
Del básico al intermedio: Arrays y cadenas (III)

Introducción
El contenido expuesto aquí tiene un propósito puramente didáctico. En ningún caso debe considerarse una aplicación final cuyo objetivo no sea el estudio de los conceptos expuestos.
En el artículo anterior, «Del básico al intermedio: Arrays y cadenas (II)», demostré de manera sencilla y fácil de comprender cómo podías aplicar los conocimientos adquiridos hasta ese momento. El objetivo era crear dos tipos de soluciones bastante simples, que mucha gente imaginaría que requieren mucho más conocimiento. Sin embargo, todo lo que se vio e implementó en ese artículo puede hacerlo cualquier principiante en programación. Eso sí, siempre y cuando utilice un poco de creatividad y aplique los conceptos mostrados hasta ese momento.
Sin embargo, aunque lo mostrado allí funcione de verdad y sea perfectamente posible de crear sin muchas dificultades, existe un pequeño detalle que puede frustrar a muchos principiantes. Este detalle tiene todo que ver con la aplicación presentada precisamente en ese artículo.
Muchos de ustedes deben haberse preguntado: ¿cómo es posible generar una contraseña a partir de dos textos o frases aparentemente sencillos? No logro entender cómo algo así puede funcionar. A pesar de haber seguido la idea y comprendido el código, para mí ese tipo de cosa no tiene ningún sentido. De hecho, querido lector, hay cosas en la programación que no tienen mucho sentido para quienes no son programadores. Una de estas cosas es precisamente lo que se hizo en ese artículo, donde manipulamos texto utilizando una matemática muy simple y básica.
Dado que este tipo de conceptos y enfoques se utilizan ampliamente en diversas actividades de programación, considero válido explicar con más detalle por qué funcionan. Sin duda, esto te ayudará a comenzar a pensar como un programador y no simplemente como un usuario. Por lo tanto, es probable que el tema principal de este artículo, que son los arrays, se posponga ligeramente. Aun así, hablaremos de arrays en este artículo, pero de una manera más sencilla. Así que comencemos con el primer tema para entender por qué lo que vimos en el artículo anterior funciona.
Traducción de valores
Una de las tareas más comunes en programación es la traducción y el tratamiento de información o bases de datos, y la programación tiene todo que ver con esto. Si estás pensando en aprender a programar, pero no entiendes o no has comprendido aún que el objetivo de una aplicación es crear datos que el ordenador pueda interpretar y luego traducir esos valores a información comprensible para los humanos, estás siguiendo un camino completamente equivocado. Es mejor detenerse y comenzar desde cero. Porque, en realidad, la programación se basa totalmente en este principio simple. Tenemos información y necesitamos hacer que el ordenador sea capaz de comprenderla. Una vez que el ordenador genera un resultado, debemos traducir ese resultado para que podamos entenderlo.
Los computadores son muy buenos trabajando con ceros y unos, pero son completamente inútiles si tienen que manejar cualquier otro tipo de información. Con las personas ocurre lo mismo: son pésimas para interpretar un montón de ceros y unos, pero comprenden perfectamente el significado de una palabra o una gráfica.
Ahora podemos hablar de manera más sencilla sobre algunos temas. Al inicio de la era de la informática, los primeros procesadores incluían en su conjunto de instrucciones, conocido como OpCode, códigos diseñados para trabajar con valores decimales. Sí, querido lector, los primeros procesadores eran capaces de entender lo que era un 8 o un 5. Estas instrucciones formaban parte del conjunto BCD, ya que permitían a los procesadores utilizar números que tenían sentido para nosotros los humanos, pero usando una lógica binaria. Sin embargo, con el tiempo, estas instrucciones BCD cayeron en desuso. Resultaba mucho más complicado enseñar, o mejor dicho, crear un circuito capaz de realizar cálculos decimales, que hacer los cálculos en binario y luego convertirlos a decimal. Por esta razón, se convirtió en responsabilidad del programador realizar y ejecutar esa traducción. Al principio, había una auténtica «ensalada de frutas» con respecto al manejo de números de punto flotante. Pero eso se explicará en otro momento. Con las herramientas actuales que se han presentado y explicado hasta este punto, no sería posible explicar cómo funciona el sistema de punto flotante. Antes de abordar el funcionamiento del punto flotante, necesito presentar algunos conceptos más.
Un detalle importante: este sistema BCD aún se utiliza, pero no de la forma que podrías estar imaginando. En un próximo artículo, exploraremos algo relacionado con este sistema BCD.
Volviendo a nuestra cuestión, así surgieron las primeras bibliotecas de traducción entre valores decimales y binarios, y viceversa. Incluso se pueden usar otras bases de datos, como la hexadecimal y la octal, que son las más comunes, aunque generalmente están orientadas a aplicaciones más específicas.
Bien. En este punto, llegamos a lo que se mostró en los artículos anteriores, donde demostré que en MQL5 existen funciones que nos permiten realizar esta traducción. En todos los casos, la transformación se basa en una cadena, ya sea como entrada o salida. Esta cadena representa la información que los humanos comprendemos, mientras que la parte binaria se envía al ordenador para su procesamiento. Sin embargo, aunque estas bibliotecas son muy prácticas y funcionan muy bien, ocultan gran parte del conocimiento sobre cómo manipular realmente los datos. Por esta razón, los cursos que enseñan ciertas lenguas no forman realmente programadores, sino personas que se creen programadores, pero que no entienden cómo funcionan las cosas en las capas subyacentes.
Como MQL5 nos da cierta libertad creativa, podemos crear algo similar a una de estas bibliotecas, aunque sea con fines exclusivamente didácticos. Sin embargo, es importante señalar lo siguiente: una biblioteca creada sin el uso de un lenguaje de bajo nivel no será más rápida ni eficiente que la biblioteca estándar del lenguaje. Y cuando hablo de lenguaje de bajo nivel, me refiero a programar en C o C++. Estos dos lenguajes permiten generar código muy similar al ensamblador puro, y nada será más rápido que ellos. Por lo tanto, el objetivo de lo que veremos aquí es meramente educativo.
Perfecto. Dada esta explicación inicial, crearemos un pequeño traductor. Con los conocimientos adquiridos hasta este punto, crearemos un traductor bastante simple. En este traductor, primero transformaremos valores binarios en hexadecimales o octales, ya que estas conversiones son más sencillas y no requieren muchas operaciones. Para ello, utilizaremos el código que se muestra a continuación como punto de partida.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64i\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. } 15. //+------------------------------------------------------------------+
Código 01
Cuando ejecutamos este código, se generará en el terminal lo que puedes ver en la imagen 01. Observa qué especificadores de formato se han utilizado aquí. Si se usan otros, el resultado será diferente. Experimenta con esto después para comprender mejor su funcionamiento.
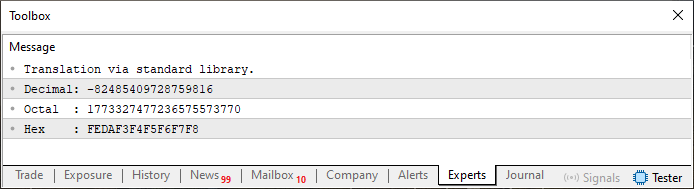
Imagen 01
Nota que es bastante simple, práctico y directo. Pero, ¿cómo logra la biblioteca estándar esto? Bien, esta es la «magia» que veremos a continuación, querido lector. Pero antes, es necesario que entiendas otra cosa: la formatación de la información que se mostrará. Y sí, hay un formato detrás de esta información. Para hacer las cosas más simples y no complicarlas, quiero que busques una tabla en la web. Esta tabla, que es muy fácil de encontrar, se conoce como tabla ASCII. Para facilitarte las cosas, muestro un ejemplo a continuación. Existen otras con más información, pero la que se ve en la imagen 02 será suficiente para entender lo que haremos.
