
Desarrollamos un Asesor Experto multidivisas (Parte 20): Ordenando la cadena de etapas de optimización automática de proyectos (I)
Introducción
En esta serie de artículos, intentamos crear un sistema de optimización automática que permita encontrar buenas combinaciones de parámetros de una estrategia comercial sin intervención humana. Estas combinaciones luego se combinarán en un EA final. El objetivo se detalla con mayor precisión en la parte 9 y la parte 11. El proceso de dicha búsqueda estará controlado por un EA (EA optimizador), y todos los datos que deban guardarse durante su funcionamiento se almacenarán en la base de datos principal.
En la base de datos, tenemos tablas para almacenar información sobre varias clases de objetos. Algunas tienen un campo de estado que puede tomar valores de un conjunto fijo de valores («Queued» (En cola), «Process» (Proceso), «Done» (Listo)), pero no todas las clases utilizan este campo. Más concretamente, por ahora solo se utiliza para tareas de optimización (task). Nuestro EA optimizador busca en la tabla de tareas (tasks) las tareas en cola para seleccionar la siguiente tarea que se va a ejecutar. Una vez completada cada tarea, su estado en la base de datos cambia a «Completed».
Intentemos implementar actualizaciones automáticas de estado no solo para las tareas, sino también para todas las demás clases de objetos (trabajos, etapas, proyectos) y organicemos la ejecución automática de todas las etapas necesarias hasta obtener el EA final, que puede funcionar de forma independiente sin conectarse a la base de datos.
Trazando el camino
En primer lugar, analizaremos detenidamente todas las clases de objetos de la base de datos que tienen un estado y formularemos reglas claras para cambiar dicho estado. Si esto se puede hacer, entonces podemos implementar estas reglas como llamadas a consultas SQL adicionales, ya sea desde el EA optimizador o desde los EA de etapa. O bien, podría ser posible implementarlos como desencadenantes en la base de datos que se activan cuando se producen determinados eventos de cambio de datos.
A continuación, debemos acordar un método para determinar el orden en que se completan las tareas. Antes esto no era un gran problema, ya que durante el desarrollo entrenábamos cada vez en una nueva base de datos y agregábamos etapas del proyecto, trabajos y tareas exactamente en el orden en el que debían completarse. Pero al pasar a almacenar información sobre múltiples proyectos en la base de datos, o incluso agregar automáticamente nuevos proyectos, ya no será posible confiar en este método para determinar el orden de prioridad de las tareas. Así que dediquemos algún tiempo a esta cuestión.
Para probar el funcionamiento de todo el transportador, donde se ejecutarán por turnos todas las tareas del proyecto de optimización automática, necesitamos automatizar algunas acciones más. Antes de esto, los realizábamos manualmente. Por ejemplo, después de completar la segunda etapa de optimización, tenemos la oportunidad de seleccionar los mejores grupos para usar en el EA final. Realizamos esta operación ejecutando la tercera etapa del EA manualmente, es decir, fuera del transportador de optimización automática. Para establecer los parámetros de lanzamiento de este EA, también seleccionamos manualmente los ID de los pases de la segunda etapa con los mejores resultados utilizando una interfaz de acceso a base de datos de terceros en relación con MQL5. Intentaremos hacer algo al respecto también.
Entonces, después de los cambios realizados, esperamos finalmente hacer un transportador completamente terminado para realizar etapas de optimización automática para obtener el EA final. A lo largo del camino, consideraremos algunas otras cuestiones relacionadas con el aumento de la eficiencia del trabajo. Por ejemplo, parece que la segunda etapa y las subsiguientes de los EA serán las mismas para diferentes estrategias comerciales. Veamos si esto es cierto. También veremos qué es más conveniente: crear diferentes proyectos más pequeños o crear un mayor número de etapas u obras en un proyecto más grande.
Reglas para cambiar de estado
Comencemos por formular las reglas para cambiar de estado. Como recordarás, nuestra base de datos contiene información sobre los siguientes objetos que tienen un campo de estado (status):
- Project. Combina una o más etapas almacenadas en la tabla projects;
- Stage. Combina uno o más trabajos, almacenados en la tabla stages.
- Job. Combina una o más tareas, almacenadas en la tabla jobs.
- Task. Normalmente combina varias pasadas de prueba, almacenadas en la tabla tasks.
Los valores de estado posibles son los mismos para cada una de estas cuatro clases de objetos y pueden ser uno de los siguientes:
- Queued. El objeto ha sido puesto en cola para su procesamiento;
- Process. El objeto está siendo procesado;
- Done. El manejo de objetos se ha completado o no se ha iniciado.
Describamos las reglas para cambiar los estados de los objetos en la base de datos de acuerdo con el ciclo normal del transportador de optimización automática del proyecto. El ciclo comienza cuando un proyecto se pone en cola para su optimización, es decir, se le asigna el estado "En cola" (Queued).
Cuando el estado de un proyecto cambia a Queued:
- Establecer el estado de todas las etapas de este proyecto como Queued.
Cuando el estado de una etapa cambia a Queued:
- Establecer el estado de todos los trabajos en esta etapa como Queued.
Cuando el estado del trabajo cambia a Queued:
- Establecer el estado de todas las tareas de este trabajo como Queued.
Cuando el estado de la tarea cambia a Queued:
- Borrar las fechas de inicio y finalización.
De esta forma, cambiar el estado del proyecto a Queued provocará una actualización en cascada de los estados de todas las etapas, trabajos y tareas de este proyecto a Queued. Todos estos objetos permanecerán en este estado hasta que se inicie el EA Optimization.ex5.
Después del lanzamiento, debe encontrarse al menos una tarea en estado Queued. Más adelante, consideraremos el orden de clasificación con múltiples tareas. El estado de la tarea cambia a Process. Esto provoca las siguientes acciones:
Cuando el estado de la tarea cambia a Process:
- Establecer la fecha de inicio igual a la hora actual;
- Eliminar todos los pases realizados anteriormente dentro del marco de la tarea.
- Establezca el estado del trabajo asociado a esta tarea en Process.
Cuando el estado del trabajo cambia a Process:
- Establece el estado de la etapa asociada a este trabajo en Process.
Cuando el estado de una etapa cambia a Process:
- Establecer el estado del proyecto, asociado a esta etapa, en Process.
Posteriormente se irán ejecutando tareas de forma secuencial en el marco de las etapas del proyecto. Los cambios de estado adicionales sólo podrán ocurrir después de completar la siguiente tarea. En este punto, el estado de la tarea cambia a Done y puede provocar que este estado se extienda a objetos de nivel superior.
Cuando el estado de la tarea cambia a Done:
- Establecer la fecha de finalización igual a la hora actual;
- Obtenemos una lista de todas las tareas en cola que forman parte del trabajo, dentro del cual se realiza esta tarea. Si no hay ninguno, establecemos el estado del trabajo asociado con esta tarea en Done.
Cuando el estado del trabajo cambia a Done:
- Obtener una lista de todos los trabajos en cola que forman parte de la etapa en la que se está realizando este trabajo. Si no hay ninguno, entonces establecemos el estado de la etapa asociada a este trabajo como Done.
Cuando el estado de una etapa cambia a Done:
- Obtenemos una lista de todas las etapas en cola incluidas en el proyecto, dentro del cual se está llevando a cabo esta etapa. Si no hay ninguno, entonces establecemos el estado del proyecto asociado a esta etapa como Done.
Por lo tanto, cuando se complete la última tarea del último trabajo de la última etapa, el proyecto pasará al estado completado.
Ahora que todas las reglas están formuladas, podemos pasar a crear desencadenantes en la base de datos que implementen estas acciones.
Creación de desencadenantes
Comencemos con el desencadenante para gestionar el cambio del estado del proyecto a Queued. Aquí hay una forma posible de implementarlo:
CREATE TRIGGER upd_project_status_queued AFTER UPDATE OF status ON projects WHEN NEW.status = 'Queued' BEGIN UPDATE stages SET status = 'Queued' WHERE id_project = NEW.id_project; END;
Una vez completado, el estado de las etapas del proyecto también cambiará a Queued. Por lo tanto, debemos activar los desencadenantes correspondientes para las etapas, los trabajos y las tareas:
CREATE TRIGGER upd_stage_status_queued
AFTER UPDATE
ON stages
WHEN NEW.status = 'Queued' AND
OLD.status <> NEW.status
BEGIN
UPDATE jobs
SET status = 'Queued'
WHERE id_stage = NEW.id_stage;
END;
CREATE TRIGGER upd_job_status_queued
AFTER UPDATE OF status
ON jobs
WHEN NEW.status = 'Queued'
BEGIN
UPDATE tasks
SET status = 'Queued'
WHERE id_job = NEW.id_job;
END;
CREATE TRIGGER upd_task_status_queued
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Queued'
BEGIN
UPDATE tasks
SET start_date = NULL,
finish_date = NULL
WHERE id_task = NEW.id_task;
END;
El inicio de la tarea se gestionará mediante el siguiente desencadenador, que establece la fecha de inicio de la tarea, borra los datos de aprobación del inicio anterior de la tarea y actualiza el estado del trabajo a Process:
CREATE TRIGGER upd_task_status_process
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Process'
BEGIN
UPDATE tasks
SET start_date = DATETIME('NOW')
WHERE id_task = NEW.id_task;
DELETE FROM passes
WHERE id_task = NEW.id_task;
UPDATE jobs
SET status = 'Process'
WHERE id_job = NEW.id_job;
END;
A continuación, los estados de la etapa y del proyecto, dentro de los cuales se está realizando este trabajo, se transmiten en cascada al proceso:
CREATE TRIGGER upd_job_status_process AFTER UPDATE OF status ON jobs WHEN NEW.status = 'Process' BEGIN UPDATE stages SET status = 'Process' WHERE id_stage = NEW.id_stage; END; CREATE TRIGGER upd_stage_status_process AFTER UPDATE OF status ON stages WHEN NEW.status = 'Process' BEGIN UPDATE projects SET status = 'Process' WHERE id_project = NEW.id_project; END;
En el disparador que se activa cuando el estado de la tarea se actualiza a Listo, es decir cuando la tarea se completa, actualizamos la fecha de finalización de la tarea y luego (dependiendo de la presencia o ausencia de otras tareas en la cola de ejecución dentro del trabajo de la tarea actual) actualizaremos el estado del trabajo a Proceso o Listo:
CREATE TRIGGER upd_task_status_done
AFTER UPDATE OF status
ON tasks
WHEN NEW.status = 'Done'
BEGIN
UPDATE tasks
SET finish_date = DATETIME('NOW')
WHERE id_task = NEW.id_task;
UPDATE jobs
SET status = (
SELECT CASE WHEN (
SELECT COUNT( * )
FROM tasks t
WHERE t.status = 'Queued' AND
t.id_job = NEW.id_job
)
= 0 THEN 'Done' ELSE 'Process' END
)
WHERE id_job = NEW.id_job;
END;
Hagamos lo mismo con los estados del escenario y del proyecto:
CREATE TRIGGER upd_job_status_done AFTER UPDATE OF status ON jobs WHEN NEW.status = 'Done' BEGIN UPDATE stages SET status = ( SELECT CASE WHEN ( SELECT COUNT( * ) FROM jobs j WHERE j.status = 'Queued' AND j.id_stage = NEW.id_stage ) = 0 THEN 'Done' ELSE 'Process' END ) WHERE id_stage = NEW.id_stage; END; CREATE TRIGGER upd_stage_status_done AFTER UPDATE OF status ON stages WHEN NEW.status = 'Done' BEGIN UPDATE projects SET status = ( SELECT CASE WHEN ( SELECT COUNT( * ) FROM stages s WHERE s.status = 'Queued' AND s.name <> 'Single tester pass' AND s.id_project = NEW.id_project ) = 0 THEN 'Done' ELSE 'Process' END ) WHERE id_project = NEW.id_project; END;
También proporcionaremos la posibilidad de transferir todos los objetos del proyecto al estado Listo al establecer este estado en el proyecto en sí. No incluimos este escenario en la lista de reglas anterior, ya que no es una acción obligatoria en el curso normal de la optimización automática. En este disparador, establecemos el estado de todas las tareas no ejecutadas o en curso en Listo (Done), lo que dará como resultado que se establezca el mismo estado para todos los trabajos y etapas del proyecto:
CREATE TRIGGER upd_project_status_done AFTER UPDATE OF status ON projects WHEN NEW.status = 'Done' BEGIN UPDATE tasks SET status = 'Done' WHERE id_task IN ( SELECT t.id_task FROM tasks t JOIN jobs j ON j.id_job = t.id_job JOIN stages s ON s.id_stage = j.id_stage JOIN projects p ON p.id_project = s.id_project WHERE p.id_project = NEW.id_project AND t.status <> 'Done' ); END;
Una vez creados todos estos desencadenadores, veamos cómo determinar el orden de ejecución de la tarea.
Transportador
Hasta ahora solo hemos trabajado con un proyecto en la base de datos, así que comencemos mirando las reglas para determinar el orden de las tareas para este caso. Una vez que entendemos cómo determinar el orden de las tareas para un proyecto, podemos pensar en el orden de las tareas para varios proyectos lanzados simultáneamente.
Obviamente, las tareas de optimización relacionadas con el mismo trabajo y que difieren solo en el criterio de optimización se pueden realizar en cualquier orden: el lanzamiento secuencial de la optimización genética con diferentes criterios no utiliza información de optimizaciones anteriores. Se utilizan diferentes criterios de optimización para aumentar la diversidad de buenas combinaciones de parámetros encontradas. Se ha observado que las optimizaciones genéticas con los mismos rangos de entradas probadas, aunque con diferentes criterios, convergen a diferentes combinaciones.
Por lo tanto, no es necesario agregar ningún campo de clasificación a la tabla de tareas. Podemos utilizar el orden en el que se añadieron las tareas de un trabajo a la base de datos, es decir, ordenarlas por id_task.
Si solo hay una tarea dentro de un trabajo, entonces el orden de ejecución dependerá del orden de ejecución de los trabajos. Los trabajos fueron concebidos para agrupar o, más precisamente, dividir tareas en diferentes combinaciones de símbolos y marcos temporales. Si consideramos un ejemplo en el que tenemos tres símbolos (EURGBP, EURUSD, GBPUSD) y dos marcos temporales (H1, M30) y dos etapas (Stage1, Stage2), entonces podemos elegir dos órdenes posibles:
- Agrupación por símbolo y período de tiempo:
- EURGBP H1 Stage1
- EURGBP H1 Stage2
- EURGBP M30 Stage1
- EURGBP M30 Stage2
- EURUSD H1 Stage1
- EURUSD H1 Stage2
- EURUSD M30 Stage1
- EURUSD M30 Stage2
- GBPUSD H1 Stage1
- GBPUSD H1 Stage2
- GBPUSD M30 Stage1
- GBPUSD M30 Stage2
- Agrupación por etapa:
- Stage1 EURGBP H1
- Stage1 EURGBP M30
- Stage1 EURUSD H1
- Stage1 EURUSD M30
- Stage1 GBPUSD H1
- Stage1 GBPUSD M30
- Stage2 EURGBP H1
- Stage2 EURGBP M30
- Stage2 EURUSD H1
- Stage2 EURUSD M30
- Stage2 GBPUSD H1
- Stage2 GBPUSD M30
Con el primer método de agrupación (por símbolo y marco temporal), después de cada finalización de la segunda etapa, podremos recibir algo listo, es decir, el EA final. Incluirá conjuntos de copias individuales de estrategias comerciales para aquellos símbolos y períodos de tiempo que ya hayan pasado ambas etapas de optimización.
Con el segundo método de agrupación (por etapa (stage)), el EA final no podrá aparecer hasta que se haya completado todo el trabajo de la primera etapa y al menos un trabajo de la segunda etapa.
Para los trabajos que solo utilizan los resultados de los pasos anteriores para el mismo símbolo y período de tiempo, no habrá diferencia entre los dos métodos. Pero si miramos un poco hacia adelante, habrá otra etapa donde se combinarán los resultados de las segundas etapas para diferentes símbolos y marcos temporales. Aún no hemos llegado a su implementación como una etapa de optimización automática, pero ya hemos preparado una etapa EA para ello e incluso la hemos lanzado, aunque de forma manual. Para esta etapa el primer método de agrupación no es adecuado, por lo que utilizaremos el segundo.
Vale la pena señalar que si todavía queremos utilizar el primer método, entonces quizás nos bastará con crear varios proyectos para cada combinación de símbolo y marco temporal. Pero por ahora los beneficios no parecen claros.
Entonces, si tenemos varios trabajos dentro de una etapa, entonces el orden de su ejecución puede ser cualquiera, y para trabajos de diferentes etapas, el orden estará determinado por el orden de prioridad de las etapas. En otras palabras, como ocurre con las tareas, no es necesario agregar ningún campo de clasificación a la tabla de trabajos. Podemos utilizar el orden en el que se añadieron los trabajos de una etapa a la base de datos, es decir, ordenarlos por id_job.
Para determinar el orden de las etapas, también podemos utilizar los datos ya disponibles en la tabla de etapas (stages). He añadido el campo de etapa principal a esta tabla (id_parent_stage) al principio, pero aún no se ha utilizado. De hecho, cuando sólo tenemos dos filas en la tabla para dos etapas, no hay dificultad en crearlas en el orden correcto: primero una fila para la primera etapa y luego para la segunda. Cuando hay más y aparecen etapas para otros proyectos, se hace más difícil mantener manualmente el orden correcto.
Así que aprovechemos la oportunidad para construir una jerarquía de etapas de ejecución, donde cada etapa se ejecuta después de que se completa su etapa principal. Al menos una etapa no debe tener un padre para poder ocupar la posición superior en la jerarquía. Escribamos una consulta SQL de prueba que combinará datos de las tablas de tareas, trabajos y etapas y mostrará todas las tareas de la etapa actual. Agregaremos todos los campos a la lista de columnas de esta consulta para que podamos ver la información más completa.
SELECT t.id_task,
t.optimization_criterion,
t.status AS task_status,
j.id_job,
j.symbol AS job_symbol,
j.period AS job_period,
j.tester_inputs AS job_tester_inputs,
j.status AS job_status,
s.id_stage,
s.name AS stage,
s.expert AS stage_expert,
s.status AS stage_status,
ps.name AS parent_stage,
ps.status AS parent_stage_status,
p.id_project,
p.status AS project_status
FROM tasks t
JOIN
jobs j ON j.id_job = t.id_job
JOIN
stages s ON s.id_stage = j.id_stage
LEFT JOIN
stages ps ON ps.id_stage = s.id_parent_stage
JOIN
projects p ON p.id_project = s.id_project
WHERE t.id_task > 0 AND
t.status IN ('Queued', 'Process') AND
(ps.id_stage IS NULL OR
ps.status = 'Done')
ORDER BY j.id_stage,
j.symbol,
j.period,
t.status,
t.id_task;

Figura 1. Resultados de una consulta para obtener las tareas de la etapa actual después de iniciar una tarea
Más adelante, reduciremos la cantidad de columnas que se muestran cuando usemos una consulta similar para encontrar otra tarea. Mientras tanto, asegurémonos de recibir correctamente la siguiente etapa (junto con sus trabajos y tareas). Los resultados que se muestran en la Figura 1 corresponden al momento en que se inició la tarea con id_task=3. Esta es la tarea correspondiente a id_job=10, que forma parte de id_stage=10. Esta etapa se denomina «First», pertenece al proyecto con id_project=1 y no tiene etapa principal (parent_stage=NULL). Podemos ver que tener una tarea en ejecución hace que aparezca el estado del proceso tanto para el trabajo como para el proyecto en el que se está realizando dicho trabajo. Pero el otro trabajo con id_job=5 sigue teniendo el estado Queued, ya que aún no se ha iniciado ninguna de las tareas del trabajo.
Ahora intentemos completar la primera tarea (simplemente estableciendo el campo de estado en la tabla como «Done») y veamos los resultados de la misma consulta:

Figura 2. Resultados de una consulta para obtener las tareas de la etapa actual después de completar una tarea en ejecución
Como puedes ver, la tarea completada ha desaparecido de esta lista y la línea superior ahora está ocupada por otra tarea, que se puede iniciar a continuación. Hasta ahora todo correcto. Ahora, lancemos y completemos las dos primeras tareas de esta lista, y lancemos la tercera tarea con id_task=7 para su ejecución:

Figura 3. Resultados de una consulta para obtener las tareas de la etapa actual después de completar las tareas del primer trabajo y comenzar la siguiente tarea
Ahora el trabajo con id_job=5 ha recibido el estado de Proceso. A continuación, ejecutaremos y completaremos las tres tareas que ahora se muestran en los resultados de la última consulta. Desaparecerán de los resultados de la consulta uno por uno. Una vez completado el último, ejecute la consulta nuevamente y obtenga lo siguiente:

Figura 4. Resultados de una consulta para obtener las tareas de la etapa actual después de que se hayan completado todas las tareas de la primera etapa
Ahora los resultados de la consulta incluyen tareas de los trabajos relacionados con las siguientes etapas. id_stage=2 es la agrupación de los resultados de la primera etapa, mientras que id_stage=3 es la segunda etapa, en la que se realiza la agrupación de los buenos ejemplos de estrategias comerciales obtenidos en la primera etapa. Esta etapa no utiliza agrupamiento, por lo que se puede ejecutar inmediatamente después de la primera etapa. Así que su presencia en esta lista no es un error. Ambas etapas tienen una etapa principal denominada First, que ahora se encuentra en estado Done.
Simulemos el lanzamiento y la finalización de las dos primeras tareas y observemos nuevamente los resultados de la consulta:

Figura 5. Resultados de una consulta para obtener tareas después de que se completen todas las tareas de la etapa de agrupamiento
Como era de esperar, las primeras líneas de los resultados están ocupadas por dos tareas de la segunda etapa (denominadas «Second»), pero las dos últimas líneas ahora contienen tareas de la segunda etapa con agrupación (denominadas «Second with clustering»). Su aparición es algo inesperada, pero no contradice el orden aceptable. De hecho, si ya hemos completado la etapa de agrupamiento, entonces también podemos lanzar la etapa que utilizará los resultados del agrupamiento. Los dos pasos que se muestran en los resultados de la consulta son independientes entre sí, por lo que se pueden realizar en cualquier orden.
Ejecutemos y completemos cada tarea nuevamente, seleccionando la más alta en los resultados cada vez. La lista de tareas recibidas después de cada cambio de estado se comportó como se esperaba, los estados de los trabajos y las etapas cambiaron correctamente. Después de completar la última tarea, los resultados de la consulta estaban vacíos, ya que todas las tareas asignadas de todos los trabajos de todas las etapas se completaron y el proyecto pasó al estado «Done».
Integremos esta consulta en el EA de optimización.
Modificación del EA optimizador
Tendremos que realizar cambios en el método para obtener el ID de la siguiente tarea del optimizador, donde ya existe una consulta SQL que realiza esta tarea. Tomemos la consulta desarrollada anteriormente y eliminemos los campos adicionales, dejando solo id_task. También podemos sustituir la clasificación por un par de campos de la tabla de trabajos (j.symbol, j.period) por j.id_job, ya que cada trabajo solo tiene un valor de estos dos campos. Al final, añadiremos un límite al número de filas devueltas. Solo necesitamos una línea.
Ahora el método GetNextTaskId() tiene el siguiente aspecto:
//+------------------------------------------------------------------+ //| Get the ID of the next optimization task from the queue | //+------------------------------------------------------------------+ ulong COptimizer::GetNextTaskId() { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT t.id_task" " FROM tasks t " " JOIN " " jobs j ON j.id_job = t.id_job " " JOIN " " stages s ON s.id_stage = j.id_stage " " LEFT JOIN " " stages ps ON ps.id_stage = s.id_parent_stage " " JOIN " " projects p ON p.id_project = s.id_project " " WHERE t.id_task > 0 AND " " t.status IN ('Queued', 'Process') AND " " (ps.id_stage IS NULL OR " " ps.status = 'Done') " " ORDER BY j.id_stage, " " j.id_job, " " t.status, " " t.id_task" " LIMIT 1;"; // ... here we get the query result return res; }
Ya que hemos decidido trabajar con este archivo, hagamos otro cambio mientras tanto: eliminemos el paso del estado a través del parámetro del método del método para obtener el número de tareas en la cola. De hecho, nunca utilizamos este método para obtener el número de tareas con estado «En cola» y «En proceso», que luego se utilizarán individualmente, no como suma. Por lo tanto, modifiquemos la consulta SQL en el método TotalTasks() para que siempre devuelva el número total de tareas con estos dos estados y eliminemos la entrada status del método:
//+------------------------------------------------------------------+ //| Get the number of tasks with the specified status | //+------------------------------------------------------------------+ int COptimizer::TotalTasks() { // Result int res = 0; // Request to get the number of tasks with the specified status string query = "SELECT COUNT(*)" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status IN ('Queued', 'Process') " " ORDER BY s.id_stage, j.id_job, t.status LIMIT 1;"; // ... here we get the query result return res; }
Guardemos los cambios en el archivo Optimizer.mqh de la carpeta actual.
Además de estas modificaciones, también tendremos que sustituir el antiguo nombre de estado «Processing» por «Process» en varios archivos, ya que hemos acordado utilizarlo anteriormente.
También sería útil proporcionar la posibilidad de obtener información sobre los errores que puedan haber ocurrido durante la ejecución de la tarea que inicia el programa Python. Ahora bien, cuando un programa de este tipo se cierra de forma anómala, el EA optimizador simplemente se queda bloqueado en la fase de espera a que se complete la tarea o, más concretamente, a que aparezca información sobre este evento en la base de datos. Si el programa finaliza con un error, no puede actualizar el estado de la tarea en la base de datos. Por lo tanto, la cinta transportadora no podrá seguir avanzando en esta fase.
Hasta ahora, la única forma de superar este obstáculo es volver a ejecutar manualmente el programa Python con los parámetros especificados en la tarea, analizar las causas de los errores, eliminarlos y volver a ejecutar el programa.
Modificación de SimpleVolumesStage3.mq5
A continuación, planeamos automatizar la tercera etapa, en la que, para cada trabajo de la segunda etapa (que difieren en el símbolo y el marco temporal utilizados), seleccionamos el mejor pase para incluirlo en el EA final.
Hasta ahora, la EA de la etapa 3 ha estado tomando como entrada una lista de ID de paso de la etapa 2, y hemos tenido que seleccionar manualmente de alguna manera esos ID de la base de datos. Aparte de eso, este EA solo realizó la creación, la evaluación de la reducción y el almacenamiento de un grupo de estos pases en la biblioteca. La EA final no apareció como resultado del lanzamiento de la tercera etapa de la EA, ya que era necesario realizar una serie de acciones adicionales. Volveremos más adelante a la automatización de estas acciones, pero por ahora vamos a trabajar en la modificación de la tercera etapa EA.
Existen diferentes métodos que se pueden utilizar para seleccionar automáticamente los ID de pase.
Por ejemplo, de todos los resultados de los pases obtenidos en el marco de un trabajo de la segunda etapa, podemos seleccionar el mejor en términos del indicador del beneficio medio anual normalizado. Cada uno de estos pases será el resultado de un grupo de 16 instancias individuales de estrategias de negociación. Entonces, la EA final incluirá un conjunto de varios grupos de instancias de estrategias individuales. Si tomamos tres símbolos y dos marcos temporales, entonces en la segunda etapa tenemos 6 trabajos. Luego, en la tercera etapa, obtendremos un grupo que incluirá 6 * 16 = 96 copias de estrategias únicas. Este método es el más fácil de implementar.
Un ejemplo de un método de selección más complejo es el siguiente: para cada trabajo de segunda fase, tomamos una serie de las mejores pasadas y probamos diferentes combinaciones de todas las pasadas seleccionadas. Esto es muy similar a lo que hicimos en la segunda etapa, solo que ahora reclutaremos a un grupo no de 16 instancias individuales, sino de 6 grupos, y en el primero de los seis grupos tomaremos uno de los mejores pases del primer trabajo, en el segundo, uno de los mejores pases del segundo trabajo, y así sucesivamente. Este método es más complicado, pero no se puede afirmar de antemano que vaya a mejorar significativamente los resultados.
Por lo tanto, primero implementaremos el método más sencillo y pospondremos la complicación para más adelante.
En esta etapa, ya no será necesario optimizar los parámetros del EA. Ahora será una sola pasada. Para ello, debemos especificar los parámetros adecuados en la configuración de la etapa en la base de datos: la columna de optimización debe ser 0.

Figura 6. Contenido de la tabla de etapas
En el código EA, añadiremos el ID de la tarea de optimización a las entradas para que este EA pueda ejecutarse en el transportador y guardar correctamente los resultados de la pasada en la base de datos:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput int idTask_ = 0; // - Optimization task ID sinput string fileName_ = "database911.sqlite"; // - File with the main database input group "::: Selection for the group" input string passes_ = ""; // - Comma-separated pass IDs input group "::: Saving to library" input string groupName_ = ""; // - Group name (if empty - no saving)
El parámetro passes_ se puede eliminar, pero lo dejaré por ahora por si acaso. Escribamos una consulta SQL que obtenga una lista de los mejores ID de pase para los trabajos de la segunda etapa. Si el parámetro passes_ está vacío, tomamos los ID de los mejores pases. Si el parámetro passes_ pasa algunos ID específicos, los aplicaremos.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); CTesterHandler::TesterInit(idTask_, fileName_); // Initialization string with strategy parameter sets string strategiesParams = NULL; // If the connection to the main database is established, if(DB::Connect(fileName_)) { // Form a request to receive passes with the specified IDs string query = (passes_ == "" ? StringFormat("SELECT DISTINCT FIRST_VALUE(p.params) OVER (PARTITION BY p.id_task ORDER BY custom_ontester DESC) AS params " " FROM passes p " " WHERE p.id_task IN (" " SELECT pt.id_task " " FROM tasks t " " JOIN " " jobs j ON j.id_job = t.id_job " " JOIN " " stages s ON s.id_stage = j.id_stage " " JOIN " " jobs pj ON pj.id_stage = s.id_parent_stage " " JOIN " " tasks pt ON pt.id_job = pj.id_job " " WHERE t.id_task = %d " " ) ", idTask_) : StringFormat("SELECT params" " FROM passes " " WHERE id_pass IN (%s);", passes_) ); Print(query); int request = DatabasePrepare(DB::Id(), query); if(request != INVALID_HANDLE) { // Structure for reading results struct Row { string params; } row; // For all query result strings, concatenate initialization rows while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } } DB::Close(); } // ... // Successful initialization return(INIT_SUCCEEDED); }
Guarde los cambios realizados en el archivo SimpleVolumesStage3.mq5 en la carpeta actual.
Con esto se completa la modificación de la tercera etapa EA. Pasemos el proyecto de la base de datos al estado «Queued» y lancemos el EA de optimización.
Resultados de optimización del transportador
A pesar de que aún no hemos implementado todas las etapas planificadas, ahora ya contamos con una herramienta que proporciona automáticamente un EA final casi listo. Después de completar la tercera etapa, tenemos dos entradas en la biblioteca de parámetros (tabla strategy_groups):

El primero contiene el ID del pase, en el que se combinan los mejores grupos de la segunda fase sin agruparlos. El segundo es el ID del pase, en el que se combinan los mejores grupos de la segunda etapa con agrupamiento. Por consiguiente, podemos obtener cadenas de inicialización de la tabla passes para estos ID de paso y examinar los resultados de estas dos combinaciones.
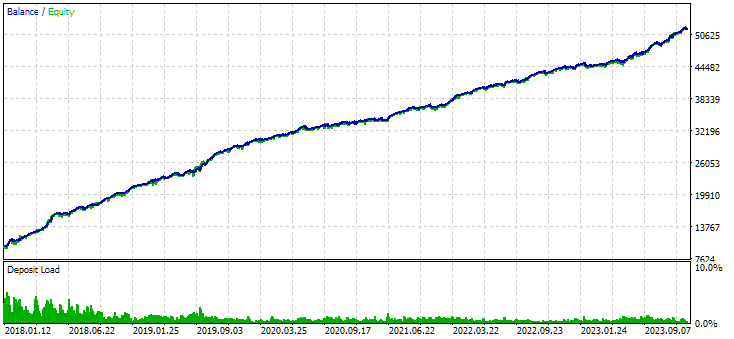
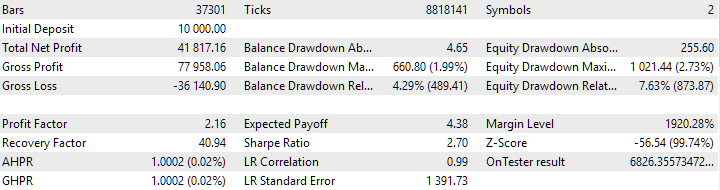
Figura 7. Resultados del grupo combinado de instancias obtenidos sin utilizar clustering
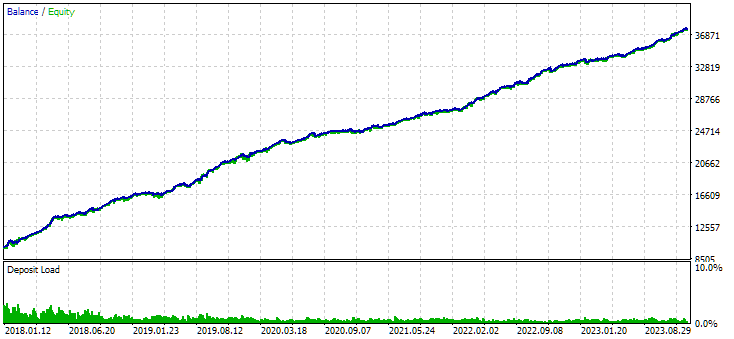
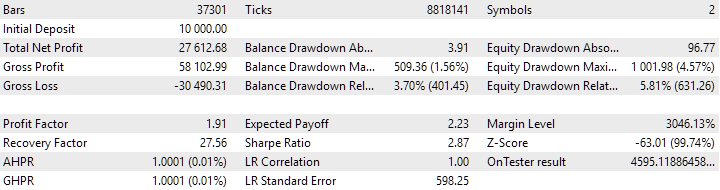
Figura 8. Resultados del grupo combinado de instancias obtenidos mediante agrupamiento
La variante sin agrupamiento muestra mayores ganancias. Sin embargo, la variante con agrupamiento tiene un índice de Sharpe más alto y una mejor linealidad. Pero por ahora no analizaremos estos resultados en detalle, ya que aún no son definitivos.
El siguiente paso es agregar etapas para ensamblar el EA final. Necesitamos exportar la biblioteca para obtener el archivo de inclusión ExportedGroupsLibrary.mqh en la carpeta de datos. Luego debemos copiar este archivo a la carpeta de trabajo. Esta operación se puede realizar utilizando un programa Python o utilizando las funciones de copia del sistema desde la DLL. En la última etapa, solo necesitamos compilar el EA final y lanzar la terminal con la nueva versión de EA.
Todo esto requerirá una cantidad importante de tiempo para su implementación, por lo que continuaremos su descripción en el siguiente artículo.
Conclusión
Entonces, veamos lo que tenemos. Hemos puesto en orden la auto ejecución de las primeras etapas del transportador de auto optimización, consiguiendo su correcto funcionamiento. Podemos mirar los resultados intermedios y decidir, por ejemplo, abandonar el paso de agrupamiento. O por el contrario déjalo y elimina la opción sin agrupar.
Disponer de una herramienta de este tipo nos ayudará a realizar experimentos en el futuro e intentar responder preguntas difíciles. Por ejemplo, supongamos que realizamos optimización en diferentes rangos de entradas en la primera etapa. ¿Qué es mejor: combinarlos por separado o juntos mediante los mismos símbolos y marcos temporales?
Añadiendo etapas al transportador podemos implementar el ensamblaje gradual de EA cada vez más complejo.
Por último, podemos considerar la cuestión de la reoptimización parcial e incluso la reoptimización continua realizando un experimento apropiado. En este caso, la reoptimización significa una optimización repetida en un intervalo de tiempo diferente. Pero hablaremos más sobre esto la próxima vez.
¡Gracias por su atención! ¡Nos vemos pronto!
Advertencia importante:
Todos los resultados presentados en este artículo y en todos los artículos anteriores de la serie se basan únicamente en datos de pruebas históricas y no son una garantía de ganancias en el futuro. El trabajo dentro de este proyecto es de naturaleza investigativa. Todos los resultados publicados pueden ser utilizados por cualquier persona bajo su propio riesgo.
Contenido del archivo
| # | Nombre | Versión | Descripción | Cambios recientes |
|---|---|---|---|---|
| MQL5/Experts/Article.16134 | ||||
| 1 | Advisor.mqh | 1.04 | Clase base del EA | Parte 10 |
| 2 | ClusteringStage1.py | 1.01 | Programa para agrupar los resultados de la primera etapa de optimización | Parte 20 |
| 3 | Database.mqh | 1.07 | Clase para el manejo de la base de datos | Parte 19 |
| 4 | database.sqlite.schema.sql | 1.05 | Estructura de la base de datos | Parte 20 |
| 5 | ExpertHistory.mqh | 1.00 | Clase para exportar el historial comercial a un archivo | Parte 16 |
| 6 | ExportedGroupsLibrary.mqh | — | Se genera un listado de nombres de grupos de estrategias de archivos y la matriz de sus cadenas de inicialización | Parte 17 |
| 7 | Factorable.mqh | 1.02 | Clase base de objetos creados a partir de una cadena (string) | Parte 19 |
| 8 | GroupsLibrary.mqh | 1.01 | Clase para trabajar con una biblioteca de grupos de estrategias seleccionados | Parte 18 |
| 9 | HistoryReceiverExpert.mq5 | 1.00 | EA para reproducir el historial de transacciones con el gestor de riesgos | Parte 16 |
| 10 | HistoryStrategy.mqh | 1.00 | Clase de estrategia comercial para reproducir el historial de transacciones | Parte 16 |
| 11 | Interface.mqh | 1.00 | Clase básica para visualizar varios objetos | Parte 4 |
| 12 | LibraryExport.mq5 | 1.01 | EA que guarda cadenas de inicialización de pases seleccionados de la biblioteca en el archivo ExportedGroupsLibrary.mqh | Parte 18 |
| 13 | Macros.mqh | 1.02 | Macros útiles para operaciones con matrices | Parte 16 |
| 14 | Money.mqh | 1.01 | Clase básica de administración del dinero | Parte 12 |
| 15 | NewBarEvent.mqh | 1.00 | Clase para definir una nueva barra para un símbolo específico | Parte 8 |
| 16 | Optimization.mq5 | 1.03 | EA gestiona el lanzamiento de tareas de optimización | Parte 19 |
| 17 | Optimizer.mqh | 1.01 | Clase para el gestor de proyectos de optimización automática | Parte 20 |
| 18 | OptimizerTask.mqh | 1.01 | Clase de tarea de optimización | Parte 20 |
| 19 | Receiver.mqh | 1.04 | Clase base para convertir volúmenes abiertos en posiciones de mercado | Parte 12 |
| 20 | SimpleHistoryReceiverExpert.mq5 | 1.00 | EA simplificado para reproducir el historial de transacciones | Parte 16 |
| 21 | SimpleVolumesExpert.mq5 | 1.20 | EA para la operación paralela de varios grupos de estrategias de modelo. Los parámetros se tomarán de la biblioteca de grupo incorporada. | Parte 17 |
| 22 | SimpleVolumesStage1.mq5 | 1.18 | Estrategia comercial de optimización de instancia única EA (stage 1) | Parte 19 |
| 23 | SimpleVolumesStage2.mq5 | 1.02 | Optimización de grupos de instancias de estrategias comerciales EA (stage 2) | Parte 19 |
| 24 | SimpleVolumesStage3.mq5 | 1.02 | El EA que guarda un grupo estandarizado generado de estrategias en una biblioteca de grupos con un nombre determinado. | Parte 20 |
| 25 | SimpleVolumesStrategy.mqh | 1.09 | Clase de estrategia comercial que utiliza volúmenes de ticks | Parte 15 |
| 26 | Strategy.mqh | 1.04 | Clase base de estrategia comercial | Parte 10 |
| 27 | TesterHandler.mqh | 1.05 | Clase de manejo de eventos de optimización | Part 19 |
| 28 | VirtualAdvisor.mqh | 1.07 | Clase del EA que maneja posiciones virtuales (órdenes) | Parte 18 |
| 29 | VirtualChartOrder.mqh | 1.01 | Clase de posición virtual gráfica | Parte 18 |
| 30 | VirtualFactory.mqh | 1.04 | Clase de fábrica de objetos | Parte 16 |
| 31 | VirtualHistoryAdvisor.mqh | 1.00 | Clase EA de repetición del historial comercial | Parte 16 |
| 32 | VirtualInterface.mqh | 1.00 | Clase GUI del EA | Parte 4 |
| 33 | VirtualOrder.mqh | 1.07 | Clase de órdenes y posiciones virtuales | Parte 19 |
| 34 | VirtualReceiver.mqh | 1.03 | Clase para convertir volúmenes abiertos en posiciones de mercado (receiver) | Parte 12 |
| 35 | VirtualRiskManager.mqh | 1.02 | Clase de gestión de riesgos (risk manager) | Parte 15 |
| 36 | VirtualStrategy.mqh | 1.05 | Clase de estrategia comercial con posiciones virtuales | Parte 15 |
| 37 | VirtualStrategyGroup.mqh | 1.00 | Clase de grupo(s) de estrategias comerciales | Parte 11 |
| 38 | VirtualSymbolReceiver.mqh | 1.00 | Clase receptora de símbolos | Parte 3 |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16134
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
 Observador de Connexus (Parte 8): Cómo agregar un observador de solicitudes
Observador de Connexus (Parte 8): Cómo agregar un observador de solicitudes
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Hola Yuriy
He utilizado Google Translate para llegar a la parte 20. Busca en Google "Google Translate" y ponlo en una nueva pestaña del navegador. Colocará un icono en la barra de búsqueda en el extremo derecho. Carga la página en su idioma nativo y pulsa el icono para seleccionar el idioma del artículo y el que se traducirá a él. Presto, ¡estoy en la parte 20! No hace un trabajo perfecto pero la traducción es útil en un 99%.
He cargado tu Fuente de Archivo en Excel y he añadido unas cuantas columnas para ordenar los contenidos. Además de la clasificación en Excel, la hoja de cálculo puede importarse directamente a una base de datos OutLook.
Estoy teniendo problemas para identificar el artículo de inicio para establecer la base de datos SQL. Intenté ejecutar Simple Volume Stage 1 y obtuve una línea plana que me indica que probablemente necesite retroceder y crear otra base de datos SQL. Sería extremadamente útil disponer de una tabla con el orden de ejecución de los programas necesarios para obtener un sistema que funcione. Tal vez podría añadirla a la tabla Fuente de archivos.
Otra pequeña petición es utilizar la opción <> para las especificaciones de archivos include en lugar de "". Mantengo su sistema separado en mis directorios Experts e Include, #include <!!!! MultiCurrency\VirtualAdvisor.mqh>, así que este cambio hará más fácil añadir la especificación del subdirectorio/.
Gracias por tu aportación
CapeCoddah
Hola.
Sobre el llenado inicial de la base de datos con información sobre el proyecto, etapas, obras y tareas se puede ver en las partes 13, 18, 19. Este no es el tema principal, por lo que la información que necesita estará en algún lugar más cerca del final de los artículos. Por ejemplo, en la parte 18:
O en la parte 19:
O puede esperar al próximo artículo, que estará dedicado, entre otras cosas, a la cuestión del llenado inicial de la base de datos con la ayuda de un script auxiliar.
El cambio al uso de la carpeta include para almacenar los archivos de la biblioteca está en los planes, pero todavía no se ha llegado a eso.
muchas gracias
Hola Yuriy,
¿Has enviado el próximo artículo o sabes cuándo se publicará?