
Del básico al intermedio: Paso por valor o por referencia

Introducción
El contenido presentado aquí tiene como único objetivo la enseñanza. En ningún caso debe considerarse como una aplicación final cuyo propósito no sea el estudio de los conceptos expuestos.
En el artículo anterior "Del básico al intermedio: Operadores", se explicó un poco sobre operaciones aritméticas y lógicas. Aunque fue algo bastante superficial, es suficiente para que podamos adentrarnos en otros temas. Con el paso del tiempo y a medida que se vayan escribiendo los artículos, profundizaremos gradualmente en los temas relacionados durante esta etapa inicial.
Por ello, ten paciencia y estudia con calma el material que se está publicando, ya que los resultados no se logran de la noche a la mañana. Aparecen con el tiempo. Y si estudias el material desde ahora, ni siquiera notarás que la carga se está incrementando. Dicho esto, como se mencionó en el artículo anterior, aquí empezaríamos a hablar de operadores de control. Sin embargo, antes de abordar este tema, es interesante hablar de otra cuestión. Esto hará que sea más entretenido y útil observar lo que se puede hacer con los operadores de control.
Para comprender de manera completa y perfecta lo que se explicará y presentará en este artículo, existe un requisito previo: entender y diferenciar entre una variable y una constante. Si no comprendes o desconoces esta diferencia, consulta el artículo "Del básico al intermedio: Variables (I)".
Uno de los aspectos que más dudas y errores genera en los programas de quienes están comenzando es saber cuándo usar valores o referencias en sus funciones y procedimientos. Esto se debe a que, dependiendo del caso, resulta más práctico el paso por referencia. Sin embargo, el paso por valor, en muchos casos, es más seguro. Entonces, ¿cuándo usar uno u otro? Depende, estimado lector. No existe una regla clara y definitiva para esta práctica. Esto se debe a que, en algunos casos, efectivamente se utiliza el paso por referencia, mientras que en otros se requerirá el paso por valor.
Normalmente, el compilador toma decisiones para que el código ejecutable sea lo más eficiente posible. Sin embargo, es necesario que entiendas lo que cada situación puede requerir. Para construir un código seguro y eficiente.
Paso por valor
Para empezar a entender esto en la práctica, lo más adecuado es utilizar un código lo más sencillo posible de implementar. Así que comenzaremos analizando un primer modelo de uso. Este será el paso por valor, aplicado en el código que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int info = 10; 07. 08. Print(__FUNCTION__, " : #1 => ", info); 09. Procedure(info); 10. Print(__FUNCTION__, " : #2 => ", info); 11. } 12. //+------------------------------------------------------------------+ 13. void Procedure(int arg1) 14. { 15. Print(__FUNCTION__, " : #1 => ", arg1); 16. arg1 = arg1 + 3; 17. Print(__FUNCTION__, " : #2 => ", arg1); 18. } 19. //+------------------------------------------------------------------+
Código 01
Cuando este código 01 sea ejecutado, verás en el terminal de MetaTrader 5 algo similar a lo que se muestra en la imagen 01, justo a continuación.
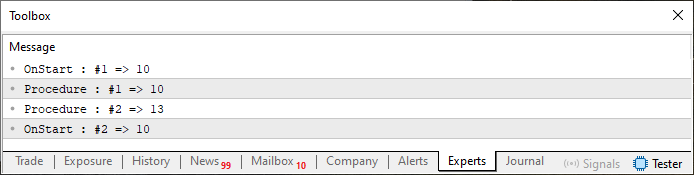
Imagen 01
Sé que para muchos lo que aparece en la imagen 01 puede parecer muy complejo. Pero como tú estás decidido a aprender de manera correcta cómo programar en MQL5, vamos a entender qué nos está diciendo esta imagen. Para ello, será necesario que sigas tanto lo que se ve en el código 01 como lo que se presenta en la imagen 01.
Con base en lo explicado en los artículos anteriores, ya deberías saber que en la línea seis estamos definiendo una variable con un valor específico. En la línea ocho, estamos imprimiendo esta misma variable. Sin embargo, al observar la imagen, notarás que aparecen otras informaciones adicionales. En este caso, es el nombre del procedimiento o función donde se encuentra la línea ocho.
Ahora presta atención, estimado lector. Durante la fase de compilación del código 01, el compilador, al encontrar la macro predefinida __FUNCTION__, buscará el nombre de la rutina actual. En este caso, el nombre se define en la línea cuatro, es decir, OnStart. Una vez identificado este nombre, el compilador sustituirá la palabra __FUNCTION__ por el nombre OnStart, creando así una nueva cadena de texto para ser impresa en el terminal. Esto ocurre porque el comando Print está dirigido a la salida estándar, que en este caso es el terminal, como puedes notar en la imagen 01. Por esta razón, obtenemos tanto la información de la rutina como el valor de la variable declarada en la línea seis. Existen otras macros predefinidas, y cada una resulta bastante útil en diferentes situaciones. Estúdialas, ya que facilitan enormemente el seguimiento de lo que está haciendo tu código. De la misma manera que __FUNCTION__ dentro de la rutina OnStart es sustituida por su nombre, __FUNCTION__ dentro de la rutina Procedure también será reemplazada. Así queda finalmente explicado qué significan esas informaciones que preceden a los valores numéricos.
Volvamos a la cuestión de entender el uso del paso por valor. Debido a que estamos empleando un sistema de paso por valor, al ejecutar la llamada en la línea nueve, el valor de la variable definida en la línea seis será transferido al procedimiento de la línea 13. Es importante destacar algo en este momento. Aunque digo que estamos pasando, o mejor dicho, copiando el valor de la variable info dentro de la variable arg1, esto no siempre sucede literalmente. En muchas ocasiones, el compilador, de manera bastante inteligente, hace que arg1 apunte hacia la variable info. Sin embargo, y es aquí donde la cuestión se pone realmente interesante, la variable arg1 no comparte la misma memoria que la variable info. Lo que ocurre es que el compilador establece que arg1 observe lo que hay en info en la memoria, de forma similar a mirar a través de una ventana de vidrio. Sin embargo, precisamente debido al vidrio, no puedes tocar el objeto observado. Lo mismo ocurre aquí: para arg1, info es vista como si fuera una constante.
Por esta razón, en la línea 15, pedimos imprimir el valor contenido en arg1. Al hacerlo, podemos observar en la segunda línea de la imagen 01 que muestra exactamente el mismo valor tanto para arg1 como para info. Sin embargo, en la línea 16, modificamos el valor de arg1. En este momento, durante la compilación, y sabiendo que esto ocurrirá durante la ejecución del código, el compilador reserva espacio para almacenar la misma cantidad de bytes que contiene la variable info. No obstante, esto no cambia el hecho de que arg1 continúa observando a info. Pero cuando se ejecuta la línea 16, lo que sucede es que arg1 utiliza el valor presente en la variable info como si info no fuera una variable, sino una constante. Esto hace que arg1 cree un valor local para sí misma. A partir de este momento, arg1 queda completamente desvinculada de la variable info, pasando a tener "vida propia". Por esta razón, en el momento en que se ejecuta la línea 17, vemos que la tercera línea es impresa en el terminal, mostrando que efectivamente el valor ha sido modificado.
Sin embargo, cuando el procedimiento retorna, llegamos a la ejecución de la línea 10, lo que hace que se imprima la cuarta línea de la imagen 01, mostrando que info continúa con su valor intacto.
Esto, estimado lector, es básicamente el mecanismo utilizado para el paso por valor. Claro, la forma exacta en que se implementa depende de cómo fue construido el compilador, pero esencialmente así es como funciona.
Muy bien, esta fue la parte fácil. Sin embargo, incluso este mecanismo de paso por valor puede aparecer en un código de manera algo diferente. No entraré en detalles sobre esto en este momento. Esto se debe a que, antes de mencionar otras formas de utilizar este mecanismo de paso por valor, será necesario explicar otros aspectos relacionados con operadores y tipos de datos. Aspectos que, si se abordaran aquí, complicarían más que aclarar. Así que vayamos con calma.No obstante, incluso este mecanismo que vimos arriba puede tener una modelación algo distinta. Esto para evitar precisamente lo que ocurrió en el código anterior. Para explorar esto de manera adecuada, hagamos una pequeña suposición. Por algún motivo, no deseas que la variable arg1 pueda modificar su valor. Quieres que simplemente observe la variable info, y que, cada vez que se use arg1, el valor presente en info sea el que realmente se utilice.
¿Cómo lograr esto? Existen varias formas y métodos. Uno de ellos consiste en tener mucho cuidado para no modificar la variable arg1 durante todo el bloque de código presente en el procedimiento. Sin embargo, aunque esto parezca sencillo, no lo es. Muchas veces, sin darnos cuenta, terminamos alterando el valor de una variable, y solo nos percatamos de ello debido a algún comportamiento extraño de la aplicación al ejecutarla. Este tipo de problemas puede hacernos perder mucho tiempo tratando de corregir el error. Pero hay otra solución: hacer que el compilador trabaje para nosotros, advirtiéndonos si intentamos hacer algo que no debería hacerse.
Para ilustrar esto con claridad, usemos el código que aparece a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int info = 10; 07. 08. Print(__FUNCTION__, " : #1 => ", info); 09. Procedure(info); 10. Print(__FUNCTION__, " : #2 => ", info); 11. } 12. //+------------------------------------------------------------------+ 13. void Procedure(const int arg1) 14. { 15. Print(__FUNCTION__, " : #1 => ", arg1); 16. arg1 = arg1 + 3; 17. Print(__FUNCTION__, " : #2 => ", arg1); 18. } 19. //+------------------------------------------------------------------+
Código 02
Al intentar compilar este código 02, recibirás el siguiente mensaje de error.

Imagen 02
Claramente puedes notar que el compilador indica que el error se encuentra en la línea 16. Esto sucede porque estamos intentando cambiar el valor de la variable arg1. Pero un momento. Ahora arg1 ya no es una variable; es una constante. Por lo tanto, durante todo el código presente en el procedimiento, ya no podrás modificar el valor de arg1. Esto asegura que el riesgo que teníamos antes ya no tenga sentido, ya que el propio compilador se encargará de no permitir la modificación de arg1. Es decir, saber lo que estás haciendo y contar con los conceptos adecuados es de gran ayuda. Facilita enormemente el trabajo de programación.
¿Entonces no podemos modificar el valor que se imprimirá en la línea 17 del código 02? Sí, estimado lector, podemos modificar el valor, siempre que lo asignemos a otra variable, incluso si esta no está explícita en el código. Así, para obtener el mismo resultado que el mostrado en la imagen 01, pero utilizando algo similar al código 02, podemos emplear un código muy parecido al que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int info = 10; 07. 08. Print(__FUNCTION__, " : #1 => ", info); 09. Procedure(info); 10. Print(__FUNCTION__, " : #2 => ", info); 11. } 12. //+------------------------------------------------------------------+ 13. void Procedure(const int arg1) 14. { 15. Print(__FUNCTION__, " : #1 => ", arg1); 16. Print(__FUNCTION__, " : #2 => ", arg1 + 3); 17. } 18. //+------------------------------------------------------------------+
Código 03
Al realizar los cambios, obtenemos el código 03, en el que arg1 sigue siendo una constante. Sin embargo, en la línea 16 de este código 03, estamos asignando el resultado de la suma de una constante, que en este caso es arg1, con otra constante, que es el valor tres, a una nueva variable. Esta será creada automáticamente por el compilador para permitir que Print pueda mostrar el valor correcto. Por supuesto, podrías crear una variable únicamente para este propósito. Sin embargo, no veo la necesidad de hacerlo, al menos no en este tipo de código que se está mostrando.
Paso por referencia
La otra manera de pasar valores entre rutinas es mediante referencia. En este caso, debemos tomar algunas precauciones adicionales. Pero antes de continuar, quiero hacer una pequeña pausa para explicar algo muy importante en este momento.
Tú, estimado lector, debes evitar al máximo utilizar el paso por referencia, salvo que sea realmente y extremadamente necesario hacerlo. Uno de los problemas más comunes y difíciles de solucionar en la programación es el uso inadecuado y descuidado del paso por referencia. En algunos casos, llega a convertirse casi en una costumbre o hábito de ciertos programadores, lo que hace que corregir y mejorar el código resultante sea un verdadero tormento. Por lo tanto, evita al máximo utilizar el paso por referencia, especialmente si el objetivo es modificar solo un único valor. Te mostraré un ejemplo de esto en un momento, pero antes veamos un caso en el que se utiliza el paso por referencia y cómo afecta a la aplicación. Para ello, emplearemos el siguiente código.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int info = 10; 07. 08. Print(__FUNCTION__, " : #1 => ", info); 09. Procedure(info); 10. Print(__FUNCTION__, " : #2 => ", info); 11. } 12. //+------------------------------------------------------------------+ 13. void Procedure(int & arg1) 14. { 15. Print(__FUNCTION__, " : #1 => ", arg1); 16. arg1 = arg1 + 3; 17. Print(__FUNCTION__, " : #2 => ", arg1); 18. } 19. //+------------------------------------------------------------------+
Código 04
Ahora presta mucha, pero muchísima atención a lo que voy a mencionar en esta parte. Aquí la situación puede complicarse, especialmente cuando estés trabajando en códigos realmente complejos. Al ejecutar este código, verás en el terminal de MetaTrader 5 la salida que se muestra en la imagen a continuación.
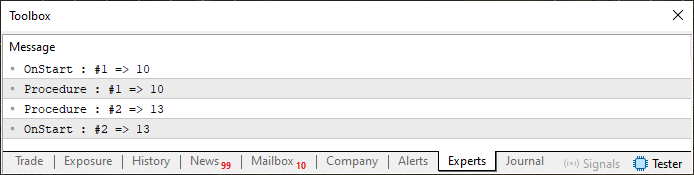
Imagen 03
Este tipo de situación, cuando ocurre de manera no intencionada, puede hacerte perder horas, días e incluso meses tratando de entender por qué el código no está funcionando como debería. Observa que el resultado es completamente diferente al mostrado en la imagen 01, especialmente en lo que respecta a la cuarta línea en la figura 03. Pero ¿por qué ocurrió esto? Si aparentemente el código 04 es idéntico al código 01, no tiene sentido que la cuarta línea de la imagen 03 sea diferente de la cuarta línea de la imagen 01.
Bueno, estimado lector, aunque parezcan idénticos, los códigos 01 y 04 tienen una pequeña pero crucial diferencia. Esta diferencia se encuentra precisamente en la línea 13. Me he asegurado de dejarlo bien evidente para que puedas entenderlo. Observa la presencia de un símbolo aparentemente inofensivo que está en el código 04, pero no en el código 01. Este símbolo < & >, conocido como AMPERSAND, es la causa de la diferencia entre la imagen 03 y la imagen 01. Normalmente, este mismo símbolo se utiliza en operaciones de lógica bit a bit para realizar una operación AND cuando hablamos de MQL5. Pero en C y C++, además de servir para operaciones AND, también se usa para referenciar variables en memoria.
¡Vaya! Aquí la cosa se pone seria. Porque si ya es complicado entender lo que puede significar un simple símbolo, imagina que dentro del mismo contexto de código pueda tener dos significados completamente diferentes. Es, literalmente, una locura. Por eso programar en C y C++ es tan complicado y requiere mucho tiempo para convertirse en un programador realmente bueno. Sin embargo, en MQL5, las cosas son un poco más simples. Al menos no enfrentamos toda la complejidad que existe en C y C++, principalmente porque MQL5 no utiliza directamente un recurso muy presente en C y C++: los punteros.
Para que entiendas correctamente, estimado lector, por qué la presencia de este símbolo en la línea 13 del código 04 influye en el resultado final, es necesario comprender qué significa realmente este símbolo. Para ello, explicaré el concepto de puntero presente en C y C++, pero sin adentrarme en las cuestiones complicadas que rodean este concepto.
Un puntero es como una variable, pero no una variable cualquiera. Es una variable que, como su nombre indica, apunta a algo. En este caso, un puntero señala una posición de memoria donde realmente existe otra variable. Sé que esto puede parecer confuso. Usar una variable para apuntar a otra variable es un concepto mucho más complicado de lo que parece. Sin embargo, este concepto es ampliamente utilizado en C y C++ para producir los más variados estilos de código. y es una de las razones por las que C y C++ son de las lenguas de programación más rápidas que existen, al nivel del lenguaje ensamblador en términos de velocidad de procesamiento. Pero sin entrar en detalles sobre estos punteros, ya que eso podría confundirte por completo, lo importante aquí es que, cuando arg1 se declara como en el código 04, NO ESTAMOS usando una forma convencional de instanciar la variable info. De hecho, el compilador de MQL5 trata a arg1 como un puntero a la variable info.
Por esta razón, cuando hacemos algo como la suma presente en la línea 16, lo que estamos modificando no es la variable arg1. NO, y repito, NO ESTAMOS SUMANDO la variable arg1. Lo que realmente estamos modificando es la variable info, porque tanto info como arg1 comparten el mismo espacio de memoria. En otras palabras, dentro de la rutina Procedure, arg1 e info son lo mismo; arg1 es info e info es arg1.
¿Es confuso? En efecto, esto es apenas la parte sencilla y manejable de trabajar con punteros. Como MQL5 NO USA (o mejor dicho, no nos permite usar) punteros al estilo de C y C++, aquí termina la explicación de cómo arg1 puede modificar info. Solo necesitas pensar en arg1 e info como la misma entidad, aunque estén en lugares diferentes y aparentemente sin ningún vínculo visible entre ellas. En C y C++, este tipo de comportamiento es mucho más complejo. Y como no quiero causar confusión en tu mente, estimado lector, todo se reduce a lo que hemos explicado hasta este punto.
Ahora surge una pregunta: ¿Existe alguna forma de bloquear esta modificación? Es decir, ¿cómo podemos evitar que arg1, incluso cuando sea modificada en la línea 16, altere también la variable info? Sí, estimado lector, hay formas de impedir que arg1 modifique info. Una de ellas es utilizando el paso por valor, como se explicó en el tema anterior. Otra forma es modificar el código 04 para que se parezca al que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int info = 10; 07. 08. Print(__FUNCTION__, " : #1 => ", info); 09. Procedure(info); 10. Print(__FUNCTION__, " : #2 => ", info); 11. } 12. //+------------------------------------------------------------------+ 13. void Procedure(const int & arg1) 14. { 15. Print(__FUNCTION__, " : #1 => ", arg1); 16. arg1 = arg1 + 3; 17. Print(__FUNCTION__, " : #2 => ", arg1); 18. } 19. //+------------------------------------------------------------------+
Código 05
Sin embargo, al hacer lo que se muestra en el código 05, nos enfrentamos al mismo problema que vimos en el código 02. Es decir, ahora arg1 será tratada como una constante. Por esta razón, intentar compilar este código 05 producirá el mismo resultado que intentar compilar el código 02, reflejado en la imagen 02. Aunque arg1 esté apuntando a info, que es una variable, y pueda parecer un error, en realidad no lo es. En muchas ocasiones, nos vemos obligados, o mejor dicho, forzados, a realizar algo como lo mostrado en el código 05. Pero este no se podrá compilar precisamente porque la línea 16 intenta modificar arg1. La solución final para este problema será adoptar algo similar al código 03, dando origen al código que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int info = 10; 07. 08. Print(__FUNCTION__, " : #1 => ", info); 09. Procedure(info); 10. Print(__FUNCTION__, " : #2 => ", info); 11. } 12. //+------------------------------------------------------------------+ 13. void Procedure(const int & arg1) 14. { 15. Print(__FUNCTION__, " : #1 => ", arg1); 16. Print(__FUNCTION__, " : #2 => ", arg1 + 3); 17. } 18. //+------------------------------------------------------------------+
Código 06
Maravilloso, con esto tenemos un código que funciona y se asemeja mucho al código 03. Sin embargo, a diferencia del código 03, que utiliza el paso por valor, aquí estamos empleando el paso por referencia. El resultado de la ejecución de este código 06 será el mismo que se muestra en la imagen 01.
En este punto, podemos retomar el tema planteado al inicio de este apartado: evitar usar el paso por referencia para modificar el valor de una única variable.
Si, por cualquier motivo, necesitas que una rutina modifique el valor de una variable, especialmente una de tipo básico, deberías preferir el uso de una función en lugar de un procedimiento. Por eso las funciones existen en los lenguajes de programación. No fueron creadas para embellecer el código, sino para prevenir problemas en su ejecución.
Ahora, suponiendo que realmente quieres que la variable info sea modificada, no desde el código donde se encuentra, sino desde una rutina que hayas creado, la forma correcta, o mejor dicho, la más adecuada de hacerlo es usando un código similar al que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int info = 10; 07. 08. Print(__FUNCTION__, " : #1 => ", info); 09. info = Function(info); 10. Print(__FUNCTION__, " : #2 => ", info); 11. } 12. //+------------------------------------------------------------------+ 13. int Function(const int & arg1) 14. { 15. Print(__FUNCTION__, " : #1 => ", arg1); 16. 17. return arg1 + 3; 18. } 19. //+------------------------------------------------------------------+
Código 07
Observa que en este código 07, seguimos utilizando el paso por referencia. Sin embargo, aquí no ocurren situaciones indeseadas. Esto se debe a que, mirando la línea 09, notamos que el valor de info será modificado de manera completamente controlada por nuestro código. Difícilmente un código escrito de esta manera, utilizando funciones, generará problemas. El resultado de la ejecución de este código 07 puede observarse justo a continuación.
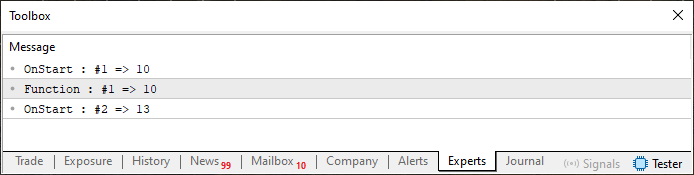
Imagen 04
Nota que en ningún momento quedamos con dudas sobre lo que está ocurriendo. Basta con mirar el código para comprender la razón por la cual el valor de info fue modificado dentro del bloque OnStart. Ahora, presta atención para no hacer algo como lo que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. int info = 10; 07. 08. Print(__FUNCTION__, " : #1 => ", info); 09. info = Function(info); 10. Print(__FUNCTION__, " : #2 => ", info); 11. } 12. //+------------------------------------------------------------------+ 13. int Function(int & arg1) 14. { 15. Print(__FUNCTION__, " : #1 => ", arg1); 16. 17. return (arg1 = arg1 + 3) + 3; 18. } 19. //+------------------------------------------------------------------+
Código 08
Es muy común que algunos programadores intenten alcanzar un objetivo y terminen creando una gran confusión. Este código 08 es un ejemplo de ello. Sé que no es un ejemplo completamente adecuado, ya que este tipo de situación suele darse en operaciones muy complejas que involucran muchas variables y pasos. Sin embargo, este caso sirve únicamente para ilustrar una posible condición problemática.
Ahora te pregunto, estimado lector: ¿Cuál es el valor de info que se imprimirá en la línea 10 del código 08? Bueno, tal vez no lo hayas notado, pero arg1 ya no es una constante. Entonces, ¿cuál es el valor de info que se imprimirá en la línea 10? Quizás esto te haya resultado algo confuso debido a la línea 17 y al hecho de que tanto el valor retornado como el valor asignado a la variable info están siendo modificados al mismo tiempo. Pero antes de explicar por qué no es tan confuso como parece, veamos el resultado impreso en el terminal, el cual puede observarse en la imagen 05 a continuación.
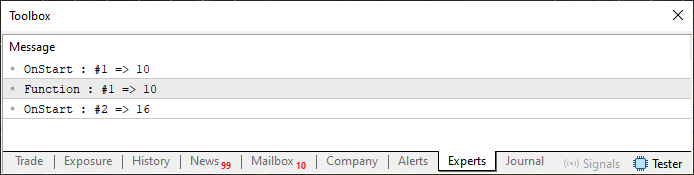
Imagen 05
Observa que el valor no es 13, sino 16. ¿Por qué? El motivo es que, aunque arg1 es un puntero a info y en la línea 17 estamos asignando el valor 13 para ser utilizado en arg1 y, por consiguiente, en info, el valor de retorno sobrescribe el valor 13. Esto ocurre porque el retorno de la función está sumando otros 3 al valor asignado en la línea 17. Por lo tanto, el resultado impreso es efectivamente 16, ya que el retorno de la función se está asignando a la variable info.
Sin embargo, si en lugar de asignar el valor a info en la línea 9 simplemente ignoraras el valor que retorna la función, seguramente terminarías en la misma situación que en los códigos anteriores. Es decir, el valor de info sería modificado, pero tratar de entender el código y corregirlo te llevaría bastante tiempo solo para localizar el error. Y recuerda este hecho: normalmente, los códigos que contienen este tipo de fallos suelen estar compuestos por varios archivos con cientos de líneas en cada uno, lo que implica un trabajo considerable para encontrar dónde está el problema.
En cuanto al valor de retorno, no es raro que muchas veces sea simplemente ignorado, ya que no estamos obligados a asignarlo o incluso a utilizarlo. Por esta razón, ten cuidado al implementar este tipo de estructuras en tus códigos. A pesar de las grandes ventajas que el paso por referencia puede ofrecer, no es difícil ni improbable que en algún momento tengas problemas con este enfoque, especialmente si tienes poca experiencia en programación.
Bien, como último punto a tratar aquí, existe otro problema relacionado con el paso por referencia. En muchas ocasiones, ocurre debido a un error al pasar los argumentos a la rutina que los procesará. Cuando trabajamos con el paso por valor, las posibilidades de fallos derivados de una sustitución accidental de un argumento por otro tienen un efecto limitado en el código en general. A menudo, durante el proceso de compilación, recibimos algún tipo de alerta del compilador al respecto, siempre y cuando los tipos de datos esperados sean diferentes. Pero cuando usamos el paso por referencia, a veces el compilador nos alerta de que hay un fallo, aunque no detectamos que la causa es el orden incorrecto de los argumentos. Esto puede derivar en un error que hace aún más difícil localizar la falla en una aplicación. Por ejemplo, supongamos que quieres crear una función en la que indiques una fecha y una hora específica. La función suma una cantidad de horas que proporcionas y, además, quieres que convierta el tiempo a segundos en la variable correspondiente al número de horas. Esto parece una tarea bastante sencilla y práctica, y puede realizarse con el código que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. uint info = 10; 07. datetime dt = D'17.07.2024'; 08. 09. Print(__FUNCTION__, " : #1 => ", info, " :: ", dt); 10. dt = Function(dt, info); 11. Print(__FUNCTION__, " : #2 => ", info, " :: ", dt); 12. } 13. //+------------------------------------------------------------------+ 14. datetime Function(ulong &arg1, datetime arg2) 15. { 16. Print(__FUNCTION__, " : #1 => ", arg1, " :: ", arg2); 17. 18. return arg2 + (arg1 = arg1 * 3600); 19. } 20. //+------------------------------------------------------------------+
Código 09
Sin embargo, al solicitar al compilador que cree el ejecutable, este genera una alerta como la que se muestra a continuación. Este tipo de alerta no impide que el código sea compilado.

Imagen 06
Pero, como eres un programador que siempre presta atención a cada mensaje enviado por el compilador, revisas inmediatamente la línea mencionada y haces la corrección correspondiente. En este caso, simplemente se trata de dejar explícito que el valor del tipo ulong debe convertirse al tipo datetime. Un detalle importante: ambos tipos tienen la misma longitud en bits. Por eso, este tipo de alerta suele ser ignorado por muchas personas. Así, esa línea 18 del código 09 se modifica para quedar como se muestra a continuación.
return arg2 + (datetime)(arg1 = arg1 * 3600);
Ahora, el compilador ya no genera la alerta. Sin embargo, al ejecutar el código, para tu sorpresa y desconcierto total, el resultado es el que se muestra a continuación.
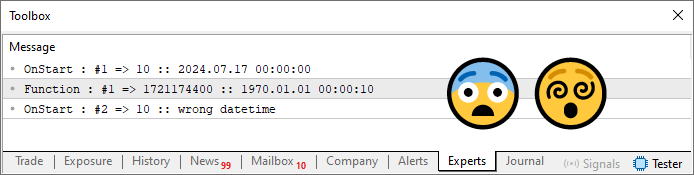
Imagen 07
En este momento, te sientes completamente desorientado, ya que aparentemente tu código no funciona. Y aquí es donde radica el gran detalle: tu código no está realmente mal. Solo tiene un pequeño error, y este tipo de error puede ser difícil de detectar. En este caso, es fácil identificarlo porque el código es, primero, simple y bastante corto. Segundo, estamos solo demostrando algunas funcionalidades básicas. En la práctica, rara vez tú u otro programador escribirán un pequeño fragmento de código para probarlo inmediatamente. Lo que suele ocurrir es que creas una serie de elementos que interactúan entre sí. En un momento dado, haces una prueba para verificar si todo funciona. A veces detectas un error, y otras veces no. Lo que hace que encontrar un fallo en un código más complejo sea especialmente difícil es que, con frecuencia, la rutina que causa el problema lo hace en algunas partes del código, mientras que en otras parece funcionar sin problemas. En este tipo de escenarios, resolver el problema se vuelve realmente complicado.
Para concluir, vamos entender dónde está el error aquí. Se encuentra precisamente en la línea diez. En este momento, podrías estar pensando: “¿Cómo es posible que el error esté en la línea 10? Con toda seguridad, el error está dentro de la rutina en la línea 14, probablemente en la línea 18. Definitivamente no está en la línea diez”.
Pero ahí es donde te equivocas, estimado lector. Presta atención y reflexiona conmigo. Quieres que la variable info contenga el valor final expresado en segundos y que la variable dt comience con la fecha declarada en la línea siete, pero ajustada en horas con base en la variable info. Este ajuste se realizará dentro de la rutina de la línea 14, específicamente en la línea 18. Hasta aquí todo parece correcto. Sin embargo, hay un pequeño error en el código. Como el tipo datetime ocupa 8 bytes y el tipo ulong también ocupa 8 bytes, la rutina no generará errores por la diferencia de tipos de datos. Pero nota que info es de tipo uint. Podrías pensar que el problema está aquí. Pero no es el caso. Como 24 horas contienen 86.400 segundos, el tipo uint, que ocupa 4 bytes, es suficiente para almacenar el valor correcto. Podrías usar un tipo de datos más pequeño, pero eso aumentaría el riesgo de errores en el valor retornado.
Ahora bien, como arg1 es un puntero, estará usando el paso por referencia, mientras que arg2 utiliza el paso por valor. Por lo tanto, el error está efectivamente en la línea diez, ya que el primer argumento debería ser la variable info, ya que es la que será modificada. La variable dt, en cambio, solo será ajustada con el valor que retorne la función. Teniendo esto en cuenta, corriges la línea diez con el código que se muestra a continuación.
dt = Function(info, dt);
Al intentar compilar el código, el compilador generará una advertencia indicando el siguiente error:
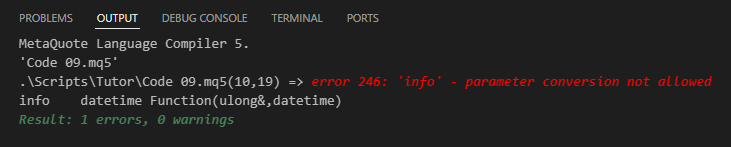
Imagen 08
Desesperado por hacer que el código funcione de cualquier manera, y sabiendo que no necesitas un valor de 8 bytes porque con uno de 4 bytes es suficiente, decides modificar la línea 14 como se muestra a continuación.
datetime Function(uint &arg1, datetime arg2)
Finalmente, el código es compilado, y al ejecutarlo, como por arte de magia, el tan esperado resultado se presenta correctamente, tal como se muestra en la imagen siguiente.
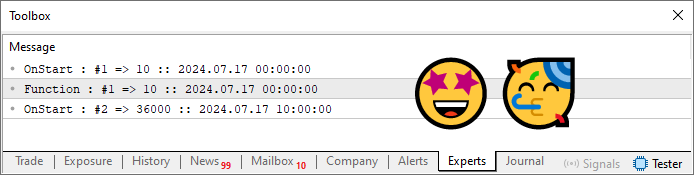
Imagen 09
Consideraciones finales
En este artículo se explicaron las sutilezas presentes en una programación real. Por supuesto, aquí todos los ejemplos son simples y están orientados a la enseñanza, pero aun así, no deja de ser extremadamente divertido y gratificante explicar cómo funcionan las cosas en realidad. Sé que muchos consideran este tipo de material poco interesante, especialmente aquellos que llevan bastante tiempo creando y desarrollando programas. Pero me pregunto: ¿Cuánto tiempo te tomó aprender lo que este sencillo artículo explicó de manera tan clara? Yo mismo tardé bastante en entender por qué mis códigos en C/C++ a veces hacían cosas extrañas y sin sentido, hasta que finalmente logré comprender cada detalle involucrado.
Una vez que entendí todo aquello, el resto se volvió mucho más simple y directo. Hoy en día, disfruto programando en varios lenguajes diferentes y hasta me divierto con los problemas que me presentan. Esto es porque logré construir una base sólida y confiable gracias a C/C++. MQL5 es un lenguaje mucho más agradable, simple y fácil de explicar que toda esa complejidad presente en C/C++. Sin embargo, si tú, estimado lector, logras comprender lo que se explicó y demostró en este artículo, podrás aprender de manera mucho más rápida a crear excelentes aplicaciones en MQL5. Así que, en el próximo artículo, finalmente podremos empezar con un material mucho más entretenido. Nos vemos allí.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15345
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hola. Inexactitud en el texto (subrayado con líneas rojas)
Saludos, Vladimir.
Hola. Inexactitud en el texto (subrayado con líneas rojas)
Saludos, Vladimir.
Gracias, corregido