Redes neurais de maneira fácil (Parte 34): Função quantil totalmente parametrizada

Sumário
- Introdução
- 1. Aspectos teóricos da parametrização completa
- 1.1. Redes de quantil implícitas (Implicit Quantile Networks - IQN)
- 1.2. Função quantil totalmente parametrizada (Fully Parameterized Quantile Function - FQF)
- 2. Implementação usando MQL5
- 3. Teste
- Considerações finais
- Links
- Programas utilizados no artigo
Introdução
Continuamos a explorar os algoritmos de aprendizado Q distribuído. Em artigos anteriores, já analisamos 2 algoritmos. No primeiro [4] nosso modelo aprendeu as probabilidades de receber uma recompensa dentro de uma determinada faixa de valores. No segundo [5], mudamos a abordagem para resolver o problema. E treinamos o modelo para prever o nível de recompensa com uma determinada probabilidade.
É evidente que em ambos os algoritmos, para resolver o problema, precisamos de algum conhecimento prévio sobre a natureza da distribuição de recompensas. No primeiro algoritmo, precisamos fornecer ao modelo os níveis de recompensa esperados. No segundo algoritmo, a tarefa do usuário é um pouco mais simples, pois precisamos especificar um conjunto de quantis cujos tamanhos são normalizados entre 0 e 1 e estão dispostos em ordem ascendente. No entanto, sem o conhecimento da verdadeira distribuição dos valores de recompensa, é difícil determinar o número necessário de quantis e o tamanho de cada um.
Aqui, é importante mencionar que introduzimos a suposição de uma distribuição uniforme para a sequência em análise. E utilizamos intervalos uniformes de quantis. Nesse contexto, a quantidade desses quantis se tornou o principal hiperparâmetro regulador. Tal quantidade é determinada de forma experimental com base em uma amostra de validação.
1. Aspectos teóricos da parametrização completa
Ambos os métodos mencionados exigem o estudo prévio da amostra de treinamento e a otimização dos hiperparâmetros. Contudo, é importante destacar que, ao otimizar os hiperparâmetros, selecionamos valores médios. Em outras palavras, buscamos algo que nos aproxime ao máximo do objetivo desejado. Os parâmetros escolhidos devem satisfazer, na medida do possível, todos os estados possíveis do sistema em análise. Lembrando também da suposição que fizemos sobre a distribuição uniforme, obtemos um modelo repleto de soluções incompletas variadas. Fica evidente que tal modelo estará longe de ser ótimo.
Com o objetivo de alcançar a máxima verossimilhança e minimizar o erro de previsão, somos obrigados a aumentar o número de quantis a serem treinados. Isso resulta em um aumento do tamanho e do tempo necessário para o treinamento do modelo. Na maioria das situações, essa abordagem se mostra pouco eficiente. Entretanto, nosso propósito é estudar o ambiente ao máximo. Surge, então, o interesse em se desviar das categorias fixas de valores no primeiro algoritmo e dos quantis fixos no segundo algoritmo.
1.1. Redes de quantil implícitas (Implicit Quantile Networks - IQN)
Aqui, o uso de quantis parece mais avançado. Concordamos que para definir categorias, é necessário estudar completamente a distribuição inicial e determinar seus limites. Além disso, o modelo não está preparado para valores que estejam fora da faixa especificada. O modelo de categorias não é universal e varia de acordo com a tarefa.
Ao mesmo tempo, as probabilidades de ocorrência de eventos têm limites claros, variando de 0 a 1. Mas o uso de uma distribuição uniforme de quantis limita nossas liberdades e a gama de funções a serem otimizadas. E gostaríamos de encontrar um algoritmo onde o próprio modelo determine a distribuição ótima de quantis sem aumentar o número de quantis.
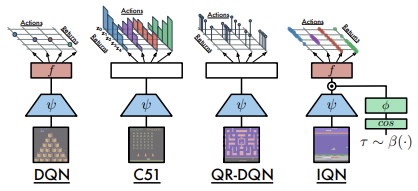
Em julho de 2018, o primeiro algoritmo desse tipo foi proposto no artigo "Implicit Quantile Networks for Distributional Reinforcement Learning". Os autores abordaram o problema do quantil ideal de forma um pouco diferente. Eles desenvolveram seu algoritmo com base no QR-DQN, que já havia sido discutido. No entanto, em vez de procurar pelos quantis ideais, os autores optaram por gerá-los aleatoriamente e alimentá-los junto com os dados iniciais que descrevem o estado do ambiente na entrada do modelo. A ideia é que, durante o processo de aprendizado, o mesmo conjunto de estados do sistema seja alimentado na entrada do modelo com diferentes distribuições de quantis. Como resultado, o modelo será forçado a usar uma aproximação completa da função quantil, em vez de apenas uma fatia específica.
Esta abordagem permite treinar um modelo que é menos sensível ao hiperparâmetro do número de quantis. E sua distribuição aleatória torna possível ampliar a gama de funções aproximadas para funções não uniformemente distribuídas.
Antes de ser inserido na entrada do modelo, é criado uma incorporação de quantis gerados aleatoriamente, utilizando a fórmula apresentada abaixo.
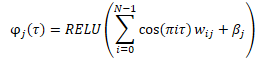
Durante o processo de combinação da incorporação resultante com o tensor de dados de entrada, existem várias possibilidades. Isso pode ser feito através de uma simples concatenação de dois tensores ou por meio da multiplicação adamar (elemento por elemento) de duas matrizes.
Abaixo está uma comparação das arquiteturas consideradas, conforme apresentadas pelos autores do artigo.
A eficácia do modelo de aprendizado Q foi confirmada por meio de testes em 57 jogos Atari. Abaixo podemos observar uma tabela comparativa retirada do artigo original [8].
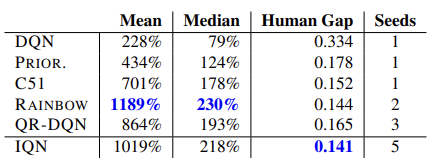
Hipoteticamente, dado o tamanho não limitado do modelo, esta abordagem permite que qualquer distribuição da recompensa prevista possa ser aprendida.
1.2. Função quantil totalmente parametrizada (Fully Parameterized Quantile Function - FQF)
O modelo de redes de quantis implícitas apresentado tem capacidade de aproximar diversas funções. Contudo, esse processo está relacionado ao crescimento do próprio modelo, o que pode limitar sua aplicação na prática devido aos recursos limitados disponíveis. Além disso, há o risco de obtenção de valores subótimos ao gerar quantis aleatórios, tanto durante o treinamento quanto durante seu uso prático.
Em novembro de 2019, foi proposto um modelo denominado "Fully Parameterized Quantile Function for Distributional Reinforcement Learning" que, essencialmente, é a mesma coisa que o modelo IQN.
A diferença é que em vez de um gerador de quantis aleatórios, é usada uma camada neural totalmente acoplada que retorna uma distribuição de quantis com base no estado atual do ambiente alimentado à entrada. Com este modelo, é possível gerar uma distribuição quantitativa para cada par de valores de ação estatal, permitindo assim, uma aproximação da distribuição ótima da recompensa esperada para cada ação em um determinado estado do sistema. Isso foi explicado no início deste artigo.
Ao realizar a normalização dos dados na saída da camada neural usando a função SoftMax e, em seguida, a adição cumulativa de elementos do vetor normalizado, é possível manter os requisitos básicos de quantil, que consistem no aumento no intervalo entre 0 e 1.
No artigo original, os autores apresentam os resultados de testes de um novo algoritmo em 55 jogos Atari. Abaixo está uma tabela resumida dos resultados do artigo original. Os dados apresentados demonstram a superioridade do algoritmo de parametrização completa da função quantil em relação a outros algoritmos de aprendizado Q distribuídos. No entanto, essa vantagem foi alcançada à custa do desempenho do modelo, já que um modelo adicional de geração de quantis requer recursos computacionais adicionais.
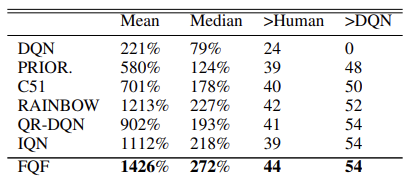
Além disso, os autores do método realizaram experimentos para determinar o número ideal de quantis e sugerem o uso de uma distribuição de 32 quantis.
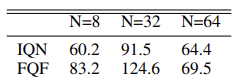
Eu sugiro que você aprenda o algoritmo do método através da sua implementação.
2. Implementação usando MQL5
No seu trabalho, os autores do método de parametrização completa da função quantil mencionam o uso de duas redes neurais - uma para gerar a distribuição de quantis e outra para aproximar a função quantil. No entanto, o algoritmo descrito acima também utiliza uma terceira rede neural convolucional que cria uma incorporação do estado do ambiente. É essa incorporação do estado que é os dados de entrada para o algoritmo em questão.
No entanto, a biblioteca que construímos anteriormente está focada na construção de modelos consistentes. E não criamos um algoritmo para transferir o gradiente de erro entre modelos. O que pode ser necessário no treinamento de vários modelos consecutivos.
Naturalmente, podemos aproveitar o mecanismo de transferência de aprendizado e treinar cada modelo individualmente. No entanto, decidi implementar todo o algoritmo dentro de um único modelo.
Para criar uma incorporação do estado do ambiente, são utilizados modelos de convolução, que já conhecemos [1]. Dessa forma, podemos facilmente construir um modelo semelhante com as ferramentas disponíveis.
Em seguida, temos que implementar o algoritmo FQF. Na minha opinião, a maneira mais simples de implementá-lo dentro do conceito da nossa biblioteca é criar uma nova classe de camada neural. Essa classe receberá como entrada a incorporação do estado atual do sistema sendo analisado e produzirá como saída a ação do agente correspondente. Dessa forma, dentro da nova classe, construiremos o agente do nosso modelo.
Vamos criar uma nova classe chamada CNeuronFQF que será uma subclasse da classe base da camada neural CNeuronBaseOCL. Na nova classe, iremos redefinir o conjunto padrão de métodos e, no bloco protegido, declararemos os objetos internos que usaremos na implementação do algoritmo FQF. A finalidade desses objetos será explicada durante a construção do algoritmo.
Em nossa classe, usamos objetos internos estáticos, o que nos permite deixar o construtor e o destruidor da classe vazios.
A classe e os objetos internos são inicializados no método Init. Para o processo de inicialização de objetos internos, precisaremos dos seguintes parâmetros:
- numOutputs — número de neurônios na próxima camada
- myIndex — índice do neurônio atual na camada
- open_cl — ponteiro para o objeto de trabalho com OpenCL
- actions — número de ações possíveis de um agente
- quantiles — número de quantis
- numInputs — tamanho da camada neural anterior
- optimization_type — função a ser utilizada para otimizar os parâmetros do modelo
- batch — tamanho do parâmetro de atualização do modelo.
No corpo do método, não definimos um bloco para verificar os parâmetros recebidos. Em vez disso, chamamos imediatamente um método similar da classe pai, que já contém todos os controles necessários. O método da classe pai controla os parâmetros externos e inicializa os objetos herdados. Portanto, após ser executado com sucesso, só precisamos inicializar os objetos recém-declarados.
Lembre-se também de desativar a função de ativação do objeto. Todas as funções de ativação necessárias são definidas pelo algoritmo e serão especificadas para objetos internos.
De acordo com o algoritmo FQF, a incorporação do estado do sistema é fornecida como entrada na rede geradora de quantis. Para isso, os autores do método utilizaram uma única camada totalmente conectada com normalização de dados usando a função SoftMax. Em nossa implementação, haverá dois objetos: uma camada totalmente conectada sem função de ativação e uma camada SoftMax.
Como vamos gerar uma distribuição de quantis para cada ação possível, o tamanho das camadas utilizadas será definido como o produto do número de ações possíveis pelo número de quantis especificado. No caso da SoftMax, também normalizaremos os dados em relação às ações.
Em seguida, conforme o algoritmo, precisamos criar uma incorporação dos quantis obtidos. Faremos isso em duas etapas. Primeiro, preparamos os dados e os armazenamos no buffer da camada neural cCosine. Em seguida, passamos pela camada totalmente conectada cCosineEmbeding com a função de ativação ReLU. Outra função desempenhada pela camada cCosineEmbeding é alinhar o tamanho do tensor de incorporação com o tamanho dos dados de entrada para a subsequente multiplicação de tensores.
Por fim, temos que passar os dados através do modelo de função quantil. Este conterá uma camada oculta totalmente conectada com número de neurônios igual a quatro vezes o produto do número de ações e quantidade de quantis, e uma função de ativação ReLU. Além disso, haverá uma camada totalmente conectada sem função de ativação na saída. O tamanho da camada de resultado é igual ao produto do número de ações possíveis pelo número de quantis.
Durante a implementação do método, não se esqueça de monitorar a execução das operações. Após a inicialização bem-sucedida de todos os objetos internos, saia do método com um resultado positivo.
2.1. Propagação
Após a inicialização dos objetos, passamos à construção do processo de propagação. Mas antes de começarmos a criar o método CNeuronFQF::feedForward, temos que criar os kernels faltantes no OpenCL. O trabalho das camadas neurais já foi totalmente implementado, mas a nova funcionalidade ainda precisa ser implementada.
De acordo com o algoritmo FQF, os dados brutos na forma de uma incorporação do estado atual são direcionados para o modelo de geração de quantis. A operação das duas camadas neurais (totalmente conectadas cFraction e cSoftMax) é implementada. No entanto, a partir da SoftMax, obtemos um tensor com a soma dos valores para cada ação igual a 1. Precisamos, por outro lado, aumentar as frações dos quantis. Depois disso, será necessário criar as incorporações desses quantis usando a fórmula a seguir.
A fórmula mencionada é exatamente a mesma de uma camada neural totalmente conectada com uma função de ativação ReLU. Apenas os dados de entrada são cos(πiт). O tensor desses cossenos será preparado no buffer de resultados da camada neural cCosine.
Para implementar essa funcionalidade, vamos criar um kernel FQF_Cosine. Vamos alimentar o kernel com dois ponteiros para os buffers de dados. Um deles conterá os dados da camada SoftMax. No segundo, registraremos os resultados do nosso kernel.
Lembre-se de que o algoritmo FQF prevê a criação de quantis para cada ação possível. Portanto, construiremos o algoritmo do kernel levando em consideração um espaço bidimensional de tarefas. Em uma dimensão, os quantis serão dispostos, e na outra, as possíveis ações do agente.
No corpo do kernel, identificamos imediatamente o identificador do fluxo em ambas as dimensões. Também solicitamos o número total de fluxos na primeira dimensão, o que nos ajudará a determinar o deslocamento nos tensores antes do primeiro quantil da ação analisada.
Em seguida, precisamos calcular a parte acumulada do quantil atual, o que faremos em um ciclo.
Considerando o exposto, é importante prestar atenção na abordagem utilizada. Com o algoritmo QR-DQN, não se determina o limite superior do quantil, mas sim seu valor médio. Dessa forma, é necessário somar a fração de todos os quantis anteriores determinados pela SoftMax na etapa anterior e adicionar metade da fração do quantil atual.
Finalmente, podemos escrever o cosseno do produto do valor médio do quantil atual, o número pi e o número ordinal do quantil.
Realizaremos outras operações para criar a incorporação de quantis utilizando a funcionalidade da camada interna cCosineEmbeding. No entanto, em seguida, temos a operação de multiplicação de Hadamard do tensor de incorporação de quantis pelo tensor de dados de origem (a incorporação do estado do sistema). Precisaremos de outro kernel para realizar essa operação. Mas antes de criar um novo kernel, observei as redes neurais já existentes e criadas anteriormente. Minha atenção foi atraída pelo kernel que criamos para a camada Dropout. Lembre-se de que, para o funcionamento dessa camada, criamos um kernel no qual multiplicamos o tensor de coeficientes pelos dados de entrada, elemento por elemento. Agora, temos que realizar uma operação matemática semelhante, mas com dados diferentes e com o significado lógico da operação diferente. Como você pode perceber, o processo de operações matemáticas não é afetado. Portanto, utilizaremos com segurança uma solução já pronta.
A seguir, estão as operações da rede de quantis, que implementamos como um perceptron com uma camada oculta. A saída deste perceptron produzirá uma distribuição de recompensa esperada semelhante ao modelo QR-DQN. No entanto, em contraste com o método anteriormente discutido, uma distribuição de probabilidade diferente é usada para cada ação possível do agente. Para obter um valor de recompensa discreto, precisamos multiplicar o nível de recompensa de cada quantil pela sua probabilidade e somar esses valores para cada ação do agente.
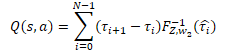
Em nosso caso específico, todos os deltas de probabilidade já foram calculados no buffer de resultados da camada cSoftMax. E agora, precisamos apenas multiplicar o valor desse buffer pelos resultados do buffer da função quantil do perceptron proveniente da camada neural cQuantile2. Somaremos o resultado dessa operação em termos das possíveis ações dos agentes.
Criaremos um novo kernel, FQF_Output, para realizar as operações especificadas. Nos parâmetros do kernel, forneceremos ponteiros para três buffers de dados: resultados da função quantil, deltas de probabilidade e buffer de resultados. Também indicaremos a quantidade de quantis.
Executamos o núcleo em um espaço unidimensional de tarefas, que corresponde ao número de ações de agentes possíveis.
No corpo do núcleo, primeiro consultamos o identificador do fluxo e determinamos a mudança nos buffers de dados para o vetor de distribuição de quantis correspondente.
Em seguida, no loop, realizamos uma multiplicação do vetor de probabilidade pelo vetor de distribuição de quantis. E escrevemos o resultado da operação no buffer de resultados apropriado.
Observe que o buffer de resultados será muito menor do que os buffers de dados da fonte. Como ele contém apenas um valor discreto para cada possível ação de agente. Considerando que os dados originais contêm todo um vetor de valores para cada ação. Assim, a compensação no buffer de resultados é o identificador da linha atual.
Executamos todo o algoritmo de propagação FQF e criamos os núcleos que faltam. Agora podemos voltar a trabalhar em nossa classe e repetir todo o algoritmo usando o MQL5. Como de costume, anulamos o método CNeuronFQF::feedForward para realizar a propagação.
Nos parâmetros, o método de propagação recebe um ponteiro para a camada neural anterior, cujo buffer de resultados (esperamos) contém a incorporação do estado atual do sistema.
No corpo do método, não criamos um bloco de controle para os dados de entrada. Em vez disso, chamamos imediatamente os métodos de propagação das camadas neurais internas cFraction e cSoftMax. A ausência do bloco de controle de dados de entrada neste caso não apresenta riscos, já que cada um dos métodos chamados possui seu próprio bloco de controle. Só precisamos verificar o resultado das operações dos métodos chamados.
Em seguida, precisamos criar uma incorporação dos níveis de probabilidade dos quantis. Neste ponto, primeiro chamamos o kernel de preparação de dados FQF_Cosine, criado anteriormente. Este kernel funciona em um espaço bidimensional de tarefas. Na primeira dimensão, especificamos o número de quantis. E, na segunda dimensão, o número de ações possíveis que um agente pode realizar.
Vale ressaltar que não criamos variáveis internas para os hiperparâmetros especificados. No entanto, o tamanho do buffer de resultados da camada CNeuronFQF é igual ao número de ações possíveis do agente. E podemos determinar o número de quantis como a relação entre o buffer de resultados da camada cSoftMax e o número de ações.
Passamos os ponteiros dos buffers para os parâmetros do kernel e enviamos o kernel para a fila de execução. Ao fazer isso, não esquecemos de monitorar o andamento das operações em cada etapa.
A seguir, chamamos o método cCosineEmbeding da camada neural interna, que completa o processo de incorporação de quantil.
Na próxima etapa do algoritmo FQF, precisamos combinar a incorporação do estado atual do sistema (dados de entrada) com a incorporação dos quantis. Como você deve se lembrar, para esta operação decidimos usar o kernel da camada neural Dropout. No corpo deste kernel, utilizamos operações vetoriais em vetores de 4 elementos. Portanto, o número de threads será 4 vezes menor do que o tamanho dos buffers de dados.
Transferimos os dados necessários aos parâmetros do kernel. Em seguida, colocamos o kernel na fila de execução.
Agora precisamos determinar os níveis da distribuição de quantis. Para fazer isso, chamamos sequencialmente os métodos de propagação das camadas neurais da nossa função perceptron de quantil.
Ao concluir o método de propagação, chamaremos o kernel FQF_Output para converter a distribuição de quantis em um valor discreto da recompensa esperada para cada possível ação do agente. O procedimento para colocar o kernel na fila de execução permanece o mesmo:
- definimos o espaço de tarefas
- passamos indicações para buffers e outras informações necessárias para os parâmetros do kernel
- chamamos os procedimentos para execução do kernel.
E lembre-se de monitorar o processo de execução das operações em cada etapa.
Terminamos o trabalho na propagação de nossa classe e agora passamos para a redefinição dos métodos de retropropagação. Na nossa classe, esses métodos serão representados por dois métodos: "calcInputGradients" e "updateInputWeights".
2.2. Retropropagação
O primeiro método que vamos analisar é o calcInputGradients, que transfere o gradiente para todas as camadas internas e para a camada neural anterior.
O método indicado é exatamente o mesmo que o método de propagação, só que na direção oposta. Assim, para todos os kernels que foram criados durante a propagação, devem ser criados kernels com operações "espelho". E como todo o processo de retropropagação é executado na sequência inversa da propagação, construiremos os kernels de maneira semelhante.
Na saída do método de propagação, convertemos a distribuição de quantis em um valor discreto para cada possível ação do agente. Na entrada do método de propagação, esperamos obter um gradiente de erro para cada ação. E temos que alocar o gradiente resultante tanto para o valor da função quantil quanto para os deltas das probabilidades da faixa de quantil.
Implementaremos esta função no kernel FQF_OutputGradient. Nos parâmetros do kernel, passaremos ponteiros para 5 buffers de dados de uma vez. 3 deles conterão os dados brutos e 2 para registrar os resultados do kernel.
Lembrando que nossos tensores de probabilidade delta e resultados da função quantil são estruturados com lógica tabular em termos de quantis e possíveis ações dos agentes. Da mesma forma, executaremos o kernel no espaço bidimensional de tarefas em termos de quantis e ações dos agentes.
No corpo do kernel, solicitamos imediatamente os identificadores de linha em ambas as dimensões, o número de fluxos na primeira dimensão e determinamos o viés nos buffers de dados.
Em seguida, temos que alocar o gradiente de erro. Na propagação, obtivemos o resultado multiplicando duas variáveis. A derivada da operação de multiplicação é o segundo multiplicador. Consequentemente, para transferir o gradiente, precisamos multiplicar o gradiente de erro resultante pelo elemento correspondente do tensor oposto.
Note que precisamos multiplicar um elemento do buffer dos gradientes resultantes pelos elementos correspondentes dos dois tensores. Isso significa que teremos que acessar o mesmo item de buffer global duas vezes. No entanto, sabemos que acessar itens de memória global é "caro". Para reduzir o tempo total de execução, primeiro transferimos o valor do item de buffer global para a variável de memória privada mais rápida. Em seguida, realizaremos as demais operações com essa variável "rápida".
Armazene os resultados das operações nos itens correspondentes nos 2 buffers de resultados.
O próximo kernel que chamamos diretamente do nosso método de propagação é o Dropout. Nele, realizamos a multiplicação elementar de dois tensores de incorporação: o estado do ambiente e os quantis. Se usássemos o kernel Dropout criado anteriormente para a propagação, agora precisaríamos chamar o kernel duas vezes consecutivas com dados de entrada diferentes para alocar o gradiente de erro em duas direções. No entanto, nosso objetivo é o máximo paralelismo de operações, a fim de minimizar o tempo de treinamento do modelo. Assim, dedicaremos um pouco do nosso tempo e criaremos um novo kernel chamado FQF_QuantileGradient.
Percebe-se que o algoritmo deste kernel é exatamente o mesmo do kernel anterior. Não há nada de estranho nisso, pois ambos os kernels desempenham uma função semelhante. A única diferença está no deslocamento no buffer dos gradientes resultantes. No caso anterior, o tamanho do buffer de gradientes recebidos era diferente dos outros buffers, pois tinha apenas um valor discreto para cada possível ação do agente. Neste caso, todos os buffers têm o mesmo tamanho. E, consequentemente, no buffer de gradientes, usamos um deslocamento semelhante aos demais buffers.
O último kernel que precisamos considerar é o FQF_CosineGradient, que realiza o procedimento inverso à preparação de dados para a incorporação de quantis. A derivada da operação de preparação de dados tem a seguinte forma:
![]()
Como resultado das operações deste kernel, esperamos obter um gradiente de erro na saída da camada SoftMax do modelo de previsão de probabilidade de quantis. Aqui, vale ressaltar que cada quantil utilizou o valor acumulado do tensor de resultados SoftMax. Isso significa que cada elemento do tensor influenciou todos os quantis subsequentes. Sendo assim, seria lógico que cada elemento do tensor recebesse sua parte do gradiente de acordo com sua participação no resultado final. Portanto, coletaremos o gradiente de erro de todos os elementos do buffer de gradientes recebidos que foram influenciados pelo elemento do tensor de resultados SoftMax em análise.
Considere a implementação do kernel. Nos parâmetros, passamos apontadores para 3 buffers de dados:
- resultados da camada SoftMax
- gradientes de erro obtidos
- buffer de resultados — gradientes de erro a nível do buffer de resultados da camada SoftMax.
Assim como a maioria dos kernels discutidos neste artigo, este kernel será executado em um espaço de tarefas bidimensional. Uma dimensão de quantis e a outra de possíveis ações dos agentes.
No corpo do kernel, solicitamos IDs de fluxo em ambas as dimensões e determinamos o deslocamento nos buffers de dados. Todos os buffers de dados têm o mesmo tamanho. Consequentemente, o deslocamento também será igual para todos os buffers de dados.
Cada elemento influencia apenas o seu próprio quantil e os quantis subsequentes. Portanto, primeiro, vamos simplesmente calcular a soma dos elementos anteriores.
E depois calcular o gradiente a partir do elemento relevante.
É importante observar que, na propagação, passamos o valor médio do quantil para a incorporação. Assim, calculamos o gradiente de erro usando o valor médio da probabilidade do quantil.
Em seguida, em um loop semelhante, determinamos o gradiente de erro a partir dos quantis subsequentes. Ao fazer isso, ajustaremos o efeito do gradiente de acordo com a proporção do elemento atual na probabilidade total do gradiente do quantil.
Após completar as iterações do loop, escrevemos o resultado das operações no elemento apropriado do buffer de resultados.
Nesta fase, preparamos todos os kernels para fazer a retropropagação de nossa classe. E podemos proceder a criar diretamente o método de distribuição do gradiente de erro, calcInputGradients.
Nos parâmetros, o método recebe um ponteiro para o objeto da camada neural anterior, para o qual devemos passar o gradiente de erro. E, dentro do método, fazemos um bloco de verificações. Aqui, verificamos os ponteiros para o objeto recebido e os buffers de dados internos.
Observe que, diferentemente do método de propagação, criamos aqui um bloco de controle. Isso ocorre porque as operações deste método começam com uma chamada ao kernel do OpenCL. E ao passar ponteiros para os buffers de dados para ele, devemos ter certeza de que eles existem. Caso contrário, corremos o risco de um erro crítico na execução das operações.
Após passar com sucesso pelo bloco de controle, prosseguimos com a execução direta das operações de distribuição do gradiente de erro. Primeiramente, chamamos o kernel FQF_OutputGradient, no qual alocamos o gradiente de erro para a função quantil perceptron e o bloco de previsão de quantis. As operações de enfileiramento do kernel são semelhantes às operações de propagação correspondentes. O kernel funciona em um espaço bidimensional de tarefas. A primeira dimensão corresponde aos quantis e a segunda às possíveis ações do agente.
Em seguida, passamos o gradiente de erro através da função quantil perceptron. Para isso, chamaremos sequencialmente os métodos de retropropagação das camadas neurais internas do bloco especificado.
Precisamos alocar o gradiente de erro da função quantil para a incorporação do estado atual do sistema (a camada neural anterior) e para a incorporação das probabilidades de quantis. Para realizar esta função, criamos o kernel FQF_QuantileGradient. Chamamos o kernel mencionado usando um procedimento já testado.
Na etapa seguinte, conduzimos o gradiente de erro através da incorporação de quantis. Primeiramente, chamamos o método de retropropagação da camada neural interna cCosine.
E chamamos o kernel FQF_CosineGradient, utilizando um procedimento que já elaboramos.
No final do método, conduzimos um gradiente de erro através da camada interna cSoftMax, chamando seu método de retropropagação.
Note que não passamos o gradiente de erro da camada de previsão de probabilidade dos quantis para a camada anterior. Isso está relacionado à prioridade na tarefa de determinar a recompensa esperada, em vez da distribuição de probabilidade.
O segundo método do retropropagação, updateInputWeights, que precisamos sobrescrever, é responsável pela funcionalidade de atualização dos parâmetros do nosso modelo. E aqui tudo é bastante simples. Apenas chamamos os métodos homônimos dos camadas neurais internas em sequência e verificamos o resultado da execução das operações.
Com isso, concluímos o trabalho com a funcionalidade principal da nossa nova classe CNeuronFQF. Acima, discutimos a elaboração dos processos de propagação e retropropagação. Na classe, também foram sobrescritos os métodos de salvamento de dados em arquivo e recuperação da funcionalidade da classe após o salvamento. Nestes, apenas chamamos os métodos correspondentes dos objetos internos em sequência. E convido você a se familiarizar com a construção deles por conta própria. O código completo de todas as classes e métodos utilizados pode ser encontrado no anexo do artigo.
Agora seguimos em frente. Acima, construímos uma classe para elaborar o algoritmo de treinamento do modelo usando o método de parametrização completa da função quantil. Porém, isso é apenas parte do processo. Ainda é o mesmo aprendizado Q com o uso de buffer de dados e Target Net. E, para facilitar o uso do método descrito diretamente no processo de aprendizado Q, foi criada a classe CFQF, herdeira da classe base de nossos modelos, CNet.
A classe foi criada de maneira similar à classe CQRDQN do artigo anterior, e sua estrutura é praticamente idêntica à mencionada classe. Removemos apenas as variáveis não utilizadas e a matriz de probabilidades, pois essas funções são desempenhadas por camadas neurais específicas. Dessa forma, também alteramos os métodos da classe. Não vou detalhar todos os métodos da classe agora, mas você pode consultá-los no anexo. Vou abordar apenas alguns deles.
Inicialmente, sugiro focar no método de retropropagação. Este método recebe como parâmetros os valores-alvo e o próximo estado do sistema. Vale ressaltar que o próximo estado do sistema é um parâmetro opcional. Isso pode ser útil ao treinar um novo modelo, já que utilizar um modelo não treinado para prever recompensas futuras apenas adicionaria ruído e complicaria o processo de aprendizado.
No corpo do método, verificamos se existe um parâmetro obrigatório na forma de um buffer de valores-alvo.
Posteriormente, verificamos a existência do parâmetro opcional e, caso necessário, realizamos previsões de recompensas futuras. Neste momento, também ajustamos os valores-alvo levando em consideração o valor da recompensa futura e o fator de desconto.
Após isso, verificamos se a Target Net precisa ser atualizada.
E ao final do método, vamos chamar o método de propagação da classe mãe.
O método de seleção da ação gananciosa também foi alterado. Aqui nós simplesmente identificamos o item com a recompensa máxima a partir do buffer de resultados do modelo.
Também foram feitas mudanças no método de amostragem da ação getSample. Nele, primeiro obtemos o resultado da última propagação do modelo.
Copiamos os dados recebidos do buffer para um vetor e, em seguida, aplicamos a função SoftMax a esse vetor. Após isso, calculamos as somas cumulativas dos valores do vetor.
O vetor resultante é uma espécie de distribuição quantil das probabilidades de ação do agente. A partir dessa distribuição, amostramos um valor e o retornamos para o programa que fez a chamada.
Em cada etapa, verificamos o resultado das operações. Se ocorrer um erro, retornamos "-1" para o programa de chamada.
Com isso, concluímos a nossa análise dos algoritmos para a construção de novas classes a fim de implementar o algoritmo FQF. O código completo de todas as classes e seus métodos pode ser encontrado no anexo.
3. Teste
Para treinar o modelo usando o método de uma função quantil totalmente parametrizada, criamos um EA chamado "FQF-learning.mq5". Esse EA é praticamente idêntico ao algoritmo usado no Expert Advisor "QRDQN-learning.mq5" descrito no artigo anterior. Apenas mudamos o nome do arquivo e os objetos utilizados. Por isso, não vamos entrar em detalhes sobre a arquitetura de seus algoritmos. O código completo do EA está disponível no anexo.
O modelo foi treinado com base nos dados históricos do par EURUSD dos últimos 2 anos, no período gráfico H1, utilizando os parâmetros padrão para todos os indicadores. É importante notar que esses são os mesmos parâmetros de teste utilizados em todos os modelos descritos nesta série de artigos.
Quero destacar que durante o processo de treinamento, a modelagem apresentou uma progressão suave e constante na redução do erro, o que indica uma estabilidade positiva no treinamento do modelo.
O modelo treinado foi testado no testador de estratégia usando o EA "FQF-learning-test.mq5", que foi criado com o propósito de teste. Esse EA é uma cópia do EA "QRDQN-learning-test.mq5" descrito no artigo anterior, e não iremos analisar seu algoritmo agora, pois a única diferença é o nome do arquivo e a classe do modelo. O código completo do EA está disponível no anexo.
Durante os testes, o modelo demonstrou ser capaz de gerar lucros. Os resultados dos testes mostraram um fator de lucro de 1,78 e um fator de recuperação de 3,7. Além disso, a proporção de negociações lucrativas foi superior a 57%, e o maior negócio lucrativo foi quase 2,5 vezes maior do que o maior negócio perdedor. A série mais longa de negociações lucrativas foi de 10 negociações, enquanto a série mais longa de negociações perdedoras não ultrapassou 4 negociações. Em geral, o lucro médio por negociação lucrativa foi cerca de ⅓ maior do que a perda média por negociação perdedora.


Considerações finais
Neste artigo, continuamos nosso estudo sobre algoritmos de aprendizado por reforço distribuído e construímos classes para implementar o método de aprendizado de função quantil totalmente parametrizado durante o aprendizado por reforço. Treinamos o modelo usando esse método e testamos o desempenho do modelo treinado no testador de estratégia. É importante destacar que o método mostrou uma dinâmica constante e estável na redução de erros durante o processo de treinamento, e durante os testes no testador de estratégia, foi possível observar a capacidade do modelo em gerar lucro.
Mais uma vez, gostaria de lembrar que a negociação na bolsa de valores é um método de investimento de alto risco. Os programas apresentados neste artigo são destinados apenas a demonstrar o funcionamento dos métodos e algoritmos, e não estão prontos para serem usados no trading real. No entanto, é possível criar ferramentas de negociação funcionais com base neles. Antes de utilizar essas ferramentas, elas devem ser testadas minuciosamente em todos os aspectos. Os riscos de utilizar os programas no trading real devem ser avaliados e aceitos pelo usuário.
Links
- Нейросети — это просто (Часть 3): Сверточные сети
- Нейросети — это просто (Часть 12): Dropout
- Нейросети — это просто (Часть 26): Обучение с подкреплением
- Нейросети — это просто (Часть 27): Глубокое Q-обучение (DQN)
- Нейросети — это просто (Часть 28): Policy gradient алгоритм
- Нейросети — это просто (Часть 32): Распределенное Q-обучение
- Нейросети — это просто (Часть 33): Квантильная регрессия в распределенном Q-обучении
- A Distributional Perspective on Reinforcement Learning
- Distributional Reinforcement Learning with Quantile Regression
- Implicit Quantile Networks for Distributional Reinforcement Learning
- Fully Parameterized Quantile Function for Distributional Reinforcement Learning
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | FQF-learning.mq5 | Expert Advisor | EA para otimização de modelos |
| 2 | FQF- teste de aprendizagem.mq5 | Expert Advisor | EA para prova do modelo no testador de estratégia |
| 3 | FQF.mqh | Biblioteca de classes | Classe de organização do modelo FQF |
| 4 | NeuroNet.mqh | Biblioteca de classes | Biblioteca para preparar modelos de redes neurais |
| 5 | NeuroNet.cl | Biblioteca | Biblioteca de código OpenCL para manusear modelos de redes neurais |
| 6 | NetCreator.mq5 | Expert Advisor | Ferramenta para construção de modelos |
| 7 | NetCreatotPanel.mqh | Biblioteca de classes | Biblioteca da classe para criação da ferramenta |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/11804
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Obrigado!
Sua "produtividade" é surpreendente. Não pare!
São pessoas como você que mantêm tudo funcionando!
P.S..
Estive lendo as notícias da NeuroNet....
"Нейросети тоже нуждаются в состояниях, напоминающих сны.
Esta é a conclusão a que chegaram os pesquisadores do Laboratório Nacional de Los Alamos..."
Bom dia.
Usando seu código, fiz um "Sleep" semelhante do NeuroNetwork.
A porcentagem de "previsão" aumentou em 3%. Para o meu "Supercomp", é um voo para o espaço!
Apliquei esse recurso no final de cada época de treinamento:
Você poderia testar e depois comentar como fez isso? De repente, os "sonhos" poderiam ajudar a IA?
P.S.
SleepPerriod=1;
Adicionei a
onde Delta=0. Mas meu computador é muito, muito fraco.... :-(
A arquitetura nn é semelhante à do artigo anterior, exceto pela última camada?
Sim