
Del básico al intermedio: Array (I)

Introducción
El contenido expuesto aquí tiene un propósito puramente didáctico. En ningún caso debe considerarse una aplicación final cuyo objetivo no sea el estudio de los conceptos expuestos.
En el artículo anterior, «Del básico al intermedio: Arrays y cadenas (III)», expliqué y mostré con un código adecuado al nivel de conocimiento alcanzado hasta ahora cómo la biblioteca estándar puede traducir valores binarios en valores decimales, octales y hexadecimales. Además, por supuesto, creé una representación binaria en formato de cadena, lo que nos permitió visualizar fácilmente el resultado.
Además de este concepto básico, también se demostró cómo podíamos definir el ancho de nuestra contraseña en función de una frase secreta. Y, por una feliz coincidencia, la contraseña resultante terminó teniendo una secuencia de caracteres repetida. Algo magnífico, ya que este no era el objetivo real. De hecho, fue solo una coincidencia afortunada, pero me brinda una excelente oportunidad para explicar otros conceptos y puntos relacionados con los arrays y las cadenas.
Algunos podrían pensar que hablaré del funcionamiento de cada función o procedimiento de la biblioteca estándar. Pero ese no es realmente mi objetivo. Mi verdadero propósito es mostrar los conceptos subyacentes a cada decisión. Así, podrás tomar tus propias decisiones basándote en el tipo de problema que necesites resolver. Aunque todavía estamos en un nivel bastante básico, ya contamos con algunas posibilidades reales en términos de programación, lo que nos permite comenzar a aplicar algunos conceptos un poco más avanzados.
Esto, además de facilitarme la tarea, te permitirá leer códigos un poco más elaborados. Pero no debes preocuparte por lo que veremos aquí. Introduciré los cambios poco a poco para que te acostumbres y puedas leer mis códigos sin problema, ya que suelo minimizar o compactar las expresiones de una forma que puede resultar confusa para quienes están comenzando.
De todos modos, empecemos este artículo hablando sobre lo que se vio en el artículo anterior. Es decir, aprenderemos una de las muchas maneras de evitar precisamente aquello que se obtuvo al factorizar una contraseña a partir de una frase secreta.
Una entre tantas soluciones
Muy bien. Comencemos haciendo que el código sea un poco más agradable, por así decirlo. El código original se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. 28. for (uchar c = 0; c < SizePsw; c++) 29. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 30. 31. return CharArrayToString(psw); 32. } 33. //+------------------------------------------------------------------+
Código 01
Sin embargo, en mi opinión, este código es algo desagradable. Esto se debe a que las variables declaradas en las líneas 16 y 17 solo se utilizan en el bucle de la línea 21. No obstante, si necesitamos una variable con el mismo nombre o de un tipo diferente, tendremos que realizar un trabajo adicional solo para ajustar el código. Sin embargo, como se ha visto en los artículos anteriores, podemos declarar variables dentro de un bucle FOR.
Ahora presta atención, querido lector. Si se declaran más de una variable destinada a utilizarse únicamente dentro del bucle FOR, todas ellas deben ser del mismo tipo. NO ES POSIBLE declarar e inicializar variables de tipos diferentes como en la primera expresión del comando FOR. Bien, con esto debemos hacer una pequeña elección. Dado que las variables pos e i, declaradas en las líneas 16 y 17, son del tipo uchar, y la variable c, declarada en el comando FOR, es del tipo int, podemos cambiar las dos primeras al tipo int o cambiar la variable c al tipo uchar. De cualquier forma, a mi parecer, no tiene sentido una frase con más de 255 caracteres. Por lo tanto, podemos buscar un término medio y configurar las tres variables como del tipo ushort, ya que solo se utilizan como índices de acceso. Con esta explicación, el código 01 se modifica en el código 02, que puede verse a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", Password(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string Password(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[]; 16. 17. ArrayResize(psw, SizePsw); 18. ArrayInitialize(psw, 0); 19. 20. for (ushort c = 0, pos, i = 0; szArg[c]; c++, i = (i == SizePsw ? 0 : i)) 21. { 22. pos = (ushort)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] += (uchar)szCodePhrase[pos]; 24. } 25. 26. for (uchar c = 0; c < SizePsw; c++) 27. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 28. 29. return CharArrayToString(psw); 30. } 31. //+------------------------------------------------------------------+
Código 02
A pesar de la aparente confusión que puede haber causado este código 02, sigue haciendo exactamente lo mismo que el código 01. Sin embargo, quiero llamar tu atención a la línea 20. Observa que en la primera expresión ahora se declaran todas las variables que se utilizarán en el bucle, y únicamente en este bucle. Sin embargo, fíjate en cómo está estructurada la tercera expresión del comando FOR. Observa que, en este caso, no sería posible realizar este tipo de ajuste en la variable i sin utilizar el operador ternario. Pero es importante tener en cuenta que este ajuste solo resuelve la cuestión de mantener el índice dentro del array, ya que el incremento se realiza en la línea 23.
A pesar de este cambio, el resultado es el mismo que antes. Es decir, al ejecutar el código, verás en el terminal algo parecido a la imagen siguiente.
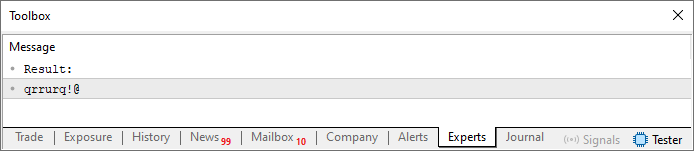
Imagen 01
Ahora reflexionemos un poco. Vemos una repetición de símbolos en la cadena de salida porque, precisamente, en la línea 27 estamos apuntando al mismo lugar de la cadena szCodePhrase. Es decir, al reducir los valores dentro del límite de la cadena definida en la línea 13, siempre estamos apuntando al mismo punto. Pero, y aquí es donde entra el gran detalle, si sumamos la posición actual con la anterior, podríamos obtener un nuevo índice totalmente diferente. Y como en la cadena de la línea 13 no hay repetición de símbolos, la cadena de salida, que sería nuestra contraseña, no tendría caracteres repetidos.
Es importante tener en cuenta algo aquí. Este tipo de enfoque no siempre es eficaz. Esto se debe a que la cantidad de símbolos presentes en la cadena de la línea 13 puede ser inadecuada. En otro caso, los valores pueden terminar formando un ciclo perfecto. Esto ocurre porque, de hecho, tenemos un ciclo de caracteres o símbolos declarados en la línea 13, donde el primer símbolo, que es un paréntesis de cierre, se conecta con el último, que es el número nueve. Sería como una serpiente mordiéndose la cola.
Muchos, que no son programadores, no lo comprenden. Pero este tipo de situación siempre ocurre, de una forma u otra, cuando trabajamos con programación.
Bien, ahora que he explicado lo que haremos, ¿qué os parece si vemos el código? Se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", Password(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string Password(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[]; 16. 17. ArrayResize(psw, SizePsw); 18. ArrayInitialize(psw, 0); 19. 20. for (ushort c = 0, pos, i = 0; szArg[c]; c++, i = (i == SizePsw ? 0 : i)) 21. { 22. pos = (ushort)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] += (uchar)szCodePhrase[pos]; 24. } 25. 26. for (uchar c = 0; c < SizePsw; c++) 27. psw[c] = (uchar)(szCodePhrase[((c ? psw[c - 1] : 0) + psw[c]) % StringLen(szCodePhrase)]); 28. 29. return CharArrayToString(psw); 30. } 31. //+------------------------------------------------------------------+s
Código 03
Este enfoque es muy interesante. Observa que apenas he cambiado el código. Solo modifiqué la línea 27, haciendo algo muy similar a lo que se hizo en la tercera expresión del bucle FOR, que puede verse en la línea 20. Pero antes de hablar de esto, veamos el resultado. Este puede analizarse a continuación.
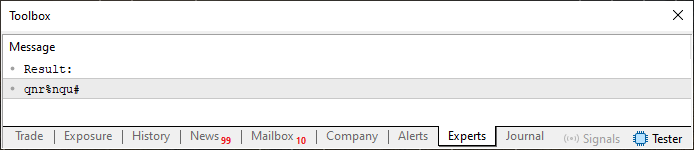
Imagen 02
Observa que ahora ya no tenemos la misma repetición de antes. Sin embargo, las cosas pueden mejorar aún más, cambiando solo una cosa en el código 03. Ahora, como se explicó en los artículos anteriores, este operador ternario de la línea 27 funciona como un comando IF. Por esta razón, el primer valor que se calcula no sufre ningún ajuste. Sin embargo, todos los valores posteriores sufrirán un ajuste dependiendo del valor usado en el índice anterior del array. Presta atención: el valor del array que se utilizará en esta corrección NO es el que se calculó en el bucle de la línea 20. Es el que se obtuvo de la cadena definida en la línea 13. Por lo tanto, para conocer el valor exacto, es necesario recurrir a la tabla ASCII y sumarlo con el valor calculado en el bucle de la línea 20. Parece algo confuso, pero es bastante simple si te detienes a pensar un poco.
Sin embargo, quiero llamar tu atención al valor cero que se está utilizando en el operador ternario. El primer índice no sufre ningún cambio precisamente debido a este valor. ¿Qué sucedería si se utilizara otro valor en su lugar? Bien, supongamos que la línea 27 se modifica como se muestra a continuación.
psw[c] = (uchar)(szCodePhrase[((c ? psw[c - 1] : 5) + psw[c]) % StringLen(szCodePhrase)]);
El resultado sería muy diferente, como puedes observar en la siguiente imagen.
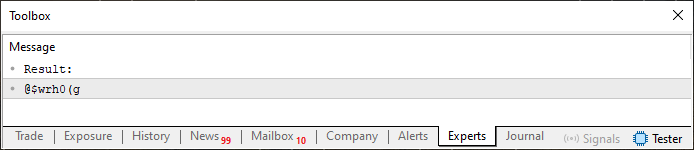
Imagen 03
Es interesante. Entonces, con un simple cambio, logramos generar algo que muchos considerarían una contraseña segura. Para ello, utilizamos cálculos sencillos y dos frases fáciles de recordar. Y fíjate, logramos todo esto con un nivel de conocimiento en programación que considero básico. No está mal para ser un principiante. Así que, querido lector, diviértete estudiando y experimentando nuevas posibilidades, ya que aquí solo he mostrado algo muy sencillo y básico, algo que un programador más experimentado haría en cuestión de minutos.
Perfecto, esta fue la parte más sencilla de la demostración sobre el uso de arrays. Sin embargo, aún no hemos terminado. Antes de dar nuevos pasos hacia algo más elaborado y complejo, necesitamos hablar de otros detalles relacionados con los arrays. Para ello, abordaremos un nuevo tema.
Tipos de datos y su relación con los arrays
Uno de los temas más complicados, confusos y difíciles de dominar en programación es precisamente el que nos ocupa. Quizás, y muy probablemente, mi querido lector, no tienes aún una idea clara de lo complicado que es este asunto. Algunos se consideran buenos programadores, pero no tienen ni la menor idea de cómo están relacionadas las cosas. Por esta razón, afirman que ciertas cosas no son posibles o que son más difíciles de lo que realmente son en la práctica.
A medida que lo asimiles, comenzarás a entender de manera natural diversos otros asuntos que, en apariencia, no tienen nada que ver, pero que, en el fondo, forman parte de lo mismo.
Para empezar, pensemos en la memoria de un ordenador. Da igual si el procesador tiene 8, 16, 32 o 64 bits, o cualquier otro valor exótico, como 48 bits. Esto definitivamente no importa. Del mismo modo, tampoco importa si trabajamos con valores binarios, octales, hexadecimales u otra base numérica. Esto tampoco marca la diferencia. Lo que realmente importa es cómo están configuradas o construidas las estructuras de datos. Por ejemplo, ¿quién dijo que un byte necesita tener ocho bits? ¿Y por qué ocho bits? ¿Acaso no podría tener diez o doce bits?
Tal vez ahora no tenga mucho sentido lo que digo. Esto se debe a que, en realidad, es muy difícil condensar décadas de experiencia en algo que todos puedan entender, especialmente si me centro en un programador principiante. Sin embargo, sin entrar en ciertos conceptos antes de tiempo, hablar sobre algunas cosas puede resultar bastante complicado. Pero, con lo que ya se mostró en los artículos anteriores, podemos hacer un pequeño experimento. Para ello, trabajaremos con un array de un tipo cualquiera y con una variable de otro tipo cualquiera. No obstante, existe una pequeña regla que debemos seguir: el tipo de dato utilizado en el array NO PUEDE SER EL MISMO que el de la variable. Aun así, podemos hacer que ambos interactúen entre sí y tengan el mismo tipo de valor, siempre que sigamos algunas reglas simples.
Hmm, parece complicado y exige tener muchos más conocimientos de programación, ¿pero es realmente así? Hagamos la prueba para comprobarlo. Para hacerlo aún más interesante, utilizaremos la función que vimos en el artículo anterior, donde podíamos convertir valores binarios a otro tipo de representación.
Bien, parece una buena idea. Y para hacer el ejemplo más extensivo, ya que usaremos mucho ese tipo de implementación para explicar varias cosas, colocaremos esa función en un archivo de cabecera. Así surge lo que se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. string ValueToString(ulong arg, char format) 05. { 06. const string szChars = "0123456789ABCDEF"; 07. string sz0 = ""; 08. 09. while (arg) 10. switch (format) 11. { 12. case 0: 13. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 14. arg /= 10; 15. break; 16. case 1: 17. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 18. arg >>= 3; 19. break; 20. case 2: 21. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 22. arg >>= 4; 23. break; 24. case 3: 25. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 26. arg >>= 1; 27. break; 28. default: 29. return "Format not implemented."; 30. } 31. 32. return sz0; 33. } 34. //+------------------------------------------------------------------+
Código 04
Ahora, un detalle importante: como este código 04 es un archivo de cabecera que estará presente y solo quiero que esté disponible para los scripts del tutorial, lo ubicaré en una carpeta dentro de la carpeta scripts. Como ya expliqué antes, esto significa para cualquier cosa creada aquí, no volveré a abordar este tema para poder avanzar. Perfecto. Mi querido lector, presta atención a lo siguiente: todos los valores que convertiremos deben considerarse como valores sin signo hasta que corrijamos este pequeño detalle en la función que aparece en el código 04.
Una vez hecho esto, podemos comprobar si todo funciona correctamente. Para ello, utilizaremos un código muy sencillo que se puede observar a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation via standard library.\n" + 11. "Decimal: %I64u\n" + 12. "Octal : %I64o\n" + 13. "Hex : %I64X", 14. value, value, value 15. ); 16. PrintFormat("Translation personal.\n" + 17. "Decimal: %s\n" + 18. "Octal : %s\n" + 19. "Hex : %s\n" + 20. "Binary : %s", 21. ValueToString(value, 0), 22. ValueToString(value, 1), 23. ValueToString(value, 2), 24. ValueToString(value, 3) 25. ); 26. } 27. //+------------------------------------------------------------------+
Código 05
Al ejecutar este código, el resultado es el que podemos observar en la siguiente imagen.
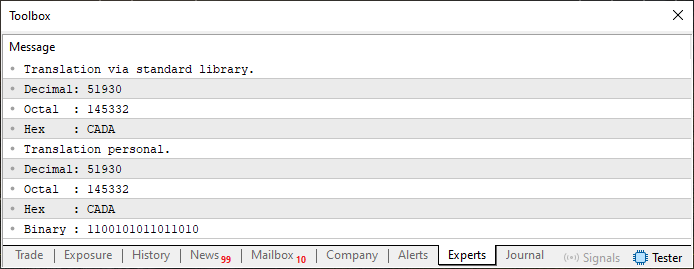
Imagen 04
Está claro que funciona. Por lo tanto, ya podemos empezar a experimentar con arrays y variables de diferentes tipos. Esto te permitirá comenzar a entender algo muy curioso que solo ocurre en ciertos lenguajes de programación. Para ello, partiremos de un cambio en el código 05, que ahora se convertirá en lo que llamaré «MARCO CERO». Este se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA}; 09. ushort value = 0; 10. 11. value = (array[0] << 8) | (array[1]); 12. 13. PrintFormat("Translation personal.\n" + 14. "Decimal: %s\n" + 15. "Octal : %s\n" + 16. "Hex : %s\n" + 17. "Binary : %s", 18. ValueToString(value, 0), 19. ValueToString(value, 1), 20. ValueToString(value, 2), 21. ValueToString(value, 3) 22. ); 23. } 24. //+------------------------------------------------------------------+
Código 06
Ahora quiero pedirte algo, mi querido lector. Te pido que dejes de lado cualquier distracción que pueda hacerte perder la atención. Quiero que te concentres por completo en lo que empezaremos a ver a partir de este momento. Porque lo que voy a explicar ahora es algo muy confuso para muchos programadores principiantes. Sin embargo, no se trata de cualquier tipo de programador, sino específicamente de aquellos que utilizan ciertos lenguajes de programación, entre ellos, MQL5.
Antes de profundizar, veamos el resultado de la ejecución del código 06. Este puede observarse a continuación.
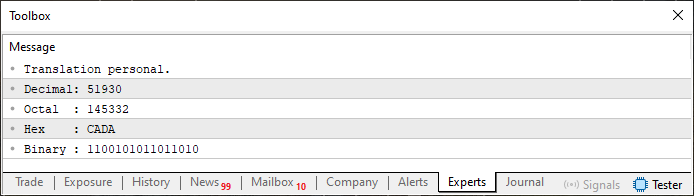
Imagen 05
Lo que se muestra aquí, en este código 06, es la base de una gran cantidad de conceptos. Si logras entenderlo mientras estudias este código, podrás comprender muchas otras cosas que surgirán más adelante sin ningún problema. Esto se debe a que muchas de ellas derivan, de alguna manera, de lo que este código 06 está haciendo.
A primera vista, es posible que no logres percibir lo complejo que es este código simple o lo que se puede hacer simplemente porque este código 06 puede implementarse. Así que tomémoslo con calma. Para quienes ya conocen esto, nada de lo que explicaré será nuevo. Pero para quienes no lo conocen, lo que explicaré aquí puede resultar muy confuso.
De acuerdo, tal vez haya dado un paso demasiado grande. Así que retrocedamos un poco y veamos lo siguiente: ¿qué parte del código 06 no logras entender, mi querido lector, basándote únicamente en lo que se ha explicado hasta ahora? Probablemente, se trate de las líneas ocho y once. De hecho, estas líneas no tienen mucho sentido para quienes están comenzando. Aunque en los códigos anteriores de este mismo artículo vimos algo muy similar, como puedes observar en el código 03 en las líneas 15, 20, 23 y 27.
Sin embargo, en el código 06 las cosas funcionan de manera un poco diferente, aunque no totalmente distinta. Tal vez cometí un error al utilizar arrays antes de explicarlos adecuadamente. Por esta razón, te pido disculpas. Es posible que ahora te sientas algo confundido al ver las cosas suceder como se observa en la imagen 05 al ejecutar el código 06.
Empecemos, pues, del modo más sencillo y correcto, desde la línea 11 de este código 06. Lo que tenemos allí equivale a lo que se puede ver en la línea de código que aparece a continuación.
value = (0xCA << 8) | (0xDA);
Tal vez resulte un poco complicado mirarlo así, aunque ya se haya explicado cómo funciona el operador de desplazamiento. De todos modos, recurramos a una ayuda visual. Así las cosas serán mucho más simples de entender.
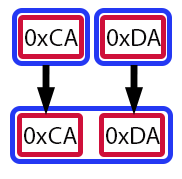
Imagen 06
Cada rectángulo rojo representa un byte, o un valor del tipo uchar. Y cada rectángulo azul representa una variable. Las flechas indican los movimientos realizados en el proceso. Es decir, en esta imagen se muestra cómo se creó el valor de la variable value en la línea 11. Déjame ver si entiendo correctamente: ¿estás diciendo que, a pesar de que value es del tipo ushort, podemos colocar valores del tipo uchar dentro de ella y crear así un nuevo valor? Exactamente, mi querido lector. Sin embargo, no es solo eso. Pero vayamos despacio para que el concepto quede claro.
Como ya debes saber, la región de memoria que estamos creando en la línea 8 es una región constante. Pero eso no es todo. Al inicializar valores en esta región de memoria, se parece a un cartucho de memoria ROM, similar a los antiguos utilizados en videojuegos.

Imagen 07
Aunque pueda parecer extraño, esta línea 08 realmente está creando una memoria ROM dentro de la memoria RAM.
Pero espera un momento, ¿cuál es el tamaño de la memoria ROM creada en esta línea 08? Eso depende, querido lector. Y no estoy dando esta respuesta para burlarme de ti. Lo digo de manera completamente honesta. Sin embargo, existe una función en la biblioteca estándar que nos indica cuál es el tamaño del bloque asignado. Recuerda que un array es una cadena de caracteres. Pero una cadena es un array especial, como se explicó anteriormente. A diferencia de los arrays mostrados en los códigos anteriores, donde creamos un generador de contraseñas a partir de frases simples, este array construido en el código 06 es, de hecho, un array puro. Es decir, no es una cadena, sino un array destinado a representar cualquier tipo de valor. Sin embargo, dado que la declaramos como un array del tipo uchar, limitamos el rango de valores que podemos colocar en ella. Pero aquí es donde las cosas se complican: podemos usar otro tipo de mayor tamaño para determinar cuál es el valor presente en el array.
Para hacer esto, debemos usar un tipo de dato que pueda contener tantos bits como los del array. Eso es lo que intenta transmitir la imagen 06, ya que la región azul representa el conjunto de todos los bits del array. Para dejar esto más claro, agregaremos un poco más de información en la línea 08 y veremos qué sucede. Sin embargo, para mantener las cosas simples, necesitamos modificar el código como se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; 09. ulong value = 0; 10. 11. for (uchar c = 0; c < array.Size(); c++) 12. value = (value << 8) | (array[c]); 13. 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. } 25. //+------------------------------------------------------------------+
Código 07
Sí, lo sé. Lo que se está haciendo en este código 07 parece una completa locura. Pero observa el resultado que se obtiene al ejecutar este código. Puedes verlo a continuación.
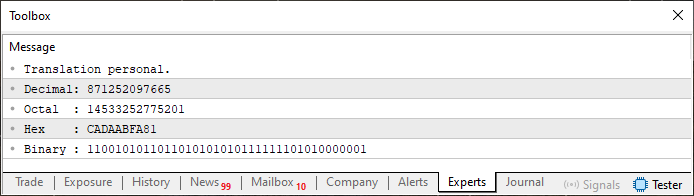
Imagen 08
Esto sí que es algo realmente alocado. Pero, como puedes ver, funciona. Es decir, mezclamos valores binarios, hexadecimales y decimales en un array. Al final, logramos montar un pequeño bloque de memoria ROM que contiene algún tipo de información. Pero lo más sorprendente no es lo que estamos viendo aquí. Esto es solo la punta del iceberg de algo mucho más grande.
Antes de profundizar un poco más, veamos qué ocurrió y cuáles son las limitaciones y precauciones que debemos tener en cuenta al manejar este tipo de cosas.
Quizá hayas notado que en la línea ocho solo añadí nuevos datos. Bien, pero ¿cuántos datos podemos colocar allí? La respuesta es: DATOS INFINITOS, o hasta donde tu equipo lo permita. En la práctica, la cantidad de información que podemos agregar dependerá de la capacidad de almacenamiento de tu ordenador para gestionar datos. Sin embargo, a diferencia de lo que ocurre con la línea ocho, esto no se aplica a la variable value. En esta última, tenemos un límite máximo de bits que podemos almacenar. Como quería que experimentaras esto de una forma más flexible, configuré el límite máximo que actualmente es posible manejar en MQL5, es decir, 64 bits u ocho bytes. ¿Esto significa que solo podemos colocar ocho bytes en la variable value? No, mi querido lector. En realidad, significa que, una vez completados 64 bits, la nueva información reemplazará a la anterior. Este comportamiento genera un modelo de flujo de datos que exploraremos más adelante.
Es importante que observes que tenemos la capacidad de colocar como máximo 64 bits en una sola variable. Sin embargo, esto no significa que podamos colocar ocho valores diferentes. Y aquí es donde se complican las cosas para quienes llegan directamente a este artículo sin haber leído los anteriores ni haber practicado lo explicado en ellos.
Antes de hablar sobre el bucle presente en la línea 11 y lo que ocurre en la línea 12, hagamos un pequeño cambio en este código 07. Esto servirá para aclarar el concepto de cantidad de información en un array. El detalle a modificar se muestra a continuación.
const ushort array[] = {0xCADA, B'1010101111111010', 0x81}; Como puedes ver en la línea mostrada arriba, nuestro array ya no tiene cinco elementos, sino tres. Es importante que observes que, a pesar de este cambio en el número de elementos, seguimos utilizando casi la misma cantidad de memoria. Aunque ahora tenemos 8 bits desperdiciados en la memoria. Esto sucede porque, a diferencia de lo que ocurre en el código 07, donde cada byte se utiliza completamente, en esta nueva estructura el último valor del array solo utiliza 8 de los 16 bits disponibles. Puede que parezca un desperdicio aceptable, pero hablaremos más sobre esto en otro momento. Por ahora, solo quiero que entiendas que el tipo de dato utilizado influye en el consumo de memoria y también afecta al funcionamiento de tu código.
in embargo, las cosas se pondrían aún peor si, por casualidad, utilizas algo parecido a la línea que se muestra a continuación.
const int array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; Sé que a muchas personas no les preocupa utilizar un tipo inadecuado en algunas variables. Pero, aunque aparentemente no haya problema (y en este caso particular no lo hay), al usar esta línea en el código 07 no solo estás desperdiciando 8 bits de memoria, sino 16 bits por cada elemento del array. Con 5 elementos, el desperdicio sería de 80 bits o 10 bytes, lo cual es más que la longitud de la contraseña que utilizamos al principio del artículo.
Esta cantidad de memoria desperdiciada puede parecer insignificante si tenemos en cuenta que hoy en día contamos con ordenadores con más de 32 gigabytes de memoria. Y, aunque este desperdicio y una posible falla podrían ocurrir, en nuestro caso actual esto no afectará al comportamiento del código, como veremos en las líneas 11 y 12, así que veamos qué sucede en ellas.
Aquí le estamos indicando al código que, por cada elemento presente en el array, queremos que el valor de la variable value se desplace 8 bits hacia la izquierda, creando así espacio para un nuevo elemento. Esto es lo que ocurre en la línea 12, pero esta línea se orienta a utilizar un elemento específico del array, que es el indicado por la variable c. Ahora bien, ¿cómo sabemos cuántos elementos hay en el array? En la línea 11, la segunda expresión que controla la finalización del bucle nos da esta información. Lo que estamos haciendo aquí es hacer una llamada a la biblioteca estándar de MQL5.
Esta llamada, que se encuentra en la línea 11, equivale a utilizar la función ArraySize. Es decir, de esta forma podemos saber cuántos elementos hay en el array, independientemente del número de bits que utilice cada elemento en realidad.
Para experimentar este concepto, basta con modificar el código para que quede como se muestra a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; 09. ulong value = 0; 10. 11. for (uchar c = 0; c < array.Size(); c++) 12. value = (value << 8) | (array[c]); 13. 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. Print("Number of elements in the array: ", ArraySize(array)); 25. } 26. //+------------------------------------------------------------------+
Código 08
Con esto, al ejecutar el código 08, podrás ver la cantidad de elementos presentes en el array, como se muestra en la imagen siguiente, en la región destacada.
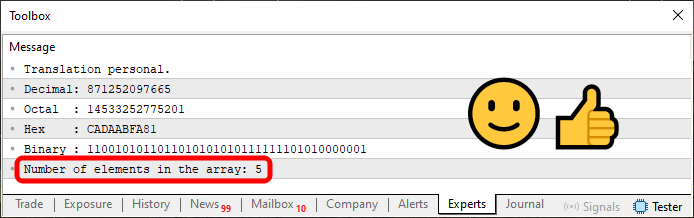
Imagen 09
Consideraciones finales
Bien, mi querido lector, este artículo ya contiene mucho material para que estudies y asimiles. Por esta razón, te daré un tiempo para que estudies y practiques lo que se ha mostrado aquí. Intenta comprender estos primeros conceptos relacionados con el uso de arrays. Aunque en este artículo se utilizan arrays ROM, que no permiten modificar su contenido, es muy importante que intentes comprender al máximo lo explicado aquí. Sé que este material es difícil de asimilar de forma inmediata, pero esfuérzate al máximo y dedica todo tu empeño a entender lo que se muestra en estos artículos, especialmente en este.
Entender los demás artículos te ayudará enormemente a convertirte en un programador excelente. Y, como el material será cada vez más complejo, los desafíos también lo serán. No te desanimes ante las dificultades que pueda presentarte este material. Practica y utiliza los anexos para comprender los puntos que no se explican completamente aquí, pero que se mencionan en el artículo, como las modificaciones que se indican, pero cuyos resultados no se muestran. Es importante que comprendas qué hacen esas modificaciones en la memoria. Así que diviértete explorando los archivos del anexo.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15462
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso