
Engenharia de Recursos com Python e MQL5 (Parte II): Ângulo de Preço

Modelos de aprendizado de máquina são instrumentos muito sensíveis. Nesta série de artigos, daremos atenção significativa a como as transformações que aplicamos aos nossos dados afetam o desempenho do modelo. Da mesma forma, nossos modelos também são sensíveis à forma como a relação entre entrada e alvo é transmitida. Isso significa que talvez precisemos criar novos recursos a partir dos dados disponíveis para que o modelo aprenda de forma eficaz.
Não há limite para quantos novos recursos podemos criar a partir de nossos dados de mercado. As transformações aplicadas aos dados de mercado — e os novos recursos derivados deles — alterarão nossos níveis de erro. Nosso objetivo é ajudá-lo a identificar quais transformações e técnicas de engenharia de features reduzirão os erros em direção a 0. Além disso, você também observará que cada modelo é afetado de forma diferente pelas mesmas transformações. Portanto, este artigo também irá orientá-lo sobre quais transformações escolher, dependendo da arquitetura do modelo em uso.
Visão Geral da Estratégia de Trading
Se você pesquisar no Fórum MQL5, encontrará muitos posts perguntando como calcular o ângulo formado pelas mudanças nos níveis de preço. A intuição é que tendências de baixa resultam em ângulos negativos, enquanto tendências de alta resultam em ângulos maiores que 0. Embora a ideia seja fácil de entender, implementá-la não é igualmente simples. Há muitos obstáculos a serem superados por membros da comunidade interessados em construir uma estratégia que incorpore o ângulo do preço. Este artigo destacará alguns dos principais problemas a serem tratados antes de considerar investir capital de forma plena. Além disso, não vamos apenas criticar as falhas da estratégia, mas também sugerir soluções possíveis para melhorá-la.
A ideia por trás do cálculo do ângulo do preço é que ele serve como uma fonte de confirmação. Traders normalmente utilizam linhas de tendência para identificar a tendência dominante do mercado. Linhas de tendência geralmente conectam 2 ou 3 pontos extremos de preço com uma linha reta. Se o preço rompe acima da linha de tendência, alguns traders veem isso como sinal de força de mercado e entram na tendência naquele ponto. Por outro lado, se o preço rompe a linha em direção oposta, isso pode ser percebido como sinal de fraqueza e que a tendência está se esgotando.
Uma limitação fundamental das linhas de tendência é que elas são definidas de forma subjetiva. Portanto, um trader pode ajustar arbitrariamente suas linhas de tendência para criar uma análise que apoie sua perspectiva, mesmo que sua perspectiva esteja errada. Portanto, é natural tentar definir linhas de tendência de uma forma mais robusta. A maioria dos traders espera fazer isso calculando a inclinação criada por mudanças nos níveis de preço. A suposição fundamental é que, conhecer a inclinação é equivalente a conhecer a direção da linha de tendência formada pela ação de preço.
Agora chegamos ao primeiro obstáculo a ser superado: definir a inclinação. A maioria dos traders tenta definir a inclinação criada pelo preço como a diferença no preço dividida pela diferença no tempo. Existem várias limitações nessa abordagem. Primeiramente, os mercados de ações ficam fechados durante o fim de semana. Em nossos terminais MetaTrader 5, o tempo que passou enquanto os mercados estavam fechados não é registrado, ele deve ser inferido a partir dos dados disponíveis. Portanto, ao usar um modelo tão simples, devemos ter em mente que o modelo não leva em conta o tempo decorrido durante o fim de semana. Isso significa que, se os níveis de preço apresentarem gap durante o fim de semana, então nossa estimativa da inclinação será inflada.
Deve ser imediatamente óbvio que a inclinação calculada pela nossa abordagem atual será muito sensível à nossa representação do tempo. Se escolhermos ignorar o tempo que passou durante o fim de semana, como afirmamos anteriormente, obteremos coeficientes inflados. E se considerarmos o tempo durante o fim de semana, obteremos coeficientes relativamente menores. Portanto, sob o nosso modelo atual, é possível obter 2 cálculos diferentes de inclinação ao analisar os mesmos dados. Isso é indesejável. Preferiríamos que nosso cálculo fosse determinístico. Ou seja, nosso cálculo da inclinação será sempre o mesmo, se estivermos analisando os mesmos dados.
Para superar essas limitações, gostaria de propor um cálculo alternativo. Poderíamos, em vez disso, calcular a inclinação formada pelo preço usando a diferença no preço de abertura dividida pela diferença no preço de fechamento. Substituímos o tempo do eixo x. Essa nova quantidade nos informa quão sensível o preço de fechamento é a mudanças no preço de abertura. Se o valor absoluto dessa quantidade for > 1, isso nos diz que grandes mudanças no preço de abertura têm pouco efeito no preço de fechamento. Da mesma forma, se o valor absoluto da quantidade for < 1, isso nos informa que pequenas mudanças no preço de abertura podem ter grandes efeitos no preço de fechamento. Além disso, se o coeficiente da inclinação for negativo, isso nos informa que o preço de abertura e o preço de fechamento tendem a mudar em direções opostas.
No entanto, essa nova quantidade tem seu próprio conjunto de limitações. Uma de particular interesse para nós, como traders, é que nossa nova métrica é sensível a candles Doji. Candles Doji são formados quando o preço de abertura e o preço de fechamento de um candle estão muito próximos um do outro. O problema é agravado quando temos um agrupamento de candles Doji, como mostrado na Fig 1 abaixo. No melhor cenário, esses candles Doji poderiam fazer com que nossos cálculos resultassem em 0 ou infinito. No entanto, no pior cenário, poderíamos obter erros de tempo de execução porque poderíamos tentar dividir por 0.
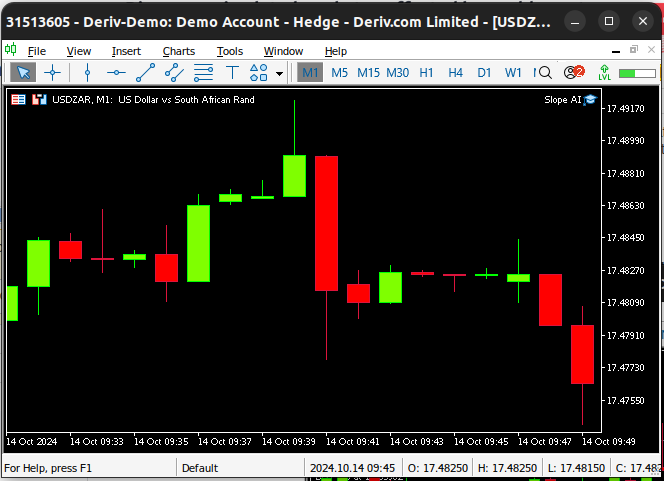
Fig 1: Um agrupamento de candles Doji
Visão Geral da Metodologia
Analisamos 10 000 linhas de dados M1 do par USDZAR. Os dados foram buscados em nosso terminal MetaTrader 5, usando um script MQL5. Primeiro, calculamos a inclinação usando a fórmula que sugerimos anteriormente. Para calcular o ângulo da inclinação, usamos o inverso da função trigonométrica tangente, arc-tan. A quantidade que calculamos exibiu níveis baixos de correlação com nossas cotações de mercado.
Embora nossos níveis de correlação não tenham sido animadores, prosseguimos para treinar uma seleção de 12 modelos diferentes de IA para prever o valor futuro da taxa de câmbio USDZAR, em 3 grupos de dados de entrada:
- Cotações OHLC do nosso terminal MetaTrader 5
- Ângulo e inclinação criados pelo preço
- Uma combinação de todos os 3.
Nosso modelo de melhor desempenho foi a regressão linear simples, usando OHLC. Embora valha a pena notar que a precisão do modelo linear permaneceu a mesma quando trocamos suas entradas do grupo 1 para o grupo 3. Nenhum dos modelos que observamos teve desempenho melhor no grupo 2 do que no grupo 1. No entanto, apenas 2 dos modelos que examinamos tiveram melhor desempenho quando usaram todos os dados disponíveis. O desempenho do algoritmo KNeighbors melhorou em 20% graças às nossas novas features. Essa observação nos leva a questionar quais outros aprimoramentos podemos obter ao realizar outras transformações úteis em nossos dados.
Ajustamos com sucesso os parâmetros do modelo KNeighbors sem overfitting dos dados de treinamento e exportamos nosso modelo para o formato ONNX para ser incluído em nosso Expert Advisor com IA.
Buscando os Dados que Precisamos
O script abaixo buscará os dados de que precisamos em nosso terminal MetaTrader 5 e os salvará em formato CSV para nós. Basta arrastar e soltar o script em qualquer mercado que você deseja analisar, e você poderá nos acompanhar.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- File name string file_name = "Market Data " + Symbol() +".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Análise Exploratória dos Dados
Para começar nossa análise, vamos primeiro importar as bibliotecas de que precisamos.
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
Agora vamos ler os dados de mercado.
#Read in the data data = pd.read_csv("Market Data USDZAR.csv")
Nossos dados estão organizados na ordem errada, inverta-os.
#The data is in reverse order, correct that data = data[::-1]
Defina até onde no futuro desejamos prever.
#Define the forecast horizon look_ahead = 20
Vamos aplicar o cálculo da inclinação. Infelizmente, nossos cálculos de inclinação nem sempre resultam em um número real. Essa é uma das limitações da versão atual do nosso algoritmo. Lembre-se, devemos chegar a uma decisão sobre como lidaremos com os valores ausentes em nosso data frame. Por enquanto, vamos excluir todos os valores ausentes no data frame.
#Calculate the angle formed by the changes in price, using a ratio of high and low price. #Then calculate arctan to realize the angle formed by the changes in pirce data["Slope"] = (data["Close"] - data["Close"].shift(look_ahead))/(data["Open"] - data["Open"].shift(look_ahead)) data["Angle"] = np.arctan(data["Slope"]) data.describe()
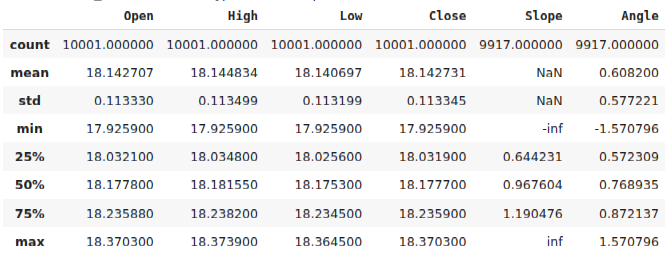
Fig 2: Nosso data frame após calcular o ângulo criado pelo preço
Vamos ampliar os casos em que nosso cálculo da inclinação resultou em infinito.
data.loc[data["Slope"] == np.inf] 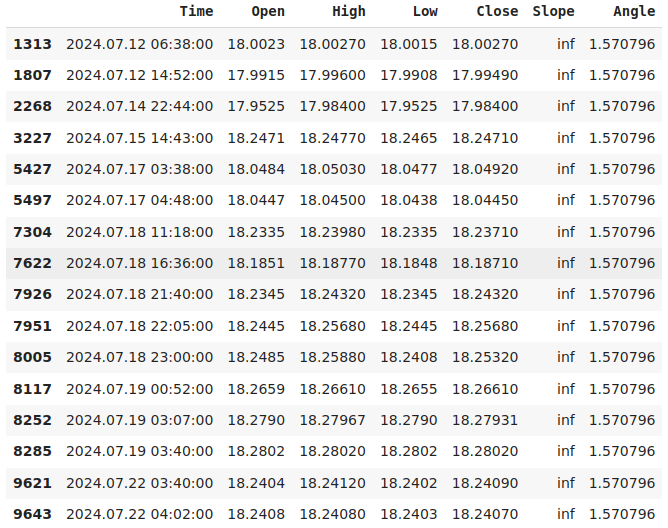
Fig 3: Nossos registros de inclinação infinita representam casos em que o preço de abertura não mudou
No gráfico abaixo, Fig 4, selecionamos aleatoriamente uma das ocorrências em que nosso cálculo da inclinação foi infinito. O gráfico mostra que esses registros correspondem a flutuações de preço, nas quais o preço de abertura não mudou.
pt = 1807 y = data.loc[pt,"Open"] plt.plot(data.loc[(pt - look_ahead):pt,"Open"]) plt.axhline(y=y,color="red") plt.xlabel("Time") plt.ylabel("USDZAR Open Price") plt.title("A slope of INF means the price has not changed")
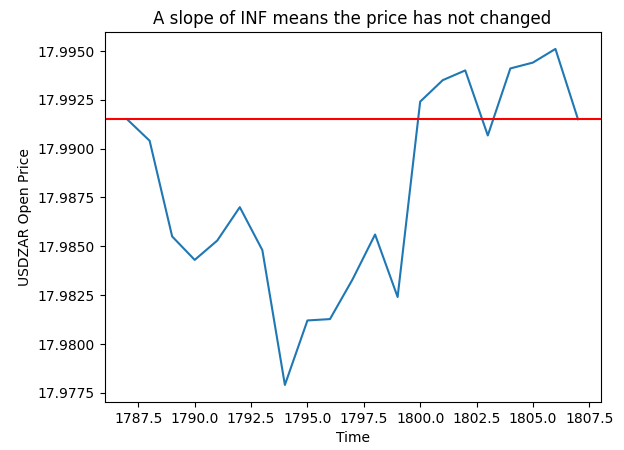
Fig 4: Visualizando os valores de inclinação que calculamos
Por enquanto, vamos simplificar nossa discussão excluindo todos os valores ausentes.
data.dropna(inplace=True)
Agora, vamos redefinir o índice do nosso conjunto de dados.
data.reset_index(drop=True,inplace=True)
Vamos plotar nossos cálculos de ângulo. Como podemos ver na Fig 5 abaixo, nosso cálculo de ângulo gira em torno de 0, isso pode dar ao computador alguma noção de escala, porque quanto mais nos afastamos de 0, maior a mudança nos níveis de preço.
data.loc[:100,"Angle"].plot()
Fig 5: Visualizando os ângulos criados pelas mudanças de preço
Vamos agora tentar estimar o ruído na nova feature que criamos. Vamos quantificar o ruído como o número de vezes em que o ângulo criado pelo preço diminuiu, mas os níveis de preço aumentaram ao mesmo tempo. Essa propriedade é indesejável porque, idealmente, gostaríamos de uma quantidade que aumentasse e diminuísse de acordo com os níveis de preço. Infelizmente, nosso novo cálculo acompanha o preço metade do tempo, e na outra metade eles podem se mover de forma independente.
Para quantificar isso, simplesmente contamos o número de linhas em que a inclinação do preço aumentou e os níveis futuros de preço diminuíram. E dividimos essa contagem pelo número total de instâncias em que a inclinação aumentou. Isso nos diz que, conhecer o valor futuro da inclinação da linha nos informa muito pouco sobre as mudanças nos níveis de preço que teriam ocorrido naquele mesmo horizonte de previsão.
#How clean are the signals generated? 1 - (data.loc[(data["Slope"] < data["Slope"].shift(-look_ahead)) & (data["Close"] > data["Close"].shift(-look_ahead))].shape[0] / data.loc[(data["Slope"] < data["Slope"].shift(-look_ahead))].shape[0])
Análise Exploratória dos Dados
Primeiro, devemos definir nossas entradas e saídas.
#Define our inputs and target ohlc_inputs = ["Open","High","Low","Close"] trig_inputs = ["Angle"] all_inputs = ohlc_inputs + trig_inputs cv_inputs = [ohlc_inputs,trig_inputs,all_inputs] target = "Target"
Agora defina o alvo clássico, o preço futuro.
#Define the target data["Target"] = data["Close"].shift(-look_ahead)
Vamos também adicionar algumas categorias para informar nosso modelo sobre a ação de preço que criou cada candle. Se o candle atual é o resultado de um movimento de alta que aconteceu ao longo dos últimos 20 candles, vamos simbolizar isso com um valor categórico definido como 1. Caso contrário, o valor será definido como 0. Aplicaremos a mesma técnica de rotulagem para nossas mudanças de ângulo.
#Add a few labels data["Bull Bear"] = np.nan data["Angle Up Down"] = np.nan data.loc[data["Close"] > data["Close"].shift(look_ahead), "Bull Bear"] = 0 data.loc[data["Angle"] > data["Angle"].shift(look_ahead),"Angle Up Down"] = 0 data.loc[data["Close"] < data["Close"].shift(look_ahead), "Bull Bear"] = 1 data.loc[data["Angle"] < data["Angle"].shift(look_ahead),"Angle Up Down"] = 1
Formatando os dados.
data.dropna(inplace=True) data.reset_index(drop=True,inplace=True) data
Vamos analisar os níveis de correlação em nossos dados. Lembre-se de que, quando estimamos os níveis de ruído associados ao novo cálculo de ângulo, observamos que preço e o cálculo do ângulo estão em harmonia apenas cerca de 50% do tempo. Portanto, os fracos níveis de correlação que observamos abaixo na Fig 6 não devem ser surpresa.
#Vamos analisar os níveis de correlação sns.heatmap(data.loc[:,all_inputs].corr(),annot=True)
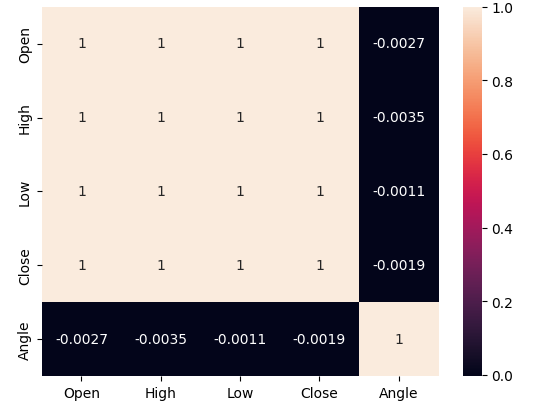
Fig 6: Nosso cálculo de ângulo tem muito pouca correlação com qualquer uma de nossas variáveis de preço
Vamos também tentar criar um gráfico de dispersão do Ângulo criado pelo preço no eixo x e o preço de Fechamento no eixo y. Os resultados obtidos não são promissores. Há uma sobreposição excessiva entre as instâncias em que os níveis de preço caíram, os pontos azuis, e as instâncias em que os níveis de preço aumentaram. Isso torna desafiador para nossos modelos de aprendizado de máquina estimar os mapeamentos entre as 2 possíveis classes de movimentos de preço.
sns.scatterplot(data=data,y="Close",x="Angle",hue="Bull Bear")
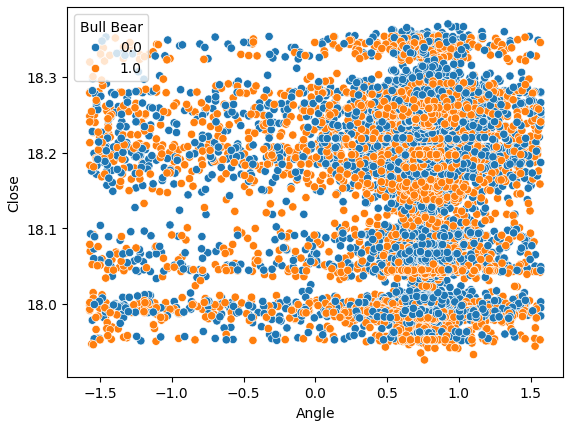
Fig 7: Nosso cálculo de Ângulo não está nos ajudando a separar melhor os dados
Se fizermos um gráfico de dispersão de nossas 2 variáveis derivadas, os cálculos de Inclinação e Ângulo, uma contra a outra, podemos observar claramente a transformação não linear que aplicamos aos dados. A maior parte de nossos dados está entre as 2 extremidades curvas dos dados e, infelizmente, não há partição entre a ação de preço de alta e de baixa que possa nos dar uma vantagem na previsão de níveis futuros de preço.
sns.scatterplot(data=data,x="Angle",y="Slope",hue="Bull Bear")
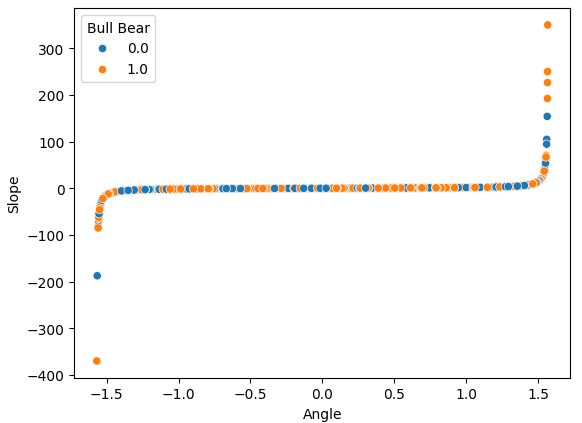
Fig 8: Visualizando nossa transformação não linear que aplicamos aos dados de preço OHLC
Vamos visualizar o ruído que estimamos anteriormente em 51%. Vamos fazer um gráfico com 2 valores em nosso eixo x. Cada valor simbolizará se o cálculo do ângulo aumentou ou diminuiu, respectivamente. Nosso eixo y registrará o preço de fechamento e cada ponto resumirá se os níveis de preço se valorizaram ou se desvalorizaram da mesma forma que descrevemos anteriormente; instâncias azuis resumem pontos onde os níveis futuros de preço caíram.
A princípio, estimamos o ruído, mas agora podemos visualizá-lo. Podemos ver claramente na Fig 9 abaixo que mudanças nos níveis futuros de preço parecem não ter relação com as mudanças no ângulo criado pelo preço.
sns.swarmplot(data=data,x="Angle Up Down",y="Close",hue="Bull Bear")
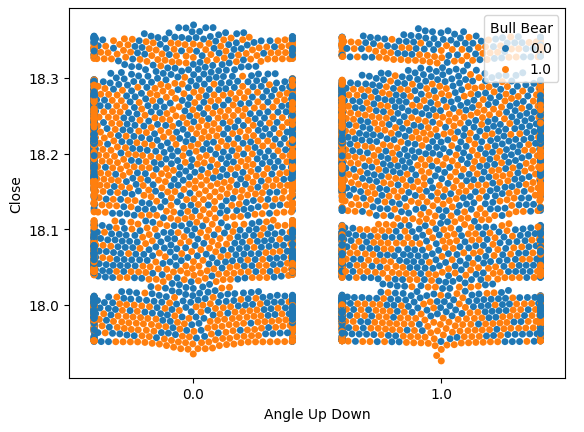
Fig 9: Níveis futuros de preço parecem não ter relação com a mudança no ângulo
Visualizar os dados em 3D mostra o quão ruidoso é o sinal. Esperaríamos observar pelo menos alguns agrupamentos de pontos que fossem todos de alta ou todos de baixa. No entanto, neste caso específico, não temos nenhum. A presença de agrupamentos poderia possivelmente identificar um padrão que poderia ser interpretado como um sinal de negociação.
#Define the 3D Plot fig = plt.figure(figsize=(7,7)) ax = plt.axes(projection="3d") ax.scatter(data["Slope"],data["Angle"],data["Close"],c=data["Bull Bear"]) ax.set_xlabel("Slope") ax.set_ylabel("Angle") ax.set_zlabel("Close")
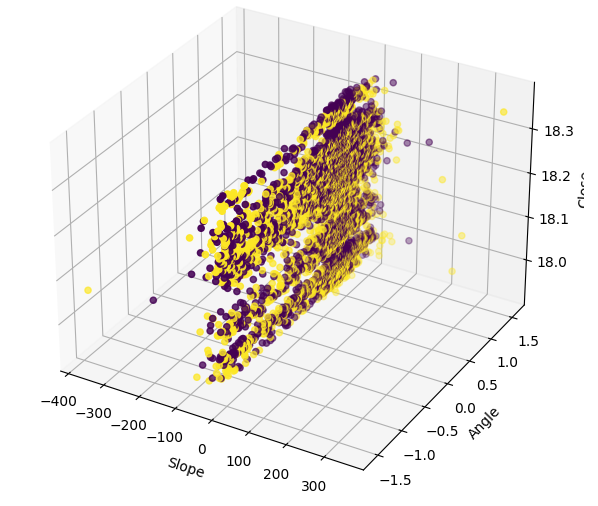
Fig 10: Visualizando nossos dados de inclinação em 3 dimensões
O gráfico de violino nos permite comparar visualmente 2 distribuições. O gráfico de violino tem um box-plot em seu núcleo, para resumir as propriedades numéricas de cada distribuição. A Fig 10 abaixo nos dá esperança de que o cálculo do ângulo não seja uma perda de tempo. Cada box-plot tem seu valor médio destacado com uma linha branca. Podemos ver claramente que, em ambas as instâncias de movimentos de ângulo, os valores médios de cada box-plot foram ligeiramente diferentes. Embora essa pequena diferença possa parecer insignificante para nós humanos, nossos modelos de aprendizado de máquina são sensíveis o suficiente para captar e aprender com tais discrepâncias na distribuição dos dados.
sns.violinplot(data=data,x="Angle Up Down",y="Close",hue="Bull Bear",split=True)
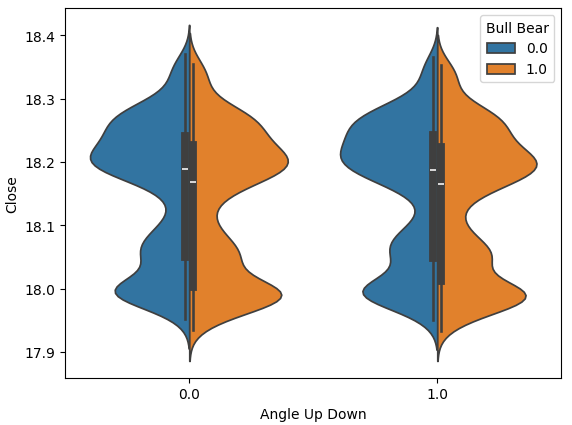
Fig 11: Comparando a distribuição de dados de preço entre as 2 classes de movimentos de ângulo
Preparando para Modelar os Dados
Agora vamos tentar modelar nossos dados. Primeiro, vamos importar as bibliotecas de que precisamos.
from sklearn.model_selection import train_test_split,cross_val_score from sklearn.preprocessing import StandardScaler from sklearn.ensemble import RandomForestRegressor, BaggingRegressor, GradientBoostingRegressor,AdaBoostRegressor from sklearn.svm import LinearSVR from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet from sklearn.neighbors import KNeighborsRegressor from sklearn.tree import DecisionTreeRegressor from sklearn.neural_network import MLPRegressor from sklearn.metrics import mean_squared_error
Divida os dados em conjuntos de treino e teste.
#Let's split our data into train test splits train_data, test_data = train_test_split(data,test_size=0.5,shuffle=False)
Escalar os dados ajudará nossos modelos a aprender de forma eficaz. Certifique-se de ajustar o objeto scaler apenas no conjunto de treino e depois transformar o conjunto de teste sem ajustar o objeto scaler uma segunda vez. Não ajuste o objeto scaler em todo o conjunto de dados porque os parâmetros aprendidos para escalar seus dados propagarão algumas informações sobre o futuro de volta para o passado.
#Scale the data
scaler = StandardScaler()
scaler.fit(train_data[all_inputs])
train_scaled= pd.DataFrame(scaler.transform(train_data[all_inputs]),columns=all_inputs)
test_scaled = pd.DataFrame(scaler.transform(test_data[all_inputs]),columns=all_inputs) Defina um data-frame para armazenar a acurácia de cada modelo.
#Create a dataframe to store our accuracy in training and testing columns = [ "Random Forest", "Bagging", "Gradient Boosting", "AdaBoost", "Linear SVR", "Linear Regression", "Ridge", "Lasso", "Elastic Net", "K Neighbors", "Decision Tree", "Neural Network" ] index = ["OHLC","Angle","All"] accuracy = pd.DataFrame(columns=columns,index=index)
Armazene os modelos em uma lista.
#Store the models models = [ RandomForestRegressor(), BaggingRegressor(), GradientBoostingRegressor(), AdaBoostRegressor(), LinearSVR(), LinearRegression(), Ridge(), Lasso(), ElasticNet(), KNeighborsRegressor(), DecisionTreeRegressor(), MLPRegressor(hidden_layer_sizes=(4,6)) ]
Valide cada modelo com cross-validation.
#Cross validate the models #First we have to iterate over the inputs for k in np.arange(0,len(cv_inputs)): current_inputs = cv_inputs[k] #Then fit each model on that set of inputs for i in np.arange(0,len(models)): score = cross_val_score(models[i],train_scaled[current_inputs],train_data[target],cv=5,scoring="neg_mean_squared_error",n_jobs=-1) accuracy.iloc[k,i] = -score.mean()
Testamos os modelos usando 3 conjuntos de entradas:
- Apenas os preços OHLC.
- Apenas a inclinação e o ângulo criados.
- Todos os dados que tínhamos.
Nem todos os nossos modelos foram capazes de usar efetivamente nossas variáveis derivadas. Dos 12 modelos em nosso conjunto de candidatos, o modelo KNeighbors obteve uma melhoria de 20% no desempenho com nossas novas variáveis e foi claramente o melhor modelo que tínhamos neste ponto.
Embora nossa regressão linear seja o melhor modelo de todo o conjunto, essa demonstração sugere que pode haver outras transformações das quais simplesmente não temos conhecimento que poderiam reduzir ainda mais nossos níveis de acurácia.
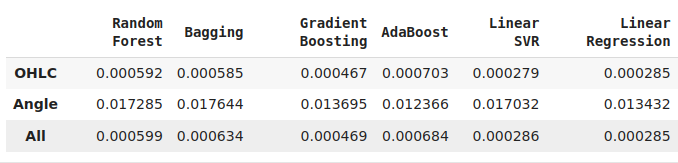
Fig 12: Alguns dos nossos níveis de acurácia. Observe que apenas 2 dos nossos modelos demonstraram habilidade usando as novas variáveis que criamos.
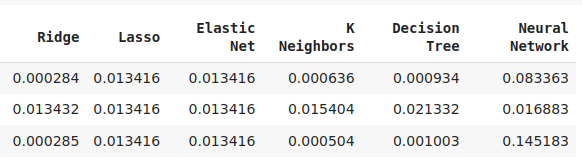
Fig 13: AdaBoost e KNeighbors foram nossos modelos mais promissores, decidimos otimizar o modelo KNeighbors
Otimização Mais Profunda
Vamos tentar encontrar configurações melhores para nosso indicador do que as configurações padrão com as quais ele vem.
from sklearn.model_selection import RandomizedSearchCV
Crie instâncias do nosso modelo.
model = KNeighborsRegressor(n_jobs=-1) Defina os parâmetros de ajuste.
tuner = RandomizedSearchCV(model,
{
"n_neighbors": [2,3,4,5,6,7,8,9,10],
"weights": ["uniform","distance"],
"algorithm": ["auto","ball_tree","kd_tree","brute"],
"leaf_size": [1,2,3,4,5,10,20,30,40,50,60,100,200,300,400,500,1000],
"p": [1,2]
},
n_iter = 100,
n_jobs=-1,
cv=5
) Ajustar (fit) o objeto tuner.
tuner.fit(train_scaled.loc[:,all_inputs],train_data[target])
Os melhores parâmetros que encontramos.
tuner.best_params_
'p': 1,
'n_neighbors': 10,
'leaf_size': 100,
'algorithm': 'ball_tree'}
Nossa melhor pontuação no conjunto de treino foi 71%. Não nos importamos muito com os erros de treino. Estamos mais preocupados com o quão bem nosso modelo irá generalizar para novos dados.
tuner.best_score_
Testando Overfitting
Vamos ver se estávamos sofrendo de overfitting no conjunto de treino. Overfitting acontece quando nosso modelo aprende informações sem sentido do conjunto de treino. Existem várias maneiras de testarmos se estamos sofrendo de overfitting. Uma delas é comparar o modelo customizado com um modelo que não tenha conhecimento prévio sobre os dados.
#Testing for over fitting model = KNeighborsRegressor(n_jobs=-1) custom_model = KNeighborsRegressor(n_jobs=-1,weights= 'uniform',p=1,n_neighbors= 10,leaf_size= 100,algorithm='ball_tree')
Se não conseguirmos superar uma instância padrão do modelo, podemos ter confiança de que personalizamos demais nosso modelo para o conjunto de treino. Podemos ver claramente que superamos o modelo padrão, o que é uma boa notícia.
model.fit(train_scaled.loc[:,all_inputs],train_data[target]) custom_model.fit(train_scaled.loc[:,all_inputs],train_data[target])
| Modelo Padrão | Modelo Customizado |
|---|---|
| 0.0009797322460441842 | 0.0009697248896608824 |
Exportando para ONNX
Open Neural Network Exchange (ONNX) é um protocolo open-source para construção e compartilhamento de modelos de aprendizado de máquina de forma agnóstica ao modelo. Utilizaremos a API ONNX para exportar nosso modelo de IA do Python e importá-lo em um programa MQL5.
Primeiro, precisamos aplicar transformações aos nossos dados de preço que possamos sempre reproduzir em MQL5. Vamos salvar os valores da média e do desvio padrão de cada coluna em um arquivo CSV.
data.loc[:,all_inputs].mean().to_csv("USDZAR M1 MEAN.csv") data.loc[:,all_inputs].std().to_csv("USDZAR M1 STD.csv")
Agora aplique a transformação nos dados.
data.loc[:,all_inputs] = ((data.loc[:,all_inputs] - data.loc[:,all_inputs].mean())/ data.loc[:,all_inputs].std())
Agora vamos importar as bibliotecas de que precisamos.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Defina o tipo de entrada do nosso modelo.
#Define the input shape
initial_type = [('float_input', FloatTensorType([1, len(all_inputs)]))] Ajuste o modelo em todos os dados que temos.
#Fit the model on all the data we have custom_model.fit(data.loc[:,all_inputs],data.loc[:,"Target"])
Converta o modelo para o formato ONNX e salve-o.
#Convert the model to ONNX format onnx_model = convert_sklearn(model, initial_types=initial_type,target_opset=12) #Save the ONNX model onnx.save(onnx_model,"USDZAR M1 OHLC Angle.onnx")
Construindo Nosso Expert Advisor em MQL5
Agora vamos integrar nosso modelo de IA em um aplicativo de negociação, para que possamos operar com uma vantagem sobre o mercado. Nossa estratégia de negociação usará nosso modelo de IA para detectar a tendência no M1. Buscaremos confirmação adicional do desempenho do par USADZAR no período diário. Se nosso modelo de IA estiver detectando uma tendência de alta, queremos ver ação de preço altista no gráfico diário. Além disso, também queremos mais confirmação do Índice do Dólar. Seguindo nosso exemplo de compra no M1, também precisaremos observar ação de preço altista no gráfico diário do Índice do Dólar como um sinal de que o Dólar provavelmente continuará subindo em prazos maiores.
Primeiro, precisamos importar o modelo ONNX que acabamos de criar.
//+------------------------------------------------------------------+ //| Slope AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the ONNX files | //+------------------------------------------------------------------+ #resource "\\Files\\USDZAR M1 OHLC Angle.onnx" as const uchar onnx_buffer[];
Vamos também carregar nossa biblioteca de negociação para gerenciar nossas posições abertas.
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
Defina algumas variáveis globais que precisaremos.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double mean_values[5] = {18.143698,18.145870,18.141644,18.143724,0.608216}; double std_values[5] = {0.112957,0.113113,0.112835,0.112970,0.580481}; long onnx_model; int macd_handle; int usd_ma_slow,usd_ma_fast; int usd_zar_slow,usd_zar_fast; double macd_s[],macd_m[],usd_zar_s[],usd_zar_f[],usd_s[],usd_f[]; double bid,ask; double vol = 0.3; double profit_target = 10; int system_state = 0; vectorf model_forecast = vectorf::Zeros(1);
Agora chegamos ao procedimento de inicialização do nosso aplicativo de negociação. Por enquanto, tudo o que precisamos é carregar nosso modelo ONNX e indicadores técnicos.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Load the ONNX file if(!onnx_load()) { //--- We failed to load the ONNX file return(INIT_FAILED); } //--- Load the MACD Indicator macd_handle = iMACD("EURUSD",PERIOD_CURRENT,12,26,9,PRICE_CLOSE); usd_zar_fast = iMA("USDZAR",PERIOD_D1,20,0,MODE_EMA,PRICE_CLOSE); usd_zar_slow = iMA("USDZAR",PERIOD_D1,60,0,MODE_EMA,PRICE_CLOSE); usd_ma_fast = iMA("DXY_Z4",PERIOD_D1,20,0,MODE_EMA,PRICE_CLOSE); usd_ma_slow = iMA("DXY_Z4",PERIOD_D1,60,0,MODE_EMA,PRICE_CLOSE); //--- Everything went fine return(INIT_SUCCEEDED); }
Se nosso programa não estiver mais em uso, vamos liberar os recursos que ele estava utilizando.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Release the handles don't need OnnxRelease(onnx_model); IndicatorRelease(macd_handle); IndicatorRelease(usd_zar_fast); IndicatorRelease(usd_zar_slow); IndicatorRelease(usd_ma_fast); IndicatorRelease(usd_ma_slow); }
Sempre que recebermos preços atualizados, vamos armazenar nossos novos dados de mercado, buscar uma nova previsão do nosso modelo e então decidir se precisamos procurar uma posição no mercado ou fechar as posições que já temos.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Update our market data update(); //--- Get a prediction from our model model_predict(); if(PositionsTotal() == 0) { find_entry(); } if(PositionsTotal() > 0) { manage_positions(); } } //+------------------------------------------------------------------+
A função que realmente atualiza nossos dados de mercado está definida abaixo. Estamos confiando no comando CopyBuffer para buscar o valor atual de cada indicador em seu array buffer. Usaremos esses indicadores de média móvel para confirmação de tendência.
//+------------------------------------------------------------------+ //| Update our market data | //+------------------------------------------------------------------+ void update(void) { bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); CopyBuffer(macd_handle,0,0,1,macd_m); CopyBuffer(macd_handle,1,0,1,macd_s); CopyBuffer(usd_ma_fast,0,0,1,usd_f); CopyBuffer(usd_ma_slow,0,0,1,usd_s); CopyBuffer(usd_zar_fast,0,0,1,usd_zar_f); CopyBuffer(usd_zar_slow,0,0,1,usd_zar_s); } //+------------------------------------------------------------------+
Não apenas isso, mas precisamos definir exatamente como nosso modelo fará previsões. Além disso, vamos começar primeiro calculando o ângulo formado pelas flutuações de preço e então armazenaremos as entradas do nosso modelo em um vetor. Por fim, padronizaremos e escalaremos nossas entradas de modelo antes de chamar a função OnnxRun para obter uma previsão do nosso modelo de IA.
//+------------------------------------------------------------------+ //| Get a forecast from our model | //+------------------------------------------------------------------+ void model_predict(void) { float angle = (float) MathArctan(((iOpen(Symbol(),PERIOD_M1,1) - iOpen(Symbol(),PERIOD_M1,20)) / (iClose(Symbol(),PERIOD_M1,1) - iClose(Symbol(),PERIOD_M1,20)))); vectorf model_inputs = {(float) iOpen(Symbol(),PERIOD_M1,1),(float) iHigh(Symbol(),PERIOD_M1,1),(float) iLow(Symbol(),PERIOD_M1,1),(float) iClose(Symbol(),PERIOD_M1,1),(float) angle}; for(int i = 0; i < 5; i++) { model_inputs[i] = (float)((model_inputs[i] - mean_values[i])/std_values[i]); } //--- Log Print("Model inputs: "); Print(model_inputs); if(!OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,model_inputs,model_forecast)) { Comment("Failed to obtain a forecast from our model: ",GetLastError()); } }
A função a seguir carregará nosso modelo ONNX a partir do buffer ONNX que definimos anteriormente.
//+------------------------------------------------------------------+ //| ONNX Load | //+------------------------------------------------------------------+ bool onnx_load(void) { //--- Create the ONNX model from the buffer we defined onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Define the input and output shapes ulong input_shape[] = {1,5}; ulong output_shape[] = {1,1}; //--- Validate the I/O parameters if(!(OnnxSetInputShape(onnx_model,0,input_shape))||!(OnnxSetOutputShape(onnx_model,0,output_shape))) { //--- We failed to define the I/O parameters Comment("[ERROR] Failed to load AI Model Correctly: ",GetLastError()); return(false); } //--- Everything was okay return(true); }
Além disso, nosso sistema precisa de regras sobre quando deve fechar nossas posições. Se o lucro flutuante em nossas posições atuais for maior que nossa meta de lucro, fecharemos nossas posições. Caso contrário, se o sistema mudar de estado, então fecharemos nossas posições de acordo.
//+------------------------------------------------------------------+ //| Manage our open positions | //+------------------------------------------------------------------+ void manage_positions(void) { if(PositionSelectByTicket(PositionGetTicket(0))) { if(PositionGetDouble(POSITION_PROFIT) > profit_target) { Trade.PositionClose(Symbol()); } } if(system_state == 1) { if(macd_m[0] < macd_s[0]) { if(model_forecast[0] < iClose(Symbol(),PERIOD_M1,0)) { Trade.PositionClose(Symbol()); } } } if(system_state == -1) { if(macd_m[0] > macd_s[0]) { if(model_forecast[0] > iClose(Symbol(),PERIOD_M1,0)) { Trade.PositionClose(Symbol()); } } } }
A função a seguir é responsável por abrir nossas posições. Só abriremos uma posição de compra se:
- A linha principal do MACD estiver acima da linha de sinal
- Nossa previsão de IA for maior que o fechamento atual
- O Índice do Dólar e o par USDZAR estiverem ambos demonstrando ação de preço altista no gráfico Diário.
//+------------------------------------------------------------------+ //| Find an entry | //+------------------------------------------------------------------+ void find_entry(void) { if(macd_m[0] > macd_s[0]) { if(model_forecast[0] > iClose(Symbol(),PERIOD_M1,0)) { if((usd_f[0] > usd_s[0]) && (usd_zar_f[0] > usd_zar_s[0])) { Trade.Buy(vol,Symbol(),ask,0,0,"Slope AI"); system_state = 1; } } } if(macd_m[0] < macd_s[0]) { if(model_forecast[0] < iClose(Symbol(),PERIOD_M1,0)) { if((usd_f[0] < usd_s[0]) && (usd_zar_f[0] < usd_zar_s[0])) { Trade.Sell(vol,Symbol(),bid,0,0,"Slope AI"); system_state = -1; } } } }
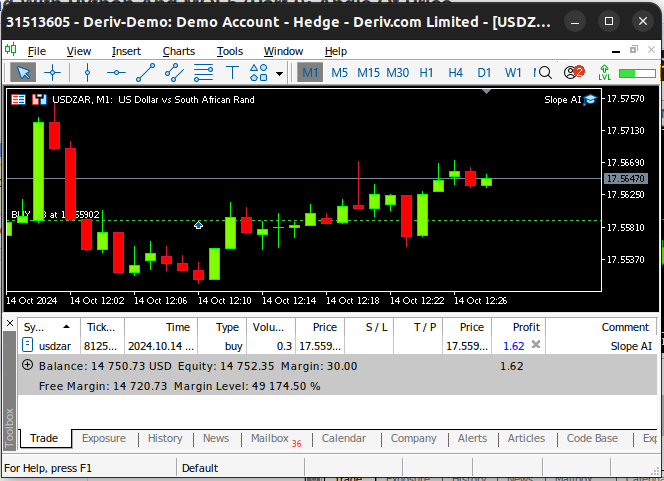
Fig 14: Nosso sistema de IA em ação
Conclusão
Até agora, demonstramos que ainda existem alguns obstáculos que atrapalham traders que desejam usar a inclinação formada pela ação de preço em suas estratégias de negociação. No entanto, parece que qualquer esforço aplicado nessa direção pode valer o tempo investido. Expor a relação entre níveis de preço usando a inclinação melhorou o desempenho do nosso modelo KNeighbors em 20%. Isso nos leva a questionar quanto mais ganhos de desempenho podemos realizar se continuarmos pesquisando nessa direção. Além disso, também destaca que cada modelo provavelmente tem seu próprio conjunto específico de transformações que aumentam seu desempenho. Nosso trabalho agora passa a ser realizar esse mapeamento.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/16124
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso