
Desarrollamos un asesor experto multidivisa (Parte 19): Creando las etapas implementadas en Python
Introducción
Hace algún tiempo (en la Parte 6) vimos cómo automatizar la selección de un buen grupo de estrategias comerciales de instancia única. En aquel momento aún no disponíamos de una base de datos que recopilara los resultados de todas los pasadas de los simuladores. Para ello, utilizábamos un archivo CSV normal. El principal objetivo de ese trabajo era probar la hipótesis de que la selección automática de un buen grupo puede producir mejores resultados que la selección manual.
La tarea se llevó a buen término y confirmamos la hipótesis. Por ello, a continuación analizamos cómo mejorar los resultados de esa selección automática. Resulta que si dividimos el conjunto de todas las instancias únicas en un número relativamente pequeño de clústeres y, al seleccionar un grupo, nos aseguramos de que no incluya instancias del mismo clúster, esto ayudará no solo a mejorar los resultados comerciales del asesor experto final, sino también a reducir el tiempo del proceso de selección en sí.
Para realizar la clusterización, utilizamos la biblioteca preparada scikit-learn para Python, en concreto, la implementación K-Means. Este no es el único algoritmo de clusterización, pero considerar otros posibles, así como comparar y seleccionar el mejor aplicado a esta tarea, superaba los límites aceptables. Por consiguiente, tomamos esencialmente el primer algoritmo que encontramos, y los resultados obtenidos tras su uso resultaron ser bastante buenos.
Sin embargo, el uso de esta implementación en particular hizo necesario ejecutar un pequeño programa en Python. De todas formas, cuando realizábamos la mayoría de las operaciones a mano, no era un problema. Pero ahora que vamos camino de automatizar el proceso completo de pruebas y selección de buenos grupos de instancias de estrategias comerciales individuales, la presencia incluso de una simple operación manual ejecutada en medio de un pipeline de tareas de optimización ejecutadas secuencialmente tiene mala pinta.
Para corregir esta desafortunada incongruencia, podemos tomar dos caminos. El primero consiste en encontrar una implementación lista del algoritmo de clusterización escrita en MQL5 o escribirla uno mismo, si la búsqueda no da buenos resultados. La segunda forma implica añadir la posibilidad de ejecutar no solo asesores expertos escritos en MQL5, sino también programas Python en las etapas necesarias del proceso de optimización automática.
Tras una breve deliberación, nos inclinamos por la segunda opción. Así que manos a la obra.
Trazando el camino
Así pues, veamos cómo podemos iniciar un programa Python desde un programa MQL5. Las formas más obvias son las siguientes:
- Inicio directo. Para ello, podemos utilizar una de las funciones del sistema operativo que permite ejecutar un archivo ejecutable con parámetros. El ejecutable será el interpretador de Python, mientras que los parámetros serán el nombre del archivo con el programa y sus parámetros de inicio. El inconveniente de este enfoque puede considerarse la necesidad de usar funciones externas de DLL, pero de todas formas ya las utilizamos para ejecutar el simulador de estrategias.
- Inicio a través de una solicitud web. Podemos crear un servidor web sencillo con la API necesaria, encargado de iniciar los programas Python necesarios cuando se reciban solicitudes de un programa MQL5 a través de la llamada de WebRequest(). Podemos utilizar, por ejemplo, el framework Flask o cualquier otro para crear un servidor web. La desventaja de este enfoque sería la excesiva complejidad para resolver un problema sencillo.
A pesar de lo atractivo que resulta el segundo método, pospondremos su aplicación para más adelante, cuando sea el momento de aplicar otras cosas relacionadas. Con el tiempo, incluso podremos crear una interfaz web completa para gestionar el proceso completo de optimización automática, convirtiendo el asesor experto Optimization.ex5 actual en un servicio MQL5. El servicio iniciado junto con el terminal controlará la aparición de proyectos con el estado Queued en la base de datos y, si aparecen, ejecutará todas las tareas de optimización añadidas a la cola para estos proyectos. Pero por ahora, aplicaremos la primera versión, más sencilla, del inicio.
La siguiente cuestión será la elección del tipo de guardado de los resultados de la clusterización. En la Parte 6, colocamos el número de clúster como una nueva columna en la tabla que originalmente almacenaba los resultados de las pasadas de optimización de instancias únicas de estrategias comerciales. Entonces, por analogía, podemos añadir una nueva columna a la tabla passes y poner en ella los números de clústeres. Pero no todos las pasadas de optimización implican una mayor clusterización de los resultados de sus pasadas. Por lo tanto, para muchas filas de la tabla passes, esta columna almacenará valores vacíos. Y eso no es bueno.
Para evitar esta situación, crearemos una tabla separada que almacenará solo los identificadores de pasada y los números de clúster asignados. Al principio de la segunda etapa de optimización, para tener en cuenta la clusterización realizada, simplemente uniremos la tabla passes con los datos de la nueva tabla, vinculándolos según los identificadores de pasada (id_pass).
Según la secuencia de acciones necesaria en la optimización automática, la etapa de clusterización deberá realizarse entre la primera y la segunda etapa. Para evitar más confusiones, seguiremos usando los nombres "primera" y "segunda" etapa para las mismas etapas que antes se denominaban primera y segunda. La nueva etapa añadida se denominará etapa de clusterización de los resultados de la primera etapa.
Entonces tendremos que hacer lo siguiente:
- Realizaremos los cambios en el asesor experto Optimisation.mq5 para que pueda ejecutar etapas implementadas en Python.
- Escribiremos un código Python que tome los parámetros necesarios, cargue la información sobre las pasadas desde la base de datos, las agrupe y guarde los resultados en la base de datos.
- Rellenaremos la base de datos con tres etapas, los trabajos para estas etapas, para diferentes instrumentos comerciales y marcos temporales, y las tareas de optimización para estos trabajos, para uno o más criterios de optimización.
- Realizaremos la optimización automática y evaluaremos los resultados.
Correcciones
Esta vez no se ha detectado ningún error crítico, así que vamos a corregir las imprecisiones que no afectan directamente al asesor experto final resultante de la optimización automática, pero que nos impiden controlar la corrección de los pasadas de optimización y los resultados de las pasadas individuales iniciadas fuera de la optimización.
Empezaremos por añadir los desencadenantes para establecer las fechas de inicio y finalización de una tarea (task). Ahora se modificarán con la ayuda de consultas SQL ejecutadas desde el asesor experto Optimisation.mq5 antes y después de detener el proceso de optimización en el simulador de estrategias:
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void StartTask(ulong taskId, string setting) { ... // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing', " " start_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); } //+------------------------------------------------------------------+ //| Task completion | //+------------------------------------------------------------------+ void FinishTask(ulong taskId) { PrintFormat(__FUNCTION__" | Task ID = %d", taskId); // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Done', " " finish_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); }
La lógica de los activadores será sencilla. Si el estado de la tarea en la tabla tasks cambia a "Processing", la fecha de inicio (start_date) deberá ser igual a la hora actual. Si el estado de la tarea cambia a "Done", entonces (finish_date) deberá ser igual a la hora actual. Si el estado de la tarea cambia a "Queued", deberemos borrar las fechas de inicio y finalización. La última operación mencionada de cambio de estado no se realizará desde el asesor experto, sino modificando manualmente el valor del campo status en la tabla tasks.
Aquí tenemos cómo podría ser la aplicación de estos disparadores:
CREATE TRIGGER IF NOT EXISTS upd_task_start_date AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Processing' BEGIN UPDATE tasks SET start_date= DATETIME('NOW') WHERE id_task=NEW.id_task; END; CREATE TRIGGER IF NOT EXISTS upd_task_finish_date AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Done' BEGIN UPDATE tasks SET finish_date= DATETIME('NOW') WHERE id_task=NEW.id_task; END; CREATE TRIGGER IF NOT EXISTS reset_task_dates AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Queued' BEGIN UPDATE tasks SET start_date= NULL, finish_date=NULL WHERE id_task=NEW.id_task; END;
Tras crear estos disparadores, podremos eliminar la modificación de start_date y finish_date del asesor experto, dejando solo el cambio de estado.
La siguiente imprecisión, menor pero igualmente desagradable, consiste en que, al ejecutar manualmente una única pasada del simulador de estrategias tras cambiar a una nueva base de datos, el valor por defecto del ID de la tarea de optimización actual es igual a 0. Y si intentamos insertar un registro en la tabla passes con dicho valor id_task, podemos provocar un error al comprobar las claves externas, si olvidamos añadir una tarea especial con un id_task = 0. Si existe, todo irá bien.
Por lo tanto, añadiremos un disparador en el evento de creación de un nuevo registro en la tabla de proyectos. En cuanto creamos un nuevo proyecto, tendremos que crear automáticamente una etapa (stage), un trabajo (job) y una tare (task) para las pasadas individuales. Una implementación de este disparador podría tener el aspecto siguiente:
CREATE TRIGGER IF NOT EXISTS insert_empty_stage AFTER INSERT ON projects BEGIN INSERT INTO stages ( id_project, name, optimization, status ) VALUES ( NEW.id_project, 'Single tester pass', 0, 'Done' ); END; DROP TRIGGER IF EXISTS insert_empty_job; CREATE TRIGGER IF NOT EXISTS insert_empty_job AFTER INSERT ON stages WHEN NEW.name = 'Single tester pass' BEGIN INSERT INTO jobs VALUES ( NULL, NEW.id_stage, NULL, NULL, NULL, 'Done' ); INSERT INTO tasks ( id_job, optimization_criterion, status ) VALUES ( (SELECT id_job FROM jobs WHERE id_stage=NEW.id_stage), -1, 'Done' ); END;
Otra imprecisión era que cuando ejecutábamos manualmente una sola pasada del simulador de estrategias, el campo pass_date de la tabla passes no contenía la hora actual, sino la hora del final del intervalo de prueba. Esto se debe a que, para establecer el valor de este tiempo, usamos la función TimeCurrent() en la consulta SQL dentro del asesor experto. Pero en el modo de prueba esta función no retorna la hora actual real, sino la hora simulada. Por consiguiente, si tenemos un intervalo de prueba que termine a finales de 2022, esta pasada también se almacenará en la tabla passes con un tiempo de finalización que coincidirá con el final de 2022.
¿Por qué entonces se escribe en la tabla passes el tiempo de finalización actual correcto de todas las pasadas realizadas durante la optimización? La respuesta ha resultado bastante sencilla. La cuestión es que durante el proceso de optimización, las consultas SQL para guardar los resultados de las pasadas son ejecutadas por una instancia de asesor experto iniciada no en el simulador, sino en el gráfico del terminal en el modo de recopilación de dataframes. Y como no funciona en el simulador, recibe el tiempo actual de la función TimeCurrent(), que es bastante real y no simulada.
Para solucionar esto, añadiremos un disparador que se ejecutará después de insertar un nuevo registro en la tabla passes, que establecerá la fecha actual:
CREATE TRIGGER IF NOT EXISTS upd_pass_date
AFTER INSERT
ON passes
BEGIN
UPDATE passes
SET pass_date = DATETIME('NOW')
WHERE id_pass = NEW.id_pass;
END;
En la consulta SQL que añadirá una nueva fila a la tabla passes desde el asesor experto; luego eliminaremos la sustitución de la hora actual calculada por el asesor experto y pasaremos allí solo la constante NULL.
Asimismo, hemos introducido algunas adiciones y correcciones menores en las clases existentes. En CVirtualOrder hemos añadido un método para cambiar el tiempo de expiración y un método estático para comprobar un array de órdenes virtuales para ver si una de ellas se activa. Estos métodos aún no se usan, pero pueden ser útiles en otras estrategias comerciales.
En CFactorable, hemos corregido el comportamiento del método ReadNumber() para que, cuando llegue al final de la línea de inicialización, devuelva NULL en lugar de repetir la salida del último número leído tantas veces como se desee. Esta edición requiere especificar exactamente tantos parámetros en la línea de inicialización para el gestor de riesgos como debería haber, es decir, 13 en lugar de 6:
// Prepare the initialization string for the risk manager string riskManagerParams = StringFormat( "class CVirtualRiskManager(\n" " 0,0,0,0,0,0,0,0,0,0,0,0,0" " )", 0 );
En la clase CDatabase, añadiremos un nuevo método estático que utilizaremos para cambiar a la base de datos deseada. Básicamente, dentro de él, solo nos conectaremos a la base de datos con el nombre y la posición deseados y cerraremos la conexión inmediatamente:
static void Test(string p_fileName = NULL, int p_common = DATABASE_OPEN_COMMON) { Connect(p_fileName, p_common); Close(); };
Tras su llamada, las llamadas posteriores al método Connect() sin parámetros se conectarán a la base de datos deseada.
Una vez terminada esta parte no esencial pero necesaria, pasaremos a la realización de la tarea principal.
La refactorización de Optimization.mq5
En primer lugar, tendremos que hacer cambios en el asesor experto Optimisation.mq5. En él deberemos añadir la comprobación del nombre del archivo a iniciar (el campoexpert) en la tabla stages. Si el nombre termina en ".py", este paso ejecutará un programa Python. Podemos colocar los parámetros necesarios para llamarlo en el campo tester_inputs de la tabla (jobs).
Sin embargo, la tarea no se limitará a esto. Asimismo, necesitaremos transmitir de alguna manera al programa Python el nombre de la base de datos y el identificador de la tarea actual, y también necesitaremos iniciarla de alguna manera. Esto provocará un aumento excesivo del código ubicado en el asesor experto, que ya es bastante grande. Empezaremos distribuyendo el código del programa existente en varios archivos.
En el archivo principal del asesor experto Optimisation.mq5 dejaremos solo la creación del temporizador y un nuevo objeto de la clase COptimizer, que hará todo el trabajo principal. Solo tendremos que llamar a su método Process() en el manejador del temporizador y encargarnos de la correcta creación/eliminación de este objeto durante la inicialización/desinicialización del asesor experto.
sinput string fileName_ = "database911.sqlite"; // - File with the main database sinput string pythonPath_ = "C:\\Python\\Python312\\python.exe"; // - Path to Python interpreter COptimizer *optimizer; // Pointer to the optimizer object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Connect to the main database DB::Test(fileName_); // Create an optimizer optimizer = new COptimizer(pythonPath_); // Create the timer and start its handler EventSetTimer(20); OnTimer(); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert timer function | //+------------------------------------------------------------------+ void OnTimer() { // Start the optimizer handling optimizer.Process(); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { EventKillTimer(); // Remove the optimizer if(!!optimizer) { delete optimizer; } }
Al crear un objeto optimizador, transmitiremos un único parámetro a su constructor: la ruta completa al archivo ejecutable del interpretador de Python en la computadora donde se ejecutará este asesor experto. Especificaremos el valor de este parámetro en el parámetro de entrada del asesor experto pythonPath_. En el futuro podremos deshacernos de este parámetro implementando la búsqueda automática de un interpretador dentro de la clase optimizadora, pero por ahora nos limitaremos a esta forma más sencilla.
Vamos a guardar ahora los cambios realizados en el archivo Optimisation.mq5 en la carpeta actual.
Clase de optimizador
Luego crearemos la clase de optimizador COptimizer. De los métodos públicos solo tendrá el método principal de procesamiento Process() y el constructor. En la sección cerrada, añadiremos el método para obtener el número de tareas en la cola de ejecución y el método para obtener el ID de la siguiente tarea en la cola. Y pasaremos todo el trabajo relacionado con la tarea de optimización específica a un nivel más abajo, a un objeto de la nueva clase COptimizerTask (tarea de optimización). Entonces necesitaremos un objeto de esta clase en el optimizador.
//+------------------------------------------------------------------+ //| Class for the project auto optimization manager | //+------------------------------------------------------------------+ class COptimizer { // Current optimization task COptimizerTask m_task; // Get the number of tasks with a given status in the queue int TotalTasks(string status = "Queued"); // Get the ID of the next optimization task from the queue ulong GetNextTaskId(); public: COptimizer(string p_pythonPath = NULL); // Constructor void Process(); // Main handling method };
El código de los métodos TotalTasks() y GetNextTaskId() lo hemos tomado casi sin cambios de las funciones correspondientes de la versión anterior de Optimisation.mq5. Lo mismo puede decirse del método Process(), al que hemos trasladado el código de la función OnTimer(). Pero aún así hemos tenido que modificarlo de forma más sustancial porque hemos introducido una nueva clase para el problema de optimización. En general, sin embargo, el código de este método se ha vuelto aún más claro:
//+------------------------------------------------------------------+ //| Main handling method | //+------------------------------------------------------------------+ void COptimizer::Process() { PrintFormat(__FUNCTION__" | Current Task ID = %d", m_task.Id()); // If the EA is stopped, remove the timer and the EA itself from the chart if (IsStopped()) { EventKillTimer(); ExpertRemove(); return; } // If the current task is completed, if (m_task.IsDone()) { // If the current task is not empty, if(m_task.Id()) { // Complete the current task m_task.Finish(); } // Get the number of tasks in the queue int totalTasks = TotalTasks("Processing") + TotalTasks("Queued"); // If there are tasks, then if(totalTasks) { // Get the ID of the next current task ulong taskId = GetNextTaskId(); // Load the optimization task parameters from the database m_task.Load(taskId); // Launch the current task m_task.Start(); // Display the number of remaining tasks and the current task on the chart Comment(StringFormat( "Total tasks in queue: %d\n" "Current Task ID: %d", totalTasks, m_task.Id())); } else { // If there are no tasks, remove the EA from the chart PrintFormat(__FUNCTION__" | Finish.", 0); ExpertRemove(); } } }
Como puede ver, a este nivel de abstracción, da igual qué tipo de tarea deba realizarse la próxima vez: ejecutar la optimización de algún asesor experto en el simulador o un programa Python. La secuencia de acciones será la misma: mientras haya tareas en la cola, cargaremos los parámetros de la siguiente tarea, la iniciaremos para su ejecución y esperaremos a que se ejecute. Una vez ejecutada, repetiremos los pasos anteriores hasta que la cola de tareas esté vacía.
Ahora guardaremos los cambios realizados en el archivo COptimizer.mqh en la carpeta actual.
Clase de tarea de optimización
Nos queda lo más interesante para la clase COptimizerTask. Aquí se ejecutará directamente el interpretador de Python y se le transmitirá el programa escrito en Python para su ejecución. Así que al principio del archivo con esta clase, importaremos una función del sistema para ejecutar los archivos:
// Function to launch an executable file in the operating system #import "shell32.dll" int ShellExecuteW(int hwnd, string lpOperation, string lpFile, string lpParameters, string lpDirectory, int nShowCmd); #import
En la propia clase tendremos varios campos para almacenar los parámetros necesarios de la tarea de optimización, como el tipo, el identificador, el experto, el intervalo de optimización, el símbolo, el marco temporal y otros.
//+------------------------------------------------------------------+ //| Optimization task class | //+------------------------------------------------------------------+ class COptimizerTask { enum { TASK_TYPE_UNKNOWN, TASK_TYPE_EX5, TASK_TYPE_PY } m_type; // Task type (MQL5 or Python) ulong m_id; // Task ID string m_setting; // String for initializing the EA parameters for the current task string m_pythonPath; // Full path to the Python interpreter // Data structure for reading a single string of a query result struct params { string expert; int optimization; string from_date; string to_date; int forward_mode; string forward_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } m_params; // Get the full or relative path to a given file in the current folder string GetProgramPath(string name, bool rel = true); // Get initialization string from task parameters void Parse(); // Get task type from task parameters void ParseType(); public: // Constructor COptimizerTask() : m_id(0) {} // Task ID ulong Id() { return m_id; } // Set the full path to the Python interpreter void PythonPath(string p_pythonPath) { m_pythonPath = p_pythonPath; } // Main method void Process(); // Load task parameters from the database void Load(ulong p_id); // Start the task void Start(); // Complete the task void Finish(); // Task completed? bool IsDone(); };
La parte de parámetros que obtendremos directamente de la base de datos mediante el método Load() se almacenará en la estructura m_params. Basándonos en estos valores, determinaremos el tipo de tarea utilizando el método ParseType(), comprobando el final del nombre del archivo:
//+------------------------------------------------------------------+ //| Get task type from task parameters | //+------------------------------------------------------------------+ void COptimizerTask::ParseType() { string ext = StringSubstr(m_params.expert, StringLen(m_params.expert) - 3); if(ext == ".py") { m_type = TASK_TYPE_PY; } else if (ext == "ex5") { m_type = TASK_TYPE_EX5; } else { m_type = TASK_TYPE_UNKNOWN; } }
Y también generaremos la cadena de inicialización para probar o ejecutar un programa Python usando el método Parse(). En ella, dependiendo del tipo específico de tarea, generaremos una línea de parámetros para el simulador de estrategias o una cadena de parámetros para ejecutar un programa Python:
//+------------------------------------------------------------------+ //| Get initialization string from task parameters | //+------------------------------------------------------------------+ void COptimizerTask::Parse() { // Get the task type from the task parameters ParseType(); // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Generate a parameter string for the tester m_setting = StringFormat( "[Tester]\r\n" "Expert=%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=%d\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=%d\r\n" "ForwardDate=%s\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d\r\n" "fileName_=%s\r\n" "%s\r\n", GetProgramPath(m_params.expert), m_params.symbol, m_params.period, m_params.optimization, m_params.from_date, m_params.to_date, m_params.forward_mode, m_params.forward_date, m_params.optimization_criterion, m_params.id_task, DB::FileName(), m_params.tester_inputs ); // If this is a task to launch a Python program } else if (m_type == TASK_TYPE_PY) { // Form a program launch string on Python with parameters m_setting = StringFormat("\"%s\" \"%s\" %I64u %s", GetProgramPath(m_params.expert, false), // Python program file DB::FileName(true), // Path to the database file m_id, // Task ID m_params.tester_inputs // Launch parameters ); } }
El método Start() será el responsable de iniciar la tarea. En ella, volvemos a fijarnos en el tipo de tarea y, en función de esta, ejecutaremos la optimización en el simulador o ejecutaremos el programa Python mediante una llamada a la función del sistema ShellExecuteW():
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void COptimizerTask::Start() { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", m_id, m_setting); // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Launch a new optimization task in the tester MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(m_setting); MTTESTER::ClickStart(); // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing' " " WHERE id_task=%d", m_id); DB::Execute(query); DB::Close(); // If this is a task to launch a Python program } else if (m_type == TASK_TYPE_PY) { PrintFormat(__FUNCTION__" | SHELL EXEC: %s", m_pythonPath); // Call the system function to launch the program with parameters ShellExecuteW(NULL, NULL, m_pythonPath, m_setting, NULL, 1); } }
La comprobación de la ejecución de la tarea se reducirá a la comprobación del estado del simulador de estrategias (detenido o no) o a la comprobación del estado de la tarea en la base de datos mediante el identificador actual:
//+------------------------------------------------------------------+ //| Task completed? | //+------------------------------------------------------------------+ bool COptimizerTask::IsDone() { // If there is no current task, then everything is done if(m_id == 0) { return true; } // Result bool res = false; // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Check if the strategy tester has finished its work res = MTTESTER::IsReady(); // If this is a task to run a Python program, then } else if(m_type == TASK_TYPE_PY) { // Request to get the status of the current task string query = StringFormat("SELECT status " " FROM tasks" " WHERE id_task=%I64u;", m_id); // Open the database if(DB::Connect()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string status; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { // Check if the status is Done res = (row.status == "Done"); } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } } else { res = true; } return res; }
Después guardaremos los cambios realizados en el archivo COptimizerTask.mqh en la carpeta actual.
Programa para la clusterización
Ahora le toca el turno al programa de Python que ya hemos mencionado muchas veces. En general, la parte de este dedicada al funcionamiento principal ya se ha escrito en la parte 6. Echemos un vistazo:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df = df.sort_values(['cluster', 'Sharpe Ratio']).groupby('cluster').agg('last').reset_index()
clusters = df.cluster
df = df.iloc[:, 1:]
df['cluster'] = clusters
df.to_csv('Params_SV_EURGBP_H1-one_cluster.csv', index=False Cambiaremos lo siguiente:
- añadiremos la posibilidad de transmitir parámetros aclaratorios usando argumentos de la línea de comandos (nombre de la base de datos, ID de la tarea, número de clústeres, etc.);
- utilizaremos la información de la tabla passes en lugar de un archivo CSV;
- añadiremos la configuración del estado de inicio y finalización de la tarea en la base de datos;
- cambiaremos la composición de los campos utilizados para la clusterización, ya que no tenemos columnas separadas para cada parámetro de entrada de asesor experto en la tabla passes;
- reduciremos el número de campos de la tabla final, ya que, en esencia, solo necesitaremos conocer la relación entre el número de clúster y el identificador de pasada;
- en lugar de guardar los resultados en otro archivo, los guardaremos en una nueva tabla de la base de datos.
Para implementar todo lo anterior, necesitaremos conectar los módulos adicionales argparse y sqlite3:
import pandas as pd
from sklearn.cluster import KMeans
import sqlite3
import argparse Ahora asignaremos el objeto de la clase ArgumentParser para analizar los parámetros de entrada transmitidos a través de los argumentos de la línea de comandos y guardar los valores leídos en variables aparte para facilitar su uso posterior:
# Setting up the command line argument parser parser = argparse.ArgumentParser(description='Clustering passes for previous job(s)') parser.add_argument('db_path', type=str, help='Path to database file') parser.add_argument('id_task', type=int, help='ID of current task') parser.add_argument('--id_parent_job', type=str, help='ID of parent job(s)') parser.add_argument('--n_clusters', type=int, default=256, help='Number of clusters') parser.add_argument('--min_custom_ontester', type=float, default=0, help='Min value for `custom_ontester`') parser.add_argument('--min_trades', type=float, default=40, help='Min value for `trades`') parser.add_argument('--min_sharpe_ratio', type=float, default=0.7, help='Min value for `sharpe_ratio`') # Read the values of command line arguments into variables args = parser.parse_args() db_path = args.db_path id_task = args.id_task id_parent_job = args.id_parent_job n_clusters = args.n_clusters min_custom_ontester = args.min_custom_ontester min_trades = args.min_trades min_sharpe_ratio = args.min_sharpe_ratio
A continuación, nos conectaremos a la base de datos, marcaremos la tarea actual como "en ejecución" y crearemos (si no la hay) una nueva tabla para guardar los resultados de la clusterización. Si esta tarea se ejecuta nuevamente, tenga cuidado de borrar los resultados guardados con anterioridad:
# Establishing a connection to the database
connection = sqlite3.connect(db_path)
cursor = connection.cursor()
# Mark the start of the task
cursor.execute(f'''UPDATE tasks SET status='Processing' WHERE id_task={id_task};''')
connection.commit()
# Create a table for clustering results if there is none
cursor.execute('''CREATE TABLE IF NOT EXISTS passes_clusters (
id_task INTEGER,
id_pass INTEGER,
cluster INTEGER
);''')
# Clear the results table from previously obtained results
cursor.execute(f'''DELETE FROM passes_clusters WHERE id_task={id_task};''') Luego formularemos una consulta SQL para obtener los datos sobre las pasadas de optimización necesarias y los cargaremos desde la base de datos directamente en el dataframe:
# Load data about parent job passes for this task into the dataframe
query = f'''SELECT p.*
FROM passes p
JOIN
tasks t ON t.id_task = p.id_task
JOIN
jobs j ON j.id_job = t.id_job
WHERE p.profit > 0 AND
j.id_job IN ({id_parent_job}) AND
p.custom_ontester >= {min_custom_ontester} AND
p.trades >= {min_trades} AND
p.sharpe_ratio >= {min_sharpe_ratio};'''
df = pd.read_sql(query, connection)
# Display dataframe
print(df)
# List of dataframe columns
print(*enumerate(df.columns), sep='\n') Después de ver la lista de columnas del dataframe, seleccionaremos algunas de ellas para efectuar la clusterización. Como no disponemos de columnas separadas para los parámetros de entrada de las instancias de estrategias comerciales, realizaremos la clusterización según varios resultados estadísticos de pasadas (beneficio, número de operaciones, reducción, factor de beneficio, etc.). Los números de las columnas seleccionadas se especificarán en los parámetros del método iloc[]. Tras la clusterización, agruparemos las filas del dataframe en cada clúster y dejaremos solo una fila para el clúster con el valor más alto de beneficio medio anual normalizado:
# Run clustering on some columns of the dataframe kmeans = KMeans(n_clusters=n_clusters, n_init='auto', random_state=42).fit(df.iloc[:, [7, 8, 9, 24, 29, 30, 31, 32, 33, 36, 45, 46]]) # Add cluster numbers to the dataframe df['cluster'] = kmeans.labels_ # Set the current task ID df['id_task'] = id_task # Sort the dataframe by clusters and normalized profit df = df.sort_values(['cluster', 'custom_ontester']) # Display dataframe print(df) # Group the lines by cluster and take one line at a time # with the highest normalized profit from each cluster df = df.groupby('cluster').agg('last').reset_index()
Después solo dejaremos tres columnas en el dataframe, para las que crearemos la tabla de resultados: id_task, id_pass, cluster. Luego dejaremos el primero para poder borrar los resultados anteriores de la clusterización cuando volvamos a ejecutar este programa con el mismo valor id_task.
# Let's leave only id_task, id_pass and cluster columns in the dataframe df = df.iloc[:, [2, 1, 0]] # Display dataframe print(df)
Después guardaremos el dataframe en el modo de adición de datos en una tabla existente, marcaremos la tarea como completada y cerraremos la conexión a la base de datos:
# Save the dataframe to the passes_clusters table (replacing the existing one)
df.to_sql('passes_clusters', connection, if_exists='append', index=False)
# Mark the task completion
cursor.execute(f'''UPDATE tasks SET status='Done' WHERE id_task={id_task};''')
connection.commit()
# Close the connection
connection.close()
Guardaremos los cambios realizados en el archivo ClusteringStage1.py en la carpeta actual.
Asesor experto de la segunda etapa
Una vez tengamos listo el programa de clusterización para los resultados de la primera etapa de optimización, solo nos quedará implementar el soporte para la utilización de los resultados obtenidos por el asesor de la segunda etapa de optimización. Intentaremos hacerlo de la forma menos costosa.
Antes utilizábamos un asesor experto independiente, pero ahora haremos posible la implementación de la segunda etapa con y sin clusterización utilizando el mismo asesor experto. Luego añadiremos el parámetro lógico de entrada useClusters_, que nos indica si los resultados de la clusterización deben utilizarse al seleccionar grupos de instancias únicas de estrategias comerciales obtenidas en la primera etapa.
Si debemos utilizar los resultados de la clusterización, simplemente añadiremos a la consulta SQL que recupera la lista de instancias únicas de estrategias comerciales una unión con la tabla passes_clusters según el ID de las pasadas. En este caso, la consulta solo dará lugar a una pasada por cada clúster.
Al mismo tiempo, añadiremos varios parámetros más como parámetros de entrada del asesor experto, en los que podremos establecer condiciones adicionales para la selección de pasadas según el beneficio medio anual normalizado, el número de transacciones y el ratio de Sharpe.
Entonces solo tendremos que realizar cambios en la lista de parámetros de entrada y en la función CreateTaskDB():
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput int idTask_ = 0; // - Optimization task ID sinput string fileName_ = "db.sqlite"; // - Main database file input group "::: Selection for the group" input int idParentJob_ = 1; // - Parent job ID input bool useClusters_ = true; // - Use clustering input double minCustomOntester_ = 0; // - Min normalized profit input int minTrades_ = 40; // - Min number of trades input double minSharpeRatio_ = 0.7; // - Min Sharpe ratio input int count_ = 16; // - Number of strategies in the group (1 .. 16) ... //+------------------------------------------------------------------+ //| Creating a database for a separate stage task | //+------------------------------------------------------------------+ void CreateTaskDB(const string fileName, const int idParentJob) { // Create a new database for the current optimization task DB::Connect(PARAMS_FILE, 0); DB::Execute("DROP TABLE IF EXISTS passes;"); DB::Execute("CREATE TABLE passes (id_pass INTEGER PRIMARY KEY AUTOINCREMENT, params TEXT);"); DB::Close(); // Connect to the main database DB::Connect(fileName); // Clustering string clusterJoin = ""; if(useClusters_) { clusterJoin = "JOIN passes_clusters pc ON pc.id_pass = p.id_pass"; } // Request to obtain the required information from the main database string query = StringFormat("SELECT DISTINCT p.params" " FROM passes p" " JOIN " " tasks t ON p.id_task = t.id_task " " JOIN " " jobs j ON t.id_job = j.id_job " " %s " "WHERE (j.id_job = %d AND " " p.custom_ontester >= %.2f AND " " trades >= %d AND " " p.sharpe_ratio >= %.2f) " "ORDER BY p.custom_ontester DESC;", clusterJoin, idParentJob_, minCustomOntester_, minTrades_, minSharpeRatio_); // Execute the request ... }
Vamos a guardar los cambios realizados en el archivo SimpleVolumesStage2.mq5 en la carpeta actual y a comenzar las pruebas.
Simulación
Hoy crearemos cuatro etapas en la base de datos para nuestro proyecto denominadas "First", "Clustering passes from first stage", "Second" y "Second with clustering". Para cada etapa, crearemos dos trabajos para los símbolos EURGBP y GBPUSD en el marco temporal H1. Para los trabajos de la primera etapa, crearemos tres tareas de optimización, cada una con criterios diferentes (compleja, beneficio máximo y personalizada). Para los demás los trabajos crearemos una tarea para cada uno. Tomaremos el periodo de 2018 a 2023 como intervalo de optimización. Para cada trabajo, indicaremos los valores correctos de los parámetros de entrada.
Como resultado, deberíamos obtener información en la base de datos que genere estos resultados de la consulta que se muestra a continuación:
SELECT t.id_task,
t.optimization_criterion,
s.name AS stage_name,
s.expert AS stage_expert,
j.id_job,
j.symbol AS job_symbol,
j.period AS job_period,
j.tester_inputs AS job_tester_inputs
FROM tasks t
JOIN
jobs j ON j.id_job = t.id_job
JOIN
stages s ON s.id_stage = j.id_stage
WHERE t.id_task > 0; 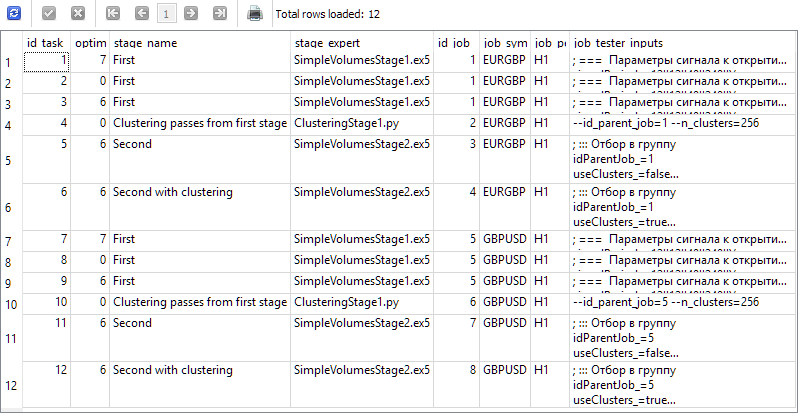
Vamos a ejecutar el asesor experto Optimisation.ex5 en el gráfico terminal y a esperar que todas las tareas se completen. Para esta cantidad de cálculos, 33 agentes han finalizado todas las etapas en unas 17 horas.
Para EURGBP, el mejor grupo encontrado sin clusterización ha tenido aproximadamente la misma rentabilidad media anual normalizada que al utilizar la clusterización (aproximadamente 4060 $). Pero en el caso de GBPUSD, la diferencia entre estas dos variantes de la segunda fase de optimización ha resultado más notable. Sin clusterización, hemos obtenido un valor de rendimiento medio anual normalizado de 4500 $ y con clusterización, un valor de 7500 $.
Esta diferencia de resultados para dos símbolos diferentes parece un poco extraña, pero bastante posible. No vamos a buscar las razones de tal diferencia, dejaremos la explicación para más adelante, cuando utilicemos más símbolos y marcos temporales en la optimización automática.
He aquí los resultados de los mejores grupos para ambos símbolos:
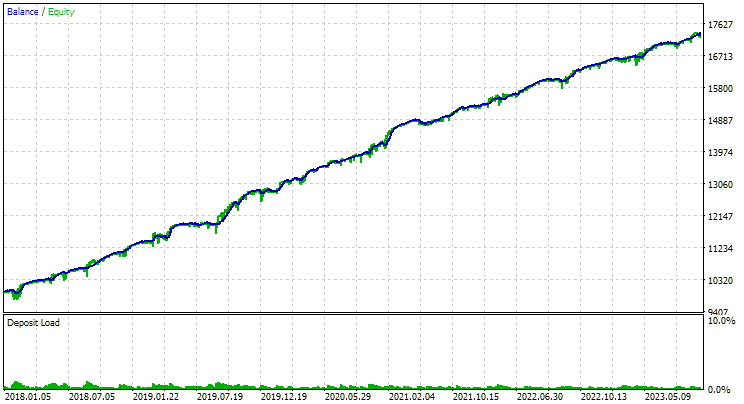
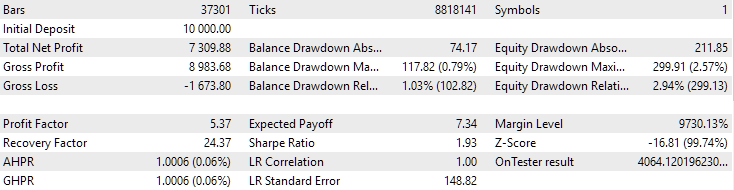
Fig. 1. Resultados del mejor grupo en la segunda etapa con clusterización para EURGBP H1
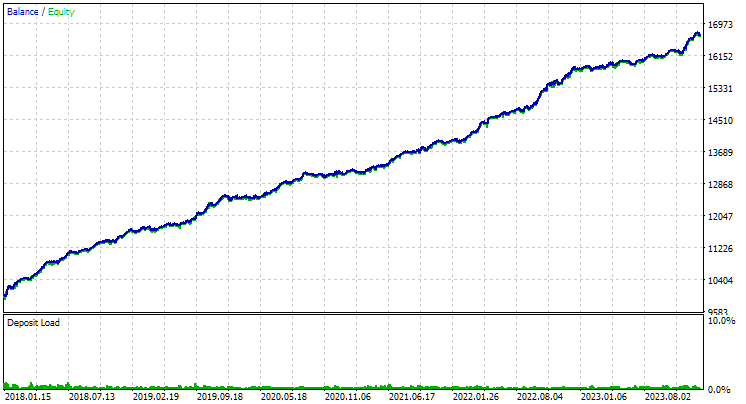
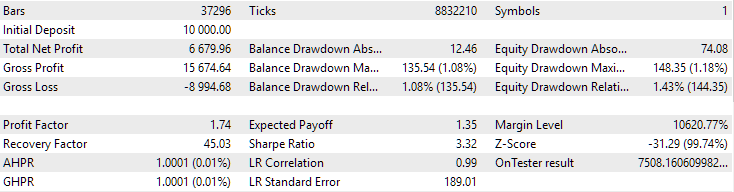
Fig. 2. Resultados del mejor grupo en la segunda etapa con clusterización para GBPUSD H1
Otra cuestión interesante que desearía plantear es la siguiente. Vamos a realizar una clusterización y de cada clúster tomaremos una mejor instancia única de la estrategia comerciales (pasada del simulador). Así formaremos una lista de buenas instancias de las que seleccionaremos el mejor grupo. Si realizamos la clusterización para 256 clústeres, tendremos 256 instancias en esta lista. En la segunda fase de optimización, seleccionaremos unas 16 instancias de 256 para fusionarlas en un solo grupo. ¿Podemos no realizar el segundo paso, y en lugar de ello tomar 16 instancias individuales de estrategias comerciales de diferentes grupos con la mayor rentabilidad media anual normalizada?
Si hacemos esto, se reducirá considerablemente el tiempo dedicado a la optimización automática. Al fin y al cabo, al realizar la optimización en la segunda etapa, tendremos un asesor experto funcionando con 16 instancias de lo que se optimizará en la primera etapa. Por ello, una pasada del simulador también conllevará proporcionalmente más tiempo.
Para el conjunto de tareas de optimización analizados en el presente artículo, podríamos reducir el tiempo en unas 6 horas. Es una fracción sustancial de las 17 horas empleadas. Y si consideramos que añadimos dos problemas de optimización de segunda etapa sin clusterización solo para comparar sus resultados con los de la segunda etapa con clusterización, la reducción relativa del tiempo resultará aún más significativa.
Para responder a esta pregunta, veamos los resultados de una consulta que selecciona instancias únicas para la segunda etapa antes de la segunda etapa. Para mayor claridad, añadiremos a la lista de columnas el índice bajo el que se tomará cada instancia en la segunda etapa, el ID de pasada de esta instancia en la primera etapa, el número de clúster y el valor del beneficio medio anual normalizado. Obtendremos lo siguiente:
SELECT DISTINCT ROW_NUMBER() OVER (ORDER BY custom_ontester DESC) AS [index], p.id_pass, pc.cluster, p.custom_ontester, p.params FROM passes p JOIN tasks t ON p.id_task = t.id_task JOIN jobs j ON t.id_job = j.id_job JOIN passes_clusters pc ON pc.id_pass = p.id_pass WHERE (j.id_job = 5 AND p.custom_ontester >= 0 AND trades >= 40 AND p.sharpe_ratio >= 0.7) ORDER BY p.custom_ontester DESC;
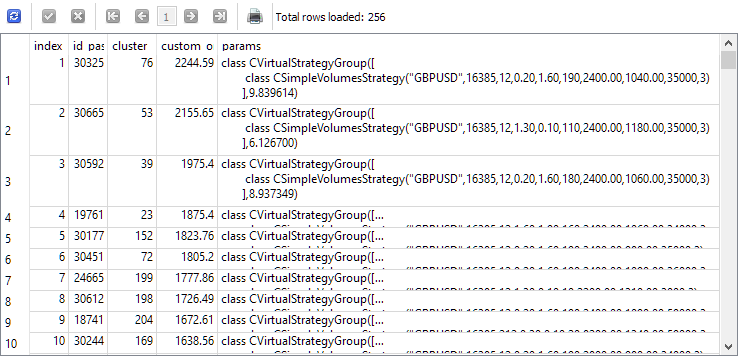
Como podemos ver, los casos individuales con los mayores rendimientos medios anuales normalizados poseen los valores de índice más pequeños. Por consiguiente, si tomamos un grupo de instancias individuales con índices del 1 al 16, obtendremos exactamente el grupo que queríamos reunir para compararlo con el mejor grupo obtenido en el segundo paso de optimización.
Vamos a utilizar el asesor experto de la segunda etapa estableciendo números del 1 al 16 en los parámetros de entrada de los índices de instancia. Obtendremos la siguiente imagen:
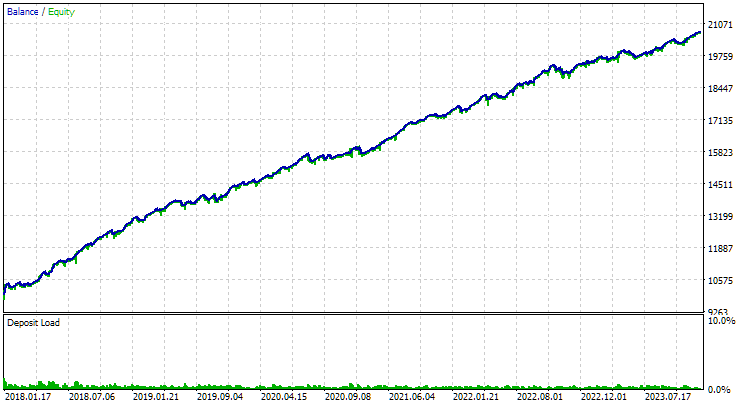
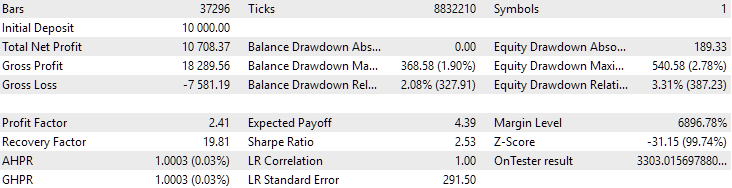
Fig. 3. Resultados del grupo de los 16 primeros casos con la mayor rentabilidad media anual normalizada para GBPUSD H1
El gráfico tiene un carácter similar al del gráfico número 2, pero el valor del beneficio medio anual normalizado se ha reducido a más de la mitad: 3300 $ frente a 7500 $. Esto se debe a la reducción mucho mayor que observamos en este grupo en comparación con la reducción del mejor grupo de la figura 2. Una situación similar se observa en el caso de EURGBP, aunque para este símbolo la disminución del beneficio medio anual normalizado ha resultado ser algo menor, pero aún significativa.
Así que parece que no podremos ahorrar tiempo en la segunda fase de optimización de esta forma.
Por último, veamos los resultados derivados de la combinación de los dos mejores grupos encontrados:
Fig. 4. Resultados de los dos grupos de mejor rendimiento conjunto para EURGBP H1 y GBPUSD H1
Como podemos ver, todos los parámetros han resultado en algún punto entre los valores de los parámetros para los grupos individuales. Por ejemplo, la rentabilidad media anual normalizada ha sido de 4900 $, un valor superior al de este parámetro para el grupo EURGBP H1, pero menor que para el grupo GBPUSD H1.
Conclusión
Echemos un vistazo a lo que tenemos. Hoy hemos añadido la posibilidad de crear etapas de optimización automáticas que pueden ejecutar aplicaciones de terceros, concretamente programas Python. No obstante, si es necesario, ahora podemos añadir soporte para ejecutar programas en otros lenguajes interpretados, o simplemente cualquier programa compilado, con un mínimo esfuerzo.
Hasta ahora, hemos usado esta característica para reducir el número de instancias únicas de estrategias comerciales de la primera etapa de optimización que participan en la segunda. Para ello, hemos dividido todas las instancias en un número relativamente pequeño de clústeres y hemos tomado solo una instancia de cada clúster. La reducción del número de instancias ha disminuido ligeramente el tiempo de la segunda etapa, mientras que los resultados no han empeorado o han mejorado significativamente. Así que no hemos trabajado en vano.
Sin embargo, aún queda margen de mejora. El perfeccionamiento del programa de clusterización puede consistir en procesar correctamente las situaciones en las que el número de instancias seleccionadas para las instancias individuales es inferior al número de clústeres. Y esto provocará un error. También podemos estudiar la posibilidad de ampliar el conjunto de estrategias comerciales y organizar cómodamente los proyectos de optimización automática. Pero eso será en otra ocasión.
Gracias por su atención, ¡hasta pronto!
Todos los resultados expuestos en este artículo y en todos los artículos anteriores de la serie se basan únicamente en datos de pruebas históricas y no ofrecen ninguna garantía de lograr beneficios en el futuro. El trabajo de este proyecto es de carácter exploratorio. Todos los resultados publicados pueden ser usados por cualquiera bajo su propia responsabilidad.
Contenido del archivo
| # | Nombre | Versión | Descripción | Cambios recientes |
|---|---|---|---|---|
| MQL5/Experts/Article.15911 | ||||
| 1 | Advisor.mqh | 1.04. | Clase básica del experto | Parte 10 |
| 2 | ClusteringStage1.py | 1.00 | Programa de clusterización de los resultados de la primera fase de optimización | Parte 19 |
| 3 | Database.mqh | 1.07 | Clase para trabajar con bases de datos | Parte 19 |
| 4 | database.sqlite.schema.sql | - | Esquema de la base de datos | Parte 19 |
| 5 | ExpertHistory.mqh | 1.00 | Clase para exportar la historia de transacciones a un archivo | Parte 16 |
| 6 | ExportedGroupsLibrary.mqh | - | Archivo generado con los nombres de los grupos de estrategias y un array con sus cadenas de inicialización | Parte 17 |
| 7 | Factorable.mqh | 1.02 | Clase básica de objetos creados a partir de una cadena | Parte 19 |
| 8 | GroupsLibrary.mqh | 1.01 | Clase para trabajar con una biblioteca de grupos estratégicos seleccionados | Parte 18 |
| 9 | HistoryReceiverExpert.mq5 | 1.00 | Asesor experto para reproducir la historia de transacciones con el gestor de riesgos | Parte 16 |
| 10 | HistoryStrategy.mqh | 1.00 | Clase de estrategia comercial para reproducir la historia de transacciones | Parte 16 |
| 11 | Interface.mqh | 1.00 | Clase básica de visualización de diversos objetos | Parte 4 |
| 12 | LibraryExport.mq5 | 1.01 | Asesor que guarda las líneas de inicialización de las pasadas seleccionadas de la biblioteca en el archivo ExportedGroupsLibrary.mqh | Parte 18 |
| 13 | Macros.mqh | 1.02 | Macros útiles para operaciones con arrays | Parte 16 |
| 14 | Money.mqh | 1.01 | Clase básica de gestión de capital | Parte 12 |
| 15 | NewBarEvent.mqh | 1.00 | Clase de definición de una nueva barra para un símbolo específico | Parte 8 |
| 16 | Optimization.mq5 | 1.03 | Asesor que gestiona el inicio de las tareas de optimización | Parte 19 |
| 17 | Optimizador.mqh | 1.00 | Clase para el gestor de optimización automática de proyectos | Parte 19 |
| 18 | OptimizerTask.mqh | 1.00 | Clase para la tarea de optimización | Parte 19 |
| 19 | Receiver.mqh | 1.04. | Clase básica de transferencia de volúmenes abiertos a posiciones de mercado | Parte 12 |
| 20 | SimpleHistoryReceiverExpert.mq5 | 1.00 | Asesor experto simplificado para reproducir la historia de transacciones | Parte 16 |
| 21 | SimpleVolumesExpert.mq5 | 1.20 | Asesor experto para el trabajo en paralelo de varios grupos de estrategias modelo. Los parámetros se tomarán de la biblioteca de grupos incorporada. | Parte 17 |
| 22 | SimpleVolumesStage1.mq5 | 1.18 | Asesor experto para optimizar una única instancia de una estrategia comercial (Etapa 1) | Parte 19 |
| 23 | SimpleVolumesStage2.mq5 | 1.02 | Asesor experto que optimiza un grupo de instancias de estrategias comerciales (Etapa 2) | Parte 19 |
| 24 | SimpleVolumesStage3.mq5 | 1.01 | Asesor experto que guarda un grupo normalizado generado de estrategias en la biblioteca de grupos con el nombre especificado. | Parte 18 |
| 25 | SimpleVolumesStrategy.mqh | 1.09 | Clase de estrategia comercial con uso de volúmenes de ticks | Parte 15 |
| 26 | Strategy.mqh | 1.04. | Clase básica de estrategia comercial | Parte 10 |
| 27 | TesterHandler.mqh | 1.05 | Clase para gestionar los eventos de optimización | Parte 19 |
| 28 | VirtualAdvisor.mqh | 1.07 | Clase de asesor experto que trabaja con posiciones (órdenes) virtuales | Parte 18 |
| 29 | VirtualChartOrder.mqh | 1.01 | Clase de posición virtual gráfica | Parte 18 |
| 30 | VirtualFactory.mqh | 1.04. | Clase de fábrica de objetos | Parte 16 |
| 31 | VirtualHistoryAdvisor.mqh | 1.00 | Clase experta para reproducir la historia de transacciones | Parte 16 |
| 32 | VirtualInterface.mqh | 1.00 | Clase de GUI del asesor | Parte 4 |
| 33 | VirtualOrder.mqh | 1.07 | Clase de órdenes y posiciones virtuales | Parte 19 |
| 34 | VirtualReceiver.mqh | 1.03 | Clase de transferencia de volúmenes abiertos a posiciones de mercado (receptor) | Parte 12 |
| 35 | VirtualRiskManager.mqh | 1.02 | Clase de gestión de riesgos (gestor de riesgos) | Parte 15 |
| 36 | VirtualStrategy.mqh | 1.05 | Clase de estrategia comercial con posiciones virtuales | Parte 15 |
| 37 | VirtualStrategyGroup.mqh | 1.00 | Clase de grupo o grupos de estrategias comerciales | Parte 11 |
| 38 | VirtualSymbolReceiver.mqh | 1.00 | Clase de receptor simbólico | Parte 3 |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/15911
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Ejecuto esto
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1. py.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
y obtengo este error
ValueError: n_samples=150 debería ser >= n_clusters=256.
entonces cambio n_clusters=150 y ejecuto
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=150
y creo que funcionó. pero en la base de datos no hay ningun cambio
despues de eso intente optimizar con n_samples=150 pero no funciono
Ejecuto este
...
y creo que funciono. pero en la base de datos no hay ningun cambio
¿No hay una nueva tabla passes_clusters en la base de datos?
¿No hay una nueva tabla passes_clusters en la base de datos?
Ha funcionado correctamente.
El error estaba relacionado con la base de datos.
Después de corregir la base de datos, el código Python y la Etapa 2 funcionaron bien.
Gracias por su ayuda.
¡Interesante artículo! Leeré toda la serie.
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
¿Por qué abandonaron la funcionalidad de la biblioteca AlgLib?
#include <Math\Alglib\alglib.mqh>Menos sólo en velocidad, pero sobre todo porque python paraleliza los cálculos en todos los núcleos.