
Entwicklung eines Expert Advisors für mehrere Währungen (Teil 19): In Python implementierte Stufen erstellen
Einführung
Wir haben uns schon vor längerer Zeit mit der Automatisierung der Auswahl einer guten Gruppe von Einzelinstanzen von Handelsstrategien beschäftigt in (Teil 6). Zu diesem Zeitpunkt verfügten wir noch nicht über eine Datenbank, in der die Ergebnisse aller Testläufe gesammelt werden konnten. Zu diesem Zweck haben wir eine normale CSV-Datei verwendet. Das Hauptziel dieses Artikels war es, die Hypothese zu testen, dass die automatische Auswahl einer guten Gruppe bessere Ergebnisse liefern kann als die manuelle Auswahl.
Wir haben die Aufgabe erfüllt und die Hypothese wurde bestätigt. Als Nächstes wurde untersucht, wie wir die Ergebnisse einer solchen automatischen Auswahl verbessern können. Es stellte sich heraus, dass, wenn wir die Menge aller Einzelinstanzen in eine relativ kleine Anzahl von Clustern aufteilen und sicherstellen, dass Instanzen aus demselben Cluster bei der Auswahl einer Gruppe nicht darin landen, dies nicht nur die Handelsergebnisse des endgültigen EA verbessert, sondern auch die Zeit für den Auswahlprozess selbst reduziert.
Für das Clustering haben wir die fertige Python-Bibliothek scikit-learn verwendet, genauer gesagt, die Implementierung des Algorithmus K-Means. Dies ist nicht der einzige Clustering-Algorithmus, aber die Betrachtung anderer möglicher Algorithmen, der Vergleich und die Auswahl des besten Algorithmus, wie er auf dieses Problem angewandt wurde, überstieg die akzeptablen Grenzen. Daher wurde im Wesentlichen der erste Algorithmus verwendet, der zur Verfügung stand, und die damit erzielten Ergebnisse erwiesen sich als recht gut.
Die Verwendung dieser speziellen Implementierung machte es jedoch erforderlich, ein kleines Python-Programm auszuführen. Dies war kein allzu großes Problem, als wir die meisten Vorgänge noch manuell durchführten. Aber jetzt, wo wir erhebliche Fortschritte bei der Automatisierung des gesamten Prozesses des Testens und der Auswahl guter Gruppen einzelner Handelsstrategie-Instanzen gemacht haben, sieht es schlecht aus, wenn selbst ein einfacher manueller Vorgang in der Mitte einer Pipeline von sequentiell ausgeführten Optimierungsaufgaben steht.
Um dies zu beheben, können wir zwei Wege einschlagen. Die erste besteht darin, eine fertige MQL5-Implementierung des Clustering-Algorithmus zu finden oder ihn selbst zu implementieren. Die zweite beinhaltet die Möglichkeit, nicht nur in MQL5 geschriebene EAs zu starten, sondern auch Python-Programme in den erforderlichen Phasen der automatischen Optimierung.
Nach einigem Überlegen habe ich mich für die zweite Option entschieden. Lassen Sie uns mit der Umsetzung beginnen.
Der Weg ist vorgezeichnet
Schauen wir uns also an, wie wir eine Python-Anwendung aus einem MQL5-Programm heraus starten können. Die naheliegendsten Möglichkeiten wären die folgenden:
- Direkter Start. Wir können eine der Funktionen des Betriebssystems verwenden, mit der wir eine ausführbare Datei mit Parametern ausführen können. Die ausführbare Datei ist der Python-Interpreter, und die Parameter sind der Name der Programmdatei und ihre Startparameter. Der Nachteil dieses Ansatzes ist die Notwendigkeit, externe Funktionen von DLL zu verwenden, aber wir verwenden sie bereits, um den Strategietester zu starten.
- Start über eine Web-Anfrage. Wir können einen einfachen Webserver mit der erforderlichen API erstellen, der für die Ausführung der erforderlichen Python-Programme verantwortlich ist, wenn Anfragen von einem MQL5-Programm über den Aufruf von WebRequest() eingehen. Um einen Webserver zu erstellen, können wir z. B. Flask oder ein anderes Framework verwenden. Der Nachteil dieses Ansatzes ist, dass er zu komplex ist, um ein einfaches Problem zu lösen.
Trotz aller Attraktivität der zweiten Methode sollten wir ihre Umsetzung auf einen späteren Zeitpunkt verschieben, wenn es an der Zeit ist, andere verwandte Dinge zu implementieren. Letztendlich werden wir sogar in der Lage sein, eine vollwertige Weboberfläche für die Verwaltung des gesamten Prozesses der automatischen Optimierung zu schaffen und den aktuellen EA Optimization.ex5 in einen MQL5-Dienst umzuwandeln. Der zusammen mit dem Terminal gestartete Dienst überwacht das Auftauchen von Projekten in der Datenbank mit dem Status „in der Warteschlange“ und führt, wenn solche erscheinen, alle in der Warteschlange stehenden Optimierungsaufgaben für diese Projekte durch. Vorerst werden wir jedoch die erste, einfachere Startoption umsetzen.
Die nächste Frage ist, wie man eine Methode zur Speicherung der Ergebnisse des Clustering wählt. In Teil 6 haben wir die Clusternummer als neue Spalte in die Tabelle eingefügt, in der ursprünglich die Ergebnisse der Optimierungsläufe einzelner Instanzen der Handelsstrategie gespeichert wurden. In ähnlicher Weise können wir dann eine neue Spalte in die Tabelle der Ausweise einfügen und darin Clusternummern unterbringen. Aber nicht jede Optimierungsstufe impliziert eine weitere Clusterung der Ergebnisse ihrer Durchgänge. Daher wird die Spalte für viele Zeilen in der Durchgangstabelle leere Werte speichern. Das ist nicht sehr gut.
Um dies zu vermeiden, erstellen wir eine separate Tabelle, in der nur die Pass-IDs und die ihnen zugewiesenen Clusternummern gespeichert werden. Zu Beginn der zweiten Optimierungsphase fügen wir einfach die Daten aus der neuen Tabelle zu den Pässen hinzu, indem wir sie mit den Pass-IDs(id_pass) verknüpfen, um das abgeschlossene Clustering zu berücksichtigen.
Ausgehend von der erforderlichen Reihenfolge der Aktionen bei der automatischen Optimierung sollte die Clusterung zwischen der ersten und der zweiten Stufe erfolgen. Um weitere Verwirrung zu vermeiden, werden wir weiterhin die Bezeichnungen „erste“ und „zweite“ Stufe für die gleichen Stufen verwenden, die zuvor als erste und zweite Stufe bezeichnet wurden. Die neu hinzugefügte Stufe wird als Stufe des Clustering der Ergebnisse der ersten Stufe bezeichnet.
Dann müssen wir Folgendes tun:
- Wir nehmen Änderungen an dem EA Optimization.mq5 vor, damit sie die in Python implementierten Schritte ausführen kann.
- Wir schreiben den Python-Code, der die erforderlichen Parameter akzeptiert, Informationen über die Pässe aus der Datenbank lädt, sie clustert und die Ergebnisse in der Datenbank speichert.
- Wir füllen die Datenbank mit drei Stufen, Aufträgen für diese Stufen, für verschiedene Handelsinstrumente und Zeitrahmen, und Optimierungsaufgaben für diese Aufträge, für ein oder mehrere Optimierungskriterien.
- Wir führen eine automatische Optimierung durch und werten die Ergebnisse aus.
Korrekturen
Dieses Mal wurden keine kritischen Fehler entdeckt, sodass wir uns auf die Korrektur von Ungenauigkeiten konzentrieren, die sich nicht direkt auf den endgültigen Berater auswirken, der durch die automatische Optimierung erhalten wurde, sondern die Gültigkeit der Optimierungsphasen und die Ergebnisse der einzelnen Durchgänge, die außerhalb des Optimierungsrahmens gestartet wurden, beeinträchtigen.
Beginnen wir mit dem Hinzufügen von Auslösern, um das Start- und Enddatum der Aufgabe festzulegen (task). Jetzt werden sie durch SQL-Abfragen geändert, die von der EA Optimization.mq5 vor und nach dem Stoppen der Optimierung im Strategietester ausgeführt werden:
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void StartTask(ulong taskId, string setting) { ... // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing', " " start_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); } //+------------------------------------------------------------------+ //| Task completion | //+------------------------------------------------------------------+ void FinishTask(ulong taskId) { PrintFormat(__FUNCTION__" | Task ID = %d", taskId); // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Done', " " finish_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); }
Die Auslöselogik wird einfach sein. Wenn der Aufgabenstatus in der Tabelle der tasks auf „in Bearbeitung“ wechselt, setzen wir das Startdatum (start_date) gleich der aktuellen Zeit. Wenn der Status der Aufgabe auf Erledigt wechselt, setzen wir das Enddatum (finish_date) auf die aktuelle Zeit. Wenn der Status der Aufgabe auf „In Warteschleife“ wechselt, sollten die Zeiten von Start und Ende gelöscht werden. Der letztgenannte Vorgang der Statusänderung wird nicht vom EA aus durchgeführt, sondern durch manuelle Änderung des Wertes des Statusfeldes in der Tabelle der tasks.
Die Umsetzung dieser Auslöser könnte folgendermaßen aussehen:
CREATE TRIGGER IF NOT EXISTS upd_task_start_date AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Processing' BEGIN UPDATE tasks SET start_date= DATETIME('NOW') WHERE id_task=NEW.id_task; END; CREATE TRIGGER IF NOT EXISTS upd_task_finish_date AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Done' BEGIN UPDATE tasks SET finish_date= DATETIME('NOW') WHERE id_task=NEW.id_task; END; CREATE TRIGGER IF NOT EXISTS reset_task_dates AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Queued' BEGIN UPDATE tasks SET start_date= NULL, finish_date=NULL WHERE id_task=NEW.id_task; END;
Nachdem wir solche Trigger erstellt haben, können wir die Änderung von start_date und finish_date aus dem EA entfernen und nur die Statusänderung stehen lassen.
Ein weiterer kleiner, aber ärgerlicher Fehler war, dass bei der manuellen Ausführung eines einzelnen Durchlaufs des Strategietesters nach der Migration zu einer neuen Datenbank der Wert der aktuellen Optimierungsaufgaben-ID standardmäßig auf 0 gesetzt wurde. Der Versuch, einen Eintrag in die Tabelle passes mit einem solchen id_task-Wert einzufügen, kann zu einem Fehler bei der Überprüfung externer Schlüssel führen, wenn wir vergessen haben, eine spezielle Aufgabe mit id_task = 0 hinzuzufügen. Wenn das da ist, ist alles in Ordnung.
Fügen wir also einen Trigger für das Ereignis der Erstellung eines neuen Eintrags in der Projekttabelle hinzu. Sobald wir ein neues Projekt erstellen, benötigen wir eine stage (Stufe), einen Job und eine task (Aufgabe) für einzelne Durchgänge, die automatisch dafür erstellt werden. Die Implementierung dieses Auslösers könnte wie folgt aussehen:
CREATE TRIGGER IF NOT EXISTS insert_empty_stage AFTER INSERT ON projects BEGIN INSERT INTO stages ( id_project, name, optimization, status ) VALUES ( NEW.id_project, 'Single tester pass', 0, 'Done' ); END; DROP TRIGGER IF EXISTS insert_empty_job; CREATE TRIGGER IF NOT EXISTS insert_empty_job AFTER INSERT ON stages WHEN NEW.name = 'Single tester pass' BEGIN INSERT INTO jobs VALUES ( NULL, NEW.id_stage, NULL, NULL, NULL, 'Done' ); INSERT INTO tasks ( id_job, optimization_criterion, status ) VALUES ( (SELECT id_job FROM jobs WHERE id_stage=NEW.id_stage), -1, 'Done' ); END;
Eine weitere Ungenauigkeit bestand darin, dass bei der manuellen Ausführung eines einzelnen Durchlaufs des Strategietesters die Tabelle passes (d. h. das Feld pass_date) die Endzeit des Testintervalls und nicht die aktuelle Zeit erhält. Dies geschieht, weil wir die Funktion TimeCurrent() in der SQL-Abfrage innerhalb des EA verwenden, um den Zeitwert festzulegen. Im Testmodus liefert diese Funktion jedoch nicht die tatsächliche aktuelle Zeit, sondern eine simulierte Zeit. Wenn also unser Prüfintervall Ende 2022 endet, wird der Durchgang in der Tabelle passes gespeichert, wobei die Endzeit mit dem Ende des Jahres 2022 zusammenfällt.
Warum also erhält die Tabelle passes die korrekte aktuelle Endzeit aller während der Optimierung durchgeführten Durchgänge? Die Antwort ist ganz einfach. Der Punkt ist, dass während des Optimierungsprozesses SQL-Abfragen zum Speichern der Ergebnisse der Durchläufe von einer Instanz des EA ausgeführt werden, die nicht im Tester, sondern auf dem Terminal-Chart im Datenrahmen-Sammelmodus gestartet wird. Und da sie im Tester nicht funktioniert, erhält sie die aktuelle (tatsächliche und nicht simulierte) Zeit von der Funktion TimeCurrent().
Um dies zu beheben, fügen wir einen Trigger hinzu, der nach dem Einfügen eines neuen Eintrags in die Tabelle passes ausgelöst wird. Der Auslöser setzt das aktuelle Datum:
CREATE TRIGGER IF NOT EXISTS upd_pass_date
AFTER INSERT
ON passes
BEGIN
UPDATE passes
SET pass_date = DATETIME('NOW')
WHERE id_pass = NEW.id_pass;
END;
In einer SQL-Abfrage, die eine neue Zeile in die Tabelle passes aus dem EA hinzufügt, entfernen wir die Ersetzung der vom EA berechneten aktuellen Zeit und übergeben dort einfach die Konstante NULL.
Verschiedene andere kleinere Ergänzungen und Korrekturen wurden an bestehenden Klassen vorgenommen. In CVirtualOrder habe ich eine Methode zum Ändern der Ablaufzeit und eine statische Methode zum Überprüfen eines Arrays von virtuellen Aufträgen hinzugefügt, um festzustellen, ob einer von ihnen ausgelöst wurde. Diese Methoden werden noch nicht verwendet, können aber für andere Handelsstrategien nützlich sein.
In CFactorable habe ich das Verhalten der Methode ReadNumber() korrigiert, sodass sie NULL zurückgibt, wenn sie das Ende des Initialisierungsstrings erreicht, anstatt die Ausgabe der zuletzt gelesenen Zahl so oft wie nötig zu wiederholen. Diese Änderung erforderte die Angabe von genau so vielen Parametern wie nötig - 13 statt 6 - im Initialisierungsstring des Risikomanagers:
// Prepare the initialization string for the risk manager string riskManagerParams = StringFormat( "class CVirtualRiskManager(\n" " 0,0,0,0,0,0,0,0,0,0,0,0,0" " )", 0 );
In der Datenbankbehandlungsklasse CDatabase haben wir eine neue statische Methode hinzugefügt, mit der wir zur gewünschten Datenbank wechseln können. Im Grunde genommen stellen wir innerhalb der Methode nur eine Verbindung zur Datenbank mit dem gewünschten Namen und Speicherort her und schließen die Verbindung sofort wieder:
static void Test(string p_fileName = NULL, int p_common = DATABASE_OPEN_COMMON) { Connect(p_fileName, p_common); Close(); };
Nach dem Aufruf dieser Methode wird durch weitere Aufrufe der Methode Connect() ohne Parameter eine Verbindung zur gewünschten Datenbank hergestellt.
Nachdem wir mit diesem unwichtigen, aber notwendigen Teil fertig sind, wollen wir uns nun der Umsetzung der Hauptaufgabe widmen.
Neugestaltung von Optimierung.mq5
Zunächst einmal müssen wir Änderungen an dem EA Optimization.mq5 vornehmen. Im EA müssen wir in der Tabelle stages eine Prüfung auf den Namen der zu startenden Datei (expert field) hinzufügen. Wenn der Name auf „.py“ endet, wird in diesem Stadium ein Python-Programm ausgeführt. Wir können die notwendigen Parameter für den Aufruf in das Feld tester_inputs der Tabelle jobs eintragen.
Doch damit ist es noch nicht getan. Wir müssen den Datenbanknamen und die aktuelle Task-ID irgendwie an das Python-Programm übergeben und es irgendwie starten. Dies wird zu einer spürbaren Vergrößerung des EA-Codes führen, und dieser ist bereits recht groß. Beginnen wir also damit, den vorhandenen Programmcode auf mehrere Dateien zu verteilen.
In der Hauptdatei des EAs Optimization.mq5 lassen wir nur die Erstellung des Timers und einer neuen Klasse COptimizer, die die Hauptarbeit leistet. Alles, was wir tun müssen, ist, die Timer-Methode in ihrem Handler Process() aufzurufen und für die korrekte Erstellung/Löschung dieses Objekts während der EA-Initialisierung/Deinitialisierung zu sorgen.
sinput string fileName_ = "database911.sqlite"; // - File with the main database sinput string pythonPath_ = "C:\\Python\\Python312\\python.exe"; // - Path to Python interpreter COptimizer *optimizer; // Pointer to the optimizer object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Connect to the main database DB::Test(fileName_); // Create an optimizer optimizer = new COptimizer(pythonPath_); // Create the timer and start its handler EventSetTimer(20); OnTimer(); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert timer function | //+------------------------------------------------------------------+ void OnTimer() { // Start the optimizer handling optimizer.Process(); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { EventKillTimer(); // Remove the optimizer if(!!optimizer) { delete optimizer; } }
Bei der Erstellung eines Optimizer-Objekts übergeben wir einen einzigen Parameter an seinen Konstruktor - den vollständigen Pfad zur ausführbaren Datei des Python-Interpreters auf dem Computer, auf dem der EA gestartet werden soll. Wir geben den Wert dieses Parameters pythonPath_ in der Eingabe des EAs an. In Zukunft können wir diesen Parameter loswerden, indem wir eine automatische Suche für den Interpreter innerhalb der Optimizer-Klasse implementieren, aber für den Moment beschränken wir uns auf diese einfachere Methode.
Wir speichern die Änderungen an der Datei Optimization.mq5 im aktuellen Ordner.
Die Klasse des Optimierers
Erstellen wir nun die Klasse COptimizer. Von den öffentlichen Methoden wird es nur die Hauptmethode Process() und den Konstruktor geben. Im privaten Abschnitt fügen wir eine Methode hinzu, um die Anzahl der Aufgaben in der Ausführungswarteschlange zu ermitteln und eine Methode, um die ID der nächsten Aufgabe in der Warteschlange zu ermitteln. Wir übertragen die gesamte Arbeit im Zusammenhang mit einer bestimmten Optimierungsaufgabe eine Ebene tiefer - auf das neue Klassenobjekt COptimizerTask (Optimierungsaufgabe). Dann brauchen wir ein Objekt dieser Klasse im Optimierer.
//+------------------------------------------------------------------+ //| Class for the project auto optimization manager | //+------------------------------------------------------------------+ class COptimizer { // Current optimization task COptimizerTask m_task; // Get the number of tasks with a given status in the queue int TotalTasks(string status = "Queued"); // Get the ID of the next optimization task from the queue ulong GetNextTaskId(); public: COptimizer(string p_pythonPath = NULL); // Constructor void Process(); // Main processing method };
Den Code der Methoden TotalTasks() und GetNextTaskId() habe ich fast unverändert aus den entsprechenden Funktionen der Vorgängerversion von Optimization.mq5 übernommen. Dasselbe gilt für die Methode Process(), in die der Code von der Funktion OnTimer() migriert wurde. Sie musste aber noch deutlicher verändert werden, da wir eine neue Klasse für die Optimierungsaufgabe eingeführt haben. Insgesamt ist der Code für diese Methode noch klarer geworden:
//+------------------------------------------------------------------+ //| Main handling method | //+------------------------------------------------------------------+ void COptimizer::Process() { PrintFormat(__FUNCTION__" | Current Task ID = %d", m_task.Id()); // If the EA is stopped, remove the timer and the EA itself from the chart if (IsStopped()) { EventKillTimer(); ExpertRemove(); return; } // If the current task is completed, if (m_task.IsDone()) { // If the current task is not empty, if(m_task.Id()) { // Complete the current task m_task.Finish(); } // Get the number of tasks in the queue int totalTasks = TotalTasks("Processing") + TotalTasks("Queued"); // If there are tasks, then if(totalTasks) { // Get the ID of the next current task ulong taskId = GetNextTaskId(); // Load the optimization task parameters from the database m_task.Load(taskId); // Launch the current task m_task.Start(); // Display the number of remaining tasks and the current task on the chart Comment(StringFormat( "Total tasks in queue: %d\n" "Current Task ID: %d", totalTasks, m_task.Id())); } else { // If there are no tasks, remove the EA from the chart PrintFormat(__FUNCTION__" | Finish.", 0); ExpertRemove(); } } }
Wie Sie sehen können, macht es auf dieser Abstraktionsebene keinen Unterschied, welche Art von Aufgabe das nächste Mal ausgeführt werden muss - die Optimierung eines EA im Tester oder ein Programm in Python. Die Reihenfolge der Aktionen ist dieselbe: Solange sich Aufgaben in der Warteschlange befinden, laden wir die Parameter der nächsten Aufgabe, starten sie zur Ausführung und warten, bis sie abgeschlossen ist. Anschließend wiederholen wir die oben genannten Schritte, bis die Aufgabenwarteschlange leer ist.
Speichern wir die Änderungen an der Datei COptimizer.mqh im aktuellen Ordner.
Klasse der Optimierungsaufgaben
Das Interessanteste haben wir der Klasse COptimizerTask überlassen. In diesem Verzeichnis wird der Python-Interpreter direkt gestartet und das geschriebene Python-Programm wird ihm zur Ausführung übergeben. Also importieren wir am Anfang der Datei mit dieser Klasse die Systemfunktion zum Ausführen von Dateien:
// Function to launch an executable file in the operating system #import "shell32.dll" int ShellExecuteW(int hwnd, string lpOperation, string lpFile, string lpParameters, string lpDirectory, int nShowCmd); #import
In der Klasse selbst werden wir mehrere Felder haben, um die notwendigen Parameter der Optimierungsaufgabe zu speichern, wie Typ, ID, EA, Optimierungsintervall, Symbol, Zeitrahmen und andere.
//+------------------------------------------------------------------+ //| Optimization task class | //+------------------------------------------------------------------+ class COptimizerTask { enum { TASK_TYPE_UNKNOWN, TASK_TYPE_EX5, TASK_TYPE_PY } m_type; // Task type (MQL5 or Python) ulong m_id; // Task ID string m_setting; // String for initializing the EA parameters for the current task string m_pythonPath; // Full path to the Python interpreter // Data structure for reading a single string of a query result struct params { string expert; int optimization; string from_date; string to_date; int forward_mode; string forward_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } m_params; // Get the full or relative path to a given file in the current folder string GetProgramPath(string name, bool rel = true); // Get initialization string from task parameters void Parse(); // Get task type from task parameters void ParseType(); public: // Constructor COptimizerTask() : m_id(0) {} // Task ID ulong Id() { return m_id; } // Set the full path to the Python interpreter void PythonPath(string p_pythonPath) { m_pythonPath = p_pythonPath; } // Main method void Process(); // Load task parameters from the database void Load(ulong p_id); // Start the task void Start(); // Complete the task void Finish(); // Task completed? bool IsDone(); };
Der Teil der Parameter, den wir mit der Methode Load() direkt aus der Datenbank erhalten, ist in der Struktur m_params zu speichern. Anhand dieser Werte bestimmen wir den Aufgabentyp mit der Methode ParseType(), indem wir die Endung des Dateinamens überprüfen:
//+------------------------------------------------------------------+ //| Get task type from task parameters | //+------------------------------------------------------------------+ void COptimizerTask::ParseType() { string ext = StringSubstr(m_params.expert, StringLen(m_params.expert) - 3); if(ext == ".py") { m_type = TASK_TYPE_PY; } else if (ext == "ex5") { m_type = TASK_TYPE_EX5; } else { m_type = TASK_TYPE_UNKNOWN; } }
Wir werden auch eine Zeichenkette für die Initialisierung von Tests oder die Ausführung eines Python-Programms mit der Methode Parse() erzeugen. In diesem String wird ein Parameterstring entweder für den Strategietester oder für die Ausführung eines Python-Programms gebildet, je nach Aufgabentyp:
//+------------------------------------------------------------------+ //| Get initialization string from task parameters | //+------------------------------------------------------------------+ void COptimizerTask::Parse() { // Get the task type from the task parameters ParseType(); // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Generate a parameter string for the tester m_setting = StringFormat( "[Tester]\r\n" "Expert=%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=%d\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=%d\r\n" "ForwardDate=%s\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d\r\n" "fileName_=%s\r\n" "%s\r\n", GetProgramPath(m_params.expert), m_params.symbol, m_params.period, m_params.optimization, m_params.from_date, m_params.to_date, m_params.forward_mode, m_params.forward_date, m_params.optimization_criterion, m_params.id_task, DB::FileName(), m_params.tester_inputs ); // If this is a task to launch a Python program } else if (m_type == TASK_TYPE_PY) { // Form a program launch string on Python with parameters m_setting = StringFormat("\"%s\" \"%s\" %I64u %s", GetProgramPath(m_params.expert, false), // Python program file DB::FileName(true), // Path to the database file m_id, // Task ID m_params.tester_inputs // Launch parameters ); } }
Die Methode Start() ist für das Starten der Aufgabe zuständig. In der Methode wird wiederum der Aufgabentyp betrachtet und je nach diesem entweder die Optimierung im Tester oder das Python-Programm durch Aufruf über ShellExecuteW() ausgeführt:
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void COptimizerTask::Start() { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", m_id, m_setting); // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Launch a new optimization task in the tester MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(m_setting); MTTESTER::ClickStart(); // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing' " " WHERE id_task=%d", m_id); DB::Execute(query); DB::Close(); // If this is a task to launch a Python program } else if (m_type == TASK_TYPE_PY) { PrintFormat(__FUNCTION__" | SHELL EXEC: %s", m_pythonPath); // Call the system function to launch the program with parameters ShellExecuteW(NULL, NULL, m_pythonPath, m_setting, NULL, 1); } }
Um die Ausführung einer Aufgabe zu überprüfen, muss entweder der Status des Strategieprüfers (angehalten oder nicht) oder der Status der Aufgabe in der Datenbank anhand der aktuellen ID überprüft werden:
//+------------------------------------------------------------------+ //| Task completed? | //+------------------------------------------------------------------+ bool COptimizerTask::IsDone() { // If there is no current task, then everything is done if(m_id == 0) { return true; } // Result bool res = false; // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Check if the strategy tester has finished its work res = MTTESTER::IsReady(); // If this is a task to run a Python program, then } else if(m_type == TASK_TYPE_PY) { // Request to get the status of the current task string query = StringFormat("SELECT status " " FROM tasks" " WHERE id_task=%I64u;", m_id); // Open the database if(DB::Connect()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string status; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { // Check if the status is Done res = (row.status == "Done"); } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } } else { res = true; } return res; }
Speichern wir die an der Datei COptimizerTask.mqh vorgenommenen Änderungen im aktuellen Ordner.
Clustering-Programm
Jetzt ist es an der Zeit für das Python-Programm, das ich bereits mehrfach erwähnt habe. Im Allgemeinen wurde der Teil, der die Hauptarbeit leistet, bereits in Teil 6 entwickelt. Schauen wir es uns an:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df = df.sort_values(['cluster', 'Sharpe Ratio']).groupby('cluster').agg('last').reset_index()
clusters = df.cluster
df = df.iloc[:, 1:]
df['cluster'] = clusters
df.to_csv('Params_SV_EURGBP_H1-one_cluster.csv', index=False
Wir müssen das Folgende darin ändern:
- Wir müssen die Möglichkeit, klärende Parameter über Befehlszeilenargumente zu übergeben (Datenbankname, Task-ID, Anzahl der Cluster usw.) hinzufügen,
- die Informationen aus der Tabelle passes anstelle einer CSV-Datei verwenden,
- Start- und Endstatus der Aufgabenausführung in der Datenbank hinzufügen,
- die Zusammensetzung der für das Clustering verwendeten Felder ändern, da wir keine separaten Spalten für jeden EA-Eingabeparameter in der Tabelle passes haben,
- die Anzahl der Felder in der endgültigen Tabelle reduzieren, da wir im Wesentlichen nur die Beziehung zwischen der Clusternummer und der Pass-ID kennen müssen,
- und die Ergebnisse in einer neuen Datenbanktabelle anstatt in einer anderen Datei speichern.
Um all das zu implementieren, müssen wir zusätzliche Module anschließen - argparse und sqlite3:
import pandas as pd
from sklearn.cluster import KMeans
import sqlite3
import argparse
Das Objekt der Klasse ArgumentParser soll die über Kommandozeilenargumente übergebenen Eingaben analysieren. Wir werden die gelesenen Werte in separaten Variablen speichern, um die weitere Verwendung zu erleichtern:
# Setting up the command line argument parser parser = argparse.ArgumentParser(description='Clustering passes for previous job(s)') parser.add_argument('db_path', type=str, help='Path to database file') parser.add_argument('id_task', type=int, help='ID of current task') parser.add_argument('--id_parent_job', type=str, help='ID of parent job(s)') parser.add_argument('--n_clusters', type=int, default=256, help='Number of clusters') parser.add_argument('--min_custom_ontester', type=float, default=0, help='Min value for `custom_ontester`') parser.add_argument('--min_trades', type=float, default=40, help='Min value for `trades`') parser.add_argument('--min_sharpe_ratio', type=float, default=0.7, help='Min value for `sharpe_ratio`') # Read the values of command line arguments into variables args = parser.parse_args() db_path = args.db_path id_task = args.id_task id_parent_job = args.id_parent_job n_clusters = args.n_clusters min_custom_ontester = args.min_custom_ontester min_trades = args.min_trades min_sharpe_ratio = args.min_sharpe_ratio
Als Nächstes stellen wir eine Verbindung zur Datenbank her, markieren die aktuelle Aufgabe als ausgeführt und erstellen (falls nicht vorhanden) eine neue Tabelle zum Speichern der Ergebnisse des Clustering. Wenn diese Aufgabe erneut ausgeführt wird, müssen wir darauf achten, dass zuvor gespeicherte Ergebnisse gelöscht werden:
# Establishing a connection to the database
connection = sqlite3.connect(db_path)
cursor = connection.cursor()
# Mark the start of the task
cursor.execute(f'''UPDATE tasks SET status='Processing' WHERE id_task={id_task};''')
connection.commit()
# Create a table for clustering results if there is none
cursor.execute('''CREATE TABLE IF NOT EXISTS passes_clusters (
id_task INTEGER,
id_pass INTEGER,
cluster INTEGER
);''')
# Clear the results table from previously obtained results
cursor.execute(f'''DELETE FROM passes_clusters WHERE id_task={id_task};''')
Anschließend erstellen wir eine SQL-Abfrage, um Daten zu den erforderlichen Optimierungsdurchläufen zu erhalten, und laden sie aus der Datenbank direkt in den Datenrahmen:
# Load data about parent job passes for this task into the dataframe
query = f'''SELECT p.*
FROM passes p
JOIN
tasks t ON t.id_task = p.id_task
JOIN
jobs j ON j.id_job = t.id_job
WHERE p.profit > 0 AND
j.id_job IN ({id_parent_job}) AND
p.custom_ontester >= {min_custom_ontester} AND
p.trades >= {min_trades} AND
p.sharpe_ratio >= {min_sharpe_ratio};'''
df = pd.read_sql(query, connection)
# Let's look at the dataframe
print(df)
# List of dataframe columns
print(*enumerate(df.columns), sep='\n')
Nachdem wir die Liste der Spalten im Datenrahmen gesehen haben, wählen wir einige davon für das Clustering aus. Da wir keine separaten Spalten für die Eingaben der Handelsstrategie-Instanzen haben, werden wir eine Clusterung nach verschiedenen statistischen Ergebnissen der Durchläufe vornehmen (Gewinn, Anzahl der Transaktionen, Drawdown, Gewinnfaktor usw.). Die Nummern der ausgewählten Spalten werden in den Parametern der Methode iloc[] angegeben. Nach der Clusterung gruppieren wir die Zeilen des Datenrahmens nach jedem Cluster und lassen nur eine Zeile für das Cluster mit dem höchsten Wert des normalisierten durchschnittlichen Jahresgewinns übrig:
# Run clustering on some columns of the dataframe kmeans = KMeans(n_clusters=n_clusters, n_init='auto', random_state=42).fit(df.iloc[:, [7, 8, 9, 24, 29, 30, 31, 32, 33, 36, 45, 46]]) # Add cluster numbers to the dataframe df['cluster'] = kmeans.labels_ # Set the current task ID df['id_task'] = id_task # Sort the dataframe by clusters and normalized profit df = df.sort_values(['cluster', 'custom_ontester']) # Let's look at the dataframe print(df) # Group the lines by cluster and take one line at a time # with the highest normalized profit from each cluster df = df.groupby('cluster').agg('last').reset_index()
Danach verbleiben nur noch drei Spalten in dem Datenrahmen, für den wir die Ergebnistabelle erstellt haben: id_task, id_pass und cluster. Wir haben die erste belassen, damit wir frühere Ergebnisse des Clustering löschen können, wenn wir das Programm erneut mit demselben id_task-Wert ausführen.
# Let's leave only id_task, id_pass and cluster columns in the dataframe df = df.iloc[:, [2, 1, 0]] # Let's look at the dataframe print(df)
Wir speichern den Datenrahmen im Modus des Hinzufügens von Daten zu einer bestehenden Tabelle, markieren den Abschluss der Aufgabe und schließen die Verbindung zur Datenbank:
# Save the dataframe to the passes_clusters table (replacing the existing one)
df.to_sql('passes_clusters', connection, if_exists='append', index=False)
# Mark the task completion
cursor.execute(f'''UPDATE tasks SET status='Done' WHERE id_task={id_task};''')
connection.commit()
# Close the connection
connection.close()
Wir speichern die an der Datei ClusteringStage1.py vorgenommenen Änderungen im aktuellen Ordner.
Der EA der zweiten Stufe
Nun, da wir ein Programm zum Clustern der Ergebnisse der ersten Optimierungsphase haben, müssen wir nur noch eine Unterstützung für die Verwendung der erhaltenen Ergebnisse durch die zweite Optimierungsphase EA implementieren. Wir werden versuchen, dies mit einem minimalen Aufwand zu tun.
Bisher haben wir einen separaten EA verwendet, aber jetzt werden wir es so einrichten, dass die zweite Stufe ohne vorheriges Clustering und mit Clustering unter Verwendung desselben EA durchgeführt werden kann. Fügen wir den logischen Parameter useClusters_ hinzu, der die Frage beantwortet, ob es notwendig ist, die Ergebnisse des Clustering bei der Auswahl von Gruppen aus einzelnen Instanzen von Handelsstrategien, die in der ersten Stufe gewonnen wurden, zu verwenden.
Wenn die Ergebnisse des Clustering verwendet werden müssen, fügen wir der SQL-Abfrage, die die Liste der einzelnen Instanzen der Handelsstrategien erhält, einfach die Tabelle passes_clusters nach den Durchgangs-IDs hinzu. In diesem Fall erhalten wir als Ergebnis der Abfrage nur einen Durchlauf für jeden Cluster.
Auf dem Weg dorthin werden wir einige weitere Parameter als Eingaben des EA hinzufügen, in denen wir zusätzliche Bedingungen für die Auswahl von Pässen durch den normalisierten durchschnittlichen Jahresgewinn, die Anzahl der Transaktionen und die Sharpe Ratio festlegen können.
Dann müssen wir nur noch Änderungen an der Liste der Eingaben und der Funktion CreateTaskDB() vornehmen:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput int idTask_ = 0; // - Optimization task ID sinput string fileName_ = "db.sqlite"; // - Main database file input group "::: Selection for the group" input int idParentJob_ = 1; // - Parent job ID input bool useClusters_ = true; // - Use clustering input double minCustomOntester_ = 0; // - Min normalized profit input int minTrades_ = 40; // - Min number of trades input double minSharpeRatio_ = 0.7; // - Min Sharpe ratio input int count_ = 16; // - Number of strategies in the group (1 .. 16) ... //+------------------------------------------------------------------+ //| Creating a database for a separate stage task | //+------------------------------------------------------------------+ void CreateTaskDB(const string fileName, const int idParentJob) { // Create a new database for the current optimization task DB::Connect(PARAMS_FILE, 0); DB::Execute("DROP TABLE IF EXISTS passes;"); DB::Execute("CREATE TABLE passes (id_pass INTEGER PRIMARY KEY AUTOINCREMENT, params TEXT);"); DB::Close(); // Connect to the main database DB::Connect(fileName); // Clustering string clusterJoin = ""; if(useClusters_) { clusterJoin = "JOIN passes_clusters pc ON pc.id_pass = p.id_pass"; } // Request to obtain the required information from the main database string query = StringFormat("SELECT DISTINCT p.params" " FROM passes p" " JOIN " " tasks t ON p.id_task = t.id_task " " JOIN " " jobs j ON t.id_job = j.id_job " " %s " "WHERE (j.id_job = %d AND " " p.custom_ontester >= %.2f AND " " trades >= %d AND " " p.sharpe_ratio >= %.2f) " "ORDER BY p.custom_ontester DESC;", clusterJoin, idParentJob_, minCustomOntester_, minTrades_, minSharpeRatio_); // Execute the request ... }
Speichern wir die an der Datei SimpleVolumesStage2.mq5 vorgenommenen Änderungen im aktuellen Ordner und starten Sie den Test.
Test
Für unser Projekt legen wir in der Datenbank vier Stufen mit den Namen „First“, „Clustering passes from first stage“, „Second“ und „Second with clustering“ an. Für jede Phase werden wir zwei Jobs für die Symbole EURGBP und GBPUSD auf dem H1-Zeitrahmen erstellen. In der ersten Phase werden wir drei Optimierungsaufgaben mit unterschiedlichen Kriterien (komplex, maximaler Gewinn und nutzerdefiniert) erstellen. Für die übrigen Aufträge wird jeweils eine Aufgabe erstellt. Als Optimierungsintervall nehmen wir den Zeitraum von 2018 bis 2023. Für jeden Auftrag werden wir die richtigen Eingabewerte angeben.
Als Ergebnis sollten wir Informationen in unserer Datenbank haben, die die folgenden Ergebnisse der nachstehenden Abfrage liefern:
SELECT t.id_task,
t.optimization_criterion,
s.name AS stage_name,
s.expert AS stage_expert,
j.id_job,
j.symbol AS job_symbol,
j.period AS job_period,
j.tester_inputs AS job_tester_inputs
FROM tasks t
JOIN
jobs j ON j.id_job = t.id_job
JOIN
stages s ON s.id_stage = j.id_stage
WHERE t.id_task > 0;
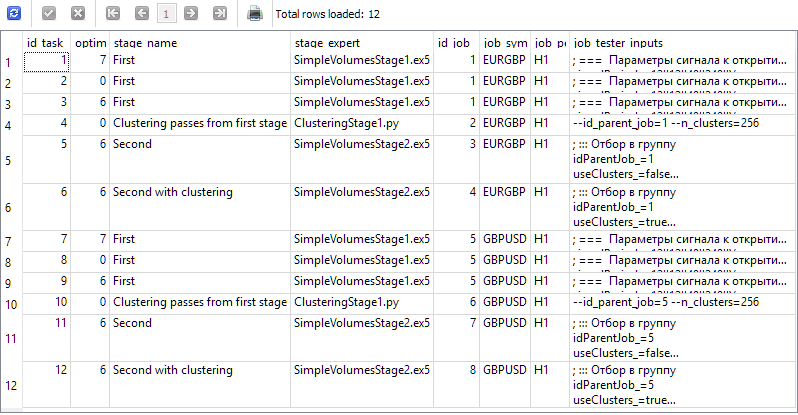
Wir starten Optimization.ex5 auf dem Terminal-Chart und warten Sie, bis alle Aufgaben abgeschlossen sind. Bei dieser Menge an Berechnungen haben 33 Agenten alle Phasen in etwa 17 Stunden abgeschlossen.
Für den EURGBP wies die beste Gruppe, die ohne Clustering gefunden wurde, in etwa die gleiche normalisierte durchschnittliche jährliche Rendite auf wie bei Verwendung von Clustering (etwa 4060 USD). Bei GBPUSD war der Unterschied zwischen diesen beiden Optionen für die Durchführung der zweiten Optimierungsphase jedoch deutlicher zu erkennen. Ohne Clustering lag der Wert des normalisierten durchschnittlichen Jahresgewinns bei 4500 USD, mit Clustering bei 7500 USD.
Dieser Unterschied in den Ergebnissen für zwei verschiedene Symbole erscheint etwas seltsam, ist aber durchaus möglich. Wir werden uns jetzt nicht mit der Suche nach den Gründen für diesen Unterschied befassen, sondern dies auf einen späteren Zeitpunkt verschieben, wenn wir bei der automatischen Optimierung eine größere Anzahl von Symbolen und Zeitrahmen verwenden werden.
So sehen die besten Gruppenergebnisse für beide Symbole aus:
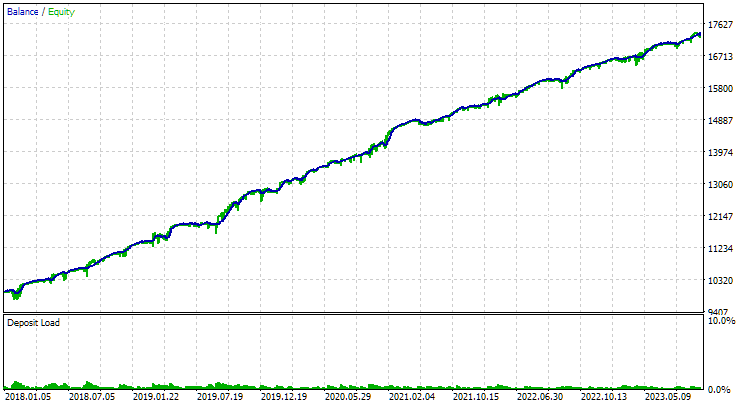
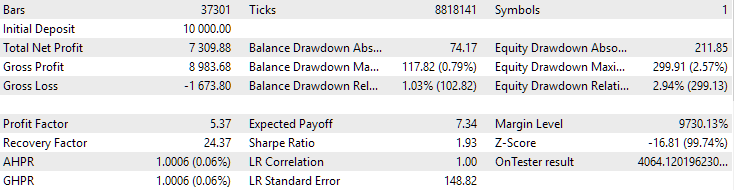
Abb. 1. Ergebnisse der besten Gruppe in der zweiten Stufe mit Clustering für EURGBP H1
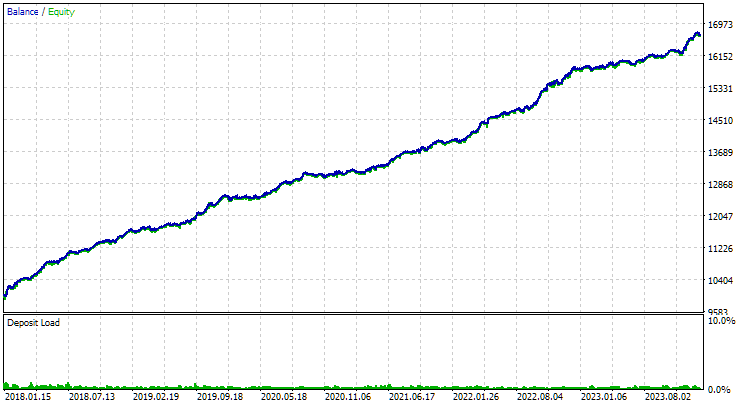
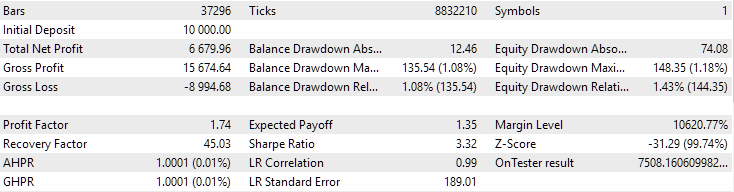
Abb. 2. Ergebnisse der besten Gruppe in der zweiten Stufe mit Clustering für GBPUSD H1
Es gibt noch eine weitere interessante Frage, die ich aufwerfen möchte. Wir führen eine Clusterbildung durch und wählen aus jedem Cluster die beste Einzelinstanz der Handelsstrategie aus (Testergebnis). Auf diese Weise erstellen wir eine Liste mit guten Exemplaren, aus der wir die beste Gruppe auswählen werden. Wenn wir ein Clustering für 256 Cluster durchgeführt haben, dann enthält diese Liste 256 Instanzen. In der zweiten Optimierungsphase wählen wir aus 256 Instanzen 16 aus, die wir zu einer Gruppe zusammenfassen. Ist es möglich, die zweite Stufe zu überspringen und nur 16 einzelne Exemplare der Handelsstrategie aus verschiedenen Clustern mit dem höchsten normalisierten durchschnittlichen Jahresgewinn zu nehmen?
Wenn dies möglich ist, wird der Zeitaufwand für die automatische Optimierung erheblich reduziert. Denn während der Optimierung in der zweiten Phase starten wir einen EA mit 16 Kopien dessen, was in der ersten Phase optimiert wird. Daher nimmt ein Testlauf verhältnismäßig mehr Zeit in Anspruch.
Für die in diesem Artikel betrachteten Optimierungsprobleme konnten wir die Zeit um etwa 6 Stunden reduzieren. Dies ist ein erheblicher Teil der 17 Stunden, die dafür aufgewendet wurden. Und wenn wir berücksichtigen, dass wir zwei Optimierungsaufgaben der zweiten Stufe ohne Clustering hinzugefügt haben, nur um deren Ergebnisse mit den Ergebnissen der zweiten Stufe mit Clustering zu vergleichen, dann ist die relative Zeitersparnis sogar noch deutlicher.
Um diese Frage zu beantworten, sehen wir uns die Ergebnisse einer Abfrage an, die einzelne Instanzen für die zweite Phase auswählt, bevor diese beginnt. Der Übersichtlichkeit halber fügen wir der Spaltenliste den Index, unter dem jede Instanz in der zweiten Stufe genommen wird, die ID des Durchgangs dieser Instanz in der ersten Stufe, die Clusternummer und den Wert des normalisierten durchschnittlichen Jahresgewinns hinzu. Wir erhalten Folgendes:
SELECT DISTINCT ROW_NUMBER() OVER (ORDER BY custom_ontester DESC) AS [index], p.id_pass, pc.cluster, p.custom_ontester, p.params FROM passes p JOIN tasks t ON p.id_task = t.id_task JOIN jobs j ON t.id_job = j.id_job JOIN passes_clusters pc ON pc.id_pass = p.id_pass WHERE (j.id_job = 5 AND p.custom_ontester >= 0 AND trades >= 40 AND p.sharpe_ratio >= 0.7) ORDER BY p.custom_ontester DESC;
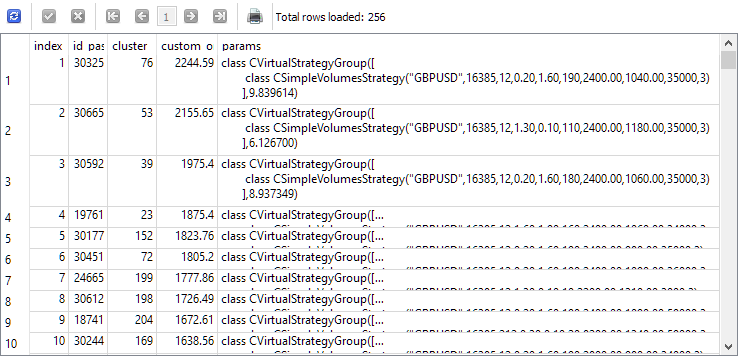
Wie wir sehen können, haben die einzelnen Instanzen mit dem höchsten normalisierten durchschnittlichen Jahresgewinn die kleinsten Indexwerte. Wenn wir also eine Gruppe von Einzelinstanzen mit Indizes von 1 bis 16 nehmen, erhalten wir genau die Gruppe, die wir für den Vergleich mit der besten Gruppe, die wir als Ergebnis der zweiten Optimierungsstufe erhalten haben, zusammenstellen wollten.
Verwenden wir die zweite Stufe von EA, indem wir Zahlen von 1 bis 16 in den Eingabeparametern der Instanzindizes angeben. Wir erhalten das folgende Bild:
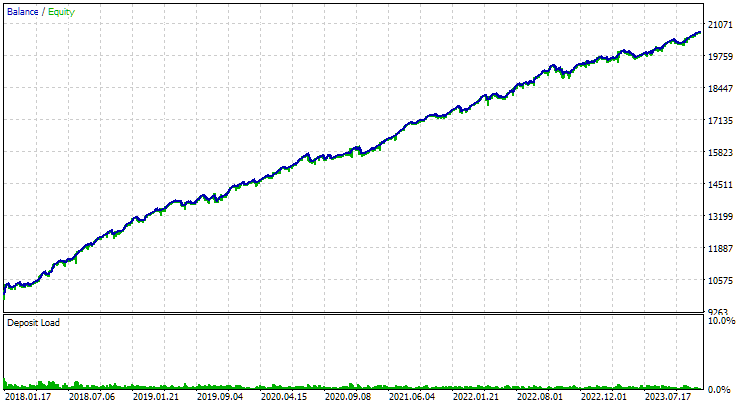
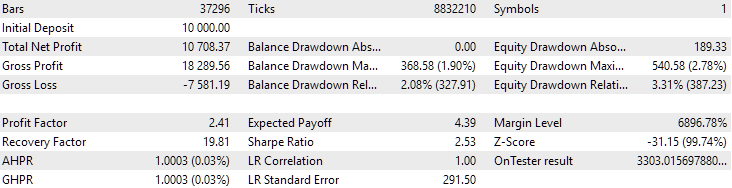
Abb. 3. Ergebnisse der besten 16 Stichproben mit der höchsten normalisierten durchschnittlichen Jahresrendite für GBPUSD H1
Das Diagramm sieht ähnlich aus wie das in Abbildung 2, aber der Wert des normalisierten durchschnittlichen Jahresgewinns ist mehr als doppelt so hoch: 7500 USD gegenüber 3300 USD. Dies ist darauf zurückzuführen, dass der Drawdown bei dieser Gruppe viel größer ist als bei der besten Gruppe in Abbildung 2. Ähnlich verhält es sich beim EURGBP, wenngleich der Rückgang des normalisierten durchschnittlichen Jahresgewinns bei diesem Symbol etwas geringer, aber immer noch signifikant ist.
Es sieht also so aus, als könnten wir auf diese Weise keine Zeit bei der Optimierung der zweiten Stufe sparen.
Betrachten wir abschließend die Ergebnisse der Kombination der beiden besten gefundenen Gruppen:
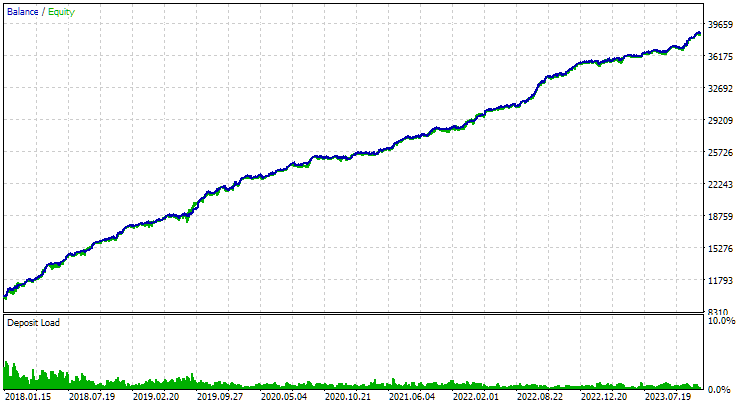
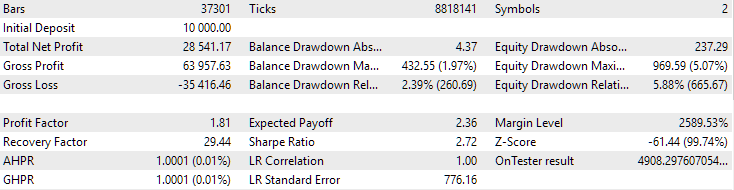
Abb. 4. Ergebnisse der gemeinsamen Arbeit der beiden besten Gruppen für EURGBP H1 und GBPUSD H1
Wie wir sehen können, liegen alle resultierenden Parameter irgendwo zwischen den Parameterwerten der einzelnen Gruppen. So lag der normalisierte durchschnittliche Jahresgewinn bei 4900 USD und damit über dem Wert dieses Parameters für die EURGBP-H1-Gruppe, aber unter dem Wert für die GBPUSD-H1-Gruppe.
Schlussfolgerung
Schauen wir uns also an, was wir haben. Wir haben die Möglichkeit hinzugefügt, automatische Optimierungsschritte zu erstellen, die Anwendungen von Drittanbietern, insbesondere Python-Programme, ausführen können. Falls erforderlich, können wir jetzt mit minimalem Aufwand die Unterstützung für die Ausführung von Programmen in anderen interpretierten Sprachen oder einfach nur von kompilierten Programmen hinzufügen.
Bisher haben wir diese Funktion genutzt, um die Anzahl der einzelnen Instanzen von Handelsstrategien aus der ersten Optimierungsphase zu reduzieren, die an der zweiten Phase teilnehmen. Zu diesem Zweck haben wir alle Instanzen in eine relativ kleine Anzahl von Clustern unterteilt und nur eine Instanz aus jedem Cluster genommen. Durch die Verringerung der Anzahl der Kopien konnte der Zeitaufwand für die zweite Stufe etwas reduziert werden, und die Ergebnisse verschlechterten sich entweder nicht oder wurden deutlich besser. Die Arbeit war also nicht umsonst.
Es gibt jedoch noch Raum für weitere Fortschritte. Die Verbesserung des Clustering-Programms kann in der korrekten Handhabung von Situationen bestehen, in denen die Anzahl der für einzelne Instanzen ausgewählten Cluster geringer ist als die Anzahl der Cluster. Dies führt nun zu einem Fehler. Wir können auch auf die Erweiterung der Palette von Handelsstrategien und die bequeme Organisation von Auto-Optimierungsprojekten setzen. Aber dazu beim nächsten Mal mehr.
Vielen Dank für Ihre Aufmerksamkeit! Bis bald!
Alle in diesem Artikel und in allen vorangegangenen Artikeln dieser Reihe vorgestellten Ergebnisse beruhen lediglich auf historischen Testdaten und sind keine Garantie für zukünftige Gewinne. Die Arbeiten im Rahmen dieses Projekts haben Forschungscharakter. Alle veröffentlichten Ergebnisse können von jedermann auf eigenes Risiko verwendet werden.
Inhalt des Archivs
| # | Name | Version | Beschreibung | Jüngste Änderungen |
|---|---|---|---|---|
| MQL5/Experten/Artikel.15911 | ||||
| 1 | Advisor.mqh | 1.04 | EA-Basisklasse | Teil 10 |
| 2 | ClusteringStage1.py | 1.00. | Programm zum Clustern der Ergebnisse der ersten Optimierungsstufe | Teil 19 |
| 3 | Database.mqh | 1.07 | Klasse für den Umgang mit der Datenbank | Teil 19 |
| 4 | database.sqlite.schema.sql | — | Struktur der Datenbank | Teil 19 |
| 5 | ExpertHistory.mqh | 1.00. | Klasse für den Export der Handelshistorie in eine Datei | Teil 16 |
| 6 | ExportedGroupsLibrary.mqh | — | Generierte Datei mit den Namen der Strategiegruppen und dem Array ihrer Initialisierungszeichenfolgen | Teil 17 |
| 7 | Factorable.mqh | 1.02 | Basisklasse von Objekten, die aus einer Zeichenkette erstellt werden | Teil 19 |
| 8 | GroupsLibrary.mqh | 1.01 | Klasse für die Arbeit mit einer Bibliothek ausgewählter Strategiegruppen | Teil 18 |
| 9 | HistoryReceiverExpert.mq5 | 1.00. | EA für die Wiedergabe der Historie von Geschäften mit dem Risikomanager | Teil 16 |
| 10 | HistoryStrategy.mqh | 1.00. | Klasse der Handelsstrategie für die Wiederholung der Handelshistorie | Teil 16 |
| 11 | Interface.mqh | 1.00. | Basisklasse zur Visualisierung verschiedener Objekte | Teil 4 |
| 12 | LibraryExport.mq5 | 1.01 | EA, der Initialisierungszeichenfolgen ausgewählter Durchläufe aus der Bibliothek in der Datei ExportedGroupsLibrary.mqh speichert | Teil 18 |
| 13 | Macros.mqh | 1.02 | Nützliche Makros für Array-Operationen | Teil 16 |
| 14 | Money.mqh | 1.01 | Grundkurs Geldmanagement | Teil 12 |
| 15 | NewBarEvent.mqh | 1.00. | Klasse zur Definition eines neuen Balkens für ein bestimmtes Symbol | Teil 8 |
| 16 | Optimization.mq5 | 1.03 | EA verwaltet die Einleitung von Optimierungsaufgaben | Teil 19 |
| 17 | Optimizer.mqh | 1.00. | Klasse für den Projektautooptimierungsmanager | Teil 19 |
| 18 | OptimizerTask.mqh | 1.00. | Klasse der Optimierungsaufgaben | Teil 19 |
| 19 | Receiver.mqh | 1.04 | Basisklasse für die Umwandlung von offenen Volumina in Marktpositionen | Teil 12 |
| 20 | SimpleHistoryReceiverExpert.mq5 | 1.00. | Vereinfachter EA für die Wiedergabe des Geschäftsverlaufs | Teil 16 |
| 21 | SimpleVolumesExpert.mq5 | 1.20 | EA für den parallelen Betrieb von mehreren Gruppen von Modellstrategien. Die Parameter werden aus der integrierten Gruppenbibliothek übernommen. | Teil 17 |
| 22 | SimpleVolumesStage1.mq5 | 1.18 | Handelsstrategie Einzelinstanzoptimierung EA (Phase 1) | Teil 19 |
| 23 | SimpleVolumesStage2.mq5 | 1.02 | Handelsstrategien Instanzen Gruppe Optimierung EA (Phase 2) | Teil 19 |
| 24 | SimpleVolumesStage3.mq5 | 1.01 | Der EA, der eine generierte standardisierte Gruppe von Strategien in einer Bibliothek von Gruppen mit einem bestimmten Namen speichert. | Teil 18 |
| 25 | SimpleVolumesStrategy.mqh | 1.09 | Klasse der Handelsstrategie mit Tick-Volumen | Teil 15 |
| 26 | Strategy.mqh | 1.04 | Handelsstrategie-Basisklasse | Teil 10 |
| 27 | TesterHandler.mqh | 1.05 | Klasse zur Behandlung von Optimierungsereignissen | Teil 19 |
| 28 | VirtualAdvisor.mqh | 1.07 | Klasse des EA, der virtuelle Positionen (Aufträge) bearbeitet | Teil 18 |
| 29 | VirtualChartOrder.mqh | 1.01 | Grafische virtuelle Positionsklasse | Teil 18 |
| 30 | VirtualFactory.mqh | 1.04 | Objekt-Fabrik-Klasse | Teil 16 |
| 31 | VirtualHistoryAdvisor.mqh | 1.00. | Die Klasse des EA zur Wiederholung des Handelsverlaufs | Teil 16 |
| 32 | VirtualInterface.mqh | 1.00. | EA GUI-Klasse | Teil 4 |
| 33 | VirtualOrder.mqh | 1.07 | Klasse der virtuellen Aufträge und Positionen | Teil 19 |
| 34 | VirtualReceiver.mqh | 1.03 | Klasse für die Umwandlung von offenen Volumina in Marktpositionen (Empfänger) | Teil 12 |
| 35 | VirtualRiskManager.mqh | 1.02 | Klasse Risikomanagement (Risikomanager) | Teil 15 |
| 36 | VirtualStrategy.mqh | 1.05 | Klasse einer Handelsstrategie mit virtuellen Positionen | Teil 15 |
| 37 | VirtualStrategyGroup.mqh | 1.00. | Klasse der Handelsstrategien Gruppe(n) | Teil 11 |
| 38 | VirtualSymbolReceiver.mqh | 1.00. | Symbol-Empfängerklasse | Teil 3 |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/15911
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
 Von der Grundstufe bis zur Mittelstufe: Union (I)
Von der Grundstufe bis zur Mittelstufe: Union (I)
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Ich führe Folgendes aus
python -u "C:\Benutzer\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1. py.py" "C:\Benutzer\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
und erhalte folgende Fehlermeldung
ValueError: n_samples=150 sollte >= n_clusters=256 sein.
Dann ändere ich n_clusters=150 und führe aus
python -u "C:\Benutzer\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Benutzer\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=150
und ich denke, es hat funktioniert. aber in der Datenbank keine Änderung
Danach habe ich versucht, mit n_samples=150 zu optimieren , aber es hat nicht funktioniert .
Ich führe das
...
und ich denke, es hat funktioniert. aber in der Datenbank gibt es keine Änderung
Es gibt keine neue Tabelle passes_clusters in der Datenbank?
Es gibt keine neue Tabelle passes_clusters in der Datenbank?
Es hat korrekt funktioniert.
Der Fehler stand im Zusammenhang mit der Datenbank.
Nachdem ich die Datenbank korrigiert hatte, funktionierten der Python-Code und Stufe 2 gut.
Ich danke Ihnen für Ihre Hilfe.
Interessanter Artikel! Dann werde ich die ganze Serie lesen.
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
Warum haben sie die Funktionalität der AlgLib-Bibliothek aufgegeben?
#include <Math\Alglib\alglib.mqh>Minus nur bei der Geschwindigkeit, aber hauptsächlich, weil Python die Berechnungen auf allen Kernen parallelisiert.