
Нейросети в трейдинге: Контрастный Трансформер паттернов (Окончание)

Введение
Фреймворк Atom-Motif Contrastive Transformer (AMCT) можно рассматривать в качестве системы, способной повысить качество прогнозирования рыночных трендов и тенденций путем объединения двух уровней анализа: элементарных объектов и сложных структур. Основная идея заключается в том, что свечи и составленные из них паттерны являются разными представлениями одной рыночной ситуации. Это позволяет естественным образом выравнивать два представления в процессе обучения модели. А извлечение дополнительной информации, присущей представлениям разного уровня, поможет повысить качество генерируемых прогнозов.
Кроме того, похожие рыночные паттерны на графиках различных временных интервалов или инструментов обычно предоставляют похожие сигналы. Поэтому применение методов контрастного обучения позволяет выявить ключевые паттерны и улучшить качество их интерпретации. А для более точной идентификации паттернов, играющих важную роль в определении рыночных тенденций, разработчики фреймворка AMCT ввели механизм внимания с учетом свойств, в котором эксплуатируются подходы кросс-внимания.
Авторская визуализация фреймворка Atom-Motif Contrastive Transformer представлена ниже.

В предыдущей статье мы обсудили реализацию магистралей свечей и паттернов, а так же построили класс относительного кросс-внимания, который планируем использовать в модуле анализа взаимозависимостей между свойствами рыночных ситуаций и свечными паттернами. И сегодня мы продолжим начатую работу.
1. Анализ взаимозависимостей Свойств и Мотивов
Давайте немного поговорим про модуль анализа взаимозависимостей свойств и мотивов. Один из ключевых вопросов заключается в том, что именно мы подразумеваем под "свойствами". На первый взгляд, это может показаться простым вопросом, но на практике оказывается достаточно сложным. Авторы фреймворка AMCT использовали различные свойства веществ, которые они хотели выявить и проанализировать в молекулах. Однако, как же нам определить свойства в контексте рыночных ситуаций, и более того — как их корректно описать?
Возьмём для примера тренд. В классической литературе по техническому анализу рынков тренды обычно делят на три категории: восходящий, нисходящий и боковой (флет). Но возникает вопрос: является ли эта классификация достаточной для глубокого анализа? Как мы можем точно описать динамику ценового движения и силу тренда?
Еще больше вопросов возникает при подборе свойств, характерных рыночной ситуации в контексте решения конкретных практических задач.
Но если у нас нет приемлемого решения данного вопроса, то давайте подойдем к нему с другой стороны. И попросим модель самостоятельно выучить свойства рыночных ситуаций, представленных в обучающей выборке, релевантных для решения поставленной задачи. Подобно лингвистическим примитивам, обучаемым в фреймворке RefMask3D, мы сгенерируем обучаемый тензор свойств, релевантных для решения конкретной практической задачи. Именно такой алгоритм мы реализуем в классе CNeuronPropertyAwareAttention, структура которого представлена ниже.
class CNeuronPropertyAwareAttention : public CNeuronRMAT { protected: CBufferFloat cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronPropertyAwareAttention(void) {}; ~CNeuronPropertyAwareAttention(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint properties, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronPropertyAwareAttention; } };
В качестве родительского класса мы используем CNeuronRMAT, в котором реализован алгоритм линейной модели. Как вы знаете, внутренние объекты нашего родительского класса упакованы в одном динамическом массиве. Это позволяет нам при изменении выстраиваемой внутренней архитектуры не объявлять новые объекты в структуре класса. Достаточно лишь переопределить виртуальный метод инициализации объекта, в котором и будет создана необходимая последовательность внутренних объектов. Единственное ограничение — линейность архитектуры.
К сожалению, архитектура кросс-внимания немного выходит за рамки линейности, так как использует 2 источника исходных данных. Поэтому мы вынуждены переопределить виртуальные методы прямого и обратного проходов. Предлагаю рассмотреть алгоритмы переопределяемых методов.
В параметрах метода инициализации нового объекта Init мы получаем константы, позволяющие однозначно определить архитектуру создаваемого объекта.
bool CNeuronPropertyAwareAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint properties, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * properties, optimization_type, batch)) return false;
А в теле метода мы сразу вызываем одноименный метод базового класса полносвязного нейронного слоя CNeuronBaseOCL.
Обратите внимание, в данном случае осуществляется вызов метода именно базового нейронного слоя, а не прямого родительского. Ведь вызовом указанного метода мы хотим инициализировать лишь базовые интерфейсы. А последовательность внутренних объектов мы полностью переопределяем.
Далее мы подготовим динамический массив записи указателей на внутренние объекты.
cLayers.Clear(); cLayers.SetOpenCL(OpenCL);
И объявим локальные переменные для временного хранения указателей на создаваемые объекты.
CNeuronBaseOCL *neuron=NULL; CNeuronRelativeSelfAttention *self_attention = NULL; CNeuronRelativeCrossAttention *cross_attention = NULL; CResidualConv *ff = NULL;
На этом мы завершаем подготовительную работу и переходим к построению последовательности внутренних объектов. Вначале мы создадим 2 последовательных полносвязных слоя генерации обучаемого тензора эмбединга свойств, которые могут характеризовать рыночную ситуацию.
int idx = 0; neuron = new CNeuronBaseOCL(); if (!neuron || !neuron.Init(window * properties, idx, OpenCL, 1, optimization, iBatch) || !cLayers.Add(neuron)) return false; CBufferFloat *temp = neuron.getOutput(); if (!temp.Fill(1)) return false; idx++; neuron = new CNeuronBaseOCL(); if (!neuron || !neuron.Init(0, idx, OpenCL, window * properties, optimization, iBatch) || !cLayers.Add(neuron)) return false;
Здесь мы используем подходы, успешно проверенные в предыдущих работах. Первый слой содержит только один нейрон с фиксированным значением "1". А второй нейронный слой генерирует нужную нам последовательность эмбедингов, для обучения которых мы используем базовый функционал созданного объекта. Указатели на оба объекта мы добавляем в наш динамический массив, в соответствии с последовательностью их вызова.
Далее нам предстоит построить структуру почти ванильного декодера Transformer. Мы лишь заменим в нем модули внимания на соответствующие с относительным кодированием структуры анализируемой последовательности. Для этого мы создадим цикл с числом итераций, равным заданному количеству внутренних слоев.
for (uint i = 0; i < layers; i++) { idx++; self_attention = new CNeuronRelativeSelfAttention(); if (!self_attention || !self_attention.Init(0, idx, OpenCL, window, window_key, properties, heads, optimization, iBatch) || !cLayers.Add(self_attention) ) { delete self_attention; return false; }
В теле цикла мы вначале создаем и инициализируем слой относительного Self-Attention, который анализирует взаимозависимости между эмбедингами наших обучаемых свойств, характеризующих рыночную ситуацию в контексте решаемой задачи. Поэтому длина анализируемой последовательности определяется параметром properties. Указатель на созданный объект мы также добавляем в наш динамический массив.
Следующим мы создаем слой относительного кросс-внимания.
idx++; cross_attention = new CNeuronRelativeCrossAttention(); if (!cross_attention || !cross_attention.Init(0, idx, OpenCL, window, window_key, properties, heads, window, units_count, optimization, iBatch) || !cLayers.Add(cross_attention) ) { delete cross_attention; return false; }
Здесь, в качестве основного потока, мы также используем информацию об эмбединге свойств, что, собственно, и определяет размер тензора результатов. Поэтому длину последовательности блока FeedForward мы тоже укажем равной количеству генерируемых свойств.
idx++; ff = new CResidualConv(); if (!ff || !ff.Init(0, idx, OpenCL, window, window, properties, optimization, iBatch) || !cLayers.Add(ff) ) { delete ff; return false;}
}
Добавляем указатели на созданные объекты в динамический массив и переходим к следующей итерации цикла.
После успешного выполнения необходимого количества итераций цикла, в нашем динамическом массиве соберется весь набор объектов, требуемых для корректной реализации алгоритма модуля анализа взаимозависимостей обучаемых свойств и найденных паттернов. Нам остается лишь осуществить подмену указателей на буфера данных, что позволяет нам значительно сократить количество операций в процессе обучения моделей.
if (!SetOutput(ff.getOutput()) || !SetGradient(ff.getGradient())) return false; //--- return true;}
И завершаем работу метода, передав логический результат выполнения операций вызывающей программе.
После завершения работы по инициализации нового объекта нашего класса, мы переходим к построению алгоритма прямого прохода, который реализован в методе feedForward. И здесь необходимо сразу обратить внимание, что несмотря на использование модуля кросс-внимания в архитектуре нашего блока, метод прямого прохода получает лишь один указатель на объект исходных данных. Это связано с тем, что второй источник исходных данных ("свойства") генерируется непосредственно объектами нашего класса.
bool CNeuronPropertyAwareAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В теле метода мы сразу проверяем актуальность полученного указателя. Ведь получаемый объект мы будем использовать в качестве дополнительного источника данных. А значит, будем напрямую обращаться к буферам данного объекта и, в случае неактуального указателя на объект, рискуем получить критическую ошибку.
Объявим локальную переменную для временного хранения указателей на объект.
CNeuronBaseOCL *neuron = NULL;
Обратите внимание, что мы объявляем переменную нашего базового типа нейронных слоев. Напомню, что она является общим предком для всех наших объектов нейронных слоев. Это позволяет нам сохранить в объявленной переменной указатель на любой из объектов внутренних нейронных слоев и использовать его базовые интерфейсы и переопределенные методы.
Далее мы переходим к работе с нашей моделью генерации эмбедингов свойств. Напомню, что её объекты записаны в первых двух элементах нашего динамического массива. Первый нейронный слой у нас содержит фиксированное значение, поэтому мы сразу переходим к вызову метода прямого прохода второго объекта, передав ему в качестве исходных данных указатель на объект первого слоя.
if (bTrain) { neuron = cLayers[1]; if (!neuron || !neuron.FeedForward(cLayers[0])) return false; }
Однако метод прямого прохода второго слоя мы вызываем только в процессе обучения объекта, так как на этапе обучения мы изучаем рыночные состояния из обучающей выборки в поисках свойств, релевантных для поставленной задачи. В процессе же эксплуатации, мы будем использовать ранее выученные эмбединги свойств, а значит, результат работы данного слоя будет всегда постоянным. И нам нет необходимости выполнять операции генерации тензора эмбедингов на каждом проходе. Следовательно, в процессе эксплуатации мы опускаем данный шаг, что позволит нам сократить время принятия решения моделью.
Далее мы просто организовываем цикл перебора оставшихся внутренних слоев с последовательным вызовом их методов прямого прохода. А в качестве источников исходных данных мы будем передавать результаты работы предыдущего слоя и буфер результатов объекта, полученного в параметрах метода.
for (int i = 2; i < cLayers.Total(); i++) { neuron = cLayers[i]; if (!neuron.FeedForward(cLayers[i - 1], NeuronOCL.getOutput())) return false; } //--- return true; }
Обратите внимание, что в качестве основного источника исходных данных используются результаты работы предыдущего слоя. Именно по данной магистрали передаются эмбединги обучаемых свойств рыночных ситуаций. И они анализируются во всех модулях внимания и блоке FeedForward нашего декодера. Получаемые в параметрах метода эмбединги паттернов, найденных в описании анализируемой рыночной ситуации, помогут нам расставить акценты на свойствах, релевантных текущей рыночной ситуации. Таким образом, на выходе Декодера мы получаем ещё одно представление рыночной ситуации в виде свойств с расставленными акцентами.
После выполнения всех итераций нашего цикла, завершаем работу метода прямого прохода, предварительно передав логический результат выполнения операций вызывающей программе.
Далее нам предстоит поработать над организацией процессов обратного прохода нашего класса. В организации метода обновления параметров модели updateInputWeights нет сложностей. Здесь мы просто последовательно вызываем одноименные методы внутренних объектов. Но в методе распределения градиентов ошибки calcInputGradients есть своя изюминка.
Как вы знаете, алгоритм метода распределения градиентов ошибки должен полностью повторить поток информации прямого прохода, но в обратном порядке, распределяя градиент ошибки по всем объектам, в соответствии с их влиянием на общий результат работы модели. И если какой-либо объект является источником исходных данных для нескольких информационных потоков, то он должен получить свою долю градиента ошибки от каждого из них.
Посмотрите на реализацию метода прямого прохода. В нем указатель на объект эмбедингов паттернов передается в параметрах всех внутренних нейронных слоев нашего Декодера. Конечно, модули Self-Attention и FeedForward просто проигнорируют его, так как они не используют второй источник исходных данных. Но вот модуль кросс-внимания будет использовать их на каждом внутреннем слое нашего Декодера. Следовательно, в процессе распределения ошибки нам предстоит суммировать на объект эмбединга паттернов его долю градиента ошибки с каждого модуля кросс-внимания.
В параметрах метода мы получаем указатель на объект представления обнаруженных паттернов. И в теле метода сразу проверяем актуальность полученного указателя.
bool CNeuronPropertyAwareAttention::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Далее нам предстоит выполнить некоторую подготовительную работу. Здесь мы сначала проверяем наличие ранее инициализированного вспомогательного буфера данных, в который планируем записывать промежуточные значения градиентов ошибки. И обязательно убедимся в достаточности его размера. В случае негативного результата, на любой точке контроля мы инициализируем новый буфер данных достаточного размера.
if (cTemp.GetIndex() < 0 || cTemp.Total() < NeuronOCL.Neurons()) { cTemp.BufferFree(); if (!cTemp.BufferInit(NeuronOCL.Neurons(), 0) || !cTemp.BufferCreate(OpenCL)) return false; }
А затем обнулим буфер градиентов ошибки полученного в параметрах объекта.
if (!NeuronOCL.getGradient() || !NeuronOCL.getGradient().Fill(0)) return false;
Обычно мы не выполняем подобной операции, так как при выполнении операций распределения градиентов ошибки мы заменяем ранее сохраненные значения на новые. И это хорошее решение для линейных моделей. Но с другой стороны, такая реализация заставляет нас искать обходные пути в случае сбора градиентов ошибки с нескольких магистралей.
После успешного выполнения подготовительной работы, мы организовываем цикл обратного перебора внутренних слоев нашего блока с целью распределения по ним градиента ошибки.
CNeuronBaseOCL *neuron = NULL; for (int i = cLayers.Total() - 2; i > 0; i--) { neuron = cLayers[i]; if (!neuron.calcHiddenGradients(cLayers[i + 1], NeuronOCL.getOutput(), GetPointer(cTemp), (ENUM_ACTIVATION)NeuronOCL.Activation())) return false;
В теле цикла мы вызываем метод распределения градиентов ошибки каждого внутреннего слоя с передачей соответствующих параметров. Только вместо буфера градиентов ошибки, мы передаем указатель на наш буфер временного хранения данных. И после успешного выполнения операций вызванного метода внутреннего объекта мы проверяем тип нейронного слоя. Ведь мы помним, что не все внутренние нейронные слои использовали второй источник данных. В случае нахождения модуля кросс-внимания, мы прибавляем полученный градиент ошибки второго источника данных к ранее накопленным значениям в буфере объекта эмбедингов паттернов.
if (neuron.Type() == defNeuronRelativeCrossAttention) { if (!SumAndNormilize(NeuronOCL.getGradient(), GetPointer(cTemp), NeuronOCL.getGradient(), 1, false, 0, 0, 0, 1)) return false; } //--- return true;}
После успешного выполнения всех итераций нашего цикла, мы возвращаем вызывающей программе логический результат выполнения операций и завершаем работу метода.
На этом мы завершаем работу над блоком внимания с учетом свойств. А с полным кодом данного класса и всех его методов вы можете ознакомиться во вложении.
2. Фреймворк AMCT
Мы проделали большую работу и реализовали отдельные блоки, составляющие фреймворк Atom-Motif Contrastive Transformer. И пришло время объединить созданные модули в единую структуру. Для выполнения этой задачи мы создадим объект CNeuronAMCT, структура которого представлена ниже.
class CNeuronAMCT : public CNeuronBaseOCL { protected: CNeuronRMAT cAtomEncoder; CNeuronMotifEncoder cMotifEncoder; CLayer cMotifProjection; CNeuronPropertyAwareAttention cPropertyDecoder; CLayer cPropertyProjection; CNeuronBaseOCL cConcatenate; CNeuronMHAttentionPooling cPooling; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronAMCT(void) {}; ~CNeuronAMCT(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint properties, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronAMCT; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
В представленной структуре мы видим объявление реализованных нами объектов, к которым добавляется 2 динамических массива. Об их функционале мы поговорим немного позже. Все объекты объявлены статично, что позволяет нам оставить пустыми конструктор и деструктор класса. Инициализация всех унаследованных и объявленных объектов осуществляется в методе Init.
В параметрах метода инициализации мы получаем основные константы, позволяющие однозначно определить архитектуру создаваемого объекта.
bool CNeuronAMCT::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint properties, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
А в теле метода мы сразу вызываем одноименный метод родительского класса, передав в него часть из полученных параметров.
Думаю вы обратили внимание, что в представленной структуре объекта нет внутренних переменных для сохранения значений полученных параметров. Все константы, определяющие архитектура нашего класса будут использоваться для инициализации внутренних объектов, в недрах которых и будет сохранены необходимые значения. Мы же в методах прямого и обратного проходов будем оперировать лишь с внутренними объектами. Поэтому мы не будем создавать излишние переменные.
Далее мы переходим к инициализации внутренних объектов. И первыми мы инициализируем объекты наших двух магистралей: свечей и паттернов.
int idx = 0; if (!cAtomEncoder.Init(0, idx, OpenCL, window, window_key, units_count, heads, layers, optimization, iBatch)) return false; idx++; if (!cMotifEncoder.Init(0, idx, OpenCL, window, window_key, units_count, heads, layers, optimization, iBatch)) return false;
Несмотря на различия в архитектуре магистралей, обе они будут работать с одним источником исходных данных, и на данном этапе получают идентичные параметры.
На выходе магистралей мы ожидаем получить два представления анализируемой рыночной ситуации: на уровне свечей и паттернов. И авторы фреймворка предлагают сопоставить их для взаимного обогащения и уточнения представлений. Но тут следует обратить внимание, что размеры тензоров результатов в обоих случаях отличаются. И этот факт, несомненно, усложняет процесс сопоставления результатов. Поэтому мы воспользуемся небольшой моделью масштабирования данных, которую применим к результатам магистрали паттернов. Указатели на объекты модели масштабирования мы сохраним в динамическом массиве cMotifProjection.
Сначала мы подготавливаем указанный динамический массив.
cMotifProjection.Clear(); cMotifProjection.SetOpenCL(OpenCL);
И определим длину последовательности паттернов. Как вы знаете, на выходе магистрали паттернов мы получаем конкатенированный тензор эмбедингов двух уровней.
int motifs = int(cMotifEncoder.Neurons() / window);
Обратите внимание, что тензоры представлений отличаются лишь по длине последовательности. При этом мы сохранили размер вектора описания одного элемента последовательности. Поэтому вполне логично, что в процессе масштабирования мы будем работать с отдельными унитарными рядами последовательности. Для этого мы сначала транспонируем тензор представлений на уровне паттернов.
idx++; CNeuronTransposeOCL *transp = new CNeuronTransposeOCL(); if (!transp || !transp.Init(0, idx, OpenCL, motifs, window, optimization, iBatch) || !cMotifProjection.Add(transp)) return false;
А затем воспользуемся сверточным слоем для масштабирования унитарных последовательностей.
idx++; CNeuronConvOCL *conv = new CNeuronConvOCL(); if (!conv || !conv.Init(0, idx, OpenCL, motifs, motifs, units_count, 1, window, optimization, iBatch) || !cMotifProjection.Add(conv)) return false; conv.SetActivationFunction((ENUM_ACTIVATION)cAtomEncoder.Activation());
Обратите внимание, что размер окна исходных данных и его шага равны длине последовательности представления на уровне паттернов. При этом количество фильтров равно длине последовательности представления на уровне свечей.
Ещё один момент, на который стоит обратить внимание — параметры длины последовательности и количества унитарных последовательностей. В данном случае мы указали, что последовательность исходных данных состоит из одного элемента. А количество унитарных рядов в последовательности равно размеру вектора описания одного элемента последовательности исходных данных. Такой набор параметров позволяет нам создать отдельные обучаемые матрицы весов для каждой унитарной последовательности получаемых исходных данных. Иными словами, для масштабирования последовательностей разных элементов, в описании одного элемента исходной последовательности будут использоваться различные матрицы масштабирования. Что позволит нам настроить более гибкий процесс масштабирования.
И обязательно не забудем синхронизировать функции активации на выходах сверточного слоя масштабирования и магистрали представления на уровне свечей.
После чего вернем уже масштабированные данные в исходное представление с помощью слоя транспонирования данных.
idx++; transp = new CNeuronTransposeOCL(); if (!transp || !transp.Init(0, idx, OpenCL, window, units_count, optimization, iBatch) || !cMotifProjection.Add(transp)) return false; transp.SetActivationFunction((ENUM_ACTIVATION)conv.Activation());
Далее мы инициализируем блок кросс-внимания свойств и паттернов, на выходе которого планируем получить представление анализируемого рыночного состояния на уровне свойств.
idx++; if (!cPropertyDecoder.Init(0, idx, OpenCL, window, window_key, properties, motifs, heads, layers, optimization, iBatch)) return false;
И вот мы пришли к кульминационному моменту. На выходе трех блоков мы получили три различных представления одного анализируемого рыночного состояния. Более того, все они представлены тензорами различных размеров. И что дальше? Как их использовать для решения конкретных задач? Какой из них выбрать для получения результатов максимального качества?
Я думаю, надо использовать результаты всех трех блоков. Модель масштабирования представления паттернов мы уже инициализировали. Создадим аналогичную для масштабирования представления свойств. Указатели на объекты данной модели масштабирования сохраним в динамическом массиве cPropertyProjection.
cPropertyProjection.Clear(); cPropertyProjection.SetOpenCL(OpenCL); idx++; transp = new CNeuronTransposeOCL(); if (!transp || !transp.Init(0, idx, OpenCL, properties, window, optimization, iBatch) || !cPropertyProjection.Add(transp)) return false; idx++; conv = new CNeuronConvOCL(); if (!conv || !conv.Init(0, idx, OpenCL, properties, properties, units_count, 1, window, optimization, iBatch) || !cPropertyProjection.Add(conv)) return false; conv.SetActivationFunction((ENUM_ACTIVATION)cAtomEncoder.Activation()); idx++; transp = new CNeuronTransposeOCL(); if (!transp || !transp.Init(0, idx, OpenCL, window, units_count, optimization, iBatch) || !cPropertyProjection.Add(transp)) return false; transp.SetActivationFunction((ENUM_ACTIVATION)conv.Activation());
Приведенные к единой размерности три представления мы конкатенируем в единый тензор.
idx++; if (!cConcatenate.Init(0, idx, OpenCL, 3 * window * units_count, optimization, iBatch)) return false;
А теперь посмотрите, мы получили конкатенированный тензор, который объединяет три разносторонних взгляда на одну рыночную ситуацию. Не напоминает ли это вам результаты многоголового внимания? Фактически, мы имеем результаты трех голов и для получения итоговых значений воспользуемся слоем пулинга на основе зависимостей.
idx++; if(!cPooling.Init(0, idx, OpenCL, window, units_count, 3, optimization, iBatch)) return false;
Теперь нам остается осуществить подмену буферов данных в унаследованных интерфейсах на соответствующие объекта пулинга, что позволит нам исключить излишние операции копирования данных.
if (!SetOutput(cPooling.getOutput(), true) || !SetGradient(cPooling.getGradient(), true)) return false; //--- return true; }
И завершаем работу метода инициализации, предварительно передав логический результат выполнения операций вызывающей программе.
После завершения работы по построению метода инициализации нашего объекта, мы переходим к организации процессов прямого прохода. Как обычно, его алгоритм мы реализуем в методе feedForward.
bool CNeuronAMCT::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cAtomEncoder.FeedForward(NeuronOCL)) return false; if(!cMotifEncoder.FeedForward(NeuronOCL)) return false;
В параметрах метода мы получаем указатель на объект исходных данных, который сразу передаем в наши магистрали представления рыночной ситуации на уровне свечей и паттернов.
Результаты работы магистрали паттернов мы передадим в модуль кросс-внимания свойств и паттернов.
if(!cPropertyDecoder.FeedForward(cMotifEncoder.AsObject())) return false;
На данном этапе мы получили три представления анализируемой ситуации. Приведем их к единому масштабу данных. Для этого мы сначала масштабируем представление на уровне паттернов.
//--- Motifs projection CNeuronBaseOCL *prev = cMotifEncoder.AsObject(); CNeuronBaseOCL *current = NULL; for(int i = 0; i < cMotifProjection.Total(); i++) { current = cMotifProjection[i]; if(!current || !current.FeedForward(prev, NULL)) return false; prev = current; }
И организуем аналогичный процесс для представления на уровне свойств.
//--- Property projection prev = cPropertyDecoder.AsObject(); for(int i = 0; i < cPropertyProjection.Total(); i++) { current = cPropertyProjection[i]; if(!current || !current.FeedForward(prev, NULL)) return false; prev = current; }
Теперь мы можем объединить три представления в единый тензор.
//--- Concatenate uint window = cAtomEncoder.GetWindow(); uint units = cAtomEncoder.GetUnits(); prev = cMotifProjection[cMotifProjection.Total() - 1]; if(!Concat(cAtomEncoder.getOutput(), prev.getOutput(), current.getOutput(), cConcatenate.getOutput(), window, window, window, units)) return false;
И воспользуемся слоем пуллинга для взвешенного суммирования результатов трех представлений.
//--- Out if(!cPooling.FeedForward(cConcatenate.AsObject())) return false; //--- return true; }
Благодаря подмене указателей на буфера данных, осуществленной в методе инициализации, нам нет необходимости копировать данные в буфера интерфейсов нашего класса. Мы просто завершаем работу метода, вернув логический результат выполнения операций вызывающей программе.
Следующим этапом нашей работы является построение методов обратного прохода. И наибольший интерес, с точки зрения построения алгоритма, представляет метод распределения градиента ошибки calcInputGradients. Дело в том, что разветвленная структура зависимостей между информационными потоками, предложенная авторами фреймворка AMCT, наложила свой отпечаток на алгоритм указанного метода. Предлагаю более детально посмотреть на его реализацию в коде.
В параметрах метода, как обычно, мы получаем указатель на объект предыдущего слоя, в который нам и предстоит передать градиент ошибки, в соответствии с влиянием исходных данных на конечный результат.
bool CNeuronAMCT::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Мы сразу проверяем актуальность полученного указателя. Ведь в случае его недействительности, все дальнейшие операции теряют смысл.
Затем мы переходим к последовательному распределению градиента ошибки между внутренними объектами. Здесь стоит обратить внимание, что благодаря подмене указателей на буфера данных интерфейсов, нам нет необходимости копировать данные из внешних интерфейсов во внутренние объекты. И мы можем сразу начинать распределение градиента ошибки по внутренним объектам. Сначала мы определим градиент ошибки на уровне конкатенированного тензора трех представлений анализируемого состояния окружающей среды.
if(!cConcatenate.calcHiddenGradients(cPooling.AsObject())) return false;
А затем распределим градиент ошибки между магистралями отдельных представлений. Градиент ошибки представления на уровне свечей мы сразу передаем в Энкодер. А два других передаем на соответствующие модели масштабирования.
uint window = cAtomEncoder.GetWindow(); uint units = cAtomEncoder.GetUnits(); CNeuronBaseOCL *motifs = cMotifProjection[cMotifProjection.Total() - 1]; CNeuronBaseOCL *prop = cPropertyProjection[cPropertyProjection.Total() - 1]; if (!motifs || !prop || !DeConcat(cAtomEncoder.getGradient(), motifs.getGradient(), prop.getGradient(), cConcatenate.getGradient(), window, window, window, units)) return false;
Затем мы скорректируем градиенты ошибок отдельных представлений на соответствующие функции активации.
if (cAtomEncoder.Activation() != None) { if (!DeActivation(cAtomEncoder.getOutput(), cAtomEncoder.getGradient(), cAtomEncoder.getGradient(), cAtomEncoder.Activation())) return false; if (motifs.Activation() != None) { if (!DeActivation(motifs.getOutput(), motifs.getGradient(), motifs.getGradient(), motifs.Activation())) return false; if (prop.Activation() != None) { if (!DeActivation(prop.getOutput(), prop.getGradient(), prop.getGradient(), prop.Activation())) return false;
И добавим градиент ошибки сопоставления представлений свечей и паттернов.
if(!motifs.calcAlignmentGradient(cAtomEncoder.AsObject(), true)) return false;
После чего, мы распределим градиент ошибки по моделям масштабирования, организовав циклы обратного перебора нейронных слоев моделей.
for (int i = cMotifProjection.Total() - 2; i >= 0; i--) { motifs = cMotifProjection[i]; if (!motifs || !motifs.calcHiddenGradients(cMotifProjection[i + 1])) return false; }
for (int i = cPropertyProjection.Total() - 2; i >= 0; i--) { prop = cPropertyProjection[i]; if (!prop || !prop.calcHiddenGradients(cPropertyProjection[i + 1])) return false; }
Градиент ошибки от модели масштабирования представления свойств мы передаем на модуль кросс-внимания свойств и паттернов. И далее до Энкодера паттернов.
if (!cPropertyDecoder.calcHiddenGradients(cPropertyProjection[0]) || !cMotifEncoder.calcHiddenGradients(cPropertyDecoder.AsObject())) return false;
Но надо отметить, что результаты Энкодера паттернов использовались и для модели масштабирования представления паттернов. Следовательно, мы должны добавить градиент ошибки второго информационного потока. Для этого мы сначала сохраним указатель на объект буфера градиентов ошибки нашего Энкодера паттернов в локальной переменной. А затем заменим его на буфер "донора".
В качестве объекта-донора мы избрали слой конкатенации трех представлений. Градиент ошибки с него мы уже распределили по соответствующим информационным потокам. Сам же слой не имеет обучаемых параметров. Поэтому мы безболезненно можем удалить значения буфера. Кроме того, это слой с самым большим размером буферов среди всех внутренних объектов нашего блока, что делает его лучшим кандидатом в "доноры".
После подмены буфера, мы получаем градиент ошибки от модели масштабирования. Суммируем данные двух информационных потоков и возвращаем указатели на буферы данных в исходное состояние. А затем передаем градиент ошибки на уровень исходных данных.
CBufferFloat *temp = cMotifEncoder.getGradient(); if (!cMotifEncoder.SetGradient(cConcatenate.getGradient(), false) || !cMotifEncoder.calcHiddenGradients(cMotifProjection[0]) || !SumAndNormilize(temp, cMotifEncoder.getGradient(), temp, window, false, 0, 0, 0, 1) || !cMotifEncoder.SetGradient(temp, false) || !NeuronOCL.calcHiddenGradients(cMotifEncoder.AsObject())) return false;
Аналогичная ситуация нас ожидает и на уровне исходных данных: к градиенту ошибки, полученному от Энкодера паттернов, нам необходимо добавить долю влияния на результат по магистрали Энкодера свечей. Мы повторяем трюк с подменой указателя на буфер данных, но уже для другого объекта.
temp = NeuronOCL.getGradient(); if (!NeuronOCL.SetGradient(cConcatenate.getGradient(), false) || !NeuronOCL.calcHiddenGradients(cAtomEncoder.AsObject()) || !SumAndNormilize(temp, NeuronOCL.getGradient(), temp, window, false, 0, 0, 0, 1) || !NeuronOCL.SetGradient(temp, false)) return false; //--- return true; }
И теперь, когда мы полностью распределили градиент ошибки между всеми объектами модели и исходными данными, можно завершить работу метода, но предварительно вернем логический результат выполнения операций вызывающей программе.
Хочется акцентировать ваше внимание на двух моментах представленной реализации. Первое, при подмене указателей на буферы градиентов здесь мы в обязательном порядке сначала сохраняем указатель на исходный буфер данных. А затем, при вызове метода замены указателя, в обязательном порядке устанавливаем флаг false, который предотвращает удаление ранее записанного объекта. Это позволяет нам сохранить объект буфера и, в последующем, вернуть указатель на место. При использовании флага true, как это делали в методе инициализации, мы бы удалили имеющийся объект буфера данных, и при последующих обращениях к нему получили критическую ошибку.
Второй момент касается архитектуры построения метода. В представленном алгоритме нет создания контрастности представлений паттернов, предусмотренной авторами фреймворка AMCT. Но я напомню, что мы добавили диверсификацию представлений в объекте относительного кросс-внимания. Так что фактически мы просто перенесли точку добавления ошибки контрастного обучения.
На этом мы завершаем рассмотрение алгоритмов построения фреймворка Atom-Motif Contrastive Transformer. А с полным кодом всех представленных классов и их методов вы можете ознакомиться во вложении. Там же представлены программы взаимодействия с окружающей средой и обучения моделей. Все они перенесены без изменений из предыдущих работ. Были внесены лишь точечные правки в архитектуру Энкодера окружающей среды. Здесь мы заменили один слой.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronAMCT; descr.window = BarDescr; // Window (Indicators to bar) { int temp[] = {HistoryBars, 100}; // Bars, Properties if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.window_out = EmbeddingSize / 2; // Key Dimension descr.layers = 5; // Layers descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Полное описание архитектуры обучаемых моделей представлено во вложении.
3. Тестирование
Мы проделали большую работу по реализации фреймворка Atom-Motif Contrastive Transformer средствами MQL5, и пришло время проверить эффективность реализованных подходов на практике. Для этого мы осуществляем обучение модели с использованием новых объектов на реальных исторических данных с последующей проверкой обученной политики в тестере стратегий MetaTrader 5 на временном отрезке за пределами обучающей выборки.
Как обычно, обучение модели мы осуществляем офлайн на заранее собранной обучающей выборке из проходов за весь 2023 год. Обучение осуществляется итерационно, и, после нескольких итераций обучения моделей, мы осуществляем актуализацию обучающей выборки. Это позволяет нам добиться максимально точной оценки действий Агента в соответствии с актуальной политикой.
В процессе обучения нам удалось получить модель, способную генерировать прибыль как на обучающей, так и на тестовой выборке. Но есть один нюанс. Полученная нами модель совершает слишком мало сделок. И мы даже увеличили период тестирования до 3 месяцев. Результаты тестирования представлены ниже.
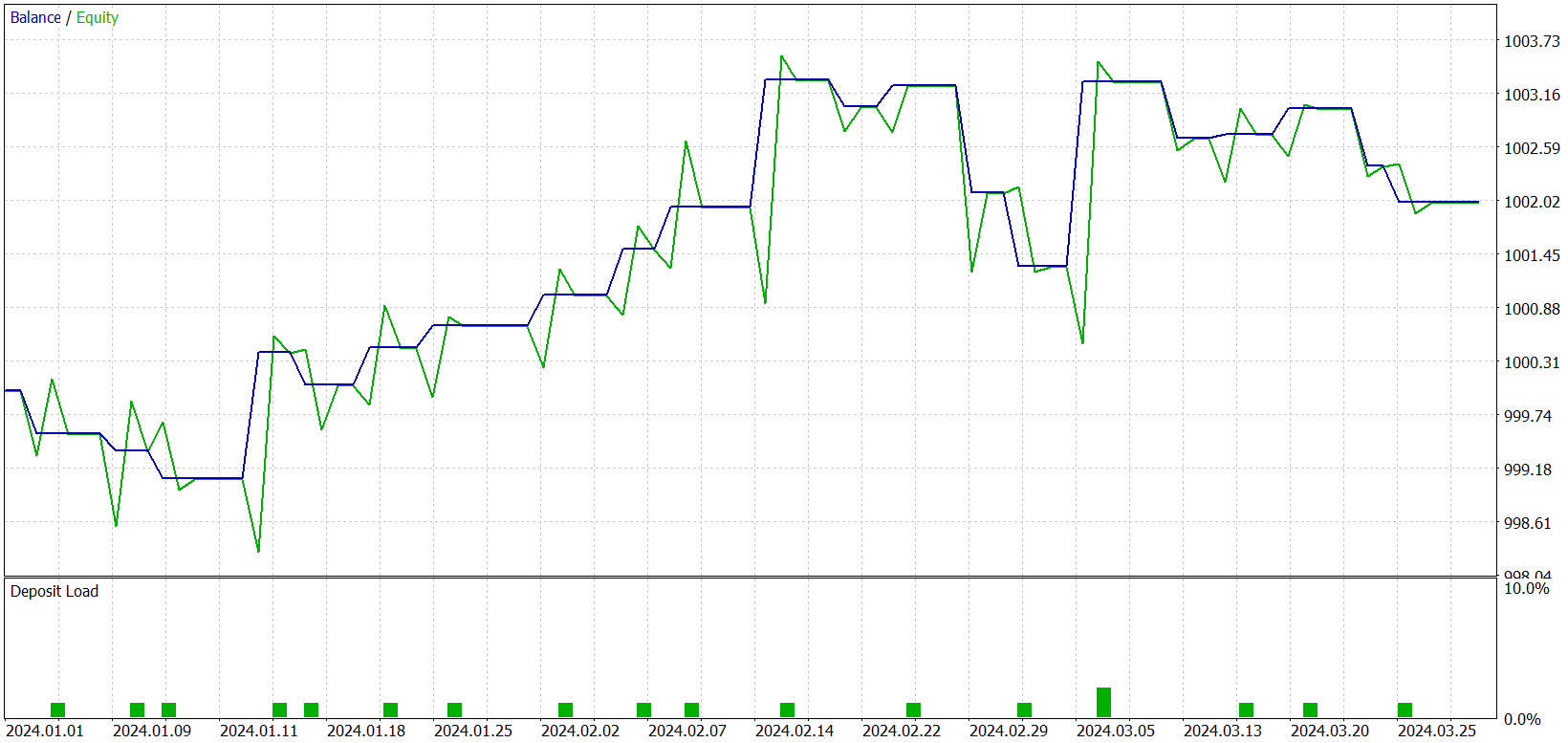
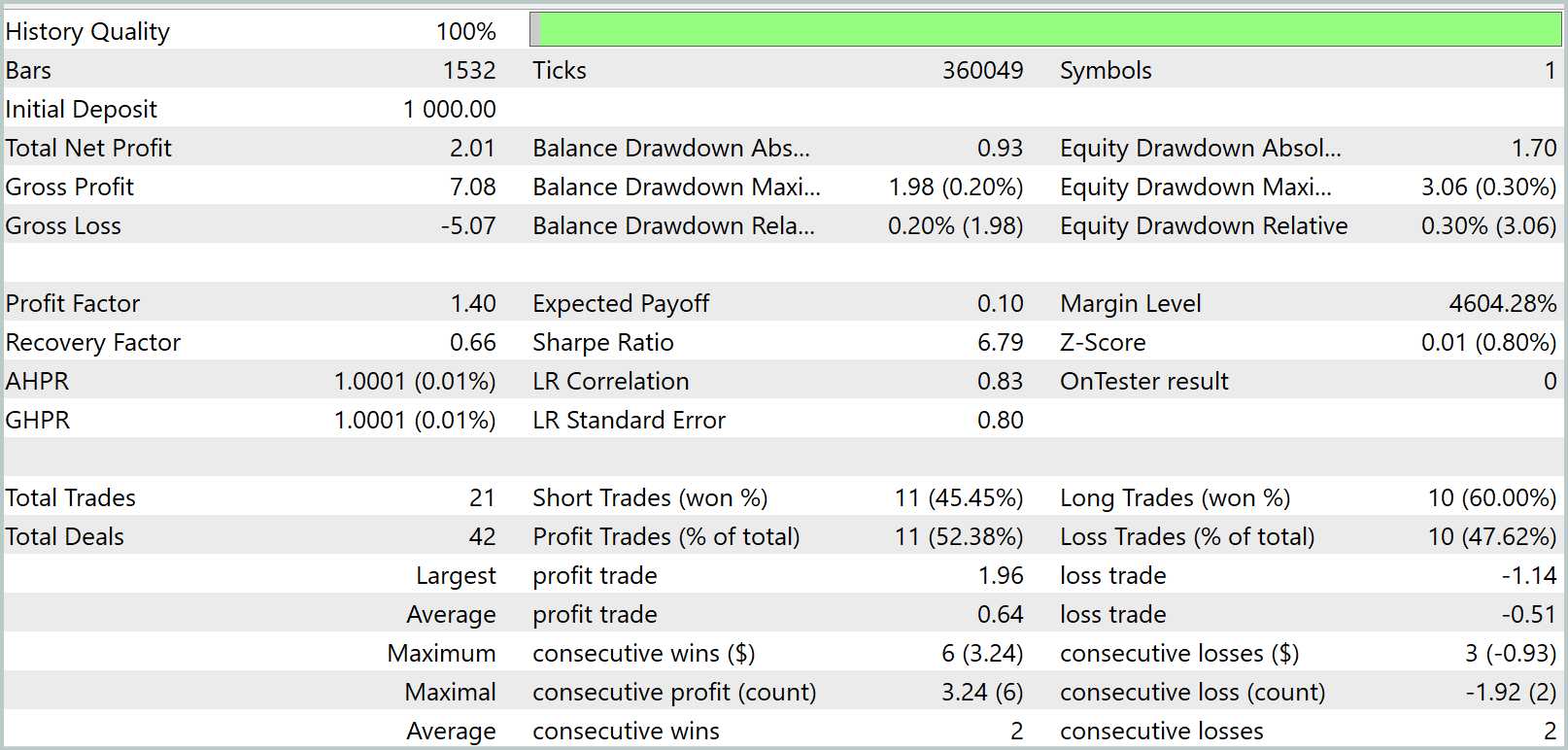
Как видно из представленных данных, за трехмесячный интервал периода тестирования модель совершила всего 21 сделку и чуть более половины из них было закрыто с прибылью. Но давайте посмотрим на график баланса. В первые полтора месяца мы наблюдаем рост баланса, который потом сменяется боковым движением. На самом деле, это весьма ожидаемое поведение. Наша модель лишь собирает статистику с рыночных состояний обучающей выборки. И как в любой статистической модели, обучающая выборка должна быть репрезентативной. А из графика баланса можно сделать вывод, что обучающая выборка в 1 год репрезентативна на последующие 1.2 — 1.5 месяца.
Тогда можно предположить, что обучение модели на обучающей выборке в 10 лет способно дать модель со стабильной работой в рамках 1 года. Можно также предположить, что большая обучающая выборка позволит выделить большее количество ключевых паттернов и обучаемых свойств. А это потенциально увеличит количество совершаемых торговых операций. Однако, для подтверждения или опровержения данных гипотез необходимо проведение дополнительной работы с моделью.
Заключение
В двух последних работах мы познакомились с фреймворком Atom-Motif Contrastive Transformer (AMCT), который опирается на концепции атомарных элементов (свечей) и мотивов (паттернов). Основная идея метода заключается в применении контрастного обучения для выделения информативных и неинформативных паттернов на разных уровнях: от элементарных составляющих до сложных структур. Это позволяет модели не только учитывать локальные движения цены на рынке, но и выявлять значимые паттерны, которые могут предоставить дополнительные сведения для более точного прогнозирования будущего рыночного поведения. Архитектура Transformer, лежащая в основе этого фреймворка, эффективно распознаёт долгосрочные зависимости и сложные взаимосвязи между свечами и паттернами.
В практической части мы реализовали свое видение предложенных подходов средствами MQL5, обучили модели и провели их тестирование на реальных исторических данных. К сожалению, полученная нами модель оказалась "скудной на сделки". Однако, просматривается некий потенциал, который мы надеемся развить в следующих работах.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования