
取引におけるニューラルネットワーク:暗号通貨市場向けメモリ拡張コンテキスト認識学習(最終回)

はじめに
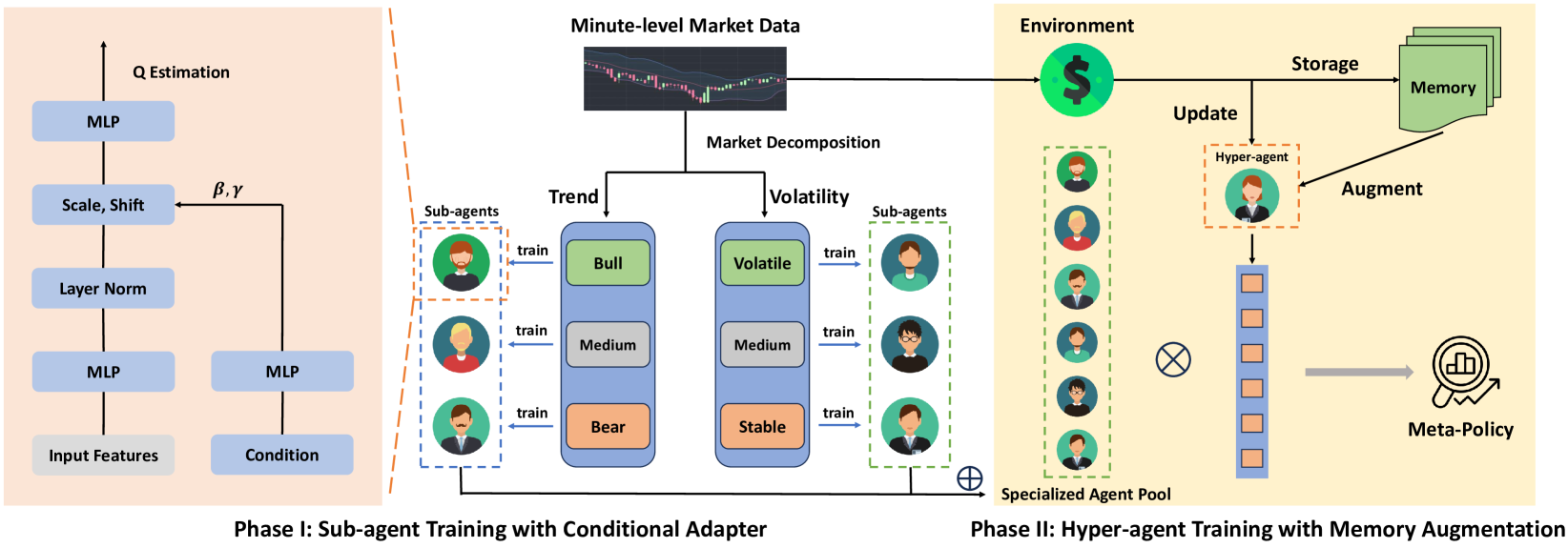
前回の記事では、高頻度暗号資産取引(HFT)のために開発されたMacroHFTフレームワークを紹介しました。このフレームワークは、文脈依存型の強化学習手法とメモリ活用を組み合わせた現代的なアプローチであり、リスクを最小限に抑えながら動的な市場環境へ効率的に適応することを可能にします。
MacroHFTの動作原理は、個々の構成要素を2段階で学習させる点に基づいています。第1段階では、市場状態をトレンド方向とボラティリティ水準に応じて分類します。このプロセスにより主要な市場状態が特定され、それらを用いて特化型サブエージェントを学習させます。各サブエージェントは、特定のシナリオ下で動作するよう最適化されています。第2段階では、メモリモジュールを備えたハイパーエージェントを学習させ、サブエージェントの協調動作を管理します。このモジュールは過去データを考慮し、これまでの経験に基づいたより精度の高い意思決定を可能にします。
MacroHFTアーキテクチャには、いくつかの重要な構成要素があります。第一に、データ前処理モジュールがあり、入力される市場情報のフィルタリングと正規化をおこないます。これによりノイズが除去され、後続の分析にとって極めて重要なデータ品質が向上します。
サブエージェントは、特定の市場シナリオに基づいて学習されたディープラーニングモデルです。これらは強化学習手法を用いて、複雑かつ急速に変化する状況へ適応します。最後の構成要素が、メモリ拡張型ハイパーエージェントです。このエージェントはサブエージェントの出力を統合し、過去の出来事と現在の市場状態の双方を分析します。これにより、高い予測精度と市場急変に対する耐性が実現されます。
これらすべての要素を統合することで、MacroHFTは高いボラティリティ環境下でも効果的に機能するだけでなく、収益性指標を大幅に向上させることが可能となります。
MacroHFTフレームワークのオリジナルの可視化図を以下に示します。
前回の記事の実践パートでは、ハイパーエージェントオブジェクトを作成し、サブエージェントとの相互作用アルゴリズムを実装しました。本日はこの作業を継続し、MacroHFTアーキテクチャの新たな側面に焦点を当てていきます。
リスク管理モジュール
前回の記事では、ハイパーエージェントの動作をCNeuronMacroHFTHyperAgent オブジェクトとして整理し、サブエージェントとの相互作用アルゴリズムを開発しました。さらに、以前作成したより複雑なアーキテクチャを持つアナリストエージェントをサブエージェントとして利用することにしました。一見すると、これでMacroHFTフレームワークの実装は十分なように思えます。しかし、現在の実装にはいくつかの制限があります。サブエージェントとハイパーエージェントの両方が、環境の状態のみを分析している点です。この方法では、将来の価格変動の予測、取引方向の決定、ストップロスやテイクプロフィットの設定は可能ですが、取引サイズの決定という、戦略全体において重要な要素には対応できません。
固定の取引サイズを使用したり、予測されたストップロスと口座残高に対する固定リスクレベルに基づいて取引量を計算することは可能です。しかし、各予測には固有の信頼度が伴います。この信頼度が取引サイズの決定に中心的な役割を果たすべきであると考えるのが論理的です。予測に高い信頼度がある場合は大きな取引をおこない、全体の収益性を最大化できます。一方、信頼度が低い場合は、より慎重なアプローチが望ましいです。
これらの要素を考慮し、リスク管理モジュールを実装に追加することにしました。このモジュールは既存のアーキテクチャに統合され、柔軟で適応的な取引サイズの決定を提供します。リスク管理を導入することで、不安定な市場環境に対するモデルの耐性が向上し、特に高頻度取引において重要となります。
重要な点として、この場合のリスク管理アルゴリズムは、直接的な環境分析から部分的に「切り離されて」います。代わりに、エージェントの行動が財務結果に与える影響の評価に焦点を当てています。具体的には、各取引を口座残高の変化と関連付け、方針の有効性を示すパターンを特定します。利益の出る取引が増え、残高が着実に増加している場合は、現在の方針の成功を示しており、1取引あたりのリスクを高めることが正当化されます。逆に、損失が増加している場合は、リスクを抑えたより慎重な戦略が必要です。このアプローチにより、市場状況の変化に対する適応力が向上し、資本管理全体の効率も改善されます。さらに分析の精度を向上させるため、口座の現在および過去の状態の異なる側面を表す複数の口座状態予測を作成します。これにより、戦略のパフォーマンスをより正確に評価でき、市場のダイナミクスに応じた適時の適応が可能になります。
リスク管理アルゴリズムは、CNeuronMacroHFTvsRiskManagerオブジェクト内で実装され、その構造は以下の通りです。
class CNeuronMacroHFTvsRiskManager : public CResidualConv { protected: CNeuronBaseOCL caAccountProjection[2]; CNeuronMemoryDistil cMemoryAccount; CNeuronMemoryDistil cMemoryAction; CNeuronRelativeCrossAttention cCrossAttention; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronMacroHFTvsRiskManager(void) {}; ~CNeuronMacroHFTvsRiskManager(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint nactions, uint account_decr, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMacroHFTvsRiskManager; } //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
提示された構造では、標準的なオーバーライド可能メソッドと、前述したリスク管理メカニズムの実装において中核的な役割を果たす複数の内部オブジェクトを確認できます。これらの内部オブジェクトの機能については、クラスメソッドの説明に沿って詳細に解説し、その使用ロジックをより深く理解できるようにします。
リスク管理クラス内のすべての内部オブジェクトはstaticとして宣言されています。これによりオブジェクト構造が簡素化され、初期化やメモリ解放のための追加処理が不要となるため、コンストラクタとデストラクタは空のままにできます。継承されたオブジェクトおよび宣言されたすべてのオブジェクトの初期化はInitメソッド内でおこなわれ、このメソッドがクラス生成時のアーキテクチャ構築を担当します。
クラスのパラメータには、オブジェクト構造を明確に定義するための定数が含まれています。
bool CNeuronMacroHFTvsRiskManager::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint nactions, uint account_decr, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (nactions + 2) / 3, optimization_type, batch)) return false;
メソッド本体では、最初に同名の親クラスメソッドが呼び出されます。この場合、それはフィードバックを持つ畳み込みブロックです。このモジュールの出力は、取引意思決定行列を表すテンソルである点に注意が必要です。各行は個別の取引を表し、取引量、ストップロス、テイクプロフィットからなる取引パラメータベクトルを含みます。取引分析を正しくおこなうため、買い取引と売り取引は別々の行として扱われ、それぞれを独立して分析できるようにしています。
畳み込み演算の構成において、カーネルサイズとストライドは3に設定されています。これは取引記述に含まれるパラメータ数に対応しています。
次に、内部オブジェクトの初期化処理を見ていきます。リスク管理モジュールは、主に2つのデータソースに依存している点が重要です。1つはエージェントの行動であり、もう1つは分析対象となる口座状態を記述するベクトルです。エージェント行動を表す主データストリームはニューラル層オブジェクトとして提供され、口座状態を含む副次ストリームはデータバッファを通じて渡されます。
すべての内部コンポーネントを正しく機能させるためには、両方のデータストリームをニューラル層オブジェクトとして表現する必要があります。そのため最初の段階として、副次ストリームのデータを受け取るための全結合層を初期化します。
int index = 0; if(!caAccountProjection[0].Init(0, index, OpenCL, account_decr, optimization, iBatch)) return false;
次の段階では、口座状態記述の投影を形成するための全結合層を追加します。この学習可能な層は、指定された次元の部分空間において複数の口座状態投影を含むテンソルを生成します。投影の数および部分空間の次元はメソッドのパラメータとして与えられており、さまざまなタスクに応じて柔軟に層構成を調整できます。
index++; if(!caAccountProjection[1].Init(0, index, OpenCL, window * units_count, optimization, iBatch)) return false;
リスク管理モジュールが受け取る生データは、分析対象状態の静的な記述のみを提供します。しかし、エージェント方針の有効性を正確に評価するためには、時間的な変化、すなわち動的情報を考慮する必要があります。そのため、両方の情報ストリームに対してメモリモジュールを適用し、データの時系列的な連続性を保持します。ここで重要な設計判断となるのが、元の口座状態ベクトルを保存するか、それともその投影を保存するかという点です。元のベクトルはサイズが小さく、計算資源の効率に優れています。一方、メモリ処理後に生成される投影は、口座残高の動態を静的データに統合するため、より情報量の豊富な表現を提供します。
index++; if(!cMemoryAccount.Init(caAccountProjection[1].Neurons(), index, OpenCL, account_decr, window_key, 1, heads, stack_size, optimization, iBatch)) return false;
エージェントの取引行動に対するメモリモジュールは、個々の取引単位で動作します。
index++; if(!cMemoryAction.Init(0, index, OpenCL, 3, window_key, (nactions + 2) / 3, heads, stack_size, optimization, iBatch)) return false;
方針分析の精度を高めるために、クロスアテンションモジュールを使用します。このモジュールは、直近のエージェント行動と口座状態の動態を相互に関連付け、意思決定とそれに伴う財務結果との関係性を抽出します。
index++; if(!cCrossAttention.Init(0, index, OpenCL, 3, window_key, (nactions + 2) / 3, heads, window, units_count, optimization, iBatch)) return false; //--- return true; }
ここで内部オブジェクトの初期化は完了です。メソッド全体もこの時点で終了し、処理結果を論理値として呼び出し元プログラムに返します。
リスク管理オブジェクトの初期化後、feedForwardメソッドにおいてフォワードパスアルゴリズムの構築に進みます。
bool CNeuronMacroHFTvsRiskManager::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(caAccountProjection[0].getOutput() != SecondInput) { if(!caAccountProjection[0].SetOutput(SecondInput, true)) return false; }
このメソッドは2つの生データオブジェクトへのポインタを受け取ります。そのうち1つはデータバッファとして提供され、その内容を内部ニューラル層オブジェクトへ転送する必要があります。すべてのデータをコピーする代わりに、より効率的な方法を採用しています。具体的には、内部オブジェクトが保持するバッファポインタを入力データバッファのポインタに置き換えています。これにより処理速度が大幅に向上します。
次に、両方の情報ストリームに対して、蓄積された動態情報を付加します。データは過去の状態や変化を保持する専用メモリモジュールを通過し、時間的依存関係を維持することで、より正確な処理に必要な文脈を確保します。
if(!cMemoryAccount.FeedForward(caAccountProjection[0].AsObject())) return false; if(!cMemoryAction.FeedForward(NeuronOCL)) return false;
これらの拡張された情報に基づき、口座状態ベクトルの投影が生成されます。これらの投影は、口座動態を分析し、過去の行動が現在の状態に与えた影響を評価するための包括的な基盤を提供します。
if(!caAccountProjection[1].FeedForward(cMemoryAccount.AsObject())) return false;
前処理段階が完了すると、クロスアテンションブロックを用いて、エージェントの方針が財務結果に与える影響を分析します。エージェント行動と財務変化を関連付けることで、意思決定と結果の関係が明確になります。
if(!cCrossAttention.FeedForward(cMemoryAction.AsObject(), caAccountProjection[1].getOutput())) return false;
取引判断を形成する最終的な処理は、親クラスのメカニズムによって実行され、最終的な情報統合がおこなわれます。
return CResidualConv::feedForward(cCrossAttention.AsObject());
}
これら一連の処理の結果は論理値として呼び出し元プログラムに返され、メソッドは終了します。
バックプロパゲーションメソッドは線形アルゴリズムを用いて実装されており、学習において追加の説明を必要とする可能性は低いと考えられます。以上でリスク管理オブジェクトの解説は完了です。クラスおよびすべてのメソッドの完全なコードは、添付ファイルに収録されています。
モデルアーキテクチャ
MQL5を用いたMacroHFTフレームワークの実装作業を引き続き進めます。次の段階では、学習可能なモデルのアーキテクチャを構築します。本ケースでは、単一のActorモデルを学習させ、そのアーキテクチャはCreateDescriptionsメソッド内で定義されます。
bool CreateDescriptions(CArrayObj *&actor) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; }
このメソッドは、作成するモデルのアーキテクチャを記録するための動的配列オブジェクトへのポインタを受け取ります。そして、メソッド本体では、受け取ったポインタの関連性をすぐに確認します。必要に応じて、動的配列オブジェクトの新しいインスタンスを作成します。
次に、全結合層の記述を作成します。この層は生の入力データを受け取るために使用され、分析対象となる環境状態を記述するテンソルを格納できる十分なサイズを持つ必要があります。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
ここで注意すべき点として、生の入力データはターミナルから直接取得されます。これらのデータに対する前処理ブロックは、バッチ正規化層として構成されています。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
正規化後、環境状態の記述は、MacroHFTフレームワーク内で作成した層へと渡されます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFT; //--- Windows { int temp[] = {BarDescr, 120, NActions}; //Window, Stack Size, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.layers =3; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
MacroHFTは1分足時間軸で動作するよう設計されている点に注意してください。それに伴い、環境状態のメモリスタックは120要素に拡張されており、これは2時間分のシーケンスに相当します。これにより市場ダイナミクスをより包括的に考慮でき、取引戦略における予測精度および意思決定の質が向上します。
前述のとおり、このモジュールは環境状態の分析のみに特化しており、リスク評価機能は備えていません。そのため、次のステップとしてリスク管理モジュールを追加します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFTvsRiskManager; //--- Windows { int temp[] = {3, 15, NActions,AccountDescr}; //Window, Stack Size, N Actions, Account Description if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = 10; descr.window_out = 16; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
この場合、メモリスタックは15要素に削減されています。これにより処理データ量が減少し、より短期的な動態に焦点を当てることが可能になります。その結果、市場変化に対してより高速な反応が実現されます。
リスク管理モジュールの出力は正規化された値です。これらをエージェントが必要とする行動空間へと写像するために、適切な活性化関数を持つ畳み込み層を使用します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; } //--- return true; }
メソッドの処理が完了すると、操作結果の論理値が呼び出し元プログラムに返されます。
なお、本実装ではエージェントに確率的ヘッドは使用していません。高頻度取引においては、確率的要素は不要なノイズを導入するだけであると考えているためです。HFT戦略では、市場変化に対して迅速かつ根拠のある反応をおこなうため、ランダム要因を最小限に抑えることが極めて重要です。
モデルの学習
この段階で、MQL5を用いてMacroHFTフレームワークの著者が提案したアプローチを、独自の解釈に基づいて実装する作業は完了しました。学習可能なモデルのアーキテクチャも定義され、次はいよいよモデルの学習に進みます。ただし、その前に学習用データセットを収集する必要があります。これまでのモデルでは1時間足のデータを用いて学習をおこなっていましたが、今回は1分足の情報が必要になります。
時間足を短くするとデータ量が増加する点に注意が必要です。同じ履歴期間であっても、バーの数は60倍になります。他の条件が同じであれば、学習データセットのサイズも比例して増加します。そのため、データ量を抑えるための対策が必要になります。方法は2つあり、学習期間を短縮するか、学習データセットに保存するパス数を減らすかのいずれかです。
今回は学習期間を1年とすることにしました。これは、少なくとも季節性に関する一定の知見を得るために必要な最小期間であると考えています。一方で、各パスの長さは1か月に制限しました。各月についてランダム方針による2パスを保存し、合計24パスとしています。完全な学習には不十分ですが、この構成でも学習データセットファイルのサイズはすでに3GBを超えています。
学習データセット収集に関するこれらの制約は非常に厳しいものでした。なお、ランダムなエージェント方針から収益性を期待する人はいません。そのため、すべてのパスにおいて、口座残高は短時間で完全に失われました。マージンコールによってテストが停止しないよう、取引判断を生成するための最低口座残高の閾値を設定しました。これにより、取引による報酬は得られないものの、分析期間中のすべての環境状態をデータセットに保持することができました。
また、MacroHFTの著者は、暗号資産取引モデルの学習において独自のテクニカル指標リストを使用している点にも触れておく必要があります。このリストは原著記事の付録に掲載されています。
実装では、これまでに使用してきた分析指標のリストをそのまま維持しました。これにより、実装した新しいソリューションの有効性を、過去に構築および学習したモデルと直接比較できます。同一の指標を用いることで、結果を客観的に比較し、新モデルの強みと弱みを明確に評価できます。
学習データセットの収集は、エキスパートアドバイザー(EA)「...\MacroHFT\Research.mq5」によっておこなわれます。本記事では、ターミナルデータの取得と取引実行の中核アルゴリズムが実装されているOnTickメソッドに焦点を当てます。
void OnTick() { //--- if(!IsNewBar()) return;
メソッド本体では、まず新しいバーが形成されたかどうかを確認します。新しいバーが出現した場合にのみ、以降の処理が実行されます。最初に、分析対象のテクニカル指標データを更新し、過去の価格変動データを読み込みます。
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
次に、ターミナルから取得したデータに基づいて、環境状態を記述するバッファを生成するループを構成します。
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
オシレーター系指標の値は、外観が比較的似ており、時間の経過に対して分布の安定性を保つ点に注意してください。そのため、価格変動指標については差分のみを分析対象とし、分布の安定性を維持することで、分析結果が過度な変動によって歪められるのを防いでいます。
次のステップでは、保有中のポジションおよび達成された財務結果を考慮した口座状態記述ベクトルを作成します。まず、保有ポジションに関する情報を収集します。
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
次に、タイムスタンプの調和成分を生成します。
bTime.Clear(); double time = (double)Rates[0].time; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
準備処理がすべて完了した後、すべての財務結果を単一のデータバッファに統合します。
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance)); bAccount.AddArray(GetPointer(bTime)); //--- if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return;
必要な生データがすべて準備できたら、口座残高を確認します。条件を満たしている場合、モデルはフォワードパスを実行します。
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); //--- vector<float> temp; if(sState.account[0] > 50) { if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions); //--- for(int i = 0; i < NActions; i++) { float random = float(rand() / 32767.0 * 5 * min_lot - min_lot); temp[i] += random; } } else temp = vector<float>::Zeros(NActions);
環境探索を強化するため、生成された取引判断には小さなノイズが付加されます。初期段階のランダム方針実行時には不要に見えますが、事前学習済み方針を用いて学習データセットを更新する際には有効に機能します。
口座残高が下限に達した場合、取引判断ベクトルはすべてゼロで埋められ、取引をおこなわないことを示します。
次に、取得した取引判断ベクトルを処理します。まず、相反する操作の取引量を相殺します。
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
続いて、ロングポジションのパラメータを確認します。取引判断にロングポジションが含まれていない場合、既存のロングポジションがあればクローズします。
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
ロングポジションを新規に開く、または維持する必要がある場合は、取引パラメータを必要な形式に変換し、既存ポジションの取引レベルを調整します。
else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp);
その後、ポジションの増減または部分クローズによって、保有量を調整します。
if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
ショートポジションについても、同様の処理をおこないます。
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
取引の実行後、報酬ベクトルを生成します。
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0;
最後に、すべての蓄積データを学習データセット用のストレージバッファに転送し、次の新しいバーの生成を待ちます。
for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
新しいデータを学習データセットバッファに追加できなかった場合、プログラムは終了処理に入ります。これはエラーが発生した場合、またはバッファが完全に満たされた場合に起こります。
このEAの完全なコードは、添付ファイルに収録されています。
実際の学習データセットの収集は、MetaTrader 5ストラテジーテスターにおいて低速最適化を用いて実行されます。

限られたパス数で収集された学習データセットを用いる場合、モデル学習には特別なアプローチが必要です。特に、データの大部分が環境状態情報のみで構成されているため、学習可能性が制限されます。このような条件下では、「ほぼ理想的な」取引判断に基づいてモデルを学習させる方法が最適であると考えられます。この手法は、近年学習させた複数のモデルでも使用しており、データ量が限られている状況でも、学習データを最大限に活用できます。
また、モデル学習プログラムは学習データセットのみに依存して動作し、データ収集時に使用した時間足や金融商品には依存しない点も重要です。これにより、以前に開発した学習プログラムを、アルゴリズムを変更することなく再利用できます。結果として、既存のリソースや手法を有効活用しながら、モデル学習の品質を損なうことなく、時間と労力を節約できます。
テスト
MQL5を用いて、MacroHFTフレームワークの著者が提案したアプローチを独自に解釈し実装するための大規模な作業が完了しました。次のステップでは、実装した手法の有効性を、実際の過去データを用いて評価します。
なお、ここで提示している実装は、テクニカル指標の選択を含め、オリジナルの実装とは大きく異なります。そのため、得られる結果にも必然的に影響があり、ここでの結論はあくまで暫定的であり、これらの修正に特有のものである点に注意が必要です。
モデルの学習には、2024年のEUR/USDの1分足 (M1)データを使用しました。分析対象となる指標のパラメータは変更せず、指標設定の影響を排除し、アルゴリズムおよびアプローチ自体の評価に集中しています。学習データセットの収集手順およびモデル学習の方法については、前述のとおりです。
学習済みモデルは、2025年1月の履歴データを用いてテストされました。以下にそのテスト結果を示します。


2週間のテスト期間中にモデルが実行した取引は8回のみであり、高頻度取引EAとしては明らかに少ない回数です。一方で、実行された取引の効率は注目に値します。不利益となった取引は1回のみであり、その結果、プロフィットファクターは2.47となりました。

取引履歴を詳細に確認すると、上昇トレンドにおいてポジションのスケーリングアップがおこなわれている様子を確認できます。
結論
本記事では、暗号資産市場における高頻度取引のための革新的かつ有望なツールであるMacroHFTフレームワークについて検討しました。このフレームワークの大きな特徴は、マクロ経済的な文脈とローカルな市場ダイナミクスの両方を考慮できる点にあります。この組み合わせにより、急速に変化する金融環境への効果的な適応と、より根拠のある取引判断が可能になります。
実践的な検討では、提案されたアプローチをMQL5を用いて独自に解釈・実装し、フレームワークの動作にいくつかの調整を加えました。モデルは実際の過去データを用いて学習させ、学習に使用していないデータでテストをおこないました。実行された取引回数は期待外れであり、一般的な高頻度取引の特性を反映しているとは言えません。この要因としては、テクニカル指標の選択が最適でなかった可能性や、学習データセットが限定的であった点が考えられます。これらの仮定を検証するには、さらなる調査が必要です。一方で、テスト結果からは、モデルが実際に安定したパターンを識別できる能力を示していることが確認できました。その結果、テストデータセットにおいて高い割合で収益性のある取引を実現しています。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 説明 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いたサンプル収集用EA |
| 3 | Study.mq5 | EA | モデル学習用EA |
| 4 | Test.mq5 | EA | モデルテスト用EA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態とモデルアーキテクチャ記述構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコード |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16993
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。


- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索