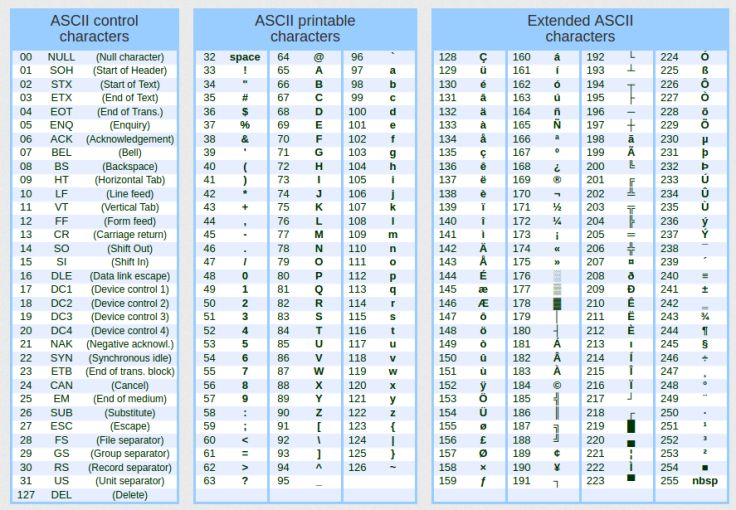
Imagen 02
La tabla que nos interesa es la de caracteres imprimibles, es decir, la que se encuentra en la parte central de la imagen 02. La parte izquierda corresponde a caracteres especiales, mientras que la parte derecha varía de una tabla a otra. Incluso podría crearse con nuestra propia aplicación. Aunque este no es el caso en MQL5, ya que para crear esta tabla de la derecha se necesita acceso a ciertas partes del hardware, algo que no está permitido en MQL5 y no es accesible en gran parte de los lenguajes. Básicamente, este tipo de tarea la realizan quienes programan en lenguajes de bajo nivel, como C o C++. Sin embargo, lo menciono solo para que sepas que pueden existir diferencias entre las figuras mostradas en el lado derecho de la imagen.
Bien, ¿por qué es tan importante esta tabla ASCII para nosotros en MQL5? En realidad, esta tabla no solo es importante para nosotros, sino para cualquiera que quiera manipular datos. Existen otras tablas con valores y símbolos diferentes, como las tablas UTF-8, UTF-16, ISO 8859, etc. Cada una tiene un propósito concreto. Sin embargo, en MQL5 normalmente podemos utilizar la tabla ASCII, salvo en ciertos casos en los que necesitaremos otras tablas. Esto se explicará en algún momento en el futuro.
Muy bien, querido lector. Ahora, para poder traducir la información, necesito que entiendas algo. Observa la imagen 02. Para traducir un valor binario a un valor hexadecimal, debemos utilizar los dígitos del 0 al 9 y las letras de la A a la F. Al mirar la tabla, podemos ver que el dígito cero corresponde al número 48 y que, a partir de este punto, cada número que avanzamos corresponde a un dígito. Por ejemplo, si avanzamos seis posiciones, que sería el dígito seis, utilizaremos el valor 54. ¿Entendido? Bien, con las letras ocurre lo mismo. La letra A mayúscula tiene el valor 65. Ya tenemos un punto de partida. Sin embargo, debes recordar que la A mayúscula en hexadecimal representa el valor diez, y así sucesivamente, siendo la F el valor quince. Básicamente, es algo muy simple y práctico. En este caso, el único cuidado que debemos tener es que hay algunos símbolos que deben omitirse entre el dígito 9 y la letra A. De esta manera, evitaremos que la cadena hexadecimal incluya caracteres extraños. Si deseamos realizar un acceso directo a la tabla ASCII, podemos manejarlo de esta manera. Sin embargo, aunque esto es posible, para nuestro propósito utilizaremos un enfoque ligeramente diferente. El objetivo es explicar por qué el código mostrado en el artículo anterior funciona. Así que, con esto en mente y para alcanzar el objetivo propuesto, veamos el código que utilizaremos. Puede verse justo a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64i\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s", 18. ValueToString(value, 0), 19. ValueToString(value, 1), 20. ValueToString(value, 2) 21. ); 22. } 23. //+------------------------------------------------------------------+ 24. string ValueToString(ulong arg, char format) 25. { 26. const string szChars = "0123456789ABCDEF"; 27. string sz0 = ""; 28. 29. while (arg) 30. { 31. switch (format) 32. { 33. case 0: 34. arg = 0; 35. break; 36. case 1: 37. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 38. arg >>= 3; 39. break; 40. case 2: 41. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 42. arg >>= 4; 43. break; 44. default: 45. return "Format not implemented."; 46. } 47. } 48. 49. return sz0; 50. } 51. //+------------------------------------------------------------------+
Código 02
Al ejecutar este código 02, el resultado se muestra inmediatamente abajo en el terminal.
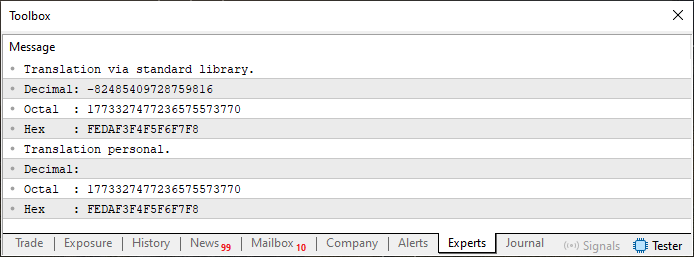
Imagen 03
Como gran parte de este código es fácil de entender para quienes han estado siguiendo y estudiando los contenidos de los artículos, solo destacaré lo que ocurre en las líneas 37 y 41. Esto se debe al uso del operador AND para aislar ciertos bits. Puede parecer complicado, pero es mucho más simple de lo que parece. Pensemos solo en el caso de la línea 37: sabemos que un valor octal solo tendrá dígitos que van del cero al siete. En binario, el valor siete se representa de la siguiente manera: 111. Es decir, si realizamos una operación AND bit a bit con cualquier valor, obtendremos un resultado que va de cero a siete. Lo mismo ocurre en la línea 41, solo que allí el valor irá de cero a quince. Ahora, observa la línea 26. Aquí tenemos los caracteres que se utilizarán cuando se esté generando la información. Como en MQL5 una cadena es un tipo especial de array, al acceder a la cadena de la línea 26 de la manera en que se hace en las líneas 37 y 41, en realidad estaremos buscando UNO y solo UNO de los caracteres presentes en la cadena. Por lo tanto, en este momento, LA CADENA NO SE ESTÁ ACCEDIENDO como una cadena, sino como un array.
Debido a ciertas cuestiones, la numeración de los elementos siempre empieza desde cero. Sin embargo, este cero NO REPRESENTA el tamaño de la cadena, sino el primer carácter que aparece en ella. Si no hay ningún carácter, la longitud de la cadena será cero. Si existe alguno, la longitud será mayor que cero. Pero esto no cambia el hecho de que la numeración siempre comenzará desde cero.
Sé que, al principio, puede parecerte muy confuso e ilógico. Sin embargo, a medida que te familiarices con el uso de arrays, este tipo de cosas se volverán cada vez más naturales para ti, querido lector.
Sin embargo, aún falta implementar un aspecto en este código 02. Este aspecto se refiere específicamente a los valores decimales. Para resolver correctamente esta cuestión, necesitamos usar un recurso que todavía no he explicado: saber cómo trabajar con él. Pero, para no dejarte sin una solución ni una explicación, haremos una pequeña suposición. No tiene sentido complicar innecesariamente el código para asegurar una representación exacta de los datos. Además, aunque falta un recurso que será explicado más adelante, tal y como está implementado ya podremos convertir cualquier valor de tipo entero de hasta 64 bits de ancho de manera casi 100 % precisa. Sin embargo, cuando explique ese recurso, que es la creación de template y typename, podremos convertir cualquier valor sin complicaciones. Hasta entonces, centrémonos únicamente en los aspectos más simples.
Observa que el tipo declarado en la línea seis es un entero con signo. Por esta razón, deberíamos comprobar si el valor puede ser negativo. Sin embargo, para no complicar innecesariamente las cosas, asumiremos que todos los valores serán enteros sin signo. Es decir, no será posible representar valores negativos. Con esta suposición aplicada a nuestro código, podemos modificarlo para verificar si los valores se visualizan correctamente. Esto se logra usando el código que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. long value = 0xFEDAF3F4F5F6F7F8; 07. 08. PrintFormat("Translation via standard library.\n" + 09. "Decimal: %I64u\n" + 10. "Octal : %I64o\n" + 11. "Hex : %I64X", 12. value, value, value 13. ); 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. } 25. //+------------------------------------------------------------------+ 26. string ValueToString(ulong arg, char format) 27. { 28. const string szChars = "0123456789ABCDEF"; 29. string sz0 = ""; 30. 31. while (arg) 32. switch (format) 33. { 34. case 0: 35. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 36. arg /= 10; 37. break; 38. case 1: 39. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 40. arg >>= 3; 41. break; 42. case 2: 43. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 44. arg >>= 4; 45. break; 46. case 3: 47. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 48. arg >>= 1; 49. break; 50. default: 51. return "Format not implemented."; 52. } 53. 54. return sz0; 55. } 56. //+------------------------------------------------------------------+
Código 03
Como bono adicional, en este código 03 también añadí la conversión del valor a su representación binaria. Como en los demás casos, es tan simple como esto. De todos modos, cuando se ejecuta, el resultado de este código 03 se muestra justo debajo.
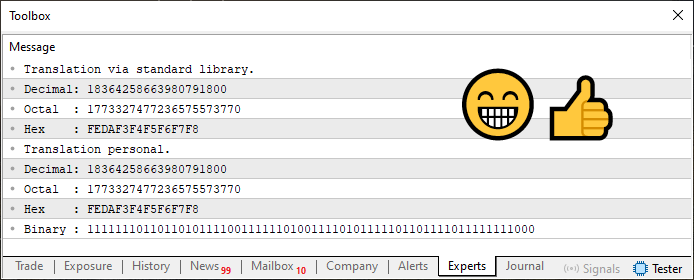
Imagen 04
Ahora, querido lector, presta mucha atención a lo que está ocurriendo aquí. Tal vez sea lo más importante que se dirá y mostrará en este artículo. Entre el código 03 y el 02 prácticamente no hay diferencias. Sin embargo, si observas la imagen 3 y la comparas con la 4, notarás algo diferente en ellas.
La diferencia está en el valor de la traducción realizada por la biblioteca estándar. Observa el valor DECIMAL. Notarás que es diferente. Sin embargo, esto no tiene sentido, ya que la línea seis, tanto del código 03 como del código 04, es exactamente igual. Entonces, ¿dónde está la diferencia que hizo que el valor se imprimiera de una manera completamente distinta a la esperada? Bien, querido lector, la diferencia está precisamente en la línea nueve. Observa con mucha atención esta línea nueve en el código 03 y luego en el código 04. El simple hecho de esta mínima diferencia hace que el valor, que por la declaración de tipo en la línea seis debería ser negativo, se convierta en positivo. Existe una forma de resolver este tipo de falla, pero, como mencioné antes, es necesario explicar cómo usar otro recurso que aún no ha sido abordado.
Hasta entonces, ten cuidado al introducir valores en el terminal. Esto se debe a que cualquier descuido podría llevarte a cometer un error de interpretación de los valores calculados. Por ello, es importante estudiar y practicar lo que se está viendo. No basta con leer la documentación o estos artículos para convertirse en un programador de calidad. Es necesario practicar y estudiar todo lo presentado.
Muy bien, a pesar de este pequeño detalle, puedes observar que la traducción del valor en su representación decimal es completamente correcta. Además, el cálculo necesario para realizar la conversión es bastante simple. En la línea 35, usamos el símbolo de porcentaje % para obtener el resto de la división por 10, que indica cuál será el símbolo que debe utilizarse, entre los presentes en szChars. Justo después, en la línea 36, ajustamos el valor de arg dividiéndolo por 10 y el resultado es el valor que se utilizará en la siguiente iteración. De este modo, transformamos un valor binario en uno legible para humanos.
Con base en esta explicación, creo que los códigos mostrados en el artículo anterior podrán entenderse ahora correctamente. Sin embargo, podemos mejorar un poco más las cosas en relación con lo que se mostró en él. Para lograrlo, utilizaremos el último código presentado en el artículo anterior, es decir, el código que utilizaba arrays de manera más directa. Sin embargo, para hacerlo correctamente, pasaremos a un nuevo tema.
Configuración del ancho de la contraseña
Bien, para comenzar a hablar sobre algo que podemos hacer en el código 06 mostrado en el artículo anterior, primero debemos verlo aquí. Así que replicaremos ese código a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg) 12. { 13. const string szCodePhrase = "The quick brown fox jumps over the lazy dog"; 14. 15. uchar psw[], 16. pos; 17. 18. ArrayResize(psw, StringLen(szArg)); 19. for (int c = 0; szArg[c]; c++) 20. { 21. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 22. psw[c] = (uchar)szCodePhrase[pos]; 23. } 24. return CharArrayToString(psw); 25. } 26. //+------------------------------------------------------------------+
Código 04
A continuación, procederemos con una breve explicación. Empecemos por el siguiente hecho: existen dos tipos de arrays que podemos utilizar. Una es un array estático y el otro es un array dinámico. La forma en que se declara determina si un array es estático o dinámico. Esta cuestión no tiene nada que ver con el uso de la palabra reservada static en la declaración ni con si el array se utiliza o no. Como esta cuestión es bastante compleja y no quiero ofrecerte una explicación mediocre, haré un breve resumen solo para que comprendas el código 04.
Un array dinámico se declara como se muestra en la línea 15. Nota que allí tenemos el nombre de la variable, que en este caso es psw, y justo después un par de corchetes vacíos, sin ningún tipo de información dentro de ellos. Se trata de un array dinámico. Al ser dinámico, podemos definir su tamaño en tiempo de ejecución. De hecho, es necesario hacerlo, ya que intentar acceder a cualquier posición de un array dinámico NO ALOCADO se considera un error y hará que tu código se cierre inmediatamente. Por esta razón, en la línea 18 se encuentra el lugar donde asignamos suficiente memoria para almacenar datos en el array.
Recuerda que una cadena es un array especial. Y, siempre que no sea constante, una cadena es un array dinámico para el cual no necesitamos asignar memoria explícitamente. El propio compilador agrega las rutinas necesarias para manejar esta tarea sin necesidad de intervenir directamente. Sin embargo, aquí no estamos usando una cadena, sino un array puro y simple. Por lo tanto, necesitamos especificar la cantidad de memoria que queremos o necesitamos. Y aquí radica un pequeño secreto.
Si durante la ejecución de la línea 18 del código 04 especificamos el tamaño de la contraseña que queremos crear, podemos limitarla de una manera bastante interesante. Al mismo tiempo, esto nos permite trabajar mejor con la contraseña que se debe generar. Teniendo esto en cuenta, es necesario realizar algunos pequeños cambios en este código. Estos cambios se muestran a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = "The quick brown fox jumps over the lazy dog"; 14. 15. uchar psw[], 16. pos; 17. 18. ArrayResize(psw, SizePsw); 19. for (int c = 0; szArg[c]; c++) 20. { 21. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 22. psw[c] = (uchar)szCodePhrase[pos]; 23. } 24. return CharArrayToString(psw); 25. } 26. //+------------------------------------------------------------------+
Código 05
Ahora presta mucha atención al siguiente hecho. En la línea 8 del código 05, estamos pasando un nuevo argumento a la función de la línea 11. Este mismo argumento se utiliza en la línea 18 para definir el número de caracteres de la contraseña, que en este caso son ocho. Sin embargo, si intentas ejecutar este código, fallará en la línea 22. Esto se debe a que en la línea seis estamos creando una frase secreta que contiene más de ocho caracteres. Como el bucle de la línea 19 solo se detendrá cuando se encuentre el símbolo NULL en la cadena szArg, que en este caso es precisamente la cadena declarada en la línea 6, en la línea 22 se estará intentando acceder a una posición de memoria no válida. Esto provoca un error y el código fallará.
Sin embargo, este no es realmente un problema. Todo lo que necesitamos es decidir si queremos usar toda la frase definida en la línea seis o solo una parte de ella para completar los ocho caracteres deseados. En función de la decisión que tomemos, el enfoque del código final será ligeramente diferente. Por eso es importante aprender a programar, porque una solución propuesta por un programador puede que no sea la preferida de otro. Pero con comunicación, se puede llegar a un entendimiento. Sin embargo, si no sabes programar, no podrías implementar la mejor solución para ti, por lo que quedarías completamente dependiente de la decisión que alguien más tome por ti.
De acuerdo, tomemos la siguiente decisión: usaremos toda la frase secreta. Al mismo tiempo, modificaremos la cadena de la línea 13 por otra que apareció en el artículo anterior. De esta manera, conseguiremos algo un poco más interesante.
No obstante, antes de crear realmente el código, quiero que regreses a la imagen 02 del tema anterior y observes cada uno de los valores presentes en esa tabla, que forman parte de la cadena declarada en la línea seis. ¿Has notado algo interesante en estos datos? La cuestión es que, al decidir usar toda la frase declarada en la línea seis, tendremos que utilizar algún otro recurso. Esto se debe a que, si hacemos la modificación que se muestra en el siguiente código...
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. for (int c = 0; szArg[c]; c++) 21. { 22. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] = (uchar)szCodePhrase[pos]; 24. i = (i == SizePsw ? 0 : i); 25. } 26. return CharArrayToString(psw); 27. } 28. //+------------------------------------------------------------------+
Código 06
... no utilizaremos toda la frase, sino únicamente los ocho últimos caracteres presentes en la frase secreta definida en la línea seis. Esto se puede comprobar ejecutando el código 06 y comparando los resultados con los del artículo anterior, donde se usa la misma frase que en el código 06.
Sin embargo, incluso sin ejecutar este código 06, al analizarlo se puede observar que, aunque la línea 23 ya no provocará el fallo del código, tendrá poco efecto. Esto se debe a que la línea 24 nos obliga a renovar siempre el valor de la contraseña en la posición exacta que hemos definido como límite de la misma. Por lo tanto, aunque la frase de la línea 6 contenga todos esos caracteres, al final sería como si solo ocho de ellos realmente existieran. Esto nos da una falsa sensación de seguridad al crear una frase secreta. Ahora bien, como sabemos por la imagen 02, cada símbolo está definido por un valor, por lo que podemos utilizar este array para generar la suma de esos valores. De este modo, se utilizarán todos los símbolos. Sin embargo, querido lector, presta atención a un detalle aquí. El valor máximo que podemos asignar al array viene definido por el tipo utilizado en él. Detallaré este punto más adelante en el próximo artículo. Pero, por ahora, podemos realizar algunos cambios adicionales en el código, como se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. return CharArrayToString(psw); 28. } 29. //+------------------------------------------------------------------+
Código 07
Ahora sí, tenemos algo que utiliza toda la frase secreta. Fíjate en que ha sido necesario modificar muy poco el código. Entre los cambios, destaca el hecho de que, en la línea 20, indiquemos que el array se inicialice con un valor concreto: en este caso, cero. Si lo deseas, puedes establecer otro valor inicial. Esto marcará una diferencia posteriormente, especialmente si tienes una frase secreta que utiliza el mismo símbolo más de una vez. Para este tipo de problema, existen varios métodos diferentes que permiten evitar que un mismo símbolo asigne el mismo valor a diferentes posiciones. En el próximo artículo, hablaremos más sobre este tema. La clave está precisamente en la línea 24. Ahora estamos sumando los valores y, por tanto, utilizando completamente ambas frases. Sin embargo, hay un problema. Este problema se observa al ejecutar el código.
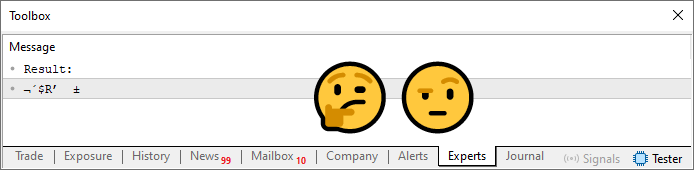
Imagen 05
Entonces, ¿cómo podrás utilizar esta contraseña? Difícil, ¿no? Lo que ocurre es que el array contiene los valores calculados mediante la suma, pero está limitado. Necesitamos hacer que los valores calculados apunten a uno de los valores presentes en la cadena declarada en la línea 13. Para lograrlo, será necesario usar otro bucle. A continuación se muestra el código resultante.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. 28. for (uchar c = 0; c < SizePsw; c++) 29. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 30. 31. return CharArrayToString(psw); 32. } 33. //+------------------------------------------------------------------+
Código 08
Después de pasar por el bucle que se encuentra en la línea 28 de este código 08, obtendremos algo que puedes observar justo abajo.
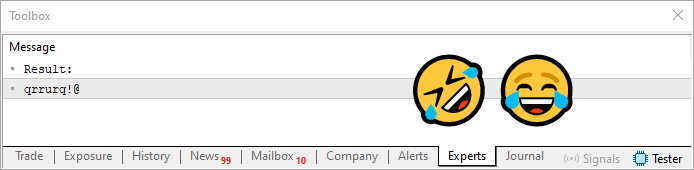
Imagen 06
Eso sí que puedo llamarlo una feliz coincidencia. Estaba hablando de una contraseña que podría contener caracteres repetidos y de cómo podríamos resolverlo. Y, para nuestra suerte, el resultado contiene justamente caracteres repetidos. ¡Es realmente mucha suerte! (risas).
Consideraciones finales
En este artículo, se mostró de manera parcial cómo se traducen los valores binarios a otros tipos de valores. También dimos los primeros pasos para comprender cómo una cadena puede manejarse como un array. Además, vimos cómo evitar un tipo de error muy común al usar arrays en nuestro código. Sin embargo, lo que vimos aquí fue una feliz coincidencia que será mejor explicada en el próximo artículo. En él, entenderemos cómo evitar que vuelvan a ocurrir cosas de este tipo. Asimismo, profundizaremos un poco más en la cuestión de los tipos de datos en arrays. ¡Hasta pronto!
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15461
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso