
Ganhe uma Vantagem Sobre Qualquer Mercado (Parte III): Índice de Gastos com Cartões Visa

Introdução
Na era dos big data, existem fontes quase infinitas de dados alternativos disponíveis para o investidor moderno. Cada conjunto de dados tem o potencial de gerar níveis mais altos de precisão ao prever os retornos do mercado. No entanto, poucos conjuntos de dados cumprem essa promessa. Nesta série de artigos, vamos ajudá-lo a explorar o vasto panorama de dados alternativos, para ajudá-lo a tomar uma decisão informada sobre se deve incluir esses conjuntos de dados em sua análise. Por outro lado, se esses conjuntos de dados apresentarem resultados insatisfatórios, podemos ajudá-lo a economizar seu tempo.
Nossa justificativa é que, ao considerar conjuntos de dados alternativos não diretamente disponíveis no Terminal MetaTrader 5, podemos descobrir variáveis que preveem níveis de preço com maior precisão em comparação com o participante casual do mercado, que depende exclusivamente das cotações do mercado.
Resumo da Estratégia de Negociação
A VISA é uma empresa multinacional americana de serviços de pagamento. Foi fundada em 1958 e hoje a empresa opera uma das maiores redes de processamento de transações do mundo. A VISA está bem posicionada para ser uma fonte de dados alternativos confiáveis, pois penetrou em quase todos os mercados do mundo desenvolvido. Além disso, o Banco da Reserva Federal de St. Louis também coleta parte de seus dados macroeconômicos da VISA.
Nesta discussão, vamos analisar o Índice de Gastos com Cartões Visa (SMI). O Índice é um indicador macroeconômico do comportamento dos gastos do consumidor. Os dados são agregados pela VISA, usando suas redes proprietárias e cartões de débito e crédito VISA. Todos os dados são despersonalizados e, na maioria das vezes, coletados nos Estados Unidos. À medida que a VISA continua a agregar dados de diferentes mercados, esse índice pode eventualmente se tornar um benchmark do comportamento global do consumidor.
Usaremos um serviço de API fornecido pelo Banco da Reserva Federal de St. Louis para recuperar os conjuntos de dados do SMI da VISA. A API do Banco Econômico da Reserva Federal (FRED) nos permite acessar centenas de milhares de diferentes séries temporais de dados econômicos coletados de todo o mundo.
Resumo da Metodologia
Os dados do SMI são liberados mensalmente pela VISA e contêm menos de 200 linhas no momento da escrita. Portanto, precisamos de uma técnica de modelagem que seja simultaneamente resistente ao overfitting e flexível o suficiente para capturar relações complexas. Isso pode ser uma tarefa ideal para uma rede neural.
Otimizamos 5 parâmetros de uma rede neural profunda para classificar as mudanças no EURUSD, dado um conjunto de preços ordinários de abertura, alta, baixa e fechamento, com 3 entradas adicionais, sendo os conjuntos de dados da VISA. Nosso modelo otimizado conseguiu atingir 71% de precisão na validação, superando o modelo padrão. No entanto, o leitor deve ter em mente que essa precisão foi com dados mensais!
Empregamos 1000 iterações de um algoritmo de busca randomizada para otimizar a rede neural profunda e treinamos com sucesso o modelo sem overfitting nos dados de treinamento. Por mais impressionantes que esses resultados possam parecer, não podemos afirmar com confiança que a relação observada seja confiável. Nossos algoritmos de seleção de características descartaram todos os 3 conjuntos de dados da VISA ao selecionar as características mais importantes de forma não paramétrica. Além disso, os 3 conjuntos de dados da VISA têm pontuações de informação mútua relativamente baixas, o que pode nos indicar que os conjuntos de dados são independentes ou que falhamos em expor a relação de maneira significativa para nosso modelo.
Extração de Dados
Para buscar os dados que precisamos, você deve primeiro criar uma conta no site do FRED. Após criar a conta, você pode usar sua chave da API do FRED para acessar os dados de séries temporais econômicas mantidos pelo Banco da Reserva Federal de St. Louis e acompanhar nossa discussão. Nossos dados de mercado sobre cotações do EURUSD serão obtidos diretamente do Terminal usando a API Python do MetaTrader 5.
Para começar, carregue as bibliotecas necessárias.
#Import the libraries we need import pandas as pd import seaborn as sns import numpy as np from fredapi import Fred import MetaTrader5 as mt5 from datetime import datetime import time import pytz
Agora configure sua chave da API do FRED e busque os dados que precisamos.
#Let's setup our FredAPI
fred = Fred(api_key="ENTER YOUR API KEY")
visa_discretionary = pd.DataFrame(fred.get_series("VISASMIDSA"),columns=["visa d"])
visa_headline = pd.DataFrame(fred.get_series("VISASMIHSA"),columns=["visa h"])
visa_non_discretionary = pd.DataFrame(fred.get_series("VISASMINSA"),columns=["visa nd"])
Definição do horizonte de previsão.
#Define how far ahead we want to forecast look_ahead = 10
Visualize os Dados
Vamos visualizar os três conjuntos de dados.
visa_discretionary.plot(title="VISA Spending Momentum Index: Discretionary") 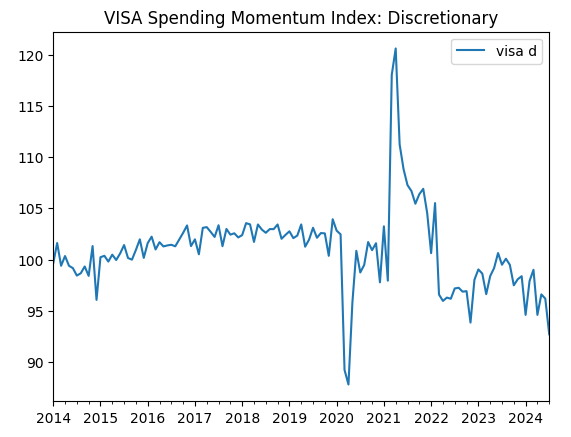
Fig 1: O primeiro conjunto de dados da VISA
Agora vamos visualizar o segundo conjunto de dados.
visa_headline.plot(title="VISA Spending Momentum Index: Headline") 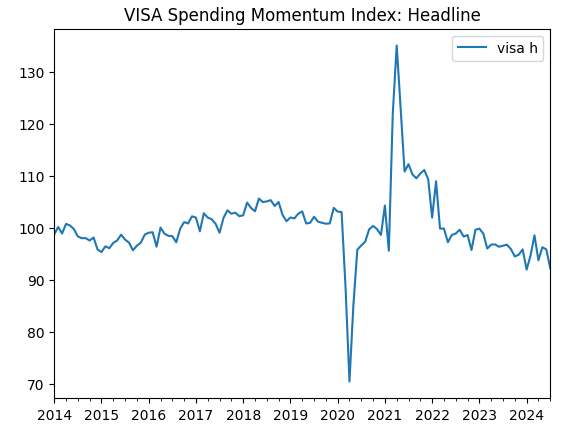
Fig 2: O segundo conjunto de dados da VISA
E finalmente, o nosso terceiro conjunto de dados da VISA.
visa_non_discretionary.plot(title="VISA Spending Momentum Index: Non-Discretionary") 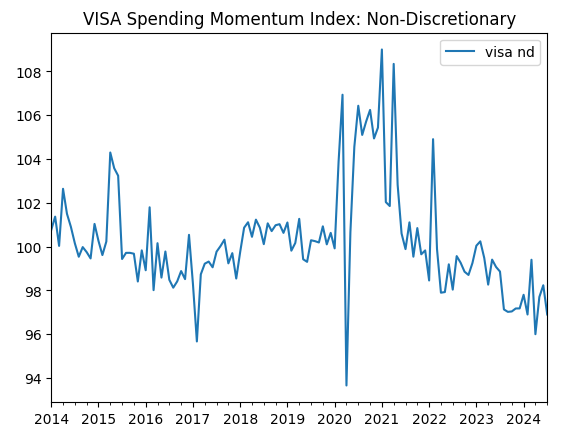
Fig 3: O terceiro conjunto de dados da VISA
Os dois primeiros conjuntos de dados parecem quase idênticos. Além disso, como veremos mais adiante em nossa discussão, eles têm níveis de correlação de 0,89, o que significa que podem conter as mesmas informações. Isso sugere que podemos descartar um e manter o outro. No entanto, deixaremos que nosso algoritmo de seleção de características decida se isso é necessário.
Obtendo os Dados do Nosso Terminal MetaTrader 5
Agora vamos inicializar nosso terminal.
#Initialize the terminal
mt5.initialize()
Agora vamos especificar nosso fuso horário.
#Set timezone to UTC timezone = pytz.timezone("Etc/UTC")
Crie um objeto de data e hora.
#Create a 'datetime' object in UTC utc_from = datetime(2024,7,1,tzinfo=timezone)
Obtendo os dados do MetaTrader 5 e organizando-os em um DataFrame do pandas.
#Fetch the data eurusd = pd.DataFrame(mt5.copy_rates_from("EURUSD",mt5.TIMEFRAME_MN1,utc_from,visa_headline.shape[0]))
Vamos rotular os dados e usar o timestamp como nosso índice.
#Label the data eurusd["target"] = np.nan eurusd.loc[eurusd["close"] > eurusd["close"].shift(-look_ahead),"target"] = 0 eurusd.loc[eurusd["close"] < eurusd["close"].shift(-look_ahead),"target"] = 1 eurusd.dropna(inplace=True) eurusd.set_index("time",inplace=True)
Agora vamos combinar os conjuntos de dados usando as datas que eles compartilham.
#Let's merge the datasets merged_data = eurusd.merge(visa_headline,right_index=True,left_index=True) merged_data = merged_data.merge(visa_discretionary,right_index=True,left_index=True) merged_data = merged_data.merge(visa_non_discretionary,right_index=True,left_index=True)
Análise Exploratória de Dados
Estamos prontos para explorar nossos dados. Os gráficos de dispersão são úteis para visualizar a relação entre duas variáveis. Vamos observar os gráficos de dispersão criados por cada um dos conjuntos de dados da VISA, plotados contra o preço de fechamento. Os pontos azuis resumem as instâncias em que o preço caiu nas 10 velas seguintes, enquanto os pontos laranja resumem o contrário.
Embora a separação seja ruidosa em direção ao centro do gráfico, parece que nos níveis extremos, os conjuntos de dados da VISA separam os movimentos para cima e para baixo de forma razoavelmente boa.
#Let's create scatter plots sns.scatterplot(data=merged_data,y="close",x="visa h",hue="target").set(title="EURUSD Close Against VISA Momentum Index: Headline")
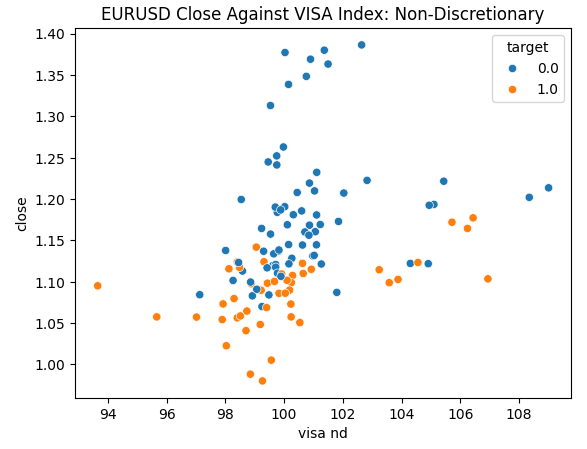
Fig 4: Plotando nosso conjunto de dados não discricionário da VISA contra o fechamento do EURUSD

Fig 5: Plotando nosso conjunto de dados discricionário da VISA contra o fechamento do EURUSD
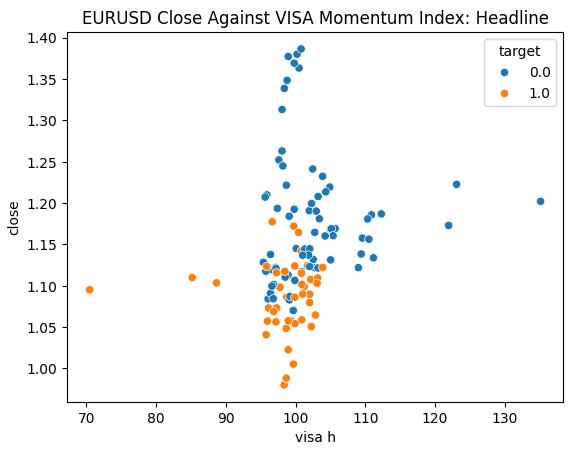
Fig 6: Plotando nosso conjunto de dados Headline da VISA contra o fechamento do EURUSD
Os níveis de correlação entre os conjuntos de dados da VISA e o mercado EURUSD são moderados e todos com valores positivos. Nenhum dos níveis de correlação é particularmente interessante para nós. No entanto, vale ressaltar que o valor positivo indica que as duas variáveis tendem a subir e descer juntas. O que está em linha com nosso entendimento da macroeconomia, já que o gasto do consumidor nos EUA tem algum nível de influência sobre as taxas de câmbio. Se os consumidores coletivamente decidirem não gastar, suas ações reduzirão a quantidade total de moeda em circulação, o que pode causar a valorização do dólar.
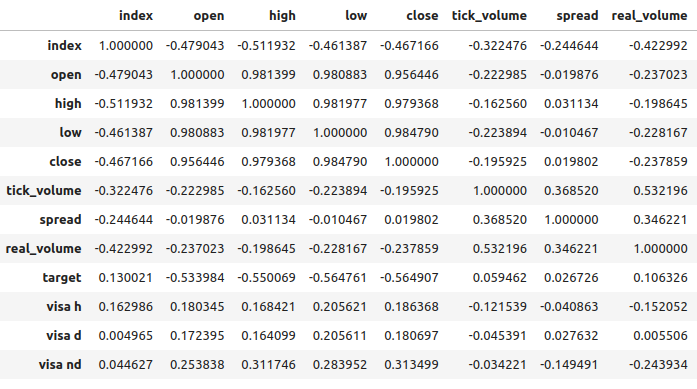
Fig 7: Análise de correlação do nosso conjunto de dados
Seleção de Atributos
Quão importante é a relação entre nosso alvo e nossas novas variáveis? Vamos observar se as novas variáveis serão eliminadas pelo nosso algoritmo de seleção de características. Se o algoritmo não selecionar nenhuma das novas variáveis, isso pode indicar que a relação não é confiável.<br0>
O algoritmo de seleção progressiva começa com um modelo nulo e adiciona uma característica de cada vez, em seguida, seleciona o melhor modelo de uma única variável e começa a buscar uma segunda variável, e assim por diante. Ele nos retornará o melhor modelo que construiu. No nosso estudo, apenas o preço de abertura foi selecionado pelo algoritmo, indicando que a relação pode não ser estável.
Importe as bibliotecas que precisamos.
#Let's see which features are the most important from mlxtend.feature_selection import SequentialFeatureSelector as SFS from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs import matplotlib.pyplot as plt
Crie o objeto de seleção progressiva.
#Create the forward selection object sfs = SFS( MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"]), k_features=(1,train_X.shape[1]), forward=False, scoring="accuracy", cv=5 ).fit(train_X,train_y)
Agora vamos plotar os resultados.
fig1 = plot_sfs(sfs.get_metric_dict(),kind="std_dev") plt.title("Neural Network Backward Feature Selection") plt.grid()
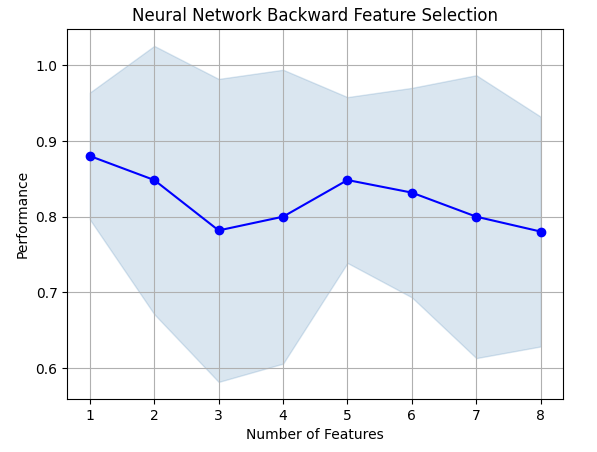
Fig 8: À medida que aumentamos o número de características no modelo, nosso desempenho piorou
Infelizmente, nossa precisão continuou caindo à medida que adicionávamos mais características. Isso pode significar que a associação simplesmente não é tão forte, ou que não estamos expondo a associação de uma forma que nosso modelo consiga interpretar. Então, parece que um modelo com 1 característica ainda pode ser capaz de resolver o problema.
A melhor característica que identificamos.
sfs.k_feature_names_
Agora vamos observar nossas pontuações de informação mútua (MI). A MI nos informa o quanto cada variável tem de potencial para prever o alvo, as pontuações de MI têm valor positivo e variam de 0 até o infinito na teoria, mas na prática raramente observamos pontuações de MI acima de 2 e uma pontuação de MI acima de 1 é boa.
Importe o classificador de MI do scikit-learn.
#Mutual information
from sklearn.feature_selection import mutual_info_classif A pontuação de MI para o conjunto de dados Headline.
#Mutual information from the headline visa dataset, print(f"VISA Headline dataset has a mutual info score of: {mutual_info_classif(train_X.loc[:,['visa h']],train_y)[0]}")
A pontuação de MI para o conjunto de dados Discretionary.
#Mutual information from the second visa dataset, print(f"VISA Discretionary dataset has a mutual info score of: {mutual_info_classif(train_X.loc[:,['visa d']],train_y)[0]}")
Todos os nossos conjuntos de dados tiveram pontuações de MI baixas, o que pode ser uma razão convincente para tentar aplicar diferentes transformações ao conjunto de dados da VISA, e, esperamos, descobrir uma associação mais forte.
Ajuste de Parâmetros
Agora vamos tentar ajustar nossa rede neural profunda para prever o EURUSD. Antes disso, precisamos dimensionar nossos dados. Primeiro, redefina o índice do conjunto de dados combinado.
#Reset the index
merged_data.reset_index(inplace=True)
Defina o alvo e os preditores.
#Define the target target = "target" ohlc_predictors = ["open","high","low","close","tick_volume"] visa_predictors = ["visa d","visa h","visa nd"] all_predictors = ohlc_predictors + visa_predictors
Agora vamos dimensionar e transformar nossos dados. De cada valor em nosso conjunto de dados, vamos subtrair a média e dividir pela desvio padrão da respectiva coluna. Vale notar que essa transformação é sensível a outliers.
#Let's scale the data scale_factors = pd.DataFrame(index=["mean","standard deviation"],columns=all_predictors) for i in np.arange(0,len(all_predictors)): #Store the mean and standard deviation for each column scale_factors.iloc[0,i] = merged_data.loc[:,all_predictors[i]].mean() scale_factors.iloc[1,i] = merged_data.loc[:,all_predictors[i]].std() merged_data.loc[:,all_predictors[i]] = ((merged_data.loc[:,all_predictors[i]] - scale_factors.iloc[0,i]) / scale_factors.iloc[1,i]) scale_factors
Dando uma olhada nos dados dimensionados.
#Let's see the normalized data merged_data
Importando bibliotecas padrão.
#Lets try to train a deep neural network to uncover relationships in the data from sklearn.neural_network import MLPClassifier from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
Crie uma divisão entre treino e teste.
#Create train test partitions for our alternative data train_X,test_X,train_y,test_y = train_test_split(merged_data.loc[:,all_predictors],merged_data.loc[:,"target"],test_size=0.5,shuffle=False)
Ajustando o modelo para as entradas disponíveis. Lembre-se de que primeiro devemos passar o modelo que queremos ajustar e, em seguida, especificar os parâmetros do modelo que estamos interessados. Depois, precisamos indicar quantos folds queremos usar para validação cruzada.
tuner = RandomizedSearchCV(MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False), { "activation": ["relu","identity","logistic","tanh"], "solver": ["lbfgs","adam","sgd"], "alpha": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], "learning_rate": ["constant", "invscaling", "adaptive"], "learning_rate_init": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], }, cv=5, n_iter=1000, scoring="accuracy", return_train_score=False )
Ajustando o tuner.
tuner.fit(train_X,train_y)
Vamos ver os resultados obtidos nos dados de treinamento, em ordem do melhor para o pior.
tuner_results = pd.DataFrame(tuner.cv_results_) params = ["param_activation","param_solver","param_alpha","param_learning_rate","param_learning_rate_init","mean_test_score"] tuner_results.loc[:,params].sort_values(by="mean_test_score",ascending=False)

Fig 9: Nossos resultados de otimização
Nossa maior precisão foi de 88% nos dados de treinamento. Observe que, devido à natureza estocástica do algoritmo de otimização que escolhemos, pode ser desafiador reproduzir os resultados obtidos nesta demonstração.
