
Как опередить любой рынок (Часть III): Индекс расходов Visa

Введение
В эпоху больших данных современному инвестору доступны практически бесконечные источники альтернативных данных. Каждый набор данных потенциально может обеспечить более высокий уровень точности при прогнозировании доходности рынка. Однако лишь немногие наборы данных оказываются по-настоящему полезными. В этой серии статей мы рассмотрим различные альтернативные данные, чтобы помочь вам принять обоснованное решение о том, следует ли вам включать их в свой анализ. Если эти наборы данных дают неудовлетворительные результаты, то вы сэкономите свое время.
Рассматривая альтернативные наборы данных, которые напрямую не доступны в терминале MetaTrader 5, мы можем обнаружить переменные, которые предсказывают уровни цен с относительно большей точностью, чем если бы мы полагались исключительно на рыночные котировки.
Краткий обзор торговой стратегии
VISA — американская транснациональная платежная компания. Компания была основана в 1958 году и сегодня является одной из крупнейших в мире сетей обработки транзакций. VISA имеет все возможности стать источником надежных альтернативных данных, поскольку она проникла практически на все рынки в развитых странах. Кроме того, Федеральный резервный банк Сент-Луиса также собирает некоторые макроэкономические данные, получаемые от VISA.
В этом обсуждении мы проанализируем индекс расходов VISA (VISA Spending Momentum Index, SMI). Индекс является макроэкономическим индикатором поведения потребительских расходов. Данные собираются компанией VISA с использованием ее собственных сетей и фирменных дебетовых и кредитных карт VISA. Все данные обезличены и собираются в основном на территории США. Поскольку VISA продолжает собирать данные с разных рынков, этот индекс в конечном итоге может стать эталонным показателем глобального потребительского поведения.
Для извлечения наборов данных VISA SMI мы будем использовать API Федерального резервного банка Сент-Луиса. API экономической базы данных Федеральной резервной системы (Federal Reserve Economic Database, FRED) позволяет нам получать доступ к сотням тысяч различных экономических временных рядов данных, собранных по всему миру.
Краткое изложение методологии
Данные SMI публикуются VISA ежемесячно и на момент написания статьи содержат менее 200 строк. Поэтому нам нужна методика моделирования, которая одновременно устойчива к переобучению и достаточно гибка, чтобы фиксировать сложные взаимосвязи. Возможно, это идеальная задача для нейронной сети.
Мы оптимизировали 5 параметров глубокой нейронной сети для классификации изменений в EURUSD с учетом набора обычных цен открытия, максимума, минимума и закрытия с 3 дополнительными входными данными, представляющими собой наборы данных VISA. Наша оптимизированная модель смогла достичь точности проверки в 71%, что значительно превышает показатели модели по умолчанию. Однако не забывайте, что эта точность касалась ежемесячных данных!
Мы применили 1000 итераций рандомизированного алгоритма поиска для оптимизации глубокой нейронной сети и успешно обучили модель без чрезмерной подгонки под обучающие данные. Какими бы впечатляющими ни казались эти результаты, мы не можем с уверенностью утверждать, что наблюдаемая взаимосвязь надежна. Наши алгоритмы выбора признаков отбросили все 3 набора данных VISA при выборе наиболее важных признаков непараметрическим способом. Кроме того, все три набора данных VISA имеют относительно низкие показатели взаимной информации, что может указывать на то, что наборы данных могут быть независимыми или что нам не удалось осмысленно продемонстрировать взаимосвязь для нашей модели.
Извлечение данных
Чтобы получить необходимые нам данные, вам необходимо сначала создать учетную запись на сайте FRED. После создания учетной записи вы сможете использовать свой ключ API FRED для доступа к экономическим временным рядам данных, хранящимся в Федеральном резервном банке Сент-Луиса, и следить за изложением. Наши рыночные данные по котировкам EURUSD будут извлекаться непосредственно из терминала с помощью MetaTrader 5 Python API.
Сначала загрузим необходимые библиотеки.
#Import the libraries we need import pandas as pd import seaborn as sns import numpy as np from fredapi import Fred import MetaTrader5 as mt5 from datetime import datetime import time import pytz
Теперь настроим ключ API FRED и получим необходимые нам данные.
#Let's setup our FredAPI
fred = Fred(api_key="ENTER YOUR API KEY")
visa_discretionary = pd.DataFrame(fred.get_series("VISASMIDSA"),columns=["visa d"])
visa_headline = pd.DataFrame(fred.get_series("VISASMIHSA"),columns=["visa h"])
visa_non_discretionary = pd.DataFrame(fred.get_series("VISASMINSA"),columns=["visa nd"])
Определим горизонт прогнозирования.
#Define how far ahead we want to forecast look_ahead = 10
Визуализация данных
Давайте визуализируем все три набора данных.
visa_discretionary.plot(title="VISA Spending Momentum Index: Discretionary") 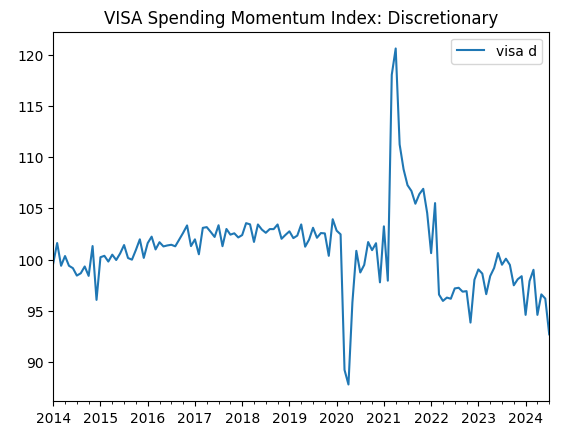
Рис. 1. Первый набор данных VISA
Теперь давайте визуализируем второй набор данных.
visa_headline.plot(title="VISA Spending Momentum Index: Headline") 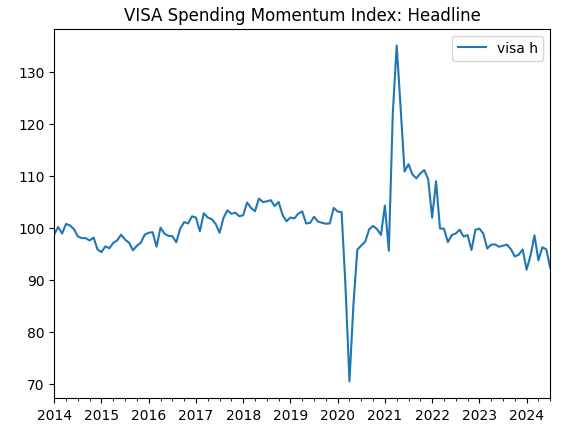
Рис. 2. Второй набор данных VISA
И наконец, наш третий набор данных VISA.
visa_non_discretionary.plot(title="VISA Spending Momentum Index: Non-Discretionary") 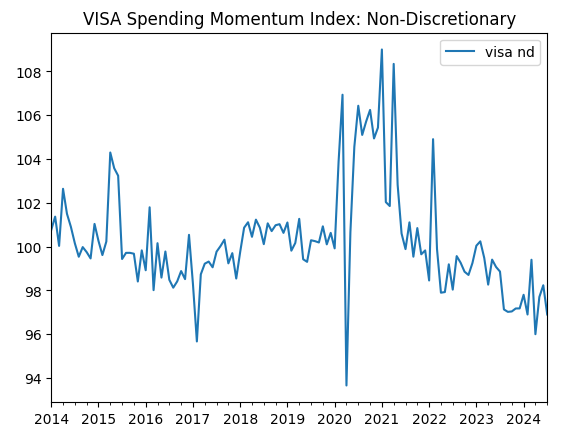
Рис. 3. Третий набор данных VISA
Первые два набора данных кажутся почти идентичными, более того, как мы увидим далее в нашем обсуждении, они имеют уровень корреляции 0,89, что означает, что они могут содержать одну и ту же информацию. Это говорит нам о том, что мы можем отказаться от одного из них. Однако мы позволим нашему алгоритму выбора признаков решить, необходимо ли это.
Извлечение данных из терминала MetaTrader 5
Инициализируем терминал.
#Initialize the terminal
mt5.initialize()
Укажем наш часовой пояс.
#Set timezone to UTC timezone = pytz.timezone("Etc/UTC")
Создадим объект datetime.
#Create a 'datetime' object in UTC utc_from = datetime(2024,7,1,tzinfo=timezone)
Извлечем данные из MetaTrader 5 и поместим их во фрейм данных pandas.
#Fetch the data eurusd = pd.DataFrame(mt5.copy_rates_from("EURUSD",mt5.TIMEFRAME_MN1,utc_from,visa_headline.shape[0]))
Промаркируем данные и будем использовать временную метку в качестве индекса.
#Label the data eurusd["target"] = np.nan eurusd.loc[eurusd["close"] > eurusd["close"].shift(-look_ahead),"target"] = 0 eurusd.loc[eurusd["close"] < eurusd["close"].shift(-look_ahead),"target"] = 1 eurusd.dropna(inplace=True) eurusd.set_index("time",inplace=True)
Объединим наборы данных, используя общие для них даты.
#Let's merge the datasets merged_data = eurusd.merge(visa_headline,right_index=True,left_index=True) merged_data = merged_data.merge(visa_discretionary,right_index=True,left_index=True) merged_data = merged_data.merge(visa_non_discretionary,right_index=True,left_index=True)
Разведочный анализ данных
Мы готовы исследовать наши данные. Диаграммы рассеяния полезны для визуализации взаимосвязи между двумя переменными. Давайте рассмотрим диаграммы рассеяния, созданные каждым из наборов данных VISA, построенные в зависимости от цены закрытия. Синие точки суммируют случаи, когда цена продолжала падать в течение следующих 10 свечей, тогда как оранжевые точки суммируют обратные случаи.
Хотя разделение по направлению к центру графика становится более "шумным", похоже, что на крайних уровнях наборы данных VISA достаточно хорошо разделяют восходящие и нисходящие движения.
#Let's create scatter plots sns.scatterplot(data=merged_data,y="close",x="visa h",hue="target").set(title="EURUSD Close Against VISA Momentum Index: Headline")
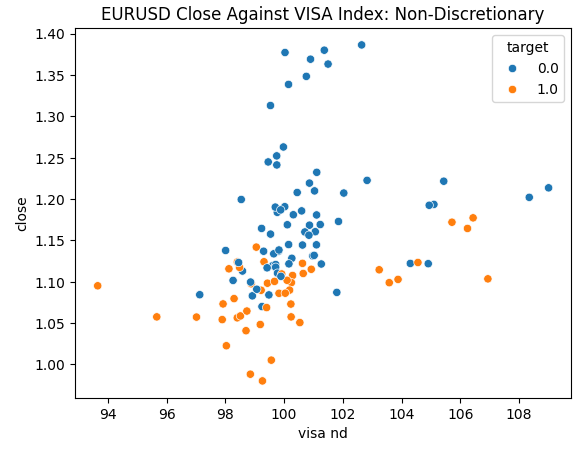
Рис. 4. Диаграмма недискреционного набора данных VISA относительно закрытия EURUSD
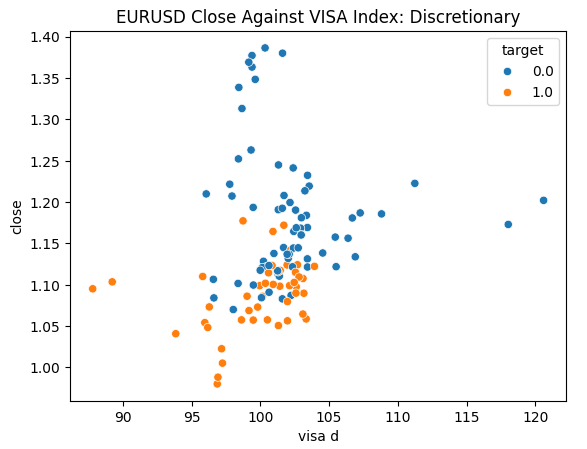
Рис. 5. Диаграмма дискреционного набора данных VISA относительно закрытия EURUSD
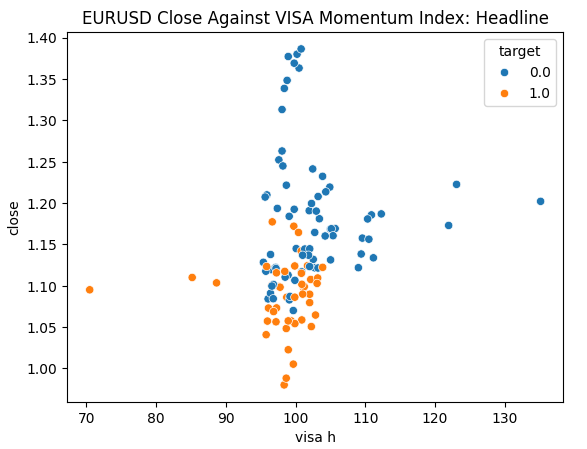
Рис. 6. Диаграмма основного набора данных VISA относительно закрытия EURUSD
Уровни корреляции между наборами данных VISA и рынком EURUSD умеренные и все имеют положительные значения. Ни один из уровней корреляции не представляет для нас особого интереса. Однако стоит отметить, что положительное значение указывает на то, что обе переменные имеют тенденцию расти и падать одновременно. Это соответствует нашему пониманию макроэкономики - потребительские расходы в США оказывают определенное влияние на обменные курсы. Если потребители решат не тратить деньги, то их действия приведут к сокращению общего количества денег в обращении, что может привести к укреплению доллара.
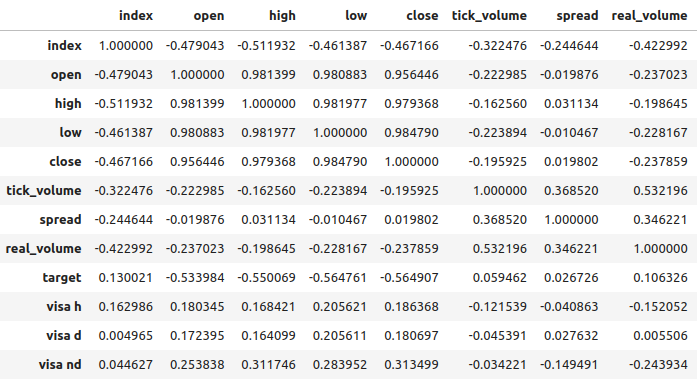
Рис. 7. Корреляционный анализ нашего набора данных
Выбор признаков
Насколько важна связь между нашей целью и нашими новыми признаками? Давайте посмотрим, будут ли новые признаки исключены нашим алгоритмом отбора признаков. Если наш алгоритм не выбирает ни одну из новых переменных, это может указывать на то, что связь ненадежна.
Алгоритм прямого выбора (forward selection) начинается с нулевой модели и добавляет по одному признаку за раз, затем он выбирает лучшую модель с одной переменной, а затем начинает поиск второй переменной и т. д. Он вернет нам лучшую модель, которую построил. В нашем исследовании алгоритм выбрал только цену открытия, что указывает на то, что взаимосвязь может быть нестабильной.
Импортируем необходимые нам библиотеки.
#Let's see which features are the most important from mlxtend.feature_selection import SequentialFeatureSelector as SFS from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs import matplotlib.pyplot as plt
Создадим объект прямого выбора.
#Create the forward selection object sfs = SFS( MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"]), k_features=(1,train_X.shape[1]), forward=False, scoring="accuracy", cv=5 ).fit(train_X,train_y)
Отобразим результаты на графике.
fig1 = plot_sfs(sfs.get_metric_dict(),kind="std_dev") plt.title("Neural Network Backward Feature Selection") plt.grid()
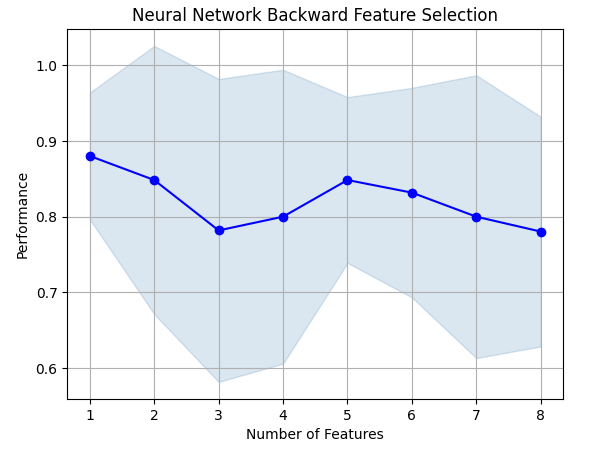
Рис. 8. По мере увеличения количества признаков в модели производительность ухудшалась
К сожалению, наша точность продолжала снижаться по мере добавления новых признаков. Это может означать либо то, что связь просто не настолько сильна, либо мы не раскрываем связь таким образом, который может интерпретировать наша модель. Таким образом, похоже, что модель с одной функцией все равно может справиться с задачей.
Лучший выявленный признак.
sfs.k_feature_names_
Давайте теперь посмотрим на наши показатели взаимной информации (mutual information, MI). MI информирует нас о том, насколько велик потенциал каждой переменной для прогнозирования цели. Теоретически значения MI имеют положительное значение и варьируются от 0 до бесконечности, но на практике мы редко наблюдаем значения MI выше 2, а значение MI выше 1 считается хорошим.
Импортируем классификатор MI из scikit-learn.
#Mutual information
from sklearn.feature_selection import mutual_info_classif Оценка MI для основного набора данных.
#Mutual information from the headline visa dataset, print(f"VISA Headline dataset has a mutual info score of: {mutual_info_classif(train_X.loc[:,['visa h']],train_y)[0]}")
Оценка MI для дискреционного набора данных.
#Mutual information from the second visa dataset, print(f"VISA Discretionary dataset has a mutual info score of: {mutual_info_classif(train_X.loc[:,['visa d']],train_y)[0]}")
Все наши наборы данных имели низкие показатели MI. Это может быть веской причиной попробовать применить различные преобразования к набору данных VISA. Надеюсь, нам удастся обнаружить более сильную связь.
Настройка параметров
Давайте теперь попробуем настроить нашу глубокую нейронную сеть для прогнозирования EURUSD. Перед этим нам необходимо масштабировать наши данные. Сначала сбросим индекс объединенного набора данных.
#Reset the index
merged_data.reset_index(inplace=True)
Определим цель и предикторы.
#Define the target target = "target" ohlc_predictors = ["open","high","low","close","tick_volume"] visa_predictors = ["visa d","visa h","visa nd"] all_predictors = ohlc_predictors + visa_predictors
Теперь нам необходимо масштабировать и преобразовать наши данные. Из каждого значения в нашем наборе данных мы вычтем среднее значение и разделим на стандартное отклонение соответствующего столбца. Стоит отметить, что это преобразование чувствительно к выбросам.
#Let's scale the data scale_factors = pd.DataFrame(index=["mean","standard deviation"],columns=all_predictors) for i in np.arange(0,len(all_predictors)): #Store the mean and standard deviation for each column scale_factors.iloc[0,i] = merged_data.loc[:,all_predictors[i]].mean() scale_factors.iloc[1,i] = merged_data.loc[:,all_predictors[i]].std() merged_data.loc[:,all_predictors[i]] = ((merged_data.loc[:,all_predictors[i]] - scale_factors.iloc[0,i]) / scale_factors.iloc[1,i]) scale_factors
Рассмотрим масштабированные данные.
#Let's see the normalized data merged_data
Импортируем стандартные библиотеки.
#Lets try to train a deep neural network to uncover relationships in the data from sklearn.neural_network import MLPClassifier from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
Создадим обучающую и тестовую выборки.
#Create train test partitions for our alternative data train_X,test_X,train_y,test_y = train_test_split(merged_data.loc[:,all_predictors],merged_data.loc[:,"target"],test_size=0.5,shuffle=False)
Настроим модель на доступные входные данные. Напомним, что сначала мы должны передать модель, которую хотим настроить, а затем указать параметры интересующей нас модели. После этого нам нужно указать, сколько сверток мы намерены использовать для перекрестной проверки.
tuner = RandomizedSearchCV(MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False), { "activation": ["relu","identity","logistic","tanh"], "solver": ["lbfgs","adam","sgd"], "alpha": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], "learning_rate": ["constant", "invscaling", "adaptive"], "learning_rate_init": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], }, cv=5, n_iter=1000, scoring="accuracy", return_train_score=False )
Устанавливаем тюнер.
tuner.fit(train_X,train_y)
Давайте рассмотрим результаты, полученные на обучающих данных, от лучших к худшим.
tuner_results = pd.DataFrame(tuner.cv_results_) params = ["param_activation","param_solver","param_alpha","param_learning_rate","param_learning_rate_init","mean_test_score"] tuner_results.loc[:,params].sort_values(by="mean_test_score",ascending=False)

Рис. 9. Результаты нашей оптимизации
Наша максимальная точность составила 88% на обучающих данных. Обратите внимание, что из-за стохастического характера выбранного нами алгоритма оптимизации может быть сложно воспроизвести результаты, полученные в этой демонстрации.
Тестирование на переобучение
Давайте теперь сравним наши стандартные и настроенные модели, чтобы увидеть, не переобучаем ли мы обучающие данные. Если мы переобучаем, то модель по умолчанию превзойдет нашу настроенную модель на проверочном наборе, в противном случае наша настроенная модель будет работать лучше.
Давайте подготовим 2 модели.
#Let's compare the default model and our customized model on the hold out set default_model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False) customized_model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"])
Измерим точность модели по умолчанию.
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
accuracy_score(test_y,default_model.predict(test_X))
Точность нашей индивидуальной модели.
#The accuracy of the defualt model
customized_model.fit(train_X,train_y)
accuracy_score(test_y,customized_model.predict(test_X))
Похоже, мы обучили модель без чрезмерной подгонки под тренировочные данные. Также обратите внимание, что наша ошибка обучения обычно всегда выше нашей ошибки тестирования, однако расхождение между ними не должно быть слишком большим. Наша ошибка обучения составила 88%, а ошибка тестирования — 74%. Неплохо. Большой разрыв между ошибками обучения и тестирования был бы тревожным сигналом, поскольку он мог бы указывать на то, что мы переобучаем сеть!
Реализация стратегии
Сначала определим глобальные переменные, которые будем использовать.
#Let us now start building our trading strategy SYMBOL = 'EURUSD' TIMEFRAME = mt5.TIMEFRAME_MN1 DEVIATION = 1000 VOLUME = 0 LOT_MULTIPLE = 1
Теперь инициализируем терминал MetaTrader 5.
#Get the system up
if not mt5.initialize():
print('Failed To Log in')
Теперь нам нужно узнать больше подробностей о рынке.
#Let's fetch the trading volume
for index,symbol in enumerate(mt5.symbols_get()):
if symbol.name == SYMBOL:
print(f"{symbol.name} has minimum volume: {symbol.volume_min}")
VOLUME = symbol.volume_min * LOT_MULTIPLE
Эта функция вычислит для нас текущую рыночную цену.
#A function to get current prices def get_prices(): start = datetime(2024,1,1) end = datetime.now() data = pd.DataFrame(mt5.copy_rates_range(SYMBOL,TIMEFRAME,start,end)) data['time'] = pd.to_datetime(data['time'],unit='s') data.set_index('time',inplace=True) return(data.iloc[-1,:])
Давайте также создадим функцию для извлечения самых последних альтернативных данных из FRED API.
#A function to get our alternative data def get_alternative_data(): visa_d = fred.get_series_as_of_date("VISASMIDSA",datetime.now()) visa_d = visa_d.iloc[-1,-1] visa_h = fred.get_series_as_of_date("VISASMIHSA",datetime.now()) visa_h = visa_h.iloc[-1,-1] visa_n = fred.get_series_as_of_date("VISASMINSA",datetime.now()) visa_n = visa_n.iloc[-1,-1] return(visa_d,visa_h,visa_n)
Нам нужна функция, отвечающая за нормализацию и масштабирование наших входных данных.
#A function to prepare the inputs for our model def get_model_inputs(): LAST_OHLC = get_prices() visa_d , visa_h , visa_n = get_alternative_data() return( np.array([[ ((LAST_OHLC['open'] - scale_factors.iloc[0,0]) / scale_factors.iloc[1,0]), ((LAST_OHLC['high'] - scale_factors.iloc[0,1]) / scale_factors.iloc[1,1]), ((LAST_OHLC['low'] - scale_factors.iloc[0,2]) / scale_factors.iloc[1,2]), ((LAST_OHLC['close'] - scale_factors.iloc[0,3]) / scale_factors.iloc[1,3]), ((LAST_OHLC['tick_volume'] - scale_factors.iloc[0,4]) / scale_factors.iloc[1,4]), ((visa_d - scale_factors.iloc[0,5]) / scale_factors.iloc[1,5]), ((visa_h - scale_factors.iloc[0,6]) / scale_factors.iloc[1,6]), ((visa_n - scale_factors.iloc[0,7]) / scale_factors.iloc[1,7]) ]]) )
Давайте обучим нашу модель на всех имеющихся у нас данных.
#Let's train our model on all the data we have model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation="logistic",solver="lbfgs",alpha=0.00001,learning_rate="constant",learning_rate_init=0.00001) model.fit(merged_data.loc[:,all_predictors],merged_data.loc[:,"target"])
Эта функция получит прогноз от нашей модели.
#A function to get a prediction from our model def ai_forecast(): model_inputs = get_model_inputs() prediction = model.predict(model_inputs) return(prediction[0])
Теперь мы подошли к сути нашего алгоритма. Сначала проверим, сколько у нас открытых позиций. Затем получим прогноз от нашей модели. Если у нас нет открытых позиций, мы воспользуемся прогнозом нашей модели для открытия позиции. В противном случае мы будем использовать прогноз нашей модели в качестве сигнала выхода, если у нас есть открытые позиции.
while True: #Get data on the current state of our terminal and our portfolio positions = mt5.positions_total() forecast = ai_forecast() BUY_STATE , SELL_STATE = False , False #Interpret the model's forecast if(forecast == 0.0): SELL_STATE = True BUY_STATE = False elif(forecast == 1.0): SELL_STATE = False BUY_STATE = True print(f"Our forecast is {forecast}") #If we have no open positions let's open them if(positions == 0): print(f"We have {positions} open trade(s)") if(SELL_STATE): print("Opening a sell position") mt5.Sell(SYMBOL,VOLUME) elif(BUY_STATE): print("Opening a buy position") mt5.Buy(SYMBOL,VOLUME) #If we have open positions let's manage them if(positions > 0): print(f"We have {positions} open trade(s)") for pos in mt5.positions_get(): if(pos.type == 1): if(BUY_STATE): print("Closing all sell positions") mt5.Close(SYMBOL) if(pos.type == 0): if(SELL_STATE): print("Closing all buy positions") mt5.Close(SYMBOL) #If we have finished all checks then we can wait for one day before checking our positions again time.sleep(24 * 60 * 60)
We have 0 open trade(s)
Opening a sell position
Реализация средствами MQL5
Чтобы реализовать нашу стратегию на MQL5, нам сначала необходимо экспортировать наши модели в формат Open Neural Network Exchange (ONNX). ONNX — это протокол для представления моделей машинного обучения в виде комбинации графа и ребер. Этот стандартизированный протокол позволяет разработчикам с легкостью создавать и развертывать модели машинного обучения с использованием различных языков программирования. К сожалению, не все модели и фреймворки машинного обучения полностью поддерживаются текущим API ONNX.
Для начала импортируем несколько библиотек.
#Import the libraries we need import pandas as pd import numpy as np from fredapi import Fred import MetaTrader5 as mt5 from datetime import datetime import time import pytz
Затем нам нужно ввести наш ключ FRED API, чтобы получить доступ к необходимым нам данным.
#Let's setup our FredAPI
fred = Fred(api_key="")
visa_discretionary = pd.DataFrame(fred.get_series("VISASMIDSA"),columns=["visa d"])
visa_headline = pd.DataFrame(fred.get_series("VISASMIHSA"),columns=["visa h"])
visa_non_discretionary = pd.DataFrame(fred.get_series("VISASMINSA"),columns=["visa nd"])
Обратите внимание, что после извлечения данных мы масштабировали их, используя тот же формат, который был описан выше. Мы опустили эти шаги, чтобы избежать повторения одной и той же информации. Единственное небольшое отличие заключается в том, что теперь мы обучаем модель прогнозировать фактическую цену закрытия, а не просто бинарную цель.
После масштабирования данных давайте попробуем настроить параметры нашей модели.
#A few more libraries we need from sklearn.neural_network import MLPRegressor from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error
Нам необходимо разделить наши данные так, чтобы у нас был обучающий набор для оптимизации модели и проверочный набор, который мы будем использовать для проверки на переобучение.
#Create train test partitions for our alternative data train_X,test_X,train_y,test_y = train_test_split(merged_data.loc[:,all_predictors],merged_data.loc[:,"close target"],test_size=0.5,shuffle=False)
Теперь выполним настройку гиперпараметров. Обратите внимание, что мы установили метрику оценки на "neg mean squared error" (отрицательная средняя квадратическая ошибка). Эта метрика оценки будет определять модель, которая дает наименьшее значение MSE, как наиболее эффективную модель.
tuner = RandomizedSearchCV(MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False,early_stopping=True), { "activation": ["relu","identity","logistic","tanh"], "solver": ["lbfgs","adam","sgd"], "alpha": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], "learning_rate": ["constant", "invscaling", "adaptive"], "learning_rate_init": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], }, cv=5, n_iter=1000, scoring="neg_mean_squared_error", return_train_score=False, n_jobs=-1 )
Установка объекта тюнера.
tuner.fit(train_X,train_y)
Проверим на переобучение.
#Let's compare the default model and our customized model on the hold out set default_model = MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False) customized_model = MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"])
Точность нашей модели по умолчанию.
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
mean_squared_error(test_y,default_model.predict(test_X))
Нам удалось превзойти нашу модель по умолчанию на отложенном проверочном наборе, что является хорошим признаком того, что мы не переобучаемся.
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
mean_squared_error(test_y,default_model.predict(test_X))
0.006138795093781729
Давайте применим настроенную модель ко всем имеющимся у нас данным, прежде чем экспортировать ее в формат ONNX.
#Fit the model on all the data we have
customized_model.fit(test_X,test_y)
Импортируем библиотеки преобразования ONNX.
#Convert to ONNX
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx import convert_sklearn
import netron
import onnx Определим тип и форму входных данных нашей модели.
#Define the initial types initial_types = [("float_input",FloatTensorType([1,train_X.shape[1]]))]
Создадим ONNX-представление модели в памяти.
#Create the onnx representation onnx_model = convert_sklearn(customized_model,initial_types=initial_types,target_opset=12)
Сохраним представление ONNX на жестком диске.
#Save the ONNX model onnx_model_name = "EURUSD VISA MN1 FLOAT.onnx" onnx.save(onnx_model,onnx_model_name)
Просмотрим модель ONNX в netron.
#View the ONNX model
netron.start(onnx_model_name) 
Рис. 10. Наша глубокая нейронная сеть в формате ONNX

Рис. 11. Метаданные нашей модели ONNX
Мы почти готовы приступить к созданию нашего советника. Однако сначала нам необходимо создать фоновый сервис Python, который будет извлекать данные из FRED и передавать их в нашу программу.
Сначала импортируем необходимые нам библиотеки.
#Import the libraries we need import pandas as pd import numpy as np from fredapi import Fred from datetime import datetime
Затем войдем в систему, используя наши учетные данные FRED.
#Let's setup our FredAPI fred = Fred(api_key="")
Нам нужно определить функцию, которая будет извлекать данные для нас и записывать их в CSV.
#A function to write out our alternative data to CSV def write_out_alternative_data(): visa_d = fred.get_series_as_of_date("VISASMIDSA",datetime.now()) visa_d = visa_d.iloc[-1,-1] visa_h = fred.get_series_as_of_date("VISASMIHSA",datetime.now()) visa_h = visa_h.iloc[-1,-1] visa_n = fred.get_series_as_of_date("VISASMINSA",datetime.now()) visa_n = visa_n.iloc[-1,-1] data = pd.DataFrame(np.array([visa_d,visa_h,visa_n]),columns=["Data"],index=["Discretionary","Headline","Non-Discretionary"]) data.to_csv("C:\\Users\\Westwood\\AppData\\Roaming\\MetaQuotes\\Terminal\\D0E8209F77C8CF37AD8BF550E51FF075\\MQL5\\Files\\fred_visa.csv")
Теперь нам нужно написать цикл, который будет проверять наличие новых данных раз в день и обновлять наш CSV-файл.
while True: #Update the fred data for our MT5 EA write_out_alternative_data() #If we have finished all checks then we can wait for one day before checking for new data time.sleep(24 * 60 * 60)Теперь, когда у нас есть доступ к последним данным FRED, мы можем приступить к созданию нашего советника.
Сначала загрузим нашу модель ONNX в приложение в качестве ресурса. //+------------------------------------------------------------------+ //| VISA EA.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Resorces | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD VISA MN1 FLOAT.onnx" as const uchar onnx_buffer[];
Затем загрузим торговую библиотеку, которая поможет нам открывать и управлять нашими позициями.
//+------------------------------------------------------------------+ //| Libraries we need | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
Пока что наше приложение работает хорошо. Давайте создадим глобальные переменные, которые будем использовать в различных блоках нашего приложения.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; double mean_values[8],std_values[8]; float visa_data[3]; vector model_forecast = vector::Zeros(1); double trading_volume = 0.3; int state = 0;
Прежде чем мы сможем начать использовать нашу модель ONNX, нам необходимо сначала создать модель ONNX из ресурса, который нам потребовался в начале программы. После этого нам необходимо определить входные и выходные формы модели.
//+------------------------------------------------------------------+ //| Load the ONNX model | //+------------------------------------------------------------------+ bool load_onnx_model(void) { //--- Try create the ONNX model from the buffer we have onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Validate the model if(onnx_model == INVALID_HANDLE) { Comment("Failed to create the ONNX model. ",GetLastError()); return(false); } //--- Set the I/O shape ulong input_shape[] = {1,8}; ulong output_shape[] = {1,1}; //--- Validate the I/O shapes if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set the ONNX model input shape. ",GetLastError()); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set the ONNX model output shape. ",GetLastError()); return(false); } return(true); }
Напомним, что мы стандартизировали наши данные, вычитая среднее значение столбца и разделив его на стандартное отклонение каждого столбца. Нам необходимо сохранить эти значения в памяти. Поскольку эти значения никогда не изменятся, я просто жестко закодировал их в программе.
//+------------------------------------------------------------------+ //| Mean & Standard deviation values | //+------------------------------------------------------------------+ void load_scaling_values(void) { //--- Mean & standard deviation values for the EURUSD OHLCV mean_values[0] = 1.146552; std_values[0] = 0.08293; mean_values[1] = 1.165568; std_values[1] = 0.079657; mean_values[2] = 1.125744; std_values[2] = 0.083896; mean_values[3] = 1.143834; std_values[3] = 0.080655; mean_values[4] = 1883520.051282; std_values[4] = 826680.767222; //--- Mean & standard deviation values for the VISA datasets mean_values[5] = 101.271017; std_values[5] = 3.981438; mean_values[6] = 100.848506; std_values[6] = 6.565229; mean_values[7] = 100.477269; std_values[7] = 2.367663; }
Созданная нами фоновая служба Python всегда будет предоставлять нам самые последние доступные данные. Давайте создадим функцию для чтения этого CSV-файла и сохраним значения в массиве.
