
Redes neuronales: así de sencillo (Parte 36): Modelos relacionales de aprendizaje por refuerzo (Relational Reinforcement Learning)

Introducción
Continuamos estudiando los métodos de aprendizaje por refuerzo. En artículos anteriores, hemos analizado varios algoritmos, pero siempre hemos usado modelos convolucionales, y esto no es sorprendente. Al diseñar y probar todos los algoritmos considerados anteriormente, hemos usado varios videojuegos, suministrando principalmente a la entrada de los modelos la imagen de los niveles de varios videojuegos. Las tareas de reconocimiento de imágenes y la detección de varios objetos en ellas se resuelven fácilmente usando modelos convolucionales.
La imagen de una escena de los videojuegos está desprovista del ruido y la distorsión de los objetos, y simplifica la tarea de su reconocimiento. En una situación real, estaremos privados de semejantes condiciones "estériles", y nuestros datos estarán llenos de varios tipos de ruido, por lo que, muy a menudo, las imágenes estudiadas se encontrarán lejos de las expectativas ideales. Las imágenes pueden desplazarse por la escena (las redes convolucionales pueden gestionar esto fácilmente), y pueden estar sujetas a diversas distorsiones: estiradas o comprimidas, o presentadas desde un ángulo diferente. Esta tarea de los modelos convolucionales convencionales es más difícil de manejar.
Hay situaciones en las que no solo la presencia de dos o más objetos, sino también su posición relativa resulta importante para solucionar el problema con éxito; dichos problemas ya son difíciles de resolver usando solo modelos convolucionales, pero los modelos relacionales los resuelven bien.
1. Aprendizaje relacional por refuerzo
La principal ventaja de los modelos relacionales es la capacidad de crear dependencias entre objetos, lo cual permite estructurar los datos de origen. El modelo relacional se puede representar más claramente en forma de gráficos, y los objetos y eventos se representan como nodos. Las relaciones muestran dependencias entre objetos y eventos relacionados.

El uso de gráficos nos permite construir visualmente la estructura de las dependencias entre objetos. Por ejemplo, si queremos describir un patrón de ruptura de un canal, dibujaremos un gráfico, en cuya parte superior habrá la formación de un canal. La descripción de la formación del canal también se puede representar como un gráfico. A continuación, crearemos 2 nodos de ruptura del canal (bordes superior e inferior). Ambos nodos tendrán las mismas conexiones con el anterior nodo de formación del canal, pero no están conectados entre sí. Para evitar entrar en una posición en caso de una ruptura falsa, podemos esperar un retroceso hacia el borde del canal. Estos serán 2 nodos más de retroceso hacia los bordes superior e inferior del canal, los cuales tendrán conexiones con los nodos de ruptura del borde del canal correspondiente, pero, una vez más, no tendrán conexiones entre sí.
La estructura descrita encaja bien en el gráfico y ofrece una estructuración clara de los datos y la secuencia de eventos. Ya analizamos algo similar al construir las reglas asociativas, pero esto difícil se conecta con las redes convolucionales que usamos anteriormente.
Parecería que las redes convolucionales se usan para identificar objetos en los datos. Podemos entrenar el modelo para resaltar algunos puntos de reversión del movimiento o pequeñas tendencias, pero en la práctica, el proceso de formación del canal puede extenderse en el tiempo con diferentes intensidades de tendencia dentro del canal, mientras que los modelos convolucionales no siempre se adaptan bien a tales distorsiones. Además, ni las capas neuronales convolucionales ni las completamente conectadas pueden separar 2 patrones diferentes que consten de los mismos objetos con una secuencia diferente.
También debemos considerar que las redes neuronales convolucionales solo son capaces de detectar objetos: no son capaces de construir dependencias entre ellos. Entonces necesitaremos encontrar algún otro algoritmo que pueda aprender tales dependencias, y aquí deberemos recordar los modelos de atención. Son precisamente los modelos de atención los que hacen posible centrar la atención en objetos individuales, destacándolos del array de datos general.
El "mecanismo de atención generalizada" fue propuesto por primera vez en septiembre de 2014 para mejorar la eficiencia de los modelos de traducción automática usando modelos recurrentes. Entonces se propuso crear una capa adicional de atención que recopilara los estados ocultos del codificador al procesar la secuencia original. Esto resolvió el problema de la memoria a largo plazo, mientras que el análisis de dependencias entre los elementos de la secuencia ayudó a mejorar la calidad de la traducción automática.
El algoritmo de funcionamiento de este mecanismo incluía las siguientes iteraciones:
1. Creamos los estados ocultos del codificador y los acumulamos en el bloque de atención.
2. Estimamos las dependencias por pares entre los estados ocultos de cada elemento del codificador y el último estado oculto del decodificador.
3. Las puntuaciones resultantes se combinan en un solo vector y se normalizan usando la función Softmax.
4. Calculamos el vector de contexto multiplicando todos los estados ocultos del codificador por sus puntuaciones de alineación correspondientes.
5. Decodificamos el vector de contexto y combinamos el valor resultante con el estado anterior del codificador.
Todas las iteraciones se repiten hasta que obtengamos la señal de final de la oración.
La siguiente figura muestra la representación de la solución propuesta.

No obstante, entrenar modelos recurrentes es un proceso bastante lento, y en junio de 2017, en el artículo "Attention Is All You Need", se propuso un nuevo Transformador de arquitectura de red neuronal en el que se abandonaba el uso de bloques recurrentes y se proponía un nuevo algoritmo de atención llamado algoritmo de auto-atención. A diferencia del algoritmo descrito anteriormente, el algoritmo de auto-atención analiza las dependencias emparejadas dentro de la misma secuencia. En artículos anteriores, ya hemos creado 3 tipos de capas neuronales usando el algoritmo de auto-atención, y en el marco de este artículo, usaremos uno de ellos. Pero antes de continuar con la implementación del asesor experto, vamos a ver cómo el algoritmo de auto-atención puede aprender la estructura de un gráfico.

En la entrada del algoritmo Self-Attention, esperaremos el tensor de los datos originales, en el que cada elemento de la secuencia estará descrito por un cierto número de características. El número de dichas características está se establece de antemano y es fijo para todos los elementos de la secuencia. de esta forma, el tensor de datos inicial se nos presenta como una tabla. Cada fila de esta tabla será una descripción de un elemento de la secuencia, mientras que cada columna corresponderá a una sola característica.
Las características usadas pueden tener distribuciones completamente diferentes. Los rasgos de distribución de una característica pueden ser muy diferentes de los de otra característica, así como el impacto en el resultado final de los valores absolutos de las características y sus cambios pueden ser absolutamente opuestos. Para convertir los datos a un tipo comparable, por analogía con el estado oculto de la capa recurrente, usaremos una matriz de pesos. La multiplicación de cada fila del tensor de datos iniciales por la matriz de peso convierte la descripción del elemento de la secuencia en un cierto espacio d-dimensional de incorporación interna, mientras que la selección de los parámetros de la matriz especificada durante aprendizaje permite seleccionar aquellos valores para los cuales los elementos de la secuencia serán separables entre sí al máximo y agrupados por su similitud. Debemos decir que en el algoritmo de auto-atención se contempla la creación y el entrenamiento de tres de esas matrices, lo cual permite crear tres incorporaciones diferentes de los datos de origen: Query, Key y Value. Las dimensionalidades de los vectores Query y Key se establecen al crear el modelo, mientras que la dimensionalidad del vector Value se corresponde con el número de características en los datos de origen (el tamaño del vector de descripción de un elemento de la secuencia).
Cada una de las incorporaciones generadas tiene su propio propósito funcional. Query yKey se utilizan para determinar las interdependencias entre los elementos de una secuencia, mientras que Value determina qué información de cada elemento de la secuencia debe transmitirse.
Para determinar los coeficientes de dependencia entre los elementos de una secuencia, deberemos multiplicar por pares la incorporación de cada elemento de la secuencia del tensor Query por las incorporaciones de todos los elementos del tensor Key (incluida la incorporación del elemento correspondiente). Al usar operaciones matriciales, solo necesitaremos multiplicar la matriz Query por la matriz Keytranspuesta.
![]()
Luego dividiremos los valores resultantes por la raíz cuadrada de la dimensionalidad de la incorporación Key, y normalizaremos con la función Softmax en el contexto de los elementos de la secuencia de incorporaciones Query. Como resultado de esta operación obtendremos una matriz cuadrada de dependencias entre los elementos de la secuencia de datos de origen.
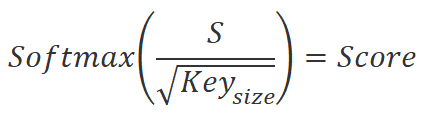
Aquí deberemos prestar atención a 2 puntos:
- Gracias a la función Softmax, hemos obtenido coeficientes de dependencia normalizados en el rango de 0 a 1. En este caso, la suma por líneas de los coeficientes será igual a 1.
- Para crear las incorporaciones Query y Key, usaremos matrices diferentes. Esto significa que hemos obtenido diferentes incorporaciones para el mismo elemento de la secuencia de datos de origen. Este enfoque nos permitirá obtener finalmente una matriz de coeficientes de dependencia no diagonal, donde el coeficiente de dependencia del elemento A respecto al elemento B y el coeficiente de dependencia inversa del elemento B respecto al elemento A serán diferentes.
En este punto, merece la pena recordar el propósito de esta acción. Como hemos mencionado anteriormente, nos gustaría obtener un modelo que pueda generar gráficos de dependencia entre varios objetos y eventos. Describiremos cada objeto o evento usando vectores de características en el tensor de datos inicial, mientras que la matriz de coeficientes de dependencia obtenida será una representación del gráfico deseado en forma de tabla, en la que los valores cero de los coeficientes indicarán la ausencia de vínculos entre los nodos correspondientes de los datos de origen, y los valores distintos de cero determinarán la influencia ponderada de un nodo sobre el valor de otro.
Volvamos al algoritmo auto-atención: los coeficientes de dependencia obtenidos los multiplicaremos por las incorporaciones correspondientes en el tensor Value. A continuación, sumaremos los valores obtenidos de las incorporaciones "ponderadas" y el vector resultante será la salida del bloque de auto-atención para el elemento de la secuencia analizado. Al usar operaciones matriciales, para nosotros será suficiente utilizar la función de multiplicación de matrices. La multiplicación de la matriz cuadrada de los coeficientes de dependencia por el tensor Value nos dará el tensor de resultados deseado del bloque de auto-atención.
![]()
Ya describimos anteriormente el algoritmo de auto-atención en el caso simple con una sola cabeza de atención. En la práctica, se usa principalmente la variante de atención multi-cabeza. En dicha implementación, se añade una matriz adicional de reducción de dimensionalidad que se encarga de reducir la dimensionalidad del tensor concatenado de todas las cabezas de atención a la dimensionalidad de los datos de origen.
Al final del algoritmo de auto-atención, se contempla la suma del tensor de datos de origen con el resultado del bloque de atención y la posterior normalización de los valores obtenidos.
Como podemos ver, en la entrada y salida del bloque de auto-atención tenemos tensores del mismo tamaño. Solo en la salida obtendremos un tensor de valores normalizados en el que se maximizarán las características que tengan un impacto significativo en el resultado, mientras que se minimizará el valor de las características que no influyan en el resultado, además de los fenómenos de ruido. Como regla general, para reforzar este efecto, en los modelos se suelen utilizar varias unidades de atención consecutivas.
Sin embargo, el bloque de atención solo puede ayudarnos a resaltar las características esenciales: no nos proporciona una solución al problema. Por lo tanto, tras el bloque de atención se organizará un bloque de decisión. Como bloque de decisión podremos utilizar un perceptrón totalmente conectado o cualquier solución arquitectónica previamente analizada.
2. Implementación usando MQL5
En cuanto a la implementación, debo decir que no vamos a repetir el modelo del artículo original "Deep reinforcement learning with relational inductive biases". Solo aprovecharemos los desarrollos sugeridos y añadiremos un módulo relacional a nuestro modelo utilizando el módulo de curiosidad interna que creamos en el artículo anterior. Asimismo, crearemos una copia del asesor experto del artículo anterior y pondremos al archivo el nombre "RLL-Learning.mq5".
Como cambiar la arquitectura interna del modelo que estamos entrenando sin cambiar la capa de datos de origen y la capa de resultados no requiere modificar el algoritmo del asesor, simplemente podríamos crear nuevos archivos de modelo y no realizar cambios directamente en el código del asesor. Sin embargo, recientemente, en los comentarios a los anteriores artículos, he encontrado a menudo preguntas con errores de carga relativos a los modelos creados con la herramienta NetCreator. Por lo tanto, en este artículo, hemos decidido regresar a la descripción de la arquitectura del modelo en el código del asesor.
Obviamente, aún podemos usar la herramienta NetCreator para crear los modelos necesarios, pero entonces le pediré que preste atención a los siguientes aspectos.
En el código del asesor, el nombre del archivo del modelo se especificará usando una macrosustitución, por lo tanto, el modelo creado deberá corresponderse con el formato dado.
#define FileName Symb.Name()+"_"+EnumToString(TimeFrame)+"_"+StringSubstr(__FILE__,0,StringFind(__FILE__,".",0))
El nombre del archivo se compone de:
- El nombre del instrumento en cuyo gráfico se inicia el asesor experto. Especificaremos el nombre completo del instrumento en nuestro terminal, incluidos los prefijos y sufijos.
- El marco temporal especificado en los parámetros del asesor.
- El nombre del archivo del asesor sin extensión.
Todos los componentes anteriores estarán separados por un guión bajo.
Al nombre del archivo añadiremos la extensión:
- "nnw" - para el modelo entrenado,
- "fwd" - para el modelo avanzado (forward model),
- "inv" - para el modelo inverso (inverse model).
Los archivos de todos los modelos creados deberán colocarse en el directorio "Files" de nuestro terminal o "Common/Files". En este caso, el directorio con los archivos deberá coincidir con el indicador common que hemos especificado en el código del programa. El valor true de la bandera common se corresponde con el directorio "Common/Files".
bool CNet::Load(string file_name, float &error, float &undefine, float &forecast, datetime &time, bool common = true)
Pero volvamos al código de nuestro asesor experto. En la función OnInit, primero inicializaremos las clases para trabajar con indicadores.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED;
Luego intentaremos cargar los modelos previamente preparados. Debemos tener en cuenta que estamos intentando cargar modelos desde el directorio "Common/Files". Este enfoque permite usar el asesor sin realizar cambios tanto en el simulador de estrategias como en tiempo real. La cosa es que cuando el asesor experto se inicia en el Simulador de Estrategias, no accede al directorio "Files" del terminal, ya que, por motivos de seguridad, el simulador de estrategias crea “su propio sandbox” para cada agente de prueba. Al mismo tiempo, cada agente tiene acceso a un recurso de archivo compartido: el directorio "Common/Files".
//--- if(!StudyNet.Load(FileName + ".icm", true)) if(!StudyNet.Load(FileName + ".nnw", FileName + ".fwd", FileName + ".inv", 6, true)) {
En caso de fallo al cargar modelos previamente entrenados, crearemos una descripción de la arquitectura de los modelos utilizados. Hemos desplazado este subproceso al método aparte CreateDescriptions. Aquí simplemente lo llamaremos y verificaremos el resultado de las operaciones. En caso de fallo, eliminaremos los objetos innecesarios y saldremos de la función de inicialización del asesor con el resultado INIT_FAILED.
CArrayObj *model = new CArrayObj(); CArrayObj *forward = new CArrayObj(); CArrayObj *inverse = new CArrayObj(); if(!CreateDescriptions(model, forward, inverse)) { delete model; delete forward; delete inverse; return INIT_FAILED; }
Después de crear con éxito la descripción de los tres modelos requeridos, llamaremos al método de creación de modelos y nos aseguraremos de verificar el resultado de las operaciones del método.
if(!StudyNet.Create(model, forward, inverse)) { delete model; delete forward; delete inverse; return INIT_FAILED; } StudyNet.SetStateEmbedingLayer(6); delete model; delete forward; delete inverse; }
A continuación, especificaremos la capa neuronal del modelo entrenado con los resultados del codificador y eliminaremos los objetos de descripción de la arquitectura de los modelos creados que ya no sean necesarios.
En el siguiente paso, pasaremos el modelo al modo de entrenamiento y especificaremos el tamaño del búfer de reproducción de la experiencia.
if(!StudyNet.TrainMode(true)) return INIT_FAILED; StudyNet.SetBufferSize(Batch, 10 * Batch);
Luego estableceremos los tamaños de los búferes de indicador
//--- CBufferFloat* temp; if(!StudyNet.GetLayerOutput(0, temp)) return INIT_FAILED; HistoryBars = (temp.Total() - 9) / 12; delete temp; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
e indicaremos el tipo de ejecución de las operaciones comerciales.
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- return(INIT_SUCCEEDED); }
Con esto, daremos por finalizado el trabajo con el método de inicialización del asesor y pasaremos a trabajar con el método para crear la descripción de la arquitectura de los modelos CreateDescriptions.
bool CreateDescriptions(CArrayObj *Description, CArrayObj *Forward, CArrayObj *Inverse)
{
En los parámetros, este método obtendrá los punteros a tres arrays dinámicos para registrar las arquitecturas de los tres modelos creados:
- Description — el modelo entrenado,
- el modelo avanzado,
- el modelo inverso.
En el cuerpo del método, comprobaremos directamente los punteros obtenidos y, si fuera necesario, crearemos nuevos ejemplares de los objetos.
//--- if(!Description) { Description = new CArrayObj(); if(!Description) return false; } //--- if(!Forward) { Forward = new CArrayObj(); if(!Forward) return false; } //--- if(!Inverse) { Inverse = new CArrayObj(); if(!Inverse) return false; }
En este caso, además, controlaremos el proceso de realización de las operaciones, y en caso de fallo, finalizaremos el funcionamiento del método con el resultado False.
Tras crear con éxito los objetos necesarios, pasaremos al propiamente al subproceso de descripción de la arquitectura de los modelos creados. Primero describiremos la arquitectura del modelo entrenado. Después limpiaremos el array dinámico para escribir la descripción de la arquitectura del modelo y prepararemos una variable para escribir el puntero al objeto de descripción de la capa neuronal CLayerDescription.
//--- Model
Description.Clear();
CLayerDescription *descr;
Como de costumbre, primero crearemos la capa neuronal de los datos de origen. Como capa de datos de entrada, usaremos una capa neuronal completamente conectada sin función de activación. A continuación, especificaremos un tamaño de la capa neuronal igual a la cantidad de valores transmitidos al modelo. Permítame recordarle que para describir cada vela de datos históricos, transmitiremos 12 valores; entre ellos se encuentran la descripción de la propia vela y los valores de los indicadores analizados. Además, le transmitiremos el estado de la cuenta y el volumen de las posiciones abiertas, lo que sumará 9 valores más.
El algoritmo de descripción de la capa neuronal se repetirá para cada capa neuronal y constará de tres etapas. Primero, crearemos un nuevo ejemplar del objeto de descripción de la capa neuronal, sin olvidarnos de comprobar el resultado de la operación, ya que si se produce un error al crear el nuevo objeto, correremos el riesgo de obtener un error crítico al acceder a un objeto inexistente.
A continuación, definiremos la descripción de la capa neuronal. Aquí, el número de parámetros especificados variará según el tipo de capa neuronal creada. Para la capa de datos de entrada, especificaremos el tipo de capa neuronal, el número de elementos en la capa neuronal, el tipo de optimización de parámetros y la función de activación.
Tras introducir todos los parámetros necesarios de la capa neuronal, añadiremos el puntero al objeto de descripción de la capa neuronal al array dinámico de la descripción de la arquitectura del modelo.
//--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = HistoryBars * 12 * 9; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
La experiencia a la hora de entrenar redes neuronales sugiere que el proceso de aprendizaje resulta más estable cuando se utilizan datos iniciales normalizados. Para normalizar los datos durante el entrenamiento y la explotación de prueba, usaremos una capa de normalización por lotes. La crearemos justo después de la capa de datos de origen.
Aquí, como antes, primero crearemos un nuevo ejemplar del objeto de descripción de la capa neuronal y verificaremos el resultado de la operación. A continuación, especificaremos el tipo de la capa neuronal creada defNeuronBatchNormOCL. El número de elementos se corresponde con el tamaño de la capa neuronal anterior, y el tamaño del lote de normalización. Después de eso, añadiremos el puntero al objeto de descripción de la capa neuronal al array dinámico de la descripción de la arquitectura del modelo.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Después de normalizar los datos, crearemos un bloque de preprocesamiento. Aquí utilizaremos capas neuronales convolucionales para buscar patrones en los datos originales.
Como antes, crearemos un nuevo ejemplar del objeto de descripción de capa neuronal CLayerDescription. Luego especificaremos el tipo de capa neuronal defNeuronConvOCL, e indicaremos una ventana de análisis de datos de 3 elementos. Asimismo, estableceremos el paso de la ventana de datos en 1. Con estos parámetros, el número de elementos en un filtro será 2 elementos menor que el tamaño de la capa anterior. Para maximizar el potencial, crearemos 16 filtros en esta capa neuronal. Semejante cantidad de filtros parece demasiado elevada, pero queríamos que el modelo fuera lo más flexible posible. Como función de activación, usaremos LeakReLU, mientras que para optimizar los parámetros, utilizaremos Adam.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count - 2; descr.window = 3; descr.step = 1; descr.window_out = 16; descr.activation = LReLU; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
El siguiente paso no será precisamente estándar. Después de la capa convolucional, estamos acostumbrados a usar una capa de submuestreo para reducir la dimensionalidad, pero en este caso, estamos tratando con series temporales, y además de los valores en sí, necesitaremos monitorear la dinámica de los cambios en las características. Con este objetivo, hemos decidido realizar un experimento e instalar un bloque LSTM después de la capa convolucional. Obviamente, su tamaño será inferior al de la salida de la capa convolucional, pero gracias a la arquitectura del bloque recurrente, esperamos conseguir una reducción de la dimensionalidad con la vista puesta en los estados previos del sistema.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 300; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Para revelar estructuras más complejas, repetiremos el bloque de capas neuronales convolucionales y recurrentes una vez más.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 100; descr.window = 3; descr.step = 3; descr.window_out = 10; descr.activation = LReLU; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 100; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
A continuación, llegaremos al bloque relacional de nuestro modelo entrenado. Aquí usaremos un bloque multicapa y multi-cabeza de auto-atención. Para hacer esto, especificaremos el tipo de capa neuronaldefNeuronMLMHAttentionOCL. Luego indicaremos un número de elementos de la secuencia de datos de origen igual al número de velas analizadas. En este caso, el número de características que describen una vela será 5.
No confunda el número de características que describen una vela en la entrada del modelo y en la entrada del bloque relacional, dado que, desde antes del bloque relacional, se ha realizado el procesamiento primario de datos mediante capas neuronales convolucionales y recurrentes.
Estableceremos el tamaño del vector Keys en 16, y el número de cabezas de atención en 64. Al igual que sucede con los filtros de las redes neuronales convolucionales, hemos indicado un número elevado de cabezas de atención para poder analizar exhaustivamente la situación actual del mercado.
Crearemos 4 capas de este tipo, pero no guardaremos 4 veces esta descripción de la capa neuronal. En su lugar, estableceremos el parámetro layers en 4.
Como en todos los casos anteriores, usaremos el método de optimización de parámetros Adam. Y la función de activación en este caso no estará indicada, ya que todas las funciones de activación son determinadas por el algoritmo de construcción de la capa neuronal.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = 20; descr.window = 5; descr.step = 64; descr.window_out = 16; descr.layers = 4; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Para completar la descripción de la arquitectura del modelo entrenado, solo nos queda indicar la capa de la función cuantil completamente parametrizada. En la descripción de esta capa neuronal indicaremos únicamente el tipo de capa neuronal defNeuronFQF, el espacio de acción, el número de cuantiles y el método de optimización de parámetros.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = 4; descr.window_out = 32; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Con esto concluiremos el subproceso de descripción de la arquitectura del modelo entrenado, pero todavía necesitamos los modelos Forward e Inverse . Hemos tomado su arquitectura por completo del artículo anterior, pero para que el asesor experto funcione correctamente, deberemos añadir su descripción en nuestro método. El subproceso de descripción repite al completo el proceso descrito anteriormente.
Primero, limpiaremos el array dinámico de la descripción de la arquitectura del modelo avanzado, y luego añadiremos la capa neuronal de los datos de origen. Para el modelo avanzado, el tamaño de la capa de datos de entrada será igual al vector concatenado del tamaño de la salida del codificador del modelo principal y el espacio de posibles acciones del agente.
//--- Forward Forward.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 104; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
Lo siguiente será una capa neuronal completamente conectada de 500 elementos con la función de activación LReLU y el método de optimización Adam.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = LReLU; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
En la salida del bloque avanzado, esperaremos obtener el siguiente estado de salida del codificador del modelo. Por lo tanto, este modelo se completará con una capa neuronal totalmente conectada con un número de neuronas igual al tamaño del vector a la salida del codificador del modelo. No utilizaremos la función de activación, y, al igual que antes, usaremos Adam como método de optimización de parámetros.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 100; descr.activation = None; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
Aplicaremos un enfoque similar a la construcción del modelo inverso, solo que suministraremos a la entrada de este bloque el vector concatenado de los dos estados posteriores. Por ello, el tamaño de la capa de datos de origen será 2 veces mayor que el tamaño de la salida del codificador del modelo.
//--- Inverse Inverse.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 200; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
La segunda capa neuronal será similar a la misma capa del modelo avanzado.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = LReLU; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
A la salida del modelo inverso, esperaremos obtener la acción aplicada. Por lo tanto, el tamaño de la siguiente capa neuronal será igual al espacio de acciones permitidas del agente, solo que esta capa no utilizará la función de activación. En su lugar, utilizaremos la siguiente capa Softmax.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 4; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = 4; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; } //--- return true; }
El código posterior del asesor lo hemos trasladado sin cambios del artículo anterior. Encontrará el código completo del asesor y todas las bibliotecas utilizadas en el archivo adjunto.
3. Simulación
El modelo ha sido entrenado y probado en el simulador de estrategias utilizando los datos históricos del instrumento EURUSD en el marco temporal H1. Asimismo, hemos usado los parámetros del indicador por defecto.

Como resultado del entrenamiento del modelo, hemos obtenido un aumento del balance en el simulador de estrategias. A pesar de que tenemos una media de 2 transacciones perdedoras por cada 2 rentables y la proporción de transacciones rentables es del 53,7%, en general, vemos un aumento bastante uniforme en el gráfico de balance y equidad, ya que la transacción ganadora promedio es un 12,5% más alta que la transacción perdedora promedio. El factor de beneficio es de 1,31, mientras que el factor de recuperación alcanza 2,85.


Conclusión
En este artículo, nos hemos familiarizado con el uso de los enfoques relacionales en el campo del aprendizaje por refuerzo. Asimismo, hemos añadido un bloque relacional al modelo y lo hemos entrenado usando el módulo de curiosidad intrínseca. Los resultados de la prueba han mostrado la capacidad de este enfoque para el entrenamiento de los modelos, así como la posibilidad de crear sobre su base asesores que generen beneficios.
Nos gustaría enfatizar que el asesor experto presentado en el artículo es capaz de realizar transacciones comerciales, sin embargo, no está listo para su uso en el comercio real. El asesor experto se presenta únicamente para mostrar la tecnología analizada. Antes de usar el asesor experto en cuentas reales, este deberá sufrir mejoras significativas y pruebas exhaustivas en varias condiciones.
Enlaces
- Neural Machine Translation by Jointly Learning to Align and Translate
- Effective Approaches to Attention-based Neural Machine Translation
- Attention Is All You Need
- Deep reinforcement learning with relational inductive biases
- Redes neuronales: así de sencillo (Parte 8): Mecanismos de atención
- Redes neuronales: así de sencillo (Parte 10): Multi-Head Attention (atención multi-cabeza)
- Redes neuronales: así de sencillo (Parte 11): Variaciones de GTP
- Redes neuronales: así de sencillo (Parte 35): Módulo de curiosidad intrínseca (Intrinsic Curiosity Module)
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | RRL-learning.mq5 | Asesor | Asesor para el entrenamiento del modelo. |
| 2 | ICM.mqh | Biblioteca de clases | Biblioteca de clases para organizar el modelo |
| 3 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 4 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/11876
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hola Dmitry Gizlyk,
Gracias por tus maravillosos artículos.
¡Por favor ayuda! Cuando trato de entrenar en Strategy Tester usando Ryzen 9 6900hx (APU), me dio este error y la EA no tenía ninguna transacción.
¿Cómo solucionar este problema hermano?
Hola Dmitry,
¡Gracias por el impresionante trabajo! Este es el mejor tutorial hasta ahora en la red con respecto a ML en la plataforma MQL5
Los detalles están bien explicados y pueden ser entendidos por el nuevo alumno.
Siguiendo su tutorial, he corrido Strategy Tester y al parecer, sólo uno de mis procesadores fueron utilizados a pesar de que hay 12 disponibles como se muestra en la siguiente imagen
¿Hay alguna manera de activar todos los núcleos en lugar de sólo uno?
SO Windows 11 build 22H2
Soporte OpenCL 3.0
CPU Intel i5-12400 ghz.html)
GPU Intel UHD Graphic 730 (integrado)
RAM 16gb
OpenCL ya están habilitados en la configuración de Metatrader.
¡Gracias por el tutorial detallado!
Hola Dmitry,
¡Gracias por el impresionante trabajo! Este es el mejor tutorial hasta ahora en la red con respecto a ML en la plataforma MQL5
Los detalles están bien explicados y pueden ser entendidos por el nuevo alumno.
Siguiendo tu tutorial, he ejecutado Strategy Tester y al parecer, sólo uno de mis procesadores fueron utilizados a pesar de que hay 12 disponibles como se muestra en la siguiente imagen
¿Hay alguna manera de activar todos los núcleos en lugar de sólo uno?
SO Windows 11 build 22H2
Soporte OpenCL 3.0
CPU Intel i5-12400 ghz.html)
GPU Intel UHD Graphic 730 (integrado)
RAM 16gb
OpenCL ya están habilitados en la configuración de Metatrader.
¡Gracias por el tutorial detallado!
Hola, en el probador de la estrategia sólo se puede ver el uso de un núcleo. Es utilizado por el programa mql, no OpenCL. OpenCL utiliza núcleos de GPU o CPU en el sistema fuera del monitor de Strategy tester. Hay varias maneras de ver el consumo de recursos de un programa OpenCL en Windows:
1. Utilizar software de monitorización del rendimiento como MSI Afterburner o GPU-Z, que muestran el uso de la GPU y otros componentes del sistema. También pueden mostrar qué porción de recursos está utilizando cada programa OpenCL.
2. Utilizar perfiladores como AMD CodeXL o NVIDIA Nsight Visual Studio Edition. Permiten analizar un programa OpenCL y mostrar qué partes del código consumen más tiempo y recursos.
3. Utiliza la API OpenCL para recopilar estadísticas. Esto le permite obtener mediante programación información sobre el uso de los recursos OpenCL, como el uso de memoria o el rendimiento del núcleo. Puede utilizar la biblioteca Performance Counters for OpenCL (PCPerfCL) para recopilar esta información en Windows.
4. Utilice herramientas de creación de perfiles como Intel VTune Amplifier, que pueden ayudarle a ver cómo utiliza un programa los recursos del procesador y de otros componentes del sistema.
Buenas tardes, Dimitri.
Por favor, ayúdame a ejecutar tu Asesor Experto de este artículo. He intentado todo para que funcione, pero por desgracia no funciona correctamente.
El problema es el siguiente: el Asesor Experto se inicia en el probador y comienza la prueba en el probador normalmente, cuenta atrás de los segundos, barra verde, no hay errores en el registro, normalmente ve la tarjeta de vídeo y la selecciona. Pero hay 0% de carga en la tarjeta de vídeo. Es como si no contara nada en ella. En Common\Files hay 2 archivos con extensiones icm y nnw con tamaño 1 kb. Cuando intento reiniciar de nuevo la prueba en el tester, me avisa de que no puede inicializar y la prueba no arranca. Si reinicio MT5 y borro los ficheros creados por este EA en Common\Files, arranca normalmente, pero tampoco utiliza la tarjeta de video y vuelve a crear estos ficheros de 1 kb. y así sucesivamente.
Traté de tomar NeuroNet.mqh archivos del siguiente artículo (que ha publicado en los comentarios) y la sustitución de la del artículo con él - no ayudó. Traté de seleccionar un pequeño período de tiempo en el probador (1 mes, 1 semana, 2 meses, etc) también no ayudó.
¿Cómo iniciarlo? Los Asesores Expertos de artículos anteriores se ejecutan normalmente y utilizan la tarjeta de vídeo correctamente.
También hay un problema con el Asesor Experto del siguiente artículo 37, 38. Por el contrario, no hay ningún progreso en el probador, pero la tarjeta de vídeo se utiliza al máximo y así por lo menos 5 horas, incluso 10 horas.
El Asesor Experto del artículo 39 funcionó bien. Allí elegí el histórico de más de 1 mes y no creaba la base de datos, pero elegí 1 mes y creaba la base de datos normalmente. El resto de sus partes funcionaban normalmente.
¡Esto es una verdadera joya, Dmitriy!
Soy un científico de datos con experiencia práctica en el desarrollo de diversos algoritmos de aprendizaje automático sobre datos de series temporales, y sin embargo encuentro tu serie informativa y bien escrita. Es una base valiosa sobre la que construir.
Gracias por compartir tu trabajo.
Bijan