
数据科学和机器学习(第 26 部分):时间序列预测的终极之战 — LSTM 对比 GRU 神经网络

内容
- 什么是长-短期记忆(LSTM)神经网络?
- 长-短期记忆(LSTM)网络背后的数学
- 什么是门控递归单元(GRU)神经网络?
- 门控递归单元(GRU)网络背后的数学
- 为 LSTM 和 GRU 网络构建父类
- LSTM 和 GRU 神经网络子类
- 训练两个模型
- 检查两个模型的特征要点
- 在策略测试器上 LSTM 对比 GRU 分类器
- LSTM 和 GRU 神经网络模型之间的差异
- 结束语
什么是长-短期记忆(LSTM)神经网络?
长-短期记忆(LSTM)是一种专为序列任务设计的递归神经网络,擅长捕获和利用数据中的长期依赖关系。与本系列上一篇文章(必读)中讨论的普通递归神经网络(简单 RNN)不同。其无法捕获数据中的长期依赖关系。
引入 LSTM 是为了修复简单 RNN 中普遍存在的短期记忆。
简单递归神经网络的问题
简单递归神经网络(RNN)的设计是在处理序列数据时,利用它们的内部隐藏状态(记忆)来捕获序列中先前输入的有关信息。尽管它们的概念很简单,并且在针对顺序数据进行建模方面取得了初步成功,然它们也存在若干局限性。
一个明显的问题就是梯度迷失问题。在反向传播期间,梯度用于更新网络的权重。在简单的 RNN 中,这些梯度会随着时间的倒退传播而呈指数级衰减,尤其是对于长序列。结果导致网络学习长期依赖关系失能,因梯度变得太小,故权重更新失效,这令简单的 RNN 难以捕获跨越多个时间步骤的形态。
另一个挑战是梯度膨胀问题,它与梯度迷失问题相反。在这种情况下,梯度在反向传播期间呈指数成长。这可能会导致数值不稳定,并令训练过程颇具挑战性。尽管比梯度迷失少见,但梯度膨胀会导致网络权重的大范围更新,其效力会导致学习过程失败。
简单的 RNN 也很难训练,因为它们容易受到梯度迷失和膨胀问题的影响,这会令训练过程效率低下,且缓慢。训练简单 RNN 会让计算成本更高,并且可能需要仔细调整超参数。
甚而,简单 RNN 无法处理数据中复杂的时间依赖关系。由于它们的记忆容量有限,它们往往难以理解并捕获复杂的顺序形态。
对于涉及理解数据中长期依赖关系的任务,简单 RNN 也许在捕获必要的上下文时失效,从而导致性能欠佳。
长-短期记忆(LSTM)网络背后的数学
为了搞明白 LSTM 背后的细节,我们首先看看 LSTM 单元。

01:遗忘门
由方程式给出。
![]()
sigmoid 函数 ![]() 取以前的隐藏状态
取以前的隐藏状态 ![]() ,和当前输入
,和当前输入 ![]() 作为输入。输出
作为输入。输出 ![]() 是一个介于 0 和 1 之间的数值,表示在每个组件
是一个介于 0 和 1 之间的数值,表示在每个组件 ![]() 中应保留多少前一个单元状态。
中应保留多少前一个单元状态。
![]() - 遗忘门的权重。
- 遗忘门的权重。
![]() - 遗忘门的乖离。
- 遗忘门的乖离。
遗忘门判定来自前一个单元状态中的哪些信息应结转。它为单元状态 ![]() 中的每个数字输出一个介于 0 和 1 之间的数字,其中 0 表示 彻底遗忘,1 表示 完全保留。
中的每个数字输出一个介于 0 和 1 之间的数字,其中 0 表示 彻底遗忘,1 表示 完全保留。
02:输入门
由公式给出。
![]()
sigmoid 函数 ![]() 判定哪个数值要更新。该门控制新数据输入到记忆单元之中。
判定哪个数值要更新。该门控制新数据输入到记忆单元之中。
![]() - 权重输入门。
- 权重输入门。
![]() - 乖离输入门。
- 乖离输入门。
该门决定新输入中的哪些值 ![]() 用来更新单元状态。它监管流入单元的新信息。
用来更新单元状态。它监管流入单元的新信息。
03:候选记忆单元
由方程式给出。
![]()
tanh 函数生成可存储在单元状态中的潜在新信息。
![]() - 候选记忆单元的权重。
- 候选记忆单元的权重。
![]() - 候选记忆单元的乖离。
- 候选记忆单元的乖离。
该组件生成可添加到单元状态的新候选值。它调用 tanh 激活函数来确保值介于 -1 和 1 之间。
04:单元状态更新
由方程式给出。
![]()
将前一个单元状态 ![]() 乘以
乘以 ![]() (遗忘门输出),来舍弃不重要的信息。然后,
(遗忘门输出),来舍弃不重要的信息。然后,![]() (输入门的输出)乘以
(输入门的输出)乘以 ![]() (候选单元状态),并将结果相加,形成新的单元状态
(候选单元状态),并将结果相加,形成新的单元状态 ![]() 。
。
通过把旧单元状态和候选值相组合,来更新单元状态。遗忘门输出控制先前的单元状态贡献,输入门的输出控制新候选值的贡献。
05:输出门
由方程式给出。
![]()
sigmoid 函数判定单元状态的哪些部分要输出。该门控制来自记忆单元的信息输出。
![]() - 输出层的权重
- 输出层的权重
![]() - 输出层的乖离
- 输出层的乖离
该门判定当前单元状态的最终输出。它基于输入 ![]() 和之前的隐藏状态
和之前的隐藏状态 ![]() ,决定单元状态的哪些部分应当输出。
,决定单元状态的哪些部分应当输出。
06:隐藏状态更新
由方程式给出。
![]()
将输出门 ![]() 与更新的单元状态
与更新的单元状态 ![]() 的 tanh 函数值相乘,来获得新的隐藏状态
的 tanh 函数值相乘,来获得新的隐藏状态 ![]() 。
。
隐藏状态基于单元状态和输出门的决策进行更新。它用作当前时间步骤的输出,和下一个时间步骤的输入
什么是门控递归单元(GRU)神经网络?
门控递归单元(GRU)是递归神经网络(RNN)的一个种类,在某些情况下,它比长-短期记忆(LSTM)更具优势。GRU 所用记忆更少,速度比 LSTM 更快,不过,当用于具有较长序列的数据集时,LSTM 更准确。
引入 LSTM 和 GRU 是为了缓解简单递归神经网络中普遍存在的短期记忆。两者都通过在单元中的门来开启长期记忆。
尽管 LSTM 和 GRU 在许多方面与简单 RNN 工作相似,但它们解决了简单递归神经网络所遭受的梯度迷失问题。
门控递归单元(GRU)网络背后的数学
下图概括了 GRU 单元在剖析时的模样。

01: 更新门
由公式给出。
![]()
该门判定应保留多少先前的隐藏状态 ![]() ,以及应取多少候选隐藏状态
,以及应取多少候选隐藏状态 ![]() 来更新隐藏状态。
来更新隐藏状态。
更新门控制应把多少先前的隐藏状态 ![]() 结转到下一个时间步骤。它有效地决定了保留旧信息、以及合并新信息之间的平衡。
结转到下一个时间步骤。它有效地决定了保留旧信息、以及合并新信息之间的平衡。
02:重置门
由公式给出。
![]()
该门中的 sigmoid 函数 ![]() 判定创建候选激活之前,先前隐藏状态的哪些部分应重置,并与当前输入结合。
判定创建候选激活之前,先前隐藏状态的哪些部分应重置,并与当前输入结合。
03:候选激活
由公式给出。
![]()
候选激活是依据当前输入 ![]() ,和重置隐藏状态
,和重置隐藏状态 ![]() 计算的。
计算的。
该组件为隐藏状态生成新的潜在值,这些值可基于更新门的决策进行组合。
04:隐藏状态更新
由公式给出。
![]()
更新门输出 ![]() 控制使用多少候选隐藏状态
控制使用多少候选隐藏状态 ![]() 来形成新的隐藏状态
来形成新的隐藏状态 ![]() 。
。
隐藏状态通过把前一个隐藏状态,与候选隐藏状态组合来更新。更新门 ![]() 控制组合,确保在合并新信息的同时保留过去的相关信息。
控制组合,确保在合并新信息的同时保留过去的相关信息。
为 LSTM 和 GRU 网络构建父类
由于 LSTM 和 GRU 在许多方面的工作方式相似,并且它们采用相同的参数,因此最好为所需的模型构建、编译、优化、检查特征重要性、以及保存函数提供一个基(父)类。该类将由后续的 LSTM 和 GRU 子类继承。
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import LSTM, GRU, Dense, Input, Dropout from keras.callbacks import EarlyStopping from keras.optimizers import Adam import tf2onnx import optuna import shap from sklearn.metrics import accuracy_score class RNNClassifier(): def __init__(self, time_step, x_train, y_train, x_test, y_test): self.model = None self.time_step = time_step self.x_train = x_train self.y_train = y_train self.x_test = x_test self.y_test = y_test # a crucial function that all the subclasses must implement def build_compile_and_train(self, params, verbose=0): raise NotImplementedError("Subclasses should implement this method") # a function for saving the RNN model to onnx & the Standard scaler parameters def save_onnx_model(self, onnx_file_name): # optuna objective function to oprtimize def optimize_objective(self, trial): # optimize for 50 trials by default def optimize(self, n_trials=50): def _rnn_predict(self, data): def check_feature_importance(self, feature_names):
使用 Optuna 优化 LSTM 和 GRU
如前述,神经网络对超参数非常敏感。若未经正确调整、且无最优参数,神经网络可能会失效。
Python
def optimize_objective(self, trial): params = { "neurons": trial.suggest_int('neurons', 10, 100), "n_hidden_layers": trial.suggest_int('n_hidden_layers', 1, 5), "dropout_rate": trial.suggest_float('dropout_rate', 0.1, 0.5), "learning_rate": trial.suggest_float('learning_rate', 1e-5, 1e-2, log=True), "hidden_activation_function": trial.suggest_categorical('hidden_activation_function', ['relu', 'tanh', 'sigmoid']), "loss_function": trial.suggest_categorical('loss_function', ['categorical_crossentropy', 'binary_crossentropy', 'mean_squared_error', 'mean_absolute_error']) } val_accuracy = self.build_compile_and_train(params, verbose=0) # we build a model with different parameters and train it, just to return a validation accuracy value return val_accuracy # optimize for 50 trials by default def optimize(self, n_trials=50): study = optuna.create_study(direction='maximize') # we want to find the model with the highest validation accuracy value study.optimize(self.optimize_objective, n_trials=n_trials) return study.best_params # returns the parameters that produced the best performing model
该方法 optimize_objective 遵照 Optuna 框架定义超参数优化的意向函数。它指导优化过程去发现可最大程度提高模型性能的最佳超参数集。
Optimize 方法使用 Optuna,重复调用 optimize_objective 方法来执行超参数优化。
使用 SHAP 检查特征重要性
衡量特征对模型预测的影响程度,对于数据科学家来说很重要,它不仅可以帮助我们了解需要改进的关键领域,还可以更加清楚我们对模型特定数据集的理解。
def check_feature_importance(self, feature_names): # Sample a subset of training data for SHAP explainer sampled_idx = np.random.choice(len(self.x_train), size=100, replace=False) explainer = shap.KernelExplainer(self._rnn_predict, self.x_train[sampled_idx].reshape(100, -1)) # Get SHAP values for the test set shap_values = explainer.shap_values(self.x_test[:100].reshape(100, -1), nsamples=100) # Update feature names for SHAP feature_names = [f'{feature}_t{t}' for t in range(self.time_step) for feature in feature_names] # Plot the SHAP values shap.summary_plot(shap_values, self.x_test[:100].reshape(100, -1), feature_names=feature_names, max_display=len(feature_names), show=False) # Adjust layout and set figure size plt.subplots_adjust(left=0.12, bottom=0.1, right=0.9, top=0.9) plt.gcf().set_size_inches(7.5, 14) plt.tight_layout() # Get the class name of the current instance class_name = self.__class__.__name__ # Create the file name using the class name file_name = f"{class_name.lower()}_feature_importance.png" plt.savefig(file_name) plt.show()
将 LSTM 和 GRU 分类器保存为 ONNX 模型格式
最后,在我们构建模型之后,我们必须将它们保存为与 MQL5 兼容的 ONNX 格式。
def save_onnx_model(self, onnx_file_name):
# Convert the Keras model to ONNX
spec = (tf.TensorSpec((None, self.time_step, self.x_train.shape[2]), tf.float16, name="input"),)
self.model.output_names = ['outputs']
onnx_model, _ = tf2onnx.convert.from_keras(self.model, input_signature=spec, opset=13)
# Save the ONNX model to a file
with open(onnx_file_name, "wb") as f:
f.write(onnx_model.SerializeToString())
# Save the mean and scale parameters to binary files
scaler.mean_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_mean.bin")
scaler.scale_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_scale.bin")
LSTM 和 GRU 神经网络子类
递归神经网络在许多方面的工作方式相似,即使实现时使用 Keras 也要遵循类似的方式和参数。它们的主要区别在于模型的类型,其它一切都保持不变。
LSTM 分类器
Python
class LSTMClassifier(RNNClassifier): def build_compile_and_train(self, params, verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.x_train.shape[2]))) self.model.add(LSTM(units=params["neurons"], activation='relu', kernel_initializer='he_uniform')) # input layer for layer in range(params["n_hidden_layers"]): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=params["neurons"], activation=params["hidden_activation_function"], kernel_initializer='he_uniform')) self.model.add(Dropout(params["dropout_rate"])) self.model.add(Dense(units=len(classes_in_y), activation='softmax', name='output_layer', kernel_initializer='he_uniform')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=params["learning_rate"]) self.model.compile(optimizer=adam_optimizer, loss=params["loss_function"], metrics=['accuracy']) if verbose != 0: self.model.summary() early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.x_train, self.y_train, epochs=100, batch_size=32, validation_data=(self.x_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.x_test, self.y_test, verbose=verbose) return val_accuracy
GRU 分类器
Python
class GRUClassifier(RNNClassifier): def build_compile_and_train(self, params, verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.x_train.shape[2]))) self.model.add(GRU(units=params["neurons"], activation='relu', kernel_initializer='he_uniform')) # input layer for layer in range(params["n_hidden_layers"]): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=params["neurons"], activation=params["hidden_activation_function"], kernel_initializer='he_uniform')) self.model.add(Dropout(params["dropout_rate"])) self.model.add(Dense(units=len(classes_in_y), activation='softmax', name='output_layer', kernel_initializer='he_uniform')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=params["learning_rate"]) self.model.compile(optimizer=adam_optimizer, loss=params["loss_function"], metrics=['accuracy']) if verbose != 0: self.model.summary() early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.x_train, self.y_train, epochs=100, batch_size=32, validation_data=(self.x_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.x_test, self.y_test, verbose=verbose) return val_accuracy
从子类分类器中可见,唯一的区别是模型的类型,LSTM 和 GRU 都采用类似的方式。
训练两个模型
首先,我们必须初始化两个模型类的实例。从 LSTM 模型开始。
lstm_clf = LSTMClassifier(time_step=time_step, x_train= x_train_seq, y_train= y_train_encoded, x_test= x_test_seq, y_test= y_test_encoded )
然后我们初始化 GRU 模型。
gru_clf = GRUClassifier(time_step=time_step, x_train= x_train_seq, y_train= y_train_encoded, x_test= x_test_seq, y_test= y_test_encoded )
两个模型优化选拔 20 遍之后;
best_params = lstm_clf.optimize(n_trials=20)
best_params = gru_clf.optimize(n_trials=20) 第 19 次选拔的 LSTM 分类器模型最佳。
[I 2024-07-01 11:14:40,588] Trial 19 finished with value: 0.5597269535064697 and parameters: {'neurons': 79, 'n_hidden_layers': 4, 'dropout_rate': 0.335909076638275, 'learning_rate': 3.0704319088493336e-05, 'hidden_activation_function': 'relu', 'loss_function': 'categorical_crossentropy'}. Best is trial 19 with value: 0.5597269535064697.
同时,在第 3 次选拔中发现的 GRU 分类器模型,依据验证数据产生了大约 55.97% 的准确率,是所有模型中最好的。
[I 2024-07-01 11:18:52,190] Trial 3 finished with value: 0.532423198223114 and parameters: {'neurons': 55, 'n_hidden_layers': 5, 'dropout_rate': 0.2729838602302831, 'learning_rate': 0.009626688728041802, 'hidden_activation_function': 'sigmoid', 'loss_function': 'mean_squared_error'}. Best is trial 3 with value: 0.532423198223114.
它为验证数据提供了大约 53.24% 的准确率。
检查两个模型的特征重要性
| LSTM 分类器 | GRU 分类器 |
|---|---|
feature_importance = lstm_clf.check_feature_importance(X.columns) 成果。 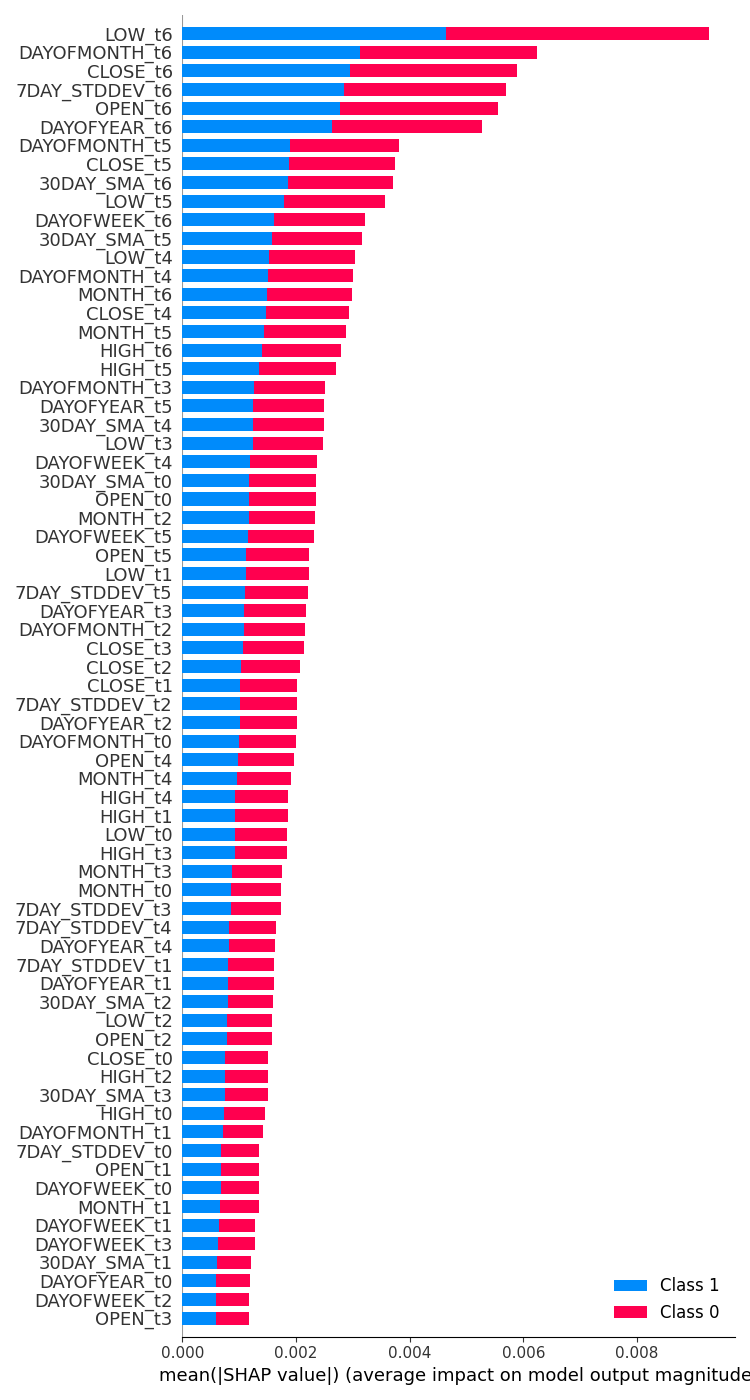 | feature_importance = gru_clf.check_feature_importance(X.columns) 成果。  |
LSTM 分类器特征重要性看起来与我们用简单 RNN 模型获得的特征重要性有点相似。重要性最少的变量来自较远的时间步骤,而重要性最高的特征是来自较近时间步骤的变量。
这就像说,对当前柱线变化贡献最大的变量是最近收盘的柱线信息。
GRU 分类器有不同的观点,这似乎没有多大意义。这可能是因为它的模型精度较低。
它说的是影响最大的变量是前 7 天的星期几。来自时间步骤值 6(即最新信息)的开盘价、最高价、最低价、和收盘价等特征被放置在中间,表明它们对最终预测结果的贡献比较平均。
策略测试器上的 LSTM 与 GRU 分类器
训练后不久,LSTM 和 GRU 分类器模型都保存为 ONNX 格式。
LSTM | Python
lstm_clf.build_compile_and_train(best_params, verbose=1) # best_params = best parameters obtained after optimization lstm_clf.save_onnx_model("lstm.EURUSD.D1.onnx")
GRU | Python
gru_clf.build_compile_and_train(best_params, verbose=1) gru_clf.save_onnx_model("gru.EURUSD.D1.onnx") # best_params = best parameters obtained after optimization
将 ONNX 模型及其定标器文件保存在 MQL5\Files 目录下之后,我们可将文件作为资源文件添加到两个智能系统当中。
| LSTM | GRU |
|---|---|
#resource "\\Files\\lstm.EURUSD.D1.onnx" as uchar onnx_model[]; //lstm model in onnx format #resource "\\Files\\lstm.EURUSD.D1.standard_scaler_mean.bin" as double standardization_mean[]; #resource "\\Files\\lstm.EURUSD.D1.standard_scaler_scale.bin" as double standardization_std[]; #include <MALE5\Recurrent Neural Networks(RNNs)\LSTM.mqh> CLSTM lstm; #include <MALE5\preprocessing.mqh> StandardizationScaler *scaler; //For loading the scaling technique | #resource "\\Files\\gru.EURUSD.D1.onnx" as uchar onnx_model[]; //gru model in onnx format #resource "\\Files\\gru.EURUSD.D1.standard_scaler_mean.bin" as double standardization_mean[]; #resource "\\Files\\gru.EURUSD.D1.standard_scaler_scale.bin" as double standardization_std[]; #include <MALE5\Recurrent Neural Networks(RNNs)\GRU.mqh> CGRU gru; #include <MALE5\preprocessing.mqh> StandardizationScaler *scaler; //For loading the scaling technique |
智能系统的其余代码与我们曾讨论的相同。
使用自本系列文章的第 24 部分以来一直使用的默认设置,我们从时间序列预测开始。
止损:500,止盈:700,滑点:50。
再次,由于数据是在日线时间帧上收集而来,因此在较低的时间帧上对其进行测试可能是个好主意,以遍避免在“休市错误”时出现错误,因为我们正在新柱线开盘时寻找交易信号。我们还可以将建模类型设置为“开盘价”,从而加快测试速度。

LSTM 智能系统结果


GRU 智能系统结果


我们可以从策略测试器结果中学到什么
尽管模型的准确度较低,只有 44.98%,但基于 LSTM 的智能系统是最有利可图的,净盈利为 138 美元,其次是基于 GRU 的智能系统,尽管总净盈利为 120 美元,但在 45.25% 的时间里盈利。
在这种情况下,LSTM 在盈利方面显然是胜者。尽管 LSTM 在技术上比其它同类 RNN 更聪明,但可能是很多因素导致的这种情况,所有递归模型都很不错,并且在某些状况下可以优于其它模型,请随意使用本文和上一篇文章中讨论的任何模型。
LSTM 和 GRU 神经网络模型之间的差异
比较并理解这些模型有助于判断每个模型相较于其它模型能提供什么。何时应当使用哪个,何时不应当。以下以表格形式列出它们的差异。
| 层面 | LSTM | GRU |
|---|---|---|
架构复杂度 | LSTM 具有更复杂的设计,搭配三个门(输入、输出、遗忘)、和一个单元状态,提供控制细节,如在每个时间步骤保留或舍弃哪些信息。 | GRU 的设计更简单,仅搭配两个门(重置和更新)。这种简单的架构令它们更易于实现。 |
训练速度 | 在 LSTM 中拥有额外的门和单元状态,意味着要完成更多的过程,更多参数需要优化。在训练期间它们的速度较慢。 | 由于门数更少、且操作更简单,故典型情况下它们的训练快于 LSTM。 |
性能 | 在复杂问题中,如捕获长期依赖关系至关重要,往往 LSTM 的性能略好于竞品。 | 对于许多任务,GRU 通常提供与 LSTM 相当的性能。 |
长期依赖关系的处理 | LSTM 的设计明确保留数据中的长期依赖关系,这要归功于单元状态、以及随时间控制信息流的门控机制。 | 而 GRU 也可能很好地处理长期依赖关系,但由于其结构更简单,它们在捕获超长期的依赖关系方面或许不如 LSTM 有效。 |
| 内存用法 | 由于结构复杂、且附加参数众多,LSTM 会消耗更多内存,这在资源制约环境中可能是一个限制。 | 另一方面,GRU 更简单,参数更少,所用内存也更少。它们更适合计算资源有限的应用。 |
后记
LSTM(长-短期记忆)和 GRU(门控递归单元)神经网络都是强力工具,为交易者寻求先进的时间序列预测模型。而 LSTM 提供了更复杂的架构,擅长捕获市场数据中的长期依赖关系,GRU 则提供了一种更简单、更高效的替代品,通常能以更低的计算成本匹敌 LSTM 的性能。
这些时间序列深度学习模型(LSTM 和 GRU)已在外汇交易之外的各个领域所用,例如天气预报、能耗建模、异常检测、和语音识别,且如大肆宣传般取得了巨大成功,然而,在始终变化的外汇市场中,我不能保证这样的承诺。
本文旨在仅提供针对这些模型的深入理解,以及如何将它们部署在 MQL5 中进行交易。您可随意探索并尝试本文中讨论的模型和数据集,并在讨论区分享您的结果。
此致敬意。
跟踪机器学习模型的开发,在 GitHub 存储库 上有更多本系列文章的讨论内容。
附件表
| 文件名 | 文件类型 | 说明/用法 |
|---|---|---|
| GRU EA.mq5 LSTM EA.mq5 | 智能系统 | 基于 GRU 的智能系统。 基于 LSTM 的智能系统。 |
| gru.EURUSD.D1.onnx lstm.EURUSD.D1.onnx | ONNX 文件 | ONNX 格式的 GRU 模型。 ONNX 格式的 LSTM 模型。 |
| lstm.EURUSD.D1.standard_scaler_mean.bin lstm.EURUSD.D1.standard_scaler_scale.bin | 二进制文件 | LSTM 模型的标准化定标二进制文件 |
| gru.EURUSD.D1.standard_scaler_mean.bin gru.EURUSD.D1.standard_scaler_scale.bin | 二进制文件 | GRU 模型的标准化定标器二进制文件 |
| preprocessing.mqh | 包含文件 | 由标准化定标器组成的函数库 |
| lstm-gru-for-forex-trading-tutorial.ipynb | Python 脚本/Jupyter 笔记簿 | 包含本文讨论的所有 python 代码 |
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/15182
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

 数据科学和机器学习(第 27 部分):MetaTrader 5 中训练卷积神经网络(CNN)交易机器人 — 值得吗?
数据科学和机器学习(第 27 部分):MetaTrader 5 中训练卷积神经网络(CNN)交易机器人 — 值得吗?