
Нейросети в трейдинге: Контрастный Трансформер паттернов

Введение
При анализе рыночных ситуаций с помощью машинного обучения мы часто фокусируемся на отдельных свечах и их характеристиках, упуская из виду свечные паттерны, которые часто могут предоставить более значимую информацию. Паттерны являются стабильными свечными структурами, возникающими в аналогичных рыночных условиях, и могут содержать критически важные закономерности.
Ранее мы познакомились с фреймворком Molformer, заимствованным из области прогнозирования молекулярных свойств. Авторы Molformer объединили представление атомов и мотивов в одну последовательность, что позволило предоставить модели информацию о структуре анализируемых данных. В то же время это привело к постановке довольно сложной задачи разделения зависимостей между узлами различных типов. Однако существуют альтернативные методы, лишенные данной проблемы.
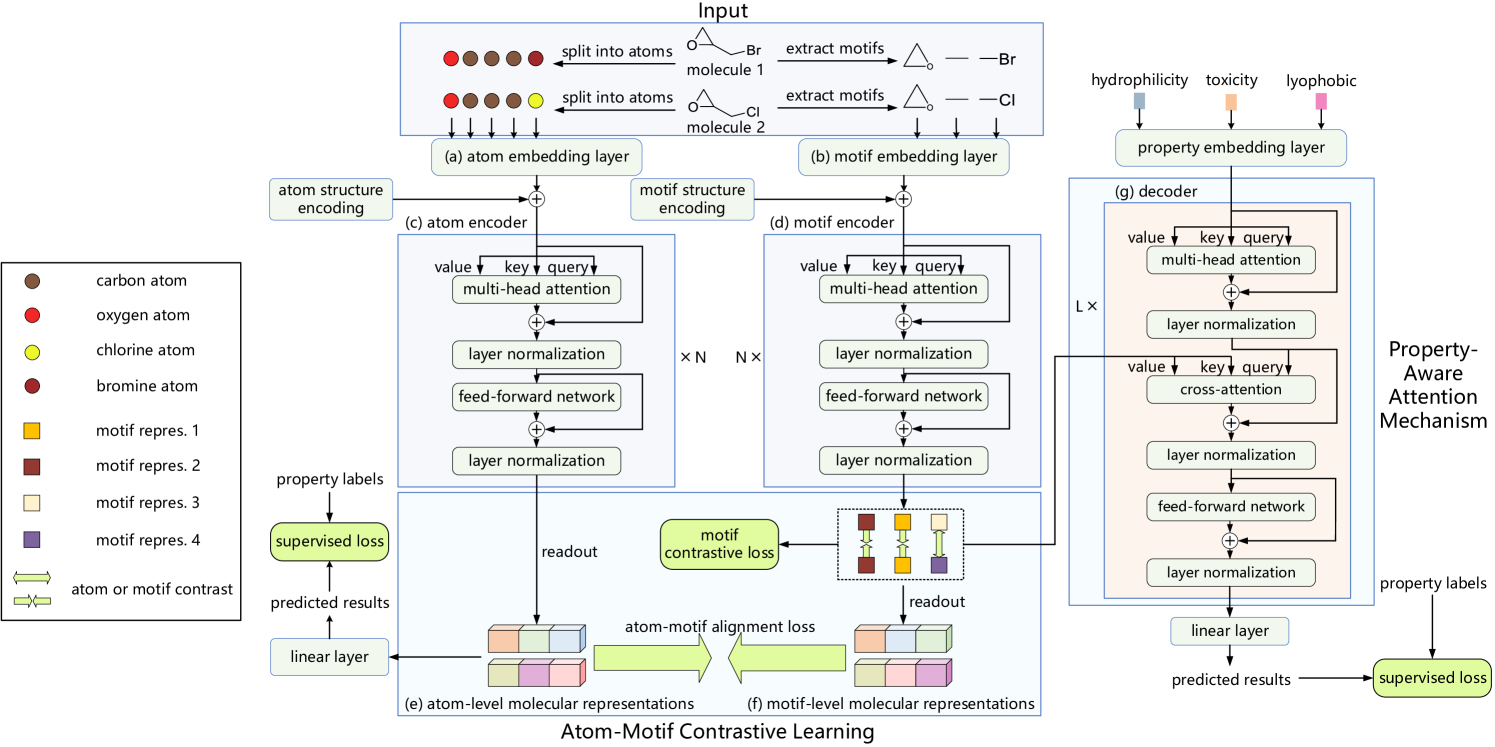
К примеру, фреймворк Atom-Motif Contrastive Transformer (AMCT), представленный в работе "Atom-Motif Contrastive Transformer for Molecular Property Prediction". Для объединения двух уровней взаимодействий и повышения способности молекулярной репрезентации авторы AMCT предложили построить контрастное обучение атом-мотив. Учитывая, что представления атомов и мотивов молекулы на самом деле являются двумя разными представлениями одного и того же экземпляра, они естественным образом выравниваются в процессе обучения. Таким образом, они могут совместно подавать сигналы самоконтроля и тем самым повышать надежность выученного молекулярного представления.
Выявлено, что идентичные мотивы в разных молекулах обычно имеют схожие химические свойства. Это означает, что идентичные мотивы должны иметь согласованные представления во всех молекулах. Следовательно, использование контрастной потери позволит максимизировать согласование идентичных мотивов в разных молекулах и получить различимое представление мотивов.
Более того, для четкой идентификации мотивов, которые имеют решающее значение для определения свойств каждой молекулы, авторы метода дополнительно конструируют механизм внимания, учитывающий свойства с помощью модуля перекрестного внимания. В частности, модуль кросс-внимания определяет зависимости между эмбедингами молекулярных свойств и представлениями мотивов. В результате можно идентифицировать ключевые мотивы на основе весов кросс-внимания.
1. Алгоритм AMCT
Поступающие на вход модели описания молекул сначала расщепляются на набор атомов и сегментируются в набор мотивов. Затем полученные последовательности подаются на параллельные слои кодирования атомов и мотивов, которые генерируют соответствующие эмбединги. Два независимых Энкодера используются для получения молекулярных представлений на уровне атомов и мотивов. А Декодер и полносвязный слой используются для получения прогнозируемых результатов. В процессе обучения модели используются ошибка выравнивания атом-мотива, контрастные ошибки на уровне мотивов и ошибки прогнозирования свойств.
В процессе кодирования атомов мы сначала получаем их эмбединги. А затем используем Энкодер атомов для извлечения взаимозависимостей между отдельными атомами молекулы. На его выходе формируется молекулярное представления на уровне атомов.
Авторы AMCT используют степень центральности для кодирования структурной информации между атомами, а именно связующих отношений атомов в молекуле. Поскольку степень центральности применяется к каждому атому, мы просто добавляем ее к эмбедингу атома.
Взаимозависимости атомов успешно улавливают низкоуровневые детали, но игнорируют высокоуровневую структурную информацию между различными атомами, поэтому в некоторых случаях их недостаточно для прогнозирования молекулярных свойств. Для решения данной проблемы авторы фреймворка AMCT вводят параллельную магистраль представления молекул на уровне мотивов. В процессе кодирования мотивов сначала их извлекаем из набора исходных данных, а затем генерируем эмбединги. После этого используется Энкодер мотивов для извлечения взаимозависимостей между мотивами.
Авторы фреймворка AMCT используют степень центральности для кодирования структурной информации между мотивами, которая добавляется к соответствующим эмбедингам.
С целью исследования дополнительной новой информацию, предоставляемой мотивами, рассматриваются отношения сходства между молекулярными представлениями на уровне атомов и мотивов. Поскольку представления атомов и мотивов одной молекулы на самом деле являются двумя разными представлениями об одного и того же, то они естественным образом выравниваются для генерации сигналов самоконтроля при обучении модели. Для сопоставления двух представлений авторы метода используют дивергенцию Кульбака-Лейблера.
Поскольку ошибка выравнивания атомов и мотивов происходит внутри молекулы и ограничена согласованностью между атомами и мотивами в одной молекуле, авторы ACTM стремятся выполнить межмолекулярный контраст и исследовать согласованность между различными молекулами. Учитывая, что идентичные мотивы в разных молекулах демонстрируют схожие химические свойства, ожидается, что они должны иметь схожие представления для всех молекул. Для достижения этой цели предлагается контрастная ошибка мотива, которая максимизирует согласованность представления идентичных мотивов в разных молекулах. При этом отталкиваются представления мотивов, принадлежащих к разным классам.
Хороший процесс декодирования также важен для получения надежного представления. AMCT предлагает декодирование с учетом свойств. В частности, сначала получаем эмбединги свойств, а затем используем декодер для извлечения молекулярных представлений, ключевых для отдельных свойств. Прогнозируемые результаты получаются после линейной проекции.
Декодер предназначен для извлечения молекулярных представлений, учитывающих свойства. Для определения мотивов, которые имеют решающее значение в определении свойств каждой молекулы, авторы AMCT строят механизм внимания, учитывающий свойства. Здесь используется модуль перекрестного внимания, который использует эмбединги свойств в качестве Query и представления мотивов в качестве Key-Value. Считается, что мотив с большим весом перекрестного внимания имеет больший вклад в молекулярное свойство.
Авторская визуализация фреймворка Atom-Motif Contrastive Transformer представлена ниже.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов фреймворка Atom-Motif Contrastive Transformer мы переходим к практической части нашей статьи, в котором представим собственное видение предложенных подходов средствами MQL5.
Фреймворк AMCT представляет собой довольно сложную и комплексную структуру. Но если внимательно присмотреться к используемым блоком, то можно заметить, что большая часть из них уже реализована в нашей библиотеке в том или ином виде. Тем не менее нам есть над чем поработать. К примеру, сравнение представлений на уровне атомов и мотивов. Надеюсь, у Вас нет сомнения, что помимо простого нахождения расхождений нам предстоит ещё распределить градиент ошибки на обе магистрали с целью минимизации расхождений. И здесь есть несколько вариантов решения данного вопроса.
Мы, конечно, можем скопировать результаты одной магистрали в буфер градиентов другой, а затем найти градиент ошибки с помощью метода базового нейронного слоя calcOutputGradients, который мы используем для нахождения ошибки работы модели. К преимуществам такого подхода можно отнести простоту реализации, ведь используются уже существующие средства. Однако это довольно затратный метод. В процессе обучения модели нам потребуется копирование двух буферов данных (результаты двух магистралей) и последовательное вычисление градиентов для каждого представления.
Поэтому мы решили создать небольшой кернел на стороне OpenCL программы, который нам позволит определить градиент ошибки сразу для обеих магистралей и без излишнего копирования данных.
__kernel void CalcAlignmentGradient(__global const float *matrix_o1, __global const float *matrix_o2, __global float *matrix_g1, __global float *matrix_g2, const int activation, const int add) { int i = get_global_id(0);
В параметрах кернела мы получаем указатели на 4 буфера данных. Из них 2 буфера содержат результаты магистралей атомов и мотивов, в нашем случае свечей и паттернов. И 2 буфера для записи соответствующих градиентов ошибки. Кроме того, в параметрах кернела мы получаем один указатель функции активации, которая использовалась для обеих магистралей.
Обратите внимание, что здесь мы однозначно ограничиваем возможность использования разной функции активации для магистралей. Дело в том, что для корректного сравнения результатов двух магистралей они должны находиться в одном подпространстве. И именно функция активации определяет область результатов слоя. Следовательно, использование одной функции активации на выходе обеих магистралей вполне логично.
Тут же мы добавим флаг, который укажет на необходимость добавления градиента ошибки к ранее накопленным данным или удалению предыдущего значения.
Данный кернел мы планируем вызывать в одномерном пространстве задач. Следовательно, идентификатор потока, который мы определяем в теле кернела, укажет нам необходимое смещение в буферах данных.
Далее мы подготовим локальные переменные, в которые сохраним соответствующие результаты прямого прохода магистралей и нулевые значения для градиентов ошибки.
const float out1 = matrix_o1[i]; const float out2 = matrix_o2[i]; float grad1 = 0; float grad2 = 0;
Мы проверяем действительность значений прямого прохода. И при наличии корректных числовых значений вычисляем отклонение, которое затем корректируем на производную функции активации. Результаты сохраняем в подготовленные локальные переменные.
if(!isnan(out1) && !isinf(out1) &&
!isnan(out2) && !isinf(out2))
{
grad1 = Deactivation(out2 - out1, out1, activation);
grad2 = Deactivation(out1 - out2, out2, activation);
}
Теперь мы можем перенести градиенты ошибки в соответствующие глобальные буфера данных. В зависимости от полученного флага мы либо добавляем значения к ранее накопленному градиенту, либо удаляем предыдущее значение и записываем новое. После чего завершаем работу кернела.
if(add > 0) { matrix_g1[i] += grad1; matrix_g2[i] += grad2; } else { matrix_g1[i] = grad1; matrix_g2[i] = grad2; } }
Надо сказать, что это наше единственное дополнение OpenCL-программы. С полным её кодом Вы можете ознакомиться во вложении.
Далее мы переходим к работе на стороне основной программы, где нам предстоит выстроить архитектуру предложенного фреймворка AMCT. Прежде всего нам необходимы 2 магистрали: атомом (баров) и мотивов (паттернов). Авторы метода в своей работе в качестве магистралей используют ванильный Transformer с добавлением структурного кодирования атомов и мотивов. Я же предлагаю заменить его на Transformer с относительным кодированием (R-MAT), рассмотренный нами в одной из предыдущих статей. И на этом можно было бы закрыть вопрос магистралей. Только для магистрали паттернов (мотивов) нам необходимо их предварительно выделить. Поэтому, магистраль паттернов я решил вынести в отдельный объект.
2.1 Построение магистрали паттернов
Алгоритм магистрали паттернов мы построим в классе CNeuronMotifEncoder, структура которого представлена ниже.
class CNeuronMotifEncoder : public CNeuronRMAT { public: CNeuronMotifEncoder(void) {}; ~CNeuronMotifEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronMotifEncoder; } };
Как можно заметить из представленной структуры нового объекта, в качестве родительского класса мы используем CNeuronRMAT. В данном классе организована работа линейной модели, нейронные слои которой упакованы в динамическом массиве. Что позволяет нам просто сформировать последовательную архитектуру нашей магистрали паттернов в методе Init. А вся необходимая функциональность будет унаследована от родительского класса.
Структура параметров метода инициализации была полностью унаследована от аналогичного метода родительского класса.
bool CNeuronMotifEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(units_count < 3) return false;
Однако выделение паттернов вносит ограничение на длину последовательности исходных данных, которую мы сразу проверяем в теле метода. После чего подготовим динамический массив для записи указателей на создаваемыми нами слои нейронов.
cLayers.Clear();
Здесь стоит обратить внимание, что мы еще не вызывали метод родительского класса. А значит все унаследованные объекты еще не инициализированы. С другой стороны, в параметрах, полученных от внешней программы, нет явного указания на размер буфера результатов, который нам необходим для выполнения метода родительского класса. И чтобы не осуществлять вычисления размера буфера результатов на данном этапе, мы сначала инициализируем слои создания эмбедингов паттернов. Размер одного паттерна мы не указали в параметрах метода, поэтому сделаем его зависимы от размера последовательности. Для размера последовательности более 10 элементов мы будем анализировать паттерны из трех элементов. В противном случае — из двух.
int bars_to_paattern = (units_count > 10 ? 3 : 2);
Генерировать эмбединги паттернов мы будем с помощью сверточного слоя, который тут же инициализируем. А указатель на созданный нейронный слой добавим в наш динамический массив.
CNeuronConvOCL *conv = new CNeuronConvOCL(); int idx = 0; int units = (int)units_count - bars_to_paattern + 1; if(!conv || !conv.Init(0, idx, open_cl, bars_to_paattern * window, window, window, units, 1, optimization_type, batch)|| !cLayers.Add(conv) ) return false; conv.SetActivationFunction(SIGMOID);
Обратите внимание, что мы строим эмбединги перекрывающихся паттернов с шагом в 1 бар. При этом размер эмбединга одного паттерна равен окну описания одного бара. Это позволит нам более качественно проанализировать исходную последовательность на наличие паттернов.
Однако мы пойдем немного дальше и проанализируем паттерны немного большего размера, состоящие из 5 или 3 баров в зависимости от размера исходной последовательности. При этом мы конкатенируем эмбединги паттернов двух уровней, чтобы предоставить модели больше информации о структуре исходных данных. Для выполнения этого функционала мы воспользуемся слоем CNeuronMotifs, созданного в рамках работы над фреймворком Molformer. Преимущество данного слоя заключается в конкатенации тензора извлеченных паттернов с исходными данными. По этой же причине мы не могли его использовать на первом этапе извлечения паттернов. Ведь нам необходимо отделить паттерны от представления баров, которые анализируются в параллельной магистрали.
idx++; units = units - bars_to_paattern + 1; CNeuronMotifs *motifs = new CNeuronMotifs(); if(!motifs || !motifs.Init(0, idx, open_cl, window, bars_to_paattern, 1, units, optimization_type, batch) || !cLayers.Add(motifs) ) return false; motifs.SetActivationFunction((ENUM_ACTIVATION)conv.Activation());
Сгенерированные эмбединги паттернов подаются на вход магистрали R-MAT. Как Вы знаете, размер вектора результатов магистрали Transformer равен тензору исходных данных. Следовательно, на данном этапе мы можем вызвать метод инициализации базового нейронного слоя, указав величину буфера результатов по размеру последнего слоя извлечения паттернов.
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, motifs.Neurons(), optimization_type, batch)) return false; cLayers.SetOpenCL(OpenCL);
А затем создадим цикл инициализации внутренних слоев нашего декодера. На каждой итерации цикла мы будем последовательно инициализировать по одному слою относительного Self-Attention (CNeuronRelativeSelfAttention) и сверточного блока с остаточной связью (CResidualConv).
CNeuronRelativeSelfAttention *attention = NULL; CResidualConv *ff = NULL; units = int(motifs.Neurons() / window); for(uint i = 0; i < layers; i++) { idx++; attention = new CNeuronRelativeSelfAttention(); if(!attention || !attention.Init(0, idx, OpenCL, window, window_key, units, heads, optimization, iBatch) || !cLayers.Add(attention) ) { delete attention; return false; } idx++; ff = new CResidualConv(); if(!ff || !ff.Init(0, idx, OpenCL, window, window, units, optimization, iBatch) || !cLayers.Add(ff) ) { delete ff; return false; } }
Точно такой же цикл мы создавали в методе инициализации родительского класса. Однако в данном случае мы не могли воспользоваться указанным методом родительского класса, так как он удалил бы созданные ранее слои экстракции паттернов.
И теперь нам остается осуществить подмену указателей на буфера данных, чтобы исключить излишние операции копирования.
if(!SetOutput(ff.getOutput()) || !SetGradient(ff.getGradient())) return false; //--- return true; }
А перед завершением работы метода мы возвращаем логический результат выполнения операций вызывающей программе.
Как уже было сказано ранее, функционал прямого и обратного проходов мы полностью унаследовали от родительского класса. Поэтому мы завершаем работу с классом магистрали паттернов CNeuronMotifEncoder.
2.2 Модуль относительного Cross-Attention
Выше для организации магистралей баров и паттернов мы воспользовались модулями относительного Self-Attention. Однако в Декодере с AMCT используется модуль кросс-внимания. Поэтому для создания целостной и согласованной архитектуры фреймворка нам предстоит построить объект Cross-Attention с относительным кодированием. Мы не будем сейчас останавливаться на теоретическом описании используемых подходов. Все они были представлены в статье, посвященной фреймворку R-MAT. Нам лишь предстоит интегрировать в реализованное ранее решение второй источник исходных данных, из которого будут формироваться сущности Key и Value. Для выполнения этой задачи мы создадим класс CNeuronRelativeCrossAttention, в котором реализуем механизм кросс-внимания с относительным кодирование. Как не сложно догадаться, в качестве родительского мы будем использовать класс соответствующего Self-Attention. Структура нового объекта представлена ниже.
class CNeuronRelativeCrossAttention : public CNeuronRelativeSelfAttention { protected: uint iUnitsKV; //--- CLayer cKVProjection; //--- //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronRelativeCrossAttention(void) {}; ~CNeuronRelativeCrossAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_kv, uint units_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRelativeCrossAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Здесь мы видим уже привычный набор переопределяемых методов и объявляем один динамический массив для записи указателей дополнительных объектов. Кроме того, мы добавляем переменную, для записи размера последовательности во втором источнике исходных данных.
Инициализация всех унаследованных и объявленных объектов, как всегда, осуществляется в методе Init.
bool CNeuronRelativeCrossAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_kv, uint units_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
В параметрах данного метода мы получаем все необходимы константы, позволяющие однозначно интерпретировать архитектуру создаваемого объекта. А в теле метода сразу вызываем одноименный метод базового класса нейронных слоев, в котором организована проверка части полученных параметров и инициализация унаследованных интерфейсов.
Мы намеренно не используем метод инициализации прямого родительского класса, так как размер большей части унаследованных от него объектов будет отличаться. А необходимость выполнение повторных операций не только не уменьшит наш труд, но и увеличит время выполнения программы. Поэтому в теле данного метода мы дополнительно осуществим инициализацию объектов, объявленных в родительском классе.
После успешного выполнения метода базового класса мы сохраняем полученные от внешней программы константы архитектуры нашего объекта во внутренние переменные.
iWindow = window; iWindowKey = window_key; iUnits = units_count; iUnitsKV = units_kv; iHeads = heads;
А затем, согласно архитектуре Transformer мы инициализируем сверточные слои генерации сущностей Query, Key и Value.
int idx = 0; if(!cQuery.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; idx++; if(!cKey.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnitsKV, 1, optimization, iBatch)) return false; idx++; if(!cValue.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnitsKV, 1, optimization, iBatch)) return false;
Обратите внимание, что для слоев формирования сущностей Key и Value мы используем размер последовательности второго источника данных. При этом размер вектора описания одного элемента последовательности мы берем от первого источника данных. Однако размер вектора описания одного элемента последовательности во втором источнике данных может отличаться. И, в действительности, ранее мы не занимались вопросов выравнивания размеров исходных последовательностей, а просто использовали разные окна слоев генерации сущностей, выравнивая лишь размер соответствующих эмбедингов. Только вот в алгоритме относительного кодирования используется расстояние между объектами, которое можно определить лишь для объектов, находящихся в одном подпространстве. Следовательно, для анализа нам необходимы соизмеримые объекты. И чтобы не ограничивать область применения модуля, мы воспользуемся механизмом обучаемой проекции данных. Но к этому вопросу вернемся позже, а сейчас просто обращаем на это внимание.
Как и при реализации алгоритма относительного Self-Attention, в качестве меры расстояния между объектами мы воспользуемся произведением двух матриц исходных данных. Но сначала нам предстоит транспонировать одну из них.
idx++; if(!cTranspose.Init(0, idx, OpenCL, iUnits, iWindow, optimization, iBatch)) return false;
И создадим объект для записи результатов матричного умножения.
idx++; if(!cDistance.Init(0, idx, OpenCL, iUnits * iUnitsKV, optimization, iBatch)) return false;
Далее организуем процесс генерации тензоров BK и BV. Напомню, что для их генерации используется MLP с одним скрытым слоем. Скрытый слой общий для всех голов внимания, а последний слой генерирует отдельные токены для каждой головы внимания. Здесь мы для каждой сущности создадим по два последовательных сверточных слоя с гиперболическим тангенсом между ними для создания нелинейности.
idx++; CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iUnits, iUnits, iWindow, iUnitsKV, 1, optimization, iBatch) || !cBKey.Add(conv)) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnitsKV, 1, optimization, iBatch) || !cBKey.Add(conv)) return false;
idx++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iUnits, iUnits, iWindow, iUnitsKV, 1, optimization, iBatch) || !cBValue.Add(conv)) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnitsKV, 1, optimization, iBatch) || !cBValue.Add(conv)) return false;
И добавим ещё 2 MLP генерации векторов глобального смещения контекста и позиции. Первый слой каждой из них статичен и содержит "1", а второй обучаемый и генерирует необходимый тензор. Указатели на создаваемые объекты мы сохраним в массивах cGlobalContentBias и cGlobalPositionalBias.
idx++; CNeuronBaseOCL *neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(iWindowKey * iHeads * iUnits, idx, OpenCL, 1, optimization, iBatch) || !cGlobalContentBias.Add(neuron)) return false; idx++; CBufferFloat *buffer = neuron.getOutput(); buffer.BufferInit(1, 1); if(!buffer.BufferWrite()) return false; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cGlobalContentBias.Add(neuron)) return false;
idx++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(iWindowKey * iHeads * iUnits, idx, OpenCL, 1, optimization, iBatch) || !cGlobalPositionalBias.Add(neuron)) return false; idx++; buffer = neuron.getOutput(); buffer.BufferInit(1, 1); if(!buffer.BufferWrite()) return false; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cGlobalPositionalBias.Add(neuron)) return false;
Этим мы завершаем работу по подготовке объектов предварительной обработки исходных данных нашего модуля относительного кросс-внимания. И переходим к объектам обработки результатов кросс-внимания. На этом этапе мы вначале создаем объект записи результатов многоголового внимания и добавим его указатель в массив cMHAttentionPooling.
idx++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cMHAttentionPooling.Add(neuron) ) return false;
А затем добавим объект пулинга на основе зависимостей. В нем осуществляется переход от результатов многоголового внимания к их взвешенной сумме. Коэффициенты влияния определяются индивидуально для каждого элемента последовательности на основе анализа зависимостей.
CNeuronMHAttentionPooling *pooling = new CNeuronMHAttentionPooling(); if(!pooling || !pooling.Init(0, idx, OpenCL, iWindowKey, iUnits, iHeads, optimization, iBatch) || !cMHAttentionPooling.Add(pooling) ) return false;
Здесь стоит обратить внимание, что размер вектора описания одного элемента последовательности на выходе слоя пулинга будет равен внутренней размерности, которая может отличаться от длины вектора описания одного объекта в исходной последовательности. Поэтому мы добавляем ещё MLP масштабирования результатов до уровня исходных данных. В ней мы используем 2 сверточных слоя с LReLU между ними для создания нелинейности.
//--- idx++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindowKey, iWindowKey, 4 * iWindow, iUnits, 1, optimization, iBatch) || !cScale.Add(conv) ) return false; conv.SetActivationFunction(LReLU); idx++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iUnits, 1, optimization, iBatch) || !cScale.Add(conv) ) return false; conv.SetActivationFunction(None);
После чего осуществим подмену указателя на буфер градиентов ошибки в интерфейсах обмена данными с другими нейронными слоями нашей модели.
//--- if(!SetGradient(conv.getGradient(), true)) return false;
А теперь вернемся к вопросу об отличиях размерностей в источниках исходных данных. В нашем модуле кросс-вниммания первый источник данных используется для формирования сущности Query и является основной для формирования магистрали. Он же используется в качестве остаточных связей. Поэтому его размерность остается неизменной. Следовательно, для выравнивания размерностей обоих источников исходных данных мы будем осуществлять проекцию значений второго источника исходных данных. Для организации обучаемой проекции данных мы создадим два последовательных нейронных слоя, указатели на которые добавим в массив cKVProjection. Первый слой будет полносвязный. Он предназначен для хранения исходные данные из второго источника.
cKVProjection.Clear(); cKVProjection.SetOpenCL(OpenCL); idx++; neuron = new CNeuronBaseOCL; if(!neuron || !neuron.Init(0, idx, OpenCL, window_kv * iUnitsKV, optimization, iBatch) || !cKVProjection.Add(neuron) ) return false;
Второй сверточный слой будет выполнять проекцию данных в нужное подпространство.
idx++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, window_kv, window_kv, iWindow, iUnitsKV, 1, optimization, iBatch) || !cKVProjection.Add(conv) ) return false;
Теперь, после инициализации всех объектов, необходимых нам для выполнения заданного функционал, мы вернем логический результат выполнения операций вызывающей программе и завершим работу метода.
//--- SetOpenCL(OpenCL); //--- return true; }
После завершения работы по инициализации нового экземпляра объекта мы переходим к построению алгоритмов прямого прохода, которые реализуем в методе feedForward. Здесь стоит сразу обратить внимание, что для выполнения алгоритма нам требуется 2 источника исходных данных. Поэтому унаследованный от родительского класса метод с одним объектом исходных данных мы переопределяем с постоянным результатом false, который сигнализируем об ошибочном вызове некорректного метода. А корректный алгоритм построим в методе с двумя объектами исходных данных.
bool CNeuronRelativeCrossAttention::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { CNeuronBaseOCL *neuron = cKVProjection[0]; if(!neuron || !SecondInput) return false; if(neuron.getOutput() != SecondInput) if(!neuron.SetOutput(SecondInput, true)) return false;
В теле метода мы проверяем корректность указателя на объект второго источника исходных данных. И, при необходимости, передадим указатель на него в первый слой модели проекции данных, указатели на которую сохранены в массиве cKVProjection. После чего организуем цикл последовательного перебора всех слоем модели проекции данных. В теле цикла мы будем вызывать методы прямого прохода каждого слоя, а в качестве исходных данных будем использовать результаты предыдущего нейронного слоя.
for(int i = 1; i < cKVProjection.Total(); i++) { neuron = cKVProjection[i]; if(!neuron || !neuron.FeedForward(cKVProjection[i - 1]) ) return false; }
После успешного осуществления проекции исходных данных из второго источника мы переходим к генерированию сущностей Query, Key и Value. При этом Query генерируем из исходных данных первого источника. А для Key и Value используем результаты проведенной выше проекции данных второго источника.
if(!cQuery.FeedForward(NeuronOCL) || !cKey.FeedForward(neuron) || !cValue.FeedForward(neuron) ) return false;
Далее нам предстоит вычислить коэффициенты расстояний между объектами. Для этого мы сначала транспонируем данные из первого источника. А затем умножим результаты проекции исходных данных из второго источника на транспонированные данные первого.
if(!cTranspose.FeedForward(NeuronOCL) || !MatMul(neuron.getOutput(), cTranspose.getOutput(), cDistance.getOutput(), iUnitsKV, iWindow, iUnits, 1) ) return false;
На основании полученных коэффициентов структуры данных мы сформируем тензоры смещений BK и BV. Сначала мы передадим информацию о структуре данных в методы прямого прохода первых слоев соответствующих моделей.
if(!((CNeuronBaseOCL*)cBKey[0]).FeedForward(cDistance.AsObject()) || !((CNeuronBaseOCL*)cBValue[0]).FeedForward(cDistance.AsObject()) ) return false;
А затем организуем циклы перебора слоев указанных моделей с последовательным вызовом методов прямого прохода вложенных нейронных слоев.
for(int i = 1; i < cBKey.Total(); i++) if(!((CNeuronBaseOCL*)cBKey[i]).FeedForward(cBKey[i - 1])) return false;
for(int i = 1; i < cBValue.Total(); i++) if(!((CNeuronBaseOCL*)cBValue[i]).FeedForward(cBValue[i - 1])) return false;
Далее мы организуем генерацию сущностей глобального смещения. Здесь мы организуем аналогичные циклы.
for(int i = 1; i < cGlobalContentBias.Total(); i++) if(!((CNeuronBaseOCL*)cGlobalContentBias[i]).FeedForward(cGlobalContentBias[i - 1])) return false; for(int i = 1; i < cGlobalPositionalBias.Total(); i++) if(!((CNeuronBaseOCL*)cGlobalPositionalBias[i]).FeedForward(cGlobalPositionalBias[i - 1])) return false;
На этом мы завершаем операции предварительной обработке исходных данных и передаем результаты проделанной работы в модуль внимания.
if(!AttentionOut()) return false;
Результаты многоголового кросс внимания мы пропускаем через модель пулинга.
for(int i = 1; i < cMHAttentionPooling.Total(); i++) if(!((CNeuronBaseOCL*)cMHAttentionPooling[i]).FeedForward(cMHAttentionPooling[i - 1])) return false;
И масштабируем до размера тензора первого источника исходных данных. Данный функционал выполняется внутренней моделью масштабирования.
if(!((CNeuronBaseOCL*)cScale[0]).FeedForward(cMHAttentionPooling[cMHAttentionPooling.Total() - 1])) return false; for(int i = 1; i < cScale.Total(); i++) if(!((CNeuronBaseOCL*)cScale[i]).FeedForward(cScale[i - 1])) return false;
Теперь нам остается лишь добавить остаточные связи. Результаты операции запишем в буфер интерфейса обмена данными с последующим нейронным слоем модели.
if(!SumAndNormilize(NeuronOCL.getOutput(), ((CNeuronBaseOCL*)cScale[cScale.Total() - 1]).getOutput(), Output, iWindow, true, 0, 0, 0, 1)) return false; //--- return true; }
И перед завершением работы метода мы вернем логический результат выполнения операций вызывающей программе.
После построения метода прямого прохода мы переходим к реализации алгоритмов обратного прохода. Как Вы знаете, операции обратного прохода мы делим на 2 этапа. Распределение градиентов ошибки до всех участников процесса в соответствии с их влиянием на конечный результат осуществляется в методе calcInputGradients. И оптимизация параметров модели в сторону снижения ошибки работы модели организована в методе updateInputWeights. Алгоритм последнего ничем не примечателен. В нем лишь осуществляется последовательный вызов одноименных методов вложенных объектов, содержащих обучаемые параметры. А вот алгоритм первого предлагаю рассмотреть подробнее.
В параметрах метода распределения градиентов ошибки calcInputGradients мы получаем указатели на 2 объекта исходных данных с буферами для записи соответствующих градиентов ошибки.
bool CNeuronRelativeCrossAttention::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondGradient) return false;
В теле метода мы проверяем актуальность полученных указателей. В противном случае все дальнейшие операции теряют смысл.
Здесь следует вспомнить, что в рамках операций прямого прохода мы сохранили указатель на буфер второго источника исходных данных во внутреннем слое. Мы проводим аналогичные операции для соответствующего буфера градиентов ошибки и тут же синхронизируем функции активации.
CNeuronBaseOCL *neuron = cKVProjection[0]; if(!neuron) return false; if(neuron.getGradient() != SecondGradient) if(!neuron.SetGradient(SecondGradient)) return false; if(neuron.Activation() != SecondActivation) neuron.SetActivationFunction(SecondActivation);
На этом подготовительная работа закончена и переходим к непосредственному распределению градиента ошибки до всех участников процесса в соответствии с их влиянием на конечный результат.
Напомню, что при инициализации нашего объекта мы организовали подмену указателя на буфер градиентов ошибки. Поэтому, работу по распределению градиентов ошибки начинаем сразу с внутренними объектами. И здесь следует вспомнить о том, авторы метода AMCT предложили контрастное обучение для мотивов. Следуя этой логике, мы добавим ошибку диверсификации на уровне результатов нашего блока кросс-внимания.
if(!DiversityLoss(AsObject(), iUnits, iWindow, true)) return false;
Следует понимать, что добавляя ошибку диверсификации к результатам блока кросс-внимания мы, конечно, стремимся максимально распределить в подпространстве именно результаты, передаваемые в последующие нейронные слои модели. В то же время, распределяя градиент ошибки вниз по объектам модели, мы косвенным образом разделяем и объекты анализируемых исходных данных, поступающие в наш блок из обоих источников.
Далее общий градиент ошибки мы сначала проводим через внутреннюю модель масштабирования результатов.
for(int i = cScale.Total() - 2; i >= 0; i--) if(!((CNeuronBaseOCL*)cScale[i]).calcHiddenGradients(cScale[i + 1])) return false; if(!((CNeuronBaseOCL*)cMHAttentionPooling[cMHAttentionPooling.Total() - 1]).calcHiddenGradients(cScale[0])) return false;
Затем распределим по головам внимания средствами модели пулинга.
for(int i = cMHAttentionPooling.Total() - 2; i > 0; i--) if(!((CNeuronBaseOCL*)cMHAttentionPooling[i]).calcHiddenGradients(cMHAttentionPooling[i + 1])) return false;
А в методе AttentionGradient мы доведем градиент ошибки до сущностей Query, Key, Value и тензоров смещения, в соответствии с их влиянием на конечный результат.
if(!AttentionGradient()) return false;
Далее мы распределим градиент ошибки по внутренним моделям обучаемых глобальных смещений путем обратного перебора их нейронных слоев.
for(int i = cGlobalContentBias.Total() - 2; i > 0; i--) if(!((CNeuronBaseOCL*)cGlobalContentBias[i]).calcHiddenGradients(cGlobalContentBias[i + 1])) return false; for(int i = cGlobalPositionalBias.Total() - 2; i > 0; i--) if(!((CNeuronBaseOCL*)cGlobalPositionalBias[i]).calcHiddenGradients(cGlobalPositionalBias[i + 1])) return false;
Аналогичным образом проведем градиент ошибки через модели генерации сущностей смещения на основе структуры объектов BK и BV.
for(int i = cBKey.Total() - 2; i >= 0; i--) if(!((CNeuronBaseOCL*)cBKey[i]).calcHiddenGradients(cBKey[i + 1])) return false; for(int i = cBValue.Total() - 2; i >= 0; i--) if(!((CNeuronBaseOCL*)cBValue[i]).calcHiddenGradients(cBValue[i + 1])) return false;
И далее до матрицы структуры данных cDistance. Только здесь есть нюанс. Матрицу структуры мы использовали для генерации обеих сущностей и градиент ошибки необходимо собрать из двух потоков информации. Поэтому мы сначала получим градиент ошибки от BK.
if(!cDistance.calcHiddenGradients(cBKey[0])) return false;
А затем подменим указатель на буфер градиентов ошибки данного объекта и возьмем градиент от BV. После чего суммируем градиенты ошибки от обеих моделей и вернем указатели на буферы данных в исходное состояние.
CBufferFloat *temp = cDistance.getGradient(); if(!cDistance.SetGradient(GetPointer(cTemp), false) || !cDistance.calcHiddenGradients(cBValue[0]) || !SumAndNormilize(temp, GetPointer(cTemp), temp, iUnits, false, 0, 0, 0, 1) || !cDistance.SetGradient(temp, false) ) return false;
Градиент ошибки собранный на матрице структуры распределим между объектами исходных данных. Только в данном случае мы распределяем не на прямую, а через слой транспонирования первого источника исходных данных и модель проекции второго источника.
neuron = cKVProjection[cKVProjection.Total() - 1]; if(!neuron || !MatMulGrad(neuron.getOutput(), neuron.getGradient(), cTranspose.getOutput(), cTranspose.getGradient(), temp, iUnitsKV, iWindow, iUnits, 1) ) return false;
Из слоя транспонирования мы передадим градиент ошибки до уровня первого источника исходных данных. И сразу суммируем полученные значения с градиентом ошибки от потока остаточных связей. Результат операции запишем в буфер градиентов слоя транспонирования данных. Он идеально подходит нам по размеру, а записанные в нем ранее значения мы можем безболезненно удалить.
if(!NeuronOCL.calcHiddenGradients(cTranspose.AsObject()) || !SumAndNormilize(NeuronOCL.getGradient(), Gradient, cTranspose.getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
Затем вычислим градиент ошибки на уровне первого источника исходных данных, получаемый от сущности Query, и добавим его к ранее накопленным данным. Только на этот раз результаты суммирования мы сохраним в буфере градиентов ошибки исходных данных.
if(!NeuronOCL.calcHiddenGradients(cQuery.AsObject()) || !SumAndNormilize(NeuronOCL.getGradient(), cTranspose.getGradient(), NeuronOCL.getGradient(), iWindow, false, 0, 0, 0, 1) || !DiversityLoss(NeuronOCL, iUnits, iWindow, true) ) return false;
И добавим к ним ошибку диверсификации.
На этом мы завершаем работу по распределению градиента ошибки до первого источника исходных данных и переходим к работе со вторым потоком информации.
Напомню, что ранее мы уже сохранили в буфере последнего слоя внутренней модели проекции второго источника исходных данных градиент ошибки от матрицы структуры. И теперь нам предстоит добавить к нему градиент ошибки от сущностей Key и Value. Для этого мы сначала осуществим подмену буфера градиентов ошибки в объекте-получателе информации. А затем последовательно осуществим вызов метода распределения градиентов ошибки от соответствующих сущностей с промежуточным добавлением результатов операций к ранее накопленным значения.
temp = neuron.getGradient(); if(!neuron.SetGradient(GetPointer(cTemp), false) || !neuron.calcHiddenGradients(cKey.AsObject()) || !SumAndNormilize(temp, GetPointer(cTemp), temp, iWindow, false, 0, 0, 0, 1) || !neuron.calcHiddenGradients(cValue.AsObject()) || !SumAndNormilize(temp, GetPointer(cTemp), temp, iWindow, false, 0, 0, 0, 1) || !neuron.SetGradient(temp, false) ) return false;
И теперь нам достаточно осуществить обратный перебор слоев модели проекции с последовательной передачей градиентов ошибки вниз по модели.
for(int i = cKVProjection.Total() - 2; i >= 0; i--) { neuron = cKVProjection[i]; if(!neuron || !neuron.calcHiddenGradients(cKVProjection[i + 1])) return false; } //--- return true; }
Следует отметить, что благодаря замене указателя на буфер градиентов ошибки в первом слое модели объектом, полученным от внешней программы в параметрах метода, мы исключили необходимость копирования данных. Таким образом, при передаче градиентов ошибки на уровень первого слоя модели, они автоматически записываются в буфер данных, предоставленный внешней программой.
Нам остается лишь вернуть логический результат выполнения операций внешней программе и завершить работу метода.
На этом мы завершаем рассмотрение методов объекта относительного кросс-внимания CNeuronRelativeCrossAttention. А с полным кодом данного класса и всех его методов Вы можете ознакомиться во вложении.
К сожалению, мы подошли к пределу объема этой статьи, не завершив нашу работу. Поэтому мы сделаем короткий перерыв и продолжим в следующей статье.
Заключение
В данной статье мы познакомились с фреймворком Atom-Motif Contrastive Transformer (AMCT), основанном на концепциях атомарных элементов (свечей) и мотивов (паттернов). Главная идея метода заключается в использовании контрастного обучения модели с целью выделения информативных и неинформативных паттернов на различных уровнях: от базовых элементов до сложных структур. Это позволяет модели не только учитывать локальные особенности рыночных движений, но и улавливать важные паттерны, которые могут предоставить дополнительную информацию для качественного прогнозирования будущего поведение рынка. Transformer-архитектура, будучи основой метода, эффективно захватывает долгосрочные зависимости и сложные взаимосвязи между свечами и паттернами.
В практической части мы начали реализацию предложенных подходов средствами MQL5. Однако объем работы превысил размеры одной статьи. Но мы продолжим начатую работу в следующей статье. И в ней оценим практические результаты, которые позволяет достичь предложенный фреймворк на реальных исторических данных.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.


 После решения ошибки компиляции, появилась ошибка тестера, вся голова сгорела, не могу понять, где решить проблему
После решения ошибки компиляции, появилась ошибка тестера, вся голова сгорела, не могу понять, где решить проблему
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования