
开发多币种 EA 交易(第 19 部分):创建用 Python 实现的阶段
概述
很久以前,我们就探讨过自动选择一组优秀交易策略的单一实例(在第 6 部分中)。当时,我们还没有一个可以收集所有测试运行结果的数据库。为此,我们使用了一个常规的 CSV 文件。那篇文章的主要目的是检验一个假设,即自动选择一个好的组可以比手动选择产生更好的结果。
我们完成了任务,假设得到了证实。接下来,我们来看看如何改进这种自动选择的结果。事实证明,如果我们将所有单个实例的集合拆分为相对较少的集群,并确保在选择一个组时,来自同一集群的实例不会最终出现在其中,那么这不仅有助于提高最终 EA 的交易结果,还有助于减少选择过程本身的时间。
为了执行聚类,我们使用了现成的 Python 库 scikit-learn ,或者更准确地说,使用了 K-Means 算法的实现。这不是唯一的聚类算法,但考虑到其他可能的算法,比较和选择应用于该问题的最佳算法超出了可接受的范围。因此,基本上采用了第一种算法,使用它获得的结果非常好。
然而,使用这种特殊的实现使得有必要运行一个小型 Python 程序。当我们手动进行大部分操作时,这并不太麻烦。但现在我们已经在自动化测试和选择良好的单个交易策略实例组的整个过程方面取得了重大进展,即使是在顺序执行的优化任务的管道中间进行简单的手动操作也显得很糟糕。
为了解决这个问题,我们可以采取两条途径。第一种是找到集群算法的现成 MQL5 实现,或者自己实现。第二种涉及添加不仅启动用 MQL5 编写的 EA 的能力,而且还在自动优化的所需阶段启动 Python 程序的能力。
经过深思熟虑,我选择了第二种方法。让我们开始实现它。
规划路径
那么,让我们看看如何从 MQL5 程序运行 Python 应用程序。最明显的方法如下:
- 直接启动。我们可以使用一个操作系统函数,该函数允许我们运行带有参数的可执行文件。可执行文件将是 Python 解释器,参数将是程序文件的名称及其启动参数。这种方法的缺点是需要使用 DLL 中的外部函数,但我们已经使用它们来启动策略测试器。
- 通过 Web 请求启动。我们可以创建一个具有必要 API 的简单 Web 服务器,负责在通过调用 WebRequest() 从 MQL5 程序接收到请求时运行所需的 Python 程序。要创建 Web 服务器,我们可以使用 Flask 或任何其他框架。这种方法的缺点是,它对于解决简单问题来说太复杂了。
尽管第二种方法很有吸引力,但让我们把它的实现推迟到以后,当实现其他相关事物的时候。最终,我们甚至能够创建一个成熟的 Web 界面来管理整个自动优化过程,将当前的 Optimization.ex5 EA 转变为 MQL5 服务。与终端一起启动的服务将监视数据库中具有排队状态的项目的外观,如果出现这种情况,将为这些项目执行所有排队的优化任务。但现在我们将实现第一个更简单的启动选项。
下一个问题是如何选择存储聚类结果的方法。在第 6 部分中,我们将集群编号作为新列放入表中,该表最初存储交易策略单个实例的优化通过的结果。然后,以类似的方式,我们可以向 passes 表中添加一个新列并将集群编号放入其中。但并非每个优化阶段都意味着对其通过的结果进行进一步的聚类。因此,该列将在 passes 表中的许多行中存储空值。这不是很好。
为了避免这种情况,让我们创建一个单独的表,其中仅存储通行 ID 和分配给它们的集群编号。在第二阶段优化开始时,我们只需将新表中的数据添加到通过 ID( id_pass )链接的 passes 表中,以考虑已完成的聚类。
根据自动优化过程中所需的操作顺序,聚类阶段应在第一和第二阶段之间执行。为了避免进一步的混淆,我们将继续使用“第一”和“第二”阶段的名称来表示以前称为第一和第二的相同阶段。新添加的阶段将被称为对第一阶段结果进行聚类的阶段。
然后我们需要做以下事情:
- 对 Optimization.mq5 EA 进行更改,以便它可以运行在 Python 中实现的步骤。
- 编写 Python 代码来接受所需的参数,从数据库加载有关通过的信息,对其进行聚类,并将结果保存到数据库。
- 用三个阶段、针对这些阶段的作业、针对不同的交易工具和时间框架以及针对这些作业的优化任务、针对一个或多个优化标准填充数据库。
- 执行自动优化并评估结果。
修复
这一次,没有检测到关键错误,因此我们将专注于纠正不准确之处,这些不准确之处不会直接影响自动优化后获得的最终顾问,但会干扰对优化阶段有效性的跟踪以及在优化框架外启动的单次过程的结果。
让我们首先添加触发器来设置任务( task )的开始和结束日期。现在,它们由在策略测试器中停止优化之前和之后从 Optimization.mq5 EA 执行的 SQL 查询进行修改:
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void StartTask(ulong taskId, string setting) { ... // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing', " " start_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); } //+------------------------------------------------------------------+ //| Task completion | //+------------------------------------------------------------------+ void FinishTask(ulong taskId) { PrintFormat(__FUNCTION__" | Task ID = %d", taskId); // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Done', " " finish_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); }
触发逻辑将会很简单。如果 tasks 表中的任务状态变为 Processing(处理中),则将开始日期 ( start_date ) 设置为当前时间。如果任务状态变为 Done(完成),则将结束日期( finish_date )设置为当前时间。如果任务状态变为 Queued(排队),则应清除开始和结束日期。最后提到的状态更改操作不是从 EA 执行的,而是通过手动修改 tasks 表中的 status 字段值来执行的。
这些触发器的实现可能如下所示:
CREATE TRIGGER IF NOT EXISTS upd_task_start_date AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Processing' BEGIN UPDATE tasks SET start_date= DATETIME('NOW') WHERE id_task=NEW.id_task; END; CREATE TRIGGER IF NOT EXISTS upd_task_finish_date AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Done' BEGIN UPDATE tasks SET finish_date= DATETIME('NOW') WHERE id_task=NEW.id_task; END; CREATE TRIGGER IF NOT EXISTS reset_task_dates AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Queued' BEGIN UPDATE tasks SET start_date= NULL, finish_date=NULL WHERE id_task=NEW.id_task; END;
创建这样的触发器后,我们可以从 EA 中删除 start_date 和 finish_date 修改,只留下状态变化。
另一个小但烦人的错误是,当我们迁移到新数据库后手动运行策略测试器的单次通过时,当前优化任务 ID 值默认为 0。如果我们忘记添加 id_task = 0 的特殊任务,则尝试向 passes 表中插入具有此类 id_task 值的条目可能会导致在检查外部键时出现错误。如果有的话,那么一切都很好。
因此,让我们为在 projects 表中创建新条目的事件添加一个触发器。一旦我们创建一个新项目,我们就需要一个阶段、一个工作和一个任务,以便为其自动创建单次通过。这个触发器的实现可能如下所示:
CREATE TRIGGER IF NOT EXISTS insert_empty_stage AFTER INSERT ON projects BEGIN INSERT INTO stages ( id_project, name, optimization, status ) VALUES ( NEW.id_project, 'Single tester pass', 0, 'Done' ); END; DROP TRIGGER IF EXISTS insert_empty_job; CREATE TRIGGER IF NOT EXISTS insert_empty_job AFTER INSERT ON stages WHEN NEW.name = 'Single tester pass' BEGIN INSERT INTO jobs VALUES ( NULL, NEW.id_stage, NULL, NULL, NULL, 'Done' ); INSERT INTO tasks ( id_job, optimization_criterion, status ) VALUES ( (SELECT id_job FROM jobs WHERE id_stage=NEW.id_stage), -1, 'Done' ); END;
另一个不准确的是,当我们手动运行策略测试器的单次通过时,passes 表(即 pass_date 字段)接收的是测试间隔的结束时间而不是当前时间。发生这种情况是因为我们在 EA 内部的 SQL 查询中使用 TimeCurrent() 函数来设置时间值。但在测试模式下,该函数返回的不是真实的当前时间,而是模拟的时间。因此,如果我们的测试间隔在 2022 年底结束,则通过将保存在 passes 表中,结束时间与 2022 年底一致。
那么,为什么 passes 表会接收优化期间执行的所有通过的正确当前结束时间?答案其实很简单。重点在于,在优化过程中,用于保存通过结果的 SQL 查询不是由测试器中启动的 EA 实例执行的,而是在数据帧收集模式下的终端图表上执行的。由于它不能在测试器中工作,因此它从 TimeCurrent() 函数接收当前(实际而非模拟)时间。
为了解决这个问题,我们将添加一个触发器,该触发器在向 passes 表插入新条目后启动。触发器将设置当前日期:
CREATE TRIGGER IF NOT EXISTS upd_pass_date
AFTER INSERT
ON passes
BEGIN
UPDATE passes
SET pass_date = DATETIME('NOW')
WHERE id_pass = NEW.id_pass;
END;
在从 EA 向 passes 表添加新行的 SQL 查询中,删除由 EA 计算的当前时间的替换,并简单地传递常量 NULL。
对现有类还进行了一些其他的小补充和更正。在 CVirtualOrder 中,我添加了一个用于更改到期时间的方法和一个用于检查虚拟订单数组以查看其中一个订单是否已被触发的静态方法。这些方法尚未使用,但可能在其他交易策略中有用。
在 CFactorable 中,我修复了 ReadNumber() 方法的行为,以便它在到达初始化字符串的末尾时返回 NULL,而不是根据需要重复输出最后一个读取的数字。此编辑要求在风险管理器初始化字符串中指定与应有的参数数量完全相同的参数 - 13 个而不是 6 个:
// Prepare the initialization string for the risk manager string riskManagerParams = StringFormat( "class CVirtualRiskManager(\n" " 0,0,0,0,0,0,0,0,0,0,0,0,0" " )", 0 );
在 CDatabase 数据库处理类中,我们添加了一个新的静态方法,我们将使用它来切换到所需的数据库。基本上,在方法内部,我们只需使用所需的名称和位置连接到数据库,然后立即关闭连接:
static void Test(string p_fileName = NULL, int p_common = DATABASE_OPEN_COMMON) { Connect(p_fileName, p_common); Close(); };
调用该方法后,再次调用不带参数的 Connect() 方法将连接到所需的数据库。
在完成这一非核心但必要的部分后,让我们继续执行主要任务。
Optimization.mq5 重构
首先,我们需要对 Optimization.mq5 EA 进行修改。在 EA 中,我们需要在 stages 表中添加对正在启动的文件的名称(expert 字段)的检查。如果名称以 “.py” 结尾,那么此阶段将运行 Python 程序。我们可以将调用它所需的参数放在 jobs 表的 tester_inputs 字段中。
然而,事情并没有结束。我们需要以某种方式将数据库名称、当前任务 ID 传递给 Python 程序,并且我们需要以某种方式启动它。这会导致 EA 代码明显增加,而且已经相当大了。因此,让我们从将现有程序代码分布到多个文件开始。
在 Optimization.mq5 EA 的主文件中,我们将只保留计时器的创建以及执行主要工作的新类 COptimizer 。我们要做的就是在其 Process() 处理程序中调用计时器方法,并在 EA 初始化/取消初始化期间注意正确创建/删除该对象。
sinput string fileName_ = "database911.sqlite"; // - File with the main database sinput string pythonPath_ = "C:\\Python\\Python312\\python.exe"; // - Path to Python interpreter COptimizer *optimizer; // Pointer to the optimizer object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Connect to the main database DB::Test(fileName_); // Create an optimizer optimizer = new COptimizer(pythonPath_); // Create the timer and start its handler EventSetTimer(20); OnTimer(); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert timer function | //+------------------------------------------------------------------+ void OnTimer() { // Start the optimizer handling optimizer.Process(); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { EventKillTimer(); // Remove the optimizer if(!!optimizer) { delete optimizer; } }
在创建优化器对象时,我们向其构造函数传递一个参数,即启动 EA 的计算机上 Python 解释器可执行文件的完整路径。我们在 pythonPath_EA 输入中指定此参数的值。将来,我们可以通过在优化器类中实现解释器的自动搜索来摆脱这个参数,但现在我们将仅限于这种更简单的方法。
我们将对当前文件夹中的 Optimization.mq5 文件所做的更改保存起来。
优化器类
让我们创建 COptimizer类。在公共方法中,它只有主要的 Process() 处理方法和构造函数。在私有部分中,我们将添加一个方法来获取执行队列中的任务数量,以及一个方法来获取队列中下一个任务的 ID。我们将把与特定优化任务相关的所有工作转移到较低级别 —— 到 COptimizerTask 新类对象(优化任务)。然后,我们将需要优化器中这个类的一个对象。
//+------------------------------------------------------------------+ //| Class for the project auto optimization manager | //+------------------------------------------------------------------+ class COptimizer { // Current optimization task COptimizerTask m_task; // Get the number of tasks with a given status in the queue int TotalTasks(string status = "Queued"); // Get the ID of the next optimization task from the queue ulong GetNextTaskId(); public: COptimizer(string p_pythonPath = NULL); // Constructor void Process(); // Main processing method };
我从 Optimization.mq5 EA 的先前版本中的相应函数中取出了 TotalTasks() 和 GetNextTaskId() 方法的代码,几乎没有任何改动。对于代码从 OnTimer() 函数迁移到的 Process() 方法也可以这样说。但是,由于我们为优化任务引入了一个新类,它仍然需要进行更大的修改。总体而言,此方法的代码变得更加清晰:
//+------------------------------------------------------------------+ //| Main handling method | //+------------------------------------------------------------------+ void COptimizer::Process() { PrintFormat(__FUNCTION__" | Current Task ID = %d", m_task.Id()); // If the EA is stopped, remove the timer and the EA itself from the chart if (IsStopped()) { EventKillTimer(); ExpertRemove(); return; } // If the current task is completed, if (m_task.IsDone()) { // If the current task is not empty, if(m_task.Id()) { // Complete the current task m_task.Finish(); } // Get the number of tasks in the queue int totalTasks = TotalTasks("Processing") + TotalTasks("Queued"); // If there are tasks, then if(totalTasks) { // Get the ID of the next current task ulong taskId = GetNextTaskId(); // Load the optimization task parameters from the database m_task.Load(taskId); // Launch the current task m_task.Start(); // Display the number of remaining tasks and the current task on the chart Comment(StringFormat( "Total tasks in queue: %d\n" "Current Task ID: %d", totalTasks, m_task.Id())); } else { // If there are no tasks, remove the EA from the chart PrintFormat(__FUNCTION__" | Finish.", 0); ExpertRemove(); } } }
正如你所看到的,在这个抽象级别上,下次需要执行什么样的任务没有区别 —— 在测试器中运行一些 EA 的优化,或者在 Python 中运行一个程序。操作顺序将是相同的:当队列中有任务时,我们加载下一个任务的参数,启动它执行,并等待它完成。完成后,重复上述步骤,直到任务队列为空。
我们将对当前文件夹中的 COptimizer.mqh 文件所做的更改保存起来。
优化任务类
我们把最有趣的东西留给了 COptimizerTask 类。在这个目录中,Python 解释器将被直接启动,并将编写的 Python 程序传递给它执行。因此,在这个类的文件的开头,我们导入了用于运行文件的系统函数:
// Function to launch an executable file in the operating system #import "shell32.dll" int ShellExecuteW(int hwnd, string lpOperation, string lpFile, string lpParameters, string lpDirectory, int nShowCmd); #import
在类本身中,我们将有几个字段来存储优化任务的必要参数,例如类型、ID、EA、优化间隔、交易品种、时间框架等。
//+------------------------------------------------------------------+ //| Optimization task class | //+------------------------------------------------------------------+ class COptimizerTask { enum { TASK_TYPE_UNKNOWN, TASK_TYPE_EX5, TASK_TYPE_PY } m_type; // Task type (MQL5 or Python) ulong m_id; // Task ID string m_setting; // String for initializing the EA parameters for the current task string m_pythonPath; // Full path to the Python interpreter // Data structure for reading a single string of a query result struct params { string expert; int optimization; string from_date; string to_date; int forward_mode; string forward_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } m_params; // Get the full or relative path to a given file in the current folder string GetProgramPath(string name, bool rel = true); // Get initialization string from task parameters void Parse(); // Get task type from task parameters void ParseType(); public: // Constructor COptimizerTask() : m_id(0) {} // Task ID ulong Id() { return m_id; } // Set the full path to the Python interpreter void PythonPath(string p_pythonPath) { m_pythonPath = p_pythonPath; } // Main method void Process(); // Load task parameters from the database void Load(ulong p_id); // Start the task void Start(); // Complete the task void Finish(); // Task completed? bool IsDone(); };
我们将使用 Load() 方法直接从数据库接收的那部分参数将存储在 m_params 结构中。根据这些值,我们将使用 ParseType() 方法通过检查文件名的结尾来确定任务类型:
//+------------------------------------------------------------------+ //| Get task type from task parameters | //+------------------------------------------------------------------+ void COptimizerTask::ParseType() { string ext = StringSubstr(m_params.expert, StringLen(m_params.expert) - 3); if(ext == ".py") { m_type = TASK_TYPE_PY; } else if (ext == "ex5") { m_type = TASK_TYPE_EX5; } else { m_type = TASK_TYPE_UNKNOWN; } }
我们还将使用 Parse() 方法生成一个字符串,用于初始化测试或运行 Python 程序。在此字符串中,我们将形成一个参数字符串,用于策略测试器,或者根据特定的任务类型运行 Python 程序:
//+------------------------------------------------------------------+ //| Get initialization string from task parameters | //+------------------------------------------------------------------+ void COptimizerTask::Parse() { // Get the task type from the task parameters ParseType(); // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Generate a parameter string for the tester m_setting = StringFormat( "[Tester]\r\n" "Expert=%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=%d\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=%d\r\n" "ForwardDate=%s\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d\r\n" "fileName_=%s\r\n" "%s\r\n", GetProgramPath(m_params.expert), m_params.symbol, m_params.period, m_params.optimization, m_params.from_date, m_params.to_date, m_params.forward_mode, m_params.forward_date, m_params.optimization_criterion, m_params.id_task, DB::FileName(), m_params.tester_inputs ); // If this is a task to launch a Python program } else if (m_type == TASK_TYPE_PY) { // Form a program launch string on Python with parameters m_setting = StringFormat("\"%s\" \"%s\" %I64u %s", GetProgramPath(m_params.expert, false), // Python program file DB::FileName(true), // Path to the database file m_id, // Task ID m_params.tester_inputs // Launch parameters ); } }
Start() 方法负责启动任务。在该方法中,我们再次查看任务类型,并根据它,在测试器中运行优化或通过调用 ShellExecuteW() 系统运行 Python 程序:
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void COptimizerTask::Start() { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", m_id, m_setting); // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Launch a new optimization task in the tester MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(m_setting); MTTESTER::ClickStart(); // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing' " " WHERE id_task=%d", m_id); DB::Execute(query); DB::Close(); // If this is a task to launch a Python program } else if (m_type == TASK_TYPE_PY) { PrintFormat(__FUNCTION__" | SHELL EXEC: %s", m_pythonPath); // Call the system function to launch the program with parameters ShellExecuteW(NULL, NULL, m_pythonPath, m_setting, NULL, 1); } }
检查任务的执行情况可以归结为检查策略测试器的状态(是否停止),或者通过当前 ID 检查数据库中任务的状态:
//+------------------------------------------------------------------+ //| Task completed? | //+------------------------------------------------------------------+ bool COptimizerTask::IsDone() { // If there is no current task, then everything is done if(m_id == 0) { return true; } // Result bool res = false; // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Check if the strategy tester has finished its work res = MTTESTER::IsReady(); // If this is a task to run a Python program, then } else if(m_type == TASK_TYPE_PY) { // Request to get the status of the current task string query = StringFormat("SELECT status " " FROM tasks" " WHERE id_task=%I64u;", m_id); // Open the database if(DB::Connect()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string status; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { // Check if the status is Done res = (row.status == "Done"); } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } } else { res = true; } return res; }
将所做的更改保存到当前文件夹中的 COptimizerTask.mqh 文件。
聚类程序
现在到了我已经多次提到过的那个 Python 程序的时间了。总的来说,其中完成主要工作的部分已经在第 6 部分中开发完毕。让我们看一下:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df = df.sort_values(['cluster', 'Sharpe Ratio']).groupby('cluster').agg('last').reset_index()
clusters = df.cluster
df = df.iloc[:, 1:]
df['cluster'] = clusters
df.to_csv('Params_SV_EURGBP_H1-one_cluster.csv', index=False
我们需要在其中进行如下修改:
- 添加通过命令行参数传递澄清参数的功能(数据库名称、任务 ID、聚类数量等);
- 使用来自 passes 表而不是 CSV 文件的信息;
- 在数据库中添加设置任务执行的开始和结束状态;
- 更改用于聚类的字段组成,因为我们在 passes 表中没有为每个 EA 输入参数设置单独的列;
- 减少最终表中的字段数量,因为我们本质上只需要知道聚类编号和通过 ID 之间的关系;
- 将结果保存到新的数据库表,而不是保存到另一个文件。
为了实现上述所有功能,我们需要连接额外的模块 argparse 和 sqlite3:
import pandas as pd
from sklearn.cluster import KMeans
import sqlite3
import argparse
ArgumentParser 类对象用于解析通过命令行参数传递的输入。我们将把读取的值保存在单独的变量中,以便于进一步使用:
# Setting up the command line argument parser parser = argparse.ArgumentParser(description='Clustering passes for previous job(s)') parser.add_argument('db_path', type=str, help='Path to database file') parser.add_argument('id_task', type=int, help='ID of current task') parser.add_argument('--id_parent_job', type=str, help='ID of parent job(s)') parser.add_argument('--n_clusters', type=int, default=256, help='Number of clusters') parser.add_argument('--min_custom_ontester', type=float, default=0, help='Min value for `custom_ontester`') parser.add_argument('--min_trades', type=float, default=40, help='Min value for `trades`') parser.add_argument('--min_sharpe_ratio', type=float, default=0.7, help='Min value for `sharpe_ratio`') # Read the values of command line arguments into variables args = parser.parse_args() db_path = args.db_path id_task = args.id_task id_parent_job = args.id_parent_job n_clusters = args.n_clusters min_custom_ontester = args.min_custom_ontester min_trades = args.min_trades min_sharpe_ratio = args.min_sharpe_ratio
接下来,我们将连接到数据库,将当前任务标记为正在运行,并创建(如果不可用)一个新表来保存聚类结果。如果再次运行此任务,您需要注意清除以前保存的结果:
# Establishing a connection to the database
connection = sqlite3.connect(db_path)
cursor = connection.cursor()
# Mark the start of the task
cursor.execute(f'''UPDATE tasks SET status='Processing' WHERE id_task={id_task};''')
connection.commit()
# Create a table for clustering results if there is none
cursor.execute('''CREATE TABLE IF NOT EXISTS passes_clusters (
id_task INTEGER,
id_pass INTEGER,
cluster INTEGER
);''')
# Clear the results table from previously obtained results
cursor.execute(f'''DELETE FROM passes_clusters WHERE id_task={id_task};''')
然后,我们形成一个 SQL 查询来获取所需优化过程的数据,并将其从数据库直接加载到数据帧中:
# Load data about parent job passes for this task into the dataframe
query = f'''SELECT p.*
FROM passes p
JOIN
tasks t ON t.id_task = p.id_task
JOIN
jobs j ON j.id_job = t.id_job
WHERE p.profit > 0 AND
j.id_job IN ({id_parent_job}) AND
p.custom_ontester >= {min_custom_ontester} AND
p.trades >= {min_trades} AND
p.sharpe_ratio >= {min_sharpe_ratio};'''
df = pd.read_sql(query, connection)
# Let's look at the dataframe
print(df)
# List of dataframe columns
print(*enumerate(df.columns), sep='\n')
在查看了数据帧中的列列表后,我们将选择其中一些进行聚类。由于我们没有单独的交易策略实例输入列,我们将根据通过的各种统计结果(利润、交易数量、回撤、利润因子等)进行聚类。所选列的数量将在 iloc[] 方法参数中指定。聚类之后,我们按每个聚类对数据框行进行分组,并且只为具有最高标准化年平均利润值的聚类留下一行:
# Run clustering on some columns of the dataframe kmeans = KMeans(n_clusters=n_clusters, n_init='auto', random_state=42).fit(df.iloc[:, [7, 8, 9, 24, 29, 30, 31, 32, 33, 36, 45, 46]]) # Add cluster numbers to the dataframe df['cluster'] = kmeans.labels_ # Set the current task ID df['id_task'] = id_task # Sort the dataframe by clusters and normalized profit df = df.sort_values(['cluster', 'custom_ontester']) # Let's look at the dataframe print(df) # Group the lines by cluster and take one line at a time # with the highest normalized profit from each cluster df = df.groupby('cluster').agg('last').reset_index()
在此之后,我们只在数据框中留下三列,为其创建结果表: id_task 、 id_pass 和 cluster 。我们保留第一个,以便在使用相同的 id_task 值再次运行程序时可以清除以前的聚类结果。
# Let's leave only id_task, id_pass and cluster columns in the dataframe df = df.iloc[:, [2, 1, 0]] # Let's look at the dataframe print(df)
我们以向现有表添加数据的方式保存数据帧,标记任务完成,并关闭与数据库的连接:
# Save the dataframe to the passes_clusters table (replacing the existing one)
df.to_sql('passes_clusters', connection, if_exists='append', index=False)
# Mark the task completion
cursor.execute(f'''UPDATE tasks SET status='Done' WHERE id_task={id_task};''')
connection.commit()
# Close the connection
connection.close()
将所做的更改保存到当前文件夹中的 ClusteringStage1.py 文件。
第二阶段的 EA 交易
现在我们有了一个对第一阶段优化结果进行聚类的程序,剩下的就是实现对优化第二阶段 EA 使用所获得结果的支持。我们将尽力以最低的成本做到这一点。
以前,我们使用了一个单独的 EA,但现在我们将使其能够在没有初步聚类的情况下进行第二阶段,并使用相同的 EA 进行聚类。让我们添加 useClusters_ 逻辑参数,它回答了在第一阶段获得的交易策略单个实例中选择组时是否有必要使用聚类结果的问题。
如果需要使用聚类结果,我们只需将通过 pass ID 连接 passes_clusters 表添加到接收交易策略单个实例列表的 SQL 查询中。在这种情况下,我们将仅获得每个聚类的一次查询结果。
在此过程中,我们将添加更多参数作为 EA 的输入,在其中我们将能够设置通过标准化平均年利润、交易数量和夏普比率选择通过的附加条件。
然后我们只需要对输入参数列表和 CreateTaskDB() 函数进行更修:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput int idTask_ = 0; // - Optimization task ID sinput string fileName_ = "db.sqlite"; // - Main database file input group "::: Selection for the group" input int idParentJob_ = 1; // - Parent job ID input bool useClusters_ = true; // - Use clustering input double minCustomOntester_ = 0; // - Min normalized profit input int minTrades_ = 40; // - Min number of trades input double minSharpeRatio_ = 0.7; // - Min Sharpe ratio input int count_ = 16; // - Number of strategies in the group (1 .. 16) ... //+------------------------------------------------------------------+ //| Creating a database for a separate stage task | //+------------------------------------------------------------------+ void CreateTaskDB(const string fileName, const int idParentJob) { // Create a new database for the current optimization task DB::Connect(PARAMS_FILE, 0); DB::Execute("DROP TABLE IF EXISTS passes;"); DB::Execute("CREATE TABLE passes (id_pass INTEGER PRIMARY KEY AUTOINCREMENT, params TEXT);"); DB::Close(); // Connect to the main database DB::Connect(fileName); // Clustering string clusterJoin = ""; if(useClusters_) { clusterJoin = "JOIN passes_clusters pc ON pc.id_pass = p.id_pass"; } // Request to obtain the required information from the main database string query = StringFormat("SELECT DISTINCT p.params" " FROM passes p" " JOIN " " tasks t ON p.id_task = t.id_task " " JOIN " " jobs j ON t.id_job = j.id_job " " %s " "WHERE (j.id_job = %d AND " " p.custom_ontester >= %.2f AND " " trades >= %d AND " " p.sharpe_ratio >= %.2f) " "ORDER BY p.custom_ontester DESC;", clusterJoin, idParentJob_, minCustomOntester_, minTrades_, minSharpeRatio_); // Execute the request ... }
将对 SimpleVolumesStage2.mq5 文件所做的更改保存在当前文件夹中并启动测试。
测试
让我们在数据库中为我们的项目创建四个阶段,名称分别为“第一阶段”、“第一阶段的聚类”、“第二阶段”和“第二阶段的聚类”。对于每个阶段,我们将在 H1 时间框架内为 EURGBP 和 GBPUSD 交易品种创建两个工作。对于第一阶段,我们将创建三个具有不同标准(复杂度、最大利润和自定义)的优化任务。对于剩余的工作,我们将分别创建一个任务。我们将以 2018 年至 2023 年为优化区间。对于每项工作,我们都会指出正确的输入参数值。
因此,我们的数据库中应该有通过以下查询生成以下结果的信息:
SELECT t.id_task,
t.optimization_criterion,
s.name AS stage_name,
s.expert AS stage_expert,
j.id_job,
j.symbol AS job_symbol,
j.period AS job_period,
j.tester_inputs AS job_tester_inputs
FROM tasks t
JOIN
jobs j ON j.id_job = t.id_job
JOIN
stages s ON s.id_stage = j.id_stage
WHERE t.id_task > 0;
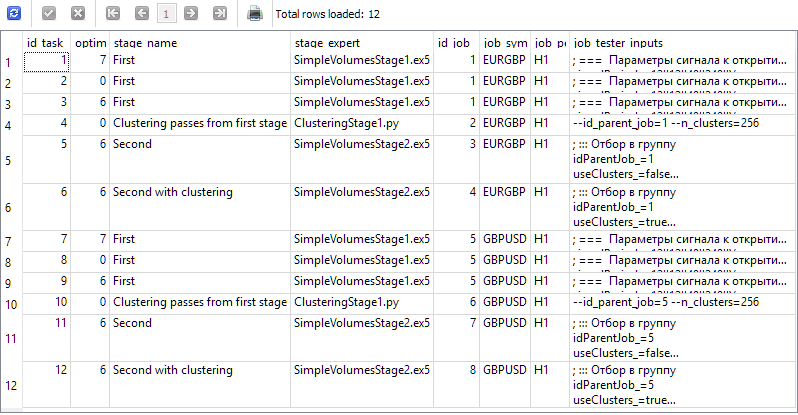
在终端图表上启动 Optimization.ex5 EA 并等待所有任务完成。对于这样的计算量,33 个代理大约需要 17 个小时才能完成所有阶段。
对于 EURGBP,未使用聚类找到的最佳组具有与使用聚类时大致相同的标准化平均年回报率(约为 4060 美元)。但对于 GBPUSD 而言,进行第二阶段优化的这两个选项之间的差异更加明显。如果不进行聚类,则获得的标准化平均年利润值为 4500 美元,而进行聚类则为 7500 美元。
两个不同交易品种的结果存在差异似乎有点奇怪,但很有可能。我们现在不会深入研究这种差异的原因,而是留到以后,当我们在自动优化中使用更多的交易品种和时间框架时再研究。
以下是两个交易品种的最佳分组结果:
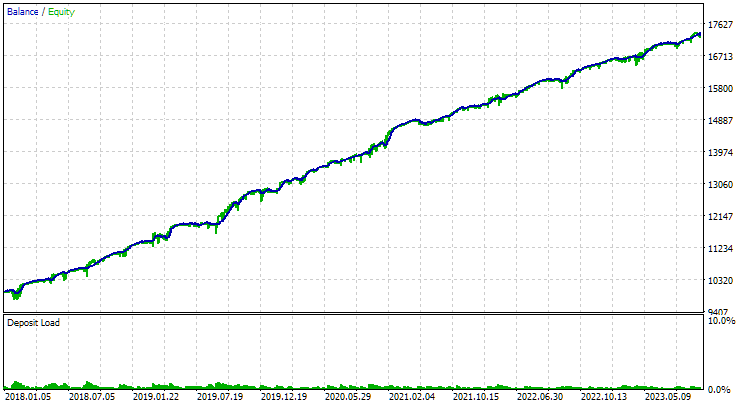
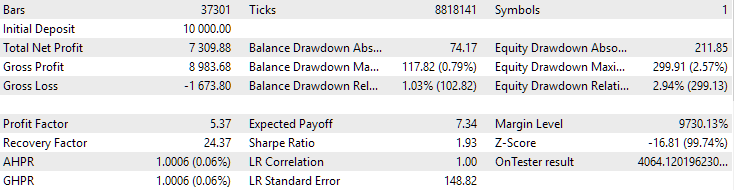
图 1.第二阶段 EURGBP H1 聚类的最佳组结果
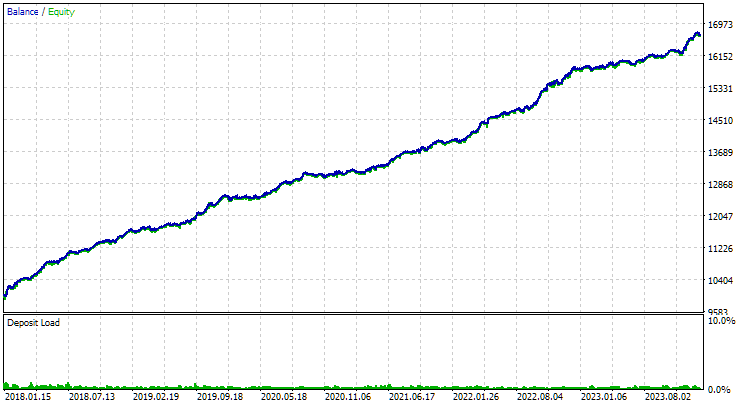
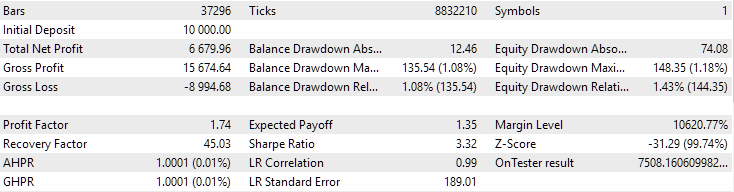
图 2.GBPUSD H1 第二阶段聚类结果
我还想提出另一个有趣的问题。我们进行聚类,并从每个聚类中取出交易策略的一个最佳单个实例(测试器通过)。通过这种方式,我们形成了一个好样本的列表,从中我们将选择最好的一组。如果我们对 256 个集群进行聚类,那么该列表将包含 256 个实例。在优化的第二阶段,我们将从 256 个实例中选择大约 16 个实例组合成一个组。是否有可能跳过第二阶段,只从具有最高归一化平均年利润的不同集群中获取 16 份交易策略的单一副本?
如果能够做到这一点,将大大减少用于自动优化的时间。毕竟,在第二阶段的优化过程中,我们启动了一个 EA,其中包含第一阶段优化内容的 16 个副本。因此,一次测试运行所需的时间按比例增加。
对于本文中考虑的一组优化问题,我们可以将时间减少约 6 小时。这是所花费的 17 个小时中的很大一部分。如果我们考虑到我们在没有聚类的情况下添加了两个第二阶段优化任务,只是为了将它们的结果与有聚类的第二阶段的结果进行比较,那么时间的相对减少将更加显著。
为了回答这个问题,让我们看看在第二阶段开始之前为其选择单个实例的查询结果。为了清楚起见,我们将在第二阶段中获取每个实例的索引、该实例在第一阶段的通过 ID、聚类编号和标准化年平均利润的值添加到列表。我们得到的结果如下:
SELECT DISTINCT ROW_NUMBER() OVER (ORDER BY custom_ontester DESC) AS [index], p.id_pass, pc.cluster, p.custom_ontester, p.params FROM passes p JOIN tasks t ON p.id_task = t.id_task JOIN jobs j ON t.id_job = j.id_job JOIN passes_clusters pc ON pc.id_pass = p.id_pass WHERE (j.id_job = 5 AND p.custom_ontester >= 0 AND trades >= 40 AND p.sharpe_ratio >= 0.7) ORDER BY p.custom_ontester DESC;
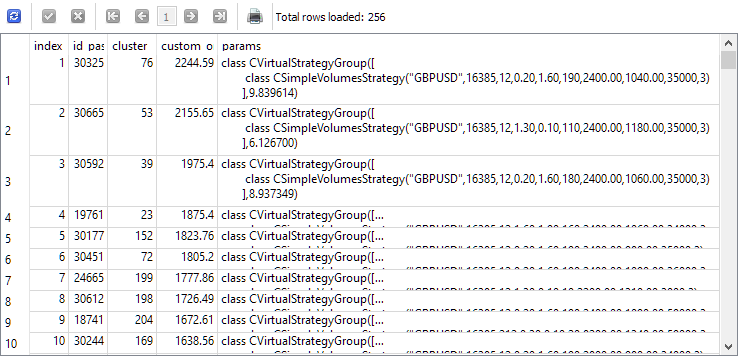
正如我们所看到的,归一化平均年利润最高的单个实例的指标值最小。因此,如果我们取一组索引为 1 到 16 的单个实例,我们将得到我们想要收集的组,以便与第二优化阶段获得的最佳组进行比较。
让我们使用第二阶段 EA,在实例索引的输入参数中指定从 1 到 16 的数字。我们得到如下图片:
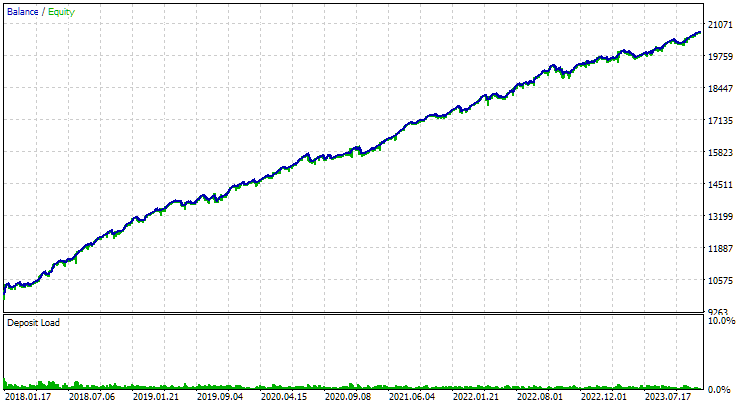
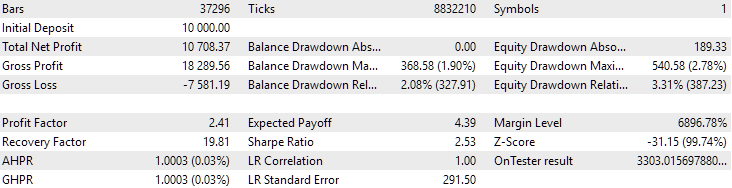
图 3.GBPUSD H1 上半年标准化年均收益率最高的 16 个样本结果
该图在性质上与图 2 中的图相似,但归一化平均年利润的值已经减小了两倍多:3300 美元对 7500 美元。这是由于与图 2 中最佳组的回撤相比,该组的回撤要大得多。EURGBP 也出现了类似的情况,尽管对于该交易品种,归一化平均年利润的下降幅度较小,但仍然很大。
因此,看起来我们无法通过这种方式在第二阶段优化上节省时间。
最后,让我们看看将发现的两个最佳组组合在一起的结果:
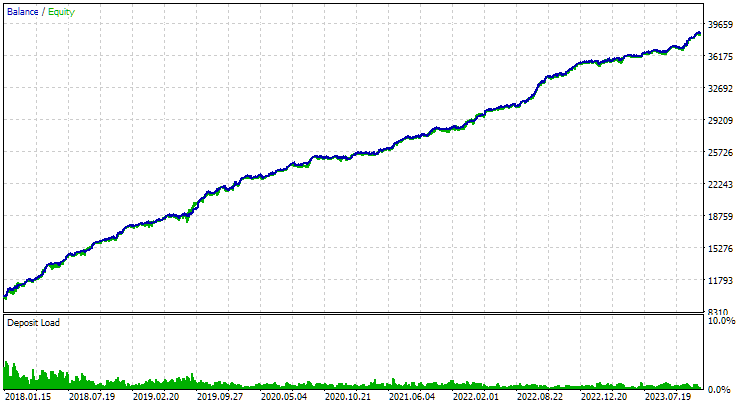
图4.EURGBP H1 和 GBPUSD H1 两个最佳组的联合工作结果
正如我们所看到的,所有结果参数都介于各个组的参数值之间。例如,标准化的平均年利润为 4900 美元,大于 EURGBP H1 组的该参数值,但小于 GBPUSD H1 组的该参数值。
结论
那么,让我们看看我们得到了什么。我们增加了创建可以运行第三方应用程序(即 Python 程序)的自动优化步骤的能力。然而,如有必要,我们现在只需稍加努力,就可以添加对以其他解释性语言运行程序的支持,或者简单地添加对任何编译程序的支持。
到目前为止,我们已经使用此功能减少了参与第二阶段优化的第一阶段交易策略的单个实例的数量。为此,我们将所有实例划分为相对较少的集群,并从每个集群中只取一个实例。减少副本的数量在一定程度上减少了完成第二阶段所需的时间,结果要么没有恶化,要么变得明显更好。所以这项工作并没有白费。
然而,仍有取得进一步进展的空间。聚类程序的改进可能在于正确处理为单个实例选择的聚类数量小于聚类数量的情况。现在这将导致错误。我们还可以考虑扩大交易策略的范围,并方便地组织自动优化项目。下次再详细讨论。
感谢您的关注!期待很快与您见面!
本文和本系列之前的所有文章中的所有结果仅基于历史测试数据,并不保证未来会有任何利润。该项目中的工作具有研究性质。所有已发表的结果都可以由任何人使用,风险自负。
存档内容
| # | 名称 | 版本 | 描述 | 最近修改 |
|---|---|---|---|---|
| MQL5/专家/文章.15911 | ||||
| 1 | Advisor.mqh | 1.04 | EA 基类 | 第 10 部分 |
| 2 | ClusteringStage1.py | 1.00 | 对第一阶段优化结果进行聚类的程序 | 第 19 部分 |
| 3 | Database.mqh | 1.07 | 处理数据库的类 | 第 19 部分 |
| 4 | database.sqlite.schema.sql | — | 数据库结构 | 第 19 部分 |
| 5 | ExpertHistory.mqh | 1.00 | 用于将交易历史导出到文件的类 | 第 16 部分 |
| 6 | ExportedGroupsLibrary.mqh | — | 生成的文件列出了策略组名称及其初始化字符串数组 | 第 17 部分 |
| 7 | Factorable.mqh | 1.02 | 从字符串创建的对象的基类 | 第 19 部分 |
| 8 | GroupsLibrary.mqh | 1.01 | 用于处理选定策略组库的类 | 第 18 部分 |
| 9 | HistoryReceiverExpert.mq5 | 1.00 | 用于与风险管理器回放交易历史的 EA | 第 16 部分 |
| 10 | HistoryStrategy.mqh | 1.00 | 用于回放交易历史的交易策略类 | 第 16 部分 |
| 11 | Interface.mqh | 1.00 | 可视化各种对象的基类 | 第 4 部分 |
| 12 | LibraryExport.mq5 | 1.01 | EA 将库中选定通过的初始化字符串保存到 ExportedGroupsLibrary.mqh 文件 | 第 18 部分 |
| 13 | Macros.mqh | 1.02 | 用于数组操作的有用的宏 | 第 16 部分 |
| 14 | Money.mqh | 1.01 | 资金管理基类 | 第 12 部分 |
| 15 | NewBarEvent.mqh | 1.00 | 用于定义特定交易品种的新柱形的类 | 第 8 部分 |
| 16 | Optimization.mq5 | 1.03 | EA 管理优化任务的启动 | 第 19 部分 |
| 17 | Optimizer.mqh | 1.00 | 项目自动优化管理器类 | 第 19 部分 |
| 18 | OptimizerTask.mqh | 1.00 | 优化任务类 | 第 19 部分 |
| 19 | Receiver.mqh | 1.04 | 将未平仓交易量转换为市场仓位的基类 | 第 12 部分 |
| 20 | SimpleHistoryReceiverExpert.mq5 | 1.00 | 简化的EA,用于回放交易历史 | 第 16 部分 |
| 21 | SimpleVolumesExpert.mq5 | 1.20 | 用于多组模型策略并行运行的 EA。参数将从内置组库中获取。 | 第 17 部分 |
| 22 | SimpleVolumesStage1.mq5 | 1.18 | 交易策略单实例优化EA(第一阶段) | 第 19 部分 |
| 23 | SimpleVolumesStage2.mq5 | 1.02 | 交易策略实例组优化EA(第二阶段) | 第 19 部分 |
| 24 | SimpleVolumesStage3.mq5 | 1.01 | 将生成的标准化策略组保存到具有给定名称的组库中的 EA。 | 第 18 部分 |
| 25 | SimpleVolumesStrategy.mqh | 1.09 | 使用分时交易量的交易策略类 | 第 15 部分 |
| 26 | Strategy.mqh | 1.04 | 交易策略基类 | 第 10 部分 |
| 27 | TesterHandler.mqh | 1.05 | 优化事件处理类 | 第 19 部分 |
| 28 | VirtualAdvisor.mqh | 1.07 | 处理虚拟仓位(订单)的 EA 类 | 第 18 部分 |
| 29 | VirtualChartOrder.mqh | 1.01 | 图形虚拟仓位类 | 第 18 部分 |
| 30 | VirtualFactory.mqh | 1.04 | 对象工厂类 | 第 16 部分 |
| 31 | VirtualHistoryAdvisor.mqh | 1.00 | 交易历史回放 EA 类 | 第 16 部分 |
| 32 | VirtualInterface.mqh | 1.00 | EA GUI 类 | 第 4 部分 |
| 33 | VirtualOrder.mqh | 1.07 | 虚拟订单和仓位类 | 第 19 部分 |
| 34 | VirtualReceiver.mqh | 1.03 | 将未平仓交易量转换为市场仓位的类(接收方) | 第 12 部分 |
| 35 | VirtualRiskManager.mqh | 1.02 | 风险管理类(风险管理器) | 第 15 部分 |
| 36 | VirtualStrategy.mqh | 1.05 | 具有虚拟仓位的交易策略类 | 第 15 部分 |
| 37 | VirtualStrategyGroup.mqh | 1.00 | 交易策略组类 | 第 11 部分 |
| 38 | VirtualSymbolReceiver.mqh | 1.00 | 交易品种接收器类 | 第 3 部分 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/15911
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
我这样运行
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
得到以下错误
ValueError: n_samples=150 should be >= n_clusters=256.
然后我更改 n_clusters=150,并运行
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=150
我认为成功了。但数据库中没有任何变化
之后,我尝试用 n_samples=150 进行优化, 但没有成功
我运行这个
...
我认为成功了。但数据库没有任何变化
数据库中没有新表passes_clusters?
数据库中没有新表 passes_clusters ?
运行正常。
错误与数据库有关。
更正数据库后,Python 代码和第 2 阶段工作正常。
感谢您的帮助。
有趣的文章!那我就把整个系列读完。
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
他们为什么放弃 AlgLib 库的功能?
#include <Math\Alglib\alglib.mqh>速度上的减分,但主要是因为 Python 可以在所有内核上进行并行计算。