
取引におけるニューラルネットワーク:階層型ダブルタワーTransformer(最終回)

はじめに
前回の記事では、複雑な多変量時系列の分析と予測のために特別に開発されたHidformerフレームワークの理論的側面を検討しました。このモデルは、その独自のアーキテクチャにより、動的でボラティリティの高いデータを処理するうえで高い有効性を示しています。
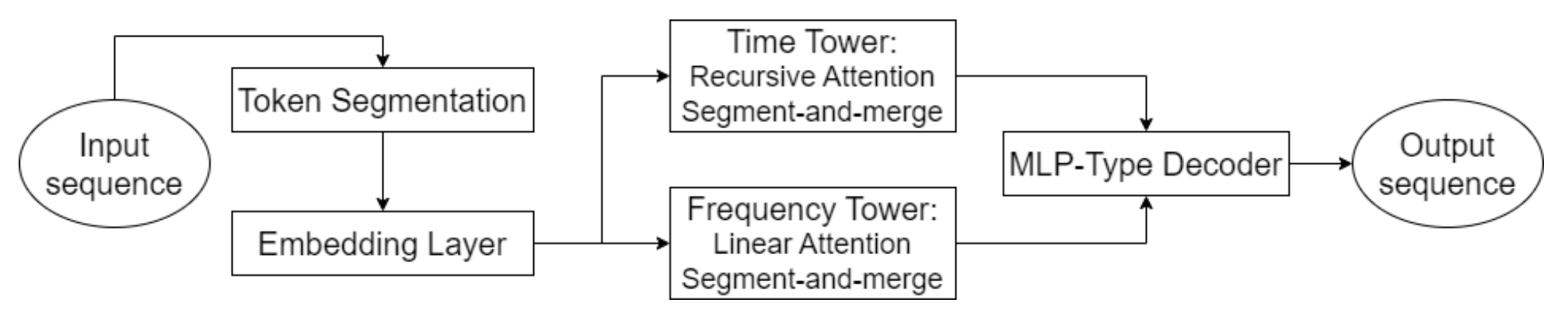
Hidformerの重要な要素のひとつは、高度なアテンション機構の活用です。これにより、データ内の明示的な依存関係を特定するだけでなく、深層に潜む潜在的な関係性を明らかにすることが可能になります。この目的のために、本モデルでは2つのタワーからなるエンコーダーを採用しており、各タワーは生データを独立して分析します。一方のタワーは時間構造の分析に特化し、トレンドやパターンを識別します。もう一方は周波数領域においてデータを解析します。このアプローチにより、市場ダイナミクスを包括的に理解できるようになり、価格系列における短期および長期の変動の両方を考慮することが可能になります。
このモデルの革新的な側面として、時間的依存関係を分析するための再帰型アテンション機構の採用が挙げられます。これにより、金融商品に内在する複雑で動的なパターンに関する情報を逐次的に蓄積することができます。これと組み合わされているのが、入力データの周波数スペクトルを解析するための線形アテンション機構です。この構成により、計算コストを最適化し、学習の安定性を確保することが可能になります。その結果、Hidformerフレームワークは、入力データの多次元性および非線形性に効果的に適応し、高い市場ボラティリティ環境下においても、より信頼性の高い予測を提供します。
多層パーセプトロンに基づいて構築されたモデルのデコーダーは、価格系列全体を一度に予測することを可能にし、逐次予測に典型的な誤差の累積を最小限に抑えます。これにより、長期予測の品質が大幅に向上し、金融分析における実務的な応用において特に価値の高いモデルとなっています。
Hidformerフレームワークのオリジナルの視覚化を以下に示します。
前回の記事の実践セクションでは、前処理作業を完了し、再帰型アテンションおよび線形アテンションアルゴリズムの独自実装をおこないました。本記事では、Hidformerフレームワークの著者らが提案したアプローチの開発をさらに継続していきます。
時系列分析
Hidformerフレームワークの著者らは、2つのタワーから構成されるエンコーダーアーキテクチャを提案しており、私たちはこれを基盤として採用しました。実装では、各エンコーダタワーを独立したオブジェクトとして表現しており、さまざまなタスクに柔軟に適応できるようになっています。ただし、元のフレームワークとは異なり、本モデルが解決する課題の特性に基づき、いくつかの変更を加えました。もともとこのフレームワークは、解析対象の時系列の将来的な延長を予測することを目的に設計されていましたが、私たちはそれをさらに発展させました。
MacroHFTおよびFinConフレームワークの実装から得られた経験を踏まえ、エンコーダータワーを、将来の取引操作に対する可能なシナリオを生成する独立したエージェントとして再定義しました。これにより、システムの機能的な可能性は大きく拡張されました。
元のHidformerアーキテクチャと同様に、エージェントは、市場データを多変量時系列およびその周波数特性として分析します。再帰型アテンション機構により、多変量時系列内の依存関係を捉えることができ、周波数スペクトルの分析は線形アテンションモジュールによっておこなわれます。このアプローチにより、データ内の構造的パターンをより深く理解できるようになり、特に高頻度取引やアルゴリズム取引において重要となる、変化する市場環境へのリアルタイム適応が可能になります。
さらに、各エージェントには、過去に下した意思決定を再帰的に分析するためのモジュールが搭載されています。これにより、進化する市場状況の中でそれらの判断を評価することができます。このモジュールは、過去の意思決定を分析し、最も効果的な戦略を特定し、市場環境の変化に応じてモデルを適応させる能力を提供します。
時系列分析エージェントは、CNeuronHidformerTSAgentオブジェクトとして実装されています。その構造は以下のとおりです。
class CNeuronHidformerTSAgent : public CResidualConv { protected: CNeuronBaseOCL caRole[2]; CNeuronRelativeCrossAttention cStateToRole; CNeuronS3 cShuffle; CNeuronRecursiveAttention cRecursiveState; CResidualConv cResidualState; CNeuronRecursiveAttention cRecursiveAction; CNeuronMultiScaleRelativeCrossAttention cActionToState; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformerTSAgent(void) {}; ~CNeuronHidformerTSAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformerTSAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
親クラスとしては、フィードバックを備えた畳み込みブロックを使用しています。これは、内部アテンションモジュールのひとつにおけるFeedForwardブロックとして機能します。
ここで示した構造には、多様なコンポーネントが幅広く含まれており、それぞれがこの新しいクラスのアルゴリズムを構成する中で独自の役割を果たしています。これらの要素は、多面的なアプローチを実現し、複雑なパターンの処理および分析において、モデルがさまざまなシナリオに適応できるようにします。これらの各コンポーネントについては、クラスメソッドの構築過程でより詳しく検討していきます。
すべてのオブジェクトは静的に宣言されているため、クラスのコンストラクタとデストラクタは「空」のままで問題ありません。継承および宣言された全オブジェクトの初期化は、Initメソッド内で実装されています。このメソッドは、生成されるオブジェクトのアーキテクチャを明確に定義する複数の定数パラメータを受け取ります。
bool CNeuronHidformerTSAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (action_space + 2) / 3, optimization_type, batch)) return false;
初期化は、親クラスの対応するメソッドを呼び出すことから始まります。この親クラスのメソッドには、継承されたオブジェクトに必要な制御ポイントおよび初期化手順がすでに含まれています。ここで注意すべき点は、親オブジェクトのインターフェースが、エージェントに期待される動作と整合する出力を生成しなければならないということです。この場合、エージェントは取引操作のテンソルを出力することが想定されており、各操作は取引量、ストップロス水準、テイクプロフィット水準という3つの主要パラメータで表されます。買いおよび売りの操作は、この行列の別々の行として表現されます。そのため、親クラスの初期化メソッドを呼び出す際には、入力データおよび出力結果のウィンドウサイズを3に設定し、シーケンス長をエージェントの行動ベクトルの3分の1に設定しています。
親クラスの処理が正常に完了した後、新たに導入した内部オブジェクトの初期化をおこないます。まず、エージェントロールテンソルを形成するための構造を初期化します。この概念はFinConフレームワークから取り入れ、現在の課題に合わせて調整しました。この概念の主な利点は、入力データの分析に関する責任を複数の並列エージェントに分担させ、それぞれが解析対象シーケンスの特定の側面に集中できる点にあります。
//--- Role int index = 0; if(!caRole[0].Init(10 * window_key, index, OpenCL, 1, optimization, iBatch)) return false; caRole[0].getOutput().Fill(1); index++; if(!caRole[1].Init(0, index, OpenCL, 10 * window_key, optimization, iBatch)) return false;
次に、エージェントに割り当てられた役割に応じて、入力データの重要な特性を強調する相対クロスアテンションモジュールを初期化します。
//--- State to Role index++; if(!cStateToRole.Init(0, index, OpenCL, window, window_key, units_count, heads, window_key, 10, optimization, iBatch)) return false;
生データの初期処理の後、元のHidformerアーキテクチャに戻り、エンコーダにデータを入力する前にセグメンテーションをおこないます。重要な点として、このセグメンテーションは各タワー内で独立して実行されます。これにより、異なるデータストリーム間で不要な相関が生じるのを防ぎ、異種の入力シーケンスに対するモデルの適応性が向上します。
改良版では、従来のセグメンテーション機構を、専用のS3モジュールに置き換えることで、エージェントの機能を拡張しました。このモジュールはセグメンテーションをおこなうだけでなく、学習可能なセグメントシャッフル機構も実装しています。このようなアプローチにより、シーケンス内の異なる部分間に潜む潜在的な関係性をより適切に捉えることが可能になります。その結果、エージェントはより堅牢で汎化性能の高い表現を形成できます。
//--- State index++; if(!cShuffle.Init(0, index, OpenCL, window, window * units_count, optimization, iBatch)) return false;
これまでのステップで準備されたデータは、再帰型アテンションモジュールとフィードバック付き畳み込みブロックから構成されるエンコーダーに入力されます。
index++; if(!cRecursiveState.Init(0, index, OpenCL, window, window_key, units_count, heads, stack_size, optimization, iBatch)) return false; index++; if(!cResidualState.Init(0, index, OpenCL, window, window, units_count, optimization, iBatch)) return false;
このようなエンコーダーにより、入力シーケンスを最新価格の文脈で分析し、想定されるサポートおよびレジスタンス水準、あるいは安定したパターン形成領域を特定することが可能になります。
次の段階では、再び元のHidformerバージョンから逸脱し、エージェントが過去に取った行動を分析するためのモジュールを追加します。まず、最新の行動を、その履歴シーケンスの文脈で再帰的に分析します。
//--- Action index++; if(!cRecursiveAction.Init(0, index, OpenCL, 3, window_key, (action_space + 2) / 3, heads, stack_size, optimization, iBatch)) return false;
次に、マルチスケールクロスアテンションモジュールを用いて、動的な市場環境の文脈でエージェントの方策を分析します。
index++; if(!cActionToState.Init(0, index, OpenCL, 3, window_key, (action_space + 2) / 3, heads, window, units_count, optimization, iBatch)) return false; //--- return true; }
FeedForwardブロックの機能は、親クラスの機能によって実装されています。
すべての内部オブジェクトの初期化が正常に完了した後、処理の論理結果を呼び出し元のプログラムに返し、メソッドを終了します。
次に、feedForwardメソッド内に実装されるフォワードパスアルゴリズムの設計に進みます。このメソッドのパラメータには、入力データを含むオブジェクトへのポインタが含まれます。
bool CNeuronHidformerTSAgent::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !caRole[1].FeedForward(caRole[0].AsObject())) return false;
メソッド内部では、まずエージェントの現在の役割を記述するテンソルを生成します。ただし、この処理はモデルの学習時にのみ実行されます。推論時には、フォワードパスの各反復で固定されたロールテンソルが生成されるため、このステップは冗長となります。そのため、まず現在の動作モードを確認し、その後にのみ、ロールテンソルを生成する内部全結合層のフォワードパスを呼び出します。このアプローチにより、不要な演算が排除され、意思決定のレイテンシが低減されます。
次に、受け取った入力データの処理に進みます。まず、エージェントの役割に関連する要素を抽出します。これはクロスアテンションモジュールを通じておこなわれます。
//--- State to Role if(!cStateToRole.FeedForward(NeuronOCL, caRole[1].getOutput())) return false;
続いて、強化された環境状態がセグメント化およびシャッフルされます。
//--- State if(!cShuffle.FeedForward(cStateToRole.AsObject())) return false;
その後、再帰型アテンションモジュールによって処理され、過去の価格変動ダイナミクスに関する情報が環境状態の表現に付加されます。
if(!cRecursiveState.FeedForward(cShuffle.AsObject())) return false; if(!cResidualState.FeedForward(cRecursiveState.AsObject())) return false;
次の段階では、エージェントの行動方策に対する詳細な分析をおこないます。まず、最新の意思決定を、再帰型アテンションモジュールのメモリに保存された過去の行動の文脈で分析します。
//--- Action if(!cRecursiveAction.FeedForward(AsObject())) return false;
次に、マルチスケールクロスアテンションモジュールを用いて、進化する市場環境の文脈でエージェントの方策を分析します。
if(!cActionToState.FeedForward(cRecursiveAction.AsObject(), cResidualState.getOutput())) return false;
ここで分かるように、行動分析モジュールのアーキテクチャは、古典的なTransformerデコーダーから着想を得ています。古典的なデコーダーは、自己アテンション、クロスアテンション、FeedForwardという順序でモジュールを使用します。本モデルでは、Hidformerフレームワークに従い、自己アテンションモジュールを再帰型アテンションモジュールに置き換えています。同様の論理に基づき、マルチヘッドクロスアテンションはマルチスケールアテンションに置き換えられています。残る要素がFeedForwardブロックであり、これは親クラスによって実装されています。ただし、これを使用する前に、このデコーダ風構造への入力が、本メソッドの前回のフォワードパス結果である点に注意する必要があります。バックプロパゲーションパスを正しく実行するためには、この情報を保存しておく必要があります。そのため、一時的に継承されたデータバッファのポインタを切り替え、その後で親クラスのfeedForwardメソッドを呼び出します。
if(!SwapBuffers(Output, PrevOutput)) return false; //--- return CResidualConv::feedForward(cActionToState.AsObject()); }
これらの操作の論理結果を呼び出し元プログラムに返して、メソッドを終了します。
次のステップは、バックプロパゲーションアルゴリズムの構築です。このオブジェクトにおける逆伝播パスは、calcInputGradientsとupdateInputWeightsの2つのメソッドで表現されます。前者は、最終出力に対する影響度に比例して、意思決定プロセスに関与したすべてのオブジェクトに誤差勾配を正しく分配します。後者は、総誤差を最小化するためにモデルの学習可能パラメータを最適化します。updateInputWeightsメソッドは通常単純で、フォワードパス中に保存されたデータを渡しながら、学習可能パラメータを含む内部オブジェクトの対応するメソッドを呼び出すだけです。一方、勾配分配メソッドはフォワードパス時の情報フローと密接に関連しており、より詳細な説明が必要となります。
calcInputGradientsメソッドのパラメータには、入力データオブジェクトへのポインタが含まれます。これはフォワードパス時に渡されたものと同一のオブジェクトです。ただし今回は、入力データがモデル出力に与えた影響に対応する誤差勾配を、このオブジェクトに送る必要があります。そのため、有効なポインタが必要となります。よって、メソッドの冒頭で直ちにポインタの有効性を確認します。
bool CNeuronHidformerTSAgent::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
この小さな制御ブロックの後、勾配分配アルゴリズムの構築に進みます。
勾配分配の情報フローは、フォワードパスのフローを逆順に辿ります。フォワードパスは親クラスのメソッド呼び出しで終了しているため、勾配分配も同様に継承された機構から開始されます。この段階では、親クラスの対応するメソッドを呼び出し、エージェントのポリシーと市場ダイナミクスの両方に対するマルチスケールクロスアテンションを担当するモジュールへ誤差を伝播させます。
if(!CResidualConv::calcInputGradients(cActionToState.AsObject())) return false;
次に、得られた勾配を2つの情報フロー、すなわちエージェントの方策分析と、多変量時系列として表現される環境状態の分析に分配する必要があります。
if(!cRecursiveAction.calcHiddenGradients(cActionToState.AsObject(), cResidualState.getOutput(), cResidualState.getGradient(), (ENUM_ACTIVATION)cResidualState.Activation())) return false;
まず、方策分析ブランチに沿って勾配を分配します。そのために、エージェントの過去の行動を処理する再帰型アテンションモジュールを通過させます。このブロックへの入力は、本オブジェクトの前回のフォワードパス結果であり、以前は別のデータバッファに保存してありました。正しい勾配分配をおこなうためには、現在の結果を保持したまま、これらの値を一時的に結果バッファへ戻す必要があります。そのため、再度バッファポインタを切り替えます。
さらに、勾配分配の過程では、対応するインターフェースバッファ内の値が上書きされます。これは、後続のパラメータ更新に必要な値を保持する観点から望ましくありません。そのため、誤差勾配バッファも同様にリダイレクトします。
すべての必要なデータが保持されていることを確認した後にのみ、再帰型アテンションモジュールを通じた勾配分配処理を実行します。正常に完了した後、バッファポインタは元の状態に戻されます。
