
Desenvolvendo um EA multimoeda (Parte 19): Criando etapas implementadas em Python
Introdução
Já faz bastante tempo (na parte 6) que analisamos a automação da seleção de um bom conjunto de instâncias individuais de estratégias de negociação. Naquela época, ainda não tínhamos um banco de dados no qual os resultados de todas as execuções do testador fossem armazenados. Para esse fim, utilizamos um arquivo CSV comum. O principal objetivo daquele artigo era testar a hipótese de que a seleção automática de um bom grupo poderia proporcionar resultados melhores do que a seleção manual.
Conseguimos atingir esse objetivo e confirmamos a hipótese. Por isso, analisamos como seria possível melhorar os resultados dessa seleção automática. Descobrimos que, se dividirmos o conjunto de todas as instâncias individuais em um número relativamente pequeno de clusters e garantirmos que o grupo selecionado não inclua instâncias do mesmo cluster, não apenas os resultados de negociação do EA final serão melhorados, mas também o tempo necessário para o próprio processo de seleção será reduzido.
Para realizar a clusterização, usamos a biblioteca scikit-learn para Python, mais especificamente a implementação do algoritmo K-Means. Embora esse não seja o único algoritmo de clusterização, analisar outras opções, compará-las e escolher a melhor para essa tarefa fugiria ao escopo aceitável. Por isso, escolhemos o primeiro algoritmo disponível, e os resultados obtidos com ele foram suficientemente bons.
No entanto, a execução de um pequeno programa em Python era exigida para usar essa implementação específica. Quando a maior parte das operações ainda era feita manualmente, isso não causava problema. Mas agora que avançamos bastante na automação de todo o processo de teste e seleção de bons grupos de instâncias individuais de estratégias de negociação, mesmo uma operação simples acionada manualmente no meio do pipeline de tarefas sequenciais de otimização parece fora de lugar.
Para corrigir esse inconveniente, podemos seguir dois caminhos. O primeiro consiste em encontrar uma implementação pronta do algoritmo de clusterização escrita em MQL5 ou escrevê-la nós mesmos, caso a busca não seja bem-sucedida. O segundo caminho envolve adicionar a possibilidade de executar, nas etapas necessárias do processo de otimização automática, não apenas EAs escritos em MQL5, mas também programas em Python.
Após uma breve reflexão, optamos pela segunda alternativa. Vamos começar a implementá-la.
Traçando o caminho
Então, vejamos de que forma podemos, afinal, executar um programa em Python a partir de um programa em MQL5. Os modos mais óbvios seriam os seguintes:
- Execução direta. Para isso, podemos usar uma das funções do sistema operacional que permite executar um arquivo executável com parâmetros. Nesse caso, o executável será o interpretador Python, e os parâmetros serão o nome do arquivo com o programa e os parâmetros de execução. A desvantagem dessa abordagem é a necessidade de usar funções externas via DLL, mas já utilizamos essas funções para executar o testador de estratégias.
- Execução via requisição web. Podemos criar um servidor web simples com as APIs necessárias, que será responsável por iniciar os programas Python ao receber requisições vindas do programa em MQL5 por meio da função WebRequest(). Para criar o servidor web, é possível usar o framework Flask, por exemplo, ou qualquer outro. A desvantagem dessa abordagem, por enquanto, é a complexidade excessiva para resolver uma tarefa simples.
Apesar da atratividade do segundo método, vamos deixar sua implementação para mais tarde, quando for o momento de implementar outras funcionalidades complementares. No fim das contas, poderemos até mesmo criar uma interface web completa para controlar todo o processo de otimização automática, transformando o EA Optimization.ex5 de hoje em um serviço MQL5. Esse serviço, executado junto com o terminal, irá monitorar o surgimento de projetos no status Queued no banco de dados e, quando houver, executará todas as tarefas de otimização enfileiradas para esses projetos. Mas, por ora, vamos implementar a primeira e mais simples opção de execução.
A próxima questão é como salvar os resultados da clusterização. Na parte 6, colocávamos o número do cluster como uma nova coluna na tabela onde inicialmente estavam armazenados os resultados das execuções de otimização das instâncias individuais da estratégia de negociação. Então, por analogia, podemos adicionar uma nova coluna à tabela passes e inserir nela os números dos clusters. No entanto, nem toda etapa de otimização implica a clusterização posterior dos seus resultados. Por isso, para muitas linhas da tabela passes, essa coluna conteria valores vazios. Isso não é muito bom.
Para evitar isso, vamos criar uma tabela separada, onde serão armazenados apenas os identificadores dos passes e os números dos clusters atribuídos a eles. No início da segunda etapa da otimização, para considerar a clusterização realizada, simplesmente uniremos à tabela passes os dados da nova tabela, relacionando-os pelos identificadores dos passes (id_pass).
Com base na sequência de ações exigidas na otimização automática, a etapa de clusterização deve ser executada entre a primeira e a segunda etapa. Para evitar confusões futuras, continuaremos utilizando os nomes "primeira" e "segunda" etapa para os mesmos estágios que anteriormente levavam esses nomes. A nova etapa adicionada será chamada de etapa de clusterização dos resultados da primeira etapa.
Então, precisaremos fazer o seguinte:
- Alterar o EA Optimization.mq5 para que ele possa executar etapas implementadas em Python.
- Escrever o código em Python, que receberá os parâmetros necessários, carregará do banco de dados as informações sobre os passes, realizará a clusterização e salvará os resultados obtidos no banco de dados.
- Preencher o banco de dados com três etapas, trabalhos para essas etapas, para diferentes instrumentos de negociação e timeframes, e tarefas de otimização para esses trabalhos, com um ou vários critérios de otimização.
- Executar a otimização automática e avaliar os resultados.
Correções
Desta vez, não foram encontradas falhas críticas, então vamos corrigir pequenas imprecisões que não afetam diretamente o EA final obtido ao fim da otimização automática, mas dificultam o acompanhamento correto da execução das etapas de otimização e dos resultados de passes individuais executados fora do contexto da otimização.
Comecemos adicionando gatilhos para configurar as datas de início e fim da tarefa (task). Atualmente, essa modificação é feita por comandos SQL executados a partir do EA Optimization.mq5 antes do início e após a interrupção do processo de otimização no testador de estratégias:
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void StartTask(ulong taskId, string setting) { ... // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing', " " start_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); } //+------------------------------------------------------------------+ //| Task completion | //+------------------------------------------------------------------+ void FinishTask(ulong taskId) { PrintFormat(__FUNCTION__" | Task ID = %d", taskId); // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Done', " " finish_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); }
A lógica dos gatilhos será simples. Se o status da tarefa na tabela tasks mudar para "Processing", então a data de início (start_date) deve ser definida como o horário atual. Se o status da tarefa mudar para "Done", então a data de término (finish_date) deve ser definida como o horário atual. Se o status da tarefa mudar para "Queued", então é necessário limpar a data de início e a de término. Essa última operação de alteração de status não é feita pelo EA, mas por meio da modificação manual do valor do campo status na tabela tasks.
Veja como pode ser a implementação desses gatilhos:
CREATE TRIGGER IF NOT EXISTS upd_task_start_date AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Processing' BEGIN UPDATE tasks SET start_date= DATETIME('NOW') WHERE id_task=NEW.id_task; END; CREATE TRIGGER IF NOT EXISTS upd_task_finish_date AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Done' BEGIN UPDATE tasks SET finish_date= DATETIME('NOW') WHERE id_task=NEW.id_task; END; CREATE TRIGGER IF NOT EXISTS reset_task_dates AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Queued' BEGIN UPDATE tasks SET start_date= NULL, finish_date=NULL WHERE id_task=NEW.id_task; END;
Depois de criar esses gatilhos, podemos remover do EA a modificação dos campos start_date e finish_date, deixando ali apenas a alteração do status.
A próxima imprecisão, pequena mas incômoda, era que, ao executarmos manualmente um passe individual no testador de estratégias após migrar para o novo banco de dados, o valor do identificador da tarefa de otimização atual é, por padrão, igual a 0. E ao tentar inserir um registro na tabela passes com esse valor em id_task, isso pode causar um erro na verificação de chaves estrangeiras, caso tenhamos esquecido de adicionar uma tarefa especial com id_task = 0. Se ela existir, tudo funciona normalmente.
Por isso, vamos adicionar um gatilho para o evento de criação de um novo registro na tabela de projetos. Assim que criarmos um novo projeto, será necessário que, para ele, sejam criados automaticamente um estágio (stage), um trabalho (job) e uma tarefa (task) para os passes individuais. A implementação desse gatilho pode ser feita da seguinte forma:
CREATE TRIGGER IF NOT EXISTS insert_empty_stage AFTER INSERT ON projects BEGIN INSERT INTO stages ( id_project, name, optimization, status ) VALUES ( NEW.id_project, 'Single tester pass', 0, 'Done' ); END; DROP TRIGGER IF EXISTS insert_empty_job; CREATE TRIGGER IF NOT EXISTS insert_empty_job AFTER INSERT ON stages WHEN NEW.name = 'Single tester pass' BEGIN INSERT INTO jobs VALUES ( NULL, NEW.id_stage, NULL, NULL, NULL, 'Done' ); INSERT INTO tasks ( id_job, optimization_criterion, status ) VALUES ( (SELECT id_job FROM jobs WHERE id_stage=NEW.id_stage), -1, 'Done' ); END;
Outra imprecisão era que, ao executar manualmente um passe individual do testador de estratégias, o campo pass_date da tabela passes recebe não o horário atual, mas o horário de término do intervalo de teste. Isso acontece porque, no comando SQL dentro do EA, usamos a função TimeCurrent() para definir esse horário. Mas no modo de teste, essa função retorna não o horário atual real, e sim o horário simulado. Então, se o intervalo de teste termina no final de 2022, o passe será salvo na tabela passes com essa data de término, correspondente ao fim de 2022.
Mas por que, então, todos os passes executados durante a otimização são gravados com o horário real correto de término? A resposta é bem simples. É que, durante a otimização, os comandos SQL de gravação dos resultados dos passes são executados pelo EA que está rodando não no testador, mas no gráfico do terminal, no modo de coleta de quadros de dados. E como ele não está no testador, a função TimeCurrent() retorna o horário real, e não o simulado.
Para corrigir isso, vamos adicionar um gatilho acionado após a inserção de um novo registro na tabela passes, que definirá a data atual:
CREATE TRIGGER IF NOT EXISTS upd_pass_date
AFTER INSERT
ON passes
BEGIN
UPDATE passes
SET pass_date = DATETIME('NOW')
WHERE id_pass = NEW.id_pass;
END;
No comando SQL que adiciona uma nova linha na tabela passes a partir do EA, vamos remover a inserção do horário atual calculado pelo EA, e simplesmente passar a constante NULL.
Mais alguns pequenos acréscimos e correções foram feitos nas classes existentes. Na CVirtualOrder, adicionamos um método para alterar o tempo de expiração e um método estático para verificar um array de ordens virtuais quanto à ativação de alguma delas. Esses métodos ainda não estão em uso, mas podem ser úteis em outras estratégias de negociação.
Na CFactorable, o comportamento do método ReadNumber() foi corrigido para que, ao atingir o fim da string de inicialização, ele retorne NULL em vez de repetir indefinidamente o último número lido. Essa correção exigiu que, na string de inicialização do gerenciador de risco, sejam informados exatamente tantos parâmetros quanto necessário, ou seja, 13 em vez de 6:
// Prepare the initialization string for the risk manager string riskManagerParams = StringFormat( "class CVirtualRiskManager(\n" " 0,0,0,0,0,0,0,0,0,0,0,0,0" " )", 0 );
Na classe de manipulação do banco de dados CDatabase, adicionamos um novo método estático com o qual faremos a troca para o banco de dados desejado. Basicamente, dentro dele, apenas nos conectamos ao banco com o nome e o caminho especificados e, em seguida, fechamos imediatamente a conexão:
static void Test(string p_fileName = NULL, int p_common = DATABASE_OPEN_COMMON) { Connect(p_fileName, p_common); Close(); };
Após essa chamada, as próximas chamadas ao método Connect() sem parâmetros se conectarão automaticamente ao banco de dados correto.
Concluída essa parte não principal, mas necessária, vamos começar a implementar a tarefa principal.
Refatoração do Optimization.mq5
Antes de tudo, será necessário modificar o EA Optimization.mq5. Nele, devemos adicionar uma verificação do nome do arquivo a ser executado (campo expert) na tabela de estágios (stages). Se o nome terminar com ".py", então o programa executado nessa etapa será um script Python. Os parâmetros necessários para sua execução podem ser inseridos no campo tester_inputs na tabela de trabalhos (jobs).
Contudo, isso não será suficiente. Precisamos de uma forma de passar o nome do banco de dados, o identificador da tarefa atual e uma maneira de executar o programa em Python. Isso resultará em um aumento significativo do código dentro do EA, que já é bastante grande. Por isso, vamos começar reorganizando o código existente em múltiplos arquivos.
No arquivo principal do EA Optimization.mq5, deixaremos apenas a criação do timer e a criação do novo objeto da classe COptimizer (otimizador), que será o responsável por toda a lógica principal. No restante, bastará chamar o método Process() desse objeto no manipulador de timer e garantir a criação e a destruição adequadas dele durante a inicialização e a finalização do EA.
sinput string fileName_ = "database911.sqlite"; // - File with the main database sinput string pythonPath_ = "C:\\Python\\Python312\\python.exe"; // - Path to Python interpreter COptimizer *optimizer; // Pointer to the optimizer object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Connect to the main database DB::Test(fileName_); // Create an optimizer optimizer = new COptimizer(pythonPath_); // Create the timer and start its handler EventSetTimer(20); OnTimer(); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert timer function | //+------------------------------------------------------------------+ void OnTimer() { // Start the optimizer handling optimizer.Process(); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { EventKillTimer(); // Remove the optimizer if(!!optimizer) { delete optimizer; } }
Ao criar o objeto otimizador, passamos para o seu construtor um único parâmetro: o caminho completo até o arquivo executável do interpretador Python no computador onde o EA será executado. Esse valor é definido pelo parâmetro de entrada do EA pythonPath_. No futuro, podemos eliminar esse parâmetro, implementando uma busca automática pelo interpretador dentro da própria classe otimizadora, mas por enquanto vamos manter esse método mais simples.
Vamos salvar as alterações feitas no arquivo Optimization.mq5 na pasta atual.
Classe do otimizador
Vamos criar a classe do otimizador COptimizer. Entre os métodos públicos, ela terá apenas o método principal de processamento Process() e o construtor. Na seção privada, vamos adicionar o método para obter a quantidade de tarefas na fila de execução e o método para obter o identificador da próxima tarefa na fila. A toda a lógica relacionada à execução de uma tarefa específica de otimização será delegada a mais um nível abaixo — um objeto da nova classe COptimizerTask (tarefa de otimização). Assim, dentro do otimizador, precisaremos de um único objeto dessa classe.
//+------------------------------------------------------------------+ //| Class for the project auto optimization manager | //+------------------------------------------------------------------+ class COptimizer { // Current optimization task COptimizerTask m_task; // Get the number of tasks with a given status in the queue int TotalTasks(string status = "Queued"); // Get the ID of the next optimization task from the queue ulong GetNextTaskId(); public: COptimizer(string p_pythonPath = NULL); // Constructor void Process(); // Main handling method };
O código dos métodos TotalTasks() e GetNextTaskId() foi praticamente copiado sem alterações das funções correspondentes da versão anterior do EA Optimization.mq5. O mesmo vale para o método Process(), cujo código veio da antiga função OnTimer(). Mas esse precisou de uma mudança mais substancial, pois agora temos a nova classe para representar a tarefa de otimização. No geral, porém, o código desse método ficou ainda mais claro:
//+------------------------------------------------------------------+ //| Main handling method | //+------------------------------------------------------------------+ void COptimizer::Process() { PrintFormat(__FUNCTION__" | Current Task ID = %d", m_task.Id()); // If the EA is stopped, remove the timer and the EA itself from the chart if (IsStopped()) { EventKillTimer(); ExpertRemove(); return; } // If the current task is completed, if (m_task.IsDone()) { // If the current task is not empty, if(m_task.Id()) { // Complete the current task m_task.Finish(); } // Get the number of tasks in the queue int totalTasks = TotalTasks("Processing") + TotalTasks("Queued"); // If there are tasks, then if(totalTasks) { // Get the ID of the next current task ulong taskId = GetNextTaskId(); // Load the optimization task parameters from the database m_task.Load(taskId); // Launch the current task m_task.Start(); // Display the number of remaining tasks and the current task on the chart Comment(StringFormat( "Total tasks in queue: %d\n" "Current Task ID: %d", totalTasks, m_task.Id())); } else { // If there are no tasks, remove the EA from the chart PrintFormat(__FUNCTION__" | Finish.", 0); ExpertRemove(); } } }
Como se pode ver, nesse nível de abstração, não há diferença no tipo de tarefa a ser executada, seja otimizar um EA no testador ou rodar um programa em Python. A sequência de ações será sempre a mesma: enquanto houver tarefas na fila, carregamos os parâmetros da próxima tarefa, iniciamos sua execução e aguardamos sua conclusão. Depois da conclusão, repetimos as ações anteriores até esvaziar a fila de tarefas.
Vamos salvar as alterações feitas no arquivo COptimizer.mqh na pasta atual.
Classe da tarefa de otimização
A parte mais interessante ficou a cargo da classe COptimizerTask. É nela que ocorrerá a execução direta do interpretador Python, com a programação escrita em Python sendo passada para ser executada. Por isso, no início do arquivo dessa classe, importaremos a função do sistema responsável pela execução de arquivos:
// Function to launch an executable file in the operating system #import "shell32.dll" int ShellExecuteW(int hwnd, string lpOperation, string lpFile, string lpParameters, string lpDirectory, int nShowCmd); #import
Dentro da própria classe, teremos diversos campos para armazenar os parâmetros necessários da tarefa de otimização, como tipo, identificador, expert, intervalo de otimização, símbolo, timeframe, entre outros.
//+------------------------------------------------------------------+ //| Optimization task class | //+------------------------------------------------------------------+ class COptimizerTask { enum { TASK_TYPE_UNKNOWN, TASK_TYPE_EX5, TASK_TYPE_PY } m_type; // Task type (MQL5 or Python) ulong m_id; // Task ID string m_setting; // String for initializing the EA parameters for the current task string m_pythonPath; // Full path to the Python interpreter // Data structure for reading a single string of a query result struct params { string expert; int optimization; string from_date; string to_date; int forward_mode; string forward_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } m_params; // Get the full or relative path to a given file in the current folder string GetProgramPath(string name, bool rel = true); // Get initialization string from task parameters void Parse(); // Get task type from task parameters void ParseType(); public: // Constructor COptimizerTask() : m_id(0) {} // Task ID ulong Id() { return m_id; } // Set the full path to the Python interpreter void PythonPath(string p_pythonPath) { m_pythonPath = p_pythonPath; } // Main method void Process(); // Load task parameters from the database void Load(ulong p_id); // Start the task void Start(); // Complete the task void Finish(); // Task completed? bool IsDone(); };
Os parâmetros que serão carregados diretamente do banco de dados por meio do método Load() serão armazenados na estrutura m_params. A partir desses valores, vamos determinar o tipo da tarefa com o método ParseType(), verificando o final do nome do arquivo:
//+------------------------------------------------------------------+ //| Get task type from task parameters | //+------------------------------------------------------------------+ void COptimizerTask::ParseType() { string ext = StringSubstr(m_params.expert, StringLen(m_params.expert) - 3); if(ext == ".py") { m_type = TASK_TYPE_PY; } else if (ext == "ex5") { m_type = TASK_TYPE_EX5; } else { m_type = TASK_TYPE_UNKNOWN; } }
E também vamos montar a string de inicialização do teste ou da execução do programa Python por meio do método Parse(). Nele, dependendo do tipo de tarefa determinado, vamos construir ou a string de parâmetros para o testador de estratégias, ou a string com os parâmetros de execução do programa Python:
//+------------------------------------------------------------------+ //| Get initialization string from task parameters | //+------------------------------------------------------------------+ void COptimizerTask::Parse() { // Get the task type from the task parameters ParseType(); // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Generate a parameter string for the tester m_setting = StringFormat( "[Tester]\r\n" "Expert=%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=%d\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=%d\r\n" "ForwardDate=%s\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d\r\n" "fileName_=%s\r\n" "%s\r\n", GetProgramPath(m_params.expert), m_params.symbol, m_params.period, m_params.optimization, m_params.from_date, m_params.to_date, m_params.forward_mode, m_params.forward_date, m_params.optimization_criterion, m_params.id_task, DB::FileName(), m_params.tester_inputs ); // If this is a task to launch a Python program } else if (m_type == TASK_TYPE_PY) { // Form a program launch string on Python with parameters m_setting = StringFormat("\"%s\" \"%s\" %I64u %s", GetProgramPath(m_params.expert, false), // Python program file DB::FileName(true), // Path to the database file m_id, // Task ID m_params.tester_inputs // Launch parameters ); } }
A execução da tarefa é feita pelo método Start(). Nele, verificamos novamente o tipo da tarefa e, com base nisso, iniciamos a otimização no testador ou executamos o programa Python por meio da função ShellExecuteW():
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void COptimizerTask::Start() { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", m_id, m_setting); // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Launch a new optimization task in the tester MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(m_setting); MTTESTER::ClickStart(); // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing' " " WHERE id_task=%d", m_id); DB::Execute(query); DB::Close(); // If this is a task to launch a Python program } else if (m_type == TASK_TYPE_PY) { PrintFormat(__FUNCTION__" | SHELL EXEC: %s", m_pythonPath); // Call the system function to launch the program with parameters ShellExecuteW(NULL, NULL, m_pythonPath, m_setting, NULL, 1); } }
A verificação da execução da tarefa se resume a verificar o estado do testador de estratégias (se foi finalizado ou não), ou a verificar o status da tarefa no banco de dados com base no identificador atual:
//+------------------------------------------------------------------+ //| Task completed? | //+------------------------------------------------------------------+ bool COptimizerTask::IsDone() { // If there is no current task, then everything is done if(m_id == 0) { return true; } // Result bool res = false; // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Check if the strategy tester has finished its work res = MTTESTER::IsReady(); // If this is a task to run a Python program, then } else if(m_type == TASK_TYPE_PY) { // Request to get the status of the current task string query = StringFormat("SELECT status " " FROM tasks" " WHERE id_task=%I64u;", m_id); // Open the database if(DB::Connect()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string status; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { // Check if the status is Done res = (row.status == "Done"); } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } } else { res = true; } return res; }
Vamos salvar as alterações feitas no arquivo COptimizerTask.mqh na pasta atual.
Programa para clusterização
Agora chegou a vez do programa Python propriamente dito, sobre o qual já falamos várias vezes. No geral, sua parte responsável pela lógica principal já havia sido escrita na parte 6. Vamos dar uma olhada nela:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df = df.sort_values(['cluster', 'Sharpe Ratio']).groupby('cluster').agg('last').reset_index()
clusters = df.cluster
df = df.iloc[:, 1:]
df['cluster'] = clusters
df.to_csv('Params_SV_EURGBP_H1-one_cluster.csv', index=False Precisamos alterar o seguinte:
- adicionar a possibilidade de passar parâmetros adicionais pela linha de comando (nome do banco de dados, identificador da tarefa, número de clusters etc.);
- em vez de usar um arquivo CSV, usar as informações da tabela passes;
- adicionar a marcação de status de início e fim da execução da tarefa no banco de dados;
- alterar o conjunto de campos utilizados na clusterização, já que na tabela passes não temos colunas separadas para cada parâmetro de entrada do EA;
- reduzir o número de campos na tabela final, pois, na verdade, só precisamos saber qual número de cluster está associado a qual identificador de passe;
- em vez de salvar os resultados em outro arquivo, gravar os dados na nova tabela do banco de dados.
Para implementar tudo isso, vamos precisar importar os módulos adicionais argparse e sqlite3:
import pandas as pd
from sklearn.cluster import KMeans
import sqlite3
import argparse A análise dos parâmetros passados pela linha de comando será feita por um objeto da classe ArgumentParser, e os valores lidos serão armazenados em variáveis separadas para facilitar o uso posterior:
# Setting up the command line argument parser parser = argparse.ArgumentParser(description='Clustering passes for previous job(s)') parser.add_argument('db_path', type=str, help='Path to database file') parser.add_argument('id_task', type=int, help='ID of current task') parser.add_argument('--id_parent_job', type=str, help='ID of parent job(s)') parser.add_argument('--n_clusters', type=int, default=256, help='Number of clusters') parser.add_argument('--min_custom_ontester', type=float, default=0, help='Min value for `custom_ontester`') parser.add_argument('--min_trades', type=float, default=40, help='Min value for `trades`') parser.add_argument('--min_sharpe_ratio', type=float, default=0.7, help='Min value for `sharpe_ratio`') # Read the values of command line arguments into variables args = parser.parse_args() db_path = args.db_path id_task = args.id_task id_parent_job = args.id_parent_job n_clusters = args.n_clusters min_custom_ontester = args.min_custom_ontester min_trades = args.min_trades min_sharpe_ratio = args.min_sharpe_ratio
Em seguida, nos conectaremos ao banco de dados, marcaremos a tarefa atual como em execução e criaremos uma nova tabela para armazenar os resultados da clusterização, caso ainda não exista. Se a tarefa estiver sendo executada novamente, será necessário garantir a limpeza dos resultados salvos anteriormente:
# Establishing a connection to the database
connection = sqlite3.connect(db_path)
cursor = connection.cursor()
# Mark the start of the task
cursor.execute(f'''UPDATE tasks SET status='Processing' WHERE id_task={id_task};''')
connection.commit()
# Create a table for clustering results if there is none
cursor.execute('''CREATE TABLE IF NOT EXISTS passes_clusters (
id_task INTEGER,
id_pass INTEGER,
cluster INTEGER
);''')
# Clear the results table from previously obtained results
cursor.execute(f'''DELETE FROM passes_clusters WHERE id_task={id_task};''') Depois disso, formamos a consulta SQL para obter os dados dos passes de otimização necessários e os carregamos diretamente de um banco de dados em um dataframe:
# Load data about parent job passes for this task into the dataframe
query = f'''SELECT p.*
FROM passes p
JOIN
tasks t ON t.id_task = p.id_task
JOIN
jobs j ON j.id_job = t.id_job
WHERE p.profit > 0 AND
j.id_job IN ({id_parent_job}) AND
p.custom_ontester >= {min_custom_ontester} AND
p.trades >= {min_trades} AND
p.sharpe_ratio >= {min_sharpe_ratio};'''
df = pd.read_sql(query, connection)
# Display dataframe
print(df)
# List of dataframe columns
print(*enumerate(df.columns), sep='\n') Ao visualizar a lista de colunas do dataframe, selecionamos algumas delas para realizar a clusterização. Como não temos colunas separadas para os parâmetros de entrada das instâncias das estratégias de negociação, a clusterização será feita com base nos diversos resultados estatísticos dos passes (lucro, número de operações, rebaixamento, profit factor, etc.). Os números das colunas escolhidas são informados nos parâmetros do método iloc[]. Após a clusterização, agrupamos as linhas do dataframe por cluster e mantemos apenas uma linha para cada cluster — aquela com o maior valor de lucro anual médio normalizado:
# Run clustering on some columns of the dataframe kmeans = KMeans(n_clusters=n_clusters, n_init='auto', random_state=42).fit(df.iloc[:, [7, 8, 9, 24, 29, 30, 31, 32, 33, 36, 45, 46]]) # Add cluster numbers to the dataframe df['cluster'] = kmeans.labels_ # Set the current task ID df['id_task'] = id_task # Sort the dataframe by clusters and normalized profit df = df.sort_values(['cluster', 'custom_ontester']) # Display dataframe print(df) # Group the lines by cluster and take one line at a time # with the highest normalized profit from each cluster df = df.groupby('cluster').agg('last').reset_index()
Depois disso, deixamos no dataframe apenas três colunas, para as quais criamos a tabela de resultados: id_task, id_pass, cluster. A primeira foi mantida para que possamos apagar os resultados de clusterizações anteriores ao executar novamente este programa com o mesmo valor de id_task.
# Let's leave only id_task, id_pass and cluster columns in the dataframe df = df.iloc[:, [2, 1, 0]] # Display dataframe print(df)
Salvamos o dataframe adicionando os dados na tabela existente, marcamos a conclusão da execução da tarefa e encerramos a conexão com o banco de dados:
# Save the dataframe to the passes_clusters table (replacing the existing one)
df.to_sql('passes_clusters', connection, if_exists='append', index=False)
# Mark the task completion
cursor.execute(f'''UPDATE tasks SET status='Done' WHERE id_task={id_task};''')
connection.commit()
# Close the connection
connection.close()
Vamos salvar as alterações feitas no arquivo ClusteringStage1.py na pasta atual.
EA da segunda etapa
Agora que já temos pronta a aplicação de clusterização dos resultados da primeira etapa de otimização, resta apenas implementar o suporte ao uso desses resultados no EA da segunda etapa de otimização. Vamos tentar fazer isso com o menor esforço possível.
Antes, usávamos um EA separado, mas agora faremos de modo que a execução da segunda etapa, com ou sem clusterização, possa ser feita com o mesmo EA. Adicionaremos um parâmetro de entrada lógico chamado useClusters_, que indicará se devemos utilizar os resultados da clusterização ao selecionar grupos de instâncias individuais das estratégias de negociação obtidas na primeira etapa.
Se for para usar os resultados da clusterização, basta incluirmos no comando SQL que obtém a lista de instâncias individuais a junção com a tabela passes_clusters, associando os registros pelos identificadores dos passes. Nesse caso, o resultado da consulta trará apenas um passe por cluster.
Aproveitaremos para adicionar como parâmetros de entrada do EA mais algumas opções, nas quais poderemos definir critérios adicionais de filtragem dos passes com base no lucro anual médio normalizado, no número de operações e no índice de Sharpe.
Com isso, será necessário alterar apenas a lista de parâmetros de entrada e a função CreateTaskDB():
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput int idTask_ = 0; // - Optimization task ID sinput string fileName_ = "db.sqlite"; // - Main database file input group "::: Selection for the group" input int idParentJob_ = 1; // - Parent job ID input bool useClusters_ = true; // - Use clustering input double minCustomOntester_ = 0; // - Min normalized profit input int minTrades_ = 40; // - Min number of trades input double minSharpeRatio_ = 0.7; // - Min Sharpe ratio input int count_ = 16; // - Number of strategies in the group (1 .. 16) ... //+------------------------------------------------------------------+ //| Creating a database for a separate stage task | //+------------------------------------------------------------------+ void CreateTaskDB(const string fileName, const int idParentJob) { // Create a new database for the current optimization task DB::Connect(PARAMS_FILE, 0); DB::Execute("DROP TABLE IF EXISTS passes;"); DB::Execute("CREATE TABLE passes (id_pass INTEGER PRIMARY KEY AUTOINCREMENT, params TEXT);"); DB::Close(); // Connect to the main database DB::Connect(fileName); // Clustering string clusterJoin = ""; if(useClusters_) { clusterJoin = "JOIN passes_clusters pc ON pc.id_pass = p.id_pass"; } // Request to obtain the required information from the main database string query = StringFormat("SELECT DISTINCT p.params" " FROM passes p" " JOIN " " tasks t ON p.id_task = t.id_task " " JOIN " " jobs j ON t.id_job = j.id_job " " %s " "WHERE (j.id_job = %d AND " " p.custom_ontester >= %.2f AND " " trades >= %d AND " " p.sharpe_ratio >= %.2f) " "ORDER BY p.custom_ontester DESC;", clusterJoin, idParentJob_, minCustomOntester_, minTrades_, minSharpeRatio_); // Execute the request ... }
Vamos salvar as alterações feitas no arquivo SimpleVolumesStage2.mq5 na pasta atual e começar os testes.
Testes
Vamos criar quatro etapas no banco de dados do nosso projeto, com os nomes "First", "Clustering passes from first stage", "Second" e "Second with clustering". Para cada etapa, criaremos dois trabalhos para os símbolos EURGBP e GBPUSD no intervalo de tempo H1. Para os trabalhos da primeira etapa, criaremos três tarefas de otimização com diferentes critérios (composto, lucro máximo e personalizado). Para os demais trabalhos, criaremos uma tarefa cada. O intervalo de otimização será de 2018 a 2023. Para cada trabalho, informaremos os valores corretos dos parâmetros de entrada.
No final, o banco de dados deverá conter informações que gerem os seguintes resultados da consulta apresentada abaixo:
SELECT t.id_task,
t.optimization_criterion,
s.name AS stage_name,
s.expert AS stage_expert,
j.id_job,
j.symbol AS job_symbol,
j.period AS job_period,
j.tester_inputs AS job_tester_inputs
FROM tasks t
JOIN
jobs j ON j.id_job = t.id_job
JOIN
stages s ON s.id_stage = j.id_stage
WHERE t.id_task > 0; 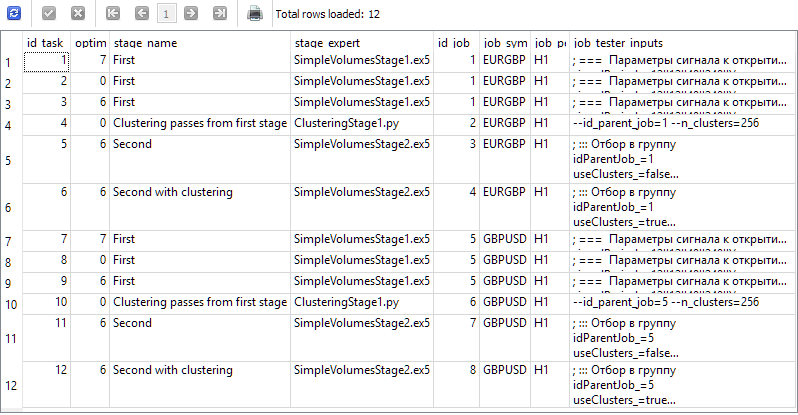
Executamos o EA Optimization.ex5 no gráfico do terminal e aguardamos até que todas as tarefas sejam concluídas. Com esse volume de cálculos, 33 agentes deram conta de todas as etapas em cerca de 17 horas.
Para o EURGBP, o melhor grupo encontrado sem clusterização teve praticamente o mesmo lucro anual médio normalizado do que com a utilização da clusterização (cerca de $4060). Já para o GBPUSD, a diferença entre esses dois métodos na segunda etapa de otimização foi bem mais evidente. Sem clusterização, o lucro anual médio normalizado foi de $4500, e com clusterização — $7500.
Essa diferença nos resultados para os dois símbolos parece um pouco estranha, mas é perfeitamente possível. Não vamos nos aprofundar agora na investigação do motivo dessa diferença, e deixaremos isso para mais tarde, quando estivermos utilizando um número maior de símbolos e timeframes na otimização automática.
Veja como ficaram os resultados dos melhores grupos para ambos os símbolos:
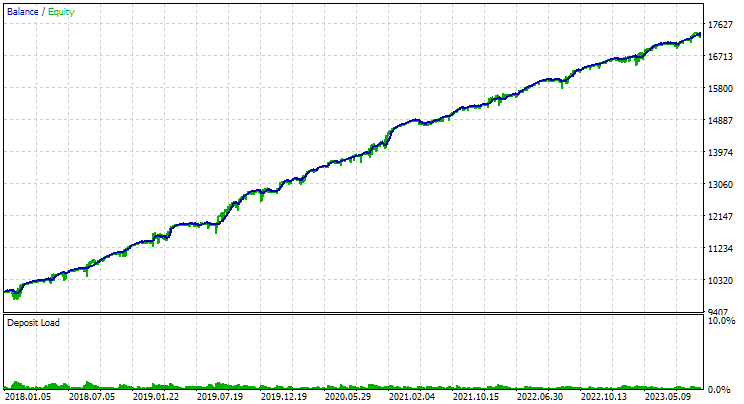
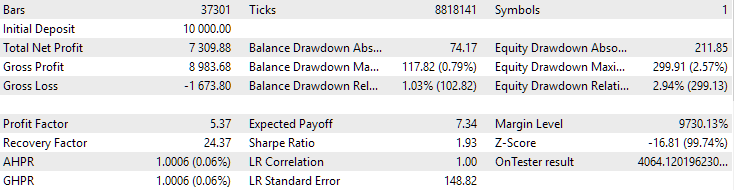
Fig. 1. Resultados do melhor grupo na segunda etapa com clusterização para EURGBP H1
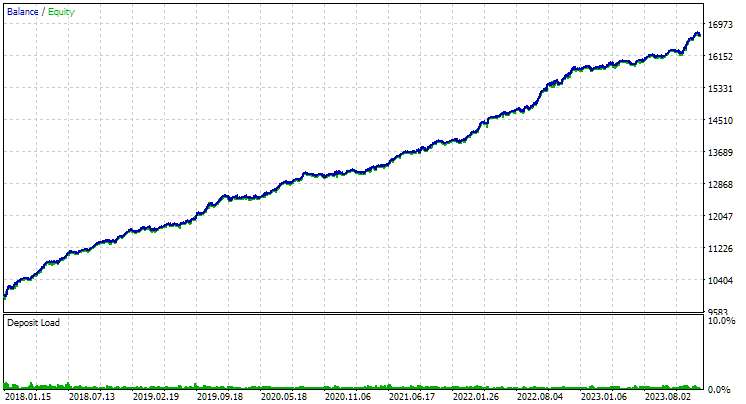
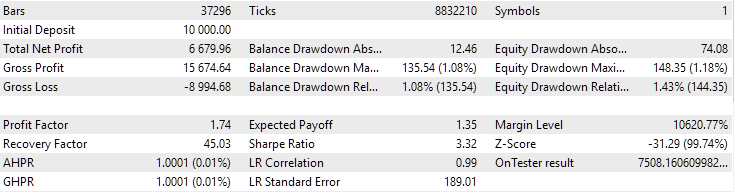
Fig. 2. Resultados do melhor grupo na segunda etapa com clusterização para GBPUSD H1
Outra questão interessante que vale abordar é a seguinte. Realizamos a clusterização e, de cada cluster, pegamos o melhor exemplar individual da estratégia de negociação (passe do testador). Assim, formamos uma lista de bons exemplares, a partir da qual escolhemos o melhor grupo. Se a clusterização foi feita em 256 clusters, então essa lista terá 256 exemplares. Na segunda etapa de otimização, selecionamos 16 desses 256 para formar um grupo. Será que não seria possível pular essa segunda etapa e simplesmente pegar os 16 exemplares individuais com maior lucro anual médio normalizado, desde que sejam de clusters diferentes?
Se isso for viável, permitiria reduzir significativamente o tempo gasto na otimização automática. Afinal, na segunda etapa, o EA é executado com 16 instâncias do que foi otimizado na primeira etapa. Por isso, cada passe do testador nessa fase leva proporcionalmente mais tempo.
Para o conjunto de tarefas de otimização analisado neste artigo, poderíamos ter economizado aproximadamente 6 horas de tempo. Isso representa uma fração significativa das 17 horas totais gastas. E considerando que incluímos duas tarefas de otimização da segunda etapa sem clusterização apenas para comparar seus resultados com os da segunda etapa com clusterização, a economia relativa de tempo seria ainda mais expressiva.
Para responder a essa questão, vamos observar os resultados da consulta que seleciona, antes da segunda etapa, os exemplares individuais que serão usados. Para facilitar a visualização, incluiremos na lista de colunas o índice com que cada exemplar será selecionado na segunda etapa, o identificador do passe desse exemplar na primeira etapa, o número do cluster e o valor do lucro anual médio normalizado. O resultado será o seguinte:
SELECT DISTINCT ROW_NUMBER() OVER (ORDER BY custom_ontester DESC) AS [index], p.id_pass, pc.cluster, p.custom_ontester, p.params FROM passes p JOIN tasks t ON p.id_task = t.id_task JOIN jobs j ON t.id_job = j.id_job JOIN passes_clusters pc ON pc.id_pass = p.id_pass WHERE (j.id_job = 5 AND p.custom_ontester >= 0 AND trades >= 40 AND p.sharpe_ratio >= 0.7) ORDER BY p.custom_ontester DESC;
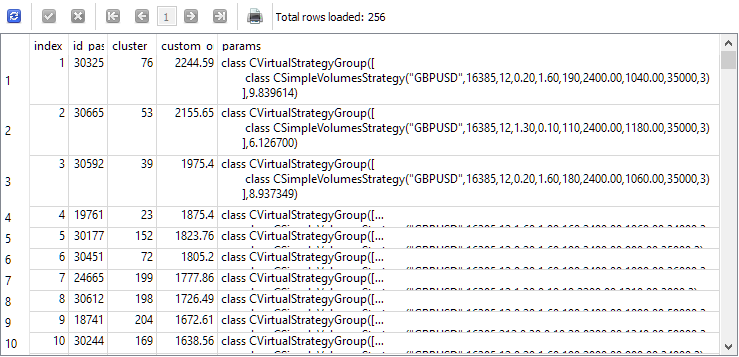
Como podemos ver, os exemplares individuais com os maiores valores de lucro anual médio normalizado têm os menores valores de índice. Portanto, se escolhermos o grupo de exemplares com índices de 1 a 16, teremos exatamente o grupo que gostaríamos de comparar com o grupo ideal obtido na segunda etapa de otimização.
Vamos utilizar o EA da segunda etapa e definir nos parâmetros de entrada os índices dos exemplares, de 1 a 16. O resultado será o seguinte:
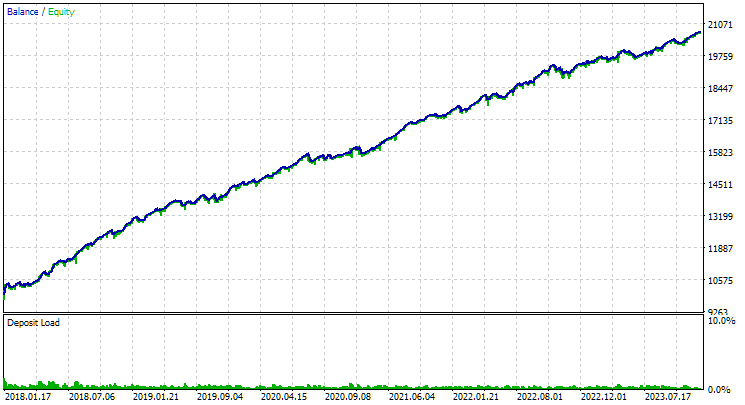
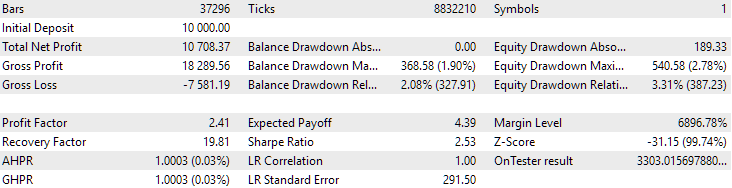
Fig. 3. Resultados do grupo dos primeiros 16 exemplares com maior lucro anual médio normalizado para GBPUSD H1
O gráfico tem um aspecto parecido com o do gráfico da figura 2, mas o valor do lucro anual médio normalizado caiu para menos da metade: $3300 contra $7500. Isso ocorreu por causa de uma redução muito maior observada para esse grupo, se comparado ao rebaixamento da melhor composição da figura 2. Situação semelhante aconteceu com o EURGBP — embora, nesse caso, a queda no lucro anual médio normalizado tenha sido um pouco menor, ainda assim foi bastante relevante.
Portanto, parece que não conseguiremos economizar tempo na otimização da segunda etapa dessa forma.
Por fim, vejamos os resultados da união das duas melhores composições encontradas:
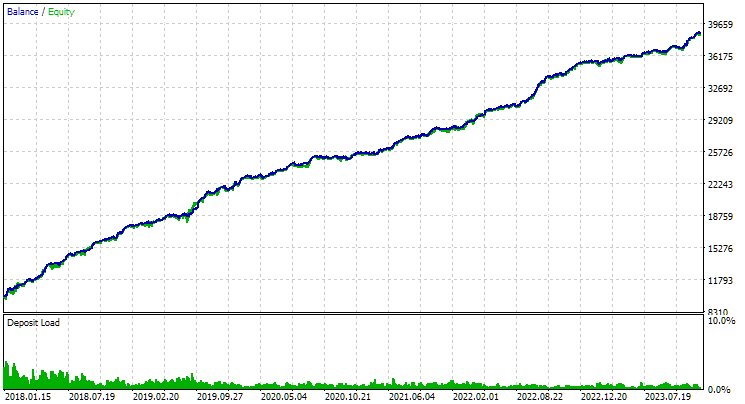
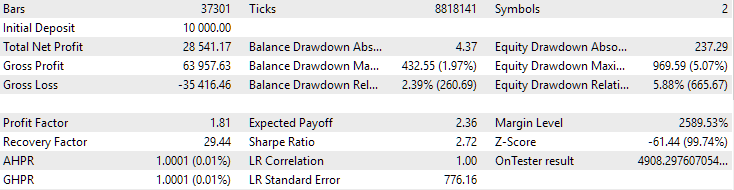
Fig. 4. Resultados do trabalho conjunto das duas melhores composições para EURGBP H1 e GBPUSD H1
Como se pode notar, todos os parâmetros ficaram em níveis intermediários em relação aos valores das composições separadas. Por exemplo, o lucro anual médio normalizado foi de $4900 — maior que o valor correspondente da composição EURGBP H1, mas menor do que o da composição GBPUSD H1.
Conclusão
Então, vamos recapitular o que alcançamos. Adicionamos a capacidade de criar etapas de otimização automática que podem executar programas externos, especificamente scripts em Python. No entanto, se necessário, agora também conseguimos, com pouco esforço, adicionar suporte para executar programas escritos em outras linguagens interpretadas ou mesmo programas compilados.
Até agora, usamos essa funcionalidade para reduzir a quantidade de instâncias individuais de estratégias de negociação da primeira etapa de otimização que participam da segunda etapa. Para isso, dividimos todas as instâncias em um número relativamente pequeno de clusters e selecionamos apenas uma instância de cada cluster. A redução da quantidade de instâncias ajudou a diminuir um pouco o tempo de execução da segunda etapa, e os resultados não se deterioraram — em alguns casos, até melhoraram significativamente. Portanto, o trabalho valeu a pena.
No entanto, ainda há espaço para avançar. A evolução do programa de clusterização pode incluir o tratamento adequado de situações em que o número de instâncias selecionadas seja menor que o número de clusters. Atualmente, isso resulta em erro. Também já podemos começar a pensar em ampliar o conjunto de estratégias de negociação e organizar os projetos de otimização automática de maneira mais conveniente. Mas isso ficará para a próxima vez.
Obrigado pela atenção e até a próxima!
Todos os resultados apresentados neste artigo e nos anteriores deste ciclo se baseiam exclusivamente em dados de teste em histórico e não constituem garantia de qualquer tipo de lucro futuro. O trabalho realizado neste projeto tem caráter experimental. Todos os resultados publicados podem ser utilizados por qualquer pessoa, sob sua total responsabilidade.
Conteúdo do arquivo
| # | Nome | Versão | Descrição | Últimas alterações |
|---|---|---|---|---|
| MQL5/Experts/Article.15911 | ||||
| 1 | Advisor.mqh | 1.04 | Classe base do EA | Parte 10 |
| 2 | ClusteringStage1.py | 1.00 | Programa de clusterização dos resultados da primeira etapa de otimização | Parte 19 |
| 3 | Database.mqh | 1.07 | Classe para trabalhar com o banco de dados | Parte 19 |
| 4 | database.sqlite.schema.sql | — | Esquema do banco de dados | Parte 19 |
| 5 | ExpertHistory.mqh | 1.00 | Classe para exportar histórico de operações para arquivo | Parte 16 |
| 6 | ExportedGroupsLibrary.mqh | — | Arquivo gerado com a lista de nomes de grupos de estratégias e array de strings de inicialização | Parte 17 |
| 7 | Factorable.mqh | 1.02 | Classe base de objetos criados a partir de string | Parte 19 |
| 8 | GroupsLibrary.mqh | 1.01 | Classe para manipular biblioteca de grupos selecionados de estratégias | Parte 18 |
| 9 | HistoryReceiverExpert.mq5 | 1.00 | EA para reprodução do histórico de operações com gerenciador de risco | Parte 16 |
| 10 | HistoryStrategy.mqh | 1.00 | Classe de estratégia de negociação para reprodução de histórico | Parte 16 |
| 11 | Interface.mqh | 1.00 | Classe base de visualização de diferentes objetos | Parte 4 |
| 12 | LibraryExport.mq5 | 1.01 | EA que salva strings de inicialização de passes selecionados da biblioteca em arquivo ExportedGroupsLibrary.mqh | Parte 18 |
| 13 | Macros.mqh | 1.02 | Macros úteis para manipulação de arrays | Parte 16 |
| 14 | Money.mqh | 1.01 | Classe base de gerenciamento de capital | Parte 12 |
| 15 | NewBarEvent.mqh | 1.00 | Classe para detectar novo candle de símbolo específico | Parte 8 |
| 16 | Optimization.mq5 | 1.03 | EA responsável pela execução das tarefas de otimização | Parte 19 |
| 17 | Optimizer.mqh | 1.00 | Classe do gerenciador de otimização automática de projetos | Parte 19 |
| 18 | OptimizerTask.mqh | 1.00 | Classe da tarefa de otimização | Parte 19 |
| 19 | Receiver.mqh | 1.04 | Classe base para conversão de volumes abertos em posições a mercado | Parte 12 |
| 20 | SimpleHistoryReceiverExpert.mq5 | 1.00 | EA simplificado para reprodução do histórico de operações | Parte 16 |
| 21 | SimpleVolumesExpert.mq5 | 1.20 | EA para execução paralela de múltiplos grupos de estratégias modeladas. Parâmetros são obtidos da biblioteca embutida de grupos. | Parte 17 |
| 22 | SimpleVolumesStage1.mq5 | 1.18 | EA de otimização de instância individual da estratégia (Etapa 1) | Parte 19 |
| 23 | SimpleVolumesStage2.mq5 | 1.02 | EA de otimização de grupo de instâncias de estratégias de negociação (Etapa 2) | Parte 19 |
| 24 | SimpleVolumesStage3.mq5 | 1.01 | EA que salva o grupo normalizado de estratégias na biblioteca com nome definido | Parte 18 |
| 25 | SimpleVolumesStrategy.mqh | 1.09 | Classe de estratégia de negociação com uso de volumes em ticks | Parte 15 |
| 26 | Strategy.mqh | 1.04 | Classe base da estratégia de negociação | Parte 10 |
| 27 | TesterHandler.mqh | 1.05 | Classe para lidar com eventos de otimização | Parte 19 |
| 28 | VirtualAdvisor.mqh | 1.07 | Classe do EA que trabalha com posições (ordens) virtuais | Parte 18 |
| 29 | VirtualChartOrder.mqh | 1.01 | Classe de posição virtual gráfica | Parte 18 |
| 30 | VirtualFactory.mqh | 1.04 | Classe da fábrica de objetos | Parte 16 |
| 31 | VirtualHistoryAdvisor.mqh | 1.00 | Classe do EA de reprodução do histórico de operações | Parte 16 |
| 32 | VirtualInterface.mqh | 1.00 | Classe da interface gráfica do EA | Parte 4 |
| 33 | VirtualOrder.mqh | 1.07 | Classe de ordens e posições virtuais | Parte 19 |
| 34 | VirtualReceiver.mqh | 1.03 | Classe de conversão de volumes abertos em posições a mercado (receptor) | Parte 12 |
| 35 | VirtualRiskManager.mqh | 1.02 | Classe de gerenciamento de risco (risk manager) | Parte 15 |
| 36 | VirtualStrategy.mqh | 1.05 | Classe de estratégia com posições virtuais | Parte 15 |
| 37 | VirtualStrategyGroup.mqh | 1.00 | Classe de grupo de estratégias ou grupos de grupos | Parte 11 |
| 38 | VirtualSymbolReceiver.mqh | 1.00 | Classe de receptor por símbolo | Parte 3 |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/15911
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Executo o seguinte
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1. py.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
e recebo este erro
ValueError: n_samples=150 deveria ser >= n_clusters=256.
Em seguida, altero n_clusters=150 e executo
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=150
e acho que funcionou. mas no banco de dados não houve nenhuma alteração
Depois disso, tentei otimizar com n_samples=150, mas não funcionou
Eu executo isso
...
e acho que funcionou. mas no banco de dados não houve nenhuma alteração
Não há uma nova tabela passes_clusters no banco de dados?
Não há uma nova tabela passes_clusters no banco de dados?
Ela funcionou corretamente.
O erro estava relacionado ao banco de dados.
Depois de corrigir o banco de dados, o código Python e o Estágio 2 funcionaram bem.
Obrigado por sua ajuda.
Artigo interessante! Vou ler a série inteira, então.
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
Por que eles abandonaram a funcionalidade da biblioteca AlgLib?
#include <Math\Alglib\alglib.mqh>Menos apenas em velocidade, mas principalmente porque o python paraleliza os cálculos em todos os núcleos.