
Neuronale Netze im Handel: Hierarchical Dual-Tower Transforme (letzter Teil)

Einführung
Im vorangegangenen Artikel haben wir die theoretischen Aspekte von Hidformer besprochen, der speziell für die Analyse und Prognose komplexer multivariater Zeitreihen entwickelt wurde. Das Modell zeigt dank seiner einzigartigen Architektur eine hohe Effizienz bei der Verarbeitung dynamischer und flüchtiger Daten.
Ein Schlüsselelement von Hidformer ist der Einsatz fortschrittlicher Aufmerksamkeitsmechanismen, die es nicht nur ermöglichen, explizite Abhängigkeiten in den Daten zu identifizieren, sondern auch tiefere, latente Beziehungen aufzudecken. Um dies zu erreichen, verwendet das Modell einen Doppelturm-Encoder, wobei jeder Turm eine unabhängige Analyse der Rohdaten durchführt. Ein Turm ist auf die Analyse der zeitlichen Struktur und die Ermittlung von Trends und Mustern spezialisiert, während der zweite Turm die Daten im Frequenzbereich untersucht. Dieser Ansatz bietet ein umfassendes Verständnis der Marktdynamik und ermöglicht es dem Modell, sowohl kurzfristige als auch langfristige Veränderungen der Preisreihen zu berücksichtigen.
Ein innovativer Aspekt des Modells ist die Verwendung eines rekursiven Aufmerksamkeitsmechanismus zur Analyse zeitlicher Abhängigkeiten, der es ihm ermöglicht, sequentiell Informationen über komplexe dynamische Muster des untersuchten Finanzinstruments zu sammeln. In Kombination mit dem linearen Aufmerksamkeitsmechanismus, der für die Analyse des Frequenzspektrums der Eingabedaten verwendet wird, optimiert dieser Ansatz die Rechenkosten und gewährleistet die Stabilität des Trainings. Auf diese Weise kann sich der Hidformer-Rahmen effektiv an die Multidimensionalität und Nichtlinearität der Eingabedaten anpassen und unter Bedingungen mit hoher Marktvolatilität zuverlässigere Prognosen liefern.
Der Decoder des Modells, der auf einem mehrschichtigen Perzeptron aufbaut, ermöglicht die Vorhersage der gesamten Preisfolge in einem einzigen Schritt, wodurch die für die schrittweise Vorhersage typische Fehlerhäufung minimiert wird. Dadurch wird die Qualität der langfristigen Prognosen erheblich verbessert, was das Modell für praktische Anwendungen in der Finanzanalyse besonders wertvoll macht.
Die Originalvisualisierung des Hidformer-Frameworks ist unten zu sehen.
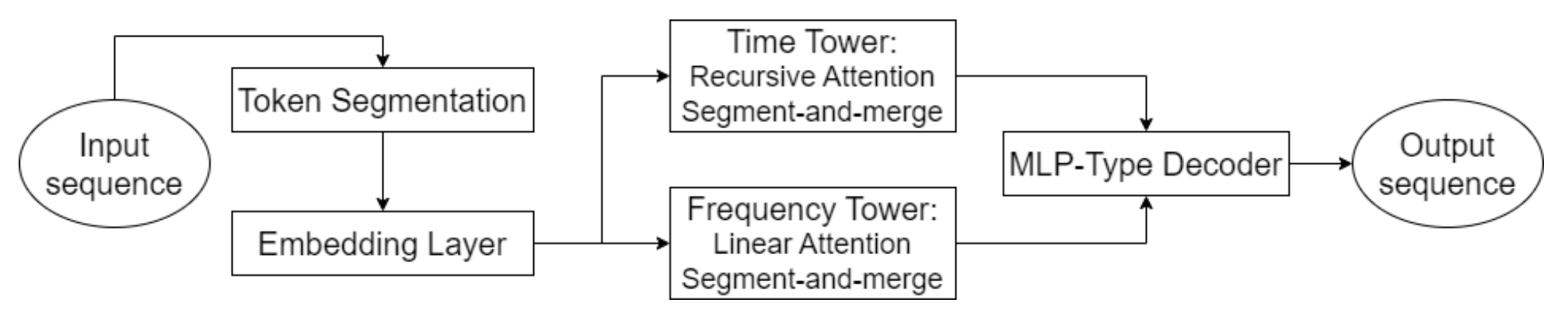
Im praktischen Teil des vorherigen Artikels haben wir die Vorarbeiten abgeschlossen und unsere eigenen Versionen der rekursiven und linearen Aufmerksamkeitsalgorithmen implementiert. Heute setzen wir die Entwicklung der von den Autoren des Hidformer-Frameworks vorgeschlagenen Ansätze fort.
Zeitreihenanalyse
Die Autoren des Hidformer-Frameworks haben eine Doppelturm-Encoder-Architektur vorgeschlagen, die wir als Grundlage übernommen haben. In unserer Implementierung wird jeder Encoder-Turm als separates Objekt dargestellt, was eine flexible Anpassung des Modells an verschiedene Aufgaben ermöglicht. Im Gegensatz zum ursprünglichen Rahmen haben wir jedoch einige Änderungen vorgenommen, die sich aus den Besonderheiten des Problems ergeben, das unser Modell lösen soll. Ursprünglich war der Rahmen für die Vorhersage der Fortsetzung der analysierten Zeitreihen gedacht, aber wir gingen noch einen Schritt weiter.
Auf der Grundlage der Erfahrungen, die bei der Umsetzung des MacroHFT und FinCon haben wir die Encoder-Türme zu unabhängigen Agenten umfunktioniert, die mögliche Szenarien für anstehende Handelsoperationen generieren. Dadurch wird der Funktionsumfang des Systems erheblich erweitert.
Wie in der ursprünglichen Hidformer-Architektur analysieren unsere Agenten die Marktdaten in Form von multivariaten Zeitreihen und deren Häufigkeitsmerkmalen. Der rekursive Aufmerksamkeitsmechanismus ermöglicht es dem Modell, Abhängigkeiten innerhalb multivariater Zeitreihen zu erfassen, während die Analyse des Frequenzspektrums mit linearen Aufmerksamkeitsmodulen durchgeführt wird. Dieser Ansatz ermöglicht ein tieferes Verständnis der strukturellen Muster in den Daten und erlaubt es dem Modell, sich in Echtzeit an sich ändernde Marktbedingungen anzupassen - besonders wichtig im Hochfrequenz- und algorithmischen Handel.
Darüber hinaus ist jeder Agent mit einem Modul zur wiederkehrenden Analyse früherer Entscheidungen ausgestattet, sodass er diese im Kontext der sich entwickelnden Marktsituation bewerten kann. Dieses Modul bietet die Möglichkeit, frühere Entscheidungen zu analysieren, die effektivsten Strategien zu ermitteln und das Modell an veränderte Marktbedingungen anzupassen.
Der Zeitreihenanalyse-Agent ist als CNeuronHidformerTSAgent-Objekt implementiert. Seine Struktur ist unten dargestellt.
class CNeuronHidformerTSAgent : public CResidualConv { protected: CNeuronBaseOCL caRole[2]; CNeuronRelativeCrossAttention cStateToRole; CNeuronS3 cShuffle; CNeuronRecursiveAttention cRecursiveState; CResidualConv cResidualState; CNeuronRecursiveAttention cRecursiveAction; CNeuronMultiScaleRelativeCrossAttention cActionToState; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformerTSAgent(void) {}; ~CNeuronHidformerTSAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformerTSAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Als übergeordnete Klasse verwenden wir einen Faltungsblock mit Rückkopplung, der als Block feedForward eines der internen Aufmerksamkeitsmodule dient.
Es ist erwähnenswert, dass die vorgestellte Struktur ein breites Spektrum an verschiedenen Komponenten umfasst, von denen jede ihre eigene einzigartige Funktion bei der Organisation dieser neuen Klasse von Algorithmen erfüllt. Diese Elemente gewährleisten einen vielschichtigen Ansatz, der es dem Modell ermöglicht, sich an verschiedene Szenarien der Informationsverarbeitung und der Analyse komplexer Muster anzupassen. Wir werden jede dieser Komponenten bei der Konstruktion der Klassenmethoden genauer untersuchen.
Alle Objekte werden statisch deklariert, sodass wir den Konstruktor und Destruktor der Klasse leer lassen können. Die Initialisierung aller geerbten und deklarierten Objekte ist in der Methode Init implementiert. Diese Methode akzeptiert mehrere konstante Parameter, die die Architektur des erstellten Objekts klar definieren.
bool CNeuronHidformerTSAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (action_space + 2) / 3, optimization_type, batch)) return false;
Die Initialisierung beginnt mit einem Aufruf der entsprechenden Methode der Elternklasse, die bereits die notwendigen Kontrollpunkte und Initialisierungsprozeduren für geerbte Objekte enthält. Es ist zu beachten, dass die Schnittstellen des übergeordneten Objekts Ausgaben erzeugen müssen, die mit dem beabsichtigten Verhalten des Agenten übereinstimmen. In diesem Fall wird vom Agenten erwartet, dass er einen Tensor von Handelsoperationen ausgibt, wobei jede Operation durch drei Schlüsselparameter dargestellt wird: Handelsvolumen, Stop-Loss-Level und Take-Profit-Level. Kauf- und Verkaufsoperationen werden als separate Zeilen dieser Matrix dargestellt. Wenn wir also die Initialisierungsmethode der übergeordneten Klasse aufrufen, setzen wir die Fenstergröße sowohl für die Eingabedaten als auch für die Ausgabeergebnisse auf 3 und die Sequenzlänge auf ein Drittel des Aktionsvektors des Agenten.
Nach der erfolgreichen Ausführung der Operationen der übergeordneten Klasse initialisieren wir die neu eingeführten internen Objekte. Zunächst initialisieren wir die Strukturen, die für die Bildung des Tensors der Agenten-Rollen verantwortlich sind. Wir haben dieses Konzept aus dem FinCon-Rahmen übernommen und an die aktuelle Aufgabe angepasst. Der Hauptvorteil dieses Konzepts liegt in der Aufteilung der Verantwortlichkeiten für die Analyse der Eingabedaten auf mehrere parallele Agenten, die sich so auf bestimmte Aspekte der analysierten Sequenz konzentrieren können.
//--- Role int index = 0; if(!caRole[0].Init(10 * window_key, index, OpenCL, 1, optimization, iBatch)) return false; caRole[0].getOutput().Fill(1); index++; if(!caRole[1].Init(0, index, OpenCL, 10 * window_key, optimization, iBatch)) return false;
Als Nächstes initialisieren wir das relative Kreuzaufmerksamkeits-Modul, das die Schlüsseleigenschaften der Eingabedaten entsprechend der zugewiesenen Rolle des Agenten hervorhebt.
//--- State to Role index++; if(!cStateToRole.Init(0, index, OpenCL, window, window_key, units_count, heads, window_key, 10, optimization, iBatch)) return false;
Nach der anfänglichen Verarbeitung der Rohdaten kehren wir zur ursprünglichen Hidformer-Architektur zurück, die einen Segmentierungsschritt umfasst, bevor die Daten in den Encoder eingespeist werden. Es ist wichtig zu erwähnen, dass die Segmentierung unabhängig in jedem Turm durchgeführt wird, was dazu beiträgt, unerwünschte Korrelationen zwischen verschiedenen Datenströmen zu vermeiden und die Anpassungsfähigkeit des Modells an heterogene Eingangssequenzen zu verbessern.
In unserer modifizierten Version haben wir die Funktionalität des Agenten erweitert, indem wir den klassischen Segmentierungsmechanismus durch einen spezialisierten Mechanismus ersetzt haben das Modul S3 ersetzt. Dieses Modul führt nicht nur die Segmentierung durch, sondern implementiert auch einen Mechanismus zur lernfähigen Segmentumschichtung. Ein solcher Ansatz ermöglicht es, latente Beziehungen zwischen verschiedenen Teilen der Sequenz besser zu erkennen. Infolgedessen kann der Agent robustere und verallgemeinerte Repräsentationen bilden.
//--- State index++; if(!cShuffle.Init(0, index, OpenCL, window, window * units_count, optimization, iBatch)) return false;
Die in den vorangegangenen Schritten aufbereiteten Daten werden in den Encoder eingespeist, der aus einem rekursiven Aufmerksamkeitsmodul und einem Faltungsblock mit Rückkopplung besteht.
index++; if(!cRecursiveState.Init(0, index, OpenCL, window, window_key, units_count, heads, stack_size, optimization, iBatch)) return false; index++; if(!cResidualState.Init(0, index, OpenCL, window, window, units_count, optimization, iBatch)) return false;
Ein solcher Encoder ermöglicht es uns, die Eingabesequenz im Kontext des aktuellen Kurses zu analysieren und wahrscheinliche Unterstützungs- und Widerstandsniveaus oder Bereiche mit stabilen Mustern zu identifizieren.
In der nächsten Stufe weichen wir wieder von der ursprünglichen Hidformer-Version ab und fügen ein Modul zur Analyse der zuvor durchgeführten Aktionen des Agenten hinzu. Zunächst analysieren wir rekursiv die letzte Aktion im Kontext ihrer historischen Abfolge.
//--- Action index++; if(!cRecursiveAction.Init(0, index, OpenCL, 3, window_key, (action_space + 2) / 3, heads, stack_size, optimization, iBatch)) return false;
Anschließend analysieren wir die Politik des Agenten im Kontext dynamischer Marktbedingungen mit Hilfe eines Multiskalen-Moduls für Kreuzaufmerksamkeit.
index++; if(!cActionToState.Init(0, index, OpenCL, 3, window_key, (action_space + 2) / 3, heads, window, units_count, optimization, iBatch)) return false; //--- return true; }
Die Funktionalität des FeedForward-Blocks wird durch die Fähigkeiten der übergeordneten Klasse implementiert.
Nach erfolgreicher Initialisierung aller internen Objekte geben wir das logische Ergebnis der Operationen an das aufrufende Programm zurück und beenden die Methode.
Wir fahren nun mit der Entwicklung des Vorwärtsdurchlauf-Algorithmus fort, der im Rahmen der Methode feedForward implementiert wird. Die Methodenparameter enthalten einen Zeiger auf das Objekt, das die Eingabedaten enthält.
bool CNeuronHidformerTSAgent::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !caRole[1].FeedForward(caRole[0].AsObject())) return false;
Innerhalb der Methode beginnen wir mit der Erstellung des Tensors, der die aktuelle Rolle des Agenten beschreibt. Dieser Vorgang wird jedoch nur während des Modelltrainings durchgeführt. Es ist leicht zu erkennen, dass während der Modellinferenz bei jeder Iteration des Vorwärtsdurchlaufs ein fester Rollentensor erzeugt wird. Dieser Schritt ist überflüssig. Daher prüfen wir zunächst die aktuelle Betriebsart und rufen erst dann den Vorwärtsdurchlauf der internen, vollständig vernetzten Schicht auf, die für die Erzeugung des Rollentensors zuständig ist. Auf diese Weise werden unnötige Vorgänge vermieden und die Latenzzeit bei der Entscheidungsfindung verringert.
Dann fahren wir mit der Verarbeitung der empfangenen Eingabedaten fort. Zunächst extrahieren wir die Elemente, die für die Rolle des Agenten relevant sind. Dies geschieht über das Modul der Kreuzaufmerksamkeit.
//--- State to Role if(!cStateToRole.FeedForward(NeuronOCL, caRole[1].getOutput())) return false;
Anschließend wird der Zustand der erweiterten Umgebung segmentiert und neu gemischt.
//--- State if(!cShuffle.FeedForward(cStateToRole.AsObject())) return false;
Sie werden dann vom rekursiven Aufmerksamkeitsmodul verarbeitet, das die Darstellung des Umweltzustands mit Informationen über frühere Preisbewegungsdynamiken anreichert.
if(!cRecursiveState.FeedForward(cShuffle.AsObject())) return false; if(!cResidualState.FeedForward(cRecursiveState.AsObject())) return false;
In der nächsten Phase führen wir eine eingehende Analyse der Verhaltenspolitik des Agenten durch. Zunächst wird die jüngste Entscheidung im Zusammenhang mit früheren Aktionen analysiert, die im Speicher des rekursiven Aufmerksamkeitsmoduls gespeichert sind.
//--- Action if(!cRecursiveAction.FeedForward(AsObject())) return false;
Dann analysieren wir die Politik des Agenten im Kontext des sich entwickelnden Marktumfelds unter Verwendung des Multiskalen-Moduls für die Kreuzaufmerksamkeit.
if(!cActionToState.FeedForward(cRecursiveAction.AsObject(), cResidualState.getOutput())) return false;
Wie Sie sehen, ist die Architektur des Moduls für die Aktionsanalyse dem klassischen Transformer-Decoder entlehnt. Ein klassischer Decoder verwendet nacheinander die Module Selbstaufmerksamkeit → Kreuzaufmerksamkeit → Vorwärtsdurchlauf. In unserem Fall wurde das Selbstaufmerksamkeitsmodul durch ein rekursives Aufmerksamkeitsmodul in Übereinstimmung mit dem Hidformer-Rahmen ersetzt. Nach der gleichen Logik haben wir die Kreuzaufmerksamkeit mit mehreren Köpfen durch die Multiskalen-Aufmerksamkeit ersetzt. Die verbleibende Komponente ist der FeedForward-Block. Sie wird über die übergeordnete Klasse implementiert. Bevor wir sie einsetzen, müssen wir jedoch beachten, dass der Input für diese decoderähnliche Struktur aus den Ergebnissen des vorherigen Vorwärtsdurchlaufs unserer Methode besteht. Damit der Rückwärtsdurchlauf korrekt ausgeführt werden kann, müssen wir diese Informationen speichern. Daher leiten wir die geerbten Datenpufferzeiger vorübergehend um und rufen erst dann die Methode für den Vorwärtsdurchlauf der übergeordneten Klasse auf.
if(!SwapBuffers(Output, PrevOutput)) return false; //--- return CResidualConv::feedForward(cActionToState.AsObject()); }
Das logische Ergebnis dieser Operationen wird an das aufrufende Programm zurückgegeben, und die Methode ist beendet.
Der nächste Schritt ist die Entwicklung der Algorithmen für den Rückwärtsdurchlauf. Der Rückwärtsdurchlauf in unseren Objekten wird durch zwei Methoden dargestellt: calcInputGradients und updateInputWeights. Ersteres gewährleistet eine korrekte Verteilung des Fehlergradienten auf alle am Entscheidungsprozess beteiligten Objekte, proportional zu ihrem Einfluss auf das Endergebnis. Letzteres führt eine Optimierung der trainierbaren Parameter des Modells durch, um den Gesamtfehler zu minimieren. Die Methode updateInputWeights ist in der Regel einfach zu handhaben. Sie besteht in der Regel darin, die entsprechenden Methoden interner Objekte mit trainierbaren Parametern aufzurufen und dabei die während des Vorwärtsdurchlaufs gespeicherten Daten weiterzugeben. Die Methode der Gradientenverteilung ist jedoch eng mit den Informationsflüssen des Vorwärtsdurchlaufs verbunden und bedarf einer ausführlicheren Erklärung.
Die Parameter der Methode calcInputGradients enthalten einen Zeiger auf das Eingabedatenobjekt. Dabei handelt es sich um dasselbe Objekt, das beim Vorwärtsdurchlauf übergeben wurde. Dieses Mal müssen wir jedoch den Fehlergradienten eingeben, der dem Einfluss der Eingabedaten auf die Ausgabe des Modells entspricht. Natürlich ist ein gültiger Zeiger erforderlich, um diese Informationen zu übertragen. Deshalb überprüfen wir innerhalb der Methode sofort die Gültigkeit des Zeigers.
bool CNeuronHidformerTSAgent::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Nach diesem kleinen Kontrollblock fahren wir mit der Konstruktion des Algorithmus für die Gradientenverteilung fort.
Die Informationsflüsse der Gradientenverteilung spiegeln die Flüsse des Vorwärtsdurchlaufs wider, allerdings in umgekehrter Richtung. Der Vorwärtsdurchlauf endete mit einem Aufruf der Methode der übergeordneten Klasse. Dementsprechend beginnt die Gradientenverteilung mit Hilfe vererbter Mechanismen. In diesem Stadium rufen wir die entsprechende Methode der übergeordneten Klasse auf und leiten den Fehler an das Modul weiter, das für die skalenübergreifende Beobachtung sowohl der Politik des Agenten als auch der Marktdynamik zuständig ist.
if(!CResidualConv::calcInputGradients(cActionToState.AsObject())) return false;
Als Nächstes müssen wir den sich ergebenden Gradienten auf zwei Informationsflüsse aufteilen: die Analyse der Politik des Agenten und die Analyse des Umweltzustands, der durch die multivariaten Zeitreihen dargestellt wird.
if(!cRecursiveAction.calcHiddenGradients(cActionToState.AsObject(), cResidualState.getOutput(), cResidualState.getGradient(), (ENUM_ACTIVATION)cResidualState.Activation())) return false;
Zunächst verteilen wir den Gradienten entlang des Zweigs der politischen Analyse. Dazu müssen wir sie durch das rekursive Aufmerksamkeitsmodul leiten, das für die Verarbeitung der vorherigen Aktionen des Agenten zuständig ist. Beachten Sie, dass die Eingaben in diesen Block die Ergebnisse des vorherigen Vorwärtsdurchlaufs unseres Objekts waren. Wir haben sie zuvor in einem separaten Datenpuffer gespeichert. Um eine korrekte Gradientenverteilung zu gewährleisten, müssen diese Werte vorübergehend in den Ergebnispuffer zurückgespeichert werden, wobei die aktuellen Ergebnisse erhalten bleiben. Deshalb ersetzen wir wieder die Pufferzeiger.
Außerdem werden bei der Gradientenverteilung die Werte in den entsprechenden Schnittstellenpuffern überschrieben. Dies ist unerwünscht, da diese Werte für die Aktualisierung der Parameter weiterhin benötigt werden. Daher leiten wir auch den Puffer für den Fehlergradienten um.
Erst nachdem wir sichergestellt haben, dass alle erforderlichen Daten erhalten bleiben, führen wir die Gradientenverteilungsoperationen durch das rekursive Aufmerksamkeitsmodul durch. Nach erfolgreicher Ausführung werden die Pufferzeiger wieder in ihren ursprünglichen Zustand versetzt.
//--- Action CBufferFloat *temp = Gradient; if(!SwapBuffers(Output, PrevOutput) || !SetGradient(cRecursiveAction.getPrevOutput(), false)) return false; if(!calcHiddenGradients(cRecursiveAction.AsObject())) return false; if(!SwapBuffers(Output, PrevOutput)) return false; Gradient = temp;
Anschließend gehen wir zur Gradientenverteilung entlang des multivariaten Zeitreihenanalysepfads über. Zunächst propagieren wir die Gradienten auf die Ebene des rekursiven Aufmerksamkeitsmoduls, das den Zustand der Umgebung analysiert.
//--- State if(!cRecursiveState.calcHiddenGradients(cResidualState.AsObject())) return false;
Anschließend wird der Gradient an den Segmentierungs- und Shuffling-Block weitergeleitet.
if(!cShuffle.calcHiddenGradients(cRecursiveState.AsObject())) return false;
Im weiteren Verlauf dieser Verzweigung wird der Gradient an das Modul für Kreuzaufmerksamkeit weitergeleitet, das die Rohdaten im Zusammenhang mit der Rolle des Agenten analysiert.
if(!cStateToRole.calcHiddenGradients(cShuffle.AsObject())) return false;
Von diesem Punkt aus teilt sich der Gradient wieder in zwei Ströme auf: in Richtung des Eingangsdatenobjekts und in Richtung des Zweigs für die Bildung der Bearbeiterrolle.
if(!NeuronOCL.calcHiddenGradients(cStateToRole.AsObject(), caRole[1].getOutput(), caRole[1].getGradient(), (ENUM_ACTIVATION)caRole[1].Activation())) return false; //--- return true; }
Es ist erwähnenswert, dass entlang des Rollenbildungszweigs keine weitere Gradientenausbreitung stattfindet. Die erste Schicht dieser MLP ist fest, und nur die zweite neuronale Schicht enthält trainierbare Parameter, denen wir bereits das Fehlersignal übergeben haben.
Schließlich geben wir das logische Ergebnis der Ausführung an das aufrufende Programm zurück und schließen die Methode ab.
Damit ist die Diskussion über die Algorithmen abgeschlossen, mit denen die Methoden des Agenten für die Zeitreihenanalyse des Umweltzustands entwickelt wurden. Den vollständigen Code dieses Objekts und alle seine Methoden finden Sie in den Anhängen.
Arbeiten mit dem Frequenzbereich
Der nächste Schritt besteht darin, einen Agenten für die Analyse der Frequenzmerkmale des analysierten Signals zu entwickeln. Es sei darauf hingewiesen, dass die Struktur dieses Agenten dem zuvor erstellten Agenten für die Zeitreihenanalyse sehr ähnlich ist. Gleichzeitig weist es bestimmte Merkmale auf, die mit der Umwandlung des Eingangssignals in den Frequenzbereich zusammenhängen. Um die hoch- und niederfrequenten Komponenten des Umgebungszustandssignals zu isolieren, haben wir eine diskrete Wavelet-Transformation implementiert, entlehnt aus dem Rahmenwerk Multitask-Stockformer.
Die Agentenalgorithmen für den Frequenzbereich werden durch das Objekt CNeuronHidformerFreqAgent implementiert. Seine Struktur ist unten dargestellt.
class CNeuronHidformerFreqAgent : public CResidualConv { protected: CNeuronTransposeOCL cTranspose; CNeuronLegendreWaveletsHL cLegendre; CNeuronTransposeRCDOCL cHLState; CNeuronLinerAttention cAttentionState; CResidualConv cResidualState; CNeuronS3 cShuffle; CNeuronRecursiveAttention cRecursiveAction; CNeuronMultiScaleRelativeCrossAttention cActionToState; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformerFreqAgent(void) {}; ~CNeuronHidformerFreqAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint filters, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformerFreqAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
In der vorgestellten Struktur kann man leicht Ähnlichkeiten in den Namen der internen Objekte feststellen, was auf eine verwandte Struktur zwischen den Agenten im Zeit- und im Frequenzbereich hinweist. Es gibt jedoch auch Unterschiede, die wir bei der Konstruktion der Methoden für diese neue Klasse genauer untersuchen werden.
Alle internen Objekte werden statisch deklariert, was uns erlaubt, den Konstruktor und den Destruktor des Objekts leer zu lassen. Die Initialisierung aller neu deklarierten und geerbten Objekte wird in der Methode Init durchgeführt.
bool CNeuronHidformerFreqAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint filters, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (action_space + 2) / 3, optimization_type, batch)) return false;
Die Methodenparameter enthalten eine Reihe von Konstanten, die eine eindeutige Interpretation der Architektur des zu erstellenden Objekts ermöglichen. Innerhalb der Methode rufen wir zunächst die entsprechende Methode der Elternklasse auf, die bereits die notwendigen Kontrollpunkte und die Initialisierung der geerbten Objekte und Schnittstellen implementiert. Es ist zu beachten, dass der Agent trotz der unterschiedlichen Datendomänen den gleichen Tensor für die Handelsoperationen ausgeben soll. Daher sind die oben beschriebenen Ansätze für den Aufruf der Initialisierungsmethode der Elternklasse im Zeitreihenagenten auch hier anwendbar.
Als Nächstes initialisieren wir die neu deklarierten Objekte. Achten Sie auf eine Unterscheidung bei der Gestaltung von Agenten für verschiedene Bereiche. Der Frequenzbereichsagent verfügt nicht über ein Modul zur Rollengenerierung. In unserer Implementierung planen wir nicht, eine große Anzahl von Agenten im Frequenzbereich zu verwenden.
Außerdem wurde der Segmentierungsblock durch ein Modul zur diskreten Wavelet-Transformation ersetzt. Die Umwandlung vom Zeitbereich in den Frequenzbereich wird an Einheitsfolgen vorgenommen. Zur bequemen Handhabung dieser Sequenzen transponieren wir zunächst die Eingabedatenmatrix.
int index = 0; if(!cTranspose.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
Die univariaten Zeitreihen werden in gleiche Segmente unterteilt. Auf jedes Segment wird eine diskrete Wavelet-Transformation angewandt, die es uns ermöglicht, wichtige strukturelle Komponenten der zeitlichen Abhängigkeiten zu extrahieren. Die Mindestgröße der Segmente ist auf fünf Elemente begrenzt, wodurch ein Gleichgewicht zwischen Analysegenauigkeit und Rechenkosten erreicht wird.
index++; uint wind = (units_count>=20 ? (units_count + 3) / 4 : units_count); uint units = (units_count + wind - 1) / wind; if(!cLegendre.Init(0, index, OpenCL, wind, wind, units, filters, window, optimization, batch)) return false;
Es ist zu beachten, dass das Ergebnis der diskreten Wavelet-Transformation ein Tensor ist, der sowohl die hoch- als auch die niederfrequenten Komponenten des Signals enthält. Die Hochfrequenzkomponente folgt unmittelbar auf die Niederfrequenzkomponente eines jeden Segments, und die Daten können als dreidimensionaler Tensor [Segment, [Low, High], Filters]. dargestellt werden.
Für die weitere Analyse ist es wichtig, die Daten in die jeweiligen Komponenten zu zerlegen. Da jedoch auf beide Signaltypen identische Operationen angewendet werden, ist es effizienter, sie parallel zu verarbeiten. Daher teilen wir das Signal nicht explizit in einzelne Objekte auf, sondern wir transponieren den Tensor, was eine effizientere Nutzung der Rechenressourcen ermöglicht und die Datenverarbeitung beschleunigt.
index++; if(!cHLState.Init(0, index, OpenCL, units * window, 2, filters, optimization, iBatch)) return false;
Wie von den Autoren von Hidformer vorgesehen, wenden wir dann einen linearen Aufmerksamkeitsalgorithmus an. In unserem Fall führen wir getrennte Analysen der hoch- und niederfrequenten Komponenten durch, was die Identifizierung der wichtigsten Muster und die adaptive Anpassung der Signalverarbeitungsstrategie entsprechend ihrer Frequenzmerkmale ermöglicht.
index++; if(!cAttentionState.Init(0, index, OpenCL, filters, filters, units* window, 2, optimization, iBatch)) return false;
Die resultierenden Ausgaben werden durch einen Faltungsblock mit Rückkopplung geleitet, der als FeedForward-Modul unseres Frequenzbereichs-Encoders dient.
index++; if(!cResidualState.Init(0, index, OpenCL, filters, filters, 2 * units * window, optimization, iBatch)) return false;
Als Nächstes initialisieren wir den Agenten-Politik-Analyseblock, analog zu dem, der bei der Konstruktion des Zeitreihenagenten verwendet wurde. Es gibt jedoch einen Vorbehalt. Für das lineare Aufmerksamkeitsmodul ist die Reihenfolge der Segmente irrelevant, da die Analyse auf die gesamte Sequenz auf einmal angewendet wird. Bei der Verwendung des skalenübergreifenden Kreuzaufmerksamkeits-Moduls müssen wir uns jedoch mit der Priorisierung der Segmente befassen, da dieses Modul für Zeitreihensequenzen konzipiert wurde und den jüngsten Elementen Priorität einräumt.
Um dieses Problem zu lösen, verwenden wir das Objekt zum Segmentierung und Mischen. In diesem Fall sind unsere Daten bereits segmentiert, und der Schwerpunkt liegt auf der erlernbaren Umschichtung der Segmente. Auf diese Weise kann das Modell auf der Grundlage der Trainingsdaten selbständig die Segmentpriorität erlernen.
index++; if(!cShuffle.Init(0, index, OpenCL, filters, cResidualState.Neurons(), optimization, iBatch)) return false;
Auf die Funktionalität der vom Agenten-Politik-Analysemodul verwendeten Objekte wird hier nicht weiter eingegangen, da die für den Zeitreihenagenten beschriebenen Ansätze beibehalten werden.
//--- Action index++; if(!cRecursiveAction.Init(0, index, OpenCL, 3, filters, (action_space + 2) / 3, heads, stack_size, optimization, iBatch)) return false; index++; if(!cActionToState.Init(0, index, OpenCL, 3, filters, (action_space + 2) / 3, heads, filters, 2 * units * window, optimization, iBatch)) return false; //--- return true; }
Sobald alle internen Objekte erfolgreich initialisiert sind, schließen wir die Methode ab und geben ein logisches Ergebnis an das aufrufende Programm zurück.
Um die Länge des Artikels zu verkürzen, werden die Methoden für die Vorwärts- und Rückwärtsdurchläufe einer unabhängigen Studie überlassen. Ihre Algorithmen folgen denselben Prinzipien wie die für den Zeitreihenagenten beschriebenen. Der vollständige Code für beide Agenten und ihre Methoden ist im Anhang enthalten.
Top-Level Objekt
Nach der Konstruktion der Objekte der multivariaten Zeitreihen und der Türme im Frequenzbereich besteht der nächste Schritt beim Aufbau des vollständigen Hidformer-Rahmens darin, sie in einer einzigen Struktur zu kombinieren und einen Decoder hinzuzufügen. Die Autoren von Hidformer verwendeten einen MLP als Decoder für die Vorhersage der erwarteten Fortsetzung der analysierten Zeitreihe. Trotz unserer Änderung der Aufgabe kann ein Perzeptron immer noch verwendet werden, um die endgültige Entscheidung zu treffen. Wir sind jedoch noch einen Schritt weiter gegangen und haben das Konzept eines Hyper-Agenten aus dem MacroHFT-Rahmen übernommen. Inspiriert von dieser Idee haben wir das Objekt CNeuronHidformer mit der folgenden Struktur geschaffen.
class CNeuronHidformer : public CNeuronBaseOCL { protected: CNeuronTransposeOCL cTranspose; CNeuronHidformerTSAgent caTSAgents[4]; CNeuronHidformerFreqAgent caFreqAgents[2]; CNeuronMacroHFTHyperAgent cHyperAgent; CNeuronBaseOCL cConcatenated; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHidformer(void) {}; ~CNeuronHidformer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint stack_size, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronHidformer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
In dieser Architektur kann man deutlich die strukturelle Ähnlichkeit mit der Klasse CNeuronMacroHFT aus dem MacroHFT-Rahmenwerk sehen. Im Wesentlichen handelt es sich bei der neuen Struktur um eine modifizierte Version, bei der die grundlegenden Gestaltungsprinzipien beibehalten und gleichzeitig gezielte Änderungen zur Verbesserung der Datenverarbeitungseffizienz vorgenommen wurden.
Ein wesentlicher Unterschied liegt in der Konfiguration der Agenten für die Umweltanalyse. In dieser Version werden sechs spezialisierte Agenten eingesetzt: vier für die Analyse multivariater Zeitreihen und zwei für die Verarbeitung von Eingangsdaten im Frequenzbereich. Um eine ausgewogene Analyse zu gewährleisten, werden alle Agenten gleichmäßig auf die Verarbeitung der direkten und der transponierten Darstellungen der Eingabedaten verteilt. Diese Architektur ermöglicht eine detailliertere Untersuchung verschiedener Aspekte der Eingabedaten, wodurch verborgene Muster aufgedeckt und die Verarbeitungsstrategie adaptiv angepasst werden kann.
Insgesamt führen die Änderungen an der Agentenstruktur nur zu geringfügigen Anpassungen an den Algorithmen der Methoden des Objekts. Die Hauptlogik bleibt unverändert, und alle wichtigen Funktionsprinzipien des Modells werden beibehalten. Daher überlassen wir es dem Leser, die Konstruktionsalgorithmen der Methoden selbst zu untersuchen. Der vollständige Code für dieses Objekt und alle seine Methoden ist im Anhang enthalten.
Modell der Architektur
Ein paar Worte zur Architektur des trainierbaren Modells. Wie Sie vielleicht bemerkt haben, ist unsere konstruierte Architektur eine Synergie aus den Rahmenwerken von Hidformer und MacroHFT. Die Architektur des trainierbaren Modells und seine Trainingsmethoden sind keine Ausnahme. Wir haben die Modellarchitektur des MacroHFT-Rahmens nachgebildet und dabei nur eine einzige Schicht verändert.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronHidformer; //--- Windows { int temp[] = {BarDescr, 120, NActions}; //Window, Stack Size, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Scales descr.layers =3; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Ansonsten blieb die operative Architektur unverändert, einschließlich der Verwendung des Risikomanagement-Agenten. Eine vollständige Beschreibung der Modellarchitektur sowie der vollständige Code für die Trainings- und Testroutinen sind im Anhang enthalten, der unverändert aus dem vorherigen Artikel übernommen wurde.
Tests
Wir haben umfangreiche Arbeiten zur Umsetzung unserer Interpretation der von den Autoren von Hidformer vorgeschlagenen Ansätze durchgeführt. Wir kommen nun zur entscheidenden Phase: der Bewertung der Wirksamkeit unserer Lösungen anhand realer historischer Daten. Bei unserer Implementierung haben wir uns weitgehend an das MacroHFT-System angelehnt. Daher ist es logisch, die Leistung des neuen Modells damit zu vergleichen. Daher trainieren wir das neue Modell mit dem Trainingsdatensatz, der zuvor für das Training der MacroHFT-basierten Implementierung zusammengestellt wurde.
Dieser Trainingsdatensatz wurde aus historischen Daten für das gesamte Jahr 2024 für das Währungspaar EURUSD auf dem Zeitrahmen M1 zusammengestellt. Alle Indikatorparameter wurden auf ihre Standardwerte gesetzt.
Zum Trainieren und Testen des Modells werden die gleichen Expert Advisors verwendet. Die Tests wurden mit historischen Daten vom Januar 2025 durchgeführt, wobei alle anderen Parameter beibehalten wurden. Die Testergebnisse sind wie folgt:
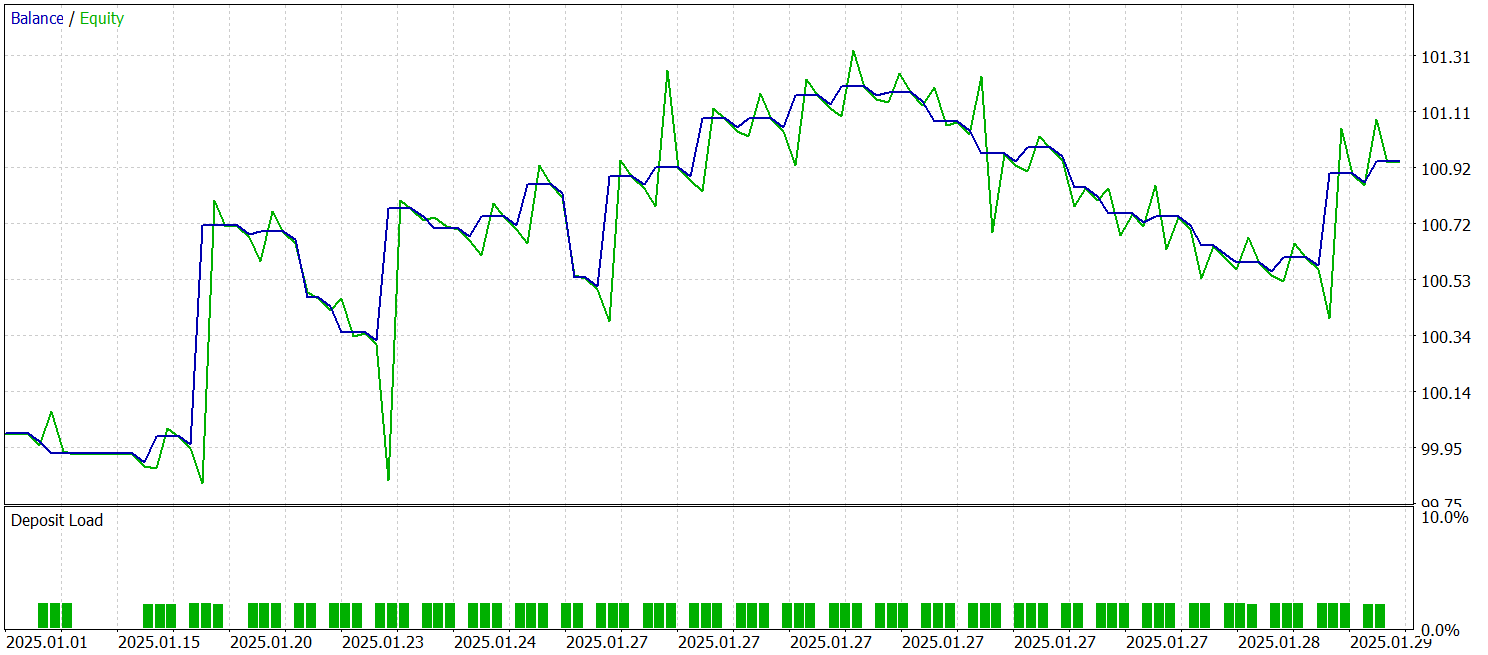
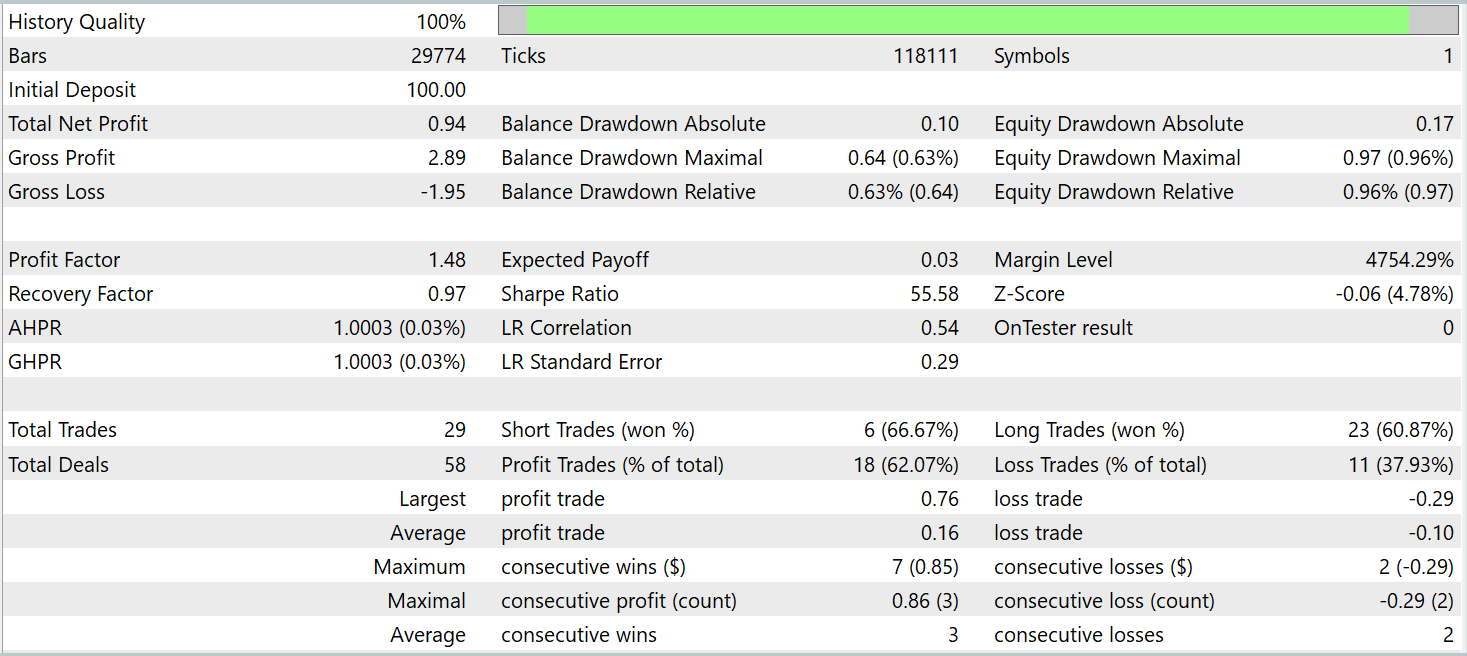
Die Ergebnisse zeigen, dass das Modell bei historischen Daten außerhalb des Trainingsdatensatzes Gewinne erzielt. Insgesamt führte das Modell während des Kalendermonats 29 Handelsgeschäfte aus. Dies ergibt etwas mehr als einen Handel pro Handelstag, was für den Hochfrequenzhandel nicht ausreichend ist. Gleichzeitig waren mehr als 60 % der Handelsgeschäfte gewinnbringend, und der durchschnittlich gewinnbringende Handel übertraf den durchschnittlichen Verlusthandel um 60 %.
Schlussfolgerung
Wir haben den Hidformer-Rahmen untersucht, der für die Analyse und Vorhersage komplexer multivariater Zeitreihen entwickelt wurde. Das Modell weist dank seiner einzigartigen Architektur des Encoders „Unique Dual-Tower“ eine hohe Effizienz auf. Ein Turm analysiert die zeitliche Struktur der Eingabedaten, während der andere im Frequenzbereich arbeitet. Der rekursive Aufmerksamkeitsmechanismus deckt komplexe Preisänderungsmuster auf, während die lineare Aufmerksamkeit den Rechenaufwand für die Analyse langer Sequenzen reduziert.
Im praktischen Teil dieser Arbeit haben wir unsere eigene Interpretation der vorgeschlagenen Ansätze mit MQL5 umgesetzt. Wir haben das Modell anhand echter historischer Daten trainiert und anhand von Out-of-Sample-Daten getestet. Die Testergebnisse zeigen das Potenzial des Modells. Bevor es jedoch im Live-Handel eingesetzt werden kann, muss das Modell auf einem repräsentativeren Datensatz trainiert werden, gefolgt von umfassenden Tests.
Referenzen
- Hidformer: Transformer-Style Neural Network in Stock Price Forecasting
- Hidformer: Hierarchical dual-tower transformer using multi-scale mergence for long-term time series forecasting
- Andere Artikel dieser Serie
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor zum Sammeln von Beispielen |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor für die Probenahme mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Expert Advisor für das Modelltraining |
| 4 | Test.mq5 | Expert Advisor | Modellprüfung Expert Advisor |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Beschreibung des Systemzustands und der Modellarchitektur |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Bibliothek | OpenCL-Programmcode |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17104
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.