
Разрабатываем мультивалютный советник (Часть 19): Создаём этапы, реализованные на Python
Введение
Уже довольно давно (в части 6) мы рассматривали автоматизацию подбора хорошей группы из одиночных экземпляров торговых стратегий. Тогда у нас ещё не было базы данных, в которой собирались бы результаты всех проходов тестера. Для этой цели мы использовали обычный CSV-файл. Основной задачей той статьи ставилась проверка гипотезы, что автоматический подбор хорошей группы может давать лучшие результаты, чем ручной подбор.
С поставленной задачей мы справились, и гипотеза подтвердилась. Поэтому далее мы посмотрели, каким образом можно улучшить результаты такого автоматического отбора. Выяснилось, что если мы разобьём множество всех одиночных экземпляров на относительно небольшое число кластеров, и при отборе в группу будем следить, чтобы в неё не попадали экземпляры из одного кластера, то это поможет не только улучшить торговые результаты итогового советника, но и сократить время на сам процесс отбора.
Для проведения кластеризации мы воспользовались готовой библиотекой scikit-learn для Python, а точнее реализацией алгоритма K-Means. Это не единственный алгоритм кластеризации, но рассмотрение других возможных, сравнение и выбор наилучшего, применительно к данной задаче, выходило за допустимые рамки. Поэтому был взят, по сути, первый попавшийся алгоритм, и результаты, полученные с его использованием, оказались достаточно хорошими.
Однако использование именно этой реализации делало необходимым запуск небольшой программы на Python. Когда мы большую часть операций всё равно выполняли вручную, то это не составляло проблемы. Но теперь, когда мы уже сильно продвинулись по пути автоматизации всего процесса тестирования и отбора хороших групп отдельных экземпляров торговых стратегий, наличие даже простой операции, запускаемой вручную посреди конвейера последовательно выполняемых задач оптимизации, выглядит плоховато.
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
После недолгих раздумий, мы склонились ко второму варианту. Давайте приступим к его реализации.
Намечаем путь
Итак, посмотрим, каким образом мы вообще можем запустить программу на Python из программы на MQL5. Наиболее очевидными способами будут следующие:
- Непосредственный запуск. Для этого можно воспользоваться одной из функций операционной системы, позволяющей запустить исполняемый файл с параметрами. Исполняемым файлом будет интерпретатор Python, а параметрами — имя файла с программой и её параметры запуска. Минусом такого подхода можно считать необходимость использования внешних функций из DLL, но мы всё равно уже используем их для запуска тестера стратегий.
- Запуск через web-запрос. Мы можем создать простой веб-сервер с необходимыми API, отвечающим за запуск нужных программ на Python при поступлении запросов из программы на MQL5 через вызов WebRequest(). Для создания веб-сервера можно использовать, например, фреймворк Flask или любой другой. Недостатком такого подхода будет пока что избыточная сложность для решения простой задачи.
Несмотря на всю привлекательность второго способа, отложим его реализацию на более позднее время, когда подойдет пора реализации других сопутствующих вещей. В конечном итоге мы сможем создать даже полноценный веб-интерфейс управления всем процессом автоматической оптимизации, превратив сегодняшний советник Optimization.ex5 в сервис MQL5. Запускаемый вместе с терминалом сервис будет отслеживать появление в базе данных проектов в статусе Queued и, при возникновении таковых, будет выполнять все добавленные в очередь задачи оптимизации для этих проектов. Но пока что реализуем первый, более простой вариант запуска.
Следующим вопросом является выбор способа сохранения результатов кластеризации. В части 6 мы помещали номер кластера как новый столбец в таблице, в которой изначально хранились результаты проходов оптимизации одиночных экземпляров торговой стратегии. Тогда по аналогии мы можем добавить новый столбец в таблицу passes и помещать номера кластеров в него. Но не всякий этап оптимизации подразумевает дальнейшую кластеризацию результатов его проходов. Поэтому для многих строк в таблице passes в этом столбце будут храниться пустые значения. Это не очень хорошо.
Чтобы избежать этого, сделаем отдельную таблицу, в которой будут храниться только идентификаторы проходов и назначенные им номера кластеров. При начале второго этапа оптимизации, для учёта выполненной кластеризации, мы просто присоединим к таблице passes данные из новой таблицы, связав их по идентификаторам проходов (id_pass).
Исходя из требуемой последовательности действий при автоматической оптимизации, этап кластеризации должен выполняться между первым и вторым этапом. Чтобы избежать дальнейшей путаницы, будем по-прежнему использовать названия "первый" и "второй" этап для тех же этапов, которые раньше назывались первым и вторым. Новый, добавляемый этап будем называть этапом кластеризации результатов первого этапа.
Тогда нам понадобится сделать следующее:
- Внести изменения в советник Optimization.mq5, чтобы он мог запускать на выполнение этапы, реализованные на Python.
- Написать код на Python, который будет принимать необходимые параметры, загружать из базы данных информацию о проходах, проводить их кластеризацию и сохранять полученные результаты в базу данных.
- Наполнить базу данных тремя этапами, работами для этих этапов, для разных торговых инструментов и таймфреймов, и задачами оптимизации для этих работ, для одного или нескольких критериев оптимизации.
- Выполнить автоматическую оптимизацию и оценить результаты.
Исправления
На этот раз каких-либо критических ошибок не выявилось, поэтому займемся исправлением неточностей, которые не оказывают непосредственного влияния на итоговый советник, получаемый в результате автоматической оптимизации, но мешают отслеживать правильность выполнения этапов оптимизации и результатов одиночных проходов, запускаемых вне рамок оптимизации.
Начнём с добавления триггеров на установку дат начала и окончания задачи (task). Сейчас их модификацией занимаются SQL-запросы, выполняемые из советника Optimization.mq5 до начала и после остановки процесса оптимизации в тестере стратегий:
//+------------------------------------------------------------------+ //| Запуск задачи | //+------------------------------------------------------------------+ void StartTask(ulong taskId, string setting) { ... // Обновляем статус задачи в базе данных DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing', " " start_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); } //+------------------------------------------------------------------+ //| Завершение задачи | //+------------------------------------------------------------------+ void FinishTask(ulong taskId) { PrintFormat(__FUNCTION__" | Task ID = %d", taskId); // Обновляем статус задачи в базе данных DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Done', " " finish_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); }
Логика триггеров будет проста. Если статус задачи в таблице tasks меняется на "Processing", то дату начала (start_date) надо установить равной текущему времени. Если статус задачи меняется на "Done", то установить равной текущему времени надо дату окончания (finish_date). Если же статус задачи меняется на "Queued", то надо очистить дату начала и окончания. Последняя упомянутая операция изменения статуса выполняется не из советника, а путём ручной модификации значения поля status в таблице tasks.
Вот как может выглядеть реализация данных триггеров:
CREATE TRIGGER IF NOT EXISTS upd_task_start_date AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Processing' BEGIN UPDATE tasks SET start_date= DATETIME('NOW') WHERE id_task=NEW.id_task; END; CREATE TRIGGER IF NOT EXISTS upd_task_finish_date AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Done' BEGIN UPDATE tasks SET finish_date= DATETIME('NOW') WHERE id_task=NEW.id_task; END; CREATE TRIGGER IF NOT EXISTS reset_task_dates AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Queued' BEGIN UPDATE tasks SET start_date= NULL, finish_date=NULL WHERE id_task=NEW.id_task; END;
После создания таких триггеров, мы можем убрать модификацию start_date и finish_date из советника, оставив там только изменение статуса.
Следующая незначительная, но неприятная неточность, состояла в том, что когда мы вручную запускаем одиночный проход тестера стратегий после перехода на новую базу данных, то значение идентификатора текущей задачи оптимизации по умолчанию равно 0. А при попытке вставить запись в таблицу passes c таким значением id_task может приводить к ошибке при проверке внешних ключей, если мы забыли добавить специальную задачу с id_task = 0. Если она есть, то всё в порядке.
Поэтому добавим триггер на событие создания новой записи в таблице проектов. Как только мы создаём новый проект, то надо чтобы для него автоматически создался этап (stage), работа (job) и задача (task) для одиночных проходов. Реализация этого триггера может выглядеть так:
CREATE TRIGGER IF NOT EXISTS insert_empty_stage AFTER INSERT ON projects BEGIN INSERT INTO stages ( id_project, name, optimization, status ) VALUES ( NEW.id_project, 'Single tester pass', 0, 'Done' ); END; DROP TRIGGER IF EXISTS insert_empty_job; CREATE TRIGGER IF NOT EXISTS insert_empty_job AFTER INSERT ON stages WHEN NEW.name = 'Single tester pass' BEGIN INSERT INTO jobs VALUES ( NULL, NEW.id_stage, NULL, NULL, NULL, 'Done' ); INSERT INTO tasks ( id_job, optimization_criterion, status ) VALUES ( (SELECT id_job FROM jobs WHERE id_stage=NEW.id_stage), -1, 'Done' ); END;
Ещё одна неточность состояла в том, что когда мы вручную запускаем одиночный проход тестера стратегий, то в таблицу passes в поле pass_date попадает не текущее время, а время окончания интервала тестирования. Это связано с тем, что для задания значения этого времени, в SQL-запросе внутри советника мы используем функцию TimeCurrent(). Но в режиме тестирования эта функция возвращает не настоящее текущее время, а моделируемое. Поэтому, если интервал тестирования у нас завершается в конце 2022 года, то и в таблице passes это проход будет сохранён с временем окончания, совпадающим с концом 2022 года.
Почему же тогда в таблицу passes пишется правильное текущее время окончания всех проходов, выполняемых в процессе оптимизации? Ответ оказался довольно прост. Дело в том, что в процессе оптимизации SQL-запросы сохранения результатов проходов выполняет экземпляр советника, запущенный не в тестере, а на графике терминала в режиме сбора фреймов данных. А раз он работает не в тестере, то и текущее время получает от функции TimeCurrent() вполне настоящее, а не моделируемое.
Для исправления добавим триггер, запускаемый после вставки новой записи в таблицу passes, который будет устанавливать текущую дату:
CREATE TRIGGER IF NOT EXISTS upd_pass_date
AFTER INSERT
ON passes
BEGIN
UPDATE passes
SET pass_date = DATETIME('NOW')
WHERE id_pass = NEW.id_pass;
END;
В SQL-запросе, добавляющем новую строку в таблицу passes из советника, уберем подстановку текущего времени, вычисляемого советником, и просто передадим там константу NULL.
Ещё несколько мелких добавлений и исправлений были внесены в существующие классы. В CVirtualOrder добавили метод изменения времени истечения и статический метод проверки массива виртуальных ордеров на предмет срабатывания одного из них. Эти методы пока не используются, но могут пригодиться в других торговых стратегиях.
В CFactorable исправлено поведение метода ReadNumber(), чтобы при достижении конца строки инициализации, он возвращал NULL, а не повторял выдачу последнего прочитанного числа сколько угодно раз. Эта правка потребовала указывать в строке инициализации для риск-менеджера ровно столько параметров, сколько там должно быть, то есть 13 вместо 6:
// Подготавливаем строку инициализации для риск-менеджера string riskManagerParams = StringFormat( "class CVirtualRiskManager(\n" " 0,0,0,0,0,0,0,0,0,0,0,0,0" " )", 0 );
В классе работы с базой данных CDatabase мы добавили новый статический метод, с помощью которого будем переключаться на нужную базу данных. По сути, внутри него мы просто подключаемся к базе данных с нужным именем и положением и сразу закрываем соединение:
static void Test(string p_fileName = NULL, int p_common = DATABASE_OPEN_COMMON) { Connect(p_fileName, p_common); Close(); };
После его вызова, дальнейшие вызовы метода Connect() без параметров будут подключаться к нужной базе данных.
Закончив с этой непрофильной, но необходимой частью, приступим к реализации основной задачи.
Рефакторинг Optimization.mq5
Прежде всего нам потребуется вносить изменения в советник Optimization.mq5. В нём необходимо добавить проверку имени запускаемого файла (поле expert) в таблице этапов (stages). Если имя оканчивается на ".py", то в этом этапе будет запускаться программа на Python. Необходимые параметры для её вызова мы можем разместить в поле tester_inputs в таблице работ (jobs).
Однако этим дело не ограничится. Надо как-то передать программе на Python имя базы данных, идентификатор текущей задачи, надо как-то запустить её. Это приведет к заметному разрастанию кода, расположенного в советнике, а он и так уже достаточно большой. Поэтому начнём с того, что распределим уже имеющийся программный код по нескольким файлам.
В основном файле советника Optimization.mq5 мы оставим только создание таймера и нового объекта класса COptimizer (оптимизатор), который будет выполнять всю основную работу. Нам останется только вызывать в обработчике таймера его метод Process() и позаботиться о корректном создании/удалении этого объекта при инициализации/деинициализации советника.
sinput string fileName_ = "database911.sqlite"; // - Файл с основной базой данных sinput string pythonPath_ = "C:\\Python\\Python312\\python.exe"; // - Путь к интерпретатору Python COptimizer *optimizer; // Указатель на объект оптимизатора //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Подключаемся к основной базе данных DB::Test(fileName_); // Создаём оптимизатор optimizer = new COptimizer(pythonPath_); // Создаём таймер и запускаем его обработчик EventSetTimer(20); OnTimer(); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert timer function | //+------------------------------------------------------------------+ void OnTimer() { // Запускаем обработку оптимизатора optimizer.Process(); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { EventKillTimer(); // Удаляем оптимизатор if(!!optimizer) { delete optimizer; } }
При создании объекта оптимизатора мы передаём его конструктору единственный параметр — полный путь к исполняемому файлу интерпретатора Python на компьютере, где будет запускаться этот советник. Значение этого параметра мы указываем во входном параметре советника pythonPath_. В дальнейшем можно избавиться и от этого параметра, реализовав автоматический поиск интерпретатора внутри класса оптимизатора, но пока что ограничимся таким более простым способом.
Сохраним сделанные изменения в файле Optimization.mq5 в текущей папке.
Класс оптимизатора
Создадим класс оптимизатора COptimizer. Из публичных методов в нём будет только основной метод обработки Process() и конструктор. В закрытой секции мы добавим метод получения количества задач в очереди на выполнение и метод получения идентификатора следующей задачи в очереди. А всю работу, связанную с конкретной задачей оптимизации, мы передадим ещё на один уровень ниже — объекту нового класса COptimizerTask (задача оптимизации). Тогда в оптимизаторе нам понадобится один объект этого класса.
//+------------------------------------------------------------------+ //| Класс для менеджера автоматической оптимизации проектов | //+------------------------------------------------------------------+ class COptimizer { // Текущая задача оптимизации COptimizerTask m_task; // Получение количества задач с заданным статусом в очереди int TotalTasks(string status = "Queued"); // Получение идентификатора следующей задачи оптимизации из очереди ulong GetNextTaskId(); public: COptimizer(string p_pythonPath = NULL); // Конструктор void Process(); // Основной метод обработки };
Код методов TotalTasks() и GetNextTaskId() мы практически без изменений взяли из соответствующих функций предыдущей версии советника Optimization.mq5. То же самое можно сказать и про метод Process(), куда перекочевал код из функции OnTimer(). Но его всё-таки пришлось поменять существеннее, так как мы ввели новый класс для задачи оптимизации. В целом же, код этого метода стал ещё нагляднее:
//+------------------------------------------------------------------+ //| Основной метод обработки | //+------------------------------------------------------------------+ void COptimizer::Process() { PrintFormat(__FUNCTION__" | Current Task ID = %d", m_task.Id()); // Если советник остановлен, то удаляем таймер и самого советника с графика if (IsStopped()) { EventKillTimer(); ExpertRemove(); return; } // Если текущая задача выполнена, то if (m_task.IsDone()) { // Если текущая задача не пустая, то if(m_task.Id()) { // Звершаем текущую задачу m_task.Finish(); } // Получаем количество задач в очереди int totalTasks = TotalTasks("Processing") + TotalTasks("Queued"); // Если задачи есть, то if(totalTasks) { // Получаем идентификатор очередной текущей задачи ulong taskId = GetNextTaskId(); // Загружаем параметры задачи оптимизации из базы данных m_task.Load(taskId); // Запускаем текущую задачу m_task.Start(); // Выводим на график количество оставшихся задач и текущую задачу Comment(StringFormat( "Total tasks in queue: %d\n" "Current Task ID: %d", totalTasks, m_task.Id())); } else { // Если задач нет, то удаляем советник с графика PrintFormat(__FUNCTION__" | Finish.", 0); ExpertRemove(); } } }
Как видно, на этом уровне абстракции нет никакой разницы, какого рода задачу надо выполнять в очередной раз — запускать оптимизацию какого-либо советника в тестере или программу на Python. Последовательность действий будет одной и той же: пока есть задачи в очереди, загружаем параметры следующей задачи, запускаем её на выполнение и ждем, пока она не будет выполнена. После выполнения, повторяем вышеперечисленные действия до опустошения очереди задач.
Сохраним сделанные изменения в файле COptimizer.mqh в текущей папке.
Класс задачи оптимизации
Самое интересное у нас осталось для класса COptimizerTask. Именно в нём будет осуществляться непосредственный запуск интерпретатора Python с передачей ему на выполнение написанной программы на Python. Поэтому вначале файла с этим классом мы импортируем системную функцию для запуска файлов:
// Функция запуска исполняемого файла в операционной системе #import "shell32.dll" int ShellExecuteW(int hwnd, string lpOperation, string lpFile, string lpParameters, string lpDirectory, int nShowCmd); #import
В самом классе у нас будет несколько полей для хранения необходимых параметров задачи оптимизации, таких как тип, идентификатор, эксперт, интервал оптимизации, символ, таймфрейм и прочие.
//+------------------------------------------------------------------+ //| Класс для задачи оптимизации | //+------------------------------------------------------------------+ class COptimizerTask { enum { TASK_TYPE_UNKNOWN, TASK_TYPE_EX5, TASK_TYPE_PY } m_type; // Тип задачи (MQL5 или Python) ulong m_id; // Идентификатор задачи string m_setting; // Строка инициализации параметров советника для текущей задачи string m_pythonPath; // Полный путь к интерпретатору Python // Структура данных для чтения одной строки результата запроса struct params { string expert; int optimization; string from_date; string to_date; int forward_mode; string forward_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } m_params; // Получение полного или относительного пути к заданному файлу в текущей папке string GetProgramPath(string name, bool rel = true); // Получение строки инициализации из параметров задачи void Parse(); // Получение типа задачи из параметров задачи void ParseType(); public: // Конструктор COptimizerTask() : m_id(0) {} // Идентификатор задачи ulong Id() { return m_id; } // Установка полного пути к интерпретатору Python void PythonPath(string p_pythonPath) { m_pythonPath = p_pythonPath; } // Основной метод void Process(); // Загрузка параметров задачи из базы данных void Load(ulong p_id); // Запуск задачи void Start(); // Завершение задачи void Finish(); // Задача выполнена? bool IsDone(); };
Ту часть параметров, которую мы будем получать непосредственно из базы данных с помощью метода Load(), будем хранить в структуре m_params. На основании этих значений мы будем определять тип задачи с помощью метода ParseType(), проверяя окончание имени файла:
//+------------------------------------------------------------------+ //| Получение типа задачи из параметров задачи | //+------------------------------------------------------------------+ void COptimizerTask::ParseType() { string ext = StringSubstr(m_params.expert, StringLen(m_params.expert) - 3); if(ext == ".py") { m_type = TASK_TYPE_PY; } else if (ext == "ex5") { m_type = TASK_TYPE_EX5; } else { m_type = TASK_TYPE_UNKNOWN; } }
А также будем формировать строку инициализации тестирования или запуска программы на Python с помощью метода Parse(). В нём, в зависимости от определённого типа задачи, мы будем либо формировать строку параметров для тестера стратегий, либо строку с параметрами для запуска программы на Python:
//+------------------------------------------------------------------+ //| Получение строки инициализации из параметров задачи | //+------------------------------------------------------------------+ void COptimizerTask::Parse() { // Получаем тип задачи из параметров задачи ParseType(); // Если это задача на оптимизацию советника if(m_type == TASK_TYPE_EX5) { // Формируем строку параметров для тестера m_setting = StringFormat( "[Tester]\r\n" "Expert=%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=%d\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=%d\r\n" "ForwardDate=%s\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d\r\n" "fileName_=%s\r\n" "%s\r\n", GetProgramPath(m_params.expert), m_params.symbol, m_params.period, m_params.optimization, m_params.from_date, m_params.to_date, m_params.forward_mode, m_params.forward_date, m_params.optimization_criterion, m_params.id_task, DB::FileName(), m_params.tester_inputs ); // Если это задача на запуск программы на Python } else if (m_type == TASK_TYPE_PY) { // Формируем строку запуска программы на Python с параметрами m_setting = StringFormat("\"%s\" \"%s\" %I64u %s", GetProgramPath(m_params.expert, false), // Файл с программой на Python DB::FileName(true), // Путь к файлу с базой данных m_id, // Идентификатор задачи m_params.tester_inputs // Парамтры запуска ); } }
За запуск задачи отвечает метод Start(). В нём мы снова смотрим на тип задачи и, в зависимости от него, либо запускаем оптимизацию в тестере, либо запускаем программу на Python с помощью вызова системной функции ShellExecuteW():
//+------------------------------------------------------------------+ //| Запуск задачи | //+------------------------------------------------------------------+ void COptimizerTask::Start() { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", m_id, m_setting); // Если это задача на оптимизацию советника if(m_type == TASK_TYPE_EX5) { // Запускаем новую задачу оптимизации в тестере MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(m_setting); MTTESTER::ClickStart(); // Обновляем статус задачи в базе данных DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing' " " WHERE id_task=%d", m_id); DB::Execute(query); DB::Close(); // Если это задача на запуск программы на Python } else if (m_type == TASK_TYPE_PY) { PrintFormat(__FUNCTION__" | SHELL EXEC: %s", m_pythonPath); // Вызываем системную функцию запуска программы с параметрами ShellExecuteW(NULL, NULL, m_pythonPath, m_setting, NULL, 1); } }
Проверка выполнения задачи сводится либо к проверке состояния тестера стратегий (остановлен или нет), либо проверке статуса задачи в базе данных по текущему идентификатору:
//+------------------------------------------------------------------+ //| Задача выполнена? | //+------------------------------------------------------------------+ bool COptimizerTask::IsDone() { // Если нет текущей задачи, то всё выполнено if(m_id == 0) { return true; } // Результат bool res = false; // Если это задача на оптимизацию советника if(m_type == TASK_TYPE_EX5) { // Проверяем, завершил ли работу тестер стратегий res = MTTESTER::IsReady(); // Если это задача на запуск программы на Python, то } else if(m_type == TASK_TYPE_PY) { // Запрос на получение статуса текущей задачи string query = StringFormat("SELECT status " " FROM tasks" " WHERE id_task=%I64u;", m_id); // Открываем базу данных if(DB::Connect()) { // Выполняем запрос int request = DatabasePrepare(DB::Id(), query); // Если нет ошибки if(request != INVALID_HANDLE) { // Структура данных для чтения одной строки результата запроса struct Row { string status; } row; // Читаем данные из первой строки результата if(DatabaseReadBind(request, row)) { // Проверяем, равен ли статус Done res = (row.status == "Done"); } else { // Сообщаем об ошибке при необходимости PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Сообщаем об ошибке при необходимости PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Закрываем базу данных DB::Close(); } } else { res = true; } return res; }
Сохраним сделанные изменения в файле COptimizerTask.mqh в текущей папке.
Программа для кластеризации
Теперь настала очередь той самой программы на Python, про которую мы уже много раз упоминали. В целом, её часть, выполняющая основную работу, уже была написана в части 6. Давайте на неё посмотрим:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df = df.sort_values(['cluster', 'Sharpe Ratio']).groupby('cluster').agg('last').reset_index()
clusters = df.cluster
df = df.iloc[:, 1:]
df['cluster'] = clusters
df.to_csv('Params_SV_EURGBP_H1-one_cluster.csv', index=False Нам необходимо изменить в ней следующее:
- добавить возможность передавать уточняющие параметры через аргументы командной строки (имя базы данных, идентификатор задачи, количество кластеров и т.д.);
- вместо CSV-файла использовать информацию из таблицы passes;
- добавить установку статуса начала и окончания выполнения задачи в базе данных;
- изменить состав полей, используемых для кластеризации, так как в таблице passes у нас нет отдельных столбцов для каждого входного параметра советника;
- сократить количество полей в итоговой таблице, так как нам, по сути, нужно знать только связь номера кластера с идентификатором прохода;
- вместо сохранения результатов в другой файл, сохранять их в новую таблицу базы данных.
Для реализации всего вышеперечисленного нам понадобится подключить дополнительные модули argparse и sqlite3:
import pandas as pd
from sklearn.cluster import KMeans
import sqlite3
import argparse Разбором входных параметров, передаваемых через аргументы командной строки, поручим заниматься объекту класса ArgumentParser и сохраним прочитанные значения в отдельные переменные для удобства дальнейшего использования:
# Настраиваем парсер аргументов командной строки parser = argparse.ArgumentParser(description='Clustering passes for previous job(s)') parser.add_argument('db_path', type=str, help='Path to database file') parser.add_argument('id_task', type=int, help='ID of current task') parser.add_argument('--id_parent_job', type=str, help='ID of parent job(s)') parser.add_argument('--n_clusters', type=int, default=256, help='Number of clusters') parser.add_argument('--min_custom_ontester', type=float, default=0, help='Min value for `custom_ontester`') parser.add_argument('--min_trades', type=float, default=40, help='Min value for `trades`') parser.add_argument('--min_sharpe_ratio', type=float, default=0.7, help='Min value for `sharpe_ratio`') # Читаем значения аргументов командной строки в переменные args = parser.parse_args() db_path = args.db_path id_task = args.id_task id_parent_job = args.id_parent_job n_clusters = args.n_clusters min_custom_ontester = args.min_custom_ontester min_trades = args.min_trades min_sharpe_ratio = args.min_sharpe_ratio
Далее будем подключаться к базе данных, отмечать текущую задачу, как выполняющуюся, и создавать (при отсутствии) новую таблицу для сохранения результатов кластеризации. В том случае, если эта задача запускается повторно, надо позаботиться об очистке ранее сохранённых результатов:
# Устанавливаем соединение с базой данных
connection = sqlite3.connect(db_path)
cursor = connection.cursor()
# Отмечаем старт задачи
cursor.execute(f'''UPDATE tasks SET status='Processing' WHERE id_task={id_task};''')
connection.commit()
# Создаём таблицу для результатов кластеризации при её отсутствии
cursor.execute('''CREATE TABLE IF NOT EXISTS passes_clusters (
id_task INTEGER,
id_pass INTEGER,
cluster INTEGER
);''')
# Очищаем таблицу результатов от ранее полученных результатов
cursor.execute(f'''DELETE FROM passes_clusters WHERE id_task={id_task};''') Затем формируем SQL-запрос на получение данных о нужных проходах оптимизации и загружаем их из базы данных сразу в датафрейм:
# Загружаем в датафрейм данные о проходах родительской работы для данной задачи
query = f'''SELECT p.*
FROM passes p
JOIN
tasks t ON t.id_task = p.id_task
JOIN
jobs j ON j.id_job = t.id_job
WHERE p.profit > 0 AND
j.id_job IN ({id_parent_job}) AND
p.custom_ontester >= {min_custom_ontester} AND
p.trades >= {min_trades} AND
p.sharpe_ratio >= {min_sharpe_ratio};'''
df = pd.read_sql(query, connection)
# Посмотрим на датафрейм
print(df)
# Список столбцов датафрейма
print(*enumerate(df.columns), sep='\n') Увидев список столбцов датафрейма, мы отберём некоторые из них для проведения кластеризации. Так как у нас нет отдельных столбцов для входных параметров экземпляров торговых стратегий, то будем осуществлять кластеризацию по различным статистическим результатам проходов (прибыль, количество сделок, просадка, профит-фактор и др.). Номера выбранных столбцов укажем при параметрах метода iloc[]. После кластеризации, мы проводим группировку строк датафрейма по каждому кластеру и оставляем только одну строку для одного кластера с наибольшим значением нормированной среднегодовой прибыли:
# Запускаем кластеризацию на некоторых столбцах датафрейма kmeans = KMeans(n_clusters=n_clusters, n_init='auto', random_state=42).fit(df.iloc[:, [7, 8, 9, 24, 29, 30, 31, 32, 33, 36, 45, 46]]) # Добавляем номера кластеров к датафрейму df['cluster'] = kmeans.labels_ # Установим идентификатор текущей задачи df['id_task'] = id_task # Сортируем датафрейм по кластерам и нормированной прибыли df = df.sort_values(['cluster', 'custom_ontester']) # Посмотрим на датафрейм print(df) # Группируем строки по кластеру и берём по одной строке # с самой большой нормированной прибылью из каждого кластера df = df.groupby('cluster').agg('last').reset_index()
После этого оставляем в датафрейме только три столбца, под которые мы создали таблицу результатов: id_task, id_pass, cluster. Первый из них мы оставили для того, чтобы можно было очищать предыдущие результаты кластеризации при повторном запуске этой программы с таким же значением id_task.
# Оставим в датафрейме только столбцы id_task, id_pass и cluster df = df.iloc[:, [2, 1, 0]] # Посмотрим на датафрейм print(df)
Сохраняем датафрейм в режиме добавления данных в существующую таблицу, отмечаем завершение выполнения задачи и закрываем соединение с базой данных:
# Сохраняем датафрейм в таблицу passes_clusters (заменяя существующую)
df.to_sql('passes_clusters', connection, if_exists='append', index=False)
# Отмечаем выполнение задачи
cursor.execute(f'''UPDATE tasks SET status='Done' WHERE id_task={id_task};''')
connection.commit()
# Закрываем соединение
connection.close()
Сохраним сделанные изменения в файле ClusteringStage1.py в текущей папке.
Советник второго этапа
После того, как у нас готова программа кластеризации результатов первого этапа оптимизации, остаётся реализовать только поддержку использования полученных результатов со стороны советника второго этапа оптимизации. Постараемся сделать это с минимальными затратами.
Раньше мы использовали отдельный советник, но сейчас мы сделаем так, что проводить второй этап без предварительной кластеризации и с кластеризацией можно будет с помощью одного и того же советника. Добавим входной логический параметр useClusters_, отвечающий на вопрос, надо ли использовать результаты кластеризации при подборе групп из одиночных экземпляров торговых стратегий, полученных на перовом этапе.
Если результаты кластеризации надо использовать, то мы просто добавим в SQL-запрос, получающий список одиночных экземпляров торговых стратегий, объединение с таблицей passes_clusters по идентификаторам проходов. В этом случае, в результате запроса у нас получится только по одному проходу для каждого кластера.
Попутно добавим в качестве входных параметров советника ещё несколько параметров, в которых мы сможем задавать дополнительные условия отбора проходов по нормированной среднегодовой прибыли, количеству сделок и коэффициенту Шарпа.
Тогда нам надо внести изменения только в список входных параметров и функцию CreateTaskDB():
//+------------------------------------------------------------------+ //| Входные параметры | //+------------------------------------------------------------------+ sinput int idTask_ = 0; // - Идентификатор задачи оптимизации sinput string fileName_ = "db.sqlite"; // - Файл с основной базой данных input group "::: Отбор в группу" input int idParentJob_ = 1; // - Идентификатор родительской работы input bool useClusters_ = true; // - Использовать кластеризацию input double minCustomOntester_ = 0; // - Мин. нормированная прибыль input int minTrades_ = 40; // - Мин. количество сделок input double minSharpeRatio_ = 0.7; // - Мин. коэффициент Шарпа input int count_ = 16; // - Количество стратегий в группе (1 .. 16) ... //+------------------------------------------------------------------+ //| Создание базу данных для отдельной задачи этапа | //+------------------------------------------------------------------+ void CreateTaskDB(const string fileName, const int idParentJob) { // Создаём новую базу данных для текущей задачи оптимизации DB::Connect(PARAMS_FILE, 0); DB::Execute("DROP TABLE IF EXISTS passes;"); DB::Execute("CREATE TABLE passes (id_pass INTEGER PRIMARY KEY AUTOINCREMENT, params TEXT);"); DB::Close(); // Подключаемся к основной базе данных DB::Connect(fileName); // Объединение string clusterJoin = ""; if(useClusters_) { clusterJoin = "JOIN passes_clusters pc ON pc.id_pass = p.id_pass"; } // Запрос на получение необходимой информации из основной базы данных string query = StringFormat("SELECT DISTINCT p.params" " FROM passes p" " JOIN " " tasks t ON p.id_task = t.id_task " " JOIN " " jobs j ON t.id_job = j.id_job " " %s " "WHERE (j.id_job = %d AND " " p.custom_ontester >= %.2f AND " " trades >= %d AND " " p.sharpe_ratio >= %.2f) " "ORDER BY p.custom_ontester DESC;", clusterJoin, idParentJob_, minCustomOntester_, minTrades_, minSharpeRatio_); // Выполняем запрос ... }
Сохраним сделанные изменения в файле SimpleVolumesStage2.mq5 в текущей папке и приступим к тестированию.
Тестирование
Создадим в базе данных для нашего проекта четыре этапа с названиями "First", "Clustering passes from first stage", "Second" и "Second with clustering". Для каждого этапа создадим по две работы для символов EURGBP и GBPUSD на таймфрейме H1. Для работ первого этапа создадим по три задачи оптимизации с разными критериями (комплексный, максимальная прибыль и пользовательский). Для остальных работ создадим по одной задаче. В качестве интервала оптимизации возьмём период с 2018 по 2023 год. Для каждой работы укажем корректные значения входных параметров.
В итоге у нас в базе данных должна появиться информация, которая порождает такие результаты приведённого ниже запроса:
SELECT t.id_task,
t.optimization_criterion,
s.name AS stage_name,
s.expert AS stage_expert,
j.id_job,
j.symbol AS job_symbol,
j.period AS job_period,
j.tester_inputs AS job_tester_inputs
FROM tasks t
JOIN
jobs j ON j.id_job = t.id_job
JOIN
stages s ON s.id_stage = j.id_stage
WHERE t.id_task > 0; 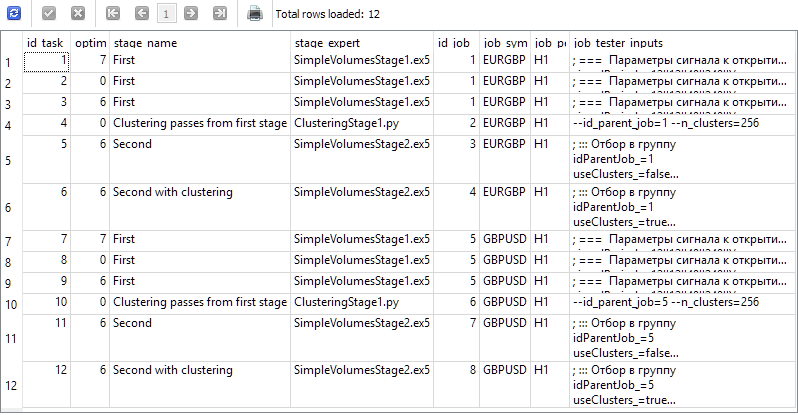
Запустим советник Optimization.ex5 на графике терминала и подождём окончания выполнения всех задач. Для такого объема вычислений 33 агента справились со всеми этапами примерно за 17 часов.
Для EURGBP лучшая группа, найденная без кластеризации, имела примерно такую же нормированную среднегодовую прибыль, как и в случае использования кластеризации (примерно $4060). Но для GBPUSD разница между этими двумя вариантами проведения второго этапа оптимизации оказалась более заметна. Без кластеризации было получено значение нормированной среднегодовой прибыли $4500, а с кластеризацией — $7500.
Такое различие в результатах для двух разных символов представляется несколько странным, но вполне возможным. Не будем сейчас углубляться в поиск причин подобного различия, а оставим его на более позднее время, когда будем использовать при автоматической оптимизации большее количество символов и таймфреймов.
Вот как выглядят результаты наилучших групп для обоих символов:
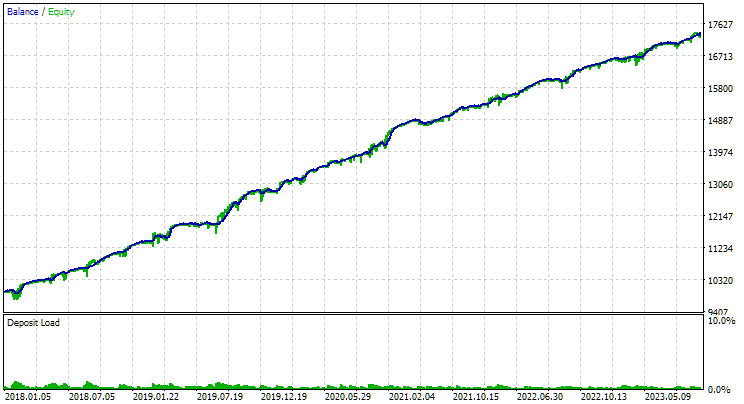
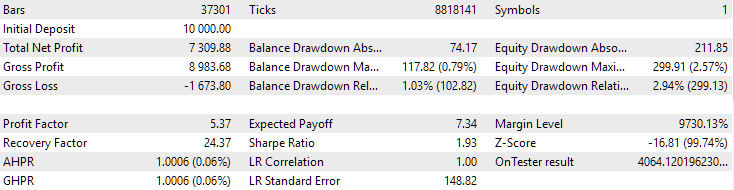
Рис. 1. Результаты лучшей группы на втором этапе с кластеризацией для EURGBP H1
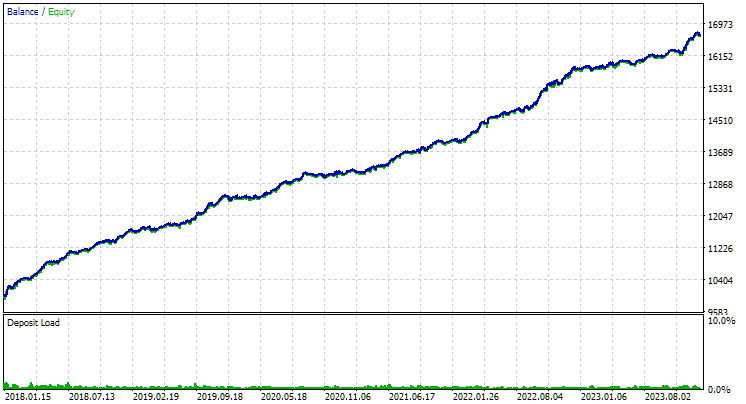
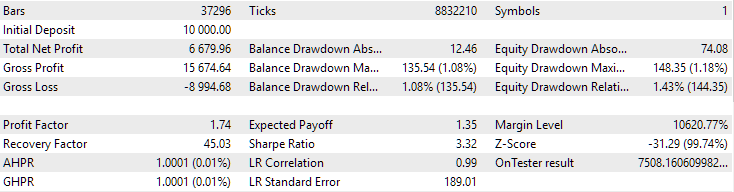
Рис. 2. Результаты лучшей группы на втором этапе с кластеризацией для GBPUSD H1
Еще один интересный вопрос, который хотелось бы затронуть, состоит в следующем. Мы проводим кластеризацию и из каждого кластера берём один самый лучший одиночный экземпляр торговой стратегии (проход тестера). Таким образом мы формируем список хороших экземпляров, из которых будем выбирать наилучшую группу. Если мы делали кластеризацию на 256 кластеров, то в этот список у нас войдёт 256 экземпляров. На втором этапе оптимизации мы будем выбирать какие-то 16 экземпляров из 256 для объединения в одну группу. Можно ли не проводить второй этап, а просто взять 16 одиночных экземпляров торговой стратегии из разных кластеров с самой большой нормированной среднегодовой прибылью?
Если так сделать можно, то это позволит существенно сократить время, затрачиваемое на автоматическую оптимизацию. Ведь при оптимизации на втором этапе у нас запускается советник с 16 экземплярами того, что оптимизируется на первом этапе. Поэтому и один проход тестера занимает пропорционально больше времени.
Для рассматриваемого в данной статье состава задач оптимизации мы могли бы сократить время примерно на 6 часов. Это существенная доля от 17 потраченных часов. А если учесть, что мы добавили две задачи оптимизации второго этапа без кластеризации только для того, чтобы сравнить их результаты с результатами второго этапа с кластеризацией, то относительное сокращение времени будет ещё более значительным.
Чтобы ответить на этот вопрос, посмотрим на результаты запроса, который выбирает перед вторым этапом одиночные экземпляры для второго этапа. Для наглядности мы добавим в список столбцов индекс, под которым каждый экземпляр будет браться во втором этапе, идентификатор прохода данного экземпляра на первом этапе, номер кластера и значение нормированной среднегодовой прибыли. Получим следующее:
SELECT DISTINCT ROW_NUMBER() OVER (ORDER BY custom_ontester DESC) AS [index], p.id_pass, pc.cluster, p.custom_ontester, p.params FROM passes p JOIN tasks t ON p.id_task = t.id_task JOIN jobs j ON t.id_job = j.id_job JOIN passes_clusters pc ON pc.id_pass = p.id_pass WHERE (j.id_job = 5 AND p.custom_ontester >= 0 AND trades >= 40 AND p.sharpe_ratio >= 0.7) ORDER BY p.custom_ontester DESC;
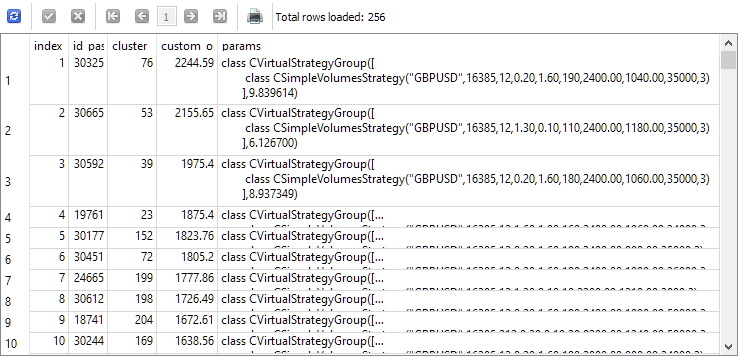
Как видим, одиночные экземпляры с самой большой нормированной среднегодовой прибылью имеют самые маленькие значения индекса. Поэтому, если мы возьмем группу одиночных экземпляров с индексами от 1 до 16, то получим как раз такую группу, которую мы хотели собрать для сравнения с наилучшей группой, полученной в результате второго этапа оптимизации.
Воспользуемся советником второго этапа, задав ему во входных параметрах индексов экземпляров числа от 1 до 16. Получим следующую картину:
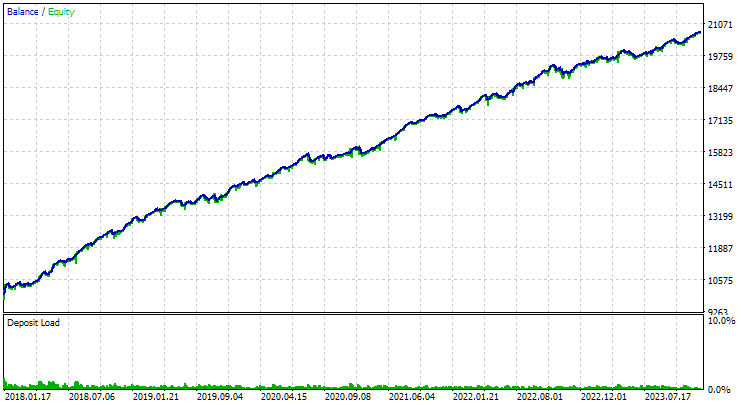

Рис. 3. Результаты группы из первых 16 экземпляров с наибольшей нормированной среднегодовой прибылью для GBPUSD H1
По характеру график выглядит похожим на график на рисунке 2, но значение нормированной среднегодовой прибыли стало более чем в два раза меньше: $3300 против $7500. Это вызвано гораздо большей просадкой, которая наблюдалась для этой группы, по сравнению с просадкой наилучшей группы на рисунке 2. Аналогичная ситуация наблюдается и для EURGBP, правда для этого символа уменьшение нормированной среднегодовой прибыли оказалось несколько меньшим, но всё равно значительным.
Так что похоже, сэкономить таким образом на времени оптимизации второго этапа нам не удастся.
Напоследок посмотрим на результаты объединения двух найденных наилучших групп:
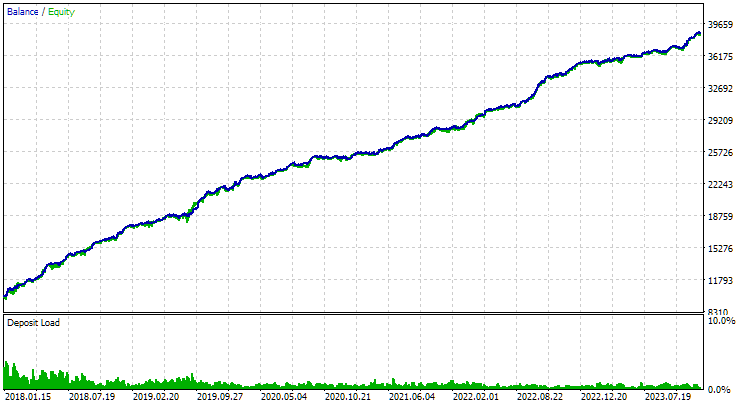
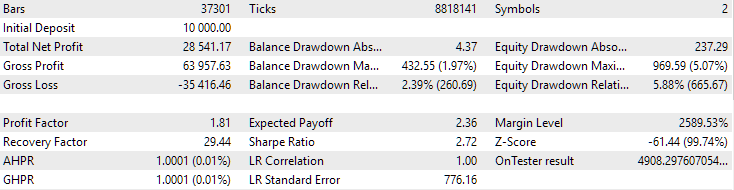
Рис. 4. Результаты совместной работы двух наилучших групп для EURGBP H1 и GBPUSD H1
Как видно, все параметры получились где-то между значениями параметров для отдельных групп. Например, нормированная среднегодовая прибыль составила $4900, что больше значения этого параметра для группы EURGBP H1, но меньше, чем для группы GBPUSD H1.
Заключение
Итак, давайте посмотрим на то, что у нас получилось. Мы добавили возможность создавать этапы автоматической оптимизации, которые могут выполнять запуск сторонних приложений, а именно — программ на Python. Однако, при необходимости, мы можем теперь с минимальными усилиями добавить поддержку запуска программ на других интерпретируемых языках, или просто каких-либо скомпилированных программ.
Пока что данную возможность мы использовали для сокращения количества одиночных экземпляров торговых стратегий из первого этапа оптимизации, принимающих участие во втором этапе. Для этого мы разбивали все экземпляры на относительно небольшое число кластеров и брали только по одному экземпляру из каждого кластера. Уменьшение количества экземпляров несколько сократило время на проведение второго этапа, а результаты либо не ухудшились, либо стали значительно лучше. Так что работа была проделана не зря.
Однако, есть еще куда двигаться дальше. Доработка программы кластеризации может состоять в корректной обработке ситуаций, когда отобранных для одиночных экземпляров окажется меньше количества кластеров. Сейчас это приведёт к ошибке. Также можно уже посмотреть и в сторону расширения набора торговых стратегий и удобной организации проектов автоматической оптимизации. Но об этом уже в следующий раз.
Спасибо за внимание, до встречи!
Все результаты, изложенные в этой статье и всех предшествующих статьях цикла, основываются только на данных тестирования на истории и не являются гарантией получения хоть какой-то прибыли в будущем. Работа в рамках данного проекта носит исследовательский характер. Все опубликованные результаты могут быть использованы всеми желающими на свой страх и риск.
Содержание архива
| # | Имя | Версия | Описание | Последние изменения |
|---|---|---|---|---|
| MQL5/Experts/Article.15911 | ||||
| 1 | Advisor.mqh | 1.04 | Базовый класс эксперта | Часть 10 |
| 2 | ClusteringStage1.py | 1.00 | Программа кластеризации результатов первого этапа оптимизации | Часть 19 |
| 3 | Database.mqh | 1.07 | Класс для работы с базой данных | Часть 19 |
| 4 | database.sqlite.schema.sql | — | Схема базы данных | Часть 19 |
| 5 | ExpertHistory.mqh | 1.00 | Класс для экспорта истории сделок в файл | Часть 16 |
| 6 | ExportedGroupsLibrary.mqh | — | Генерируемый файл с перечислением имён групп стратегий и массивом их строк инициализации | Часть 17 |
| 7 | Factorable.mqh | 1.02 | Базовый класс объектов, создаваемых из строки | Часть 19 |
| 8 | GroupsLibrary.mqh | 1.01 | Класс для работы с библиотекой отобранных групп стратегий | Часть 18 |
| 9 | HistoryReceiverExpert.mq5 | 1.00 | Советник воспроизведения истории сделок с риск-менеджером | Часть 16 |
| 10 | HistoryStrategy.mqh | 1.00 | Класс торговой стратегии воспроизведения истории сделок | Часть 16 |
| 11 | Interface.mqh | 1.00 | Базовый класс визуализации различных объектов | Часть 4 |
| 12 | LibraryExport.mq5 | 1.01 | Советник, сохраняющий строки инициализации выбранных проходов из библиотеки в файл ExportedGroupsLibrary.mqh | Часть 18 |
| 13 | Macros.mqh | 1.02 | Полезные макросы для операций с массивами | Часть 16 |
| 14 | Money.mqh | 1.01 | Базовый класс управления капиталом | Часть 12 |
| 15 | NewBarEvent.mqh | 1.00 | Класс определения нового бара для конкретного символа | Часть 8 |
| 16 | Optimization.mq5 | 1.03 | Советник, управляющей запуском задач оптимизации | Часть 19 |
| 17 | Optimizer.mqh | 1.00 | Класс для менеджера автоматической оптимизации проектов | Часть 19 |
| 18 | OptimizerTask.mqh | 1.00 | Класс для задачи оптимизации | Часть 19 |
| 19 | Receiver.mqh | 1.04 | Базовый класс перевода открытых объемов в рыночные позиции | Часть 12 |
| 20 | SimpleHistoryReceiverExpert.mq5 | 1.00 | Упрощённый советник воспроизведения истории сделок | Часть 16 |
| 21 | SimpleVolumesExpert.mq5 | 1.20 | Советник для параллельной работы нескольких групп модельных стратегий. Параметры будут браться из встроенной библиотеки групп. | Часть 17 |
| 22 | SimpleVolumesStage1.mq5 | 1.18 | Советник оптимизации одиночного экземпляра торговой стратегии (Этап 1) | Часть 19 |
| 23 | SimpleVolumesStage2.mq5 | 1.02 | Советник оптимизации группы экземпляров торговых стратегий (Этап 2) | Часть 19 |
| 24 | SimpleVolumesStage3.mq5 | 1.01 | Советник, сохраняющий сформированную нормированную группу стратегий в библиотеку групп с заданным именем. | Часть 18 |
| 25 | SimpleVolumesStrategy.mqh | 1.09 | Класс торговой стратегии с использованием тиковых объемов | Часть 15 |
| 26 | Strategy.mqh | 1.04 | Базовый класс торговой стратегии | Часть 10 |
| 27 | TesterHandler.mqh | 1.05 | Класс для обработки событий оптимизации | Часть 19 |
| 28 | VirtualAdvisor.mqh | 1.07 | Класс эксперта, работающего с виртуальными позициями (ордерами) | Часть 18 |
| 29 | VirtualChartOrder.mqh | 1.01 | Класс графической виртуальной позиции | Часть 18 |
| 30 | VirtualFactory.mqh | 1.04 | Класс фабрики объектов | Часть 16 |
| 31 | VirtualHistoryAdvisor.mqh | 1.00 | Класс эксперта воспроизведения истории сделок | Часть 16 |
| 32 | VirtualInterface.mqh | 1.00 | Класс графического интерфейса советника | Часть 4 |
| 33 | VirtualOrder.mqh | 1.07 | Класс виртуальных ордеров и позиций | Часть 19 |
| 34 | VirtualReceiver.mqh | 1.03 | Класс перевода открытых объемов в рыночные позиции (получатель) | Часть 12 |
| 35 | VirtualRiskManager.mqh | 1.02 | Класс управления риском (риск-менеждер) | Часть 15 |
| 36 | VirtualStrategy.mqh | 1.05 | Класс торговой стратегии с виртуальными позициями | Часть 15 |
| 37 | VirtualStrategyGroup.mqh | 1.00 | Класс группы торговых стратегий или групп торговых стратегий | Часть 11 |
| 38 | VirtualSymbolReceiver.mqh | 1.00 | Класс символьного получателя | Часть 3 |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
I run this
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
and get this error
ValueError: n_samples=150 should be >= n_clusters=256.
then i change n_clusters=150 and run
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=150
and i think worked. but in database not any change
after that i try optimize with n_samples=150 but dont worked
I run this
...
and i think worked. but in database not any change
There is no new table passes_clusters in database?
There is no new table passes_clusters in database?
It worked correctly.
The error was related to the database.
After correcting the database, Python code and Stage 2 worked well.
Thank you for your help.
Интересная статья! Почитаю всю серию, потом.
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
Почему отказались от функционала библиотеки AlgLib?
#include <Math\Alglib\alglib.mqh>Минус только в скорости, но в основном от того, что питон распараллеливает на все ядра вычисления.