//--- Action CBufferFloat *temp = Gradient; if(!SwapBuffers(Output, PrevOutput) || !SetGradient(cRecursiveAction.getPrevOutput(), false)) return false; if(!calcHiddenGradients(cRecursiveAction.AsObject())) return false; if(!SwapBuffers(Output, PrevOutput)) return false; Gradient = temp;
次に、多変量時系列分析パスに沿った勾配分配に進みます。まず、環境状態を解析する再帰型アテンションモジュールのレベルまで勾配を伝播させます。
//--- State if(!cRecursiveState.calcHiddenGradients(cResidualState.AsObject())) return false;
次に、勾配をセグメンテーションおよびシャッフルブロックへ渡します。
if(!cShuffle.calcHiddenGradients(cRecursiveState.AsObject())) return false;
さらにこの分岐を進め、エージェントの役割の文脈で生データを分析するクロスアテンションモジュールへ勾配を伝達します。
if(!cStateToRole.calcHiddenGradients(cShuffle.AsObject())) return false;
ここから再び勾配は2つの流れに分岐します。1つは入力データオブジェクトへ、もう一つはエージェントロール形成ブランチへ向かいます。
if(!NeuronOCL.calcHiddenGradients(cStateToRole.AsObject(), caRole[1].getOutput(), caRole[1].getGradient(), (ENUM_ACTIVATION)caRole[1].Activation())) return false; //--- return true; }
ここで注意すべき点として、ロール形成ブランチに沿ったさらなる勾配伝播はおこなわれません。このMLPの第一層は固定されており、学習可能なパラメータを持つのは第2のニューラル層のみであり、そこにはすでに誤差信号が伝えられています。
最後に、処理の論理結果を呼び出し元のプログラムに返し、メソッドを終了します。
以上で、環境状態に対する時系列分析エージェントの各メソッドを構築するために使用されたアルゴリズムの説明は終了です。このオブジェクトおよびそのすべてのメソッドの完全なコードは、添付資料に掲載されています。
周波数領域での処理
次の段階は、解析対象信号の周波数特性を分析するためのエージェントを構築することです。このエージェントの構造は、先に作成した時系列分析エージェントと非常によく似ている点に注意する必要があります。一方で、入力信号を周波数領域へ変換することに関連した明確な特徴も備えています。環境状態信号の高周波成分および低周波成分を分離するために、私たちはMultitask-Stockformerフレームワークから着想を得た離散ウェーブレット変換を実装しました。
周波数領域エージェントのアルゴリズムは、CNeuronHidformerFreqAgentオブジェクトとして実装されています。その構造は以下のとおりです。
class CNeuronHidformerFreqAgent : public CResidualConv { protected: CNeuronTransposeOCL cTranspose; CNeuronLegendreWaveletsHL cLegendre; CNeuronTransposeRCDOCL cHLState; CNeuronLinerAttention cAttentionState; CResidualConv cResidualState; CNeuronS3 cShuffle; CNeuronRecursiveAttention cRecursiveAction; CNeuronMultiScaleRelativeCrossAttention cActionToState; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformerFreqAgent(void) {}; ~CNeuronHidformerFreqAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint filters, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformerFreqAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
提示された構造を見ると、内部オブジェクトの名称に類似点が多く見られ、時間領域エージェントと周波数領域エージェントの間に構造的な関連性があることが分かります。しかし同時に、相違点も存在しており、それらについては本クラスのメソッドを構築する過程で詳しく検討していきます。
すべての内部オブジェクトは静的に宣言されているため、オブジェクトのコンストラクタおよびデストラクタは空のままにしています。新たに宣言・継承されたすべてのオブジェクトの初期化は、Initメソッド内でおこなわれます。
bool CNeuronHidformerFreqAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint filters, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (action_space + 2) / 3, optimization_type, batch)) return false;
メソッドのパラメータには、生成されるオブジェクトのアーキテクチャを明確に定義するための定数が含まれています。メソッド内部では、まず親クラスの対応するメソッドを呼び出します。このメソッドには、継承されたオブジェクトおよびインターフェースの初期化と、必要な制御ポイントがすでに実装されています。データ領域が異なるにもかかわらず、このエージェントも同様に取引操作テンソルを出力することが期待されています。そのため、時系列エージェントで説明した親クラス初期化メソッドの呼び出し方法は、ここでも同様に適用されます。
次に、新たに宣言されたオブジェクトの初期化をおこないます。ここで、異なるデータ領域向けに設計されたエージェントの構成上の違いに注目してください。周波数領域エージェントには、ロール生成モジュールが存在しません。実装で多数の周波数領域エージェントを使用する予定がないためです。
また、セグメンテーションブロックは離散ウェーブレット変換モジュールに置き換えられています。時間領域から周波数領域への変換は、ユニットシーケンス単位でおこなわれます。これらのシーケンスを扱いやすくするため、まず入力データ行列を転置します。
int index = 0; if(!cTranspose.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
単変量時系列は等しい長さのセグメントに分割されます。各セグメントに対して離散ウェーブレット変換を適用することで、時間的依存関係に含まれる重要な構造要素を抽出します。最小セグメントサイズは5要素に制限されており、解析精度と計算コストのバランスが考慮されています。
index++; uint wind = (units_count>=20 ? (units_count + 3) / 4 : units_count); uint units = (units_count + wind - 1) / wind; if(!cLegendre.Init(0, index, OpenCL, wind, wind, units, filters, window, optimization, batch)) return false;
ここで注意すべき点として、離散ウェーブレット変換モジュールの出力は、信号の高周波成分および低周波成分の両方を含むテンソルであるということが挙げられます。各セグメントにおいて、低周波成分の直後に高周波成分が配置され、データは[セグメント、[低、高]、フィルタ]という三次元テンソルとして表現されます。
後続の解析をおこなうためには、これらの成分を分離することが重要です。しかし、両方の信号タイプに対して同一の演算が適用されるため、並列処理をおこなう方が効率的です。そのため、信号を明示的に別々のオブジェクトに分割するのではなく、テンソルを転置することで、計算資源をより効率的に利用し、データ処理を高速化します。
index++; if(!cHLState.Init(0, index, OpenCL, units * window, 2, filters, optimization, iBatch)) return false;
次に、Hidformerフレームワークの著者らが提案している線形アテンションアルゴリズムを適用します。実装では、高周波成分と低周波成分を個別に解析することで、最も重要なパターンを特定し、それぞれの周波数特性に応じて信号処理戦略を適応的に調整できるようにしています。
index++; if(!cAttentionState.Init(0, index, OpenCL, filters, filters, units* window, 2, optimization, iBatch)) return false;
得られた出力は、フィードバック付き畳み込みブロックに渡されます。このブロックは、周波数領域エンコーダにおけるFeedForwardモジュールとして機能します。
index++; if(!cResidualState.Init(0, index, OpenCL, filters, filters, 2 * units * window, optimization, iBatch)) return false;
次に、時系列エージェントの構築で使用したものと同様の、エージェント方策分析ブロックを初期化します。ただし、ひとつ注意点があります。線形アテンションモジュールでは、解析がシーケンス全体に一度に適用されるため、セグメントの順序は重要ではありません。しかし、マルチスケールクロスアテンションモジュールを使用する場合、このモジュールは時系列データ向けに設計されており、最新の要素を優先するため、セグメントの優先順位を考慮する必要があります。
この問題を解決するために、セグメント化およびシャッフルオブジェクトを使用します。この場合、データはすでにセグメント化されているため、主な焦点は学習可能なセグメントシャッフルにあります。これにより、モデルは学習データに基づいてセグメントの優先度を自律的に学習できるようになります。
index++; if(!cShuffle.Init(0, index, OpenCL, filters, cResidualState.Neurons(), optimization, iBatch)) return false;
エージェント方策分析モジュールで使用されるオブジェクトの機能については、時系列エージェントで説明したアプローチがそのまま維持されているため、ここではこれ以上詳しく説明しません。
//--- Action index++; if(!cRecursiveAction.Init(0, index, OpenCL, 3, filters, (action_space + 2) / 3, heads, stack_size, optimization, iBatch)) return false; index++; if(!cActionToState.Init(0, index, OpenCL, 3, filters, (action_space + 2) / 3, heads, filters, 2 * units * window, optimization, iBatch)) return false; //--- return true; }
すべての内部オブジェクトが正常に初期化された後、論理的な結果を呼び出し元のプログラムに返してメソッドを終了します。
記事の分量を抑えるため、フォワードパスおよびバックプロパゲーションパスのメソッドについては、読者による自主的な検討に委ねます。これらのアルゴリズムは、時系列エージェントで説明した原則と同一です。両エージェントおよびそれらの全メソッドの完全なコードは、添付資料に掲載されています。
トップレベルオブジェクト
多変量時系列タワーおよび周波数領域タワーの各オブジェクトを構築した後、完全なHidformerフレームワークを構成する次のステップは、それらを単一の構造に統合し、デコーダーを追加することです。Hidformerの著者らは、解析対象の時系列の将来的な継続を予測するために、MLPをデコーダーとして使用しました。本研究ではタスクを変更していますが、最終的な意思決定を生成するためにパーセプトロンを使用することは依然として可能です。しかし、私たちはさらに一歩進み、MacroHFTフレームワークからハイパーエージェントという概念を取り入れました。このアイデアに着想を得て、以下の構造を持つCNeuronHidformerオブジェクトを作成しました。
class CNeuronHidformer : public CNeuronBaseOCL { protected: CNeuronTransposeOCL cTranspose; CNeuronHidformerTSAgent caTSAgents[4]; CNeuronHidformerFreqAgent caFreqAgents[2]; CNeuronMacroHFTHyperAgent cHyperAgent; CNeuronBaseOCL cConcatenated; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformer(void) {}; ~CNeuronHidformer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint stack_size, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
このアーキテクチャを見ると、MacroHFTフレームワークにおけるCNeuronMacroHFTクラスとの構造的な類似性が明確に分かります。本質的には、この新しい構造はその改良版であり、中核となる設計原理を維持しつつ、データ処理効率を向上させるための目的別の変更が加えられています。
主な違いは、環境分析エージェントの構成にあります。このバージョンでは、6つの専用エージェントが使用されています。内訳は、多変量時系列を分析するためのエージェントが4つ、周波数領域で入力データを処理するためのエージェントが2つです。解析のバランスを確保するため、すべてのエージェントは、入力データの直接表現と転置表現の処理に均等に割り当てられています。このアーキテクチャにより、入力データのさまざまな側面をより詳細に探索でき、隠れたパターンを明らかにしつつ、処理戦略を適応的に調整することが可能になります。
全体として、エージェント構造に対するこれらの変更は、オブジェクトの各メソッドのアルゴリズムに対しては比較的軽微な調整にとどまっています。主要なロジックは変更されておらず、モデルのすべての重要な動作原理は維持されています。そのため、本オブジェクトのメソッド構築アルゴリズムの詳細な検討は読者に委ねます。このオブジェクトとそのすべてのメソッドの完全なコードは添付ファイルに記載されています。
モデルアーキテクチャ
学習可能なモデルのアーキテクチャについて、いくつか補足します。ご覧のとおり、私たちが構築したアーキテクチャは、HidformerフレームワークとMacroHFTフレームワークのシナジーとなっています。学習可能なモデルのアーキテクチャおよびその学習手法も例外ではありません。私たちはMacroHFTフレームワークのモデルアーキテクチャを踏襲し、ただ1層のみを変更しました。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronHidformer; //--- Windows { int temp[] = {BarDescr, 120, NActions}; //Window, Stack Size, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Scales descr.layers =3; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
それ以外の運用アーキテクチャは変更されておらず、リスク管理エージェントの使用も含めてそのまま維持されています。モデルアーキテクチャの完全な説明、および学習およびテスト用ルーチンの全コードは、前回の記事から変更なく移植された形で、添付資料に掲載されています。
テスト
ここまでで、Hidformerの著者らが提案したアプローチを独自に解釈し、実装するという大きな作業を完了しました。そしていよいよ重要な段階、すなわち実際の履歴データを用いて、提案した解決策の有効性を評価する段階に到達しました。実装では、MacroHFTフレームワークから多くの要素を取り入れているため、新しいモデルの性能をそれと比較するのは自然な流れです。そこで、MacroHFTベースの実装を学習させるために以前作成した学習データセットを用いて、新しいモデルの学習をおこないました。
この学習データセットは、EUR/USD通貨ペアのM1時間足における2024年通年の履歴データから収集されたものです。すべてのインジケーターのパラメータはデフォルト値のままとしています。
モデルの学習およびテストには、同一のエキスパートアドバイザー(EA)を使用しました。テストは、その他のすべてのパラメータを維持したまま、2025年1月の履歴データを用いて実施されました。以下にそのテスト結果を示します。
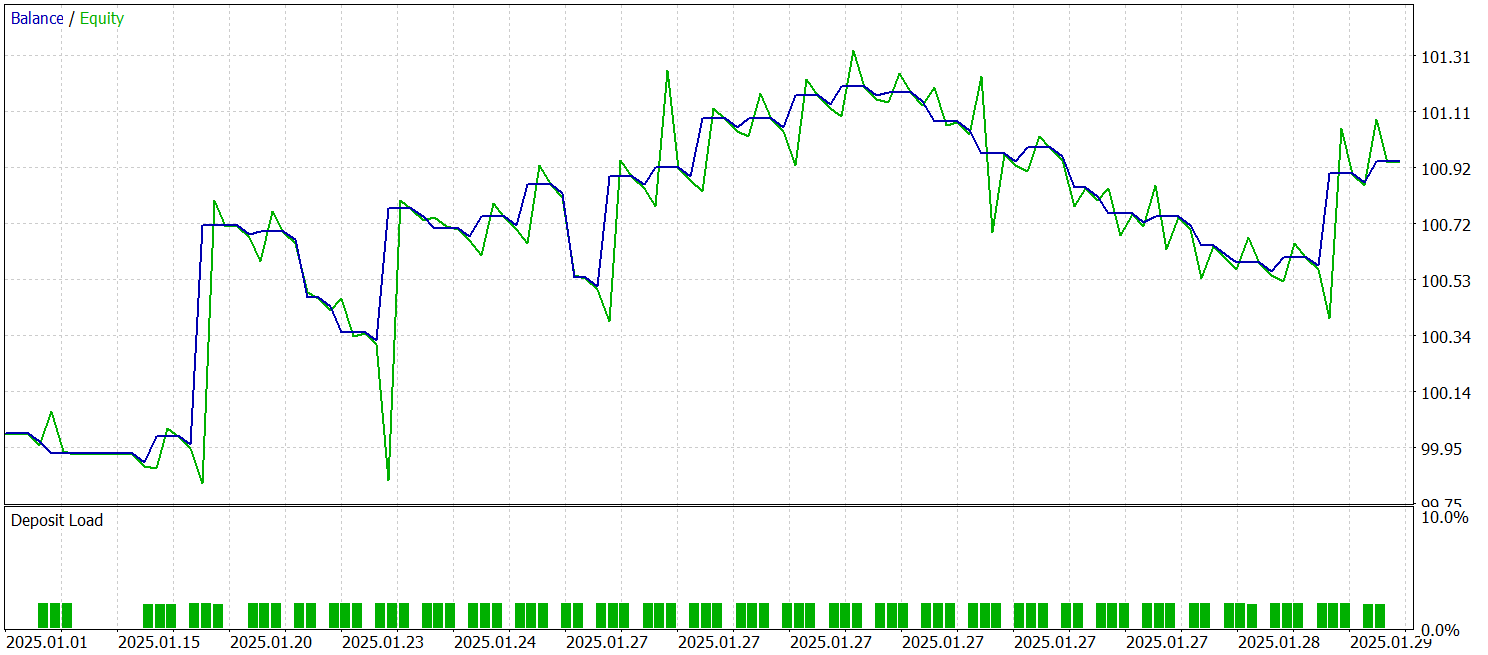
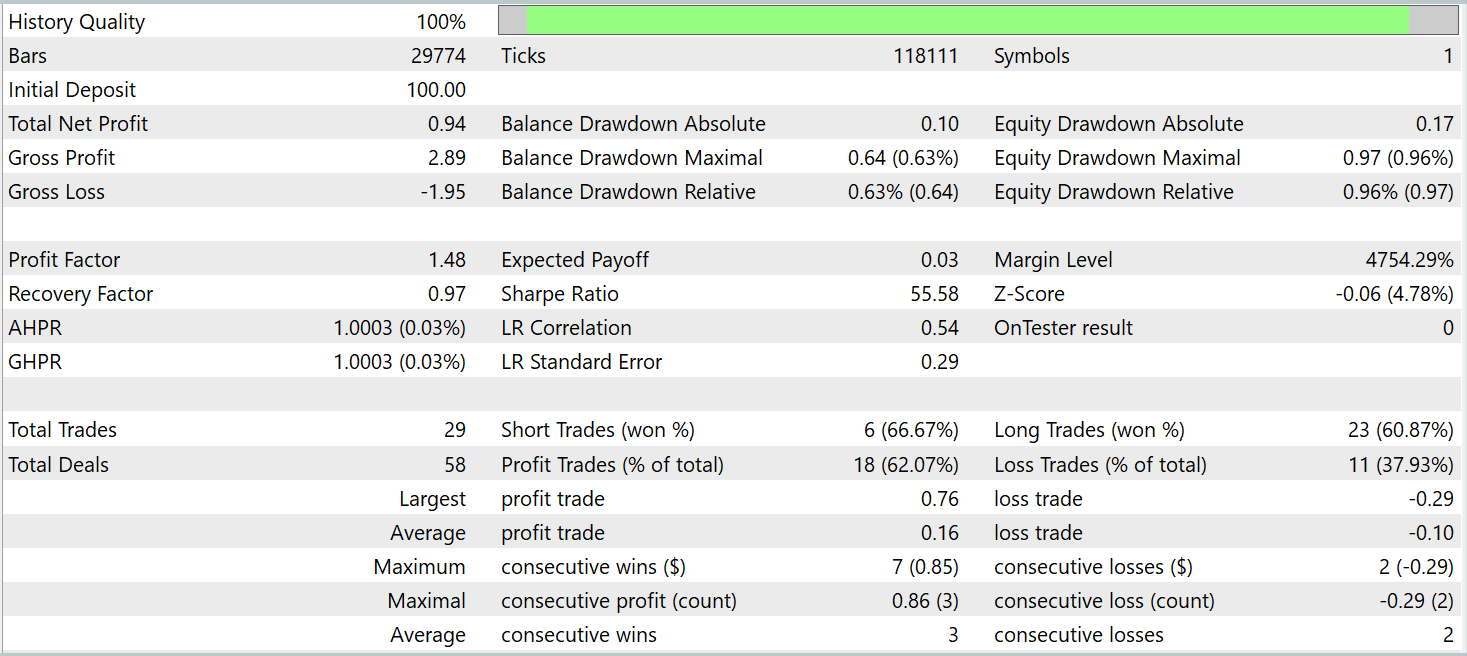
結果から分かるように、モデルは学習データセット外の履歴データに対しても利益を上げることができました。暦月中に、モデルは合計29回の取引を実行しています。これは取引日あたり平均して1回をやや上回る程度であり、高頻度取引としては十分とは言えません。しかしその一方で、取引の60%以上が利益をもたらしており、さらに平均的な利益トレードは、平均的な損失トレードを約60%上回っていました。
結論
本記事では、複雑な多変量時系列の分析および予測を目的に設計されたHidformerフレームワークを検討しました。このモデルは、独自のダブルタワー型エンコーダーアーキテクチャにより、高い効率性を示します。一方のタワーは入力データの時間構造を分析し、もう一方は周波数領域で処理をおこないます。再帰型アテンション機構は複雑な価格変動パターンを明らかにし、線形アテンションは長いシーケンスを分析する際の計算量を低減します。
本記事の実践パートでは、提案されたアプローチをMQL5を用いて独自に実装しました。モデルは実際の履歴データで学習させ、アウトオブサンプルデータでテストしました。テスト結果は、本モデルが有するポテンシャルを示しています。ただし、実運用の取引に投入する前には、より代表性の高いデータセットを用いた追加学習と、それに続く包括的な検証が必要です。
参照文献
- Hidformer:Transformer-Style Neural Network in Stock Price Forecasting
- Hidformer:Hierarchical dual-tower transformer using multi-scale mergence for long-term time series forecasting
- 本連載の他の記事
記事で使用されているプログラム
| # | 名前 | 種類 | 説明 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いたサンプル収集用EA |
| 3 | Study.mq5 | EA | モデル学習用EA |
| 4 | Test.mq5 | EA | モデルテスト用EA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態とモデルアーキテクチャ記述構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコード |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17104
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索