
初級から中級まで:共用体(II)

はじめに
ここで提示されるコンテンツは、教育目的のみに使用されることを意図しています。いかなる状況においても、提示された概念を学習し習得する以外の目的でアプリケーションを閲覧することは避けてください。
前回の「初級から中級まで:共用体(I)」では、union(共用体)とは何かについて話し始めました。実際、このテーマは最初の記事から少しずつ積み上げられてきたものであり、これまで取り上げた内容、そして今後扱う内容も、何らかの形で相互に関連しています。前回の記事で説明したことは、unionという大きなテーマのごく一部にすぎません。このテーマは、密接に関係する配列の話題と同じように、非常に広範です。
そうした背景を踏まえ、今回の記事ではunionの理解をさらに深めます。また、配列についての理解も少し広げていきます。それでは、ゆったりと構えて、この記事の最初のテーマに飛び込んでいきましょう。
配列と共用体
unionは、プログラミングにおいて非常に興味深いテーマであり、より高度な概念への扉を開くものです。しかし、このテーマに取り組む際には慎重さが求められます。よくある落とし穴のひとつは、基本を理解しただけで、完全に習得したと勘違いしてしまうことです。
多くの人は、unionを宣言した時点で、そのunionが宣言時に定義された単純なモデルに制限されると誤解しています。実際には、概念を正しく適用すれば、はるかに多くのことが可能になります。
前回の記事でも述べたように、unionを作成する(より正確には「宣言する」)とき、私たちは新しい特殊なデータ型を定義しています。これは、ある意味では文字列の扱い方に似ています。ただし、こうした特殊なデータ型で特定の構造を使用する様子を見ると、不安や懐疑的な感情を抱く読者もいるかもしれません。
これがどれほど有用で、なぜそのような使い方を選ぶのかを示すためには、ひとつの小さくても重要なポイントを理解する必要があります。unionは確かに新しく特別なデータ型であるため、その宣言方法だけでなく、特定の文脈での操作方法においても、さまざまな活用が可能です。それでは、最初の例を見ていきましょう。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits; 07. uchar u8_bits[4]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info[2]; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. View(info); 17. Set(info, 0xA1B2C3D4E5F6789A); 18. View(info); 19. for (uchar c = 0; c < info.Size(); c++) 20. info[c] = Swap(info[c]); 21. View(info); 22. } 23. //+------------------------------------------------------------------+ 24. void Set(un_01 &arg[], ulong value) 25. { 26. arg[0].u32_bits = (uint)(value >> 32); 27. arg[1].u32_bits = (uint)(value & 0xFFFFFFFF); 28. } 29. //+------------------------------------------------------------------+ 30. void View(const un_01 &arg[]) 31. { 32. Print("------------"); 33. for(uchar c = 0; c < arg.Size(); c++) 34. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg[c].u32_bits); 35. } 36. //+------------------------------------------------------------------+ 37. un_01 Swap(const un_01 &arg) 38. { 39. un_01 info = arg; 40. 41. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 42. { 43. tmp = info.u8_bits[i]; 44. info.u8_bits[i] = info.u8_bits[j]; 45. info.u8_bits[j] = tmp; 46. } 47. 48. return info; 49. } 50. //+------------------------------------------------------------------+
コード01
コード01を実行すると、MetaTrader 5端末に次の出力が表示されます。
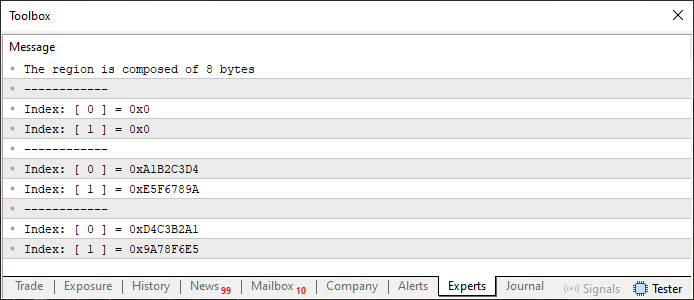
図01
このコード01の例では、これまで扱ってきたすべての内容を適用しています。配列の扱い方も、unionの扱い方も両方です。12行目をご覧ください。ここではstatic配列を宣言しています。一見すると少し奇妙に思えるかもしれません。特に、「配列にはプリミティブ型しか使えない」と思い込んでいる場合はそう感じるでしょう。しかし、ここでは4行目で定義した特殊な型を使っています。それだけのことなのです。
次に14行目では、最初に出力される情報として、変数infoが8バイトで構成されていることが示されています。最初はあまり意味が分からないかもしれません。もしそう感じたなら、ぜひ前回の記事を読み返してみてください。infoが確かに8バイトのサイズを持つ理由は、union内で最も大きいメンバーであるu32_bitsがuint型であるためです。つまり、ここで宣言しているのは、本質的には以下に示す構造体と非常によく似たものなのです。
. . . 12. uint info[2]; . . .
これで混乱することはないと思います。しかし、同じ行の中には、より注意深いプログラマーなら気づく「隠れた記述」も存在します。それこそが、まさに以下に示す内容です。
. . . 12. uchar info[2][4]; . . .
「ちょっと待ってください。どういうことですか。同じコードを二通りの見方ができるということですか。同じ内容を違う書き方で表現できるんでしょうか。正直、少し混乱してしまいます。よく理解できません。」
読者の皆さん、まさにこの点こそが、私が各記事で示した内容をしっかり学び、練習する必要性を強調してきた理由です。特に初心者に多い問題として、文法やコードのパターンばかりに頼りすぎてしまうことがあります。実際には、根底にある概念を理解しようとせず、書かれているコードだけに注目してしまうのです。
前回の記事でも述べたように、unionを作成するとき、私たちはデータを小さな区切りに分割して共有する仕組みを作っているのです。大きなメモリ領域を取り出して、小さな部分に分割し、特定の部分だけを操作できます。こうして、特定の位置を回転させたりシフトしたり、あるいは修正したりすることができるわけですが、それはunionが魔法のようだからではなく、同じメモリを複数の方法で同時に解釈できるからなのです。
先ほどは触れませんでしたが、12行目の書き方はどちらも同じものを表しています。違いは、データの区切り方だけです。最初のケースは、4バイトの要素が2つある配列です。2つ目のケースでもやはり要素は2つで、それぞれ4バイトですが、構造の表現方法が異なるだけです。多次元配列は多くの人にとって理解しづらいものですが、実際には(2つ目の12行目のような)多次元配列は、単に違った形で書かれた同じ配列にすぎません。
多次元配列はさまざまな場面で非常に役立ちますが、これについては今後のどこかの記事で扱う「行列」の話を理解することで、よりわかりやすくなります。それまでは無理に深入りせず、ここで扱っている内容に集中してください。つまり、今に集中し、先のことはあまり気にしなくてよいということです。
この初歩的な説明で、コード01に関して混乱しやすいポイントをある程度整理できたと思いますので、ここからは新しい内容に進みましょう。
ひとつ重要な注意点として、コード01の動作について詳しく説明することはしません。なぜなら、これはすでに過去の記事で扱い、説明しているからです。そこでおこなわれていることはすべて、以前に示し説明済みの内容です。もし理解が難しい場合は、ぜひ前の資料を復習してください。私は皆さんに、今回の画像に示されている結果とまったく同じ結果を出す、自分自身の解決策を作ってほしいと思っています。似たような結果ではなく、完全に同一の結果です。
以上を踏まえた上で、次の例に進みましょう。以下に示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[8]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. View(info); 17. Set(info, 0xA1B2C3D4E5F6789A); 18. View(info); 19. info = Swap(info); 20. View(info); 21. } 22. //+------------------------------------------------------------------+ 23. void Set(un_01 &arg, ulong value) 24. { 25. arg.u32_bits[0] = (uint)(value >> 32); 26. arg.u32_bits[1] = (uint)(value & 0xFFFFFFFF); 27. } 28. //+------------------------------------------------------------------+ 29. void View(const un_01 &arg) 30. { 31. Print("------------"); 32. for(uchar c = 0; c < arg.u32_bits.Size(); c++) 33. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg.u32_bits[c]); 34. } 35. //+------------------------------------------------------------------+ 36. un_01 Swap(const un_01 &arg) 37. { 38. un_01 info = arg; 39. 40. for (uchar i = 0, j = sizeof(info) - 1, tmp; i < j; i++, j--) 41. { 42. tmp = info.u8_bits[i]; 43. info.u8_bits[i] = info.u8_bits[j]; 44. info.u8_bits[j] = tmp; 45. } 46. 47. return info; 48. } 49. //+------------------------------------------------------------------+
コード02
さて、次に見ていくのは、実行すると異なる結果を生み出すコード例です。これがコード02で確認できるものです。一見すると、コード01とほとんど同じに見えますが、実際に実行してみると、出力結果は異なります。
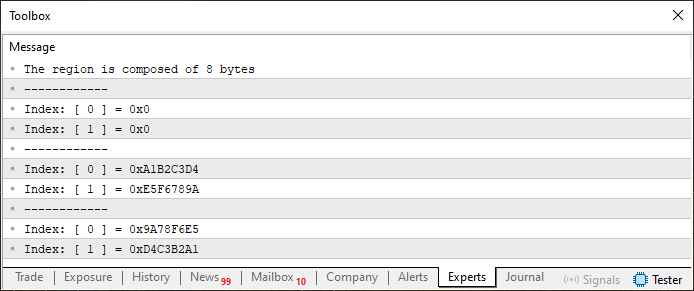
図02
画像01に示されたものとまったく同じに見えると思うかもしれません。では、もう一度よく見てください。図02をよく観察し、図01と比較してみてください。各値をじっくり見ても、まだ同じに見えるでしょうか。実は異なっているのです。その理由は、unionの宣言方法にあります。今回はunionの中に2つの配列があり、どちらもstaticで宣言されています。しかし、どこか論理的にしっくりこない点があります。コード01では、7行目で宣言された配列の要素数は4でした。ところが今回は8になっています。なぜでしょうか。単純に4のままでよかったのではないでしょうか。
これを正しく理解するために、分解して考えてみましょう。まず、要素数を変更した理由と、それがunionにどんな影響を与えるのかを考慮する必要があります。ちょっとした数学的な理由から、コードを不必要に複雑にしないために、7行目で宣言されている配列の要素数は必ず偶数にします。奇数だと、結果の解釈が難しくなる些細な問題が生じるためです。ですので、必ず偶数を使うようにしましょう。仮に要素数を8ではなく6に設定したとします。コードのそれ以外の部分は変更しません。すると、次のような構造になります。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[6]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { . . .
フラグメント01
ここでは、7行目の値のみを変更しました。この変更を加えてコード02を実行すると、次のような出力が得られます。
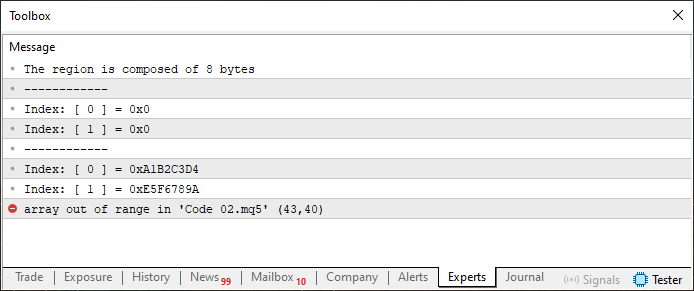
図03
先ほどはうまくいきませんでした。今回は7行目の値を再び変更して、要素を10個にしましょう。更新されたバージョンは次のようになります。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[10]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { . . .
フラグメント02
このバージョンを実行すると、出力は次のようになります。
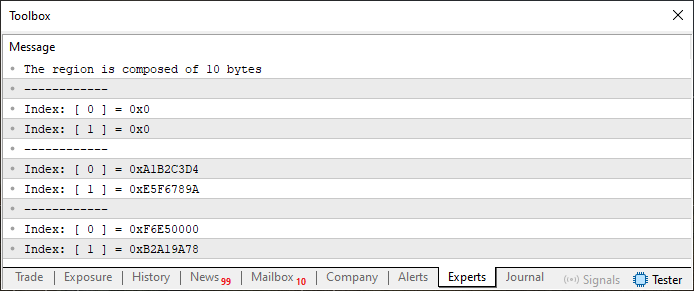
図04
この結果もあまり期待できないようです。いくつかの値が消えたように見えます。この時点で、なぜこうなったかと疑問に思うかもしれません。まさにそのために、今ここで解説をしているのです。一見意味が分からないことでも、経験を積み練習を重ねれば、物事がどのように、そしてなぜそのように振る舞うのかがだんだんと見えてくるようになります。常に重要なのは「適用されている概念」を理解することに集中することです。
では、最初に変更したケース、つまり、図03の結果となり、コードが「メモリの範囲外にアクセスしようとした」というエラーを出したケースに戻りましょう。このエラーが発生した理由は、info変数が8バイトで構成されているからです。ここでよく注目してください。unionの中でu8_bits配列は6要素、つまり6バイトを持っています(要素の型がucharなので、1要素 = 1バイトです)。したがって、変数jがu8_bitsの8番目の要素を参照しようとした時、配列の範囲外のメモリにアクセスしようとすることになります。これが、コードが43行目で失敗する理由です。この失敗は、u8_bitsの要素数が多いか少ないかによるものではありません。u8_bitsの要素数を6に正しく合わせる方法を説明する前に、まずは第2のケース、つまり図04に対応するケースで何が起こっているのかを理解しましょう。
この2つ目のシナリオでは、infoが10バイト(つまり10要素)を持っているのが分かります。これは、u8_bitsが10要素で宣言されているためです。そのため、36行目でSwap関数が実行されると、一部の値が15行目の処理で初期化されたゼロで上書きされます。つまり、ZeroMemoryがinfo変数全体のメモリ領域をクリアしているのです。
これが、一部の値が消えたように見える理由です。実際には、値は単にメモリ上の別の場所に移動したか、別の値に置き換えられただけです。これを示すために、コードに小さな変更を加えます。そして、画像03と画像04で見られた同じ問題を避けるために、新しいバージョンのコードを以下に示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. union un_01 05. { 06. uint u32_bits[2]; 07. uchar u8_bits[8]; 08. }; 09. //+------------------------------------------------------------------+ 10. void OnStart(void) 11. { 12. un_01 info; 13. 14. PrintFormat("The region is composed of %d bytes", sizeof(info)); 15. ZeroMemory(info); 16. Set(info, 0xA1B2C3D4E5F6789A); 17. View(info); 18. Debug(info); 19. info = Swap(info); 20. View(info); 21. Debug(info); 22. } 23. //+------------------------------------------------------------------+ 24. void Set(un_01 &arg, ulong value) 25. { 26. arg.u32_bits[0] = (uint)(value >> 32); 27. arg.u32_bits[1] = (uint)(value & 0xFFFFFFFF); 28. } 29. //+------------------------------------------------------------------+ 30. void View(const un_01 &arg) 31. { 32. Print("------------"); 33. for(uchar c = 0; c < arg.u32_bits.Size(); c++) 34. PrintFormat("Index: [ %d ] = 0x%I64X", c, arg.u32_bits[c]); 35. } 36. //+------------------------------------------------------------------+ 37. void Debug(const un_01 &arg) 38. { 39. string sz = ""; 40. 41. Print("*************"); 42. for(uchar c = 0; c < (uchar)arg.u8_bits.Size(); c++) 43. sz = StringFormat("%s0x%X ", sz, arg.u8_bits[c]); 44. PrintFormat("Number of elements in %cinfo.u8_bits.Size()%c is %d\nInternal content is [ %s ]", 34, 34, arg.u8_bits.Size(), sz); 45. Print("*************"); 46. } 47. //+------------------------------------------------------------------+ 48. un_01 Swap(const un_01 &arg) 49. { 50. un_01 info = arg; 51. 52. for (uchar i = 0, j = (uchar)(info.u8_bits.Size() - 1), tmp; i < j; i++, j--) 53. { 54. tmp = info.u8_bits[i]; 55. info.u8_bits[i] = info.u8_bits[j]; 56. info.u8_bits[j] = tmp; 57. } 58. 59. return info; 60. } 61. //+------------------------------------------------------------------+
コード03
このコードを実行すると、下の画像のようなものが表示されます。
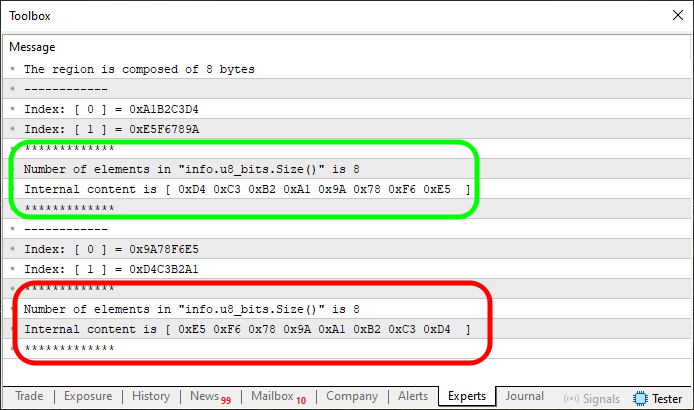
図05
ここから物事がずっと理解しやすくなっていきます。図05では、2つの特定の領域が強調表示されています。ここで注意してほしいのは、このコード03はコード02を改変したものであり、再び注目すべきは7行目です。状況を標準化して正しく理解するために、コード03の7行目の配列には、以前コード02で使ったのと同じ値を再利用しました。これによって、図05に示されている出力が得られます。
さて、ここからが重要です。もしあなたが自分の環境でこれらの結果を再現したいなら、この部分をよく理解してください。コードの52行目では、以前図03で発生したのと同じエラーを防ぐための変更を加えました。その修正によって、以前はできなかった処理が可能になっています。
まず、フラグメント01をコード03に適用してみましょう。これを実行すると、以下のような結果が得られます。
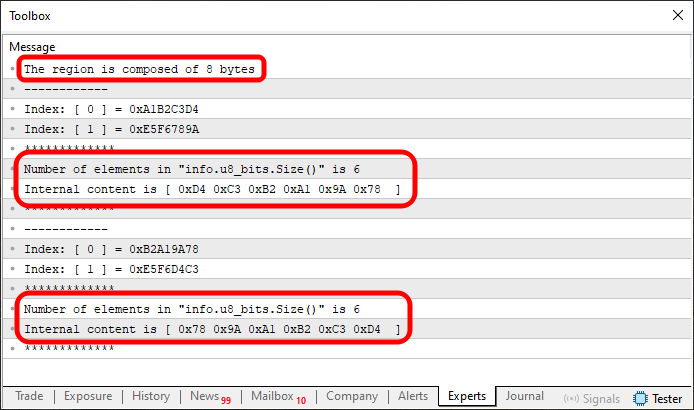
図06
今回も、重要なポイントに印を付けています。これは、内部で何が起きているのかを理解することが非常に重要だからです。u8_bitsの要素数が少なくても、処理は依然として実行されます。しかし、インデックス1の内容を見てください。データの一部が変わらず残っているのがわかるはずです。なぜでしょうか。その答えに入る前に、まずフラグメント02をコード03に適用してみましょう。
これを実行すると、以下の画像に示す結果が得られます。
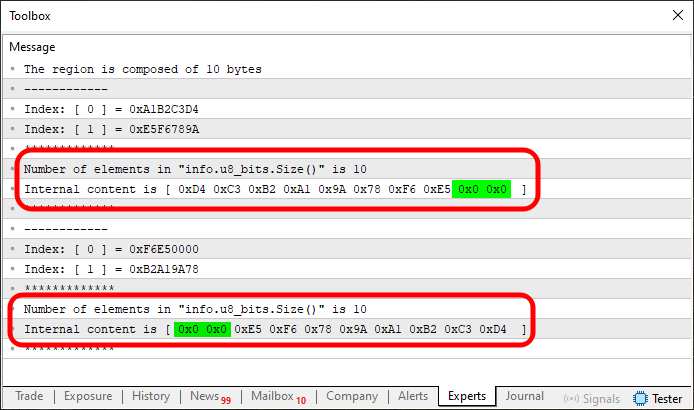
図07
さて、最初に思っていたほど単純ではないことが、ここではっきりしてきました。ですが心配はいりません、読者の皆さん。実際のところ、ここで扱っている内容はとてもシンプルで実用的です。必要なのは、集中して時間をかけ、練習することだけです。記事をただ読み流すだけでは習得できません。手を動かして実際に試してみる必要があります。図06と図07の両方で、メモリが予想通りに回転または反転しているのが確認できます。ただし、u32_bitsの要素を直接参照したときに配列のインデックスに表示される値は、最初に予想していたものとは異なる場合があります。これは、異なるメモリ構成を扱っているためです。
宣言した配列がメモリ領域全体を完全にカバーしている場合は、完全な表現が得られます。そのため、図05が期待通りの見た目になるわけです。しかし、そのメモリブロックを十分にカバーしない(不足させる)か、あるいは必要以上に多く確保する(過剰に確保する)と、結果は歪んだり散らばったりします。これが図06と07に見られる現象で、片方は不足、もう片方は過剰になっている例です。
これで、なぜ7行目の要素数を変更することが重要だったのかお分かりいただけたでしょうか。この設定を正しく扱わないと、特定の状況でメモリのカバー範囲が正しくならず、誤った結果になってしまいます。だからこそ、さまざまな方法を試し、実験することが欠かせないのです。添付ファイルは記事の飾りではありません。実際に使って学ぶためのものです。試してみて、変更を加えて、何が変わるのかを観察してください。そうして初めて、この記事で取り上げた各プログラミング要素について、確かな理解が身についていきます。それが「コピペプログラマー」から「本当に優れたプログラマー」へと成長する道です。
ここまでで、この資料をどのように学び、どのように解釈すればいいのかの基礎は固まりました。私は、あなたがすでに以前の「初級から中級まで:配列(IV)」で提示された課題に取り組む準備ができていると信じています。実際、これからそのコードをさらに改良していきます。その説明のために、新しいトピックへと進みましょう。
良いものをさらに良くする
これからおこなうことは、楽しくて実用的な内容です。しかし、この先の内容を完全に理解するためには、前のセクションで扱った内容をしっかりと習得している必要があります。もしそうでなければ、混乱して迷子になってしまうかもしれません。ですので、焦らずに、これまでに示した内容をじっくりと学び、それからこのMQL5を使った次の課題に進むようにしてください。
では、注意事項はここまでにして、本題に入りましょう。まずは、先ほど触れた以前の記事で紹介したコードの一部を再度取り上げます。その例を以下に示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uint ui = 0xCADA5169; 09. ushort us = 0x43BC; 10. uchar uc = B'01011101'; 11. 12. uchar Infos[], 13. counter = 0; 14. uint start, 15. number; 16. 17. PrintFormat("Translation personal.\n" + 18. "FUNCTION: [%s]\n" + 19. "ui => 0x%s\n" + 20. "us => 0x%s\n" + 21. "uc => B'%s'\n", 22. __FUNCTION__, 23. ValueToString(ui, FORMAT_HEX), 24. ValueToString(us, FORMAT_HEX), 25. ValueToString(uc, FORMAT_BINARY) 26. ); 27. 28. number = sizeof(ui) + 1; 29. start = Infos.Size(); 30. ArrayResize(Infos, start + number); 31. Infos[counter++] = sizeof(ui); 32. Infos[counter++] = (uchar)(ui >> 24); 33. Infos[counter++] = (uchar)(ui >> 16); 34. Infos[counter++] = (uchar)(ui >> 8); 35. Infos[counter++] = (uchar)(ui & 0xFF); 36. 37. number = sizeof(us) + 1; 38. start = Infos.Size(); 39. ArrayResize(Infos, start + number); 40. Infos[counter++] = sizeof(us); 41. Infos[counter++] = (uchar)(us >> 8); 42. Infos[counter++] = (uchar)(us & 0xFF); 43. 44. number = sizeof(uc) + 1; 45. start = Infos.Size(); 46. ArrayResize(Infos, start + number); 47. Infos[counter++] = sizeof(uc); 48. Infos[counter++] = (uc); 49. 50. Print("******************"); 51. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 52. ArrayPrint(Infos); 53. Print("******************"); 54. 55. Procedure(Infos); 56. 57. ArrayFree(Infos); 58. } 59. //+------------------------------------------------------------------+ 60. void Procedure(const uchar &arg[]) 61. { 62. Print("Translation personal.\n" + 63. "FUNCTION: ", __FUNCTION__); 64. 65. ulong value; 66. 67. for (uchar c = 0; c < arg.Size(); ) 68. { 69. value = 0; 70. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 71. value = (value << 8) | arg[c]; 72. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 73. } 74. } 75. //+------------------------------------------------------------------+
コード04
このコード04を実行すると、以下に示す結果が生成されます。
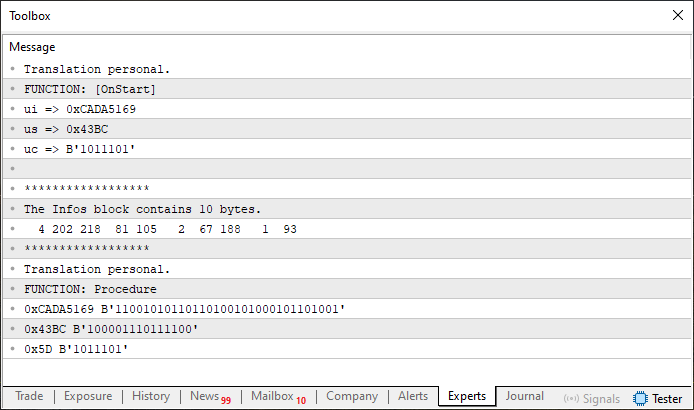
図08
ここで課題です。コード04をこれまでに学んだ内容を使って、より実装しやすくエレガントな形に改善してください。プログラミングを学び始めたばかりの自分が、習ったことを使ってコードを改良するなのは無理だと思うかもしれません。しかし、自分に挑戦せず、快適な領域から一歩も出ない人は、すぐに置いて行かれてしまいます。
新しい技術や優れた概念は常に現れ、私たちの作業をより簡単にし、コードをより効率的にし、「本物のプログラマー」と「ただコピペするだけの人」を分けます。なぜなら、どの段階でも、同じ結果をよりシンプルに実現する新しい方法が見つかるからです。では、これまでの概念をコード04にどう応用して改善できるかを見ていきましょう。そのためにはまず、現在のコードが実際に何をしているのかを分析する必要があります。
基本的には、いくつかの変数が特定の順序で宣言され、使われています。最もメモリ幅が大きい変数はuint型で、8行目に宣言され、28行目から35行目の間で使用されています。他のデータ型はそれよりも小さい型です。このことから、12行目で宣言されている配列「Info」に、同じ内部メモリ構造を再現できるよう情報を格納する方法を考えられます。では、この内部メモリ構造とは具体的に何でしょうか。そして、新しい実装が正しいかどうかはどう判断すればよいのでしょうか。
図08を見てください。特定の時点で、Info配列の正確な内容が表示されています。つまり、やるべきことはこの結果を再現するだけで、あとはコードをより使いやすくすることです。
そう、それが目標です。そして、これまでの記事でも示してきたように、unionを使えばデータをより整理できます。では具体的にどうやるのでしょうか。まず、uint、ushort、そしてucharの値を保持できるように、適切に宣言されたunionを作る必要があります(28行目から48行目までの処理を見ると、この3種類が必要になるのがわかります)。3つの異なるunionが必要だと思うかもしれませんが、実際には1つだけで十分です。その例を以下のコードフラグメントで示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. union un_Model 07. { 08. uint u32; 09. ushort u16; 10. uchar u8, 11. array[sizeof(uint)]; 12. }; 13. //+------------------------------------------------------------------+ 14. void OnStart(void) 15. { . . .
フラグメント03
それでは、フラグメント03を見てみましょう。6行目でunionを作成し、その後の行で後で使うための別々の型を宣言しています。一見すると少しややこしく感じるかもしれません。しかし、本当に注目すべきは11行目です。ここで、union内のすべてのデータ型が占めるメモリ領域全体にアクセスできるようにしています。最大の離散型データのサイズと同じ要素数を持つ静的配列を宣言している点に注目してください。これは、unionの中で何バイト必要なのか分からない場合にとても有効な方法です。
ここで、こう思うかもしれません。「ちょっと待って。もし理解が合っていれば、unionの中の変数(あるいは変数0)を変更すると、特定の変数1つだけでなく、同じメモリ空間を共有する他の変数にも影響が出るはずですね。合っていますか。」その通りです、読者の皆さん。正解です。そして、1つの変数に値を代入すると他も影響を受けてしまうので、このunionは使えないのではないかと考えるかもしれません。 それもまた正しい考え方です。しかし、ここで活用するポイントはまだ説明していません。
実は、特定の変数に代入される値自体にはあまり興味がありません。私たちが本当に気にしているのは、配列に格納されている内容です。システム構築において重要なのはそこです。もしこれまでの記事の内容をしっかり理解し(そして何より練習して)いれば、1つの配列を別の配列にコピーできることに気づいているはずです。コピーしたい要素数と、どの配列からコピーするかが分かれば、28行目から48行目までのコードを大幅に改善できます。とてもシンプルです。配列をコピーするだけです。これを実現するために、以下のコードを使います。
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. #include "Tutorial\File 01.mqh" 005. //+------------------------------------------------------------------+ 006. union un_Model 007. { 008. uint u32; 009. ushort u16; 010. uchar u8, 011. array[sizeof(uint)]; 012. }; 013. //+------------------------------------------------------------------+ 014. void OnStart(void) 015. { 016. const uint ui = 0xCADA5169; 017. ushort us = 0x43BC; 018. uchar uc = B'01011101'; 019. 020. enum eValues { 021. U32_Bits, 022. U16_Bits, 023. U8_Bits 024. }; 025. 026. uchar Infos[], 027. counter = 0; 028. 029. PrintFormat("Translation personal.\n" + 030. "FUNCTION: [%s]\n" + 031. "ui => 0x%s\n" + 032. "us => 0x%s\n" + 033. "uc => B'%s'\n", 034. __FUNCTION__, 035. ValueToString(ui, FORMAT_HEX), 036. ValueToString(us, FORMAT_HEX), 037. ValueToString(uc, FORMAT_BINARY) 038. ); 039. 040. for (eValues c = U32_Bits; c <= U8_Bits; c++) 041. { 042. un_Model data; 043. 044. ArrayResize(Infos, Infos.Size() + 1); 045. switch (c) 046. { 047. case U32_Bits: 048. Infos[counter++] = sizeof(ui); 049. data.u32 = ui; 050. break; 051. case U16_Bits: 052. Infos[counter++] = sizeof(us); 053. data.u16 = us; 054. break; 055. case U8_Bits: 056. Infos[counter++] = sizeof(uc); 057. data.u8 = uc; 058. break; 059. } 060. 061. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - Infos[counter - 1]); 062. } 063. 064. Print("******************"); 065. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 066. ArrayPrint(Infos); 067. Print("******************"); 068. 069. Procedure(Infos); 070. 071. ArrayFree(Infos); 072. } 073. //+------------------------------------------------------------------+ 074. un_Model Swap(const un_Model &arg) 075. { 076. un_Model info = arg; 077. 078. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 079. { 080. tmp = info.array[i]; 081. info.array[i] = info.array[j]; 082. info.array[j] = tmp; 083. } 084. 085. return info; 086. } 087. //+------------------------------------------------------------------+ 088. void Procedure(const uchar &arg[]) 089. { 090. Print("Translation personal.\n" + 091. "FUNCTION: ", __FUNCTION__); 092. 093. ulong value; 094. 095. for (uchar c = 0; c < arg.Size(); ) 096. { 097. value = 0; 098. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 099. value = (value << 8) | arg[c]; 100. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 101. } 102. } 103. //+------------------------------------------------------------------+
コード05
コード05を実行すると、次の結果が表示されます。
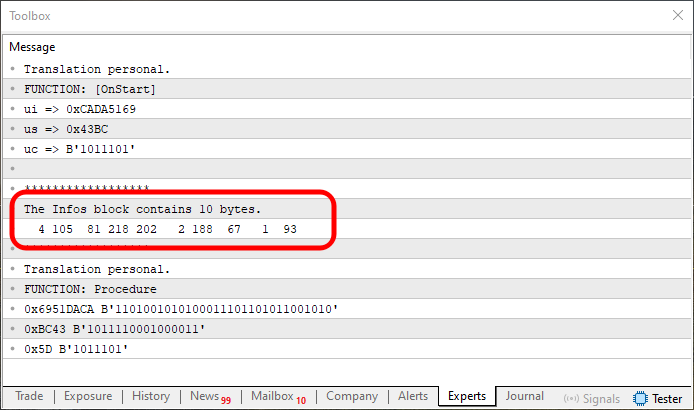
図09
うまくいったように見えますが、実際には少し違います。図09の強調表示された部分を図08とよく比較してみると、値が回転したり反転したりしているのがわかります。しかし、これは私たちにとって問題ではありません。なぜなら、値を反転やミラーリングする方法はすでにお見せしているからです。ただ、その方法に進む前に、別の解決策もあることをお伝えしたいと思います。場合によっては、こちらのほうが十分なこともあります。
画像09に表示されている値は、メモリ上だけでなく、OnStartで出力される内容とProcedureで表示される内容の間でも反転していることに注目してください。しかし、これは重要なポイントですが、具体的な状況によっては、配列が反転している事実を無視しても構わず、以下に示すアプローチを適用できる場合があります。
. . . 62. //+------------------------------------------------------------------+ 63. void Procedure(const uchar &arg[]) 64. { 65. un_Model data; 66. 67. Print("Translation personal.\n" + 68. "FUNCTION: ", __FUNCTION__); 69. 70. for (uchar c = 0; c < arg.Size(); ) 71. { 72. ZeroMemory(data.array); 73. c += (uchar)(ArrayCopy(data.array, arg, 0, c + 1, arg[c]) + 1); 74. Print("0x", ValueToString(data.u32, FORMAT_HEX), " B'", ValueToString(data.u32, FORMAT_BINARY), "'"); 75. } 76. } 77. //+------------------------------------------------------------------+
フラグメント04
もし(ここは強調しておきますが)フラグメント04をコード05内で使用することが許容されるなら、その結果の出力は以下のようになります。
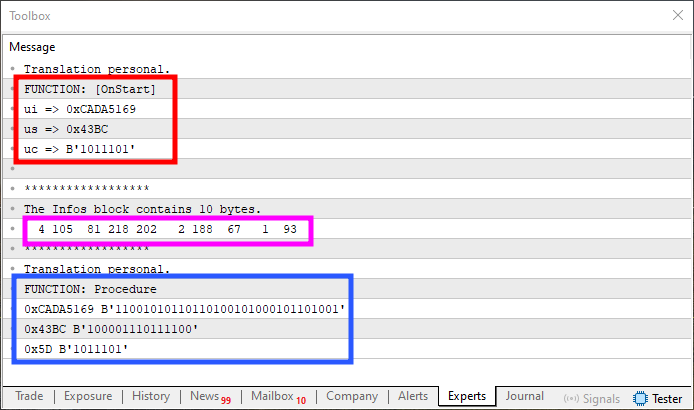
図10
では、よく注目してください、読者の皆さん。図10の赤で強調表示された部分には元の値が示されています。青い領域には出力値が表示されています。図09で見たような反転はなく、元の値と一致していることがわかります。しかし、ピンクで強調表示されたメモリ上の正確な内容は依然として反転または乱れており、図09と同様の状態です。とはいえ、図10の入力値と出力値は図08に示されたものと同一です。
つまり、実際のメモリ内容は無視できて、単に正しい入力値と出力値を得ること(図10のように)が目的なら、フラグメント04で示した解決策は有効と言えます。しかし、状況によっては、このような解決策が求める結果や許容される手法として適さない場合があります。その場合は、最終結果が図08と完全に一致するように、データを明示的に反転(ミラーリング)する必要があります。
それを実現するには、コードに小さな修正を加え、メモリに転送する前に値を反転させる処理を追加すればよいのです。これは非常に簡単で、以前のコードを以下のものに置き換えるだけです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. union un_Model 07. { 08. uint u32; 09. ushort u16; 10. uchar u8, 11. array[sizeof(uint)]; 12. }; 13. //+------------------------------------------------------------------+ 14. void OnStart(void) 15. { 16. const uint ui = 0xCADA5169; 17. ushort us = 0x43BC; 18. uchar uc = B'01011101'; 19. 20. uchar Infos[], 21. counter = 0; 22. 23. PrintFormat("Translation personal.\n" + 24. "FUNCTION: [%s]\n" + 25. "ui => 0x%s\n" + 26. "us => 0x%s\n" + 27. "uc => B'%s'\n", 28. __FUNCTION__, 29. ValueToString(ui, FORMAT_HEX), 30. ValueToString(us, FORMAT_HEX), 31. ValueToString(uc, FORMAT_BINARY) 32. ); 33. 34. { 35. un_Model data; 36. 37. ArrayResize(Infos, Infos.Size() + 1); 38. Infos[counter++] = sizeof(ui); 39. data.u32 = ui; 40. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(ui)); 41. 42. ArrayResize(Infos, Infos.Size() + 1); 43. Infos[counter++] = sizeof(us); 44. data.u16 = us; 45. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(us)); 46. 47. ArrayResize(Infos, Infos.Size() + 1); 48. Infos[counter++] = sizeof(uc); 49. data.u8 = uc; 50. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(uc)); 51. } 52. 53. Print("******************"); 54. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 55. ArrayPrint(Infos); 56. Print("******************"); 57. 58. Procedure(Infos); 59. 60. ArrayFree(Infos); 61. } 62. //+------------------------------------------------------------------+ 63. un_Model Swap(const un_Model &arg) 64. { 65. un_Model info = arg; 66. 67. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 68. { 69. tmp = info.array[i]; 70. info.array[i] = info.array[j]; 71. info.array[j] = tmp; 72. } 73. 74. return info; 75. } 76. //+------------------------------------------------------------------+ 77. void Procedure(const uchar &arg[]) 78. { 79. Print("Translation personal.\n" + 80. "FUNCTION: ", __FUNCTION__); 81. 82. ulong value; 83. 84. for (uchar c = 0; c < arg.Size(); ) 85. { 86. value = 0; 87. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 88. value = (value << 8) | arg[c]; 89. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 90. } 91. } 92. //+------------------------------------------------------------------+
コード06
これで変更が完了しました。しかし、調整が実装されたとしても、結果を見てみましょう。
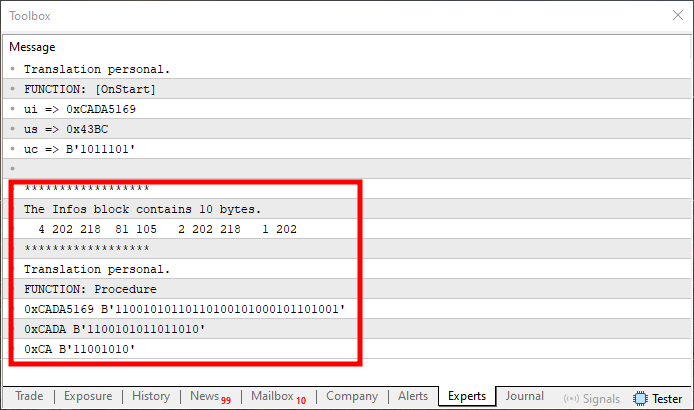
図11
これは初心者がよく挫折してしまう問題の一例です。なぜなら、最初の値だけが正しく、図08で見たものと一致しているのに対し、残りの値は間違っているからです。なぜでしょうか。問題は開始値の扱い方にあります。正しく設定する必要があるのです。これは45行目と50行目のコードで起こっています。現在、開始値がゼロに設定されているため、誤った開始位置からコピー処理が始まってしまいます。その結果、union内の配列の最初の要素にしかコピーが及んでいません。前のトピックで見たように、その配列は反転されていたため、今の最初の要素は元々は最後の要素だったのです。
これを修正するには、45行目と50行目を以下のように変更します。
. . . 34. { 35. un_Model data; 36. 37. ArrayResize(Infos, Infos.Size() + 1); 38. Infos[counter++] = sizeof(ui); 39. data.u32 = ui; 40. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, 0, sizeof(ui)); 41. 42. ArrayResize(Infos, Infos.Size() + 1); 43. Infos[counter++] = sizeof(us); 44. data.u16 = us; 45. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - sizeof(us), sizeof(us)); 46. 47. ArrayResize(Infos, Infos.Size() + 1); 48. Infos[counter++] = sizeof(uc); 49. data.u8 = uc; 50. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - sizeof(uc), sizeof(uc)); 51. } . . .
フラグメント05
フラグメント05で示した変更を取り入れたコード06を実行すると、出力は図12の通りになります。これはまさに図08で期待していた結果そのものです。つまり、完璧に動作しているということです。ただし、フラグメント05をよく見てみると、同じような処理がいくつか繰り返されていることに気づくでしょう。そのため、このコードは簡単にループでまとめることができます。というわけで、最終的なコードは付録に掲載しています。
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. #include "Tutorial\File 01.mqh" 005. //+------------------------------------------------------------------+ 006. union un_Model 007. { 008. uint u32; 009. ushort u16; 010. uchar u8, 011. array[sizeof(uint)]; 012. }; 013. //+------------------------------------------------------------------+ 014. void OnStart(void) 015. { 016. const uint ui = 0xCADA5169; 017. ushort us = 0x43BC; 018. uchar uc = B'01011101'; 019. 020. enum eValues { 021. U32_Bits, 022. U16_Bits, 023. U8_Bits 024. }; 025. 026. uchar Infos[], 027. counter = 0; 028. 029. PrintFormat("Translation personal.\n" + 030. "FUNCTION: [%s]\n" + 031. "ui => 0x%s\n" + 032. "us => 0x%s\n" + 033. "uc => B'%s'\n", 034. __FUNCTION__, 035. ValueToString(ui, FORMAT_HEX), 036. ValueToString(us, FORMAT_HEX), 037. ValueToString(uc, FORMAT_BINARY) 038. ); 039. 040. for (eValues c = U32_Bits; c <= U8_Bits; c++) 041. { 042. un_Model data; 043. 044. ArrayResize(Infos, Infos.Size() + 1); 045. switch (c) 046. { 047. case U32_Bits: 048. Infos[counter++] = sizeof(ui); 049. data.u32 = ui; 050. break; 051. case U16_Bits: 052. Infos[counter++] = sizeof(us); 053. data.u16 = us; 054. break; 055. case U8_Bits: 056. Infos[counter++] = sizeof(uc); 057. data.u8 = uc; 058. break; 059. } 060. 061. counter += (uchar)ArrayCopy(Infos, Swap(data).array, counter, sizeof(data) - Infos[counter - 1]); 062. } 063. 064. Print("******************"); 065. PrintFormat("The Infos block contains %d bytes.", Infos.Size()); 066. ArrayPrint(Infos); 067. Print("******************"); 068. 069. Procedure(Infos); 070. 071. ArrayFree(Infos); 072. } 073. //+------------------------------------------------------------------+ 074. un_Model Swap(const un_Model &arg) 075. { 076. un_Model info = arg; 077. 078. for (uchar i = 0, j = (uchar)(info.array.Size() - 1), tmp; i < j; i++, j--) 079. { 080. tmp = info.array[i]; 081. info.array[i] = info.array[j]; 082. info.array[j] = tmp; 083. } 084. 085. return info; 086. } 087. //+------------------------------------------------------------------+ 088. void Procedure(const uchar &arg[]) 089. { 090. Print("Translation personal.\n" + 091. "FUNCTION: ", __FUNCTION__); 092. 093. ulong value; 094. 095. for (uchar c = 0; c < arg.Size(); ) 096. { 097. value = 0; 098. for (uchar j = arg[c++], i = 0; (c < arg.Size()) && (i < j); i++, c++) 099. value = (value << 8) | arg[c]; 100. Print("0x", ValueToString(value, FORMAT_HEX), " B'", ValueToString(value, FORMAT_BINARY), "'"); 101. } 102. } 103. //+------------------------------------------------------------------+
コード07
最後に
この記事では、データがメモリ上にどのように配置され、どのように動作するのかを理解するという明確な目的のもと、いくつかの興味深いトピックを探求してきました。ここで扱った内容は、多くの人が踏み込もうとしない少し先の領域かもしれませんが、理解が進めば将来大きな財産になるでしょう。
ここでわかるのは、すべてが一見したほど複雑でもなく、かといって一度読んだだけで完全に理解できるほど単純でもない、ということです。常に練習と学習を続けることが重要です。しかし何よりもまず、アプリケーション開発に関わる概念を理解しようと努力することが必要です。
他のプログラマーが書いたコードを、なんとなく自分に合っているからとただ受け入れるだけでは、適切なものは作れません。その時は良さそうに見えても、使ってみると予想外の問題で困り果て、正しい知識がなければ修正できないことも多いからです。ですので、添付されたコードをよく調べて、見たものを試しながら学んでみてください。次の記事でまたお会いしましょう。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15503
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索