
Нейросети в трейдинге: Иерархический двухбашенный трансформер (Окончание)

Введение
В предыдущей статье мы познакомились с теоретическими аспектами фреймворка Hidformer, разработанного специально для анализа и прогнозирования сложных многомерных временных рядов. Модель демонстрирует высокую эффективность при обработке динамичных и волатильных данных, благодаря уникальной архитектуре.
Ключевым элементом Hidformer является использование усовершенствованных механизмов внимания, позволяющих не только выявлять явные зависимости в данных, но и обнаруживать глубокие, скрытые взаимосвязи. Для этого в модели применяется двухбашенный энкодер, каждая башня которого проводит независимый анализ исходных данных. Одна башня специализируется на анализе временной структуры, выявляя тренды и закономерности, тогда как вторая осуществляет исследование данных в частотном домене. Такой подход обеспечивает комплексное представление о динамике рынка, позволяя учитывать как краткосрочные, так и долгосрочные изменения в ценовых рядах.
Инновационным аспектом модели является применение рекурсивного механизма внимания для анализа временных зависимостей, что позволяет последовательно накапливать информацию о сложных паттернах динамики анализируемого финансового инструмента. В совокупности с линейным механизмом внимания, используемым для анализа частотного спектра исходных данных, этот подход оптимизирует вычислительные затраты и обеспечивает стабильность процесса обучения. Это позволяет фреймворку Hidformer эффективно адаптироваться к многомерности и нелинейности анализируемых данных, предоставляя более достоверные прогнозы в условиях высокой рыночной волатильности.
Декодер модели, построенный на основе многослойного перцептрона, позволяет прогнозировать всю последовательность цен за один шаг, минимизируя риск накопления ошибок, характерный для пошагового прогнозирования. Это существенно повышает качество долгосрочных прогнозов, делая модель особенно ценной для практических приложений в финансовом анализе.
Авторская визуализация фреймворка Hidformer представлена ниже.
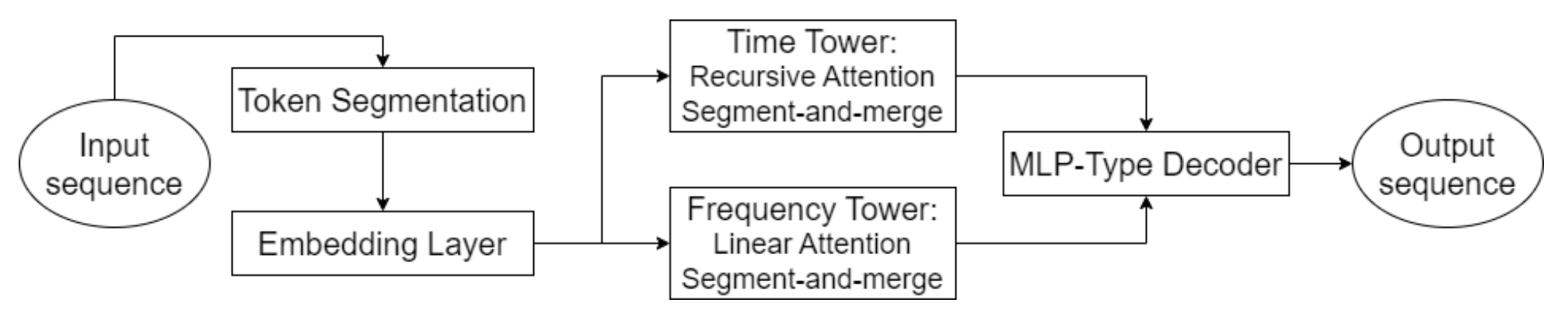
В практической части предыдущей статьи мы провели подготовительную работу и уже реализовали свое видение алгоритмов рекурсивного и линейного внимания. И сегодня мы продолжим начатую работу по построению подходов, предложенных авторами фреймворка Hidformer.
Анализ временных последовательностей
Авторы фреймворка Hidformer предложили архитектуру двухбашенного энкодера, которую мы взяли за основу. В нашей реализации каждая башня энкодера будет представлена в виде отдельного объекта, что позволяет гибко адаптировать модель под различные задачи. Однако, в отличие от оригинального фреймворка, мы внесли ряд модификаций, которые продиктованы изменением задачи, решаемой моделью. Изначально фреймворк разрабатывался для прогнозирования продолжения анализируемого временного ряда, но мы пошли немного дальше.
Опираясь на опыт, полученный при реализации фреймворков MacroHFT и FinCon, мы использовали башни энкодера в качестве независимых агентов, вырабатывающих варианты предстоящих торговых операций. Такой подход позволил существенно расширить функциональные возможности системы.
Подобно оригинальной архитектуре Hidformer, наши агенты будут анализировать рыночные данные в виде многомерных временных последовательностей и их частотных характеристик. Использование механизма рекурсивного внимания позволяет выявлять зависимости в многомерных временных рядах, а анализ частотного спектра реализуется с помощью объектов линейного внимания. Такой подход обеспечивает более глубокое понимание структурных закономерностей в данных и позволяет модели адаптироваться к изменениям рыночных условий в режиме реального времени, что особенно важно в высокочастотной торговле и алгоритмическом трейдинге.
Дополнительно, каждый агент оснащён модулем рекуррентного анализа последовательности принятых решений, что позволяет оценивать их в контексте динамики рыночной ситуации. Этот модуль обеспечивает возможность анализа прошлых решений, выявления наиболее успешных стратегий и адаптации модели к изменяющимся условиям рынка.
Агент анализа временной последовательности построен в виде объекта CNeuronHidformerTSAgent, структура которого представлена ниже.
class CNeuronHidformerTSAgent : public CResidualConv { protected: CNeuronBaseOCL caRole[2]; CNeuronRelativeCrossAttention cStateToRole; CNeuronS3 cShuffle; CNeuronRecursiveAttention cRecursiveState; CResidualConv cResidualState; CNeuronRecursiveAttention cRecursiveAction; CNeuronMultiScaleRelativeCrossAttention cActionToState; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformerTSAgent(void) {}; ~CNeuronHidformerTSAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformerTSAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
В качестве родительского класса, в данном случае, мы используем сверточный блок с обратной связью, который будет выполнять роль блока FeedForward одного из внутренних блоков внимания.
Стоит отметить, что представленная структура включает в себя широкий спектр разноплановых компонентов, каждый из которых выполняет свою уникальную функцию в организации алгоритмов нового класса. Эти элементы обеспечивают многогранность подхода, позволяя модели адаптироваться к различным сценариям обработки информации и анализа сложных закономерностей. Более детально с каждым из этих компонентов мы познакомимся в процессе построения методов класса.
Все внутренние объекты были объявлены статично, что позволяет нам оставить пустыми конструктор и деструктор класса. А инициализация всех унаследованных и объявленных внутренних объектов осуществляется в методе Init. В параметрах данного метода мы получаем ряд констант, которые дают однозначное представление об архитектуре создаваемого объекта.
bool CNeuronHidformerTSAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (action_space + 2) / 3, optimization_type, batch)) return false;
Операции инициализации объекта начинаются с вызова соответствующего метода родительского класса, в котором уже организованы необходимые точки контроля и инициализации унаследованных объектов. Следует учитывать, что интерфейсы родительского объекта должны формировать ожидаемые результаты работы агента. В данном случае на выходе агента ожидаем получить тензор торговых операций, где каждая операция представлена тремя основными параметрами: объемом сделки и уровнями стоп-лосса и тейк-профита. При этом, сделки на покупку и продажу представлены отдельными строками данной матрицы. Таким образом, при вызове метода инициализации родительского класса, устанавливаем размер окон исходных данных и результатов равным 3, а длину последовательности — втрое меньше вектора действий агента.
После успешного выполнения операций родительского класса, осуществляется инициализация вновь объявленных внутренних объектов. В первую очередь инициализируются структуры, ответственные за формирование тензора роли агента. Концепцию этих структур мы заимствовали из архитектуры фреймворка FinCon и адаптировали к текущей задаче. Основное преимущество данной концепции заключается в разделении ролей анализа исходных данных между несколькими параллельно работающими агентами, позволяя сконцентрировать их внимание на отдельных аспектах анализируемой последовательности.
//--- Role int index = 0; if(!caRole[0].Init(10 * window_key, index, OpenCL, 1, optimization, iBatch)) return false; caRole[0].getOutput().Fill(1); index++; if(!caRole[1].Init(0, index, OpenCL, 10 * window_key, optimization, iBatch)) return false;
Далее осуществляется инициализация модуля относительного кросс-внимания, который позволяет выделять ключевые особенности исходных данных, в соответствии с контекстом роли агента.
//--- State to Role index++; if(!cStateToRole.Init(0, index, OpenCL, window, window_key, units_count, heads, window_key, 10, optimization, iBatch)) return false;
После этапа первичной обработки исходных данных, мы возвращаемся к авторской архитектуре фреймворка Hidformer, в которой предусмотрен механизм сегментации исходных данных перед передачей в энкодер. Важно отметить, что сегментация выполняется независимо в каждой башне, что позволяет избежать нежелательных корреляций между различными потоками данных и повысить адаптивность модели к разнородным исходным последовательностям.
В нашей модифицированной версии мы дополнили функционал агента, заменив классическую сегментацию специализированным модулем S3. Данный модуль не только выполняет сегментацию данных, но и реализует механизм обучаемого перемешивания сегментов. Такой подход позволяет лучше выявлять скрытые зависимости между различными частями последовательности. В результате, агент получает возможность формировать более устойчивые и обобщенные представления.
//--- State index++; if(!cShuffle.Init(0, index, OpenCL, window, window * units_count, optimization, iBatch)) return false;
Подготовленные на предыдущих этапах данные поступают в энкодер, состоящий из модуля рекурсивного внимания и сверточного блока с обратной связью.
index++; if(!cRecursiveState.Init(0, index, OpenCL, window, window_key, units_count, heads, stack_size, optimization, iBatch)) return false; index++; if(!cResidualState.Init(0, index, OpenCL, window, window, units_count, optimization, iBatch)) return false;
Подобный энкодер позволяет нам проанализировать исходную последовательность в контексте последней цены, выявляя на ней вероятные уровни поддержки и сопротивления, или объекты формирования устойчивых паттернов.
А на следующем этапе мы вновь отклоняемся от авторской версии фреймворка Hidformer и добавляем модуль анализа ранее принятых действий агента. Здесь мы сначала рекурсивно анализируем последние действия агента в контексте их исторической последовательности.
//--- Action index++; if(!cRecursiveAction.Init(0, index, OpenCL, 3, window_key, (action_space + 2) / 3, heads, stack_size, optimization, iBatch)) return false;
Затем воспользуемся модулем много масштабного кросс-внимания для анализа используемой политики агента в контексте динамики рыночной ситуации.
index++; if(!cActionToState.Init(0, index, OpenCL, 3, window_key, (action_space + 2) / 3, heads, window, units_count, optimization, iBatch)) return false; //--- return true; }
А функциональность блока FeedForward мы реализуем средствами родительского класса.
После успешной инициализации всех внутренних объектов, мы возвращаем логический результат выполнения операций вызывающей программе и завершаем работу метода.
Следующим этапом мы переходим к построению алгоритмов прямого прохода, который организуем в рамках метода feedForward. В параметрах данного метода мы получаем указатель на объект, содержащий исходные данные.
bool CNeuronHidformerTSAgent::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !caRole[1].FeedForward(caRole[0].AsObject())) return false;
В теле метода мы сначала генерируем тензор описания роли текущего агента. Однако эту операцию мы выполняем только в процессе обучения модели. Несложно догадаться, что в процессе эксплуатации модели, на каждой итерации прямого прохода будет генерироваться фиксированный тензор роли. Что делает данную операцию излишней. Поэтому, мы сначала проверяем режим работы модели и только потом вызываем метод прямого прохода внутреннего полносвязного слоя генерации тензора роли. Такой подход позволит нам исключить излишние операции в режиме эксплуатации модели и снизить затраты времени на процесс принятия решения.
Далее переходим к обработке полученных исходных данных. Здесь вначале выделим моменты, релевантные для роли нашего агента. Эта операция выполняется средствами объекта кросс-внимания.
//--- State to Role if(!cStateToRole.FeedForward(NeuronOCL, caRole[1].getOutput())) return false;
Затем, анализируемое состояние окружающей среды с расставленными акцентами мы сегментируем и перемешиваем.
//--- State if(!cShuffle.FeedForward(cStateToRole.AsObject())) return false;
После чего, оно обрабатывается в модуле рекурсивного внимания, где описание анализируемого состояния окружающей среды обогащается данными предшествующей динамики ценового движения.
if(!cRecursiveState.FeedForward(cShuffle.AsObject())) return false; if(!cResidualState.FeedForward(cRecursiveState.AsObject())) return false;
На следующем этапе мы проводим углубленный анализ политики поведения агента. В первую очередь анализируется последнее принятое решение в контексте предыдущих действий, сохраненных в памяти рекурсивного модуля внимания.
//--- Action if(!cRecursiveAction.FeedForward(AsObject())) return false;
Далее проанализируем политику действий агента в контексте динамики изменения окружающей среды средствами модуля многомасштабного кросс-внимания.
if(!cActionToState.FeedForward(cRecursiveAction.AsObject(), cResidualState.getOutput())) return false;
Легко заметить, что архитектура модуля анализа действий агента заимствована от классического декодера Transformer. Классический декодер последовательно использует модули Sefl-Attention → Cross-Attention → FeedForward. В нашем случае модуль Self-Attention был заменен объектом рекурсивного внимания в соответствии с подходами фреймворка Hidformer. Руководствуясь теми же подходами, мы заменили многоголовость Cross-Attention многомасштабностью. Остается добавить блок FeedForward. Его роль будут выполнять средства родительского класса. Но перед их использованием следует обратить внимание, что на вход своеобразного декодера подаются результаты предыдущего прямого прохода нашего метода. И для корректного выполнения операций обратного прохода, нам их желательно сохранить. С этой целью мы поменяем указатели на унаследованные буферы данных, и только затем вызываем метод прямого прохода родительского класса.
if(!SwapBuffers(Output, PrevOutput)) return false; //--- return CResidualConv::feedForward(cActionToState.AsObject()); }
Логический результат выполнения операций возвращаем вызывающей программе и завершаем работу метода.
Следующим этапом нашей работы мы переходим к построению алгоритмов обратного прохода. Как вы знаете, процесс обратного прохода в наших объектах представлен двумя методами: calcInputGradients и updateInputWeights. Первый отвечает за корректность распределения градиента ошибки между всеми объектами, участвующими в процессе принятия решения, в соответствии с их влиянием на итоговый результат. А во втором осуществляется оптимизация обучаемых параметров модели с целью минимизации общей ошибки. Алгоритм второго метода, как правило, не вызывает сложностей. Ведь в нем, обычно, мы только вызываем одноименные методы внутренних объектов, содержащих обучаемые параметры, с передачей исходных данных, используемых при прямом проходе. Алгоритм же метода распределения градиента ошибки тесно связан с информационными потоками прямого прохода и требует более детального описания.
В параметрах метода распределения градиента ошибки calcInputGradients мы получаем указатель на объект исходных данных. Это тот же объект, который передавался при прямом проходе. Только на этот раз нам предстоит передать в него градиент ошибки, соответствующий влиянию исходных данных на результат работы модели. Очевидно, что для передачи данных нам необходим корректный указатель на объект. Поэтому в теле метода мы сразу проверяем актуальность полученного указателя.
bool CNeuronHidformerTSAgent::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
И после успешного прохождения небольшого контрольного блока, мы переходим к построению алгоритма распределения градиента ошибки.
Мы уже не раз говорили, что информационные потоки распределения градиента полностью повторяют аналогичные потоки прямого прохода, только направлены в обратную сторону. Операции метода прямого прохода завершились вызовом метода родительского класса. Следовательно, распределение градиента ошибки начинается с использования унаследованных средств. Здесь мы вызываем одноименный метод родительского класса для передачи погрешности на уровень объекта многомасштабного кроссвнимания политики поведения агента и динамики рынка.
if(!CResidualConv::calcInputGradients(cActionToState.AsObject())) return false;
Далее нам предстоит разделить полученный градиент ошибки между двумя информационными потоками анализа политики поведения агента и состояния окружающей среды, представленного многомерным временным рядом.
if(!cRecursiveAction.calcHiddenGradients(cActionToState.AsObject(), cResidualState.getOutput(), cResidualState.getGradient(), (ENUM_ACTIVATION)cResidualState.Activation())) return false;
Вначале мы распределим градиент ошибки по магистрали анализа политики поведения агента. Для этого нам предстоит провести его через модуль рекурсивного внимания действий агента. Но здесь стоит обратить внимание, что исходными данными для данного блока являлись результаты предыдущего прямого прохода нашего объекта. Их мы предусмотрительно сохранили в специальном буфере данных. И теперь, для целей корректного распределения погрешности, нам необходимо временно вернуть их в буфер результатов с сохранением имеющихся результатов. Для этого мы снова осуществляем подмену указателей буферов данных.
Более того, в процессе выполнения распределения градиента ошибки, мы перепишем имеющиеся данные в соответствующем буфере интерфейсов нашего объекта. Это крайне нежелательно, ведь они нам ещё потребуются для корректировки обучаемых параметров. Следовательно, осуществляем подмену указателя и буфера градиентов ошибки.
Только после получения уверенности в сохранении всех необходимых данных, мы осуществляем операции распределения градиента ошибки через модуль рекурсивного внимания. А после успешного выполнения операций, возвращаем указатели на буферы данных в исходное состояние.
//--- Action CBufferFloat *temp = Gradient; if(!SwapBuffers(Output, PrevOutput) || !SetGradient(cRecursiveAction.getPrevOutput(), false)) return false; if(!calcHiddenGradients(cRecursiveAction.AsObject())) return false; if(!SwapBuffers(Output, PrevOutput)) return false; Gradient = temp;
Далее мы переходим к распределению градиента ошибки по магистрали анализа многомерного временного ряда описания состояния окружающей среды. Здесь мы сначала опускаем погрешности до уровня модуля рекурсивного внимания анализируемого состояния окружающей среды.
//--- State if(!cRecursiveState.calcHiddenGradients(cResidualState.AsObject())) return false;
А затем, передаем его на уровень блока сегментирования и перемешивания.
if(!cShuffle.calcHiddenGradients(cRecursiveState.AsObject())) return false;
Следуя далее, по данной магистрали мы передаем информацию на уровень объекта кросс-внимания, анализирующий исходные данные в контексте роли агента.
if(!cStateToRole.calcHiddenGradients(cShuffle.AsObject())) return false;
От него градиент ошибки снова разделяется на два информационных потока: к объекту исходных данных и на магистраль формирования роли агента.
if(!NeuronOCL.calcHiddenGradients(cStateToRole.AsObject(), caRole[1].getOutput(), caRole[1].getGradient(), (ENUM_ACTIVATION)caRole[1].Activation())) return false; //--- return true; }
Здесь следует отметить, что по магистрали формирования роли агента мы не распределяем градиент ошибки далее. Ведь первый слой этой MLP имеет фиксированное значение, а обучаемые параметры содержит только второй нейронный слой, ошибку которого мы уже передали.
Теперь нам остается вернуть логический результат выполнения операций вызывающей программе и завершить работу метода.
На этом мы завершаем рассмотрение алгоритмов, используемых для построения методов агента анализа временной последовательности состояния окружающей среды. С полным кодом представленного объекта и всех его методов вы можете самостоятельно ознакомиться во вложении.
Работа с частотным доменом
Следующим этапом нашей работы является построение агента анализа частотных характеристик анализируемого сигнала. Сразу скажем, что структура построения агента довольно похожа на вышесозданный агент анализа временной последовательности. Но в то же время и не лишена некоторых особенностей, связанных с преобразованием исходного сигнала в частотный спектр. Для выделения высоко- и низкочастотных составляющих анализируемого сигнала описания состояния окружающей среды, в своей реализации мы использовали дискретное вейвлет-преобразование, заимствованное в фреймворке Multitask-Stockformer.
Алгоритмы работы агента частотного домена мы реализуем в виде объекта CNeuronHidformerFreqAgent, структура которого представлена ниже.
class CNeuronHidformerFreqAgent : public CResidualConv { protected: CNeuronTransposeOCL cTranspose; CNeuronLegendreWaveletsHL cLegendre; CNeuronTransposeRCDOCL cHLState; CNeuronLinerAttention cAttentionState; CResidualConv cResidualState; CNeuronS3 cShuffle; CNeuronRecursiveAttention cRecursiveAction; CNeuronMultiScaleRelativeCrossAttention cActionToState; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformerFreqAgent(void) {}; ~CNeuronHidformerFreqAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint filters, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformerFreqAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
В представленной структуре легко заметить схожие наименования внутренних объектов, говорящие нам о родственной структуре агентов временного и частотного домена. Но есть и отличия, которые мы более детально рассмотрим в процессе построения алгоритмов методов нового класса.
Все внутренние объекты объявлены статично, что позволяет нам оставить пустыми конструктор и деструктор нашего объекта. А инициализация всех вновь объявленных и унаследованных объектов осуществляется в методе Init.
bool CNeuronHidformerFreqAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint filters, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (action_space + 2) / 3, optimization_type, batch)) return false;
В параметрах данного метода мы получаем ряд констант, позволяющих однозначно интерпретировать архитектуру создаваемого объекта. А в теле метода мы сразу вызываем одноименный метод родительского класса, в котором уже реализованы необходимые точки контроля и инициализация унаследованных объектов и интерфейсов. И здесь следует отметить, что, несмотря на отличие в доменах анализируемых данных, на выходе агента мы ожидаем получить все тот же тензор торговых операций. Поэтому подходы, описанные выше для вызова метода инициализации родительского класса в агенте анализа временного ряда, актуальны и в данном случае.
Далее мы переходим к инициализации вновь объявленных объектов. И здесь мы сразу видим отличие в построении агентов разного домена. Агент анализа частотных характеристик лишен модуля генерации роли. В своей реализации мы не планируем использование большого количества агентов частотного домена.
Кроме того, блок сегментации был заменен модулем дискретного вейвлет-преобразования. При этом, преобразование временного ряда в частотный домен осуществляется в разрезе унитарных последовательностей. А для удобства работы с унитарными последовательностями нам необходимо предварительно осуществить транспонирование матрицы исходных данных.
int index = 0; if(!cTranspose.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
Унитарные временные ряды мы разделим на равные сегменты. Для каждого сегмента выполняется дискретное вейвлет-преобразование, что позволяет выделить значимые структурные компоненты временных зависимостей. Минимальный размер сегмента ограничен пятью элементами, что обеспечивает баланс между точностью анализа и вычислительными затратами.
index++; uint wind = (units_count>=20 ? (units_count + 3) / 4 : units_count); uint units = (units_count + wind - 1) / wind; if(!cLegendre.Init(0, index, OpenCL, wind, wind, units, filters, window, optimization, batch)) return false;
Здесь стоит обратить внимание, что на выходе модуля дискретного вейвлет-преобразования мы получаем тензор, содержащий высоко- и низкочастотные составляющие анализируемого сигнала. При этом высокочастотная составляющая следует непосредственно за низкочастотной каждого отдельного сегмента и данные можно представить в виде трехмерного тензора [Segment, [Low, High], Filters].
Для дальнейшего анализа важно разделить данные на соответствующие компоненты. Однако, поскольку над обоими типами сигналов предполагается выполнение идентичных операций, рациональнее организовать их обработку параллельно. В связи с этим, мы не производим явного разделения сигнала на отдельные объекты, а вместо этого выполняем транспонирование тензора, что позволяет более эффективно управлять вычислительными ресурсами и ускорить обработку данных.
index++; if(!cHLState.Init(0, index, OpenCL, units * window, 2, filters, optimization, iBatch)) return false;
Теперь, как и предусмотрено авторами фреймворка Hidformer, мы используем алгоритм линейного внимания. В нашем случае мы осуществляем отдельный анализ высоко- и низкочастотных компонент, что позволяет выделять наиболее значимые паттерны и адаптивно изменять стратегию обработки сигналов в зависимости от их частотных характеристик.
index++; if(!cAttentionState.Init(0, index, OpenCL, filters, filters, units* window, 2, optimization, iBatch)) return false;
Полученные результаты мы пропускаем через сверточный блок с обратной связью, который выполняет роль модуля FeedForward нашего энкодера частотного домена.
index++; if(!cResidualState.Init(0, index, OpenCL, filters, filters, 2 * units * window, optimization, iBatch)) return false;
Далее мы инициализируем блок анализа используемой политики агента, аналогичный рассмотренному выше при построении агента анализа временной последовательности. Но есть один нюанс. Если для работы модуля линейного внимания последовательность сегментов не важна, так как анализ осуществляется сразу всей последовательности, то при работе много масштабного модуля кросс-внимания, мы сталкиваемся с вопросом приоритизации сегментов. Ведь наш модуль много масштабного кросс-внимания построен для работы с временной последовательностью и отдает приоритет наиболее поздним элементам.
Для решения этой проблемы мы воспользуемся объектом сегментирования и перемешивания. В данном случае, наши данные уже сегментированы, и нам более важен процесс обучаемой перестановки сегментов. Такой подход позволит модели самостоятельно выучить приоритетность сегментов на основе данных, представленных в обучающей выборке.
index++; if(!cShuffle.Init(0, index, OpenCL, filters, cResidualState.Neurons(), optimization, iBatch)) return false;
На описании функциональности объектов, используемых модулем анализа политики агента, мы не будем останавливаться, так как здесь сохранены подходы, описанные при построении агента анализа временной последовательности.
//--- Action index++; if(!cRecursiveAction.Init(0, index, OpenCL, 3, filters, (action_space + 2) / 3, heads, stack_size, optimization, iBatch)) return false; index++; if(!cActionToState.Init(0, index, OpenCL, 3, filters, (action_space + 2) / 3, heads, filters, 2 * units * window, optimization, iBatch)) return false; //--- return true; }
После успешной инициализации всех внутренних объектов, мы завершаем работу метода, предварительно вернув логический результат работы метода вызывающей программе.
С целью экономии объёма статьи, я предлагаю оставить для самостоятельного изучения методы прямого и обратного проходов. Их алгоритмы построены на тех же принципах, которые были описаны выше при построении аналогичных методов агента анализа временной последовательности. Полный код представленных объектов обоих агентов и их методов вы найдете во вложении.
Объект верхнего уровня
После построения объектов башен анализа многомерного временного ряда и его частотных характеристик, для построения целостного фреймворка Hidformer нам остается объединить их в единую структуру и добавить декодер. Авторы фреймворка Hidformer использовали MLP в качестве декодера для прогнозирования ожидаемого продолжения анализируемого временного ряда. Несмотря на изменение нами задачи, решаемой моделью, для её реализации так же возможно использование перцептрона генерации итогового решения. Однако, мы пошли немного дальше и позаимствовали идею гиперагента в фреймворке MacroHFT. Вдохновленные этой идеей, мы создали новый объект CNeuronHidformer, структура которого представлена ниже.
class CNeuronHidformer : public CNeuronBaseOCL { protected: CNeuronTransposeOCL cTranspose; CNeuronHidformerTSAgent caTSAgents[4]; CNeuronHidformerFreqAgent caFreqAgents[2]; CNeuronMacroHFTHyperAgent cHyperAgent; CNeuronBaseOCL cConcatenated; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformer(void) {}; ~CNeuronHidformer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint stack_size, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
В представленной архитектуре нового объекта можно легко выявить структурное сходство с классом CNeuronMacroHFT, который является частью фреймворка MacroHFT. Фактически, новая структура представляет собой его модифицированную версию, где основные принципы построения были сохранены, но внесены целенаправленные изменения, для повышения эффективности обработки данных.
Ключевое отличие заключается в измененной конфигурации агентов анализа окружающей среды. В данной версии применяется шесть специализированных агентов: четыре из них выполняют анализ многомерных временных последовательностей, а два предназначены для обработки исходных данных в частотном домене. Для обеспечения сбалансированного анализа, все агенты равномерно распределены между обработкой прямого и транспонированного представлений исходных данных. Такая архитектура позволяет более детально исследовать различные аспекты исходных данных, выделяя скрытые закономерности и адаптивно корректируя стратегию обработки.
В целом же, изменение структуры агентов внесло лишь незначительные правки в алгоритмы работы методов нового объекта. Основная логика функционирования осталась неизменной, и все ключевые принципы работы модели сохраняются. Пользуясь этим, я предлагаю вам самостоятельно ознакомиться с алгоритмами построения методов. Полный код данного объекта и всех его методов представлен во вложении.
Архитектура модели
Несколько слов скажем об архитектуре обучаемой модели. Думаю вы заметили, что построенная нами архитектура является некой синергией фреймворков Hidformer и MacroHFT. Архитектура обучаемой модели и методы её обучения не стали исключением. В рамках своей работы, мы скопировали архитектуру модели, построенной при реализации фреймворка MacroHFT и заменили лишь один слой.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronHidformer; //--- Windows { int temp[] = {BarDescr, 120, NActions}; //Window, Stack Size, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Scales descr.layers =3; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
В остальном, архитектура работы осталась без изменений, включая использование агента риск-менеджмента. Полное описание архитектуры модели вы найдете во вложении. Там же представлен полный код программ обучения и тестирования модели, которые были полностью перенесены из предыдущей статьи без изменений.
Тестирование
Мы с вами проделали довольно большую работу по реализации собственного видения подходов, предложенных авторами фреймворка Hidformer. И теперь приблизились к наиболее ответственному моменту — проверке эффективности реализованных решений на реальных исторических данных. В своей реализации мы многое позаимствовали из фреймворка MacroHFT. И вполне логично сравнить результаты работы новой модели именно с этим фреймворком. С этой целью мы обучаем новую модель на обучающей выборке ранее собранной для обучения модели нашей реализации фреймворка MacroHFT.
Напомню, что обучающая выборка собиралась на исторических данных за весь 2024 год валютной пары EURUSD таймфрейм M1. Параметры всех анализируемых индикаторов используются по умолчанию.
Для обучения и тестирования модели использовались те же советники. Тестирование модели осуществляется на исторических данных Января 2025 года, с сохранением всех прочих параметров. Результаты тестирования представлены ниже.
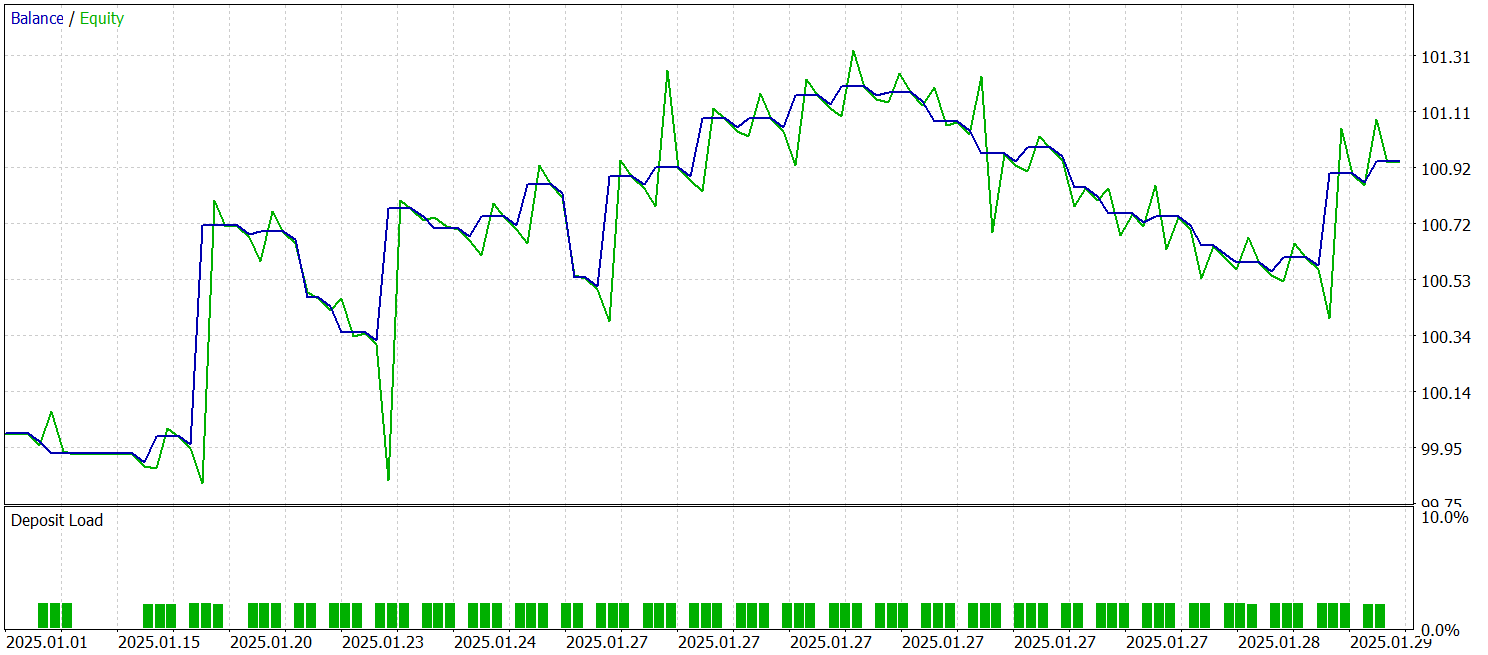
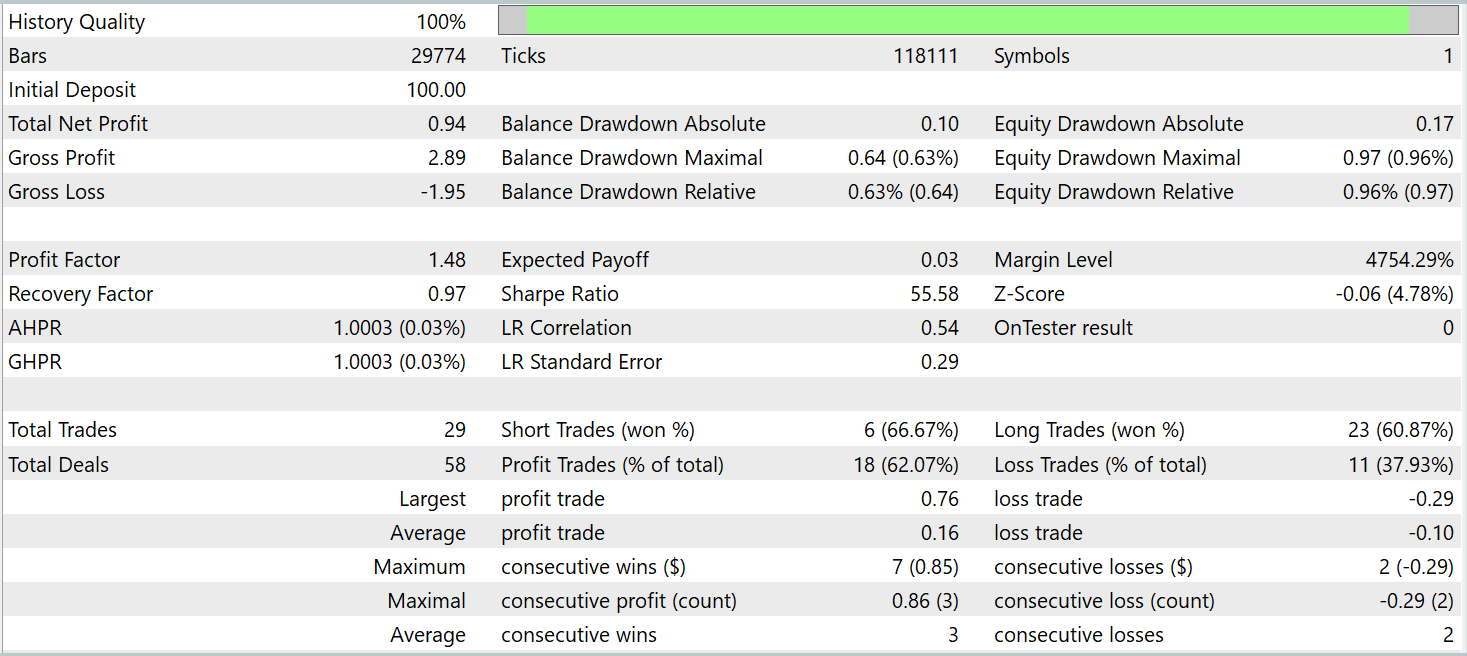
По результатам тестирования, модель смогла получить прибыль на исторических данных за пределами обучающей выборки. В целом, за календарный месяц, модель совершила 29 сделок. Это в среднем чуть более одной сделки в торговый день, что конечно мало для высокочастотной торговли. При этом, мы получили более 60% прибыльных сделок, и средняя прибыльная сделка на 60% превышает среднюю убыточную.
Заключение
Мы познакомились с фреймворком Hidformer, который предназначен для анализа и прогнозирования сложных многомерных временных рядов. Модель демонстрирует высокую эффективность, благодаря уникальной архитектуре двухбашенного энкодера. Одна башня специализируется на анализе временной структуры исходных данных, а вторая работает с их частотным представлением. Использование рекурсивного механизма внимания позволяет выявлять сложные паттерны изменений цен, а линейный механизм внимания позволяет снизить вычислительную сложность анализа длинных последовательностей.
В практической части нашей работы представлена реализация собственного видения предложенных подходов средствами MQL5. Мы обучили модель на реальных исторических данных и провели её тестирование на данных, не входящих в обучающую выборку. Результаты тестирования демонстрируют потенциал модели. Однако, перед использованием для торговли на реальных рынках необходимо обучение модели на более репрезентативных данных, с последующим всесторонним тестированием.
Ссылки
- Hidformer: Transformer-Style Neural Network in Stock Price Forecasting
- Hidformer: Hierarchical dual-tower transformer using multi-scale mergence for long-term time series forecasting
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования