
Desarrollamos un asesor experto multidivisa (Parte 6): Automatizamos la selección de un grupo de instancias
Introducción
En el artículo anterior dimos un paso importante, ya que implementamos la posibilidad de elegir la variante de funcionamiento de las estrategias: con tamaño de posición constante y con tamaño de posición variable. Esto nos ha permitido normalizar el rendimiento de las estrategias según la reducción máxima alcanzada y nos ha brindado la oportunidad de combinarlas en grupos para los que la reducción máxima también se encuentra dentro de los límites especificados. Para demostrarlo, en su momento seleccionamos manualmente algunas de las combinaciones más atractivas de parámetros de entrada a partir de los resultados de optimización de una única instancia de estrategia e intentamos combinarlas en un único grupo o incluso en un grupo de tres grupos de tres estrategias cada uno. En este último caso, obtuvimos los mejores resultados.
Sin embargo, si se trata de aumentar el número de estrategias en grupos y el número de grupos distintos que hay que fusionar, la cantidad de trabajo manual rutinario aumenta enormemente.
En primer lugar, en cada símbolo, deberemos optimizar una única instancia de estrategia con diferentes criterios de optimización. Y para cada símbolo podría ser necesario realizar una optimización separada para diferentes marcos temporales. Para nuestra estrategia modelo en concreto, también podremos realizar una optimización independiente para los tipos de órdenes que se van a abrir (stop, límite o posiciones de mercado).
En segundo lugar, deberemos seleccionar un número pequeño (10 - 20) de los mejores parámetros a partir de los conjuntos de parámetros obtenidos como resultado de las optimizaciones, que son unos 20 - 50 mil. Sin embargo, deben ser los mejores no solo por sí solos, sino también cuando trabajan juntos en grupo. El proceso de selección y adición de instancias de estrategias de una en una también requiere tiempo y paciencia.
En tercer lugar, los grupos obtenidos deberán combinarse a su vez en grupos superiores llevando a cabo una normalización. Si lo hacemos manualmente, solo podremos permitirnos dos o tres niveles. Un mayor número de niveles de agrupación parece ya demasiado laborioso.
Por lo tanto, intentaremos automatizar esta etapa del desarrollo del EA.
Trazando el camino
Por desgracia, difícilmente lograremos hacerlo todo al mismo tiempo. Por el contrario, la complejidad de la tarea podría hacernos reacios a emprenderla. Así que trataremos de enfocarla al menos desde cierto punto de vista. La principal dificultad que impide su aplicación son varias cuestiones que quedan en el aire: "¿Nos servirá de algo? ¿Sería posible sustituir la selección manual por la automática sin perder calidad (y preferiblemente aumentándola)? ¿No resultará este proceso en general aún más lento que la selección manual?".
Hasta que no demos respuesta a estas preguntas, resultará difícil abordar una solución. Por eso, haremos lo siguiente: la primera tarea consistirá en probar la hipótesis de que la selección automatizada en grupos puede resultar útil. Para comprobarlo, tomaremos cualquier conjunto de resultados de optimización de instancia única sobre un único símbolo y seleccionaremos manualmente un buen grupo normalizado. Esta será nuestra muestra de referencia para comparar los resultados (baseline). A continuación, con un gasto mínimo, escribiremos una sencilla implementación de la automatización que permita la selección no manual de grupos, y luego compararemos el resultado del grupo seleccionado por automatización con el resultado del grupo seleccionado manualmente. Si los resultados de la comparación muestran que la automatización es prometedora, entonces podremos implementar otra realización más bonita y correcta.
Preparación de los datos iniciales
Empezaremos descargando los resultados de la optimización del asesor experto SimpleVolumesExpertSingle.mq5, obtenidos tras escribir las partes anteriores, y exportándolos a XML.
Fig. 1. Exportación de los resultados de la optimización para su procesamiento posterior
Para simplificar su uso posterior, añadiremos a este archivo columnas adicionales con los valores de aquellos parámetros que no han intervenido en la optimización. Tendremos que añadir symbol, timeframe, maxCountOfOrders y, lo más importante, fittedBalance. Luego calcularemos el valor de este último según la reducción relativa máxima conocida de los fondos.
Si bien utilizamos un balance inicial de 100 000 $, la reducción absoluta fue de aproximadamente 100 000 * (relDDDpercent / 100). Este valor deberá ser el 10% de fittedBalance, por lo que obtendremos:
fittedBalance = 100000 * (relDDpercent / 100) / 0.1 = relDDpercent * 10000
El valor del marco temporal que se establece en el código mediante la constante PERIOD_H1, lo representaremos como su valor numérico 16385.
Las sumas darán como resultado una tabla de datos que guardaremos en formato CSV. En la forma transpuesta, las primeras filas de la tabla obtenida tendrán el siguiente aspecto:
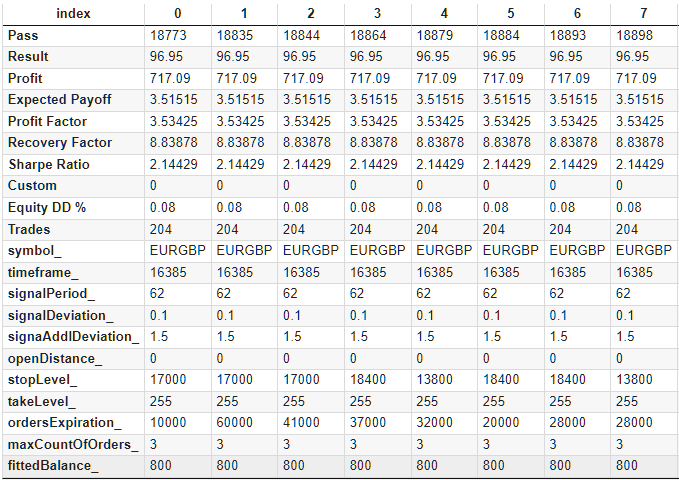
Fig. 2. Tabla completa con los resultados de la optimización
Lo ideal sería dejar este trabajo a la computadora, por ejemplo utilizando la biblioteca TesterCache, o implementando alguna otra forma de guardar datos sobre cada pasada durante la optimización. Pero hemos acordado comenzar invirtiendo el mínimo esfuerzo posible. Así que por ahora haremos este trabajo manualmente.
Esta tabla contendrá filas en las que el beneficio ha sido inferior a cero (aproximadamente 1 000 filas de un total de 18 000). Desde luego, estos resultados no nos interesan, así que los eliminaremos directamente.
Después de ello, los datos iniciales estarán listos para construir la variante básica y para su uso posterior en la selección de grupos de estrategias que puedan competir con la variante básica.
Baseline
Preparar la variante básica es un proceso sencillo pero monótono. Para empezar, de alguna manera tendremos que clasificar nuestras estrategias en orden descendente de "calidad". Para evaluar la calidad, usaremos este método. Destacaremos el conjunto de columnas que contienen las diferentes métricas de resultados en esta tabla: Profit, Expected Payoff, Profit Factor, Recovery Factor, Sharpe Ratio, Equity DD %, Trades. A cada una de ellas le aplicaremos un escalado min-max que nos llevará al rango [0; 1]. Luego obtendremos columnas adicionales con el sufijo '_s', en las que calcularemos para cada fila la suma de esta manera:
0.5 * Profit_s + ExpectedPayoff_s + ProfitFactor_s + RecoveryFactor_s + SharpeRatio_s + (1 - EquityDD_s) + 0.3 * Trades_s,
y la añadiremos como una nueva columna de la tabla. Después la clasificaremos por orden descendente.
Y empezaremos a desplazarnos por la lista de arriba abajo, añadiendo los candidatos que nos gusten al grupo y comprobando directamente cómo funcionan juntos. Intentaremos añadir conjuntos de parámetros que sean lo más diferentes posible tanto en parámetros como en resultados.
Por ejemplo, entre los conjuntos de parámetros, hay algunos que solo difieren en el nivel de SL. Pero si este nivel no se ha activado ni una sola vez durante el periodo de prueba, diferentes niveles producirán los mismos resultados. Por ello, estas combinaciones no se podrán unir, ya que tendrán el mismo tiempo de apertura y cierre de posiciones, y por lo tanto, tiempos de reducción máxima iguales. Queremos elegir instancias de forma que sus reducciones se produzcan en momentos diferentes. Esto nos permitirá aumentar la rentabilidad debido a que los volúmenes de las posiciones pueden reducirse en un menor número de veces en lugar de proporcionalmente al número de estrategias.
Seleccionaremos, pues, 16 casos normalizados de estrategias.
También aplicaremos la negociación de balance fijo a la operación. Para ello, fijaremos FixedBalance = 10000. Con esta elección, las estrategias normalizadas producirán individualmente una reducción máxima igual a 1 000. Veamos los resultados de las pruebas:
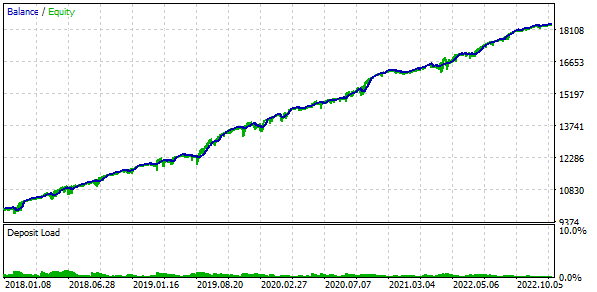
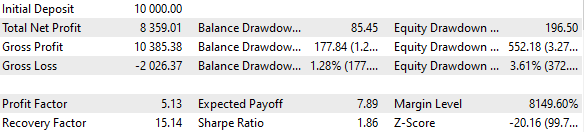
Fig. 3. Resultados de la variante básica
Resulta que si combinamos 16 instancias de estrategias y reducimos el tamaño de las posiciones abiertas por cada instancia en un factor de 16, la reducción máxima será de solo 552 $ en lugar de 1 000 $. Para convertir este grupo de estrategias en un grupo normalizado, calcularemos que puede aplicarse un multiplicador Scale de 1000 / 552 = 1,81 para mantener una reducción del 10%.
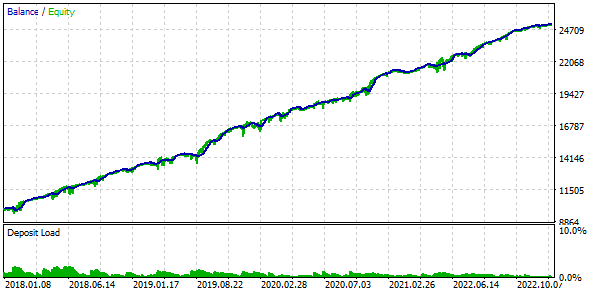

Fig. 4. Resultados de la variante básica con el grupo normalizado (Scale=1,81)
Para recordar el uso de FixedBalance = 10000 y Scale = 1.81, estableceremos estos números como valores por defecto para los parámetros de entrada correspondientes. Obtendremos el siguiente código:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" input double expectedDrawdown_ = 10; // - Maximum risk (%) input double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency input double scale_ = 1.81; // - Group scaling multiplier input group "::: Other parameters" input ulong magic_ = 27183; // - Magic CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Create an EA handling virtual positions expert = new CVirtualAdvisor(magic_, "SimpleVolumes_Baseline"); // Create and fill the array of all selected strategy instances CVirtualStrategy *strategies[] = { new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 48, 1.6, 0.1, 0, 11200, 1160, 51000, 3, 3000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 156, 0.4, 0.7, 0, 15800, 905, 18000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 156, 1, 0.8, 0, 19000, 680, 41000, 3, 900), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 14, 0.3, 0.8, 0, 19200, 495, 27000, 3, 1100), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 38, 1.4, 0.1, 0, 19600, 690, 60000, 3, 1000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 98, 0.9, 1, 0, 15600, 1850, 7000, 3, 1300), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 44, 1.8, 1.9, 0, 13000, 675, 45000, 3, 600), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 86, 1, 1.7, 0, 17600, 1940, 56000, 3, 1000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 230, 0.7, 1.2, 0, 8800, 1850, 2000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 44, 0.1, 0.6, 0, 10800, 230, 8000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 108, 0.6, 0.9, 0, 12000, 1080, 46000, 3, 800), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 182, 1.8, 1.9, 0, 13000, 675, 33000, 3, 600), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 62, 0.1, 1.5, 0, 16800, 255, 2000, 3, 800), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 12, 1.4, 1.7, 0, 9600, 440, 59000, 3, 700), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 24, 1.7, 2, 0, 11600, 1930, 23000, 3, 700), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 30, 1.1, 0.1, 0, 18400, 1295, 27000, 3, 1500), }; // Add a group of selected strategies to the strategies expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
Lo guardaremos en el archivo BaselineExpert.mq5 en la carpeta actual.
La variante básica para la comparación está lista, ahora implementaremos la automatización de la selección de instancias de estrategias en un grupo.
Mejorando la estrategia
Las combinaciones de parámetros de entrada, que tendremos que sustituir como parámetros del constructor de la estrategia, se almacenarán ahora en un archivo CSV, es decir, al leerlos desde allí los obtendremos como valores de tipo string. Resultaría muy cómodo que la estrategia tuviera un constructor que aceptara una única cadena, a partir de la cual seleccionara todos los parámetros necesarios. En el futuro, planeamos implementar exactamente esta forma de transmitir parámetros al constructor, por ejemplo, utilizando la biblioteca Input_Struct. Pero por ahora, para simplificar, añadiremos un segundo constructor de este tipo:
//+------------------------------------------------------------------+ //| Trading strategy using tick volumes | //+------------------------------------------------------------------+ class CSimpleVolumesStrategy : public CVirtualStrategy { ... public: CSimpleVolumesStrategy(const string &p_params); ... }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(const string &p_params) { string param[]; int total = StringSplit(p_params, ',', param); if(total == 11) { m_symbol = param[0]; m_timeframe = (ENUM_TIMEFRAMES) StringToInteger(param[1]); m_signalPeriod = (int) StringToInteger(param[2]); m_signalDeviation = StringToDouble(param[3]); m_signaAddlDeviation = StringToDouble(param[4]); m_openDistance = (int) StringToInteger(param[5]); m_stopLevel = StringToDouble(param[6]); m_takeLevel = StringToDouble(param[7]); m_ordersExpiration = (int) StringToInteger(param[8]); m_maxCountOfOrders = (int) StringToInteger(param[9]); m_fittedBalance = StringToDouble(param[10]); CVirtualReceiver::Get(GetPointer(this), m_orders, m_maxCountOfOrders); // Load the indicator to get tick volumes m_iVolumesHandle = iVolumes(m_symbol, m_timeframe, VOLUME_TICK); // Set the size of the tick volume receiving array and the required addressing ArrayResize(m_volumes, m_signalPeriod); ArraySetAsSeries(m_volumes, true); } }
Este constructor asume que los valores de todos los parámetros estarán empaquetados en una única cadena en el orden correcto y separados por un carácter de coma. Dicha cadena se transmitirá como un único parámetro del constructor, dividido en partes por comas, y cada parte, después de la conversión al tipo de datos correspondiente, se asignará a la propiedad requerida de la clase.
Vamos a guardar los cambios en el archivo SimpleVolumesStrategy.mqh en la carpeta actual.
Mejorando los asesores
Tomaremos el asesor experto SimpleVolumesExpert.mq5 como ejemplo, y crearemos un nuevo asesor experto basado en él que optimizará la selección de varias instancias de estrategias a partir del mismo archivo CSV que utilizamos anteriormente para la selección manual.
En primer lugar, añadiremos el grupo de parámetros de entrada que se puede utilizar para asegurarnos de que la lista de parámetros de la instancia de estrategias se cargue y se seleccione en el grupo. Para simplificar, limitaremos a ocho el número de estrategias que pueden incluirse simultáneamente en el grupo y permitiremos la posibilidad de establecer un número inferior a 8.
input group "::: Selection for the group" sinput string fileName_ = "Params_SV_EURGBP_H1.csv"; // File with strategy parameters (*.csv) sinput int count_ = 8; // Number of strategies in the group (1 .. 8) input int i0_ = 0; // Strategy index #1 input int i1_ = 1; // Strategy index #2 input int i2_ = 2; // Strategy index #3 input int i3_ = 3; // Strategy index #4 input int i4_ = 4; // Strategy index #5 input int i5_ = 5; // Strategy index #6 input int i6_ = 6; // Strategy index #7 input int i7_ = 7; // Strategy index #8
Si el parámetro count_ es inferior a 8, solo se utilizará para la enumeración el número de parámetros indicados en él que especifiquen índices de estrategia.
A continuación, nos encontraremos con cierta complejidad. El asunto es que si colocamos el archivo con los parámetros de la estrategia Params_SV_EURGBP_H1.csv en el directorio de datos de la terminal, se leerá desde allí solo cuando se ejecute este EA en el gráfico del terminal. Si lo ejecutamos en el simulador, este archivo no se detectará porque el simulador trabaja con su propio directorio de datos. Podemos, por supuesto, encontrar la ubicación del directorio de datos del simulador y copiar el archivo allí, pero esto resulta bastante incómodo y no resuelve el siguiente problema que surge.
El siguiente problema es que al ejecutar la optimización (que es para lo que desarrollamos este EA), el archivo de datos no estará disponible para el clúster de agentes de la red local, por no hablar de los agentes de MQL5 Cloud Network.
Una solución temporal a estos problemas podría ser la inclusión del contenido del archivo de datos en el código fuente del EA. Pero vamos a seguir intentando ofrecer la posibilidad de utilizar un archivo CSV externo. Para ello, tendremos que usar los medios en MQL5 como la directiva de preprocesador tester_file y el manejador de eventos OnTesterInit(). También aprovecharemos la presencia de la carpeta de datos común para todos los terminales y los agentes de ensayo en la computadora local.
Como se indica en la guía de ayuda, la directiva tester_file permite especificar el nombre del archivo para el simulador que se le transmitirá para que trabaje en él. Esto implica que, aunque el simulador se esté ejecutando en un servidor remoto, este archivo se le enviará y se ubicará en el directorio de datos del agente de pruebas. Parece ser exactamente lo que necesitamos. ¡Pero nada de eso! Este nombre de archivo deberá ser una constante y deberá definirse en el momento de la compilación. Por ello, no podremos sustituir en ella el nombre del archivo arbitrario transmitido en los parámetros de entrada del EA solo cuando se inicia la optimización.
Tendremos que usar la siguiente maniobra de distracción. Seleccionaremos un nombre de archivo fijo y lo estableceremos en el EA. Podemos construirlo, por ejemplo, a partir del nombre del propio asesor. Precisamente este nombre de constante será el que especificaremos en la directiva tester_file:
#define PARAMS_FILE __FILE__".params.csv" #property tester_file PARAMS_FILE
A continuación, añadiremos una variable global para el array de conjuntos de parámetros de estrategia como cadenas. Será en este array donde leamos los datos del archivo.
string params[]; // Array of strategy parameter sets as strings
A continuación, escribiremos una función para cargar los datos desde un archivo, que funcionará de la siguiente manera. Primero comprobaremos si el archivo con el nombre especificado existe en la carpeta de datos compartidos del terminal o en la carpeta de datos. Si está ahí, lo copiaremos en un archivo con un nombre fijo seleccionado en la carpeta de datos. Después abriremos un archivo con el nombre fijo para la lectura y leeremos los datos de él.
//+------------------------------------------------------------------+ //| Load strategy parameter sets from a CSV file | //+------------------------------------------------------------------+ int LoadParams(const string fileName, string &p_params[]) { bool res = false; // Check if the file exists in the shared folder and in the data folder if(FileIsExist(fileName, FILE_COMMON)) { // If it is in the shared folder, then copy it to the data folder with a fixed name res = FileCopy(fileName, FILE_COMMON, PARAMS_FILE, FILE_REWRITE); } else if(FileIsExist(fileName)) { // If it is in the data folder, then copy it here, but with a fixed name res = FileCopy(fileName, 0, PARAMS_FILE, FILE_REWRITE); } // If there is a file with a fixed name, that is good as well if(FileIsExist(PARAMS_FILE)) { res = true; } // If the file is found, then if(res) { // Open it int f = FileOpen(PARAMS_FILE, FILE_READ | FILE_TXT | FILE_ANSI); // If opened successfully if(f != INVALID_HANDLE) { FileReadString(f); // Ignore data column headers // For all further file strings while(!FileIsEnding(f)) { // Read the string and extract the part containing the strategy inputs string s = CSVStringGet(FileReadString(f), 10, 21); // Add this part to the array of strategy parameter sets APPEND(p_params, s); } FileClose(f); return ArraySize(p_params); } } return 0; }
Por lo tanto, si este código se ejecuta en un agente de pruebas remoto, obtendrá ya un archivo con un nombre fijo de la instancia principal del EA que ha iniciado la optimización en la carpeta de datos. Para que esto suceda, deberemos añadir una llamada a esta función de carga al manejador de eventos OnTesterInit().
En el propio manejador, estableceremos los valores de los rangos de enumeración de los índices de los conjuntos de parámetros para no tener que establecerlos manualmente en la ventana de configuración de parámetros de optimización. Si necesitamos emparejar un grupo de menos de 8 conjuntos, aquí también desactivaremos automáticamente el sobreajuste de índices innecesarios.
//+------------------------------------------------------------------+ //| Initialization before optimization | //+------------------------------------------------------------------+ int OnTesterInit(void) { // Load strategy parameter sets int totalParams = LoadParams(fileName_, params); // If nothing is loaded, report an error if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_FAILED); } // Set scale_ to 1 ParameterSetRange("scale_", false, 1, 1, 1, 2); // Set the ranges of change for the parameters of the set index iteration for(int i = 0; i < 8; i++) { if(i < count_) { ParameterSetRange("i" + (string) i + "_", true, 0, 0, 1, totalParams - 1); } else { // Disable the enumeration for extra indices ParameterSetRange("i" + (string) i + "_", false, 0, 0, 1, totalParams - 1); } } return(INIT_SUCCEEDED); }
Como criterio de optimización elegiremos el máximo beneficio que se podría obtener con una reducción máxima del 10% del balance fijo inicial. Para ello, añadiremos al asesor experto el manejador OnTester() en el que calcularemos el valor de este indicador:
//+------------------------------------------------------------------+ //| Test results | //+------------------------------------------------------------------+ double OnTester(void) { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = fixedBalance_ * 0.1 / balanceDrawdown; // Recalculate the profit double fittedProfit = profit * coeff; return fittedProfit; }
Gracias al cálculo de este indicador, recibiremos información sobre cuánto beneficio se puede obtener en una pasada, si tenemos en cuenta la reducción máxima alcanzada en esta pasada, fijando el multiplicador de escala para que pueda alcanzar el 10%.
En el manejador de inicialización OnInit() del asesor experto, también deberemos cargar primero los conjuntos de parámetros de la estrategia. A continuación, tomaremos los índices de los parámetros de entrada y comprobaremos que no haya ninguno repetido entre ellos. Si no es así, la pasada con estos parámetros de entrada no se iniciará. Si todo está bien, entonces sacaremos los conjuntos con los índices especificados del array de conjuntos de parámetros de las estrategias y los añadiremos al asesor experto.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Load strategy parameter sets int totalParams = LoadParams(fileName_, params); // If nothing is loaded, report an error if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_PARAMETERS_INCORRECT); } // Form the string from the parameter set indices separated by commas string strIndexes = (string) i0_ + "," + (string) i1_ + "," + (string) i2_ + "," + (string) i3_ + "," + (string) i4_ + "," + (string) i5_ + "," + (string) i6_ + "," + (string) i7_; // Turn the string into the array string indexes[]; StringSplit(strIndexes, ',', indexes); // Leave only the specified number of instances in it ArrayResize(indexes, count_); // Multiplicity for parameter set indices CHashSet<string> setIndexes; // Add all indices to the multiplicity FOREACH(indexes, setIndexes.Add(indexes[i])); // Report an error if if(count_ < 1 || count_ > 8 // number of instances not in the range 1 .. 8 || setIndexes.Count() != count_ // not all indexes are unique ) { return INIT_PARAMETERS_INCORRECT; } // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Create an EA handling virtual positions expert = new CVirtualAdvisor(magic_, "SimpleVolumes_OptGroup"); // Create and fill the array of all strategy instances CVirtualStrategy *strategies[]; FOREACH(indexes, APPEND(strategies, new CSimpleVolumesStrategy(params[StringToInteger(indexes[i])]))); // Create and add selected groups of strategies to the EA expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
También necesitaremos añadir al menos un manejador vacío OnTesterDeinit() a este EA. Este es un requerimiento del compilador para los asesores expertos que tienen el manejador OnTesterInit().
Luego guardaremos el código obtenido en el archivo OptGroupExpert.mq5 en la carpeta actual.
Combinación simple
Comenzaremos la optimización del asesor experto escrito especificando la ruta al archivo CSV creado con los conjuntos de parámetros de la estrategia comercial. Utilizaremos un algoritmo genético que maximice el criterio del usuario, que será el beneficio normalizado por una reducción del 10%. Usaremos el mismo periodo de prueba para la optimización: de 2018 a 2022, ambos inclusive.
Un bloque estándar de optimización genética de más de 10 000 ejecuciones ha tardado aproximadamente 9 horas utilizando 13 agentes de prueba en la red local. Y, por extraño que parezca, los resultados han superado al conjunto básico. Este será el aspecto de la parte superior de la tabla con los resultados de la optimización:
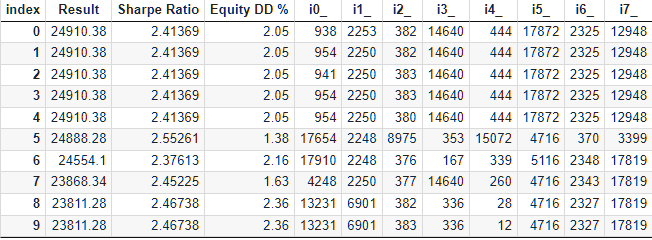
Fig. 6. Tabla con los resultados de la optimización de la selección automatizada al grupo
Veamos los mejores resultados con más detalle. Para obtener el beneficio calculado tendremos que establecer un parámetro scale_ igual a la relación entre la reducción especificada del 10% ($1 000 de $10 000) y la reducción máxima alcanzada en los fondos, además de especificar todos los índices de la primera fila de la tabla. En la tabla lo indicaremos en tanto por ciento, pero para un cálculo más preciso será mejor tomar su valor absoluto en lugar del relativo.
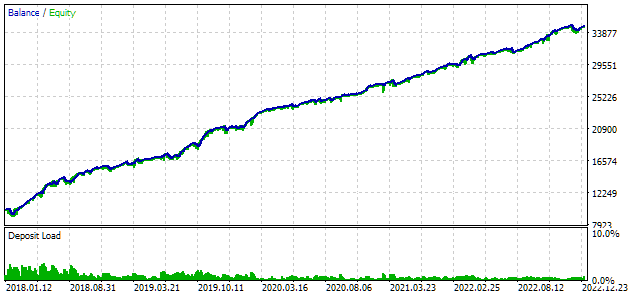
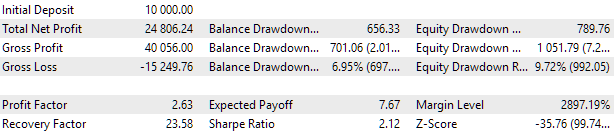
Fig. 7. Resultados de las pruebas del mejor grupo
Los resultados del beneficio difieren ligeramente de los resultados calculados, pero esta diferencia es muy insignificante y puede despreciarse. No obstante, podemos ver que la selección automatizada ha sido capaz de encontrar un grupo mejor que el que seleccionamos manualmente: el beneficio ha sido de 24 800 $ en lugar de 15 200 $, más de un 50% superior. En este proceso, no ha sido necesaria la intervención humana. Y esto ya es un resultado muy alentador. Podemos suspirar y seguir trabajando en esta dirección con más entusiasmo.
A ver si podemos mejorar algo en el proceso de selección sin hacer mucho esfuerzo. En la tabla con los resultados de la selección de estrategias en grupos, salta a la vista que los cinco primeros grupos tienen el mismo resultado: la única diferencia entre ellos es uno o dos índices de los conjuntos de parámetros. Esto es consecuencia de que en nuestro archivo original de conjuntos de parámetros de estrategias, había algunos que también daban el mismo resultado pero diferían entre sí en algún parámetro menos significativo. Por lo tanto, si en dos grupos entran dos conjuntos diferentes que den los mismos resultados, entonces esos dos grupos podrán dar los mismos resultados.
Esto también significa que varios conjuntos "idénticos" de parámetros estratégicos pueden incluirse en el mismo grupo durante la optimización. Y esto provocará a una menor diversidad en el grupo, que es lo que pretendemos para reducir las reducciones. Vamos a intentar librarnos de algún modo de las pasadas de optimización en las que tales conjuntos "idénticos" entren en el grupo.
Combinación con clusterización
Para deshacernos de estos grupos, dividiremos todos los conjuntos de parámetros de estrategias del archivo CSV original en varios grupos. Cada clúster contendrá conjuntos de parámetros que ofrecen resultados completamente iguales o similares. Para la clusterización, usaremos el algoritmo de clusterización de k-medias. Como datos de entrada para la clusterización tomaremos las siguientes columnas: signalPeriod_, signalDeviation_, signaAddlDeviation_, openDistance_, stopLevel_, takeLevel_. Intentaremos dividir todos nuestros conjuntos de parámetros en 64 clústeres utilizando este código Python:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df.to_csv('Params_SV_EURGBP_H1-with_cluster.csv', index=False)
Ahora se ha añadido a nuestro archivo de parámetros otra columna con el número de clúster. Para utilizar este archivo, crearemos un nuevo asesor experto basado en OptGroupExpert.mq5 y haremos pequeñas adiciones al mismo.
Asimismo, añadiremos un conjunto más y, al ejecutar la inicialización, lo rellenaremos con los números de clúster en los que han entrado los conjuntos de parámetros seleccionados. Realizaremos una pasada de este tipo solo si los números de todos los clústeres de este grupo de conjuntos de parámetros resultan ser diferentes. Como las líneas leídas del archivo contendrán ahora un número de clúster al final que no resultará relevante para los parámetros de la estrategia, necesitaremos eliminarlo de la cadena de parámetros antes de transmitirlo al constructor de la estrategia.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ... // Multiplicities for parameter and cluster set indices CHashSet<string> setIndexes; CHashSet<string> setClusters; // Add all indices and clusters to the multiplicities FOREACH(indexes, { setIndexes.Add(indexes[i]); string cluster = CSVStringGet(params[StringToInteger(indexes[i])], 11, 12); setClusters.Add(cluster); }); // Report an error if if(count_ < 1 || count_ > 8 // number of instances not in the range 1 .. 8 || setIndexes.Count() != count_ // not all indexes are unique || setClusters.Count() != count_ // not all clusters are unique ) { return INIT_PARAMETERS_INCORRECT; } ... FOREACH(indexes, { // Remove the cluster number from the parameter set string string param = CSVStringGet(params[StringToInteger(indexes[i])], 0, 11); // Add a strategy with a set of parameters with a given index APPEND(strategies, new CSimpleVolumesStrategy(param)) }); // Form and add a group of strategies to the EA expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
Vamos a guardar este código en el archivo OptGroupClusterExpert.mq5 en la carpeta actual.
Este dispositivo de optimización también ha desvelado sus deficiencias. Si en un algoritmo genético se incluyen en la población inicial demasiados individuos con al menos dos índices de conjuntos de parámetros iguales, se producirá una rápida degeneración de la población y una parada prematura del algoritmo de optimización. Pero en otra ejecución podríamos tener mejor suerte, y entonces la optimización llegaría al final y encontraría resultados razonablemente buenos.
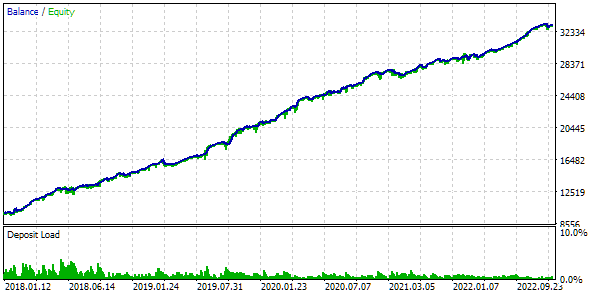
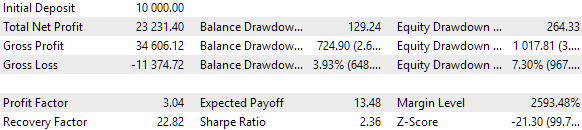
Fig. 8. Resultados de la prueba del mejor grupo con clusterización
La probabilidad de evitar la degeneración de la población podrá aumentarse mezclando los conjuntos de parámetros de entrada o reduciendo el número de estrategias incluidas en el grupo. En cualquier caso, el tiempo dedicado a la optimización se reducirá entre una vez y media y dos veces en comparación con la optimización sin clusterización.
Una instancia en el clúster
Existe otra forma de evitar la degeneración de la población: dejar en el archivo solo un conjunto perteneciente a un clúster determinado. Podremos generar un archivo con estos datos utilizando este código Python:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df = df.sort_values(['cluster', 'Sharpe Ratio']).groupby('cluster').agg('last').reset_index()
clusters = df.cluster
df = df.iloc[:, 1:]
df['cluster'] = clusters
df.to_csv('Params_SV_EURGBP_H1-one_cluster.csv', index=False
Para este archivo de datos CSV podremos utilizar cualquiera de los dos asesores expertos escritos en este artículo durante la optimización.
Si resulta que nos quedan pocos conjuntos, será posible aumentar el número de clústeres o tomar varios conjuntos de un clúster a la vez.
Veamos los resultados de la optimización de este EA:
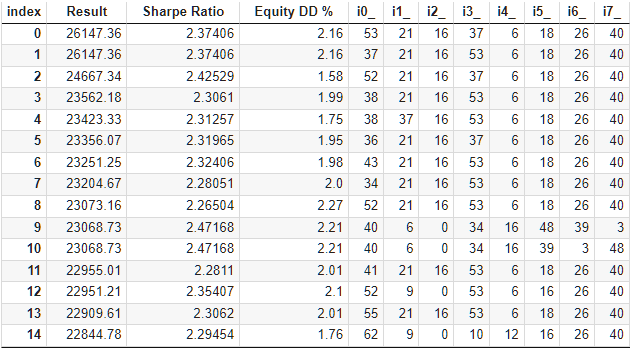
Fig. 9. Tabla con los resultados de la optimización de la selección automatizada de grupos por 64 clústeres
Son más o menos los mismos que para los dos enfoques anteriores. Hemos encontrado un grupo que supera a todos los encontrados anteriormente. Aunque es más una cuestión de suerte que de superioridad de la limitación del conjunto. Estos son los resultados del grupo de cabeza:
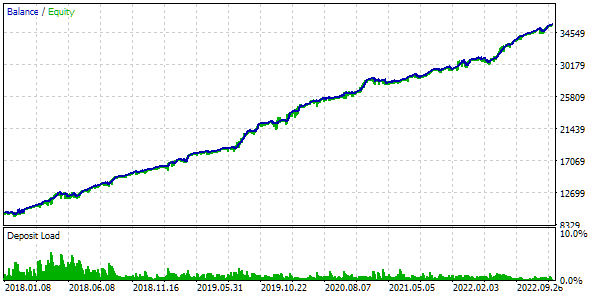
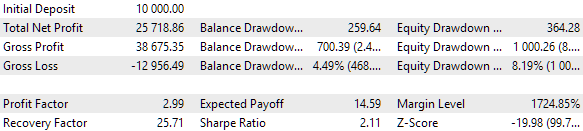
Fig. 10. Resultados de la prueba del mejor grupo con un conjunto en el clúster
En la tabla de resultados, existe una notable repetición de grupos que solo difieren en el orden de los índices de los conjuntos de parámetros de estrategias.
Esto podrá evitarse añadiendo a los asesores expertos una comprobación sobre la condición de que la combinación de índices en los parámetros de entrada debe formar una secuencia creciente. Pero esto vuelve a plantear problemas con el uso de la optimización genética debido a la rápida degeneración de la población. Y para lograr una enumeración completa, incluso una selección de 64 conjuntos de un grupo de 8 conjuntos dará demasiadas pasadas. Más bien deberemos cambiar la forma de convertir los parámetros de entrada del asesor experto en índices de conjuntos de parámetros de estrategias. Pero eso es una nota para el futuro.
Por otra parte, en los primeros minutos de la optimización se obtienen resultados comparables a los de la selección manual (~15.000 dólares de beneficio) cuando se utiliza un conjunto a la vez de un clúster. Para obtener los mejores resultados, deberemos esperar hasta casi el final de la optimización.
Conclusión
Veamos qué tenemos. Hoy hemos confirmado que la selección automática de conjuntos de parámetros en un grupo puede ofrecer mejores resultados de rentabilidad que la selección manual. Claro que el propio proceso llevará más tiempo, pero ese tiempo no requerirá de intervención humana, lo cual es muy positivo. Además, de ser necesario, podremos reducirlo significativamente cambiándolo por el uso de más agentes de simulación.
Ahora podemos seguir adelante. Si tenemos la capacidad de seleccionar grupos de instancias de estrategias, también podremos pensar en automatizar la composición de grupos a partir de grupos resultantes que sean buenos. Desde el punto de vista del código del asesor experto, la única diferencia residirá en cómo leer los parámetros correctamente y añadir no uno, sino varios grupos de estrategias al asesor experto. Aquí podremos pensar en un formato unificado para almacenar conjuntos de parámetros optimizables para estrategias y grupos en una base de datos en lugar de en archivos separados.
También estaría bien ver el comportamiento de nuestros grupos buenos en un periodo de prueba fuera del periodo en el que se ha realizado la optimización de parámetros. Supongo que eso intentaremos hacer en el próximo artículo.
Gracias por su atención, ¡hasta la próxima!
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14478
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Victor, ¡gracias por tu comentario!
Yo tampoco conozco ninguna función especial en Excel, lo hago así:
Gracias Yuri.
Pero escribiste sobre agregar las columnas Profit,Expected Payoff,Profit Factor,Recovery Factor,Sharpe Ratio,Equity DD %,Trades, con _s. ¿En qué orden debo añadirlas para que funcione? ¿Cada columna después de la columna original o se pueden añadir todas al final de la tabla? Podrías hacer una captura de pantalla de los nombres de las columnas como lo haces desde tu tabla ya editada, o simplemente adjuntar un pequeño archivo ya editado para muestra.
Además, cuando optimizas el Asesor Experto, ¿pones un criterio complejo o sólo equilibras el máximo? Lo he probado y tengo algo no muy grande número de operaciones en los pasajes encuentra, alrededor de 100-180 operaciones durante 5 años.
Y por favor dígame, si me gustaría que su EA para leer la señal y las operaciones abiertas en la apertura de una nueva barra en un marco de tiempo determinado, pero acompañado oficios cada tick como funciona ahora. ¿Dónde puedo añadir la función de comprobación de la nueva barra para trabajar de esta manera?
El orden de adición sólo importa en términos de cómo hacerlo más rápido. Para mí fue más rápido añadir estas columnas al final de la tabla (columnas AC:AI), luego calcular las desviaciones en varias columnas nuevas (AJ : AP), luego sumar AJ:AP en AQ, luego encontrar el factor de escala máximo Escala en AR, y calcular la relación Res = AR/AQ en AS. Para ordenarlo, tienes que copiar sólo los valores de AS a una nueva columna AT. He adjuntado un ejemplo.
Empiezo la optimización con el criterio complejo y luego con todos los demás criterios. El número de operaciones puede ser diferente, incluso relativamente pequeño. Depende del tamaño de los niveles SL y TP.
En el proximo articulo pienso contarles sobre la funcion de verificar una nueva barra y como se puede aplicar alli.
En el próximo artículo tengo la intención de decirle acerca de la función de comprobación de una nueva barra y cómo se puede aplicar allí.
Yuri, gracias por la tabla de ejemplo, entiendo que es del último artículo (7), también será útil, pero te pedí un ejemplo de la tabla de este artículo (6), que alimenta a la entrada de la OptGroupClusterExpert.mq5 Asesor Experto. Según tengo entendido esta tabla se llama Params_SV_EURGBP_H1-with_cluster.csv y Params_SV_EURGBP_H1.csv. Eso es lo que le he pedido. Por favor, adjunta estas tablas como ejemplo.
¡Sobre el próximo artículo genial! Esperemos:) Si sería bueno añadir a la estrategia de la posibilidad de filtro de tiempo para cada estrategia (especificar las horas de inicio y final del período de negociación) y algunos filtros en los indicadores (2-3 piezas). entonces creo que sería un gran EA para el comercio de todo el mercado :).
Victor, efectivamente, me he adelantado un poco con el ejemplo de la tabla anterior.
He adjuntado un ejemplo para Params_SV_EURGBP_H1.xlsx, ya que el archivo CSV ya no contendrá fórmulas. Tendrá que guardarlo en CSV, y si Excel utiliza ';' como delimitador, tendrá que sustituir ';' por ',' en todo el archivo CSV. El archivo Params_SV_EURGBP_H1-with_cluster .csv se obtiene automáticamente utilizando el código Python de Params_SV_EURGBP_H1.csv que figura en el artículo.
En cuanto a añadir filtros temporales e indicadores adicionales: la arquitectura utilizada lo permite - se pueden crear nuevas clases de estrategias de trading (sucesoras de CVirtualStrategy) con los filtros e indicadores que se deseen. No tengo previsto utilizar filtros de tiempo para mí, ya que nunca he conseguido mejorar los resultados de las operaciones introduciendo restricciones temporales. No planeo utilizar muchos indicadores en una estrategia, porque un fuerte filtrado de las señales de entrada es menos importante para mí. Se puede obtener indirectamente mediante la combinación de varias instancias de estrategias que utilizan un indicador diferente cada uno, por ejemplo.
Se ha publicado el nuevo artículo Desarrollo de operaciones de EA multidivisa (Parte 6): Selección automática de grupos de instancias:
Por Yuriy Bykov