
Verschaffen Sie sich einen Vorteil auf jedem Markt (Teil III): Visa-Ausgabenindex

Einführung
Im Zeitalter von Big Data stehen dem modernen Anleger nahezu unendlich viele alternative Datenquellen zur Verfügung. Jeder Datensatz birgt das Potenzial, bei der Vorhersage von Marktrenditen ein höheres Maß an Genauigkeit zu erreichen. Doch nur wenige Datensätze halten, was sie versprechen. In dieser Artikelserie werden wir Ihnen helfen, die weite Landschaft alternativer Daten zu erforschen, um Ihnen zu helfen, eine fundierte Entscheidung zu treffen, ob Sie diese Datensätze in Ihre Analyse einbeziehen sollten, andererseits, wenn diese Datensätze unbefriedigende Ergebnisse liefern, dann können wir Ihnen helfen, Zeit zu sparen.
Unser Grundgedanke ist, dass wir durch die Berücksichtigung alternativer Datensätze, die nicht direkt im MetaTrader 5-Terminal verfügbar sind, Variablen aufdecken können, die die Kursniveaus mit relativ höherer Genauigkeit vorhersagen als ein gelegentlicher Marktteilnehmer, der sich ausschließlich auf Marktnotierungen verlässt.
Überblick über die Handelsstrategie
VISA ist ein amerikanisches multinationales Zahlungsdienstleistungsunternehmen. Das Unternehmen wurde 1958 gegründet und betreibt heute eines der größten Transaktionsverarbeitungsnetzwerke der Welt. VISA ist gut positioniert, um eine Quelle für seriöse alternative Daten zu sein, da das Unternehmen fast alle Märkte in der entwickelten Welt durchdrungen hat. Darüber hinaus erhebt auch die Federal Reserve Bank of St. Louis einen Teil ihrer makroökonomischen Daten bei VISA.
In dieser Diskussion werden wir den VISA Spending Momentum Index (SMI) analysieren. Der Index ist ein makroökonomischer Indikator für das Ausgabeverhalten der Verbraucher. Die Daten werden von VISA unter Verwendung der firmeneigenen Netzwerke und der VISA-Debit- und -Kreditkarten gesammelt. Alle Daten sind entpersonalisiert und werden hauptsächlich in den Vereinigten Staaten erhoben. Da VISA weiterhin Daten aus verschiedenen Märkten sammelt, könnte dieser Index schließlich zu einem Maßstab für das weltweite Verbraucherverhalten werden.
Wir werden einen von der Federal Reserve Bank of St. Louis bereitgestellten API-Dienst nutzen, um die VISA SMI-Datensätze abzurufen. Die API der Federal Reserve Economic Database (FRED) ermöglicht uns den Zugang zu Hunderttausenden verschiedener wirtschaftlicher Zeitreihendaten, die auf der ganzen Welt gesammelt wurden.
Zusammenfassung der Methodik
Die SMI-Daten werden monatlich von VISA veröffentlicht und enthalten zum Zeitpunkt der Erstellung dieses Berichts weniger als 200 Zeilen. Daher benötigen wir eine Modellierungstechnik, die gleichzeitig resistent gegen eine Überanpassung und flexibel genug ist, um komplexe Beziehungen zu erfassen. Dies könnte eine ideale Aufgabe für ein neuronales Netz sein.
Wir haben 5 Parameter eines tiefen neuronalen Netzwerks optimiert, um die Veränderungen im EURUSD zu klassifizieren, wenn ein Satz von gewöhnlichen Eröffnungs-, Höchst-, Tiefst- und Schlusskursen mit 3 zusätzlichen Eingaben, nämlich den VISA-Datensätzen, vorliegt. Unser optimiertes Modell konnte bei der Validierung eine Genauigkeit von 71 % erreichen und übertraf damit das Standardmodell deutlich. Der Leser sollte jedoch bedenken, dass diese Genauigkeit auf monatlichen Daten beruht!
Wir setzten 1000 Iterationen eines randomisierten Suchalgorithmus ein, um das tiefe neuronale Netzwerk zu optimieren, und trainierten das Modell erfolgreich, ohne dass es sich zu stark an die Trainingsdaten anpasste. So beeindruckend diese Ergebnisse auch sein mögen, wir können nicht mit Sicherheit sagen, dass die beobachtete Beziehung zuverlässig ist. Unsere Algorithmen zur Merkmalsauswahl verwarfen alle 3 VISA-Datensätze bei der Auswahl der wichtigsten Merkmale auf nicht-parametrische Weise. Darüber hinaus weisen alle drei VISA-Datensätze relativ niedrige Werte für die gegenseitige Information auf, was für uns ein Hinweis darauf sein könnte, dass die Datensätze unabhängig sind oder dass es uns nicht gelungen ist, die Beziehung in einer für unser Modell sinnvollen Weise aufzudecken.
Datenextraktion
Um die benötigten Daten abzurufen, müssen Sie zunächst ein Konto auf der FRED-Website anlegen. Nachdem Sie ein Konto eingerichtet haben, können Sie Ihren FRED-API-Schlüssel verwenden, um auf die wirtschaftlichen Zeitreihendaten der Federal Reserve of St. Louis zuzugreifen und unserer Diskussion zu folgen. Unsere Marktdaten zu EURUSD-Kursen werden direkt vom Terminal über die MetaTrader 5 Python API abgerufen.
Um loszulegen, laden Sie zunächst die benötigten Bibliotheken.
#Import the libraries we need import pandas as pd import seaborn as sns import numpy as np from fredapi import Fred import MetaTrader5 as mt5 from datetime import datetime import time import pytz
Richten Sie nun den FRED-API-Schlüssel ein und rufen Sie die benötigten Daten ab.
#Let's setup our FredAPI
fred = Fred(api_key="ENTER YOUR API KEY")
visa_discretionary = pd.DataFrame(fred.get_series("VISASMIDSA"),columns=["visa d"])
visa_headline = pd.DataFrame(fred.get_series("VISASMIHSA"),columns=["visa h"])
visa_non_discretionary = pd.DataFrame(fred.get_series("VISASMINSA"),columns=["visa nd"])
Legen Sie den Prognosehorizont fest.