Testando para Overfitting
Agora vamos comparar nossos modelos padrão e personalizados, para ver se estamos overfitting nos dados de treinamento. Se estivermos overfitting, o modelo padrão superará nosso modelo personalizado no conjunto de validação, caso contrário, nosso modelo personalizado terá um desempenho melhor.
Vamos preparar os 2 modelos.
#Let's compare the default model and our customized model on the hold out set default_model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False) customized_model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"])
Meça a precisão do modelo padrão.
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
accuracy_score(test_y,default_model.predict(test_X))
A precisão do nosso modelo personalizado.
#The accuracy of the defualt model
customized_model.fit(train_X,train_y)
accuracy_score(test_y,customized_model.predict(test_X))
Parece que treinamos o modelo sem overfitting nos dados de treinamento. Também observe que nosso erro de treinamento é tipicamente sempre maior do que o erro de teste, no entanto, a discrepância entre eles não deve ser muito grande. Nosso erro de treinamento foi de 88% e o erro de teste foi de 74%, o que é razoável. Uma grande diferença entre o erro de treinamento e o erro de teste seria alarmante, isso poderia indicar que estamos fazendo overfitting!
Implementando a Estratégia
Primeiro, definimos as variáveis globais que vamos usar.
#Let us now start building our trading strategy SYMBOL = 'EURUSD' TIMEFRAME = mt5.TIMEFRAME_MN1 DEVIATION = 1000 VOLUME = 0 LOT_MULTIPLE = 1
Agora vamos inicializar nosso terminal MetaTrader 5.
#Get the system up
if not mt5.initialize():
print('Failed To Log in')
Agora precisamos saber mais detalhes sobre o mercado.
#Let's fetch the trading volume
for index,symbol in enumerate(mt5.symbols_get()):
if symbol.name == SYMBOL:
print(f"{symbol.name} has minimum volume: {symbol.volume_min}")
VOLUME = symbol.volume_min * LOT_MULTIPLE
Esta função irá buscar o preço atual do mercado para nós.
#A function to get current prices def get_prices(): start = datetime(2024,1,1) end = datetime.now() data = pd.DataFrame(mt5.copy_rates_range(SYMBOL,TIMEFRAME,start,end)) data['time'] = pd.to_datetime(data['time'],unit='s') data.set_index('time',inplace=True) return(data.iloc[-1,:])
Vamos também criar uma função para buscar os dados alternativos mais recentes da API FRED.
#A function to get our alternative data def get_alternative_data(): visa_d = fred.get_series_as_of_date("VISASMIDSA",datetime.now()) visa_d = visa_d.iloc[-1,-1] visa_h = fred.get_series_as_of_date("VISASMIHSA",datetime.now()) visa_h = visa_h.iloc[-1,-1] visa_n = fred.get_series_as_of_date("VISASMINSA",datetime.now()) visa_n = visa_n.iloc[-1,-1] return(visa_d,visa_h,visa_n)
Precisamos de uma função responsável por normalizar e dimensionar nossas entradas.
#A function to prepare the inputs for our model def get_model_inputs(): LAST_OHLC = get_prices() visa_d , visa_h , visa_n = get_alternative_data() return( np.array([[ ((LAST_OHLC['open'] - scale_factors.iloc[0,0]) / scale_factors.iloc[1,0]), ((LAST_OHLC['high'] - scale_factors.iloc[0,1]) / scale_factors.iloc[1,1]), ((LAST_OHLC['low'] - scale_factors.iloc[0,2]) / scale_factors.iloc[1,2]), ((LAST_OHLC['close'] - scale_factors.iloc[0,3]) / scale_factors.iloc[1,3]), ((LAST_OHLC['tick_volume'] - scale_factors.iloc[0,4]) / scale_factors.iloc[1,4]), ((visa_d - scale_factors.iloc[0,5]) / scale_factors.iloc[1,5]), ((visa_h - scale_factors.iloc[0,6]) / scale_factors.iloc[1,6]), ((visa_n - scale_factors.iloc[0,7]) / scale_factors.iloc[1,7]) ]]) )
Vamos treinar nosso modelo com todos os dados que temos.
#Let's train our model on all the data we have model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation="logistic",solver="lbfgs",alpha=0.00001,learning_rate="constant",learning_rate_init=0.00001) model.fit(merged_data.loc[:,all_predictors],merged_data.loc[:,"target"])
Esta função irá obter uma previsão do nosso modelo.
#A function to get a prediction from our model def ai_forecast(): model_inputs = get_model_inputs() prediction = model.predict(model_inputs) return(prediction[0])
Agora chegamos ao coração do nosso algoritmo. Primeiro, verificaremos quantas posições temos abertas. Em seguida, obteremos uma previsão do nosso modelo. Se não tivermos posições abertas, usaremos a previsão do nosso modelo para abrir uma posição. Caso contrário, usaremos a previsão do nosso modelo como um sinal de saída se tivermos posições abertas.
while True: #Get data on the current state of our terminal and our portfolio positions = mt5.positions_total() forecast = ai_forecast() BUY_STATE , SELL_STATE = False , False #Interpret the model's forecast if(forecast == 0.0): SELL_STATE = True BUY_STATE = False elif(forecast == 1.0): SELL_STATE = False BUY_STATE = True print(f"Our forecast is {forecast}") #If we have no open positions let's open them if(positions == 0): print(f"We have {positions} open trade(s)") if(SELL_STATE): print("Opening a sell position") mt5.Sell(SYMBOL,VOLUME) elif(BUY_STATE): print("Opening a buy position") mt5.Buy(SYMBOL,VOLUME) #If we have open positions let's manage them if(positions > 0): print(f"We have {positions} open trade(s)") for pos in mt5.positions_get(): if(pos.type == 1): if(BUY_STATE): print("Closing all sell positions") mt5.Close(SYMBOL) if(pos.type == 0): if(SELL_STATE): print("Closing all buy positions") mt5.Close(SYMBOL) #If we have finished all checks then we can wait for one day before checking our positions again time.sleep(24 * 60 * 60)
Temos 0 negociação(ns) aberta(s)
Abrindo uma posição de venda
Implementação no MQL5
Para implementarmos nossa estratégia em MQL5, primeiro precisamos exportar nossos modelos para o formato Open Neural Network Exchange (ONNX). ONNX é um protocolo para representar modelos de aprendizado de máquina como uma combinação de grafo e arestas. Esse protocolo padronizado permite que desenvolvedores construam e implementem modelos de aprendizado de máquina usando diferentes linguagens de programação com facilidade. Infelizmente, nem todos os modelos de aprendizado de máquina e frameworks são totalmente compatíveis com a API ONNX atual.
Para começar, vamos importar algumas bibliotecas.
#Import the libraries we need import pandas as pd import numpy as np from fredapi import Fred import MetaTrader5 as mt5 from datetime import datetime import time import pytz
Em seguida, precisamos inserir nossa chave da API FRED, para obter acesso aos dados que precisamos.
#Let's setup our FredAPI
fred = Fred(api_key="")
visa_discretionary = pd.DataFrame(fred.get_series("VISASMIDSA"),columns=["visa d"])
visa_headline = pd.DataFrame(fred.get_series("VISASMIHSA"),columns=["visa h"])
visa_non_discretionary = pd.DataFrame(fred.get_series("VISASMINSA"),columns=["visa nd"])
Observe que, após buscar os dados, nós os dimensionamos usando o mesmo formato que foi descrito acima. Omissos esses passos para evitar repetição da mesma informação. A única diferença sutil é que agora estamos treinando o modelo para prever o preço de fechamento real, e não apenas um alvo binário.
Após dimensionar os dados, vamos agora tentar ajustar os parâmetros do nosso modelo.
#A few more libraries we need from sklearn.neural_network import MLPRegressor from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error
Precisamos dividir nossos dados para que tenhamos um conjunto de treinamento para otimizar o modelo e um conjunto de validação que usaremos para testar o overfitting.
#Create train test partitions for our alternative data train_X,test_X,train_y,test_y = train_test_split(merged_data.loc[:,all_predictors],merged_data.loc[:,"close target"],test_size=0.5,shuffle=False)
Agora vamos realizar o ajuste de hiperparâmetros, observe que configuramos a métrica de pontuação para "erro quadrático médio negativo", essa métrica de pontuação irá identificar o modelo que produzir o menor MSE como o modelo de melhor desempenho.
tuner = RandomizedSearchCV(MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False,early_stopping=True), { "activation": ["relu","identity","logistic","tanh"], "solver": ["lbfgs","adam","sgd"], "alpha": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], "learning_rate": ["constant", "invscaling", "adaptive"], "learning_rate_init": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], }, cv=5, n_iter=1000, scoring="neg_mean_squared_error", return_train_score=False, n_jobs=-1 )
Ajustando o objeto tuner.
tuner.fit(train_X,train_y)
Agora vamos testar o overfitting.
#Let's compare the default model and our customized model on the hold out set default_model = MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False) customized_model = MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"])
A precisão do nosso modelo padrão.
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
mean_squared_error(test_y,default_model.predict(test_X))
Conseguimos superar o nosso modelo padrão no conjunto de validação reservado, o que é um bom sinal de que não estamos fazendo overfitting.
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
mean_squared_error(test_y,default_model.predict(test_X))
0.006138795093781729
Agora vamos ajustar o modelo personalizado com todos os dados que temos, antes de exportá-lo para o formato ONNX.
#Fit the model on all the data we have
customized_model.fit(test_X,test_y)
Importando bibliotecas para conversão ONNX.
#Convert to ONNX
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx import convert_sklearn
import netron
import onnx Defina o tipo e a forma de entrada do nosso modelo.
#Define the initial types initial_types = [("float_input",FloatTensorType([1,train_X.shape[1]]))]
Crie uma representação ONNX do modelo na memória.
#Create the onnx representation onnx_model = convert_sklearn(customized_model,initial_types=initial_types,target_opset=12)
Armazene a representação ONNX no disco rígido.
#Save the ONNX model onnx_model_name = "EURUSD VISA MN1 FLOAT.onnx" onnx.save(onnx_model,onnx_model_name)
Veja o modelo ONNX no Netron.
#View the ONNX model
netron.start(onnx_model_name) 
Fig 10: Nossa rede neural profunda no formato ONNX

Fig 11: Metadados do nosso modelo ONNX
Estamos quase prontos para começar a construir nosso Expert Advisor. No entanto, precisamos primeiro criar um serviço Python em segundo plano que buscará os dados do FRED e os passará para o nosso programa.
Primeiro, importamos as bibliotecas necessárias.
#Import the libraries we need import pandas as pd import numpy as np from fredapi import Fred from datetime import datetime
Em seguida, fazemos login usando nossas credenciais do FRED.
#Let's setup our FredAPI fred = Fred(api_key="")
Precisamos definir uma função que buscará os dados para nós e os escreverá em um arquivo CSV.
#A function to write out our alternative data to CSV def write_out_alternative_data(): visa_d = fred.get_series_as_of_date("VISASMIDSA",datetime.now()) visa_d = visa_d.iloc[-1,-1] visa_h = fred.get_series_as_of_date("VISASMIHSA",datetime.now()) visa_h = visa_h.iloc[-1,-1] visa_n = fred.get_series_as_of_date("VISASMINSA",datetime.now()) visa_n = visa_n.iloc[-1,-1] data = pd.DataFrame(np.array([visa_d,visa_h,visa_n]),columns=["Data"],index=["Discretionary","Headline","Non-Discretionary"]) data.to_csv("C:\\Users\\Westwood\\AppData\\Roaming\\MetaQuotes\\Terminal\\D0E8209F77C8CF37AD8BF550E51FF075\\MQL5\\Files\\fred_visa.csv")
Até agora, nossa aplicação está se formando bem, vamos criar variáveis globais que usaremos em diferentes blocos de nossa aplicação.
while True: #Update the fred data for our MT5 EA write_out_alternative_data() #If we have finished all checks then we can wait for one day before checking for new data time.sleep(24 * 60 * 60)Agora precisamos escrever um loop que verificará por novos dados uma vez por dia e atualizará nosso arquivo CSV.
Primeiro, vamos carregar nosso modelo ONNX como um recurso em nossa aplicação. //+------------------------------------------------------------------+ //| VISA EA.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Resorces | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD VISA MN1 FLOAT.onnx" as const uchar onnx_buffer[];
Em seguida, carregaremos a biblioteca de negociações para nos ajudar a abrir e gerenciar nossas posições.
//+------------------------------------------------------------------+ //| Libraries we need | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
Até agora, nossa aplicação está se formando bem, vamos criar variáveis globais que usaremos em diferentes blocos de nossa aplicação.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; double mean_values[8],std_values[8]; float visa_data[3]; vector model_forecast = vector::Zeros(1); double trading_volume = 0.3; int state = 0;
Antes de começarmos a usar nosso modelo ONNX, precisamos primeiro criar o modelo ONNX a partir do recurso que solicitamos no início do programa. Depois disso, precisamos definir as formas de entrada e saída do modelo.
//+------------------------------------------------------------------+ //| Load the ONNX model | //+------------------------------------------------------------------+ bool load_onnx_model(void) { //--- Try create the ONNX model from the buffer we have onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Validate the model if(onnx_model == INVALID_HANDLE) { Comment("Failed to create the ONNX model. ",GetLastError()); return(false); } //--- Set the I/O shape ulong input_shape[] = {1,8}; ulong output_shape[] = {1,1}; //--- Validate the I/O shapes if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set the ONNX model input shape. ",GetLastError()); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set the ONNX model output shape. ",GetLastError()); return(false); } return(true); }
Lembre-se de que padronizamos nossos dados subtraindo a média da coluna e dividindo pelo desvio padrão de cada coluna. Precisamos armazenar esses valores na memória. Como esses valores nunca irão mudar, eu simplesmente os codifiquei diretamente no programa.
//+------------------------------------------------------------------+ //| Mean & Standard deviation values | //+------------------------------------------------------------------+ void load_scaling_values(void) { //--- Mean & standard deviation values for the EURUSD OHLCV mean_values[0] = 1.146552; std_values[0] = 0.08293; mean_values[1] = 1.165568; std_values[1] = 0.079657; mean_values[2] = 1.125744; std_values[2] = 0.083896; mean_values[3] = 1.143834; std_values[3] = 0.080655; mean_values[4] = 1883520.051282; std_values[4] = 826680.767222; //--- Mean & standard deviation values for the VISA datasets mean_values[5] = 101.271017; std_values[5] = 3.981438; mean_values[6] = 100.848506; std_values[6] = 6.565229; mean_values[7] = 100.477269; std_values[7] = 2.367663; }
O serviço Python em segundo plano que criamos sempre nos dará os dados mais recentes disponíveis, vamos criar uma função para ler esse CSV e armazenar os valores em um array para nós.
//+-------------------------------------------------------------------+ //| Read in the VISA data | //+-------------------------------------------------------------------+ void read_visa_data(void) { //--- Read in the file string file_name = "fred_visa.csv"; //--- Try open the file int result = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI,","); //Strings of ANSI type (one byte symbols). //--- Check the result if(result != INVALID_HANDLE) { Print("Opened the file"); //--- Store the values of the file int counter = 0; string value = ""; while(!FileIsEnding(result) && !IsStopped()) //read the entire csv file to the end { if(counter > 10) //if you aim to read 10 values set a break point after 10 elements have been read break; //stop the reading progress value = FileReadString(result); Print("Trying to read string: ",value); if(counter == 3) { Print("Discretionary data: ",value); visa_data[0] = (float) value; } if(counter == 5) { Print("Headline data: ",value); visa_data[1] = (float) value; } if(counter == 7) { Print("Non-Discretionary data: ",value); visa_data[2] = (float) value; } if(FileIsLineEnding(result)) { Print("row++"); } counter++; } //--- Show the VISA data Print("VISA DATA: "); ArrayPrint(visa_data); //---Close the file FileClose(result); } }
Por fim, devemos definir uma função responsável por obter previsões do nosso modelo. Primeiro, armazenamos as entradas atuais em um vetor de ponto flutuante, pois o tipo de entrada do nosso modelo é float, como definimos ao criar os tipos iniciais do ONNX.
Lembre-se de que precisamos escalar cada valor de entrada subtraindo a média da coluna e dividindo pelo desvio padrão da coluna, antes de passarmos as entradas para o nosso modelo.
//+--------------------------------------------------------------+ //| Get a prediction from our model | //+--------------------------------------------------------------+ void model_predict(void) { //--- Fetch input data read_visa_data(); vectorf input_data = {(float)iOpen("EURUSD",PERIOD_MN1,0), (float)iHigh("EURUSD",PERIOD_MN1,0), (float)iLow("EURUSD",PERIOD_MN1,0), (float)iClose("EURUSD",PERIOD_MN1,0), (float)iTickVolume("EURUSD",PERIOD_MN1,0), (float)visa_data[0], (float)visa_data[1], (float)visa_data[2] }; //--- Scale the data for(int i =0; i < 8;i++) { input_data[i] = (float)((input_data[i] - mean_values[i])/std_values[i]); } //--- Show the input data Print("Input data: ",input_data); //--- Obtain a forecast OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT|ONNX_DEFAULT,input_data,model_forecast); } //+------------------------------------------------------------------+
Agora vamos definir o procedimento de inicialização. Começaremos carregando nosso modelo ONNX, depois lendo o conjunto de dados da VISA e, finalmente, carregaremos nossos valores de escalonamento.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Load the ONNX file if(!load_onnx_model()) { //--- We failed to load the ONNX model return(INIT_FAILED); } //--- Read the VISA data read_visa_data(); //--- Load scaling values load_scaling_values(); //--- We were successful return(INIT_SUCCEEDED); }
Sempre que nosso programa não estiver em uso, vamos liberar os recursos que não precisamos mais.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up the resources we don't need OnnxRelease(onnx_model); ExpertRemove(); }
Sempre que tivermos novos dados de preço disponíveis, primeiro buscaremos uma previsão do nosso modelo. Se não tivermos posições abertas, seguiremos a entrada gerada pelo nosso modelo. Por fim, se tivermos posições abertas, usaremos nosso modelo de IA para detectar possíveis reversões de preço com antecedência.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Get a prediction from our model model_predict(); Comment("Model forecast: ",model_forecast[0]); //--- Check if we have any positions if(PositionsTotal() == 0) { //--- Note that we have no trades open state = 0; //--- Find an entry and take note if(model_forecast[0] < iClose(_Symbol,PERIOD_CURRENT,0)) { Trade.Sell(trading_volume,_Symbol,SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,"Gain an Edge VISA"); state = 1; } if(model_forecast[0] > iClose(_Symbol,PERIOD_CURRENT,0)) { Trade.Buy(trading_volume,_Symbol,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,"Gain an Edge VISA"); state = 2; } } //--- If we have positions open, check for reversals if(PositionsTotal() > 0) { if(((state == 1) && (model_forecast[0] > iClose(_Symbol,PERIOD_CURRENT,0))) || ((state == 2) && (model_forecast[0] < iClose(_Symbol,PERIOD_CURRENT,0)))) { Alert("Reversal detected, closing positions now"); Trade.PositionClose(_Symbol); } } } //+------------------------------------------------------------------+

Fig 12: Nosso Expert Advisor da VISA

Fig 13: Exemplo de saída do nosso programa

Fig 14: Nossa aplicação em ação.
Conclusão
Neste artigo, demonstramos como você pode selecionar dados que podem ser úteis para a sua estratégia de negociação. Discutimos como medir a força potencial dos seus dados alternativos e como otimizar seus modelos para extrair o máximo desempenho possível sem overfitting. Discutimos como medir a força potencial dos seus dados alternativos e como otimizar seus modelos para extrair o máximo desempenho possível sem overfitting.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/15575
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Obrigado, Gamu
Ótimo artigo, obrigado por compartilhar!!!
Mais uma vez, obrigado, Gamu. Muito bem escrito, como sempre. Um ótimo modelo comentado sobre como visualizar, dimensionar, testar, verificar se há overfitting, implementar um datafeed, prever e implementar um sistema de negociação a partir de um conjunto de dados.