//+-------------------------------------------------------------------+ //| Read in the VISA data | //+-------------------------------------------------------------------+ void read_visa_data(void) { //--- Read in the file string file_name = "fred_visa.csv"; //--- Try open the file int result = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI,","); //Strings of ANSI type (one byte symbols). //--- Check the result if(result != INVALID_HANDLE) { Print("Opened the file"); //--- Store the values of the file int counter = 0; string value = ""; while(!FileIsEnding(result) && !IsStopped()) //read the entire csv file to the end { if(counter > 10) //if you aim to read 10 values set a break point after 10 elements have been read break; //stop the reading progress value = FileReadString(result); Print("Trying to read string: ",value); if(counter == 3) { Print("Discretionary data: ",value); visa_data[0] = (float) value; } if(counter == 5) { Print("Headline data: ",value); visa_data[1] = (float) value; } if(counter == 7) { Print("Non-Discretionary data: ",value); visa_data[2] = (float) value; } if(FileIsLineEnding(result)) { Print("row++"); } counter++; } //--- Show the VISA data Print("VISA DATA: "); ArrayPrint(visa_data); //---Close the file FileClose(result); } }
Наконец, мы должны определить функцию, отвечающую за получение прогнозов из нашей модели. Во-первых, мы сохраняем текущие входные данные в векторе с плавающей точкой, поскольку наша модель имеет тип входных данных с плавающей точкой.
Напомним, что нам необходимо масштабировать каждое входное значение, вычитая среднее значение столбца и разделив его на стандартное отклонение столбца, прежде чем передавать входные данные в нашу модель.
//+--------------------------------------------------------------+ //| Get a prediction from our model | //+--------------------------------------------------------------+ void model_predict(void) { //--- Fetch input data read_visa_data(); vectorf input_data = {(float)iOpen("EURUSD",PERIOD_MN1,0), (float)iHigh("EURUSD",PERIOD_MN1,0), (float)iLow("EURUSD",PERIOD_MN1,0), (float)iClose("EURUSD",PERIOD_MN1,0), (float)iTickVolume("EURUSD",PERIOD_MN1,0), (float)visa_data[0], (float)visa_data[1], (float)visa_data[2] }; //--- Scale the data for(int i =0; i < 8;i++) { input_data[i] = (float)((input_data[i] - mean_values[i])/std_values[i]); } //--- Show the input data Print("Input data: ",input_data); //--- Obtain a forecast OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT|ONNX_DEFAULT,input_data,model_forecast); } //+------------------------------------------------------------------+
Теперь определим процедуру инициализации. Начнем с загрузки нашей модели ONNX, затем прочитаем набор данных VISA и, наконец, загрузим наши значения масштабирования.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Load the ONNX file if(!load_onnx_model()) { //--- We failed to load the ONNX model return(INIT_FAILED); } //--- Read the VISA data read_visa_data(); //--- Load scaling values load_scaling_values(); //--- We were successful return(INIT_SUCCEEDED); }
Всякий раз, когда наша программа перестает использоваться, давайте освободим ресурсы, которые нам больше не нужны.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up the resources we don't need OnnxRelease(onnx_model); ExpertRemove(); }
Всякий раз, когда у нас появляются новые данные о ценах, мы сначала извлекаем прогноз из нашей модели. Если у нас нет открытых позиций, мы будем следовать записи, сгенерированной нашей моделью. Наконец, если у нас есть открытые позиции, мы будем использовать нашу модель ИИ для заблаговременного обнаружения потенциальных разворотов цены.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Get a prediction from our model model_predict(); Comment("Model forecast: ",model_forecast[0]); //--- Check if we have any positions if(PositionsTotal() == 0) { //--- Note that we have no trades open state = 0; //--- Find an entry and take note if(model_forecast[0] < iClose(_Symbol,PERIOD_CURRENT,0)) { Trade.Sell(trading_volume,_Symbol,SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,"Gain an Edge VISA"); state = 1; } if(model_forecast[0] > iClose(_Symbol,PERIOD_CURRENT,0)) { Trade.Buy(trading_volume,_Symbol,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,"Gain an Edge VISA"); state = 2; } } //--- If we have positions open, check for reversals if(PositionsTotal() > 0) { if(((state == 1) && (model_forecast[0] > iClose(_Symbol,PERIOD_CURRENT,0))) || ((state == 2) && (model_forecast[0] < iClose(_Symbol,PERIOD_CURRENT,0)))) { Alert("Reversal detected, closing positions now"); Trade.PositionClose(_Symbol); } } } //+------------------------------------------------------------------+

Рис. 12. Наш советник VISA

Рис. 13. Пример вывода нашей программы

Рис. 14. Наше приложение в действии
Заключение
Мы продемонстрировали, как можно выбрать данные, которые могут быть полезны для вашей торговой стратегии. Мы обсудили, как измерить потенциальную силу альтернативных данных и как оптимизировать модели, чтобы извлечь максимальную производительность без чрезмерной подгонки. Существуют сотни тысяч наборов данных, достойных изучения, и мы стремимся определить наиболее информативные из них.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/15575
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Спасибо, Гаму.
Отличная статья, спасибо, что поделились!!!
Еще раз спасибо Гаму. Хорошо написано, как обычно. Отличный шаблон с комментариями о том, как визуализировать, масштабировать, тестировать, проверять на перебор, реализовывать datafeed, прогнозировать и реализовывать торговую систему на основе набора данных. Фантастика очень ценна.