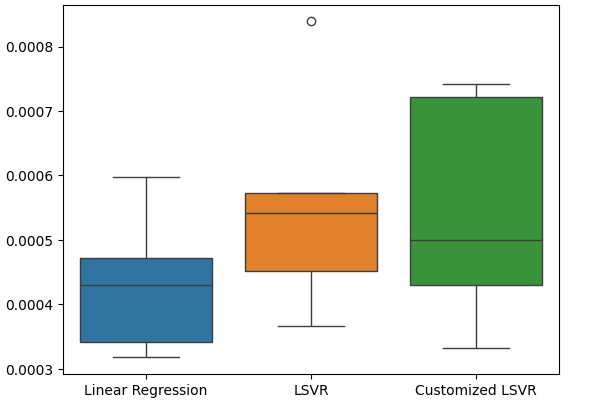
Рис. 21: Демонстрация нашей тестовой ошибки
Подготовка модели к экспорту в ONNX
Прежде чем мы сможем экспортировать нашу модель в формат ONNX, сначала надо масштабировать и стандартизировать данные, вычитая среднее значение и деля на стандартное отклонение, после чего мы запишем наши коэффициенты масштабирования в CSV таким образом, чтобы воспроизвести процедуру в MQL5.
Сначала создаем фрейм данных для хранения наших коэффициентов масштабирования.
#Let's scale our data scaling_factors = pd.DataFrame(columns=predictors,index=['mean','standard deviation']) X = merged_data.loc[:,predictors] y = merged_data.loc[:,"Target"]
Затем сохраняем среднее значение и стандартное отклонение и, наконец, выполняем процедуру масштабирования.
#Let's fill each column for i in np.arange(0,len(predictors)): scaling_factors.iloc[0,i] = X.iloc[:,i].mean() scaling_factors.iloc[1,i] = X.iloc[:,i].std() X.iloc[:,i] = ( ( X.iloc[:,i] - scaling_factors.iloc[0,i] ) / scaling_factors.iloc[1,i])
Сохраняем коэффициенты масштабирования.
#Save the scaling factors as a CSV scaling_factors.to_csv("/home/volatily/.wine/drive_c/Program Files/MetaTrader 5/MQL5/Files/usd_cad_xau_xpd_scaling_factors.csv")
Экспорт модели в ONNX формат
ONNX расшифровывается как Open Neural Network Exchange (ONNX) и представляет собой совместимую платформу машинного обучения с открытым исходным кодом, позволяющую разработчикам создавать, совместно использовать и развертывать модели машинного обучения в среде, не зависящей от языка. Это достигается путем представления каждой модели машинного обучения в виде дерева узлов и графиков, которые могут быть повторно собраны в исходную модель с помощью любого языка, поддерживающего ONNX API.
Сначала мы импортируем необходимые нам библиотеки.
#Let's prepare to export our model to ONNX format import onnx import netron import skl2onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Отображение версий библиотек.
#Display library versions print(f"Onnx version: {onnx.__version__}") print(f"Netron version: {netron.__version__}") print(f"Skl2onnx version: {skl2onnx.__version__}")
Onnx version: 1.15.0
Netron version: 7.8.0
Skl2onnx version: 1.16.0
Теперь определим типы входных данных нашей модели.
#Define the input type
initial_types = [('float_input',FloatTensorType([1,12]))]
Давайте обучим модель на основе всех имеющихся у нас данных.
#Train the model on all the data we have customized_lsvr = LinearSVR(tol=1e-05,loss='squared_epsilon_insensitive',epsilon=0,C=10000) customized_lsvr.fit(X,y)
Сконвертируем модель в ONNX format.
#Covert the sklearn model
onnx_model = convert_sklearn(customized_lsvr,initial_types=initial_types)
Сохраним модель ONNX.
#Save the onnx model onnx_name = "USDCAD XAUUSD XPDUSD M1 Float.onnx" onnx.save(onnx_model,onnx_name)
Просмотр модели ONNX.
#View the onnx model
netron.start(onnx_name)

Рис. 22: Просмотр наших моделей ONNX в Netron

Рис. 23: Параметры нашей модели ONNX соответствуют нашим ожиданиям в отношении входных и выходных данных модели
Реализация средствами MQL5
Чтобы внедрить интегрированный с искусственным интеллектом советник в MQL5, нам сначала нужно загрузить модель ONNX, которую мы экспортировали ранее.
//+------------------------------------------------------------------+ //| USDCAD AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Resources | //+------------------------------------------------------------------+ #resource "\\Files\\USDCAD XAUUSD XPDUSD M1 Float.onnx" as const uchar onnx_buffer[];
Далее мы должны загрузить торговую библиотеку, чтобы можно было открывать и закрывать позиции.
//+------------------------------------------------------------------+ //| Libraries we need | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
Давайте также определим несколько глобальных переменных, которые понадобятся нам на протяжении всей нашей программы.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; double mean_values[12],std_values[12]; vectorf model_output = vectorf::Zeros(1); int model_forecast,state; double ask,bid;
Давайте определим вспомогательные функции, которые мы будем использовать в нашей программе. Нам нужна функция, отвечающая за загрузку нашей ONNX-модели и настройку ее форм ввода и вывода. Мы сделаем это с помощью функции, которая возвращает значение true в случае успешного выполнения, а в противном случае - значение false. Наша функция сначала создает модель из буфера, который мы создали ранее, затем пытается установить и проверить входные и выходные формы.
//+------------------------------------------------------------------+ //| This function is responsible for loading our ONNX model | //+------------------------------------------------------------------+ bool load_onnx(void) { //--- First we must create the model from the buffer onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Now we shall define our I/O shape ulong input_shape [] = {1,12}; ulong output_shape [] = {1,1}; if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set ONNX input shape!"); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set ONNX output shape!"); return(false); } //--- Everything went fine return(true); } //+------------------------------------------------------------------+
Эта функция отвечает за чтение CSV-файла, содержащего наши значения масштабирования, и сохранение их в определенных нами массивах с глобальной областью действия.
//+------------------------------------------------------------------+ //| This function will read our scaling factors and store them | //+------------------------------------------------------------------+ bool load_scaling_factors(void) { //--- Read in the file string file_name = "usd_cad_xau_xpd_scaling_factors.csv"; //--- Try open the file int result = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI,","); //Strings of ANSI type (one byte symbols). //--- Check the result if(result != INVALID_HANDLE) { Print("Opened the file"); //--- Store the values of the file int counter = 0; string value = ""; while(!FileIsEnding(result) && !IsStopped()) //read the entire csv file to the end { if(counter > 100) //if you aim to read 10 values set a break point after 10 elements have been read break; //stop the reading progress value = FileReadString(result); Print("Trying to read string: ",value," count value: ",counter); //--- Check where we are if((counter >= 14) && (counter < 26)) { mean_values[counter - 14] = (float) value; } //--- Check where we are if((counter >= 27) && (counter < 39)) { std_values[counter - 27] = (float) value; } //--- Reading a new row if(FileIsLineEnding(result)) { Print("row++"); } counter++; } //---Close the file ArrayPrint(mean_values); ArrayPrint(std_values); FileClose(result); return(true); } //--- We failed to find the file else { Comment("Failed to find the file containing scaling factors"); return(false); } }
Нам также нужна функция, отвечающая за получение обновленных ценовых котировок с рынка.
//+------------------------------------------------------------------+ //| Update market prices | //+------------------------------------------------------------------+ void update_market_prices(void) { ask = SymbolInfoDouble(_Symbol,SYMBOL_ASK); bid = SymbolInfoDouble(_Symbol,SYMBOL_BID); }
Наконец, нам нужна функция для получения прогнозов из нашей модели. Прежде чем передавать данные в нашу модель, наша функция прогнозирования сначала масштабирует их.