#Define how far ahead we want to forecast look_ahead = 10
Visualisieren der Daten
Lassen Sie uns alle drei Datensätze visualisieren.
visa_discretionary.plot(title="VISA Spending Momentum Index: Discretionary") 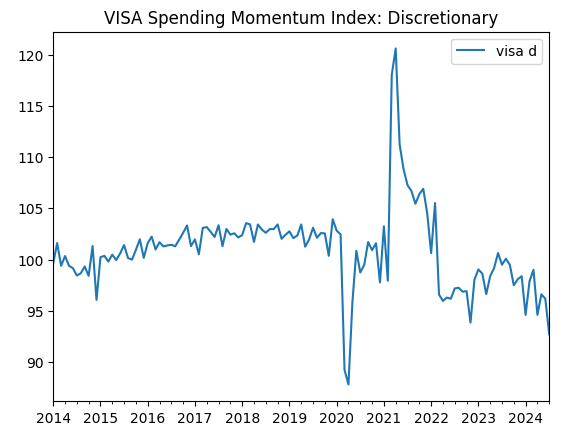
Abb. 1: Der erste VISA-Datensatz
Lassen Sie uns nun den zweiten Datensatz visualisieren.
visa_headline.plot(title="VISA Spending Momentum Index: Headline") 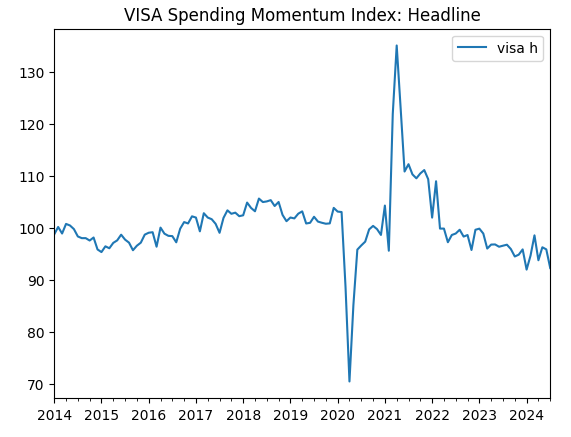
Abb. 2: Der zweite VISA-Datensatz
Und schließlich unser dritter VISA-Datensatz.
visa_non_discretionary.plot(title="VISA Spending Momentum Index: Non-Discretionary") 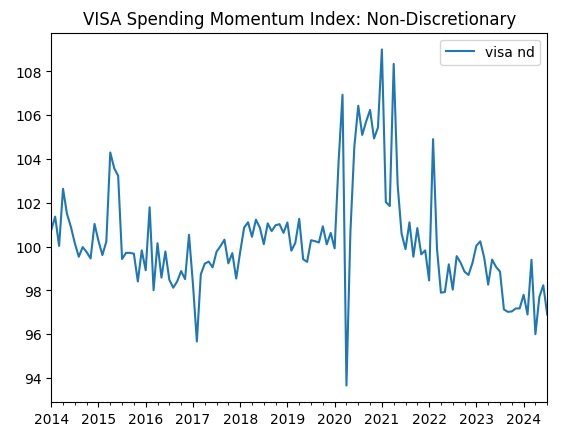
Abb. 3: Der dritte VISA-Datensatz
Die ersten beiden Datensätze scheinen fast identisch zu sein, und wie wir später noch sehen werden, weisen sie Korrelationswerte von 0,89 auf, was bedeutet, dass sie möglicherweise dieselben Informationen enthalten. Dies legt uns nahe, dass wir das eine fallen lassen und das andere behalten können. Wir überlassen es jedoch unserem Algorithmus für die Merkmalsauswahl zu entscheiden, ob dies notwendig ist.
Daten von unserem MetaTrader 5 Terminal abrufen
Wir werden nun unser Terminal initialisieren.
#Initialize the terminal
mt5.initialize()
Jetzt müssen wir unsere Zeitzone angeben.
#Set timezone to UTC timezone = pytz.timezone("Etc/UTC")
Erstellen wir ein Datetime-Objekt.
#Create a 'datetime' object in UTC utc_from = datetime(2024,7,1,tzinfo=timezone)
Abrufen der Daten aus MetaTrader 5 und Einpacken in einen Pandas-Datenrahmen.
#Fetch the data eurusd = pd.DataFrame(mt5.copy_rates_from("EURUSD",mt5.TIMEFRAME_MN1,utc_from,visa_headline.shape[0]))
Wir wollen die Daten beschriften und den Zeitstempel als Index verwenden.
#Label the data eurusd["target"] = np.nan eurusd.loc[eurusd["close"] > eurusd["close"].shift(-look_ahead),"target"] = 0 eurusd.loc[eurusd["close"] < eurusd["close"].shift(-look_ahead),"target"] = 1 eurusd.dropna(inplace=True) eurusd.set_index("time",inplace=True)
Nun werden wir die Datensätze anhand der gemeinsamen Daten zusammenführen.
#Let's merge the datasets merged_data = eurusd.merge(visa_headline,right_index=True,left_index=True) merged_data = merged_data.merge(visa_discretionary,right_index=True,left_index=True) merged_data = merged_data.merge(visa_non_discretionary,right_index=True,left_index=True)
Explorative Datenanalyse
Wir sind bereit, unsere Daten zu untersuchen. Streudiagramme sind hilfreich, um die Beziehung zwischen zwei Variablen zu visualisieren. Betrachten wir die Streudiagramme, die von jedem der VISA-Datensätze erstellt wurden, aufgetragen gegen den Schlusskurs. Die blauen Punkte fassen die Fälle zusammen, in denen der Kurs im Laufe der nächsten 10 Kerzen fiel, während die orangefarbenen Punkte den umgekehrten Fall wiedergeben.
Obwohl die Trennung in der Mitte des Diagramms verrauscht ist, scheint es, dass die VISA-Datensätze auf den extremen Ebenen Auf- und Abwärtsbewegungen recht gut trennen.
#Let's create scatter plots sns.scatterplot(data=merged_data,y="close",x="visa h",hue="target").set(title="EURUSD Close Against VISA Momentum Index: Headline")
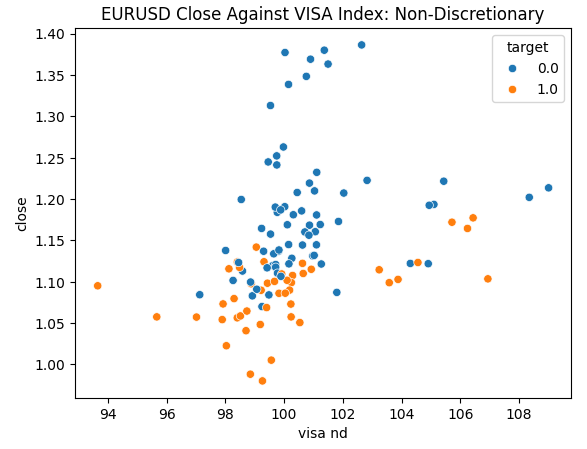
Abb. 4: Darstellung unseres nicht diskretionären VISA-Datensatzes gegen den EURUSD-Schlusskurs
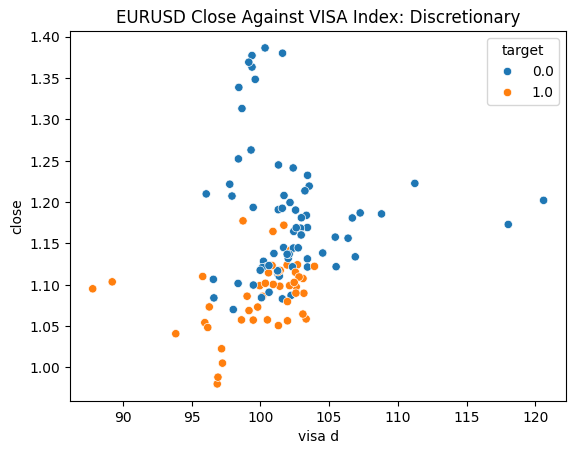
Abb. 5: Aufzeichnung unseres Discretionary VISA-Datensatzes gegen den EURUSD-Schlusskurs
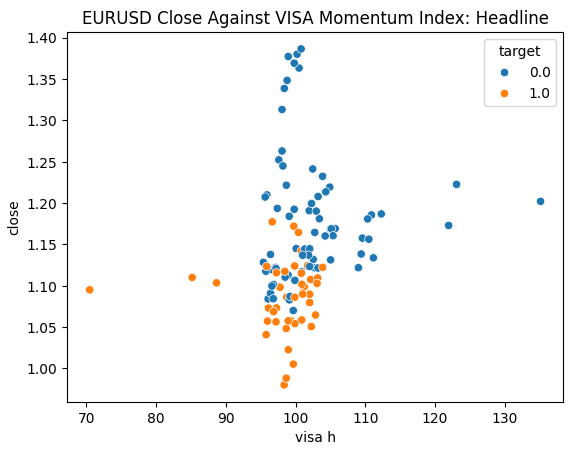
Abb. 6: Darstellung unseres Headline VISA-Datensatzes gegen den EURUSD-Schlusskurs
Die Korrelationsniveaus zwischen den VISA-Datensätzen und dem EURUSD-Markt sind moderat und alle positiv bewertet. Keines der Korrelationsniveaus ist für uns besonders interessant. Es ist jedoch anzumerken, dass der positive Wert darauf hinweist, dass die beiden Variablen dazu neigen, gemeinsam zu steigen und zu fallen. Das entspricht unserem Verständnis von Makroökonomie: Die Verbraucherausgaben in den USA haben einen gewissen Einfluss auf die Wechselkurse. Wenn sich die Verbraucher kollektiv dafür entscheiden, nichts auszugeben, verringert sich die Gesamtwährung im Umlauf, was zu einer Aufwertung des Dollars führen kann.
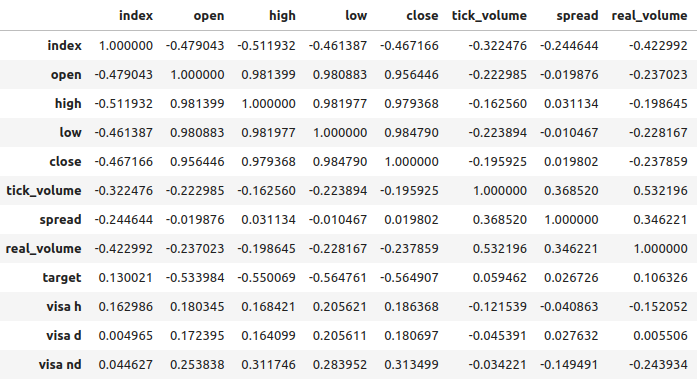
Abb. 7: Korrelationsanalyse unseres Datensatzes
Auswahl der Merkmale
Wie wichtig ist die Beziehung zwischen unserem Ziel und unseren neuen Funktionen? Lassen Sie uns beobachten, ob die neuen Merkmale durch unseren Algorithmus zur Merkmalsauswahl eliminiert werden. Wenn unser Algorithmus keine der neuen Variablen auswählt, kann dies ein Hinweis darauf sein, dass die Beziehung nicht zuverlässig ist.
Der Vorwärtsauswahlalgorithmus beginnt mit einem Nullmodell und fügt ein Merkmal nach dem anderen hinzu, wählt dann das beste Einzelvariablenmodell aus und beginnt dann mit der Suche nach einer zweiten Variablen usw. Er wird das beste Modell, das er gebaut hat, an uns zurückschicken. In unserer Studie wurde nur der Eröffnungskurs vom Algorithmus ausgewählt, was uns zeigt, dass die Beziehung möglicherweise nicht stabil ist.
Importieren wir die benötigten Bibliotheken.
#Let's see which features are the most important from mlxtend.feature_selection import SequentialFeatureSelector as SFS from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs import matplotlib.pyplot as plt
Wir erstellen das Objekt für die Vorwärtsselektion.
#Create the forward selection object sfs = SFS( MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"]), k_features=(1,train_X.shape[1]), forward=False, scoring="accuracy", cv=5 ).fit(train_X,train_y)
Stellen wir die Ergebnisse grafisch dar.
fig1 = plot_sfs(sfs.get_metric_dict(),kind="std_dev") plt.title("Neural Network Backward Feature Selection") plt.grid()
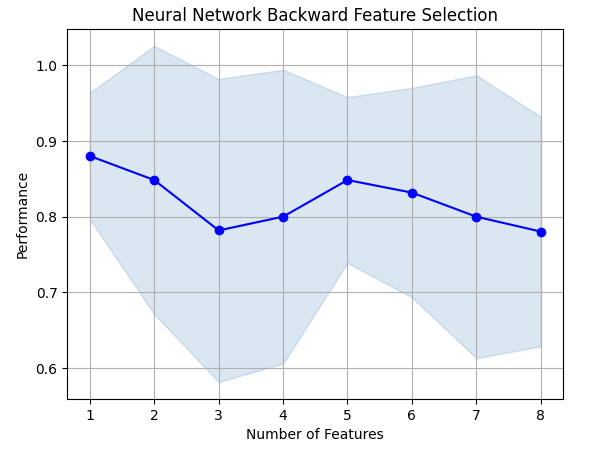
Abb. 8: Als wir die Anzahl der Merkmale im Modell erhöhten, verschlechterte sich unsere Leistung
Leider sank unsere Genauigkeit immer weiter, je mehr Funktionen wir hinzufügten. Das kann entweder bedeuten, dass die Assoziation einfach nicht so stark ist, oder wir legen die Assoziation nicht in einer Weise offen, die unser Modell interpretieren kann. Es sieht also so aus, als ob ein Modell mit 1 Merkmal immer noch in der Lage sein könnte, die Arbeit zu erledigen.
Das beste Merkmal, das wir gefunden haben.
sfs.k_feature_names_
Betrachten wir nun unsere Werte für die gegenseitige (mutual) Information (MI). Die MI-Werte sind positiv bewertet und reichen theoretisch von 0 bis unendlich, aber in der Praxis beobachten wir selten MI-Werte über 2 und ein MI-Wert über 1 ist gut.
Importieren wir den MI-Klassifikator aus scikit-learn.
#Mutual information
from sklearn.feature_selection import mutual_info_classif Der MI-Score für den Headline-Datensatz.
#Mutual information from the headline visa dataset, print(f"VISA Headline dataset has a mutual info score of: {mutual_info_classif(train_X.loc[:,['visa h']],train_y)[0]}")
Der MI-Score für den Datensatz Discretionary.
#Mutual information from the second visa dataset, print(f"VISA Discretionary dataset has a mutual info score of: {mutual_info_classif(train_X.loc[:,['visa d']],train_y)[0]}")
Alle unsere Datensätze wiesen schlechte MI-Werte auf. Dies könnte ein zwingender Grund dafür sein, verschiedene Transformationen auf den VISA-Datensatz anzuwenden, um hoffentlich eine stärkere Assoziation aufzudecken.
Einstellen der Parameter
Versuchen wir nun, unser tiefes neuronales Netzwerk so einzustellen, dass es den EURUSD prognostiziert. Zuvor müssen wir unsere Daten skalieren. Zunächst setzen wir den Index des zusammengeführten Datensatzes zurück
#Reset the index
merged_data.reset_index(inplace=True)
und definieren das Ziel und die Prädiktoren.
#Define the target target = "target" ohlc_predictors = ["open","high","low","close","tick_volume"] visa_predictors = ["visa d","visa h","visa nd"] all_predictors = ohlc_predictors + visa_predictors
Jetzt werden wir unsere Daten skalieren und transformieren. Von jedem Wert in unserem Datensatz subtrahieren wir den Mittelwert und teilen ihn durch die Standardabweichung der jeweiligen Spalte. Es ist zu beachten, dass diese Transformation empfindlich auf Ausreißer reagiert.
#Let's scale the data scale_factors = pd.DataFrame(index=["mean","standard deviation"],columns=all_predictors) for i in np.arange(0,len(all_predictors)): #Store the mean and standard deviation for each column scale_factors.iloc[0,i] = merged_data.loc[:,all_predictors[i]].mean() scale_factors.iloc[1,i] = merged_data.loc[:,all_predictors[i]].std() merged_data.loc[:,all_predictors[i]] = ((merged_data.loc[:,all_predictors[i]] - scale_factors.iloc[0,i]) / scale_factors.iloc[1,i]) scale_factors
Ein Blick auf die skalierten Daten.
#Let's see the normalized data merged_data
Importieren der Standardbibliotheken.
#Lets try to train a deep neural network to uncover relationships in the data from sklearn.neural_network import MLPClassifier from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
Erstellen einer Aufteilung in Trainings und Test.
#Create train test partitions for our alternative data train_X,test_X,train_y,test_y = train_test_split(merged_data.loc[:,all_predictors],merged_data.loc[:,"target"],test_size=0.5,shuffle=False)
Anpassung des Modells an die verfügbaren Eingaben. Erinnern Sie sich daran, dass wir zuerst das Modell übergeben müssen, das wir abstimmen wollen, und dann die Parameter des Modells angeben, an dem wir interessiert sind. Danach müssen wir angeben, wie viele Faltungen wir für die Kreuzvalidierung verwenden wollen.
tuner = RandomizedSearchCV(MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False), { "activation": ["relu","identity","logistic","tanh"], "solver": ["lbfgs","adam","sgd"], "alpha": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], "learning_rate": ["constant", "invscaling", "adaptive"], "learning_rate_init": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], }, cv=5, n_iter=1000, scoring="accuracy", return_train_score=False )
Einbau des „tuners“.
tuner.fit(train_X,train_y)
Sehen wir uns die Ergebnisse an, die mit den Trainingsdaten erzielt wurden, in der Reihenfolge vom besten zum schlechtesten Ergebnis.
tuner_results = pd.DataFrame(tuner.cv_results_) params = ["param_activation","param_solver","param_alpha","param_learning_rate","param_learning_rate_init","mean_test_score"] tuner_results.loc[:,params].sort_values(by="mean_test_score",ascending=False)

Abb. 9: Unsere Optimierungsergebnisse
Unsere höchste Genauigkeit betrug 88 % bei den Trainingsdaten. Beachten Sie, dass es aufgrund der stochastischen Natur des von uns gewählten Optimierungsalgorithmus schwierig sein kann, die in dieser Demonstration erzielten Ergebnisse zu reproduzieren.
Testen auf Überanpassung
Vergleichen wir nun unsere Standard- und angepassten Modelle, um zu sehen, ob wir die Trainingsdaten zu gut anpassen. Bei einer Überanpassung wird das Standardmodell unser angepasstes Modell in der Validierungsmenge übertreffen, andernfalls wird unser angepasstes Modell besser abschneiden.
Bereiten wir die 2 Modelle vor.
#Let's compare the default model and our customized model on the hold out set default_model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False) customized_model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"])
Wir messen die Genauigkeit des Standardmodells.
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
accuracy_score(test_y,default_model.predict(test_X))
Die Genauigkeit unseres angepassten Modells.
#The accuracy of the defualt model
customized_model.fit(train_X,train_y)
accuracy_score(test_y,customized_model.predict(test_X))
Es scheint, dass wir das Modell ohne Überanpassung an die Trainingsdaten trainiert haben. Beachten Sie auch, dass unser Trainingsfehler in der Regel immer höher ist als unser Testfehler, die Diskrepanz zwischen ihnen sollte jedoch nicht zu groß sein. Unser Trainingsfehler lag bei 88 % und der Testfehler bei 74 %, was angemessen ist. Eine große Diskrepanz zwischen dem Trainings- und dem Testfehler wäre alarmierend, denn sie könnte darauf hindeuten, dass wir uns zu sehr angepasst haben!
Umsetzung der Strategie
Zunächst definieren wir globale Variablen, die wir verwenden werden.
#Let us now start building our trading strategy SYMBOL = 'EURUSD' TIMEFRAME = mt5.TIMEFRAME_MN1 DEVIATION = 1000 VOLUME = 0 LOT_MULTIPLE = 1
Initialisieren wir nun unser MetaTrader 5 Terminal.
#Get the system up
if not mt5.initialize():
print('Failed To Log in')
Jetzt müssen wir mehr Details über den Markt wissen.
#Let's fetch the trading volume
for index,symbol in enumerate(mt5.symbols_get()):
if symbol.name == SYMBOL:
print(f"{symbol.name} has minimum volume: {symbol.volume_min}")
VOLUME = symbol.volume_min * LOT_MULTIPLE
Diese Funktion ermittelt den aktuellen Marktpreis für uns.
#A function to get current prices def get_prices(): start = datetime(2024,1,1) end = datetime.now() data = pd.DataFrame(mt5.copy_rates_range(SYMBOL,TIMEFRAME,start,end)) data['time'] = pd.to_datetime(data['time'],unit='s') data.set_index('time',inplace=True) return(data.iloc[-1,:])
Erstellen wir auch eine Funktion, um die neuesten alternativen Daten von der FRED-API abzurufen.
#A function to get our alternative data def get_alternative_data(): visa_d = fred.get_series_as_of_date("VISASMIDSA",datetime.now()) visa_d = visa_d.iloc[-1,-1] visa_h = fred.get_series_as_of_date("VISASMIHSA",datetime.now()) visa_h = visa_h.iloc[-1,-1] visa_n = fred.get_series_as_of_date("VISASMINSA",datetime.now()) visa_n = visa_n.iloc[-1,-1] return(visa_d,visa_h,visa_n)
Wir brauchen eine Funktion, die für die Normalisierung und Skalierung unserer Eingaben verantwortlich ist.
#A function to prepare the inputs for our model def get_model_inputs(): LAST_OHLC = get_prices() visa_d , visa_h , visa_n = get_alternative_data() return( np.array([[ ((LAST_OHLC['open'] - scale_factors.iloc[0,0]) / scale_factors.iloc[1,0]), ((LAST_OHLC['high'] - scale_factors.iloc[0,1]) / scale_factors.iloc[1,1]), ((LAST_OHLC['low'] - scale_factors.iloc[0,2]) / scale_factors.iloc[1,2]), ((LAST_OHLC['close'] - scale_factors.iloc[0,3]) / scale_factors.iloc[1,3]), ((LAST_OHLC['tick_volume'] - scale_factors.iloc[0,4]) / scale_factors.iloc[1,4]), ((visa_d - scale_factors.iloc[0,5]) / scale_factors.iloc[1,5]), ((visa_h - scale_factors.iloc[0,6]) / scale_factors.iloc[1,6]), ((visa_n - scale_factors.iloc[0,7]) / scale_factors.iloc[1,7]) ]]) )
Wir wollen unser Modell mit allen Daten trainieren, die wir haben.
#Let's train our model on all the data we have model = MLPClassifier(hidden_layer_sizes=(20,10,4),shuffle=False,activation="logistic",solver="lbfgs",alpha=0.00001,learning_rate="constant",learning_rate_init=0.00001) model.fit(merged_data.loc[:,all_predictors],merged_data.loc[:,"target"])
Diese Funktion liefert eine Vorhersage aus unserem Modell.
#A function to get a prediction from our model def ai_forecast(): model_inputs = get_model_inputs() prediction = model.predict(model_inputs) return(prediction[0])
Damit sind wir beim Kernstück unseres Algorithmus angelangt. Zunächst prüfen wir, wie viele Stellen wir offen haben. Dann erhalten wir eine Vorhersage von unserem Modell. Wenn wir keine offenen Positionen haben, werden wir die Prognose unseres Modells nutzen, um eine Position zu eröffnen. Andernfalls werden wir die Prognose unseres Modells als Ausstiegssignal verwenden, wenn wir Positionen offen haben.
while True: #Get data on the current state of our terminal and our portfolio positions = mt5.positions_total() forecast = ai_forecast() BUY_STATE , SELL_STATE = False , False #Interpret the model's forecast if(forecast == 0.0): SELL_STATE = True BUY_STATE = False elif(forecast == 1.0): SELL_STATE = False BUY_STATE = True print(f"Our forecast is {forecast}") #If we have no open positions let's open them if(positions == 0): print(f"We have {positions} open trade(s)") if(SELL_STATE): print("Opening a sell position") mt5.Sell(SYMBOL,VOLUME) elif(BUY_STATE): print("Opening a buy position") mt5.Buy(SYMBOL,VOLUME) #If we have open positions let's manage them if(positions > 0): print(f"We have {positions} open trade(s)") for pos in mt5.positions_get(): if(pos.type == 1): if(BUY_STATE): print("Closing all sell positions") mt5.Close(SYMBOL) if(pos.type == 0): if(SELL_STATE): print("Closing all buy positions") mt5.Close(SYMBOL) #If we have finished all checks then we can wait for one day before checking our positions again time.sleep(24 * 60 * 60)
We have 0 open trade(s)
Opening a sell position
Implementation in MQL5
Um unsere Strategie in MQL5 zu implementieren, müssen wir zunächst unsere Modelle in das Format Open Neural Network Exchange (ONNX) exportieren. ONNX ist ein Protokoll zur Darstellung von Modellen des maschinellen Lernens als eine Kombination aus Graph und Kanten. Dieses standardisierte Protokoll ermöglicht es Entwicklern, Modelle für maschinelles Lernen mit verschiedenen Programmiersprachen zu erstellen und einzusetzen. Leider werden nicht alle Modelle und Frameworks für maschinelles Lernen vollständig von der aktuellen ONNX-API unterstützt.
Für den Anfang werden wir einige Bibliotheken importieren.
#Import the libraries we need import pandas as pd import numpy as np from fredapi import Fred import MetaTrader5 as mt5 from datetime import datetime import time import pytz
Dann müssen wir unseren FRED-API-Schlüssel eingeben, um Zugriff auf die benötigten Daten zu erhalten.
#Let's setup our FredAPI
fred = Fred(api_key="")
visa_discretionary = pd.DataFrame(fred.get_series("VISASMIDSA"),columns=["visa d"])
visa_headline = pd.DataFrame(fred.get_series("VISASMIHSA"),columns=["visa h"])
visa_non_discretionary = pd.DataFrame(fred.get_series("VISASMINSA"),columns=["visa nd"])
Beachten Sie, dass wir nach dem Abruf der Daten eine Skalierung nach dem gleichen Format wie oben beschrieben vorgenommen haben. Wir haben diese Schritte weggelassen, um Wiederholungen derselben Informationen zu vermeiden. Der einzige kleine Unterschied besteht darin, dass wir das Modell jetzt so trainieren, dass es den tatsächlichen Schlusskurs vorhersagt und nicht nur ein binäres Ziel.
Nachdem wir die Daten skaliert haben, wollen wir nun versuchen, die Parameter unseres Modells abzustimmen.
#A few more libraries we need from sklearn.neural_network import MLPRegressor from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error
Wir müssen unsere Daten so aufteilen, dass wir einen Trainingssatz für die Optimierung des Modells und einen Validierungssatz haben, mit dem wir auf Überanpassung testen.
#Create train test partitions for our alternative data train_X,test_X,train_y,test_y = train_test_split(merged_data.loc[:,all_predictors],merged_data.loc[:,"close target"],test_size=0.5,shuffle=False)
Wir führen nun die Abstimmung der Hyperparameter durch. Beachten Sie, dass wir die Bewertungsmetrik auf „neg mean squared error“ (negierter mittlerer quadratischer Fehler) eingestellt haben, diese Bewertungsmetrik identifiziert das Modell mit dem niedrigsten MSE als das leistungsstärkste Modell.
tuner = RandomizedSearchCV(MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False,early_stopping=True), { "activation": ["relu","identity","logistic","tanh"], "solver": ["lbfgs","adam","sgd"], "alpha": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], "learning_rate": ["constant", "invscaling", "adaptive"], "learning_rate_init": [0.1,0.01,0.001,(10.0 ** -4),(10.0 ** -5),(10.0 ** -6),(10.0 ** -7),(10.0 ** -8),(10.0 ** -9)], }, cv=5, n_iter=1000, scoring="neg_mean_squared_error", return_train_score=False, n_jobs=-1 )
Anpassen des „tuner“-Objekts.
tuner.fit(train_X,train_y)
Testen wir nun auf Überanpassung.
#Let's compare the default model and our customized model on the hold out set default_model = MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False) customized_model = MLPRegressor(hidden_layer_sizes=(20,10,4),shuffle=False,activation=tuner.best_params_["activation"],solver=tuner.best_params_["solver"],alpha=tuner.best_params_["alpha"],learning_rate=tuner.best_params_["learning_rate"],learning_rate_init=tuner.best_params_["learning_rate_init"])
Die Genauigkeit unseres Standardmodells.
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
mean_squared_error(test_y,default_model.predict(test_X))
Es ist uns gelungen, unser Standardmodell auf der ausgeklammerten Validierungsmenge zu übertreffen, was ein gutes Zeichen dafür ist, dass wir nicht überangepasst sind.
#The accuracy of the defualt model
default_model.fit(train_X,train_y)
mean_squared_error(test_y,default_model.predict(test_X))
0.006138795093781729
Passen wir das angepasste Modell an alle Daten an, die wir haben, bevor wir es ins ONNX-Format exportieren.
#Fit the model on all the data we have
customized_model.fit(test_X,test_y)
Importieren von ONNX-Konvertierungsbibliotheken.
#Convert to ONNX
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx import convert_sklearn
import netron
import onnx Definieren wir den Eingabetyp und die Form unseres Modells,
#Define the initial types initial_types = [("float_input",FloatTensorType([1,train_X.shape[1]]))]
erstellen eine ONNX-Darstellung des Modells im Speicher,
#Create the onnx representation onnx_model = convert_sklearn(customized_model,initial_types=initial_types,target_opset=12)
speichern die ONNX-Darstellung auf der Festplatte,
#Save the ONNX model onnx_model_name = "EURUSD VISA MN1 FLOAT.onnx" onnx.save(onnx_model,onnx_model_name)
und schauen uns das ONNX-Modell mit netron an.
#View the ONNX model
netron.start(onnx_model_name) 
Abb. 10: Unser tiefes neuronales Netz im ONNX-Format

Abb. 11: Metadetails unseres ONNX-Modells
Wir sind fast bereit, mit dem Aufbau unseres Expert Advisors zu beginnen. Zunächst müssen wir jedoch einen Python-Hintergrunddienst erstellen, der die Daten von FRED abruft und an unser Programm weiterleitet.
Zunächst importieren wir die benötigten Bibliotheken.
#Import the libraries we need import pandas as pd import numpy as np from fredapi import Fred from datetime import datetime
Dann melden wir uns mit unseren FRED-Anmeldedaten an.
#Let's setup our FredAPI fred = Fred(api_key="")
Wir müssen eine Funktion definieren, die die Daten für uns abruft und sie in CSV ausgibt.
#A function to write out our alternative data to CSV def write_out_alternative_data(): visa_d = fred.get_series_as_of_date("VISASMIDSA",datetime.now()) visa_d = visa_d.iloc[-1,-1] visa_h = fred.get_series_as_of_date("VISASMIHSA",datetime.now()) visa_h = visa_h.iloc[-1,-1] visa_n = fred.get_series_as_of_date("VISASMINSA",datetime.now()) visa_n = visa_n.iloc[-1,-1] data = pd.DataFrame(np.array([visa_d,visa_h,visa_n]),columns=["Data"],index=["Discretionary","Headline","Non-Discretionary"]) data.to_csv("C:\\Users\\Westwood\\AppData\\Roaming\\MetaQuotes\\Terminal\\D0E8209F77C8CF37AD8BF550E51FF075\\MQL5\\Files\\fred_visa.csv")
Nun müssen wir eine Schleife schreiben, die einmal am Tag nach neuen Daten sucht und unsere CSV-Datei aktualisiert.
while True: #Update the fred data for our MT5 EA write_out_alternative_data() #If we have finished all checks then we can wait for one day before checking for new data time.sleep(24 * 60 * 60)Da wir nun Zugang zu den neuesten FRED-Daten haben, können wir mit dem Aufbau unseres Expert Advisors beginnen.
We will first load our ONNX model as a resource into our application. //+------------------------------------------------------------------+ //| VISA EA.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Resorces | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD VISA MN1 FLOAT.onnx" as const uchar onnx_buffer[];
Dann laden wir die Handelsbibliothek, die uns bei der Eröffnung und Verwaltung unserer Positionen hilft.
//+------------------------------------------------------------------+ //| Libraries we need | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
So weit, unsere Anwendung kommt gut zusammen, lassen Sie uns globale Variablen erstellen, die wir in verschiedenen Blöcken unserer Anwendung verwenden werden.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; double mean_values[8],std_values[8]; float visa_data[3]; vector model_forecast = vector::Zeros(1); double trading_volume = 0.3; int state = 0;
Bevor wir mit unserem ONNX-Modell beginnen können, müssen wir zunächst das ONNX-Modell aus der Ressource erstellen, die wir zu Beginn des Programms benötigt haben. Danach müssen wir die Eingangs- und Ausgangsformen des Modells definieren.
//+------------------------------------------------------------------+ //| Load the ONNX model | //+------------------------------------------------------------------+ bool load_onnx_model(void) { //--- Try create the ONNX model from the buffer we have onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Validate the model if(onnx_model == INVALID_HANDLE) { Comment("Failed to create the ONNX model. ",GetLastError()); return(false); } //--- Set the I/O shape ulong input_shape[] = {1,8}; ulong output_shape[] = {1,1}; //--- Validate the I/O shapes if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set the ONNX model input shape. ",GetLastError()); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set the ONNX model output shape. ",GetLastError()); return(false); } return(true); }
Erinnern Sie sich daran, dass wir unsere Daten standardisiert haben, indem wir den Spaltenmittelwert abgezogen und durch die Standardabweichung der einzelnen Spalten geteilt haben. Wir müssen diese Werte im Speicher ablegen. Da sich diese Werte nie ändern werden, habe ich sie einfach fest in das Programm programmiert.
//+------------------------------------------------------------------+ //| Mean & Standard deviation values | //+------------------------------------------------------------------+ void load_scaling_values(void) { //--- Mean & standard deviation values for the EURUSD OHLCV mean_values[0] = 1.146552; std_values[0] = 0.08293; mean_values[1] = 1.165568; std_values[1] = 0.079657; mean_values[2] = 1.125744; std_values[2] = 0.083896; mean_values[3] = 1.143834; std_values[3] = 0.080655; mean_values[4] = 1883520.051282; std_values[4] = 826680.767222; //--- Mean & standard deviation values for the VISA datasets mean_values[5] = 101.271017; std_values[5] = 3.981438; mean_values[6] = 100.848506; std_values[6] = 6.565229; mean_values[7] = 100.477269; std_values[7] = 2.367663; }
Der Python-Hintergrunddienst, den wir erstellt haben, wird uns immer die neuesten verfügbaren Daten liefern. Lassen Sie uns eine Funktion zum Lesen dieser CSV-Datei erstellen und die Werte in einem Array für uns speichern.
//+-------------------------------------------------------------------+ //| Read in the VISA data | //+-------------------------------------------------------------------+ void read_visa_data(void) { //--- Read in the file string file_name = "fred_visa.csv"; //--- Try open the file int result = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI,","); //Strings of ANSI type (one byte symbols). //--- Check the result if(result != INVALID_HANDLE) { Print("Opened the file"); //--- Store the values of the file int counter = 0; string value = ""; while(!FileIsEnding(result) && !IsStopped()) //read the entire csv file to the end { if(counter > 10) //if you aim to read 10 values set a break point after 10 elements have been read break; //stop the reading progress value = FileReadString(result); Print("Trying to read string: ",value); if(counter == 3) { Print("Discretionary data: ",value); visa_data[0] = (float) value; } if(counter == 5) { Print("Headline data: ",value); visa_data[1] = (float) value; } if(counter == 7) { Print("Non-Discretionary data: ",value); visa_data[2] = (float) value; } if(FileIsLineEnding(result)) { Print("row++"); } counter++; } //--- Show the VISA data Print("VISA DATA: "); ArrayPrint(visa_data); //---Close the file FileClose(result); } }
Schließlich müssen wir eine Funktion definieren, die für die Vorhersagen unseres Modells verantwortlich ist. Zunächst speichern wir die aktuellen Eingaben in einem Float-Vektor, da unser Modell den Eingabetyp float hat, den wir bei der Erstellung der ONNX-Ausgangstypen definiert haben.
Erinnern Sie sich daran, dass wir jeden Eingabewert skalieren müssen, indem wir den Spaltenmittelwert subtrahieren und durch die Spaltenstandardabweichung dividieren, bevor wir die Eingaben an unser Modell weitergeben.
//+--------------------------------------------------------------+ //| Get a prediction from our model | //+--------------------------------------------------------------+ void model_predict(void) { //--- Fetch input data read_visa_data(); vectorf input_data = {(float)iOpen("EURUSD",PERIOD_MN1,0), (float)iHigh("EURUSD",PERIOD_MN1,0), (float)iLow("EURUSD",PERIOD_MN1,0), (float)iClose("EURUSD",PERIOD_MN1,0), (float)iTickVolume("EURUSD",PERIOD_MN1,0), (float)visa_data[0], (float)visa_data[1], (float)visa_data[2] }; //--- Scale the data for(int i =0; i < 8;i++) { input_data[i] = (float)((input_data[i] - mean_values[i])/std_values[i]); } //--- Show the input data Print("Input data: ",input_data); //--- Obtain a forecast OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT|ONNX_DEFAULT,input_data,model_forecast); } //+------------------------------------------------------------------+
Definieren wir nun die Initialisierungsprozedur. Wir beginnen mit dem Laden unseres ONNX-Modells, lesen dann den VISA-Datensatz ein und laden schließlich unsere Skalierungswerte.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Load the ONNX file if(!load_onnx_model()) { //--- We failed to load the ONNX model return(INIT_FAILED); } //--- Read the VISA data read_visa_data(); //--- Load scaling values load_scaling_values(); //--- We were successful return(INIT_SUCCEEDED); }
Wenn unser Programm nicht mehr genutzt wird, sollten wir die nicht mehr benötigten Ressourcen freigeben.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up the resources we don't need OnnxRelease(onnx_model); ExpertRemove(); }
Immer wenn neue Preisdaten verfügbar sind, holen wir zunächst eine Vorhersage aus unserem Modell. Wenn wir keine offenen Positionen haben, folgen wir dem von unserem Modell generierten Einstieg. Wenn wir offene Positionen haben, nutzen wir unser KI-Modell, um potenzielle Kursumschwünge im Voraus zu erkennen.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Get a prediction from our model model_predict(); Comment("Model forecast: ",model_forecast[0]); //--- Check if we have any positions if(PositionsTotal() == 0) { //--- Note that we have no trades open state = 0; //--- Find an entry and take note if(model_forecast[0] < iClose(_Symbol,PERIOD_CURRENT,0)) { Trade.Sell(trading_volume,_Symbol,SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,"Gain an Edge VISA"); state = 1; } if(model_forecast[0] > iClose(_Symbol,PERIOD_CURRENT,0)) { Trade.Buy(trading_volume,_Symbol,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,"Gain an Edge VISA"); state = 2; } } //--- If we have positions open, check for reversals if(PositionsTotal() > 0) { if(((state == 1) && (model_forecast[0] > iClose(_Symbol,PERIOD_CURRENT,0))) || ((state == 2) && (model_forecast[0] < iClose(_Symbol,PERIOD_CURRENT,0)))) { Alert("Reversal detected, closing positions now"); Trade.PositionClose(_Symbol); } } } //+------------------------------------------------------------------+

Abb. 12: Unser VISA-Experten-Ratgeber

Abb. 13: Beispielhafte Ausgabe unseres Programms

Abb. 14: Unser Programm in Aktion
Schlussfolgerung
In diesem Artikel haben wir gezeigt, wie Sie Daten auswählen können, die für Ihre Handelsstrategie hilfreich sein können. Wir haben erörtert, wie Sie die potenzielle Stärke Ihrer alternativen Daten messen und wie Sie Ihre Modelle optimieren können, um so viel Leistung wie möglich zu erzielen, ohne sich zu sehr anzupassen. Es gibt potenziell Hunderttausende von Datensätzen, die erforscht werden können, und wir sind bestrebt, Ihnen dabei zu helfen, die informativsten zu finden.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/15575
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Vielen Dank, Gamu
Toller Artikel, danke fürs Teilen!!
Nochmals vielen Dank, Gamu. Gut geschrieben wie immer. Eine großartig kommentierte Vorlage, wie man visualisiert, skaliert, testet, auf Überanpassung prüft, einen Datafeed implementiert, ein Handelssystem aus einem Datensatz vorhersagt und implementiert. Fantastisch, sehr geschätzt