
初級から中級まで:配列(III)

はじめに
前回の「初級から中級まで:配列(II)」では、動的配列と静的配列の使い方、その違い、アプリケーションで配列を使用する際の基本的な注意点について説明しました。
今回はその続きとして、配列の応用的な使用方法をさらに掘り下げていきます。本記事を理解するためには、前回までに扱った配列の基本的な概念に加え、値渡し(pass by value)と参照渡し(pass by reference)の仕組みについてもしっかり理解していることが前提です。これらの内容はすでに以前の記事で扱っているので、もし不安がある、あるいはこれらの概念にまだ触れていないという場合には、先に前の記事を復習することをおすすめします。そのほうが、本記事の説明をよりスムーズに理解できるでしょう。
いつものように、新しいセクションを始めて、学習と実演を続けていきましょう。
関数と手続きでの配列の使用
配列を使って関数や手続き間で値を渡す方法は、初心者がよく戸惑うテーマの1つです。ここで1つはっきりさせておきたいのは、MQL5におけるこの扱い方は、他の言語でのそれよりもずっとシンプルだということです。
たとえば、CやC++のような言語はこの点で非常に複雑です。これらの言語には、MQL5のような「真の配列構造」は存在せず、代わりに「ポインタ」と呼ばれる別の構造を使います。ポインタの難しさは、間接参照を使えるために生じます。この機能はプログラマに強力な自由度を与える一方で、コードの理解を非常に難しくしてしまいます。特に、コーディングやポインタの経験が浅い人にとってはなおさらです。
一方で、MQL5はずっと理解しやすく、適用も簡単です。まず押さえておきたいのは、
MQL5では、配列は関数でも手続きでも必ず「参照渡し」で渡される
ということです。つまり、配列を引数として使う場合に「値渡し」は存在しません。
ここで、配列の引数がすべて参照渡しだったら、安全性が下がるのではと思われるかもしれません。ところが、そうではありません。驚くかもしれませんが、MQL5での配列の使用は、他の変数タイプを使うよりもむしろ安全なのです。
実際のところ、MQL5で配列を使うのは、他の多くのプログラミング言語で使われるあらゆる手法よりもずっと簡単であると断言してもいいと思います。これは、MQL5では常に参照渡しであっても、プログラマが配列に対して何ができて何ができないかを完全にコントロールできるからです。
この安全性と信頼性を支えているのは、実際にはプログラマの細心の注意です。以前、値渡しと参照渡しのメリット・デメリットを説明した際にも述べましたが、ここではもっとシンプルです。関数や手続きの宣言自体が、その扱いを明確に示しています。
もう一つ押さえておくべき重要なポイントがあります。それは
関数や手続きのパラメータとして宣言される配列は、必ず「動的配列」でなければならない
ということです。これら2つの原則を守れば、MQL5において配列を使ったあらゆる実装をおこなうことが可能です。多くの場合、コードをインラインで書くよりも、関数や手続き内で計算をおこなうほうが実用的かつ適切です。
補足として、「インラインコード」という言葉に馴染みのない方のために説明すると、これはプログラマが関数や手続きを一切使わずに、長いレシピを順に実行するかのように処理を直接書き込んでいくスタイルを指します。この手法が適用されることは稀ですが、完全に関数や手続きが存在しない実装も実際にはあります。
さて、話を元に戻しましょう。配列を関数や手続きのパラメータとして使う方法です。一見シンプルに思えますが、決して油断せず、すべてが簡単でリスクなしだと考えないでください。
実際には、実践してみて初めて気づく微妙なポイントがいくつか存在します。理論的には理解すべき概念は少なく綺麗にまとまっていますが、実際には時に厄介な問題に遭遇し、それを乗り越えるまで苦労することもあります。では、実際にどのように動くのか、以下のコードから見ていきましょう。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const char Infos[] = {2, 3, 3, 5, 8}; 07. 08. Print("Based on the values:"); 09. ArrayPrint(Infos); 10. PrintFormat("There are %d possibilities.", Possibilities(Infos)); 11. } 12. //+------------------------------------------------------------------+ 13. ushort Possibilities(const uchar &arg[]) 14. { 15. ushort info = 0; 16. 17. for (uchar c = 0; c < arg.Size(); c++) 18. info = (c ? info * arg[c] : arg[c]); 19. 20. return info; 21. } 22. //+------------------------------------------------------------------+
コード01
コード01を実行すると、下の画像のような結果が表示されます。
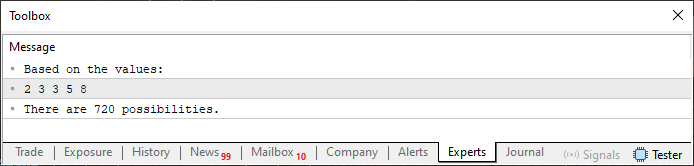
図01
図01に示されている内容は、実はさまざまな方法で生成可能です。コード01で使われている方法は、あくまでも教育的な目的のためのものです。ここでの狙いは、出力結果の中身を正しく理解してもらい、関数や手続きに配列を渡す方法を示すことにあります。
では、具体的に何が起きているのかを分解して見ていきましょう。これまでの記事で触れていない部分だけに絞って説明します。まずは6行目から見ていきます。ここでは静的配列を使っていますが、これは単にコードを簡略化するための手段です。実際には動的配列を使っても動作に違いはありません。重要なのは、13行目で宣言された関数に配列の値を渡すことです。つまり、コード01の10行目以前の処理は、関数への配列の渡し方には影響しません。ただし、関数が13行目のように宣言されている場合に限ります。
ここで特に注意してほしい点があります。以前の記事で、定数として宣言された配列は、宣言時に必ず初期化が必要だと説明しました。これはコンパイルエラーを防ぐためです。しかし、13行目をよく見ると、そこでも配列を定数として宣言していますが、コンパイラは問題なく実行ファイルを生成しています。
なぜ6行目のケースでは初期化が必要なのに、13行目では許されるのでしょうか。その理由は、13行目では配列が変数ではなくパラメータとして宣言されている点にあります。先に説明したように、MQL5では配列は必ず参照渡しされるため、ここでの定数宣言は意味合いが異なります。
特に初心者の方にありがちな誤解として、13行目で宣言されている配列が、6行目の配列のせいで定数として宣言されているのではないと誤って考えてしまう方がいるかもしれませんが、両者は全く別の文脈です。6行目の配列を完全に動的配列にしても、13行目のパラメータ宣言は変わりません。目的と意味合いがまったく異なるからです。
さらにコード01には、以前も触れたことがありますが、ここで改めて強調したいポイントがあります。17行目のテスト値です。ここではarg.Size()を使っていますが、これは ArraySize関数を使った場合と同様に許される有効な書き方です。どちらの場合でも、配列のサイズチェックは同じ方法でおこなわれます。宿題として、arg.Size()をArraySizeに置き換えてみて、実際にどのように動くか試してみてください。
以上のように、今回の概要は比較的わかりやすく、関数や手続きに配列を渡す実装例のイメージがつかめたのではないかと思います。この特定の文脈で配列をパラメータとして扱う方法や宣言の仕方は変わりません。変わるのは、使う目的だけです。
ここまでは比較的簡単な部分でした。これからもう少し複雑な話題に進みますが、1つずつ丁寧に理解できるように、新しいセクションを設けて解説を続けていきます。
配列のリモート修正
関数や手続きで配列を扱う際に、やや複雑になるケースのひとつが、配列の中身をリモートで変更できることです。つまり、配列を引数として渡し、その関数や手続きの中で内容を書き換えるということです。この動作は、時に非常に混乱を招き、問題の解決を難しくする場合があります。しかし、こうした操作は必要になることが多いため、何が起きているのかを完全に理解することが重要です。まずは、この現象がなぜ起こるのかを理解しましょう。
char、int、long、doubleといった単一の値を扱う型とは異なり、ほとんどのプログラミング言語では、配列をそのまま返すことはできません 。ただし、その言語自体が特別な仕組みを提供している場合を除きます。MQL5の場合、その例外の1つが文字列(string)です。
前回の記事で示した通り、文字列は実質的に特殊な配列の一種です。これにより、MQL5では関数から配列を返せる数少ないケースのひとつとなっています。この機能のおかげで、配列の内容を変更して返す必要がある特定の実装においても、リスクや問題が軽減されています。
しかし、実際のコードでこのテーマを深掘りする前に、他言語でこの問題がどのように扱われているかを見ておく必要があります。たとえばCやC++では、この責任は完全にプログラマに委ねられています。これらの言語では、配列の中身を書き換えることも、新たに配列を生成して返すことも可能です。ただし、この自由度があるからといってミスが減るわけではありません。むしろ、より複雑なバグを生みやすくしており、CやC++が習得困難な理由の1つとなっています。
一方、PythonやJavaScriptなどの言語は、従来の配列型の使用をある程度回避し、配列を返したり修正したりする独自のメソッドを備えています。このため、こうした言語ではリファクタリングがやや容易な場合もあります。しかし、ここでの焦点はあくまでMQL5です。
では、まず最も簡単な例から始めましょう。コード01を少しだけ修正したものが以下の通りです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. char Infos[] = {2, 3, 3, 5, 8}; 07. 08. Print("Based on the values:"); 09. ArrayPrint(Infos); 10. PrintFormat("There are %d possibilities.\nValue after call:", Possibilities(Infos)); 11. ArrayPrint(Infos); 12. } 13. //+------------------------------------------------------------------+ 14. ushort Possibilities(uchar &arg[]) 15. { 16. ushort info = 0; 17. 18. for (uchar c = 0; c < arg.Size(); c++) 19. info = (c ? info * arg[c] : arg[c]); 20. 21. arg[0] += 2; 22. 23. return info; 24. } 25. //+------------------------------------------------------------------+
コード02
コード02を実行すると、以下のような結果が得られます。
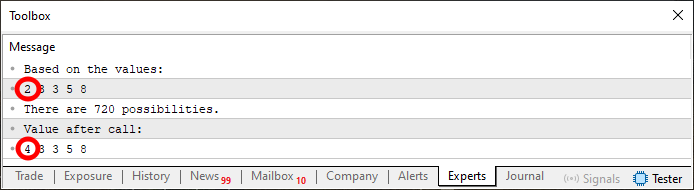
図02
図02では、2つの値を強調表示しています。これは、ここで何が起こっているのかに注意を向けてもらうためです。
コード02とコード01の違いは、14行目の関数のパラメータ宣言がもはや定数ではないという点にあります。したがって、MQL5において常に発生する参照渡しのメカニズムによって、6行目で宣言された配列の要素が、21行目で関数内から変更されることが可能になります。
今回は学習目的のコードで、MQL5に適用できる概念の説明に焦点を当てているため、この変更点は比較的分かりやすくなっています。しかし、実際の現場のコードでは、こうした変更はより深く入り組んでいて、あまりに複雑に絡み合っているため、一から書き直したくなるほど手に負えなくなることもしばしばです。
だからこそ、特にプログラミングを始めたばかりの方や、まだ経験が浅い方には、ぜひこれらの概念を何度も練習することをお勧めします。練習を重ねることでしか、将来必ず直面する問題に対処できる経験は得られません。
さて、コード02は実にシンプルで、ある意味ほとんど入門的な例です。しかし、このトピックをさらに深掘りしていくと、徐々にややこしくなっていきます。というわけで、次はもう少し複雑な例を見ていきましょう。すぐ下に掲載しています。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. char Infos[]; 07. 08. ArrayResize(Infos, 7); 09. ZeroMemory(Infos); 10. 11. Infos[0] = 2; 12. Infos[1] = 3; 13. Infos[2] = 3; 14. Infos[3] = 5; 15. Infos[4] = 8; 16. 17. Print("Based on the values:"); 18. ArrayPrint(Infos); 19. PrintFormat("There are %d possibilities.\nValue after call:", Possibilities(Infos)); 20. ArrayPrint(Infos); 21. 22. ArrayFree(Infos); 23. } 24. //+------------------------------------------------------------------+ 25. ushort Possibilities(uchar &arg[]) 26. { 27. ushort info = 0; 28. 29. for (uchar c = 0; c < arg.Size(); c++) 30. info = (c ? (arg[c] ? info * arg[c] : info) : arg[c]); 31. 32. arg[arg.Size() - 1] = 9; 33. 34. return info; 35. } 36. //+------------------------------------------------------------------+
コード03
さて、コード03では、少しだけ複雑な状況が出てきます。しかし、この複雑さは30行目に起因するものではありません。30行目自体は非常にシンプルで、理解しやすい部分です。
コード03が少し難しく感じられるのは、6行目で純粋な動的配列を宣言しているからです。ここからが、初心者にとって本格的にややこしさを感じるポイントになってきます。とはいえ、このコード03も、本連載を順を追って読んで練習してきた初心者であれば、完全に理解可能な内容です。焦らず、一つひとつのステップを確実にこなしてきた読者であれば、難なく乗り越えられるはずです。
では、コード03の実行結果を見てみましょう。下の画像に示されています。
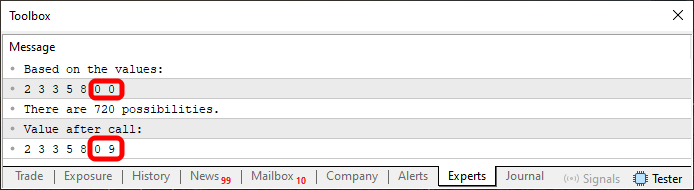
図03
もう一度、図にある情報の一部をハイライトしています。このハイライトされた情報は、今回の内容を完全に理解するために非常に重要です。
では、何が起こっているのかを順を追って説明していきましょう。8行目では、配列の要素数を7に設定しています。次に、11行目から15行目で、その一部の要素に対して初期値を代入しています。18行目で確認できるように、配列の中にはゼロの値が含まれています。これは、9行目で配列のメモリをクリアしているためです。
このゼロの存在こそが、30行目で三項演算子を追加する必要があった理由です。これがなければ、関数の戻り値はゼロになってしまいます。しかし、ここで本当に注目していただきたいのはそこではありません。ここで特に注目すべきなのは32行目です。ここで、特定の要素、つまり今回の場合は配列の最後の要素に値を代入しています。
では、なぜこのようなことをしているのでしょうか。そして、なぜこの一連のデモの流れの中でこの順番なのかというと、それは、MQL5での配列の扱い方には、普通では実現できないような操作を可能にする方法があるからです。そうした操作は、読者である皆さんが配列に関するある種の考え方を理解していなければ、本来なら実現できないものです。同時に、ここで起きていることに注意を向けることで、今後扱っていく他の概念がより自然に感じられるようにもなるでしょう。
さて、ここまでの内容で、すでにかなり高度な要素が加わっています。しかし、ここでもう少しだけ興味深いことをやってみましょう。正直なところ、この記事はここで終わりにして、これまでに示した内容を読者の皆さんに練習してもらうのが理想的だと思っています。そして正直に言えば、ここまでに提示した内容だけでも十分に多く、最初はなかなか理解が難しいこともあるでしょう。とはいえ、最後にもうひとつだけ。ここで紹介する内容は、これまでに扱ってきたことと密接に関連しており、非常に興味深いものです。そして、より複雑な考え方でもあるため、次は新しいセクションに移って話を続けましょう。
リモート初期化
ここで、親愛なる読者の皆さんに次のお願いをしたいと思います。ここまでに扱った内容を一度立ち止まってじっくりと学習してください。すべてを完全に理解し、頭の中に疑問や混乱が一切残っていないこと、そして前のコードたちをしっかりと理解していることを確認してから、初めてこのセクションに進んでください。なぜなら、これから扱う内容は、適切な準備ができていないと対処するにはあまりにも複雑すぎるからです。
これまでに見てきた内容から、配列を使ってデータを送信できることがわかりました。その後、他の関数や手続き内で配列のデータを変更できることも学びました。特に、より複雑なアプリケーションを作成している場合には、この操作には十分な注意が必要です。そして次に、配列のどこを変更するかを調整しながら配列を操作できることも見てきました。では、次は別のことをおこなうときです。それが次のコードで示されています。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. char Infos[]; 07. 08. InitArray(Infos); 09. 10. Print("Based on the values:"); 11. ArrayPrint(Infos); 12. PrintFormat("There are %d possibilities.\nValue after call:", Possibilities(Infos)); 13. ArrayPrint(Infos); 14. 15. ArrayFree(Infos); 16. } 17. //+------------------------------------------------------------------+ 18. void InitArray(uchar &arg[]) 19. { 20. ArrayResize(arg, 7); 21. ZeroMemory(arg); 22. 23. arg[0] = 2; 24. arg[1] = 3; 25. arg[2] = 3; 26. arg[3] = 5; 27. arg[4] = 8; 28. } 29. //+------------------------------------------------------------------+ 30. ushort Possibilities(uchar &arg[]) 31. { 32. ushort info = 0; 33. 34. for (uchar c = 0; c < arg.Size(); c++) 35. info = (c ? (arg[c] ? info * arg[c] : info) : arg[c]); 36. 37. arg[arg.Size() - 1] = 9; 38. 39. return info; 40. } 41. //+------------------------------------------------------------------+
コード04
さて、いよいよ本記事で取り扱う内容のクライマックスに到達しました。しかしながら、コード04の見た目の単純さに惑わされないでください。たしかに、その出力結果は以下に示すとおりですが、その背後にある仕組みは見た目以上にずっと複雑なのです。
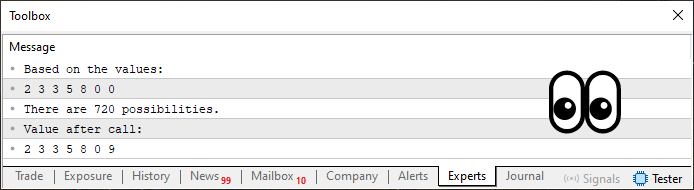
図04
出力結果が、図03で見たものとまったく同じであることに注目してください。完全に一致しています。しかし、コード04では、シンプルに見せかけながらも、扱いを間違えれば非常に複雑になる可能性のあることを示しています。ですが、正しく適切に実装すれば、この方法は多くの問題を解決する力を持っています。とりわけ、いわゆる「経験豊富なプログラマー」たちが「MQL5ではできない」と断言するようなこと、少なくとも純粋な形で、MQL5の標準機能だけでは不可能だとされているようなことを、実際には実現可能にするのです。
ここまで、段階的に変更を加えてきたのは、まさに読者の皆さんがその変化を追いやすいようにするためです。見た目には、コード04はコード03のちょっとしたバリエーションに過ぎないと思われるかもしれません。しかしその実、コード04では、ある重要な概念が根底にあります。それは、ある程度の理解なしには不可能だとされてきたことを実現できる、という事実です。
その概念のひとつが、すべての配列は参照渡しされるという事実です。そしてこの特性を、以前の記事で紹介した概念と組み合わせることによって、宣言されたスコープの外側で配列を初期化または変更するといった、多くの人が不可能だと考えるようなことが、実際には可能なのです。
しかも、ここで取り扱ってきた難易度をこれ以上上げることなく、このアイデアをさらに発展させることができます。次に示すのは、そのためにコード04をわずかに変更した例です。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. char Infos[]; 07. 08. if (ArraySize(Infos)) 09. { 10. Print("Based on the values:"); 11. ArrayPrint(Infos); 12. }else 13. Print("Array has not been initialized yet."); 14. PrintFormat("There are %d possibilities.\nValue after call:", Possibilities(Infos)); 15. ArrayPrint(Infos); 16. 17. ArrayFree(Infos); 18. } 19. //+------------------------------------------------------------------+ 20. void InitArray(uchar &arg[]) 21. { 22. const char init [] = {2, 3, 3, 5, 8}; 23. 24. ArrayCopy(arg, init); 25. } 26. //+------------------------------------------------------------------+ 27. ushort Possibilities(uchar &arg[]) 28. { 29. ushort info = 0; 30. 31. InitArray(arg); 32. 33. for (uchar c = 0; c < arg.Size(); c++) 34. info = (c ? (arg[c] ? info * arg[c] : info) : arg[c]); 35. 36. ArrayResize(arg, arg.Size() + 1); 37. arg[arg.Size() - 1] = 9; 38. 39. return info; 40. } 41. //+------------------------------------------------------------------+
コード05
上記のコード05を実行すると、下の画像のように表示されます。
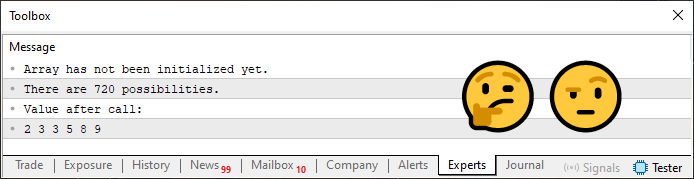
図05
さて、どうしてこのようなことが可能なのか、全然わからないと思っている方もいらっしゃるでしょう。しかし、ここではあくまでも、この記事の最初から見てきたコードを使って、少し遊んでみているだけです。パニックになる必要はまったくありませんし、焦る必要もありません。
ここでのキーポイントは、一般的な使い方とは違い、MQL5の中で正当に掘り下げることのできる概念の限界にあえて挑戦しているという点です。ただし、こうした最後のいくつかのコードサンプルでは、多くの人が理解できる範囲を少し超えているかもしれません。それは、彼らが本質的な概念を理解しておらず、ただコードをコピー&ペーストしているだけで、そのコードがなぜ動作しているのかを理解していないからです。でも、私が目指しているのは、読者の皆さんがそのなぜを本当に理解することです。もしそれが達成できたのなら、この記事を書いた価値があったということになるでしょう。
今回は他の話題には進まず、残りの部分ではコード05の詳細な解説をおこないます。というのも、コード04はコード05に比べれば少しシンプルだからです。
では、コード05の仕組みを見ていきましょう。まず、6行目では純粋に動的な配列を宣言しています。これは、いずれかの時点でメモリを確保して初期化する必要があります。
仮にこの6行目の配列が初期化されているかどうかわからない状況を想定しましょう。その場合、8行目で要素数が0かどうかをチェックします。覚えておいてください。これは純粋な動的配列です。6行目で直接初期化していれば、8行目はそれを検知できます。6行目と8行目の間で初期化されても同じです。
ただし、6行目で宣言と同時に初期化をしてしまうと、別の問題が発生します。どんな問題かは、ぜひご自身で試してみてください。それによって、配列操作の経験値を高めることができます。
いずれにせよ、配列に1つでも要素がある場合は、10行目と11行目が実行され、要素が存在していることが示されます。もし初期化されていなければ、13行目にあるメッセージが端末に表示されることになります。
そして、面白くなるのは14行目以降です。ここで27行目の関数を呼び出しています。注意すべきは、この時点でまだ配列は初期化されていないということです。実際に初期化がおこなわれるのは、31行目が実行されたときです。なぜなら、まさにこの行で、20行目にある手続きが呼び出されるからです。
この手続きでは、24行目で6行目にある動的配列を初期化します。ここで注目すべきは、22行目に定義されている静的なROM型配列を使っているという点です。これは非常に混乱を招き、理解しにくいと感じるかもしれませんが、ArrayCopy関数の仕様をよく見れば、なぜこれが可能なのかが理解できるでしょう。この関数は、基本的に片方の配列の内容をもう片方にコピーするものです。そしてこれは、実用的な場面で非常に役に立つ場合が多いのです。
その後、33行目からループに入り、14行目に返すための計算を行っています。
ただし、14行目に戻る前に、36行目で6行目の配列に新しい要素を追加しています。この配列は24行目で初期化されたものであることを忘れないでください。そして、これが非常に面白い部分なのです。なぜなら、仮に31行目が削除され、配列が初期化されなかった場合、Possibilities関数は29行目の値を返すことになります。というのも、33行目のループが実行されないからです。
ところが、6行目の配列の中身をチェックすると、なんと1つだけ要素があることに気づくでしょう。そしてその要素の値は、37行目で指定されたものです。
この挙動は、実際に自分の手でコードを動かしてみることで、ようやく実感として理解できるものです。ですから、これまでに何度かお伝えしてきたように、ぜひ付属のコードを使って実際に練習してみてください。そうすることで、ここで紹介した仕組みを深く理解できるようになるでしょう。
最終的な考察
今回の記事では、前回までの記事に比べて、遥かに面白さが増したと思います。というのも、最初の記事から説明してきた概念を活用して、新しい可能性を探り始めたからです。もし今回の記事から読み始めた方がいれば、非常に難しくてよくわからないと感じたかもしれません。でも、これまでの記事を一つひとつ読んで、実際に手を動かして練習してきた方にとっては、この内容がどれだけ面白く、価値のあるものかは、もうお分かりだと思います。。そして今回の内容は、以前の記事で軽く触れたテーマにも通じており、ここから先さらに多くの可能性が開かれていきます。
次回の記事では、これまでに学んだ要素の中から、日常のプログラミングにおいて当たり前となるものを取り上げます。いつの間にか、あなたは多くの人よりもずっと優れたプログラマーになっていることでしょう。なぜなら、正しい概念を理解し、それをどう応用すべきかを知っているからです。単にコードをコピー&ペーストするだけでは、そうはなれません。では、添付ファイルを使って楽しみながら練習をしてみてください。それでは、次回の記事でまたお会いしましょう。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15473
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索