//+------------------------------------------------------------------+ //| Model predict | //+------------------------------------------------------------------+ void model_predict(void) { //--- First fetch the market data vectorf model_input = { iOpen("USDCAD",PERIOD_CURRENT,0),iHigh("USDCAD",PERIOD_CURRENT,0),iLow("USDCAD",PERIOD_CURRENT,0),iClose("USDCAD",PERIOD_CURRENT,0), iOpen("XAUUSD",PERIOD_CURRENT,0),iHigh("XAUUSD",PERIOD_CURRENT,0),iLow("XAUUSD",PERIOD_CURRENT,0),iClose("XAUUSD",PERIOD_CURRENT,0), iOpen("XPDUSD",PERIOD_CURRENT,0),iHigh("XPDUSD",PERIOD_CURRENT,0),iLow("XPDUSD",PERIOD_CURRENT,0),iClose("XPDUSD",PERIOD_CURRENT,0) }; //--- Now standardize and scale the data for(int i =0; i < 12; i++) { model_input[i] = ((model_input[i] - mean_values[i]) / std_values[i]); } //--- Now fetch a prediction from our model OnnxRun(onnx_model,ONNX_DEFAULT,model_input,model_output); //--- Store our model's forecat if(model_output[0] > iClose("USDCAD",PERIOD_CURRENT,0)) { model_forecast = 1; } else if(model_output[0] < iClose("USDCAD",PERIOD_CURRENT,0)) { model_forecast = -1; } }
При инициализации нашего советника мы сначала загрузим наш файл ONNX, а затем считаем значения масштабирования. Если какая-либо из этих процедур завершится неудачей, мы прервем весь процесс целиком.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- This function will load our ONNX model if(!load_onnx()) { return(INIT_FAILED); } //--- This function will load our scaling factors if(!load_scaling_factors()) { return(INIT_FAILED); } //--- return(INIT_SUCCEEDED); }
Всякий раз, когда наш советник удаляется с графика, освобождаем ресурсы, которые нам больше не нужны.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up the resources we do not need OnnxRelease(onnx_model); ExpertRemove(); }
Наконец, всякий раз, когда мы получаем изменения в ценах bid и ask, мы сохраняем обновленную цену в памяти и извлекаем новый прогноз из нашей модели искусственного интеллекта. Если у нас нет открытых позиций, мы займем позицию, предложенную нашей моделью искусственного интеллекта, однако, если у нас есть открытая позиция, мы проверим, чтобы убедиться, что прогноз нашей модели искусственного интеллекта не противоречит нашей текущей позиции.
void OnTick() { //--- Update the market prices update_market_prices(); //--- Fetch a forecast from our model model_predict(); //--- Find a trading oppurtunity if(PositionsTotal() == 0) { if(model_forecast == -1) { Trade.Sell(0.2,_Symbol,ask,0,0,"USDCAD AI"); state = -1; } else if(model_forecast == 1) { Trade.Buy(0.2,_Symbol,ask,0,0,"USDCAD AI"); state = 1; } } //--- Check for reversals if(PositionsTotal() > 0) { if(state != model_forecast) { Alert("Reversal detected by our AI system, closing all positions now!"); Trade.PositionClose(_Symbol); } } } //+------------------------------------------------------------------+

Рис. 24. Наш советник в действии

Рис. 25: Наша система искусственного интеллекта обнаружила возможный разворот
Заключение
В сегодняшней статье мы продемонстрировали, как вы можете раскрыть скрытые взаимосвязи, которые могут существовать между взаимосвязанными рынками. Однако стоит отметить, что наш эмпирический анализ показывает, что, возможно, было бы лучше использовать обычные рыночные данные и более простые линейные модели. Это может быть правдой, потому что, как мы все хорошо знаем, рыночные данные могут быть зашумленными. А в случае зашумленных данных более простые модели, как правило, превосходят более сложные, поскольку сложные модели чувствительны к изменениям во входных данных.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/15762
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Еще раз спасибо Гамучираю, еще один прекрасно документированный шаблон. Очень полезно иметь практические примеры того, как определить важность признаков, корреляцию и визуализировать результат, используя различные модели данных. По мере чтения мы узнаем о машинном обучении. Сегодняшним уроком для меня стали значения "SHAP". Еще раз спасибо за проделанную работу, я не перестаю удивляться инструментам, которыми располагает Python.