
取引におけるニューラルネットワーク:階層型ダブルタワーTransformer (Hidformer)

はじめに
データの時間的構造を捉え、潜在的なパターンを特定できるニューラルネットワークモデルの需要は、特に金融予測の分野で高まっています。しかし、従来のニューラルネットワークアプローチには、高い計算複雑性や結果の解釈性の不足といった制約があります。そのため、近年では、アテンション機構に基づくアーキテクチャが注目を集めており、時系列データや金融データのより正確な解析を可能にしています。
特にTransformerアーキテクチャとその派生モデルは高い人気を誇ります。その一例として、論文「Hidformer:Transformer-Style Neural Network in Stock Price Forecasting」で紹介されたHidformerがあります。このモデルは時系列解析に特化しており、最適化されたアテンション機構による予測精度の向上、長期依存関係の効率的な特定、金融データ特性への適応を重視しています。Hidformerの最大の利点は、複雑な時間的関係性を考慮できる点にあります。これは複数の要因が資産価格に影響を与える株式市場分析において特に重要です。
このフレームワークでは、時間的依存関係の改善、計算複雑性の削減、予測精度の向上が提案されており、Hidformerは金融分析および予測の有力なツールとなっています。
Hidformerアルゴリズム
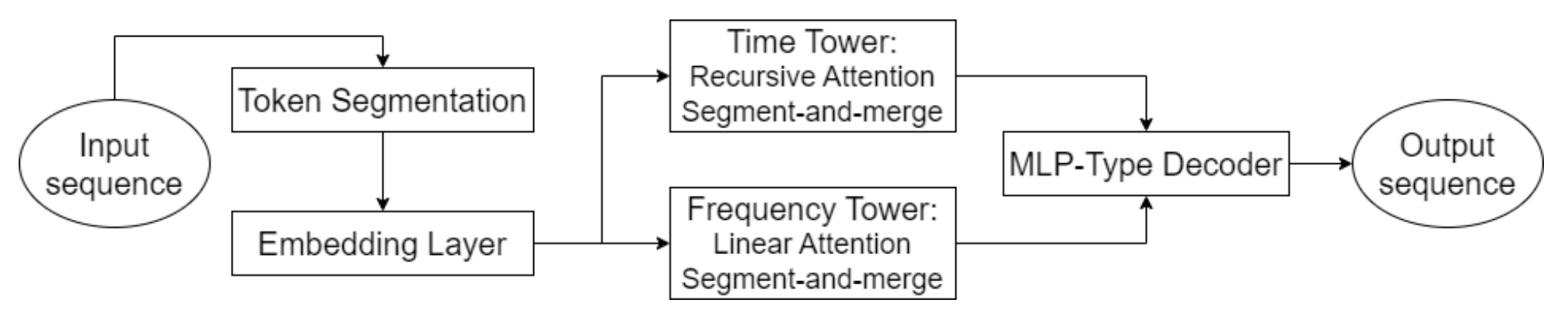
Hidformerの主な特徴のひとつは、2つのエンコーダーによるデータの並列処理です。1つ目のエンコーダーは時間的特徴を解析し、時間の経過に伴う傾向やパターンを特定します。2つ目は周波数領域で動作し、モデルがより深い依存関係を捉え、市場のノイズを排除することを可能にします。このアプローチにより、データに隠れたパターンを明らかにすることができます。これは、信号がノイズによって覆われることがある株価予測において非常に重要です。入力データはサブシーケンスに分割され、各処理段階で統合されることで、重要なパターンの検出が向上します。
この手法は、特にテクノロジー株や暗号通貨のようなボラティリティの高い資産を分析する際に有用であり、短期的な変動から基本的なトレンドを分離するのに役立ちます。Hidformerの著者は、従来のTransformerアーキテクチャで用いられるマルチヘッドアテンションの代わりに、時間的エンコーダーでは再帰型アテンション機構を、周波数スペクトルの依存関係を特定するために線形アテンション機構を提案しています。これにより、計算リソースの消費が抑えられ、予測の安定性が向上し、大量の市場データを扱う際にも効率的にモデルを運用できます。
モデルのデコーダーは多層パーセプトロンに基づいており、価格の全シーケンスを一度に予測できます。その結果、段階的に予測する際に蓄積される可能性のある誤差が排除されます。このアーキテクチャは、長期予測における不正確さの蓄積の可能性を減らすため、特に金融予測において有利です。
Hidformerフレームワークのオリジナルの視覚化を以下に示します。
MQL5での実装
Hidformerフレームワークの理論的側面を簡単に確認した後、次にMQL5を用いて提案されたアプローチを独自に解釈した実装に移ります。まずは、修正版のアテンションアルゴリズムの実装から始めます。
まず、再帰型アテンションアルゴリズムを見てみましょう。もともとは視覚対話問題を解決するために提案された再帰型アテンション機構は、過去の対話履歴に基づいて現在のクエリの正しい文脈を特定するのに役立ちます。明らかに、マルチヘッドアテンションの並列計算と比べてデータの再帰的処理はタスクを複雑にするだけです。一方で、再帰型アプローチは、必要な文脈を含む最も近い関連要素で処理を止めることで、履歴全体を処理する必要を回避できます。
このような考え方により、マルチスケールアテンションアルゴリズムの構築につながります。以前は、アテンションウィンドウを調整することで局所的および全体的な特徴を捉えるさまざまな手法について議論しました。しかし以前は、異なるアテンションレベルが別々のコンポーネントで使用されていました。今回は、以前のマルチヘッドアテンションアルゴリズムを修正し、各ヘッドが独自のコンテキストウィンドウを受け取るように提案します。さらに、コンテキストウィンドウを分析対象の要素の周囲ではなく、シーケンスの先頭から定義することを提案します。最新のデータはシーケンスの先頭に格納されます。このアプローチにより、現在の市場状況を考慮したうえで、分析対象の履歴を評価できます。
OpenCLでのアテンション修正
まず、先に説明した変更をOpenCL側で実装します。そのために、新しいカーネルMultiScaleRelativeAttentionOutを作成し、元のカーネルMHRelativeAttentionOutからほとんどのコードをコピーします。カーネルのパラメータリストは変更せずにそのまま引き継ぎます。
__kernel void MultiScaleRelativeAttentionOut(__global const float * q, ///<[in] Matrix of Querys __global const float * k, ///<[in] Matrix of Keys __global const float * v, ///<[in] Matrix of Values __global const float * bk, ///<[in] Matrix of Positional Bias Keys __global const float * bv, ///<[in] Matrix of Positional Bias Values __global const float * gc, ///<[in] Global content bias vector __global const float * gp, ///<[in] Global positional bias vector __global float * score, ///<[out] Matrix of Scores __global float * out, ///<[out] Matrix of attention const int dimension ///< Dimension of Key ) { //--- init const uint q_id = get_global_id(0); const uint k_id = get_local_id(1); const uint h = get_global_id(2); const uint qunits = get_global_size(0); const uint kunits = get_local_size(1); const uint heads = get_global_size(2); const int shift_q = dimension * (q_id * heads + h); const int shift_kv = dimension * (heads * k_id + h); const int shift_gc = dimension * h; const int shift_s = kunits * (q_id * heads + h) + k_id; const int shift_pb = q_id * kunits + k_id; const uint ls = min((uint)get_local_size(1), (uint)LOCAL_ARRAY_SIZE); const uint window = fmax((kunits + h) / (h + 1), fmin(3, kunits)); float koef = sqrt((float)dimension);
メソッド内では、まず準備作業を実装します。ここで、コンテキストウィンドウを含む必要な定数をすべて定義します。
注意すべき点として、各アテンションヘッドごとの個別の文脈サイズを渡すための別のバッファは作成していません。その代わりに、分析対象のシーケンスの長さをアテンションヘッドのIDに1を加えた値で割っています(IDは0から始まるためです)。そのため、最初のヘッドはシーケンス全体を分析し、以降のヘッドは順次小さなコンテキストウィンドウで処理をおこないます。
次に、アテンション係数を算出します。各実行スレッドは特定の要素に対して1つの係数を計算します。ただし、演算はコンテキストウィンドウ内でのみおこなわれます。ウィンドウ外の要素には、自動的にアテンション重みとして0が割り当てられます。
__local float temp[LOCAL_ARRAY_SIZE]; //--- score float sc = 0; if(k_id < window) { for(int d = 0; d < dimension; d++) { float val_q = q[shift_q + d]; float val_k = k[shift_kv + d]; float val_bk = bk[shift_kv + d]; sc += val_q * val_k + val_q * val_bk + val_k * val_bk + gc[shift_q + d] * val_k + gp[shift_q + d] * val_bk; } sc = sc / koef; }
係数の安定性を向上させるために、値を数値的に安定な領域にシフトします。そのために、コンテキストウィンドウ外の要素を除いた計算済みの係数の中から最大値を求めます。
//--- max value for(int cur_k = 0; cur_k < kunits; cur_k += ls) { if(k_id < window) if(k_id >= cur_k && k_id < (cur_k + ls)) { int shift_local = k_id % ls; temp[shift_local] = (cur_k == 0 ? sc : fmax(temp[shift_local], sc)); } barrier(CLK_LOCAL_MEM_FENCE); } uint count = min(ls, kunits); //--- do { count = (count + 1) / 2; if(k_id < (window + 1) / 2) if(k_id < ls) temp[k_id] = (k_id < count && (k_id + count) < kunits ? fmax(temp[k_id + count], temp[k_id]) : temp[k_id]); barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
その後に初めて、各係数から最大値を引いた値の指数を計算します。
if(k_id < window) sc = IsNaNOrInf(exp(fmax(sc - temp[0], -120)), 0); barrier(CLK_LOCAL_MEM_FENCE);
ただし、コンテキストウィンドウ内での演算には特に注意する必要があります。最大値をゼロにシフトすることで、最大の指数は1になります。他のすべての係数は0から1の範囲に収まります。これにより、SoftMax関数の安定性が向上します。しかし、コンテキストウィンドウ外の係数は自動的にゼロに設定されているため、その指数を計算すると最大の重みが割り当てられてしまい、これは非常に望ましくありません。そのため、コンテキストウィンドウ外の値はゼロのまま保持する必要があります。
次に、作業グループ内の係数を合計します。
//--- sum of exp for(int cur_k = 0; cur_k < kunits; cur_k += ls) { if(k_id >= cur_k && k_id < (cur_k + ls)) { int shift_local = k_id % ls; temp[shift_local] = (cur_k == 0 ? 0 : temp[shift_local]) + sc; } barrier(CLK_LOCAL_MEM_FENCE); } //--- count = min(ls, (uint)kunits); do { count = (count + 1) / 2; if(k_id < count && k_id < (window + 1) / 2) temp[k_id] += ((k_id + count) < kunits ? temp[k_id + count] : 0); if(k_id + count < ls) temp[k_id + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
次に、計算された合計で各係数を割って正規化します。
//--- score float sum = IsNaNOrInf(temp[0], 1); if(sum <= 1.2e-7f) sum = 1; sc /= sum; score[shift_s] = sc; barrier(CLK_LOCAL_MEM_FENCE);
正規化された係数は、対応するデータバッファに書き込みます。
シーケンス要素の正規化されたアテンション重みを取得した後、現在の要素の調整値を計算できます。そのために、シーケンスを順に処理し、Valueテンソルに各係数を掛けた後、その結果を合計します。
//--- out int shift_local = k_id % ls; for(int d = 0; d < dimension; d++) { float val_v = v[shift_kv + d]; float val_bv = bv[shift_kv + d]; float val = IsNaNOrInf(sc * (val_v + val_bv), 0); //--- sum of value for(int cur_v = 0; cur_v < kunits; cur_v += ls) { if(k_id >= cur_v && k_id < (cur_v + ls)) temp[shift_local] = (cur_v == 0 ? 0 : temp[shift_local]) + val; barrier(CLK_LOCAL_MEM_FENCE); } //--- count = min(ls, (uint)kunits); do { count = (count + 1) / 2; if(k_id < count && (k_id + count) < kunits) temp[k_id] += temp[k_id + count]; if(k_id + count < ls) temp[k_id + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- if(k_id == 0) out[shift_q + d] = IsNaNOrInf(temp[0], 0); barrier(CLK_LOCAL_MEM_FENCE); } }
出力は、指定されたデータバッファに格納されます。
ゼロの重みを保持することで、既存のツールを使用してバックプロパゲーションアルゴリズムを実装することができます。これでOpenCL側での作業は完了です。完全なソースコードは添付ファイルに含まれています。
マルチスケールアテンションオブジェクトの作成
次に、メインプログラム内でマルチスケールアテンションオブジェクトを作成する必要があります。オブジェクトの継承を最大限に活用するため、既存のメソッドをベースにSelf-AttentionオブジェクトとCross-Attentionオブジェクトを作成し、新しく作成したカーネルを呼び出すメソッドのみをオーバーライドしました。新しいオブジェクトの構造は以下の通りです。
class CNeuronMultiScaleRelativeSelfAttention : public CNeuronRelativeSelfAttention { protected: //--- virtual bool AttentionOut(void); public: CNeuronMultiScaleRelativeSelfAttention(void) {}; ~CNeuronMultiScaleRelativeSelfAttention(void) {}; //--- virtual int Type(void) override const { return defNeuronMultiScaleRelativeSelfAttention; } };
class CNeuronMultiScaleRelativeCrossAttention : public CNeuronRelativeCrossAttention { protected: virtual bool AttentionOut(void); public: CNeuronMultiScaleRelativeCrossAttention(void) {}; ~CNeuronMultiScaleRelativeCrossAttention(void) {}; //--- virtual int Type(void) override const { return defNeuronMultiScaleRelativeCrossAttention; } };
カーネルの実行キューイングには、従来の方法を使用しました。類似の手法はすでに何度も確認してきたので、容易に理解できるでしょう。これらのメソッドの完全なコードは付録に記載されています。
再帰型アテンションオブジェクト
前述のマルチスケールアテンションオブジェクトにより、さまざまなコンテキストウィンドウサイズでデータを解析することができます。しかし、これはHidformerの著者が提案した再帰型アテンション機構そのものではありません。あくまで準備段階を完了したに過ぎません。
次のステップは、過去に観測した履歴の文脈で現在のデータを解析できる再帰型アテンションオブジェクトを構築することです。そのために、いくつかのメモリモジュール設計手法を使用します。具体的には、定義された履歴深さに応じて観測済み状態の文脈を保存し、それを用いて現在の状態を評価します。このアルゴリズムはCNeuronRecursiveAttentionメソッド内で実装し、その構造は以下の通りです。
class CNeuronRecursiveAttention : public CNeuronMultiScaleRelativeCrossAttention { protected: CNeuronMultiScaleRelativeSelfAttention cSelfAttention; CNeuronTransposeOCL cTransposeSA; CNeuronConvOCL cConvolution; CNeuronEmbeddingOCL cHistory; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return false; } public: CNeuronRecursiveAttention(void) {}; ~CNeuronRecursiveAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint history_size, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRecursiveAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
この場合の親クラスは、前に実装したマルチスケールクロスアテンションオブジェクトです。
メソッド内では、既知のオーバーライドされた仮想メソッドのセットと、フィードフォワードおよびバックプロパゲーションの処理中に機能を確認するいくつかの内部オブジェクトが見られます。
すべての内部オブジェクトは静的に宣言されているため、クラスのコンストラクタおよびデストラクタは空のままとします。継承されたすべてのオブジェクトと新たに宣言されたオブジェクトの初期化はInitメソッド内でおこなわれます。
bool CNeuronRecursiveAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint history_size, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMultiScaleRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, window, window_key, units_count, heads, window_key, history_size, optimization_type, batch)) return false;
メソッドのパラメータには、作成されるオブジェクトのアーキテクチャを明確に定義する複数の定数が含まれています。重要なのは、クロスアテンションクラスを継承しているにもかかわらず、私たちのオブジェクトは単一の入力データストリームで動作するという点です。親クラスの正しい動作に必要な2つ目のデータストリームは内部で生成されます。この2つ目のストリームのシーケンス長は、履歴深さパラメータhistory_sizeによって定義されます。
通常通り、同名の親クラスメソッドをすぐに呼び出し、必要なパラメータを渡します。親メソッドには、継承されたオブジェクトの初期化手順や基本インターフェースを含むすべての制御点がすでに含まれていることを思い出してください。
次に、新たに宣言した内部オブジェクトの初期化をおこないます。1つ目は、マルチスケールSelf-Attentionモジュールです。
int index = 0; if(!cSelfAttention.Init(0, index, OpenCL, iWindow, iWindowKey, iUnits, iHeads, optimization, iBatch)) return false;
このオブジェクトを使用することで、元のデータのどの要素が、分析対象の金融商品の現在の状態に最も影響を与えているかを特定できます。
次に、現在の環境状態の文脈を再帰型アテンションブロックのメモリに追加する必要があります。個々の単変量シーケンスの文脈を保持したいため、まず入力データを転置します。
index++; if(!cTransposeSA.Init(0, index, OpenCL, iUnits, iWindow, optimization, iBatch)) return false;
その後、畳み込み層を使用して単一シーケンスの文脈を抽出します。
index++; if(!cConvolution.Init(0, index, OpenCL, iUnits, iUnits, iWindowKey, 1, iWindow, optimization, iBatch)) return false;
ここで注意すべきは、畳み込み層のパラメータは分析対象シーケンスの単一要素を指定しており、単一シーケンスの数は独立変数の数として渡される点です。これにより、各単一シーケンスが独自の学習可能パラメータセットを使用して完全に独立して解析され、元のマルチモーダルシーケンスのより深い分析が可能になります。
次に、埋め込み生成層を使用して分析対象環境状態の文脈を取得し、履歴メモリスタックに追加します。
index++; uint windows[] = { iWindowKey * iWindow }; if(!cHistory.Init(0, index, OpenCL, iUnitsKV, iWindowKey, windows)) return false; //--- return true; }
すべての操作が正常に完了した後、呼び出し元プログラムに論理的な成功値を返し、メソッドを終了します。
次のステップはfeedForwardメソッドを実装することです。アルゴリズムは比較的線形です。
bool CNeuronRecursiveAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cSelfAttention.FeedForward(NeuronOCL)) return false;
メソッドはマルチモーダル時系列を含む入力データオブジェクトへのポインタを受け取り、まずこのポインタをSelf-Attentionモジュールに渡して、現在の環境状態における依存関係を解析します。その結果はさらに処理するために転置されます。
if(!cTransposeSA.FeedForward(cSelfAttention.AsObject())) return false;
畳み込み層を使って単一シーケンスの文脈を抽出します。
if(!cConvolution.FeedForward(cTransposeSA.AsObject())) return false;
準備されたデータを埋め込み生成器に渡し、分析対象状態の文脈を取得してメモリスタックに追加します。
if(!cHistory.FeedForward(cConvolution.AsObject())) return false;
次に、以前取得したSelf-Attentionの結果を、履歴シーケンスの文脈で補完する必要があります。そのために親クラスの対応するメソッドを使用し、必要な情報を渡します。
return CNeuronMultiScaleRelativeCrossAttention::feedForward(cSelfAttention.AsObject(),
cHistory.getOutput());
}
ポイントとして、現在の状態を過去に観測した状態の文脈で解析するため、以前作成したマルチスケールアテンションオブジェクトを使用します。このアプローチにより、最近観測されたデータにより大きな重みを割り当て、古い情報の影響を減らすことができます。それでも「記憶の奥深く」から重要なポイントを抽出する能力は保持されます。
メソッドの最後に、初期化の成功または失敗を示すブール値を呼び出し元に返します。
Self-Attentionの結果はフィードフォワードパスで二度使用されるため、これはcalcInputGradientsメソッドで実装されるバックプロパゲーションアルゴリズムに影響します。
bool CNeuronRecursiveAttention::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
バックプロパゲーションメソッドは同じ入力データオブジェクトへのポインタを受け取りますが、今回はモデル出力に対する誤差の勾配を渡す必要があります。
メソッド内で、まず受け取ったポインタの有効性を確認します。存在しないオブジェクトにデータを渡すことはできず、以降の操作は意味を失うため、ここを通過した場合のみ処理を続行します。
ご存知の通り、フィードフォワードパスとバックプロパゲーションパスの情報フローは概念的に完全に対応しており、方向だけが異なります。フィードフォワードパスは親クラスメソッドの呼び出しで終了するため、バックプロパゲーションパスはその継承メソッドの呼び出しから開始されます。後者は、最終結果への寄与に応じて、2つのデータストリーム間で以前受け取った勾配を分配します。
if(!CNeuronMultiScaleRelativeCrossAttention::calcInputGradients(cSelfAttention.AsObject(), cHistory.getOutput(), cHistory.getGradient(), (ENUM_ACTIVATION)cHistory.Activation())) return false;
まず、オブジェクトのメモリに対応する補助データストリームに勾配を分配します。ここで、単一シーケンスの文脈を抽出する畳み込み層まで誤差を伝播します。
if(!cConvolution.calcHiddenGradients(cHistory.AsObject())) return false;
次に、Self-Attentionブロックの転置層まで勾配を伝播します。
if(!cTransposeSA.calcHiddenGradients(cConvolution.AsObject())) return false;
次に、マルチスケールSelf-Attention層に勾配を渡す必要があります。しかし、以前にすでにメインデータストリームの勾配を伝播済みであり、これは保持する必要があります。そのため、データバッファのポインタを一時的に入れ替えます。まず、オブジェクトに空きバッファのポインタを渡し、既存のバッファを保存します。
CBufferFloat *temp = cSelfAttention.getGradient(); if(!cSelfAttention.SetGradient(cTransposeSA.getPrevOutput(), false) || !cSelfAttention.calcHiddenGradients(cTransposeSA.AsObject()) || !SumAndNormilize(temp, cSelfAttention.getGradient(), temp, iWindow, false, 0, 0, 0, 1) || !cSelfAttention.SetGradient(temp, false)) return false;
その後、誤差勾配を伝播し、2つのデータストリームの値を合計します。その後、バッファポインタを元の状態に戻します。
最後に、入力データレベルまで勾配を伝播します。
if(!NeuronOCL.calcHiddenGradients(cSelfAttention.AsObject())) return false; //--- return true; }
メソッドの最後に、論理的な成功値を返します。
オブジェクトとその全メソッドの完全なコードは、付録にて参照可能です。
線形アテンションオブジェクト
前述の再帰型アテンションオブジェクトに加えて、フレームワークの著者は周波数スペクトル解析を担当するタワーで線形アテンションを使用することも提案しています。
線形アテンションは、transformerにおける従来のアテンション機構を最適化する手法のひとつです。従来のSelf-Attentionは、二次の計算量を持つ全結合行列演算に依存していましたが、線形アテンションは計算量を線形に削減するため、長いシーケンスの処理において効率的です。
線形アテンションではφ(Q)とφ(K)という因数分解を導入することで、アテンション計算をより効率的に表現できます。
![]()
線形アテンションの利点
- 線形計算量:計算コストが削減され、長いシーケンスの処理が可能です。
- 低メモリ消費:依存係数の完全なScore行列を保持する必要がないため、メモリ要件が減少します。
- オンラインタスクへの効率性:データがストリーミングで更新される場合にも対応可能です。
- カーネル選択の柔軟性:φ(x)関数を変更することで、特定のタスクにアテンション機構を適応させられます。
線形アテンションアルゴリズムの実装は、CNeuronLinerAttentionオブジェクト内にカプセル化されています。その構造は以下の通りです。
class CNeuronLinerAttention : public CNeuronBaseOCL { protected: uint iWindow; uint iWindowKey; uint iUnits; uint iVariables; //--- CNeuronConvOCL cQuery; CNeuronConvOCL cKey; CNeuronTransposeVRCOCL cKeyT; CNeuronBaseOCL cKeyValue; CNeuronBaseOCL cAttentionOut; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronLinerAttention(void) {}; ~CNeuronLinerAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronLinerAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
このオブジェクトには、アルゴリズムの実行に重要な内部オブジェクトと基本的なオーバーライドメソッドが含まれています。新しいクラスメソッドの実装中に、それらの機能についてさらに詳しく調べます。
宣言されたメソッドはすべて静的なので、コンストラクタとデストラクタを空のままにすることができます。継承および宣言されたすべてのオブジェクトは、Initメソッドで初期化されます。このメソッドのパラメータは、作成されるオブジェクトのアーキテクチャを定義するためのものです。
bool CNeuronLinerAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * variables, optimization_type, batch)) return false;
メソッド本体では、最初に同名の親クラスメソッドが呼び出されます。この場合は、全結合層です。
次に、主要なアーキテクチャパラメータを内部変数に保存し、内部オブジェクトの初期化を進めます。
iWindow = window; iWindowKey = fmax(window_key, 1); iUnits = units_count; iVariables = variables;
まず、QueryおよびKeyエンティティを生成する畳み込み層の初期化をおこないます。Queryを形成する際にはシグモイド活性化関数を使用します。これにより、各要素がオブジェクトに与える影響度を示すことができます。
int index = 0; if(!cQuery.Init(0, index, OpenCL, iWindow, iWindow, iWindowKey, iUnits, iVariables, optimization, iBatch)) return false; cQuery.SetActivationFunction(SIGMOID); index++; if(!cKey.Init(0, index, OpenCL, iWindow, iWindow, iWindowKey, iUnits, iVariables, optimization, iBatch)) return false; cKey.SetActivationFunction(TANH);
Keyエンティティには双曲線正接(tanh)を活性化関数として使用します。これにより、各要素が与える正の影響と負の影響の両方を判定できます。
次に、Keyの行列転置オブジェクトを初期化します。
index++; if(!cKeyT.Init(0, index, OpenCL, iVariables, iUnits, iWindowKey, optimization, iBatch)) return false; cKeyT.SetActivationFunction(TANH);
その後、Key行列とValue行列の積を格納するオブジェクトを初期化します。
index++; if(!cKeyValue.Init(0, index, OpenCL, iWindow * iWindowKey, optimization, iBatch)) return false; cKeyValue.SetActivationFunction(None);
ここで注意すべき点として、Valueエンティティを生成する層は使用せず、入力データをそのまま利用する設計になっています。
アテンションの結果は、専用に作成した内部オブジェクトに格納されます。
index++; if(!cAttentionOut.Init(0, index, OpenCL, Neurons(), optimization, iBatch)) return false; cAttentionOut.SetActivationFunction(None);
親クラスのインターフェースを使用して残差接続を作成します。不要なデータコピーを避けるため、勾配バッファへのポインタを差し替えます。
if(!SetGradient(cAttentionOut.getGradient(), true)) return false; //--- return true; }
メソッドを終了する前に、処理の成功を示すブール値を呼び出し元プログラムに返します。
初期化が完了したら、feedForwardメソッドでフォワードパスアルゴリズムの実装に進みます。
bool CNeuronLinerAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cQuery.FeedForward(NeuronOCL)) return false; if(!cKey.FeedForward(NeuronOCL) || !cKeyT.FeedForward(cKey.AsObject())) return false;
このメソッドは、多次元の入力データシーケンスへのポインタを受け取ります。受け取ったデータはすぐに使用され、QueryおよびKeyエンティティを形成します。
次に、転置されたKey行列と入力データを掛け合わせることで、各オブジェクトが分析対象のシーケンスに与える影響を算出します。
if(!MatMul(cKeyT.getOutput(), NeuronOCL.getOutput(), cKeyValue.getOutput(), iWindowKey, iUnits, iWindow, iVariables)) return false;
線形アテンションの結果を得るために、Queryテンソルと前の演算の出力を掛け合わせます。
if(!MatMul(cQuery.getOutput(), cKeyValue.getOutput(), cAttentionOut.getOutput(), iUnits, iWindowKey, iWindow, iVariables)) return false;
その後、残差接続を加え、演算結果を正規化します。
if(!SumAndNormilize(NeuronOCL.getOutput(), cAttentionOut.getOutput(), Output, iWindow, true, 0, 0, 0, 1)) return false; //--- return true; }
次に、操作の論理結果を呼び出し元に返して、メソッドの実行を完了します。
次に、モデル出力への寄与に応じて、誤差勾配をすべての内部オブジェクトおよび入力データに分配する必要があります。通常通り、これらの操作はcalcInputGradientsメソッド内でおこなわれます。このメソッドは入力データオブジェクトへのポインタを受け取り、今回は結果を書き込むために使用されます。
bool CNeuronLinerAttention::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
メソッド本体では、受け取ったポインタの妥当性を即座に確認します。前述した通り、この制御点は非常に重要です。
バッファポインタを差し替えているため、次のニューラル層から受け取った誤差勾配は自動的に内部の線形アテンション結果オブジェクトに入力されます。その後、情報フロー全体に配布されます。
if(!MatMulGrad(cQuery.getOutput(), cQuery.getGradient(), cKeyValue.getOutput(), cKeyValue.getGradient(), cAttentionOut.getGradient(), iUnits, iWindowKey, iWindow, iVariables)) return false; if(!MatMulGrad(cKeyT.getOutput(), cKeyT.getGradient(), NeuronOCL.getOutput(), cAttentionOut.getPrevOutput(), cKeyValue.getGradient(), iWindowKey, iUnits, iWindow, iVariables)) return false;
入力データに伝播される勾配は、以下の4つの情報フローで構成されていることに注意してください。
- Queryエンティティ
- Keyエンティティ
- Key*Valueの積
- 残差接続
前の操作では、Key*Valueの積から得られた勾配を空きバッファに保存しました。残差勾配は、現在のオブジェクトの出力から完全に伝播されます。これらの勾配はまだ、入力オブジェクトの活性化関数の微分による調整はされていません。しかし、畳み込み層のQuery/Keyを通して勾配を伝播する際に、対応する活性化関数の微分で調整がおこなわれます。すべてのフローで整合性を確保するために、勾配を合計し、入力オブジェクトの活性化関数の微分を適用します。その結果は空きバッファに格納されます。
if(!SumAndNormilize(Gradient, cAttentionOut.getPrevOutput(), cAttentionOut.getPrevOutput(), iWindow, false, 0, 0, 0, 1)) return false; //--- if(NeuronOCL.Activation() != None) if(!DeActivation(NeuronOCL.getOutput(), cAttentionOut.getPrevOutput(), cAttentionOut.getPrevOutput(), NeuronOCL.Activation())) return false;
他の情報フローについても、それぞれの活性化関数の微分に従って勾配を調整します。
if(cKeyT.Activation() != None) if(!DeActivation(cKeyT.getOutput(), cKeyT.getGradient(), cKeyT.getGradient(), cKeyT.Activation())) return false; if(cQuery.Activation() != None) if(!DeActivation(cQuery.getOutput(), cQuery.getGradient(), cQuery.getGradient(), cQuery.Activation())) return false;
次に、Key情報フローを通して勾配を伝播し、その結果を累積します。
if(!cKey.calcHiddenGradients(cKeyT.AsObject()) || !NeuronOCL.calcHiddenGradients(cKey.AsObject()) || !SumAndNormilize(NeuronOCL.getGradient(), cAttentionOut.getPrevOutput(), cAttentionOut.getPrevOutput(), iWindow, false, 0, 0, 0, 1)) return false;
Queryフローについても同様に処理をおこない、その後、結合された勾配を入力オブジェクトに渡します。
if(!NeuronOCL.calcHiddenGradients(cQuery.AsObject()) || !SumAndNormilize(NeuronOCL.getGradient(), cAttentionOut.getPrevOutput(), NeuronOCL.getGradient(), iWindow, false, 0, 0, 0, 1)) return false; //--- return true; }
メソッドの最後に、ブール値の成功値を返します。
これで、線形アテンションオブジェクトのメソッドについての説明は終了です。クラス全体のコードおよびすべてのメソッドは、付録で確認できます。
私たちは多くの作業をおこない、本記事の終わりに到達しました。しかし、作業はまだ完了していません。ここで少し休憩を取り、次の記事で論理的なまとめへと進みます。
結論
本記事では、金融データを含む時系列予測において高い性能を示すHidformerフレームワークを検討しました。その最大の特徴は、生データを時間的シーケンスとして解析するタワーと、周波数特性として解析するタワーを分離したダブルタワーエンコーダーを採用している点です。これにより、Hidformerは変化する市場環境に対して高い柔軟性と適応性を備えています。
記事の実装パートでは、Hidformerフレームワークの著者によって提案された複数のコンポーネントを実装しました。しかし、私たちの作業はまだ途中であり、近い将来この続きに取り組む予定です。
参照文献
- Hidformer:Transformer-Style Neural Network in Stock Price Forecasting
- Hidformer:Hierarchical dual-tower transformer using multi-scale mergence for long-term time series forecasting
- この連載の他の記事
記事で使用されているプログラム
| # | 名前 | 種類 | 説明 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いたサンプル収集用EA |
| 3 | Study.mq5 | EA | モデル学習用EA |
| 4 | Test.mq5 | EA | モデルテスト用EA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態とモデルアーキテクチャ記述構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコード |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17069
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
トレーディングにおけるニューラルネットワーク:階層的2バー・トランスフォーマー(Hidformer)が掲載されました:
著者:Dmitriy Gizlyk
こんにちは、ドミトリー、
OnTesterDeinit()によると、コードはテスターモードで(つまりStrategyTesterで)NNファイルを保存するはずです。
これは起こりません。また、このOnTesterDeinit()は呼び出されないようです。print 文が見当たらないからです。
これはMQL5のアップデートによるものですか?それとも、あなたのコードがファイルを保存しなくなったのはなぜですか?
これはMQL5のアップデートによるものですか?それとも、あなたのコードがファイルを保存しなくなったのはなぜですか?
親愛なるアンドレアス、
OnTesterDeinit は最適化モードでのみ実行されます。https://www.mql5.com/en/docs/event_handlers/ontesterdeinit のドキュメントをご参照ください。
テスターにモデルを保存しないのは、このEAがモデルを研究しないためです。以前に研究したモデルの有効性をチェックする必要があるからです。
よろしくお願いします。
Dmitriy.