Artículos sobre programación en el lenguaje MQL5
Aprenda el lenguaje de programación de estrategias comerciales MQL5 leyendo numerosos artículos la mayor parte de los cuales han sido escritos por Ustedes - miembros de MQL5.community. Con el fin de buscar rápidamente la respuesta sobre una u otra cuestión de programación, todos los artículos están divididos en categorías: "Integración", "Probador", "Estrategias comerciales", etc.
Siga las nuevas publicaciones y participe en sus discusiones en el foro de MQL5.community!
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Del básico al intermedio: Puntero a función
Probablemente ya hayas oído hablar de los punteros cuando se habla de programación. Pero ¿sabías que podemos hacer uso de este tipo de dato aquí, en MQL5? Esto, claro, de una manera que no nos haga perder el control ni genere comportamientos extraños durante la ejecución del código. Sin embargo, como es un recurso de uso muy específico y orientado a ciertos tipos de actividad, es difícil ver a alguien hablar sobre qué es un puntero y cómo usarlo en MQL5.

Red neuronal en la práctica: la práctica lleva a la perfección
En este artículo, mostraré cómo un simple cambio en el código, a fin de hacer que la neurona sea un poco más especializada, puede hacer que la fase de entrenamiento sea considerablemente más rápida Puesto que, una vez que la neurona, o red neuronal, como se verá más adelante, ya haya sido entrenada, el trabajo que realice será mucho más rápido. También hablaré de un problema que existe y que pocos mencionan

Características del Wizard MQL5 que debe conocer (Parte 61): Uso de patrones del ADX y el CCI con aprendizaje supervisado
El oscilador ADX y el oscilador CCI son indicadores de seguimiento de tendencias y de impulso que pueden combinarse al desarrollar un asesor experto. Analizamos cómo se puede sistematizar esto utilizando los tres modos principales de entrenamiento del aprendizaje automático. Los asesores expertos ensamblados por el Wizard MQL5 (Asistente MQL5) nos permiten evaluar los patrones que presentan estos dos indicadores, y comenzamos analizando cómo se puede aplicar el aprendizaje supervisado con estos patrones.

Procesos gaussianos en aprendizaje automático: modelo de regresión en MQL5
En este artículo, analizaremos los conceptos básicos de los procesos gaussianos (GP) como modelo de aprendizaje automático probabilístico y demostraremos su aplicación a problemas de regresión utilizando datos sintéticos.

Desarrollo de un kit de herramientas para el análisis de la acción del precio (Parte 21): Herramienta de detección de cambios en la estructura del mercado
El asesor experto (EA) «Market Structure Flip Detector» actúa como su socio vigilante, observando constantemente los cambios en el sentimiento del mercado. Mediante el uso de umbrales basados en el rango verdadero medio (ATR), detecta eficazmente los cambios de estructura y señala cada «máximo más bajo» y cada «mínimo más alto» con indicadores claros. Gracias a la rápida ejecución de MQL5 y a su API flexible, esta herramienta ofrece análisis en tiempo real que ajusta la visualización para una legibilidad óptima y proporciona un panel de control en directo para supervisar el número de cambios de estructura y los tiempos. Además, las notificaciones de sonido y push personalizables le garantizan que se mantenga informado de las señales críticas, lo que le permite comprobar cómo unos datos sencillos y unas rutinas de apoyo pueden transformar los movimientos de los precios en estrategias prácticas.

Redes neuronales en el trading: Framework de predicción cruzada de dominios de series temporales (TimeFound)
En este artículo, construiremos paso a paso el núcleo del modelo inteligente TimeFound, adaptado a tareas de pronóstico de series temporales del mundo real. Si está interesado en la implementación práctica de algoritmos de parcheo de redes neuronales en MQL5, está en el lugar correcto.

Aprendizaje automático y Data Science (Parte 37): Uso de patrones de velas japonesas e inteligencia artificial para superar al mercado
Los patrones de velas japonesas ayudan a los operadores a comprender la psicología del mercado e identificar tendencias en los mercados financieros, lo que permite tomar decisiones de inversión más informadas que pueden conducir a mejores resultados. En este artículo, exploraremos cómo utilizar los patrones de velas japonesas con modelos de IA para lograr un rendimiento óptimo en las operaciones comerciales.

Estudiamos la predicción conformal de series temporales financieras
En este artículo, nos familiarizaremos con las predicciones conformales y la biblioteca MAPIE que las implementa. Este enfoque es uno de los más modernos en aprendizaje automático y nos permite centrarnos en la gestión de riesgos para modelos de aprendizaje automático existentes y diversos. Las predicciones conformales, por sí mismas, no suponen una forma de encontrar patrones en los datos. Solo determinan el grado de confianza de los modelos existentes para predecir ejemplos específicos y permiten filtrar las predicciones fiables.
Características del Wizard MQL5 que debe conocer (Parte 60): Aprendizaje por inferencia (Wasserstein-VAE) con patrones de media móvil y oscilador estocástico
Concluimos nuestro análisis de la combinación complementaria del MA (media móvil) y el oscilador estocástico examinando qué papel puede desempeñar el aprendizaje por inferencia en un contexto posterior al aprendizaje supervisado y al aprendizaje por refuerzo. Evidentemente, existen multitud de maneras de abordar el aprendizaje por inferencia en este caso; sin embargo, nuestro enfoque consiste en utilizar autoencoders variacionales. Exploramos esto en Python antes de exportar nuestro modelo entrenado en formato ONNX para su uso en un Asesor Experto generado con el Asistente en MetaTrader 5.

Aprendizaje automático y Data Science (Parte 36): Cómo lidiar con mercados financieros sesgados
Los mercados financieros no están perfectamente equilibrados. Algunos mercados son alcistas, otros bajistas y otros presentan comportamientos laterales que indican incertidumbre en cualquier dirección. Esta información desequilibrada, cuando se utiliza para entrenar modelos de aprendizaje automático, puede resultar engañosa, ya que los mercados cambian con frecuencia. En este artículo vamos a analizar varias maneras de abordar este problema.

Minería de datos de la CFTC en Python y creación de un modelo de IA
Hoy intentaremos extraer datos de la CFTC, descargar informes COT y TFF a través de Python, conectarlos con cotizaciones de MetaTrader 5 y un modelo de IA, y obtener pronósticos. ¿Qué son los informes COT en el mercado Forex? ¿Cómo usar los informes COT y TFF para realizar previsiones?

Minería de datos de los balances de los bancos centrales y obtención de un panorama de la liquidez global
La minería de datos del balance de los bancos centrales ofrece una imagen de la liquidez global en el mercado Forex y en las divisas clave. Hoy combinaremos datos de la Fed, el BCE, el BOJ y el PBoC en un índice compuesto y utilizaremos el aprendizaje automático para descubrir patrones ocultos. Este enfoque convierte los datos sin procesar en señales comerciales reales combinando el análisis fundamental y técnico.

Creación de un Panel de administración de operaciones en MQL5 (Parte X): Interfaz basada en recursos externos
Actualmente estamos aprovechando las capacidades de MQL5 para utilizar recursos externos, como imágenes en formato BMP, para crear una interfaz de inicio con un estilo único para el Panel de Administración de Operaciones. La estrategia que se muestra aquí resulta especialmente útil al empaquetar múltiples recursos, incluyendo imágenes, sonidos y más, para una distribución más eficiente. En este artículo exploramos cómo se implementan estas características para ofrecer una interfaz moderna y visualmente atractiva para nuestro New_Admin_Panel EA.

Desarrollamos un asesor experto multidivisas (Parte 27): Componente para mostrar textos de varias líneas
Si es necesario mostrar información textual en un gráfico, podemos utilizar la función Comment(), pero sus capacidades son bastante limitadas. Por ello, en este artículo, crearemos nuestro propio componente: un cuadro de diálogo de pantalla completa capaz de mostrar texto de varias líneas con configuraciones de fuente flexibles y soporte de desplazamiento.

Indicador del modelo CAPM en el mercado Forex
Adaptación del modelo CAPM clásico para el mercado de divisas Forex en MQL5. El indicador calcula el retorno esperado y la prima de riesgo según la volatilidad histórica. Los indicadores suben en los picos y valles, lo que refleja los principios fundamentales de fijación de precios. Aplicación práctica de estrategias de contra-tendencia y seguimiento de tendencia, considerando la dinámica de la relación riesgo-retorno en tiempo real. Incluye aparato matemático e implementación técnica.

Reimaginando las estrategias clásicas (Parte 14): Configuraciones de alta probabilidad
Las configuraciones de alta probabilidad son bien conocidas en nuestra comunidad de trading, pero lamentablemente no están bien definidas. En este artículo, nuestro objetivo será encontrar una forma empírica y algorítmica de definir con precisión qué constituye una configuración de alta probabilidad, identificándolas y explotándolas. Mediante el uso de árboles de potenciación de gradiente, demostramos cómo el lector puede mejorar el rendimiento de una estrategia de negociación arbitraria y comunicar mejor la tarea exacta que debe realizarse a nuestro ordenador de una manera más significativa y explícita.

Negociamos con opciones sin opciones (Parte 1): Teoría básica y emulación a través de activos subyacentes
El artículo describe una variante de emulación de opciones a través de un activo subyacente, implementada en el lenguaje de programación MQL5. Asimismo, se comparan las ventajas y desventajas del enfoque elegido con opciones bursátiles reales utilizando el ejemplo del mercado de futuros FORTS de la bolsa de Moscú MOEX y la bolsa de criptomonedas Bybit.

Operando con el Calendario Económico MQL5 (Parte 7): Preparación para la prueba de estrategias con análisis de eventos noticiosos basado en recursos
En este artículo, preparamos nuestro sistema de trading en MQL5 para la prueba de estrategias utilizando datos del Calendario económico almacenados como recurso, lo que permite analizarlos fuera del entorno en vivo. Implementamos la carga y el filtrado de eventos por tiempo, moneda e impacto, y luego lo validamos en el Probador de Estrategias. Esto permite realizar pruebas retrospectivas efectivas de estrategias basadas en noticias.

Redes neuronales en el trading: Extracción eficiente de características para una clasificación precisa (Final)
El framework Mantis transforma series temporales complejas en tokens informativos y sirve como una base sólida para un agente comercial inteligente en tiempo real.

Integración de un modelo de IA en una estrategia de trading MQL5 ya existente
Este tema se centra en la incorporación de un modelo de IA entrenado (como un modelo basado en redes LSTM o un modelo predictivo basado en aprendizaje automático) en una estrategia de trading MQL5 existente.
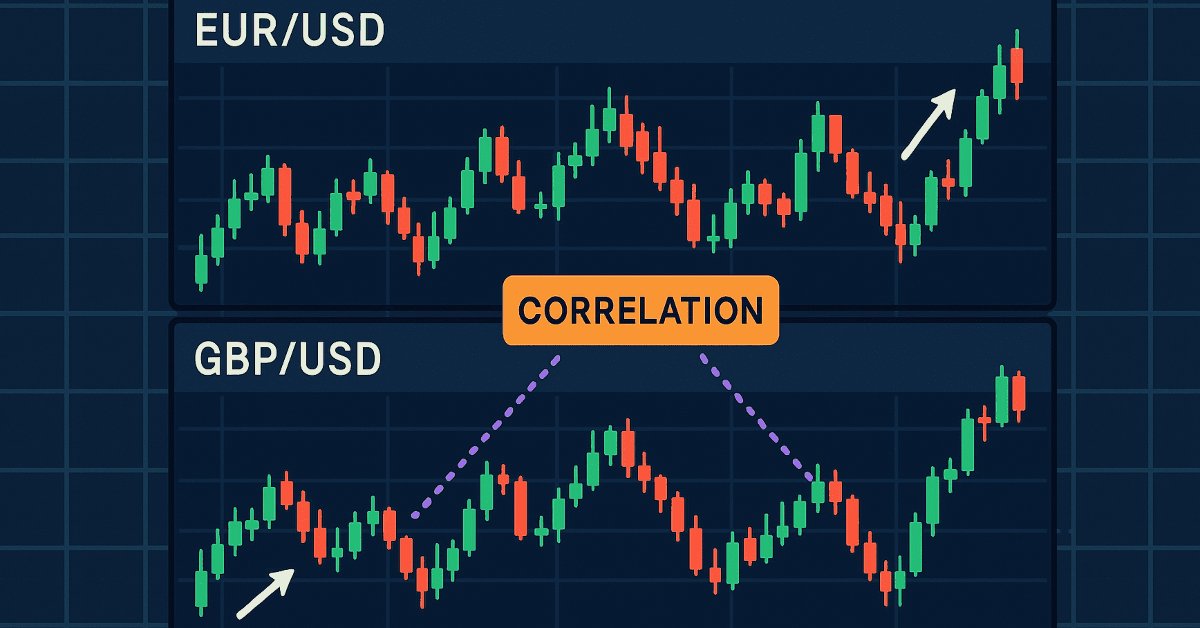
Desarrollo de un kit de herramientas para el análisis de la acción del precio (Parte 20): Flujo externo (IV) — Correlation Pathfinder
Correlation Pathfinder ofrece un nuevo enfoque para comprender la dinámica de los pares de divisas, como parte de la serie de desarrollo de herramientas de análisis de la acción del precio. Esta herramienta automatiza la recopilación y el análisis de datos, lo que permite comprender cómo interactúan pares como el EUR/USD y el GBP/USD. Mejora tu estrategia de trading con información práctica y en tiempo real que te ayudará a gestionar el riesgo y a detectar oportunidades de forma más eficaz.

Indicador de pronóstico ARIMA en MQL5
En este artículo, crearemos un indicador de pronóstico ARIMA en MQL5. El artículo analiza cómo el modelo ARIMA genera pronósticos y su aplicabilidad al mercado Forex y al mercado de valores en general. También explica qué es la autorregresión AR, cómo se utilizan los modelos autorregresivos para realizar pronósticos y cómo funciona el mecanismo autorregresivo.
Ingeniería de características con Python y MQL5 (Parte IV): Reconocimiento de patrones de velas japonesas mediante regresión con UMAP
Las técnicas de reducción de dimensiones se utilizan ampliamente para mejorar el rendimiento de los modelos de aprendizaje automático. Analicemos una técnica relativamente nueva conocida como Aproximación y Proyección de Variedades Uniformes (Uniform Manifold Approximation and Projection, UMAP). Esta nueva técnica se ha desarrollado con el objetivo expreso de superar las limitaciones de los métodos tradicionales, que generan artefactos y distorsiones en los datos. UMAP es una potente técnica de reducción de dimensionalidad que nos ayuda a agrupar velas japonesas similares de una manera novedosa y eficaz, lo que reduce el error en datos fuera de muestra y mejora nuestro rendimiento de trading.

Redes neuronales en el trading: Extracción eficiente de características para una clasificación precisa (Mantis)
Le presentamos a Mantis, un modelo básico ligero para la clasificación de series temporales basado en el Transformer con preentrenamiento contrastivo y atención híbrida que ofrece precisión y escalabilidad récord.

Creación de un Panel de administración de operaciones en MQL5 (Parte IX): Organización del código (V): Clase AnalyticsPanel
En este análisis veremos cómo obtener datos de mercado en tiempo real e información de la cuenta, calcular métricas y mostrar los datos en un panel personalizado. Para lograrlo, profundizaremos en el desarrollo de una clase AnalyticsPanel que englobe todas estas funcionalidades, incluida la creación de paneles. Este esfuerzo forma parte de nuestra continua expansión del Nuevo Panel de Administración EA, que introduce funcionalidades avanzadas utilizando principios de diseño modular y mejores prácticas para la organización del código.

Búsqueda oscilatoria determinista (DOS) — Deterministic Oscillatory Search (DOS)
El algoritmo de búsqueda oscilatoria determinista (DOS) es un método de optimización global innovador que combina las ventajas de los algoritmos de gradiente y enjambre sin usar números aleatorios. El mecanismo de oscilaciones e inclinaciones de aptitud permite a DOS explorar espacios de búsqueda complejos de manera determinista.
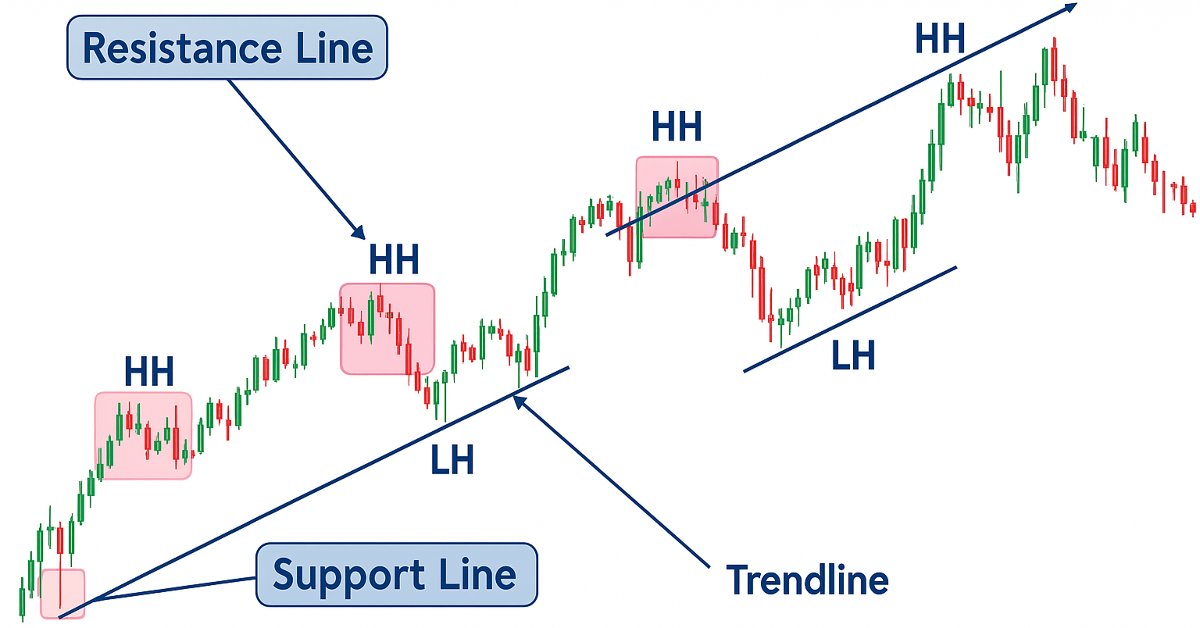
Desarrollo de un kit de herramientas para el análisis de la acción del precio (Parte 19): ZigZag Analyzer
Todos los traders que se basan en el movimiento de los precios utilizan manualmente las líneas de tendencia para confirmar las tendencias e identificar posibles niveles de cambio de tendencia o de continuación. En esta serie dedicada a la creación de un conjunto de herramientas para el análisis de la acción del precio, presentamos una herramienta diseñada para trazar líneas de tendencia inclinadas que facilitan el análisis del mercado. Esta herramienta simplifica el proceso para los traders al destacar claramente las tendencias y los niveles clave que resultan esenciales para evaluar eficazmente la evolución de los precios.

Redes neuronales en el trading: Generalización de series temporales sin vinculación a datos (Final)
En este artículo veremos cómo Mamba4Cast convierte la teoría en un algoritmo comercial funcional, allanando además el camino para experimentos propios. No pierda la oportunidad de adquirir una gama completa de conocimientos y lograr inspiración para desarrollar su propia estrategia.
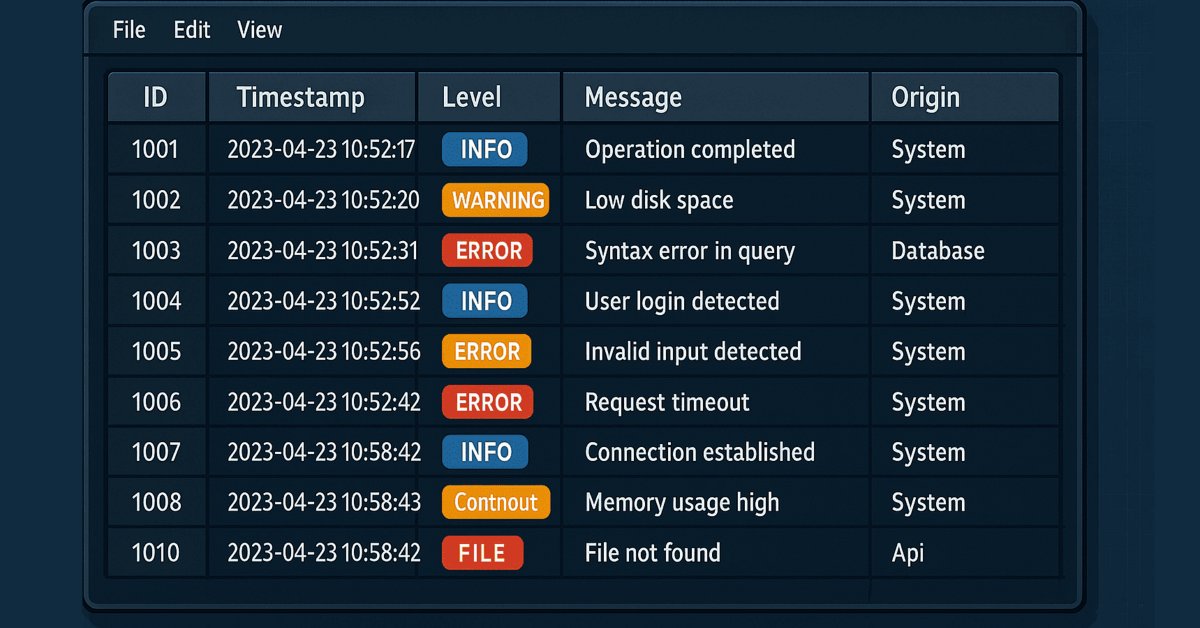
Dominando los registros (Parte 6): Guardando los registros en la base de datos
Este artículo explora el uso de bases de datos para almacenar registros de forma estructurada y escalable. Abarca conceptos fundamentales, operaciones esenciales, configuración e implementación de un controlador de base de datos en MQL5. Finalmente, valida los resultados y destaca los beneficios de este enfoque para la optimización y la monitorización eficiente.

Asesor de autoaprendizaje con red neuronal basada en matriz de estados
Asesor de autoaprendizaje con red neuronal basada en matriz de estados. Hoy combinaremos cadenas de Márkov con una red neuronal multicapa MLP, escrita en la biblioteca ALGLIB MQL5. ¿Cómo podemos combinar las cadenas de Márkov y las redes neuronales para realizar previsiones en Forex?

Creación de un Panel de administración de operaciones en MQL5 (Parte IX): Organización del código (IV): Clase sobre el Panel de gestión de operaciones
Esta discusión trata sobre el TradeManagementPanel actualizado en nuestro asesor experto New_Admin_Panel. La actualización mejora el panel mediante el uso de clases integradas para ofrecer una interfaz de gestión de operaciones fácil de usar. Incluye botones para abrir posiciones y controles para gestionar las operaciones existentes y las órdenes pendientes. Una característica clave es la gestión de riesgos integrada, que permite establecer los valores de stop loss y take profit directamente en la interfaz. Esta actualización mejora la organización del código para programas grandes y simplifica el acceso a las herramientas de gestión de pedidos, que a menudo son complejas en la terminal.

Redes neuronales en el trading: Generalización de series temporales sin vinculación a datos (Módulos básicos del modelo)
Seguimos familiarizándonos con el framework Mamba4Cast. Hoy profundizaremos en la implementación práctica de los enfoques propuestos. Mamba4Cast no ha sido diseñado para un largo periodo de calentamiento en cada nueva serie temporal, sino para un funcionamiento inmediato. Gracias al concepto de pronóstico Zero-Shot, el modelo es capaz de generar inmediatamente pronósticos de alta calidad sobre datos reales sin entrenamiento adicional ni ajuste de hiperparámetros.

Características del Wizard MQL5 que debe conocer (Parte 59): Aprendizaje por refuerzo (DDPG) con patrones de media móvil y oscilador estocástico (II)
Continuamos nuestro último artículo sobre DDPG con indicadores MA y estocásticos examinando otras clases clave de aprendizaje por refuerzo cruciales para la implementación de DDPG. Aunque programamos principalmente en Python, el producto final de una red entrenada se exportará como un archivo ONNX a MQL5, donde lo integraremos como un recurso en un Asesor Experto creado mediante un asistente.

Redes neuronales en el trading: Generalización de series temporales sin vinculación a datos (Mamba4Cast)
En este artículo, presentaremos el framework Mamba4Cast y analizaremos más de cerca uno de sus componentes clave: la codificación posicional basada en marcas temporales. Asimismo, mostraremos cómo se forma la incorporación temporal considerando la estructura de calendario de los datos.

Movimiento de precios: Modelos matemáticos y análisis técnico
Pronosticar los movimientos de los pares de divisas es un factor importante para el éxito en el trading. Este artículo explora varios modelos de movimiento de precios, analiza sus ventajas y desventajas y además explora su aplicación práctica en estrategias comerciales. Asimismo, consideraremos enfoques que nos permitirán identificar patrones ocultos y mejorar la precisión de los pronósticos.

Características del Wizard MQL5 que debe conocer (Parte 58): Aprendizaje por refuerzo (DDPG) con patrones de media móvil y oscilador estocástico
La media móvil y el oscilador estocástico son indicadores muy comunes cuyos patrones colectivos analizamos en el artículo anterior, mediante una red de aprendizaje supervisado, para ver qué «patrones se mantendrían». Partiendo de los análisis de ese artículo, vamos un paso más allá y analizamos los efectos que tendría en el rendimiento el aprendizaje por refuerzo, cuando se utiliza con esta red entrenada. Los lectores deben tener en cuenta que nuestras pruebas se han realizado en un periodo de tiempo muy limitado. No obstante, seguimos aprovechando los requisitos mínimos de programación que ofrece el Asistente de MQL5 (MQL5 Wizard) para mostrar esto.
Desarrollo de asesores expertos autooptimizables en MQL5 (Parte 6): Reglas de negociación autoadaptativas (II)
Este artículo analiza la optimización de los niveles y períodos del RSI para obtener mejores señales de trading. Presentamos métodos para estimar los valores óptimos del RSI y automatizar la selección de periodos mediante búsquedas por cuadrículas y modelos estadísticos. Por último, implementamos la solución en MQL5 mientras aprovechamos Python para el análisis. Nuestro enfoque pretende ser pragmático y directo para ayudarle a resolver problemas potencialmente complicados con sencillez.

Aprendizaje automático y Data Science (Parte 35): NumPy en MQL5, el arte de crear algoritmos complejos con menos código
La biblioteca NumPy impulsa casi todos los algoritmos de aprendizaje automático en el lenguaje de programación Python. En este artículo vamos a implementar un módulo similar que contiene una colección de todo el código complejo para ayudarnos a crear modelos y algoritmos sofisticados de cualquier tipo.

Desarrollo de un kit de herramientas para el análisis de la acción del precio (Parte 18): Introducción a la teoría de los cuartos (III) — Quarters Board
En este artículo mejoramos el script Quarters original con la introducción del Quarters Board, una herramienta que te permite alternar los niveles de cuartos directamente en el gráfico sin necesidad de volver a revisar el código. Puede activar o desactivar fácilmente niveles específicos, y el EA también proporciona comentarios sobre la dirección de la tendencia para ayudarle a comprender mejor los movimientos del mercado.
Características del Wizard MQL5 que debe conocer (Parte 57): Aprendizaje supervisado utilizando la media móvil y el oscilador estocástico
La media móvil y el oscilador estocástico son indicadores muy comunes que algunos operadores pueden no utilizar mucho debido a su naturaleza retardada. En una «miniserie» de tres partes que analiza las tres formas principales de aprendizaje automático, analizamos si este sesgo contra estos indicadores está justificado o si podrían tener alguna ventaja. Realizamos nuestro análisis con asesores expertos creados por el Asistente MQL5 (MQL5 Wizard)