
Del básico al intermedio: Precedencia de operadores

Introducción
El contenido expuesto aquí tiene un propósito puramente didáctico. En ningún caso debe considerarse una aplicación final cuyo objetivo no sea el estudio de los conceptos expuestos.
En el artículo anterior, "Del básico al intermedio: Comando FOR", hablamos sobre lo que sería lo más básico del comando FOR. Basándonos en aquel material, hasta el artículo anterior, tú, querido lector, ya podrás crear una buena cantidad de códigos en MQL5. Aunque se trate solo de aplicaciones simples y relativamente modestas, ya será algo que para muchos será un gran motivo de orgullo y satisfacción.
Esto se debe a que, aunque para otros programadores pequeños fragmentos de código creados por un principiante puedan parecer triviales, si ese principiante logra idear una solución para un problema al que se enfrenta, de hecho, es un motivo de orgullo. Sin crear falsas esperanzas, todo lo que se ha visto hasta ahora te permite, mi querido lector, crear únicamente código tipo script. Aunque sea bastante simple y con poca interacción, si lo has logrado por tu propio esfuerzo, significa que estás en el camino correcto y que ya estás comenzando a aplicar los conocimientos básicos mostrados hasta ahora.
Pero ahora ha llegado el momento de cambiar de tema. Este nos permitirá crear códigos aún más interesantes. Veremos aquí operadores. Aunque ya hemos hablado de esto antes, ahora daremos algunos pasos más. Esto se debe a que lo visto anteriormente era bastante básico y simple. Pero aquí veremos reglas de precedencia en la práctica, así como el operador ternario, que puede resultar bastante confuso para muchos, pero es extremadamente útil en muchas situaciones, ya que nos ahorra trabajo y esfuerzo en ciertas operaciones de programación.
Para poder seguir lo que se explicará en este artículo, es necesario comprender la declaración y el uso de variables en un código MQL5. Este tema se ha tratado en artículos anteriores. Si no tienes este conocimiento, te recomendamos que primero leas los artículos anteriores para poder entender este. Dicho esto, podemos comenzar con el primer tema de este artículo.
Reglas de precedencia
Entender y conocer las reglas de precedencia es muy importante. Ya lo mencioné en otro artículo. Sin embargo, aquí profundizaremos un poco más en este tema.
En la documentación, al buscar las reglas de precedencia, encontrarás un cuadro con ellas. No obstante, muchas personas no logran comprender adecuadamente su significado o la información que contienen. Si este es tu caso, querido lector, no necesitas sentirte avergonzado ni intimidado. Es algo muy común; al principio, solemos estar algo confundidos cuando nos enfrentamos a este tipo de información. Esto ocurre porque en la escuela no aprendemos las cosas de la misma manera en que las usamos aquí, como programadores.
Aunque en algunos casos ciertas factorizaciones realizadas por algunos programadores resulten algo confusas, muchas veces son correctas. Incluso cuando parezca que están arrojando un resultado diferente al esperado. Por esta razón, es fundamental comprender las reglas de precedencia. No es necesario que las memorices. Con la práctica y el uso continuo, acabarás acostumbrándote. Pero lo más importante es:
Si no entiendes tu propio código, es probable que otros tampoco lo hagan.
Por esta razón, siempre procura pensar en cómo otros podrían interpretar lo que estás intentando factorizar. Comencemos con el siguiente hecho. La tabla o cuadro mencionados al principio de este tema deben leerse de arriba abajo. Los operadores situados en la parte superior tienen mayor prioridad de ejecución. A medida que descendemos en la tabla, la prioridad disminuye gradualmente.
Sin embargo, hay un pequeño detalle que observar aquí. Para explicarlo, veremos la tabla de la figura inferior.
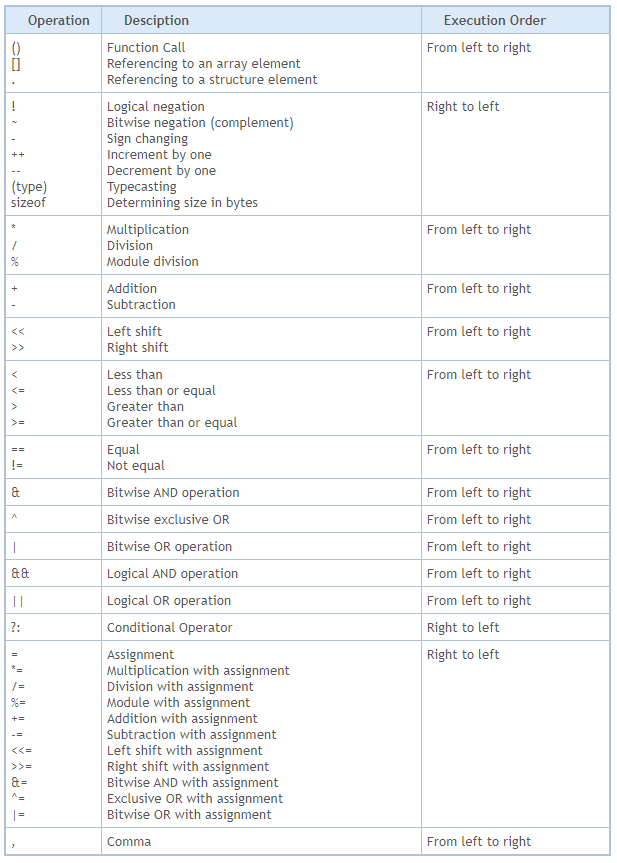
Imagen 01
Aquí puedes ver que los operadores están declarados en un orden concreto. Es muy importante observar esta secuencia. También puedes observar que están separados en grupos. Y es aquí donde mucha gente suele confundirse. Esto ocurre porque, al enfrentarnos a ciertos códigos, no sabemos cuál será el resultado de la factorización si no entendemos esta separación mostrada en la imagen 01. Esta separación es muy sencilla de entender y facilita mucho las cosas, ya que evita que tengas que memorizar las reglas de precedencia. En primer lugar, tenemos los operadores de referenciación. Estos tienen prioridad sobre todos los demás, ya que nos indican cómo acceder a un elemento determinado. Luego, tenemos los operadores binarios o de tipo. En este caso, siempre debemos leer el código de derecha a izquierda. Pero ¿cómo es eso? Tranquilo, querido lector, ya llegaremos a eso. Te explicaré cómo debes leer el código en estos casos. Ahora observa que esto es diferente a los operadores de referenciación, en los cuales el código debe leerse de izquierda a derecha.
Lo sé, esto parece una locura. Ahora puedes detenerte y preguntarte: "¿Por qué complican tanto las cosas?". Pero no se trata de complicaciones, querido lector. En la práctica verás que tiene todo el sentido. Sin verlo aplicado, realmente parece que estamos entrando en un lugar donde solo trabajan personas locas. Sin embargo, en la tercera división es donde comenzamos a hablar de cosas más comunes para muchos. Estos son los primeros operadores de funciones aritméticas. Y, en este caso, el código debe leerse de izquierda a derecha. Así continúa hasta el final de la imagen 01.
Ahora veremos un ejemplo práctico. Para ello, utilizaremos algunos códigos bastante simples y directos, en los que simplemente imprimiremos algunos valores. Esta es la parte fácil y divertida.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char value = 9; 09. 10. PrintX(value); 11. PrintX(++value * 5); 12. PrintX(value); 13. } 14. //+------------------------------------------------------------------+
Código 01
Ahora te pregunto, querido lector: ¿qué resultado se imprimirá en el terminal? Sin tener en cuenta la precedencia de los operadores, podrías decir que el resultado será 46, ya que estamos multiplicando la variable cuyo valor es nueve por una constante que vale cinco y luego sumamos una unidad. Sin embargo, estás EQUIVOCADO. El resultado de ejecutar este código 01 es 50, como se muestra en la siguiente imagen.
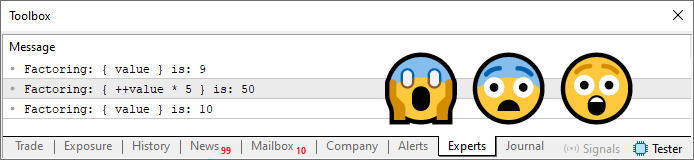
Imagen 02
¿Te pareció confuso? Bueno, ¿qué te parece si hacemos otra pequeña prueba, simplemente tocando un pequeño detalle en el código? Como puedes ver justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char value = 9; 09. 10. PrintX(value); 11. PrintX(value++ * 5); 12. PrintX(value); 13. } 14. //+------------------------------------------------------------------+
Código 02
El resultado de este código 02 se muestra a continuación.
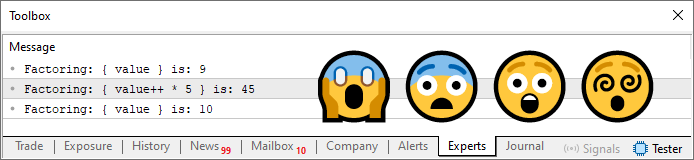
Imagen 03
¿No mencioné en el artículo anterior que nos lo pasaríamos en grande? Pues bien, podría seguir jugando con estas reglas de precedencia por un buen rato y mostrarte, mi querido lector, que, en el momento en que creas haber entendido todo y estés preparado para cualquier desafío, en realidad apenas estás poniéndote en pie e intentando dar tu primer paso.
Lo sé, y no necesitas decírmelo, parece una completa locura. Y que probablemente soy un lunático escapado de algún lugar donde solo trabajan personas cuerdas. Pero créeme, querido lector, la diversión apenas comienza. Y eso es solo el principio. Las cosas mejorarán aún más. ¿Qué te parece un código aún más interesante? Podemos empezar con el que ves justo aquí abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char v1 = 9, 09. v2 = 5; 10. 11. PrintX(v1); 12. PrintX(v2); 13. PrintX(v1 & 1 * v2); 14. PrintX((v1 & 1) * v2); 15. } 16. //+------------------------------------------------------------------+
Código 03
Es un código estupendo. Es maravilloso, especialmente cuando se ejecuta dentro de un bucle. Puedes observar el resultado que produce justo debajo.
Imagen 04
Ahora confiesa. Tú, al igual que yo, te estás divirtiendo viendo este tipo de cosas ocurrir, ¿no es así? Observa que la diferencia entre una respuesta y otra son, precisamente, los paréntesis que aparecen en una expresión y no en otra.
De hecho, existe una regla general para escribir este tipo de factorización. Aunque no esté explícita, existe de forma implícita entre los programadores. Y la regla dice lo siguiente:
Cuando programes una factorización, procura separar los términos en niveles de ejecución y delimita cada nivel con paréntesis. Así otros programadores podrán interpretarla más fácilmente.
De hecho, incluso cuando el resultado es obvio y sigue las reglas de precedencia de los operadores, si separas las cosas en términos de niveles de factorización, te resultará mucho más sencillo entender qué tipo de resultado esperas obtener. En algunos casos, ni siquiera el compilador puede interpretar claramente lo que intentas programar. ¿Quieres un ejemplo? El código mostrado a continuación es un ejemplo de una situación en la que el resultado es completamente impredecible, ya que ni siquiera el compilador puede comprender lo que debería hacerse.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char v1 = 9, 09. v2 = 5; 10. 11. PrintX(v1); 12. PrintX(v2); 13. PrintX(v1++ & 1 * v2 << 1); 14. PrintX(v1); 15. PrintX(v2); 16. } 17. //+------------------------------------------------------------------+
Código 04
En este caso, cuando intentes compilar este código 04, el compilador emitirá una advertencia. Esta advertencia aparece justo abajo.

Imagen 05
Nota que, a pesar de la advertencia, el compilador generó el código. Sin embargo, existe un peligro considerable de que este código no produzca el resultado esperado en ciertas situaciones. Por lo tanto, confiar ciegamente en este código es arriesgado, especialmente cuando el compilador lanza una advertencia de posible fallo en la factorización. En este tipo de casos, el uso de paréntesis es imprescindible. Pero, incluso sin hacer esto y utilizando únicamente las reglas de precedencia, comprobemos si el resultado sería correcto en este caso específico.
Para ello, ejecutamos el código y el resultado es el que podemos ver a continuación.
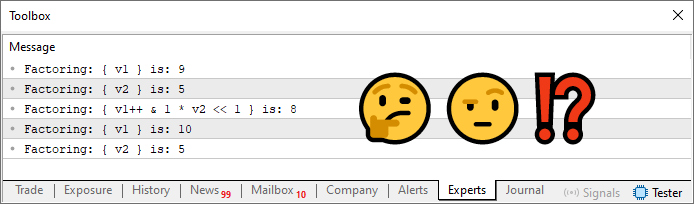
Imagen 06
Aquí, la respuesta fue el valor ocho. Pero, ¿realmente este valor es correcto? Bien, para saberlo, necesitamos realizar manualmente la factorización de lo que hizo el código. Este tipo de situación es muy común en programación. Muchas veces, y contrario a lo que muchos piensan, un programador no crea un código sin saber qué tipo de resultado debería generar. Un buen programador SIEMPRE sabe cuál será el resultado de la ejecución de su código. NUNCA crea algo cuyo resultado no conozca de antemano. Es decir, un buen programador realiza lo que se conoce como un backtest de su propio código y, posteriormente, un ForwardTest, donde los resultados son analizados uno por uno. Solo después de una batería de pruebas comienza a confiar un poco más en su código. Pero nunca confía ciegamente en todas las respuestas. Siempre mantiene cierto nivel de duda. Sin embargo, el motivo para mantenerse escéptico ante una respuesta específica se abordará en otro artículo. De momento, veamos si el valor ocho debería ser la respuesta correcta al código 04.
Para determinar si la respuesta es correcta, debemos entender cómo el compilador interpretó lo que se le pidió factorizar. Como el compilador sigue unas reglas estrictas definidas en la tabla de precedencia de operadores, podemos realizar una factorización manual del cálculo de la línea 13 y verificar si es correcta.
Para ello, primero identificamos el operador con mayor precedencia. Este sería el operador ++, que se aplica a la variable v1. Sin embargo, este operador trabaja de derecha a izquierda. Es decir, en este caso, su precedencia se modificará y se aplicará a la variable v1 solo después de que se ejecute el operador más a la derecha de mayor prioridad. En este caso, ese operador es el de multiplicación, que tiene mayor precedencia que el operador de desplazamiento hacia la izquierda y que el operador AND. Por lo tanto, la primera operación que se realiza es la multiplicación del valor 1 por el valor de v2, lo que da como resultado el valor cinco. A continuación, aplicamos el operador de desplazamiento hacia la izquierda, que desplaza el valor cinco un bit hacia la izquierda, generando el nuevo valor, que es diez. A continuación, se ejecuta la operación AND entre v1 y este valor diez. Como v1 es igual a nueve, al aplicar esta operación AND, el resultado es ocho. Finalmente, cuando se han ejecutado todos los operadores situados a la derecha, el valor de v1 se incrementará en una unidad. Por esta razón, obtenemos el valor ocho en la factorización y el valor diez para v1 cuando esta ha concluido.
Quizá estés pensando: «Lo entiendo, es todo muy simple, claro y directo». Pero, ¿es realmente así, mi querido lector? ¿De verdad has logrado comprender cómo funciona este procedimiento? Veamos. ¿Qué tal si me respondes cuál sería el resultado de la factorización que se está haciendo en el código que aparece justo debajo?
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char v1 = 9, 09. v2 = 5; 10. 11. PrintX(v1); 12. PrintX(v2); 13. PrintX(++v1 & 1 * v2 << 1); 14. PrintX(v1); 15. PrintX(v2); 16. } 17. //+------------------------------------------------------------------+
Código 05
Respóndelo sin dudar. Si realmente consigues responder esto correctamente, creeré que es posible que estés entendiendo cómo funciona la precedencia de los operadores. De todos modos, solo por diversión, te mostraré una respuesta y quiero que me digas si es correcta o incorrecta.
Cuando ejecuté este código, obtuve la respuesta que se ve justo abajo.
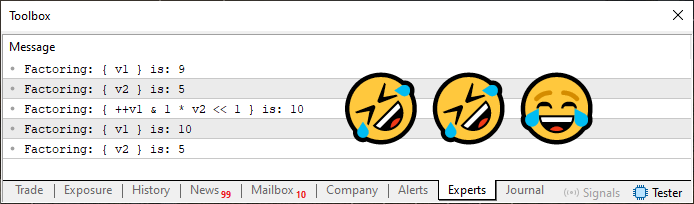
Imagen 07
Ahora dime: ¿por qué mi respuesta fue diez y no ocho? Hay un motivo para eso. De hecho, está relacionado con la regla de precedencia de los operadores. Bueno, mi querido lector, como no me gusta confundir a la gente, veamos por qué las respuestas son diferentes. Pero, para ello, abordemos un nuevo tema. No quiero sobrecargar la memoria de nadie en este artículo, ya que aún queda otro asunto por tratar.
BackTest y ForwardTest
Lo primero que necesitas entender, mi querido lector, es lo siguiente: antes de programar algo, debes saber cuál será la respuesta que dará tu código. Programar no consiste en generar un código para obtener una respuesta desconocida. Programar es exactamente lo contrario. Creas un código para obtener una respuesta que ya conoces. Y en este caso, tanto en el código 04 como en el código 05, yo ya sabía cuál sería la respuesta. Incluso siendo consciente de que podría ser incorrecta, precisamente debido a la advertencia del compilador. Pero, ¿cómo podría saber la respuesta antes siquiera de programar el código? Esto parece no tener sentido. En realidad, muchos te dicen que programes para descubrir la respuesta, pero conociendo las reglas de precedencia, puedes anticipar la respuesta antes de que te la den.
Para dejar esto bien claro, hagamos lo siguiente: como se menciona en el anexo, pondré estos códigos a tu disposición para que puedas hacer lo mismo que mostraré aquí. De esta forma, comprenderás por qué es importante conocer la respuesta antes de programar el código que te la dará.
La verdadera pregunta es la siguiente: ¿Cuál respuesta es correcta: la de la imagen 06 o la de la imagen 07? ¿Y si te dijera que ambas son correctas? ¿Qué me responderías? Probablemente pensarás que estoy loco, ya que una misma expresión no puede dar dos respuestas correctas. Pues bien, mi querido lector, aunque parezca una locura, las dos respuestas son correctas. Sin embargo, es mucho más probable que estuvieras buscando la respuesta de la imagen 07, mientras que la respuesta de la imagen 06 sería simplemente un efecto colateral de un mal uso de la precedencia de los operadores. Si usas paréntesis en el código 04 para corregir la precedencia de los operadores, la respuesta que dará el código será exactamente la que se ve en la imagen 07. Para ello no se necesita mucho; basta con ajustar las cosas para que el operador de incremento tenga mayor prioridad. En el caso del código 05, el hecho de que el operador esté delante de la variable lo coloca por encima del operador de multiplicación. Sin embargo, como se explicó en el tema anterior, el hecho de que esté después de la variable, como ocurre en el código 04, hace que el operador se ejecute más tarde.
¿No me crees? ¿Qué tal si hacemos una prueba para comprobarlo? Para ello, modifica la línea 13 del código 04 para que quede como se muestra justo abajo.
PrintX((v1++ & 1) * (v2 << 1));
Y, aun con este cambio, el compilador ya no indicará que el resultado es poco fiable. Sin embargo, el mismo código 04, que ha pasado por esta modificación sencilla, nos dará la respuesta que se ve en la imagen 07. Esto es lo que hace que la programación sea tan complicada. Muchas veces, las personas estudian programación por razones equivocadas. En realidad, el verdadero propósito es hacer que la computadora nos dé una respuesta conocida de manera más rápida. Cuando necesitamos saber algo para lo que no conocemos la respuesta, podemos considerar que la respuesta del ordenador es adecuada. Pero hay un límite para esta clase de confianza. Sin embargo, dentro de esos límites, la respuesta proporcionada tras una serie de pruebas, tanto con valores previamente conocidos como con aquellos que sabemos calcular, nos permite finalmente afirmar: "MI PROGRAMA PUEDE CALCULAR ESTO O AQUELLO". Antes de todas esas pruebas, es muy probable que tu código contenga errores, precisamente porque no ha sido debidamente probado.
De acuerdo, en este punto, dejaré que lo estudies con calma y reflexiones al respecto. Sin embargo, antes de terminar este artículo, quiero hablar de otra cuestión. Se trata de otro operador que no encaja con los que hemos visto hasta ahora. Así que vayamos al último tema.
Operador ternario
Este es mi operador favorito. Quienes realmente siguen y estudian mis códigos, que pueden encontrarse en diversos artículos de esta comunidad, ya deben estar cansados de verme utilizar este operador. Pero ¿por qué es mi favorito? La razón es simple: me permite crear expresiones sin necesidad de utilizar el comando IF. En muchos casos, necesitamos usar el comando IF para modificar el flujo de ejecución del código. Sin embargo, existen situaciones en las que podemos usar el operador ternario, incluso cuando el comando IF no sería viable. En mi opinión, este operador es de nivel intermedio. Es decir, para aprovechar plenamente el operador ternario es necesario dominar bien los demás operadores. Además, es fundamental entender muy bien cómo se producirá el cambio de flujo al usarlo, ya que rara vez se emplea de manera aislada. Casi siempre está asociado a un operador de asignación o a un operador lógico. Por esta razón, solo explicaré cómo debe interpretarse. De momento, no lo usaremos. O, al menos, intentaré no hacerlo por el momento.
Veamos un código sencillo en el que se podría utilizar este operador. De alguna manera, podría hacerse de otra forma, pero el objetivo aquí es puramente didáctico. Así que ignoren el hecho de que podría utilizarse otro método. Simplemente intenten entender el concepto utilizado aquí.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print("Factoring: { ", #X, " } is: ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. char v1 = 9, 09. v2 = 5; 10. 11. PrintX(v1); 12. PrintX(v2); 13. PrintX(v1 * ((v2 & 1) == true ? v2 - 1 : v2 + 1)); 14. PrintX(v2++); 15. PrintX(v1 * ((v2 & 1) == true ? v2 - 1 : v2 + 1)); 16. PrintX(v1); 17. PrintX(v2); 18. } 19. //+------------------------------------------------------------------+
Código 06
Cuando se ejecute este código 06, el resultado que se verá está mostrado en la imagen siguiente.
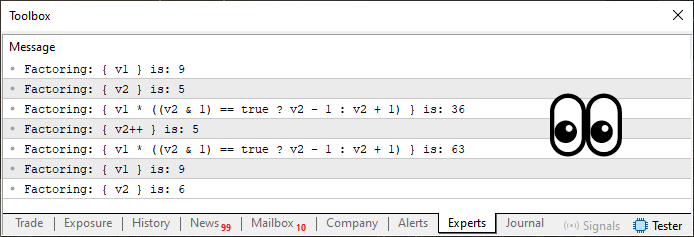
Imagen 08
Como este operador ternario puede resultar bastante confuso para mucha gente, especialmente para principiantes, explicaré con calma lo que está ocurriendo aquí. Sin embargo, es necesario que estudies todo el artículo para poder asimilar completamente su contenido. Estúdialo con calma y presta atención a lo que estoy explicando. Dado que el tema es bastante denso, es posible que te lleve un tiempo entenderlo del todo.
Volvamos al código 06. Gran parte de este código es fácil de entender. Claro que tenemos una macro, la cual aún no he explicado cómo utilizar en tus códigos. Pero incluso esta macro es bastante sencilla de comprender. Como se ha utilizado en otros códigos de este artículo, lo que explicaré aquí también se aplica a los demás códigos. La macro definida en la línea cuatro nos permite enviar algún tipo de información al terminal, dependiendo de lo que se use en el código. ¿Pero cómo? Para hacerlo, le enviamos un argumento. Este argumento, precedido por el símbolo de tres en raya ( # ), indica al compilador que debe tomar el argumento y presentarlo tal y como se implementó. Por esta razón, podemos mostrar el cálculo que se está realizando, así como el valor del resultado y, en algunos casos, el nombre de la variable utilizada. Es una buena forma de depurar ciertos tipos de código.
Bueno, pero esto es solo una parte de la historia. Lo que realmente nos interesa es cómo funcionan las líneas 13 y 15, ya que en ellas se encuentra el operador ternario. Para explicar esto de manera sencilla, tomemos solo una de las líneas como base de estudio, ya que la otra funciona de manera muy similar.
Por lo tanto, tomemos la línea 13 y descompongámosla para no usar el operador ternario, sino el comando IF. Pero, ¿por qué usar el comando IF para explicar el operador ternario? La razón es que el operador ternario es, esencialmente, un comando IF, pero con la capacidad de ser una expresión, lo que permite colocarlo en una parte del código como si fuera una variable. Sin embargo, a pesar de esta similitud con el comando IF, el operador ternario no lo sustituye, ya que no permite implementar bloques de código dentro de él. Esto es diferente del comando IF, que sí permite el uso de bloques de código, pero no puede utilizarse como una expresión dentro de un comando.
De acuerdo. Entonces, al traducir la línea 13, tendríamos algo similar a lo que se muestra a continuación.
if ((v2 & 1) == true) value = v1 * (v2 - 1); else value = v1 * (v2 + 1); Print("Factoring: { v1 * ((v2 & 1) == true ? v2 - 1 : v2 + 1) } is: ", value);
El único detalle aquí es la variable value, que en realidad no existe. Solo la estoy utilizando para explicar cómo el compilador interpreta las cosas. Por lo tanto, entiende la variable value como una variable temporal a la que no podrás acceder de ninguna manera.
Así, comprendiendo este concepto, es fácil entender cómo el compilador interpreta un operador ternario. Observa que, al usar el comando IF, todo el código se vuelve mucho más claro. unque, en ciertos casos donde el operador ternario es realmente necesario, esto sería algo prácticamente imposible de realizar. Pero, para fines didácticos, funciona. Lo mismo ocurre con el comando Print que se ve en este pequeño fragmento de traducción. Este comando está realizando la traducción de lo que sería el código de la macro.
De hecho, a primera vista, parece bastante complicado de comprender de forma repentina. Más aún porque, como ya mencioné, este tipo de codificación es, en mi opinión, una implementación de nivel intermedio. Así que no tengas prisa por entender todo lo que está ocurriendo, querido lector. Procura estudiar y practicar poco a poco. Sin embargo, cuando realmente comprendas que el operador ternario es un if especial, todo será mucho más fácil de asimilar a medida que se vayan presentando los próximos artículos.
Consideraciones finales
En este artículo solo presenté e intenté explicar algo que, sinceramente, es uno de los temas más complicados en términos de programación, si nos limitamos al campo teórico. En la práctica, este tema sobre operadores es mucho más sencillo y fácil de comprender y estudiar. Esto se debe a que, al observar el resultado de cada acción o forma de implementar algo, se hace más evidente que los programadores no intentan crear algo desconocido. Todo programa tiene como objetivo responder a algo que ya conocemos inicialmente. Sin embargo, a medida que la aplicación se prueba y ajusta, con el tiempo podemos usarla para obtener una respuesta más rápida a una cuestión específica.
Para finalizar, quiero darte un consejo: estudia y practica mucho en diferentes tipos de desafíos. Solo así podrás dominar adecuadamente la forma de utilizar cada uno de ellos. No creas que tener conocimientos teóricos sobre el tema será suficiente. Porque no es así. En el trabajo con operadores, la experiencia será mucho más importante que la teoría. Así que empieza a practicar.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15440
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso