
Neuronale Netze leicht gemacht (Teil 36): Relationales Verstärkungslernen

Einführung
Wir studieren weiterhin das Verstärkungslernen, das Reinforcement Learning. In den vorangegangenen Artikeln haben wir bereits verschiedene Algorithmen besprochen. Aber wir haben immer Faltungsmodelle verwendet. Der Grund dafür ist einfach. Bei der Entwicklung und dem Testen aller zuvor betrachteten Algorithmen haben wir verschiedene Computerspiele verwendet. Deshalb haben wir vor allem die Bilder von Levels verschiedener Computerspiele in die Modelle eingespeist. Mit Hilfe von Faltungsmodellen lassen sich Aufgaben im Zusammenhang mit der Bilderkennung und der Erkennung von Objekten auf diesen Bildern leicht lösen.
Bilder aus Computerspielen weisen kein Rauschen oder Objektverzerrungen auf. Dies vereinfacht die Erkennungsaufgabe. In der Realität gibt es jedoch keine solchen „idealen“ Bedingungen. Die Daten sind voll von verschiedenen Arten von Rauschen. Sehr oft sind die untersuchten Bilder weit von den idealen Erwartungen entfernt. Sie können in der Szene bewegt werden (Faltungsnetzwerke können dies problemlos bewältigen) und sind verschiedenen Verzerrungen ausgesetzt. Sie können auch gestreckt, gestaucht oder in einem anderen Winkel präsentiert werden. Diese Aufgabe ist für ein gewöhnliches Faltungsmodell schwieriger zu bewältigen.
In manchen Situationen ist nicht nur das Vorhandensein von zwei oder mehr Objekten, sondern auch deren relative Position für die erfolgreiche Lösung des Problems wichtig. Es ist schwierig, solche Probleme mit reinen Faltungsmodellen zu lösen. Aber sie werden durch relationale Modelle gut gelöst.
1. Relationales Verstärkungslernen
Der Hauptvorteil relationaler Modelle ist die Möglichkeit, Abhängigkeiten zwischen Objekten aufzubauen. Das ermöglicht die Strukturierung der Quelldaten. Das relationale Modell kann in Form von Graphen dargestellt werden, in denen Objekte und Ereignisse als Knoten dargestellt werden, während Beziehungen Abhängigkeiten zwischen Objekten und Ereignissen aufzeigen.

Anhand der Graphen können wir die Struktur der Abhängigkeiten zwischen den Objekten visuell darstellen. Wenn wir zum Beispiel ein Kanalausbruchsmuster beschreiben wollen, können wir ein Chart mit einer Kanalformation an der Spitze erstellen. Die Beschreibung der Kanalbildung kann auch als Graph dargestellt werden. Als Nächstes erstellen wir zwei Kanalausbruchsknoten (obere und untere Grenze). Beide Knoten haben die gleichen Verbindungen zum vorherigen Kanalbildungsknoten, sind aber nicht miteinander verbunden. Um zu vermeiden, dass wir im Falle eines falschen Ausbruchs eine Position eingehen, können wir abwarten, bis der Kurs wieder an die Kanalgrenze zurückgeht. Dies sind zwei weitere Knotenpunkte für den Rollback an den oberen und unteren Rand des Kanals. Sie haben Verbindungen zu den Knotenpunkten der entsprechenden Kanalgrenzübergänge. Aber auch hier gilt, dass sie keine Verbindung zueinander haben.
Die beschriebene Struktur fügt sich in den Graphen ein und sorgt so für eine klare Strukturierung der Daten und des Ablaufs eines Ereignisses. Bei der Erstellung von Assoziationsregeln haben wir uns etwas Ähnliches überlegt. Aber das kann man kaum mit den Faltungsnetzen vergleichen, die wir früher verwendet haben.
Faltungsnetzwerke werden verwendet, um Objekte in Daten zu identifizieren. Wir können das Modell so trainieren, dass es Umkehrpunkte der Bewegung oder kleine Trends erkennt. In der Praxis kann der Prozess der Kanalbildung jedoch zeitlich ausgedehnt werden, wobei die Intensität der Trends innerhalb des Kanals unterschiedlich ist. Allerdings können Faltungsmodelle mit solchen Verzerrungen nicht gut umgehen. Darüber hinaus können weder Faltungsschichten noch vollständig verknüpfte neuronale Schichten zwei verschiedene Muster trennen, die aus denselben Objekten mit unterschiedlicher Reihenfolge bestehen.
Es sollte auch beachtet werden, dass Neuronale Faltungsnetze nur Objekte erkennen können, aber keine Abhängigkeiten zwischen ihnen aufbauen können. Daher müssen wir einen anderen Algorithmus finden, der solche Abhängigkeiten lernen kann. Kommen wir nun zurück zu den Aufmerksamkeitsmodellen. Die Aufmerksamkeitsmodelle (attention models), die es ermöglichen, die Aufmerksamkeit auf einzelne Objekte zu lenken und sie aus der allgemeinen Datenmenge herauszufiltern.
Der „generalisierte Aufmerksamkeitsmechanismus“ wurde erstmals im September 2014 vorgeschlagen, um die Effizienz von maschinellen Übersetzungsmodellen mit rekurrenten Modellen zu verbessern. Die Idee war, eine zusätzliche Aufmerksamkeitsebene zu schaffen, die die ausgeblendeten Zustände des Encoders bei der Verarbeitung des Originaldatensatzes erfasst. Damit wurde das Problem des Langzeitgedächtnisses gelöst. Die Analyse der Abhängigkeiten zwischen den Sequenzelementen half, die Qualität der maschinellen Übersetzung zu verbessern.
Der Algorithmus für den Betrieb des Mechanismus umfasste die folgenden Iterationen:
1. Erzeugen von ausgeblendeten Zuständen des Encoders und Akkumulieren dieser Zustände im Aufmerksamkeitsblock.
2. Bewerten der paarweisen Abhängigkeiten zwischen den ausgeblendeten Zuständen jedes Encoder-Elements und dem letzten ausgeblendeten Zustand des Decoders.
3. Kombinieren der sich ergebenden Punktzahlen zu einem einzigen Vektor und Normalisierung mit Hilfe der Softmax-Funktion.
4. Berechnen des Kontextvektors durch Multiplikation aller ausgeblendeten Zustände des Encoders mit ihren entsprechenden Alignment Scores.
5. Dekodieren des Kontextvektors und Kombination des resultierenden Wertes mit dem vorherigen Zustand des Dekoders.
Alle Iterationen werden wiederholt, bis das Satzende-Signal empfangen wird.
Die folgende Abbildung zeigt die Visualisierung dieser Lösung:

Das Training von rekurrenten Modellen ist jedoch ein recht zeitaufwändiger Prozess. So wurde im Juni 2017 in dem Artikel „Attention Is All You Need“ eine weitere Variante vorgeschlagen. Dabei handelte es sich um eine neue Architektur des neuronalen Netzes Transformer, das keine rekurrenten Blöcke, sondern einen neuen Self-Attention- (Selbstbeobachtungs-) Algorithmus verwendete. Anders als der zuvor beschriebene Algorithmus analysiert Self-Attention paarweise Abhängigkeiten innerhalb einer Sequenz. In früheren Artikeln haben wir bereits 3 Arten von neuronalen Schichten mit dem Self Attention-Algorithmus erstellt. Wir werden in diesem Artikel eine von ihnen verwenden. Bevor wir jedoch mit der Implementierung des Expert Advisors fortfahren, wollen wir uns ansehen, wie der Self Attention-Algorithmus die Graphenstruktur erlernen kann.

Am Eingang des Self Attention Algorithmus erwarten wir einen Tensor der Quelldaten, in dem jedes Element der Sequenz durch eine bestimmte Anzahl von Merkmalen beschrieben wird. Die Anzahl dieser Merkmale ist vorgegeben und für alle Elemente der Sequenz festgelegt. Der anfängliche Datentensor wird also in Form einer Tabelle dargestellt. Jede Zeile dieser Tabelle ist eine Beschreibung eines Elements der Sequenz. Jede Spalte steht für ein einzelnes Merkmal.
Die verwendeten Merkmale können völlig unterschiedliche Verteilungen haben. Die Verbreitungsmerkmale eines Merkmals können sich stark von denen eines anderen Merkmals unterscheiden. Die Auswirkungen der absoluten Werte von Merkmalen und deren Änderungen auf das Endergebnis können auch absolut entgegengesetzt sein. Um die Daten in eine vergleichbare Form zu bringen, verwenden wir, ähnlich wie beim ausgeblendeten Zustand der rekurrenten Schicht, eine Gewichtsmatrix. Durch Multiplikation jeder Zeile des ursprünglichen Datentensors mit der Gewichtsmatrix wird die Beschreibung des Sequenzelements in einen bestimmten d-dimensionalen internen Einbettungsraum transformiert. Die Auswahl der Parameter für die angegebene Matrix im Lernprozess ermöglicht die Auswahl der Werte, für die die Elemente der Sequenz maximal trennbar sind und nach Ähnlichkeit gruppiert werden. Beachten Sie, dass der Self Attention-Algorithmus das Erstellen und das Training von drei solcher Matrizen ermöglicht. Die Matrizen ermöglichen es uns, drei verschiedene Einbettungen von Quelldaten zu bilden: Query, Key und Value (Abfrage, Schlüssel und Wert). Die Dimensionen der Query- und Key-Vektoren werden bei der Modellerstellung festgelegt. Die Dimension des Value-Vektors entspricht der Anzahl der Merkmale in den Quelldaten (der Größe eines Elementes des Beschreibungsvektors).
Jede der erzeugten Einbettungen (embeddings) hat ihren eigenen funktionalen Zweck. Query und Key werden verwendet, um Abhängigkeiten zwischen den Sequenzelementen zu definieren. Value legt fest, welche Informationen von jedem Element weitergegeben werden sollen.
Um die Abhängigkeitskoeffizienten zwischen den Elementen der Sequenz zu ermitteln, müssen wir paarweise die Einbettung jedes Sequenzelements aus dem Query-Tensor mit den Einbettungen aller Elemente aus dem Key-Tensor (einschließlich der Einbettung des entsprechenden Elements) multiplizieren. Bei der Verwendung von Matrixoperationen können wir einfach die Query-Matrix mit der transponierten Key-Matrix multiplizieren.
![]()
Wir teilen die erhaltenen Werte durch die Quadratwurzel der eingebetteten Dimension des Keys und normalisieren sie mit der Softmax-Funktion im Kontext der Einbettung von Sequenzelementen der Query. Als Ergebnis dieser Operation erhalten wir eine quadratische Matrix der Abhängigkeiten zwischen den Elementen der ursprünglichen Datenfolge.
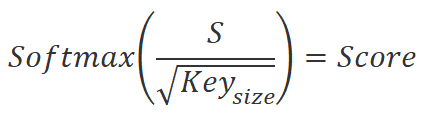
Achten Sie auf die folgenden beiden Punkte:
- Durch die Verwendung der Softmax-Funktion erhielten wir normalisierte Abhängigkeitskoeffizienten im Bereich von 0 bis 1. In diesem Fall ist die zeilenweise Summe der Koeffizienten gleich 1.
- Wir haben verschiedene Matrizen verwendet, um die eingebetteten Query und Key zu erstellen. Das bedeutet, dass wir verschiedene Einbettungen für dasselbe Element der Quelldatensequenz erhalten haben. Mit diesem Ansatz erhalten wir schließlich eine nicht diagonale Matrix von Abhängigkeitskoeffizienten. In dieser Matrix unterscheiden sich der Abhängigkeits-Koeffizient des Elements A vom Element B und der umgekehrte Abhängigkeits-Koeffizient des Elements B vom Element A.
Erinnern wir uns an den Zweck dieser Aktion. Wie bereits erwähnt, möchten wir ein Modell erhalten, das Diagramme von Abhängigkeiten zwischen verschiedenen Objekten und Ereignissen erstellen kann. Wir beschreiben jedes Objekt oder Ereignis durch Merkmalsvektoren im anfänglichen Datentensor. Die daraus resultierende Matrix der Abhängigkeitskoeffizienten ist eine tabellarische Darstellung des gewünschten Graphen. In dieser Matrix zeigen die Nullwerte der Koeffizienten an, dass es keine Verbindungen zwischen den entsprechenden Knoten der Quelldaten gibt. Werte ungleich Null bestimmen den gewichteten Einfluss eines Knotens auf den Wert eines anderen.
Aber zurück zum Algorithmus der Self Attention. Wir multiplizieren die erhaltenen Abhängigkeits-Koeffizienten mit den entsprechenden Einbettungen im Value-Tensor. Die sich ergebenden Werte der „gewichteten“ Einbettungen werden addiert, und der sich daraus ergebende Vektor ist die Ausgabe des Self Attention Blocks für das analysierte Element der Sequenz. Bei Matrixoperationen verwenden wir einfach die Funktion der Matrixmultiplikation. Durch Multiplikation einer quadratischen Matrix von Abhängigkeitskoeffizienten mit dem Value-Tensor erhalten wir den gewünschten Tensor des Self Attention Blocks.
![]()
Self-Attention ist oben für einen einfachen Fall beschrieben. In der Praxis verwenden wir jedoch hauptsächlich die Option der Mehrkopfaufmerksamkeit. Bei einer solchen Implementierung wird eine weitere Matrix zur Dimensionalitätsreduktion hinzugefügt. Sie reduziert die Dimension des verketteten Tensors aus allen Aufmerksamkeiten auf die Dimension der Quelldaten.
Am Ende des Self-Attention-Algorithmus addieren wir den Quelldatentensor mit dem Aufmerksamkeitsblock und normalisieren dann den resultierenden Wert.
Wie Sie sehen können, sind die Tensoren am Eingang und am Ausgang des Self Attention Blocks gleich groß. Der Ausgabetensor enthält jedoch normalisierte Werte, sodass die Merkmale, die einen wesentlichen Einfluss auf das Ergebnis haben, maximiert werden. Im Gegenteil, der Wert von Merkmalen, die das Ergebnis nicht beeinflussen, und Rauschphänomene werden minimiert. In der Regel werden in Modellen mehrere aufeinander folgende Aufmerksamkeitsblöcke verwendet, um diesen Effekt zu verstärken.
Der Aufmerksamkeitsblock kann uns jedoch nur helfen, die signifikanten Merkmale zu finden. Sie bietet keine Lösung für das Problem. Daher folgt auf den Aufmerksamkeitsblock ein Entscheidungsblock. Bei diesem Block kann es sich um ein vollständig verbundenes Perzeptron oder eine andere zuvor untersuchte architektonische Lösung handeln.
2. Implementierung mittels MQL5
Wenn wir nun zur Implementierung übergehen, ist zu beachten, dass wir das Modell aus dem ursprünglichen Artikel „Deep reinforcement learning with relational inductive biases“ (Tiefes Verstärkungslernen mit relationalem, induktivem Bias) nicht erneut verwenden werden. Wir werden die vorgeschlagenen Entwicklungen nutzen und unser Modell mit Hilfe des internen Neugiermoduls um ein relationales Modul erweitern. Wir haben eine Kopie dieses Modells im vorherigen Artikel erstellt. Wir erstellen eine Kopie des Expert Advisors aus dem vorherigen Artikel und speichern ihn als RLL-Learning.mq5.
Eine Änderung der internen Architektur des Modells, das wir trainieren, ohne die Quelldatenschicht und die Ergebnisebene zu ändern, erfordert keine Änderung des EA-Algorithmus, sodass wir einfach neue Modelldateien erstellen können, ohne direkte Änderungen am EA-Code vorzunehmen. In den Kommentaren zu bereits veröffentlichten Artikeln erhalte ich jedoch häufig Meldungen über Fehler beim Laden der Modelle, die mit NetCreator erstellt wurden. Deshalb habe ich mich in diesem Artikel entschlossen, die Beschreibung der Modellarchitektur im EA-Code zu kompilieren.
Natürlich können Sie weiterhin den NetCreator verwenden, um die erforderlichen Modelle zu erstellen. In diesem Fall sollten Sie jedoch auf Folgendes achten.
Im EA-Code wird der Modellname durch eine Makrosubstitution angegeben. Daher sollte das Modell dem vorgegebenen Format entsprechen.
#define FileName Symb.Name()+"_"+EnumToString(TimeFrame)+"_"+StringSubstr(__FILE__,0,StringFind(__FILE__,".",0))
Der Dateiname setzt sich zusammen aus:
- Das Symbol des Charts, auf dem der EA ausgeführt wird. Es ist der vollständige Name des Symbols, wie er in Ihrem Terminal erscheint, einschließlich der Präfixe und Suffixe.
- Der in den EA-Parametern angegebene Zeitrahmen.
- EA-Dateiname ohne Erweiterung.
Alle oben genannten Komponenten sind durch einen Unterstrich getrennt.
Dem Dateinamen wird eine der folgenden Erweiterungen hinzugefügt:
- „nnw“ für ein zu trainierendes Modell
- „fwd“ für Forward Model,
- „inv“ für Inverses Modell.
Speichern Sie alle Dateien der erstellten Modelle im Verzeichnis „Files“ Ihres Terminals oder in „Common/Files“. In diesem Fall muss das Verzeichnis, in dem sich die Dateien befinden, mit dem im Programmcode angegebenen Flag Common übereinstimmen. Der eigentliche Wert des Common-Flags entspricht dem Verzeichnis „Common/Files“.
bool CNet::Load(string file_name, float &error, float &undefine, float &forecast, datetime &time, bool common = true)
Kehren wir nun zum Code unseres Expert Advisors zurück. In der Funktion OnInit initialisieren wir zunächst die Klassen für die Arbeit mit Indikatoren.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED;
Dann versuchen wir, die vorbereiteten Modelle zu laden. Bitte beachten Sie, dass ich Modelle aus dem Verzeichnis „Common/Files“ lade. Dieser Ansatz ermöglicht es mir, den EA ohne Änderungen sowohl im Strategy Tester als auch in Echtzeit zu verwenden. Das liegt daran, dass der EA, wenn er im Strategy Tester gestartet wird, nicht auf das Verzeichnis „Files“ des Terminals zugreift. Aus Sicherheitsgründen erstellt der Strategy Tester für jeden Testagenten „dessen eigene Sandbox“. Jeder Agent hat jedoch Zugriff auf die gemeinsame Dateiressource, d. h. das Verzeichnis „Common/Files“.
//--- if(!StudyNet.Load(FileName + ".icm", true)) if(!StudyNet.Load(FileName + ".nnw", FileName + ".fwd", FileName + ".inv", 6, true)) {
Wenn die vortrainierten Modelle nicht geladen werden können, erstellen wir eine Beschreibung der Architektur der verwendeten Modelle. Ich habe diesen Teilprozess in der separaten Methode CreateDescriptions implementiert. Hier rufen wir es auf und überprüfen das Ergebnis der Operationen. Im Falle eines Fehlers löschen wir unnötige Objekte und beenden die EA-Initialisierungsfunktion mit dem Ergebnis INIT_FAILED.
CArrayObj *model = new CArrayObj(); CArrayObj *forward = new CArrayObj(); CArrayObj *inverse = new CArrayObj(); if(!CreateDescriptions(model, forward, inverse)) { delete model; delete forward; delete inverse; return INIT_FAILED; }
Nachdem die Beschreibung aller drei benötigten Modelle erfolgreich erstellt wurde, rufen wir die Methode zur Modellerstellung auf. Vergessen wir nicht, die Ergebnisse der Ausführung der Operation zu überprüfen.
if(!StudyNet.Create(model, forward, inverse)) { delete model; delete forward; delete inverse; return INIT_FAILED; } StudyNet.SetStateEmbedingLayer(6); delete model; delete forward; delete inverse; }
Als Nächstes geben wir die neuronale Schicht des Modells an, das wir mit den Encoderergebnissen trainieren, und löschen die Architekturbeschreibungsobjekte der erstellten Modelle, die nicht mehr benötigt werden.
Im nächsten Schritt schalten wir das Modell in den Trainingsmodus und legen die Größe des Erfahrungswiedergabepuffers fest.
if(!StudyNet.TrainMode(true)) return INIT_FAILED; StudyNet.SetBufferSize(Batch, 10 * Batch);
Lassen Sie uns die Größen der Indikatorpuffer festlegen.
//--- CBufferFloat* temp; if(!StudyNet.GetLayerOutput(0, temp)) return INIT_FAILED; HistoryBars = (temp.Total() - 9) / 12; delete temp; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
Geben Sie die Art der Ausführung von Handelsgeschäften an.
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- return(INIT_SUCCEEDED); }
Damit ist die EA-Initialisierungsmethode abgeschlossen. Nun geht es weiter mit der Methode CreateDescriptions, die eine Beschreibung der Modellarchitektur erstellt.
bool CreateDescriptions(CArrayObj *Description, CArrayObj *Forward, CArrayObj *Inverse)
{
In den Parametern erhält diese Methode Zeiger auf drei dynamische Arrays, um die Architekturen der drei Modelle zu schreiben:
- Description — (Beschreibung) zu trainierendes Modell,
- Forward — das Vorwärtsmodell,
- Inverse — das invertierte Modell,
Im Hauptteil der Methode werden die empfangenen Zeiger sofort überprüft. Falls erforderlich, erstellen wir neue Objektinstanzen.
//--- if(!Description) { Description = new CArrayObj(); if(!Description) return false; } //--- if(!Forward) { Forward = new CArrayObj(); if(!Forward) return false; } //--- if(!Inverse) { Inverse = new CArrayObj(); if(!Inverse) return false; }
Wir kontrollieren erneut den Prozess der Operationsausführung. Im Falle eines Fehlschlags wird die Methode mit dem Ergebnis Falsch beendet.
Nach der erfolgreichen Erstellung der erforderlichen Objekte gehen wir zum nächsten Teilprozess über, in dem wir die Architektur der zu erstellenden Modelle beschreiben. Wir beginnen mit der Architektur des Trainingsmodells. Wir löschen das dynamische Array, um die Beschreibung der Modellarchitektur zu schreiben, und bereiten eine Variable vor, um einen Zeiger auf ein Objekt zur Beschreibung der neuronalen Schicht, ClayerDescription, zu schreiben.
//--- Model
Description.Clear();
CLayerDescription *descr;
Wie üblich erstellen wir zunächst die neuronale Schicht der Quelldaten. Als Eingabedatenschicht wird eine vollständig verbundene neuronale Schicht ohne Aktivierungsfunktion verwendet. Wir legen die Größe der neuronalen Schicht gleich der Anzahl der an das Modell übertragenen Werte fest. Beachten Sie, dass wir zur Beschreibung jeder Kerze mit historischen Daten 12 Werte übertragen. Es handelt sich dabei um die Beschreibung der Kerze und die Werte der analysierten Indikatoren. Darüber hinaus übermitteln wir den Kontostand und das Volumen der offenen Positionen. Damit kommen 9 weitere Werte hinzu.
Der Algorithmus zur Beschreibung neuronaler Schichten wird für jede neuronale Schicht wiederholt. Sie besteht aus drei Schritten. Zunächst erstellen wir eine neue Instanz des Objekts zur Beschreibung der neuronalen Schicht. Wir müssen das Ergebnis der Operation überprüfen, denn wenn ein Fehler bei der Erstellung eines neuen Objekts auftritt, kann ein kritischer Fehler beim Zugriff auf ein nicht vorhandenes Objekt auftreten.
Als Nächstes legen wir die Beschreibung der neuronalen Schicht fest. Hier variiert die Anzahl der angegebenen Parameter je nach Art der neuronalen Schicht. Für die Eingabedatenschicht geben wir den Typ der neuronalen Schicht, die Anzahl der Elemente in der neuronalen Schicht, den Typ der Parameteroptimierung und die Aktivierungsfunktion an.
Nach der Angabe aller erforderlichen Parameter der neuronalen Schicht fügen wir dem dynamischen Array der Modellarchitekturbeschreibung einen Zeiger auf das Objekt zur Beschreibung der neuronalen Schicht hinzu.
//--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = HistoryBars * 12 * 9; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Nach meiner Erfahrung beim Training neuronaler Netze ist der Lernprozess stabiler, wenn normalisierte Ausgangsdaten verwendet werden. Um die Daten während des Trainings und der Nutzung zu normalisieren, wird eine Batch-Normalisierungsschicht verwendet. Wir werden sie direkt nach der Quelldatenebene erstellen.
Auch hier erstellen wir zunächst eine neue Instanz des Objekts zur Beschreibung der neuronalen Schicht und überprüfen das Ergebnis der Operation. Als Nächstes spezifizieren wir den Typ der zu erstellenden neuronalen Schicht - defNeuronBatchNormOCL, die Anzahl der Elemente auf der Größenebene der vorherigen neuronalen Schicht und die Größe der Normalisierungsgruppe. Danach fügen wir einen Zeiger auf das Objekt der Beschreibung der neuronalen Schicht in das dynamische Array der Modellarchitekturbeschreibung ein.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Nach der Normalisierung der Daten werden wir einen Vorverarbeitungsblock erstellen. Hier werden wir Faltungsneurale Schichten verwenden, um Muster in den Quelldaten zu finden.
Wie zuvor erstellen wir eine neue Instanz des Beschreibungsobjekts ClayerDescription für neuronale Schichten, geben den Typ defNeuronConvOCL für neuronale Schichten an, legen das Fenster der analysierten Daten auf 3 Elemente fest und setzen den Datenfensterschritt auf 1. Mit diesen Parametern ist die Anzahl der Elemente in einem Filter um 2 kleiner als die Größe der vorherigen Schicht. Um das Potenzial zu maximieren, habe ich 16 Filter in dieser neuronalen Schicht erstellt. Das scheinen zu viele Filter zu sein, aber ich wollte das Modell so flexibel wie möglich gestalten. Ich habe LeakReLU als Aktivierungsfunktion verwendet. Zur Optimierung der Parameter werden wir Adam verwenden.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count - 2; descr.window = 3; descr.step = 1; descr.window_out = 16; descr.activation = LReLU; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Der nächste Schritt ist kein Standard. Nach der Faltungsschicht wird in der Regel eine Unterabtastungsschicht zur Dimensionalitätsreduktion verwendet. Diesmal arbeiten wir jedoch mit Zeitreihen. Zusätzlich zu den Werten müssen wir die Dynamik der Merkmalsänderung verfolgen. Zu diesem Zweck beschloss ich, ein Experiment durchzuführen und einen LSTM-Block nach der Faltungsschicht zu verwenden. Natürlich ist seine Größe kleiner als die Ausgabe der Faltungsschicht. Aufgrund der Architektur des rekurrenten Blocks erwarten wir jedoch eine Dimensionalitätsreduktion unter Berücksichtigung der vorherigen Zustände des Systems.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 300; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Um komplexere Strukturen zu erkennen, werden wir den Block der Faltungsschichten und der rekurrenten neuronalen Schichten wiederholen.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 100; descr.window = 3; descr.step = 3; descr.window_out = 10; descr.activation = LReLU; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 100; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Als Nächstes wenden wir uns dem relationalen Block unseres Trainingsmodells zu. Hier werden wir einen Block aus einem mehrschichtigen und ‚mehrköpfigen‘ Self Attention verwenden. Zu diesem Zweck wird der neuronale Schichttyp defNeuronMLMHAttentionOCL festgelegt. Die Anzahl der Elemente der Ausgangsdatenfolge entspricht der Anzahl der analysierten Kerzen. In diesem Fall beträgt die Anzahl der Merkmale zur Beschreibung eines Kerzenständers 5.
Verwechseln Sie nicht die Anzahl der Zeichen, die eine Kerze am Modelleingang und am Eingang des relationalen Blocks beschreiben. Da dem relationalen Block eine Vorverarbeitung der Daten durch Faltungsschichten und rekurrente neuronale Schichten vorausging.
Die Größe des Keys-Vektors ist gleich 16. Die Anzahl der Köpfe ist gleich 64. Ähnlich wie bei den Filtern der Faltungsneuronalen Netze habe ich eine höhere Anzahl von Aufmerksamkeitsköpfen angegeben, um die aktuelle Marktsituation umfassend zu analysieren.
Wir werden vier solcher Ebenen erstellen. Aber wir werden diese Beschreibung der neuronalen Schicht nicht viermal speichern. Stattdessen setzen wir den Parameter layers auf 4.
Wie in allen vorangegangenen Fällen werden wir zur Optimierung der Parameter die Methode Adam anwenden. Wir geben die Aktivierungsfunktion in diesem Fall nicht an, da alle Aktivierungsfunktionen durch den Algorithmus zur Konstruktion neuronaler Schichten angegeben werden.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = 20; descr.window = 5; descr.step = 64; descr.window_out = 16; descr.layers = 4; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Um die Beschreibung der Modellarchitektur zu vervollständigen, müssen wir die Ebene der vollständig parametrisierten Quantilsfunktion angeben. In der Beschreibung dieser neuronalen Schicht geben wir nur den Typ der neuronalen Schicht defNeuronFQF, den Aktionsraum, die Anzahl der Quantile und die Methode der Parameteroptimierung an.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = 4; descr.window_out = 32; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Damit ist der Teilprozess zur Beschreibung der Architektur des Trainingsmodells abgeschlossen. Jetzt brauchen wir die Modelle von Forward und Inverse. Wir werden ihre Architektur aus dem vorherigen Artikel verwenden. Damit der Expert Advisor richtig funktioniert, müssen wir seine Beschreibung in unsere Methode aufnehmen. Der Teilprozess Beschreibung ist identisch mit dem oben beschriebenen Prozess.
Zunächst wird das dynamische Array der Architekturbeschreibung des Vorwärtsmodells gelöscht. Dann fügen wir die neuronale Ebene der Quelldaten hinzu. Für das Vorwärtsmodell ist die Größe der Eingabedatenschicht gleich dem konkatenierten Vektor aus der Größe der Encoderausgabe des Hauptmodells und dem Raum der möglichen Agentenaktionen.
//--- Forward Forward.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 104; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
Darauf folgt eine vollverknüpfte neuronale Schicht mit 500 Elementen mit der Aktivierungsfunktion LReLU und der Optimierungsmethode Adam.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = LReLU; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
Am Ausgang des Forward-Blocks erwarten wir den nächsten Zustand am Ausgang des Modell-Encoders. Daher wird dieses Modell durch eine vollständig verbundene neuronale Schicht vervollständigt, bei der die Anzahl der Neuronen gleich der Größe des Vektors am Ausgang des Modell-Encoders ist. Es wird keine Aktivierungsfunktion verwendet. Auch hier verwenden wir Adam als Methode zur Parameteroptimierung.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 100; descr.activation = None; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
Der Ansatz der inversen Modellkonstruktion ist ähnlich. Der einzige Unterschied besteht darin, dass wir den verketteten Vektor von zwei aufeinanderfolgenden Zuständen in diesen Block einspeisen. Daher ist die Größe der Quelldatenschicht doppelt so groß wie die Ausgabe des Modell-Encoders.
//--- Inverse Inverse.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 200; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
Die zweite neuronale Schicht ist die gleiche wie die des Vorwärtsmodells.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = LReLU; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
Wir erwarten die ergriffenen Maßnahmen am Ausgang des Inversen Modells. Daher ist die Größe der nächsten neuronalen Schicht gleich dem Raum der möglichen Aktionen des Agenten. In dieser Schicht wird die Aktivierungsfunktion nicht verwendet. Wir werden stattdessen die nächste Softmax-Schicht verwenden.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 4; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = 4; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; } //--- return true; }
Der restliche EA-Code ist derselbe, den wir im vorherigen Artikel besprochen haben. Der vollständige EA-Code und alle verwendeten Bibliotheken sind im Anhang enthalten.
3. Test
Das Modell wurde im Strategy Tester anhand der historischen EURUSD-Daten mit dem Zeitrahmen H1 trainiert und getestet. Die Indikatoren wurden mit Standardparametern verwendet.

Das Modelltraining zeigte das Gleichgewichtswachstum im Strategy Tester. Obwohl im Durchschnitt auf 2 Positionen mit Gewinn 2 mit Verlust kommen, lag der Anteil der Gewinner bei 53,7 %. Im Allgemeinen ist ein ziemlich gleichmäßiger Anstieg des Saldos und des Eigenkapitals zu beobachten, da der durchschnittliche gewinnbringende Handel 12,5 % höher ist als der durchschnittliche Verlusthandel. Der Gewinnfaktor liegt bei 1,31 und der Erholungsfaktor bei 2,85.


Schlussfolgerung
In diesem Artikel haben wir uns mit den relationalen Ansätzen auf dem Gebiet des Verstärkungslernens vertraut gemacht. Wir fügten dem Modell einen relationalen Block hinzu und trainierten es mit dem Modul für intrinsische Neugier. Die Testergebnisse bestätigten die Machbarkeit dieses Ansatzes für die Modellbildung. Diese Modelle können als Grundlage für die Erstellung von EAs verwendet werden, die in der Lage sind, Gewinne zu erzielen.
Obwohl der vorgestellte EA Handelsoperationen durchführen kann, ist er nicht für den Einsatz im realen Handel geeignet. Der EA wird nur zu Bewertungszwecken vorgelegt. Vor dem Einsatz in der Praxis sind erhebliche Verbesserungen und umfassende Tests unter allen möglichen Bedingungen erforderlich.
Liste der Referenzen
- Neural Machine Translation by Jointly Learning to Align and Translate
- Effective Approaches to Attention-based Neural Machine Translation
- Attention Is All You Need
- Deep reinforcement learning with relational inductive biases
- Neuronale Netze leicht gemacht (Teil 8): Attention-Mechanismen
- Neuronale Netze leicht gemacht (Teil 10): Multi-Head Aufmerksamkeit
- Neuronale Netze leicht gemacht (Teil 11): Ein Blick auf GPT
- Neuronale Netze leicht gemacht (Teil 35): Modul für intrinsische Neugierde
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | RRL-learning.mq5 | Expert Advisor | Modelltraining EA |
| 2 | ICM.mqh | Klassenbibliothek | Modellorganisation Klassenbibliothek |
| 3 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 4 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/11876
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Hallo Dmitry Gizlyk,
vielen Dank für Ihre wunderbaren Artikel.
Bitte hilf mir! Wenn ich versuche, in Strategy Tester mit Ryzen 9 6900hx (APU) zu trainieren, bekomme ich diesen Fehler und der EA hatte keine Transaktion.
Wie kann man dieses Problem beheben, Bruder?
Hallo Dmitry,
Vielen Dank für die tolle Arbeit! Dies ist das beste Tutorial bisher im Netz über ML auf MQL5 Plattform
Details sind gut erklärt und können von neuen Lernenden verstanden werden.
Nach Ihrer Anleitung habe ich den Strategy Tester ausgeführt und anscheinend wurde nur einer meiner Prozessoren verwendet, obwohl 12 zur Verfügung stehen, wie auf dem Bild unten zu sehen ist
Gibt es eine Möglichkeit, alle Kerne zu aktivieren, anstatt nur einen?
OS Windows 11 build 22H2
OpenCL Support 3.0
CPU Intel i5-12400 ghz.html)
GPU Intel UHD Graphic 730 (integriert)
RAM 16gb
OpenCL sind bereits in den Einstellungen von Metatrader aktiviert.
Vielen Dank für die ausführliche Anleitung!
Hallo Dmitry,
Vielen Dank für die tolle Arbeit! Dies ist das beste Tutorial so weit im Netz über ML auf MQL5 Plattform
Details sind gut erklärt und kann von neuen Lernenden verstanden werden.
Nach Ihrer Anleitung habe ich den Strategy Tester ausgeführt und anscheinend wurde nur einer meiner Prozessoren verwendet, obwohl 12 zur Verfügung stehen, wie in der Abbildung unten zu sehen ist
Gibt es eine Möglichkeit, alle Kerne zu aktivieren, anstatt nur einen?
OS Windows 11 build 22H2
OpenCL Support 3.0
CPU Intel i5-12400 ghz.html)
GPU Intel UHD Graphic 730 (integrated)
RAM 16gb
OpenCL sind bereits in den Einstellungen von Metatrader aktiviert.
Vielen Dank für die ausführliche Anleitung!
Hallo, bei Strategy tester können Sie nur einen Kern verwenden sehen. Er wird vom mql-Programm verwendet, nicht von OpenCL. OpenCL verwendet GPU- oder CPU-Kerne im System außerhalb des Strategy-Tester-Monitors. Es gibt mehrere Möglichkeiten, den Ressourcenverbrauch eines OpenCL-Programms in Windows zu sehen:
1. eine Software zur Leistungsüberwachung wie MSI Afterburner oder GPU-Z verwenden, die die GPU-Nutzung und andere Systemkomponenten anzeigen. Sie können auch zeigen, welchen Anteil der Ressourcen jedes OpenCL-Programm verwendet.
2. verwenden Sie Profiler wie AMD CodeXL oder NVIDIA Nsight Visual Studio Edition. Damit können Sie ein OpenCL-Programm analysieren und anzeigen, welche Teile des Codes die meiste Zeit und die meisten Ressourcen verbrauchen.
3. verwenden Sie die OpenCL-API, um Statistiken zu sammeln. Damit können Sie programmatisch Informationen über die Nutzung von OpenCL-Ressourcen abrufen, wie z. B. die Speichernutzung oder die Kernleistung. Sie können die Bibliothek Performance Counters for OpenCL (PCPerfCL) verwenden, um diese Informationen unter Windows zu sammeln.
4. verwenden Sie Profiling-Tools wie Intel VTune Amplifier, mit denen Sie sehen können, wie ein Programm die Ressourcen des Prozessors und anderer Systemkomponenten nutzt.
Guten Tag Dimitri!
Bitte helfen Sie mir, Ihren Expert Advisor aus diesem Artikel auszuführen. Ich habe alles versucht, damit es funktioniert, aber leider funktioniert es nicht richtig.
Das Problem ist folgendes: der Expert Advisor startet im Tester und startet den Test im Tester normal, zählt die Sekunden herunter, grüner Balken, keine Fehler im Log, sieht normalerweise die Grafikkarte und wählt sie aus. Aber die Grafikkarte ist zu 0% ausgelastet. Es ist so, als würde nichts gezählt werden. In Common\Files gibt es 2 Dateien mit den Erweiterungen icm und nnw mit einer Größe von 1 kb. Wenn ich versuche, den Test im Tester neu zu starten, warnt er, dass er nicht initialisiert werden kann und der Test nicht startet. Wenn ich MT5 neu starte und die von diesem EA erstellten Dateien in Common\Files lösche, startet er normal, benutzt aber auch nicht die Grafikkarte und erstellt wieder diese Dateien von 1 kb. und so weiter und so fort.
Ich habe versucht, die NeuroNet.mqh-Dateien aus dem nächsten Artikel (den Sie in den Kommentaren gepostet haben) zu nehmen und die im Artikel damit zu ersetzen - es hat nicht geholfen. Ich habe versucht, einen kleinen Zeitraum im Tester auszuwählen (1 Monat, 1 Woche, 2 Monate usw.) - auch das hat nicht geholfen.
Wie kann man ihn starten? Die Expert Advisors aus früheren Artikeln laufen normal und nutzen die Grafikkarte korrekt.
Es gibt auch ein Problem mit dem Expert Advisor aus dem nächsten Artikel 37, 38. Im Gegenteil, es gibt keinen Fortschritt in der Tester, aber die Grafikkarte ist auf das Maximum und so mindestens 5 Stunden, sogar 10 Stunden verwendet.
Der Expert Advisor aus Artikel 39 funktionierte einwandfrei. Dort wählte ich die Geschichte mehr als 1 Monat und es hat nicht die Datenbank erstellen, aber ich wählte 1 Monat und es erstellt die Datenbank normal. Der Rest der Teile funktionierte normal.
Das ist ein echtes Juwel, Dmitriy!
Ich bin Datenwissenschaftler mit praktischer Erfahrung in der Entwicklung verschiedener Algorithmen für maschinelles Lernen auf Zeitreihendaten, und dennoch finde ich Ihre Serie informativ und gut geschrieben. Dies ist eine wertvolle Grundlage, auf der man aufbauen kann.
Vielen Dank, dass Sie Ihre Arbeit mit uns teilen.
Bijan