
多通貨エキスパートアドバイザーの開発(第19回):Pythonで実装されたステージの作成
はじめに
単一インスタンスのトレーディング戦略の中から、良好なグループを自動的に選定する方法については、かなり前(第6回)に検討しました。その当時は、すべてのテスト結果を蓄積するためのデータベースはまだ存在しておらず、代わりにCSVファイルを使用していました。その記事の主な目的は、優れたグループを自動で選定することで、手動による選定よりも良好な結果が得られるという仮説を検証することでした。
その目的は達成され、仮説も確認されました。次に、こうした自動選定の結果をどのようにさらに改善できるかを考察しました。その結果、すべての単一インスタンスを比較的少数のクラスタに分け、同じクラスタ内のインスタンスが最終的なグループに同時に含まれないようにすることで、最終的なEAの取引成績を向上させるだけでなく、グループ選定にかかる時間も短縮できることが分かりました。
クラスタリングには、Pythonの既製ライブラリであるscikit-learnのK-Meansアルゴリズムの実装を使用しました。これは唯一のクラスタリング手法ではありませんが、他のアルゴリズムを検討・比較してこの問題に最適なものを選ぶという作業は、現実的な範囲を超えていたため、手に入りやすいこのアルゴリズムを採用しました。その結果はかなり良好でした。
しかし、この実装を使うためには、小さなPythonプログラムを実行する必要がありました。操作の大部分を手動でおこなっていた当時は、これはそれほど面倒ではありませんでした。しかし今では、テストおよび戦略インスタンスのグループ選定のプロセス全体をかなり自動化しているため、連続的に実行される最適化タスクの中で、たとえ単純なものであっても手動操作が入るのは望ましくありません。
この問題を解決するには、2つの方法があります。ひとつは、MQL5で記述されたクラスタリングアルゴリズムの既製の実装を探すか、自分で実装する方法です。もうひとつは、最適化の自動化ステージの任意の段階で、MQL5で書かれたEAだけでなく、Pythonプログラムも実行できるようにすることです。
検討した結果、私は後者を選択しました。それでは、その実装に取りかかりましょう。
パスの設計
それでは、MQL5プログラムからPythonアプリケーションを実行する方法を見ていきましょう。最も明白な方法は次のとおりです。
- 直接起動:実行ファイルをパラメータ付きで起動できるOSの機能を使います。ここでの実行ファイルはPythonインタプリタであり、パラメータとしてはプログラムファイル名および起動パラメータを指定します。この方法の欠点は、DLLからの外部関数を使用する必要がある点ですが、すでにストラテジーテスターを起動する際にそれらを使用しているため、大きな問題ではありません。
- WebRequest経由での起動必要なAPIを備えた簡易Webサーバーを構築し、MQL5プログラムからのWebRequest呼び出しによってリクエストを受け取った際に、必要なPythonプログラムを実行させるという方法です。Webサーバーの構築には、たとえばFlaskや他の任意のフレームワークを使用できます。この方法の欠点は、単純な課題に対して仕組みが複雑すぎることです。
魅力的ではあるものの、2番目の方法の実装は今後に取っておきましょう。他の関連機能の実装が必要になったときに改めて取り組みます。最終的には、自動最適化の全体プロセスを管理するための完全なWebインターフェイスを作成することもできるでしょう。現在のOptimization.ex5 EAをMQL5サービスとして機能させることが可能です。端末とともに起動されるこのサービスは、データベース内で「Queued(保留中)」のステータスを持つプロジェクトを監視し、該当するプロジェクトが見つかれば、それに対応するすべての最適化タスクを順次実行します。しかし今のところは、より単純な最初の実行方法を実装することにします。
次に考えるべきは、クラスタリングの結果をどう保存するかという点です。第6回では、最適化パスの結果を格納したテーブルに、新たな列としてクラスタ番号を追加していました。今回も同様の手法で、passesテーブルに新しい列を追加し、そこにクラスタ番号を格納することは可能です。しかし、すべての最適化ステージがクラスタリングを必要とするわけではありません。そのため、多くの行に空の値が入ってしまう可能性があります。これはあまり良い方法とは言えません。
この問題を回避するために、新しいテーブルを作成し、そこにパスIDとそれに対応するクラスタ番号だけを保存するようにしましょう。そして、最適化の第2ステージ開始時に、この新しいテーブルからのデータをパスID(id_pass)で結合してpassesテーブルに取り込み、クラスタリングの結果を反映させます。
自動最適化の実行手順に基づくと、クラスタリングは第1ステージと第2ステージの間に実行されるべきです。混乱を避けるために、従来どおり「第1ステージ」「第2ステージ」という名前をそのまま使い、今回新たに追加するステージは「第1ステージの結果のクラスタリングステージ」と呼ぶことにします。
以下のタスクを実行する必要があります。
- Pythonで実装されたステップを実行できるように、Optimization.mq5 EAを修正する
- 必要なパラメータを受け取り、データベースからパス情報を読み込み、クラスタリングを実行し、その結果をデータベースに保存するPythonスクリプトを作成する
- データベースに、3つのステージと、それぞれのステージに対するジョブを、異なる通貨ペアや時間枠ごとに作成し、各ジョブに対して、1つ以上の最適化基準を指定した最適化タスクを登録する
- 自動最適化を実行し、結果を評価する
修正
今回は、致命的なエラーは検出されなかったため、自動最適化の結果として得られる最終的なEAには直接影響しないものの、最適化ステージの妥当性や、最適化フレームワーク外で実行された単一パスの結果の追跡を妨げる不正確な点の修正に集中します。
まずは、タスク(task)の開始日および終了日を設定するためのトリガーを追加することから始めましょう。これまでは、これらの日付は、ストラテジーテスターで最適化を開始・停止する直前と直後に、Optimization.mq5 EAから実行されるSQLクエリによって変更されていました。
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void StartTask(ulong taskId, string setting) { ... // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing', " " start_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); } //+------------------------------------------------------------------+ //| Task completion | //+------------------------------------------------------------------+ void FinishTask(ulong taskId) { PrintFormat(__FUNCTION__" | Task ID = %d", taskId); // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Done', " " finish_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); }
トリガーのロジックはシンプルです。tasksテーブル内のタスクのステータスがProcessing(処理中)に変更された場合、開始日(start_date)を現在の時刻に設定します。ステータスがDone(完了)に変更された場合は、終了日(finish_date)を現在の時刻に設定します。そしてステータスがQueued(キューに追加済み)に変更された場合には、開始日と終了日をクリアします。なお、最後に挙げたステータス変更(Queuedへの変更)は、EAからではなく、tasksテーブル内のstatusフィールドの値を手動で変更することで実行されます。
これらのトリガーの実装は次のようになります。
CREATE TRIGGER IF NOT EXISTS upd_task_start_date AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Processing' BEGIN UPDATE tasks SET start_date= DATETIME('NOW') WHERE id_task=NEW.id_task; END; CREATE TRIGGER IF NOT EXISTS upd_task_finish_date AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Done' BEGIN UPDATE tasks SET finish_date= DATETIME('NOW') WHERE id_task=NEW.id_task; END; CREATE TRIGGER IF NOT EXISTS reset_task_dates AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Queued' BEGIN UPDATE tasks SET start_date= NULL, finish_date=NULL WHERE id_task=NEW.id_task; END;
このようなトリガーを作成した後、EAからstart_dateとfinish_dateの変更を削除し、ステータスの変更のみを残すことができます。
もう1つの小さな、しかし厄介なバグとして、新しいデータベースに移行した後にストラテジーテスターで手動で単一のパスを実行すると、現在の最適化タスクのID値がデフォルトで0になってしまうという問題がありました。この状態でid_task = 0の値を持つエントリをpassesテーブルに挿入しようとすると、外部キー制約のチェック時にエラーが発生する可能性があります。もしid_task = 0 のタスクが特別に追加されていれば問題はありませんが、追加を忘れているとエラーになります。
したがって、この問題を回避するために、projectsテーブルに新しいエントリが作成されたときに実行されるトリガーを追加しましょう。新しいプロジェクトを作成したら、単一パス用のステージ、ジョブ、タスクが自動的に作成される必要があります。このトリガーの実装は次のようになります。
CREATE TRIGGER IF NOT EXISTS insert_empty_stage AFTER INSERT ON projects BEGIN INSERT INTO stages ( id_project, name, optimization, status ) VALUES ( NEW.id_project, 'Single tester pass', 0, 'Done' ); END; DROP TRIGGER IF EXISTS insert_empty_job; CREATE TRIGGER IF NOT EXISTS insert_empty_job AFTER INSERT ON stages WHEN NEW.name = 'Single tester pass' BEGIN INSERT INTO jobs VALUES ( NULL, NEW.id_stage, NULL, NULL, NULL, 'Done' ); INSERT INTO tasks ( id_job, optimization_criterion, status ) VALUES ( (SELECT id_job FROM jobs WHERE id_stage=NEW.id_stage), -1, 'Done' ); END;
もう1つの不正確な点として、ストラテジーテスターで単一パスを手動で実行した場合に、passesテーブル(具体的にはpass_dateフィールド)に保存されるのが実行時の現在時刻ではなくテスト区間の終了時刻になってしまうという問題がありました。これは、EA内のSQLクエリで時間を設定する際に、TimeCurrent関数を使用しているためです。しかし、テストモードではこの関数は実際の現在時刻ではなく、シミュレーション中の時刻を返します。そのため、たとえばテスト区間が2022年末で終わる場合、そのパスはpassesテーブルに2022年末の時刻として保存されてしまいます。
では、なぜ最適化中に実行されるすべてのパスについては、passesテーブルに正しい「実際の現在時刻」が保存されているのでしょうか。その理由は、意外にも単純でした。最適化処理中のパス結果を保存するSQLクエリは、テスター上で動作しているEAインスタンスではなく、「データ収集モード」でターミナルのチャート上で動作しているEAインスタンスによって実行されているためです。そして、チャート上で実行されているEAはテストモードではないため、TimeCurrent関数は実際の(シミュレートされていない)現在時刻を返します。
この問題を修正するために、passesテーブルに新しいエントリが挿入された後に実行されるトリガーを追加し、pass_dateを現在の日付に自動更新するようにします。
CREATE TRIGGER IF NOT EXISTS upd_pass_date
AFTER INSERT
ON passes
BEGIN
UPDATE passes
SET pass_date = DATETIME('NOW')
WHERE id_pass = NEW.id_pass;
END;
EAからpassesテーブルに新しい行を追加するSQLクエリにおいて、EAが計算した現在時刻の代わりにNULLを直接渡すように変更しました。これにより、pass_dateはトリガー側で自動的に現在時刻に設定されるようになります。
また、いくつかの既存クラスに対して、いくつかの小さな追加と修正をおこないました。CVirtualOrderクラスには、有効期限を変更するためのメソッド、および仮想オーダーの配列の中にトリガーされたオーダーがあるかどうかをチェックする静的メソッドを追加しました。これらのメソッドは現時点ではまだ使用されていませんが、他の取引戦略で役立つ可能性があります。
CFactorableクラスでは、ReadNumberメソッドの動作を修正しました。以前は、初期化文字列の終端に達しても、最後に読み取られた数値を繰り返し返していましたが、これをNULLを返すように変更しました。この修正により、リスクマネージャーの初期化文字列では、必要なパラメータの数(6ではなく13)を正確に指定する必要があります。
// Prepare the initialization string for the risk manager string riskManagerParams = StringFormat( "class CVirtualRiskManager(\n" " 0,0,0,0,0,0,0,0,0,0,0,0,0" " )", 0 );
CDatabaseデータベース処理クラスに、新しい静的メソッドを追加しました。このメソッドは、指定したデータベースに切り替えるために使用します。基本的には、このメソッドの内部で、指定された名前と場所のデータベースに接続し、すぐに接続を閉じるだけの処理をおこないます。
static void Test(string p_fileName = NULL, int p_common = DATABASE_OPEN_COMMON) { Connect(p_fileName, p_common); Close(); };
このメソッドを一度呼び出した後は、引数なしでConnectメソッドを呼び出しても、必要なデータベースに接続されるようになります。
これで、本質的ではないものの必要な準備が整いましたので、いよいよ本題の実装に進みましょう。
Optimization.mq5のリファクタリング
まず最初に、Optimization.mq5EAに変更を加える必要があります。このEA内では、stagesテーブルに登録されている起動ファイル名(expertフィールド)をチェックする処理を追加する必要があります。もしその名前が「.py」で終わっていれば、そのステージではPythonプログラムを実行するということになります。Pythonプログラムを呼び出すために必要なパラメータは、jobsテーブルのtester_inputsフィールドに格納しておくことができます。
しかし、これだけでは不十分です。Pythonプログラムには、使用するデータベース名や現在のタスクIDなどの情報も何らかの方法で渡す必要があります。また、Pythonプログラムの起動そのものも行わなければなりません。これらの追加により、EAのコード量が大幅に増加することになりますが、もともとこのEAのコードはすでにかなり大きくなっています。そこで、まずは既存のプログラムコードを複数のファイルに分割して整理することから始めましょう。
Optimization.mq5 EAのメインファイルには、タイマーの生成と、主な処理を担当する新しいクラスCOptimizerの作成だけを残します。私たちがおこなうべきことは、Processハンドラ内でこのクラスのタイマー処理メソッドを呼び出し、EAの初期化・終了時にこのオブジェクトを正しく作成/削除するようにすることだけです。
sinput string fileName_ = "database911.sqlite"; // - File with the main database sinput string pythonPath_ = "C:\\Python\\Python312\\python.exe"; // - Path to Python interpreter COptimizer *optimizer; // Pointer to the optimizer object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Connect to the main database DB::Test(fileName_); // Create an optimizer optimizer = new COptimizer(pythonPath_); // Create the timer and start its handler EventSetTimer(20); OnTimer(); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert timer function | //+------------------------------------------------------------------+ void OnTimer() { // Start the optimizer handling optimizer.Process(); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { EventKillTimer(); // Remove the optimizer if(!!optimizer) { delete optimizer; } }
オプティマイザーオブジェクトを作成する際には、コンストラクタに1つのパラメータを渡します。それは、EAが実行されるコンピュータ上にあるPythonインタプリタの実行ファイルへのフルパスです。このパラメータの値は、EAの入力変数pythonPath_EAに指定します。将来的には、このパラメータを不要にして、オプティマイザークラス内でインタプリタを自動検索する機能を実装することも可能ですが、今のところはこのシンプルな方法にとどめておきます。
現在のフォルダに、Optimization.mq5ファイルの変更内容を保存します。
オプティマイザークラス
それでは、COptimizerクラスを作成しましょう。publicメソッドとしては、メインの処理用メソッドProcessと、コンストラクタのみを持たせます。privateセクションには、実行キュー内のタスク数を取得するメソッドとキュー内の次のタスクのIDを取得するメソッドを追加します。特定の最適化タスクに関連する処理はすべて、もう一段下のレベルに移動します。そのために、新しいクラスCOptimizerTask(最適化タスク)を作成し、その中に実装を移します。そして、COptimizer内部ではこのクラスのオブジェクトを1つだけ保持する構成とします。
//+------------------------------------------------------------------+ //| Class for the project auto optimization manager | //+------------------------------------------------------------------+ class COptimizer { // Current optimization task COptimizerTask m_task; // Get the number of tasks with a given status in the queue int TotalTasks(string status = "Queued"); // Get the ID of the next optimization task from the queue ulong GetNextTaskId(); public: COptimizer(string p_pythonPath = NULL); // Constructor void Process(); // Main processing method };
TotalTasksメソッドとGetNextTaskIdメソッドのコードは、以前のバージョンのOptimization.mq5 EAにあった対応する関数から、ほとんど変更せずに流用しました。Processメソッドについても、元々はOnTimer関数にあったコードを移植したものですが、新しく最適化タスク用のクラスを導入したため、こちらはより大きな変更が必要になりました。それでも、全体としてこのメソッドのコードはより明確で読みやすくなりました。
//+------------------------------------------------------------------+ //| Main handling method | //+------------------------------------------------------------------+ void COptimizer::Process() { PrintFormat(__FUNCTION__" | Current Task ID = %d", m_task.Id()); // If the EA is stopped, remove the timer and the EA itself from the chart if (IsStopped()) { EventKillTimer(); ExpertRemove(); return; } // If the current task is completed, if (m_task.IsDone()) { // If the current task is not empty, if(m_task.Id()) { // Complete the current task m_task.Finish(); } // Get the number of tasks in the queue int totalTasks = TotalTasks("Processing") + TotalTasks("Queued"); // If there are tasks, then if(totalTasks) { // Get the ID of the next current task ulong taskId = GetNextTaskId(); // Load the optimization task parameters from the database m_task.Load(taskId); // Launch the current task m_task.Start(); // Display the number of remaining tasks and the current task on the chart Comment(StringFormat( "Total tasks in queue: %d\n" "Current Task ID: %d", totalTasks, m_task.Id())); } else { // If there are no tasks, remove the EA from the chart PrintFormat(__FUNCTION__" | Finish.", 0); ExpertRemove(); } } }
ご覧の通り、この抽象化レベルでは、次に実行すべきタスクがテスター内でのEAの最適化であろうとPythonプログラムの実行であろうと、違いはありません。処理の流れは同じです。タスクキューにタスクがある限り、次のタスクのパラメータを読み込み、実行を開始し、完了まで待機します。完了後は、タスクキューが空になるまでこれを繰り返します。
現在のフォルダに、COptimizer.mqhファイルの変更内容を保存します。
最適化タスククラス
最も興味深い点がCOptimizerTaskクラスの実装です。このクラス内で、Pythonインタプリタを直接起動し、実行するPythonプログラムを渡す処理がおこなわれます。そのため、このクラスのファイルの冒頭で、ファイルを実行するためのシステム関数をインポートします。
// Function to launch an executable file in the operating system #import "shell32.dll" int ShellExecuteW(int hwnd, string lpOperation, string lpFile, string lpParameters, string lpDirectory, int nShowCmd); #import
クラス内部には、最適化タスクに必要なパラメータを格納するための複数のフィールドを持たせます。たとえば、タスクの種類、ID、EA名、最適化期間、銘柄、時間軸などです。
//+------------------------------------------------------------------+ //| Optimization task class | //+------------------------------------------------------------------+ class COptimizerTask { enum { TASK_TYPE_UNKNOWN, TASK_TYPE_EX5, TASK_TYPE_PY } m_type; // Task type (MQL5 or Python) ulong m_id; // Task ID string m_setting; // String for initializing the EA parameters for the current task string m_pythonPath; // Full path to the Python interpreter // Data structure for reading a single string of a query result struct params { string expert; int optimization; string from_date; string to_date; int forward_mode; string forward_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } m_params; // Get the full or relative path to a given file in the current folder string GetProgramPath(string name, bool rel = true); // Get initialization string from task parameters void Parse(); // Get task type from task parameters void ParseType(); public: // Constructor COptimizerTask() : m_id(0) {} // Task ID ulong Id() { return m_id; } // Set the full path to the Python interpreter void PythonPath(string p_pythonPath) { m_pythonPath = p_pythonPath; } // Main method void Process(); // Load task parameters from the database void Load(ulong p_id); // Start the task void Start(); // Complete the task void Finish(); // Task completed? bool IsDone(); };
データベースからLoadメソッドで直接取得するパラメータの部分は、m_params構造体に格納します。この値をもとに、ファイル名の末尾をチェックするParseTypeメソッドでタスクの種類を判別します。
//+------------------------------------------------------------------+ //| Get task type from task parameters | //+------------------------------------------------------------------+ void COptimizerTask::ParseType() { string ext = StringSubstr(m_params.expert, StringLen(m_params.expert) - 3); if(ext == ".py") { m_type = TASK_TYPE_PY; } else if (ext == "ex5") { m_type = TASK_TYPE_EX5; } else { m_type = TASK_TYPE_UNKNOWN; } }
また、Parseメソッドを使って、テストの初期化やPythonプログラムの実行に使う文字列を生成します。この文字列は、タスクの種類に応じて、ストラテジーテスター用のパラメータ文字列か、Pythonプログラム実行用のパラメータ文字列のいずれかを形成します。
//+------------------------------------------------------------------+ //| Get initialization string from task parameters | //+------------------------------------------------------------------+ void COptimizerTask::Parse() { // Get the task type from the task parameters ParseType(); // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Generate a parameter string for the tester m_setting = StringFormat( "[Tester]\r\n" "Expert=%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=%d\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=%d\r\n" "ForwardDate=%s\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d\r\n" "fileName_=%s\r\n" "%s\r\n", GetProgramPath(m_params.expert), m_params.symbol, m_params.period, m_params.optimization, m_params.from_date, m_params.to_date, m_params.forward_mode, m_params.forward_date, m_params.optimization_criterion, m_params.id_task, DB::FileName(), m_params.tester_inputs ); // If this is a task to launch a Python program } else if (m_type == TASK_TYPE_PY) { // Form a program launch string on Python with parameters m_setting = StringFormat("\"%s\" \"%s\" %I64u %s", GetProgramPath(m_params.expert, false), // Python program file DB::FileName(true), // Path to the database file m_id, // Task ID m_params.tester_inputs // Launch parameters ); } }
Startメソッドは、タスクの実行開始を担当します。このメソッド内で再びタスクの種類を判別し、それに応じて、ストラテジーテスターでの最適化を実行するか、ShellExecuteWシステム関数を呼び出してPythonプログラムを実行します。
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void COptimizerTask::Start() { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", m_id, m_setting); // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Launch a new optimization task in the tester MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(m_setting); MTTESTER::ClickStart(); // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing' " " WHERE id_task=%d", m_id); DB::Execute(query); DB::Close(); // If this is a task to launch a Python program } else if (m_type == TASK_TYPE_PY) { PrintFormat(__FUNCTION__" | SHELL EXEC: %s", m_pythonPath); // Call the system function to launch the program with parameters ShellExecuteW(NULL, NULL, m_pythonPath, m_setting, NULL, 1); } }
タスクの実行状況の確認は、ストラテジーテスターの状態がstopped(停止)であるかどうかを確認するか、現在のタスクIDを使って、データベース内のタスクの状態をチェックするかのどちらかです。
//+------------------------------------------------------------------+ //| Task completed? | //+------------------------------------------------------------------+ bool COptimizerTask::IsDone() { // If there is no current task, then everything is done if(m_id == 0) { return true; } // Result bool res = false; // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Check if the strategy tester has finished its work res = MTTESTER::IsReady(); // If this is a task to run a Python program, then } else if(m_type == TASK_TYPE_PY) { // Request to get the status of the current task string query = StringFormat("SELECT status " " FROM tasks" " WHERE id_task=%I64u;", m_id); // Open the database if(DB::Connect()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string status; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { // Check if the status is Done res = (row.status == "Done"); } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } } else { res = true; } return res; }
現在のフォルダに、COptimizerTask.mqhファイルの変更内容を保存します。
クラスタリングプログラム
さて、いよいよ何度も触れてきたあのPythonプログラムの登場です。基本的には、そのメインの処理部分はすでに第6回で開発済みです。内容を見ていきましょう。
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df = df.sort_values(['cluster', 'Sharpe Ratio']).groupby('cluster').agg('last').reset_index()
clusters = df.cluster
df = df.iloc[:, 1:]
df['cluster'] = clusters
df.to_csv('Params_SV_EURGBP_H1-one_cluster.csv', index=False
以下の点を変更する必要があります。
- コマンドライン引数で補足パラメータ(データベース名、タスクID、クラスタ数など)を渡せるようにする
- CSVファイルの代わりにpassesテーブルから情報を取得する
- タスク実行の開始・終了状態をデータベースに設定する処理を追加する
- passesテーブルに各EA入力パラメータの個別カラムがないため、クラスタリングに使うフィールド構成を変更する
- 最終テーブルのフィールド数を減らす(本質的にはクラスタ番号とパスIDの関係だけ分かればよいため)
- 結果を別ファイルに保存するのではなく、新しいデータベースのテーブルに保存する
これらすべてを実現するために、追加でargparseモジュールとsplite3モジュールをインポートします。
import pandas as pd
from sklearn.cluster import KMeans
import sqlite3
import argparse
ArgumentParserクラスのオブジェクトは、コマンドライン引数で渡された入力を解析するために使用します。読み取った値は、後で使いやすいように個別の変数に保存します。
# Setting up the command line argument parser parser = argparse.ArgumentParser(description='Clustering passes for previous job(s)') parser.add_argument('db_path', type=str, help='Path to database file') parser.add_argument('id_task', type=int, help='ID of current task') parser.add_argument('--id_parent_job', type=str, help='ID of parent job(s)') parser.add_argument('--n_clusters', type=int, default=256, help='Number of clusters') parser.add_argument('--min_custom_ontester', type=float, default=0, help='Min value for `custom_ontester`') parser.add_argument('--min_trades', type=float, default=40, help='Min value for `trades`') parser.add_argument('--min_sharpe_ratio', type=float, default=0.7, help='Min value for `sharpe_ratio`') # Read the values of command line arguments into variables args = parser.parse_args() db_path = args.db_path id_task = args.id_task id_parent_job = args.id_parent_job n_clusters = args.n_clusters min_custom_ontester = args.min_custom_ontester min_trades = args.min_trades min_sharpe_ratio = args.min_sharpe_ratio
次に、データベースに接続し、現在のタスクを「実行中」とマークします。また、クラスタリング結果を保存するための新しいテーブルがまだなければ作成します。このタスクが再度実行される場合は、以前に保存された結果をクリアする処理も行う必要があります。
# Establishing a connection to the database
connection = sqlite3.connect(db_path)
cursor = connection.cursor()
# Mark the start of the task
cursor.execute(f'''UPDATE tasks SET status='Processing' WHERE id_task={id_task};''')
connection.commit()
# Create a table for clustering results if there is none
cursor.execute('''CREATE TABLE IF NOT EXISTS passes_clusters (
id_task INTEGER,
id_pass INTEGER,
cluster INTEGER
);''')
# Clear the results table from previously obtained results
cursor.execute(f'''DELETE FROM passes_clusters WHERE id_task={id_task};''')
続いて、必要な最適化パスのデータを取得するためのSQLクエリを作成し、データベースから直接データフレームに読み込みます。
# Load data about parent job passes for this task into the dataframe
query = f'''SELECT p.*
FROM passes p
JOIN
tasks t ON t.id_task = p.id_task
JOIN
jobs j ON j.id_job = t.id_job
WHERE p.profit > 0 AND
j.id_job IN ({id_parent_job}) AND
p.custom_ontester >= {min_custom_ontester} AND
p.trades >= {min_trades} AND
p.sharpe_ratio >= {min_sharpe_ratio};'''
df = pd.read_sql(query, connection)
# Let's look at the dataframe
print(df)
# List of dataframe columns
print(*enumerate(df.columns), sep='\n')
データフレームの列の一覧を確認した上で、クラスタリングに使用するいくつかの列を選択します。取引戦略インスタンスの入力パラメータ用の個別列がないため、クラスタリングはパスの各種統計結果(利益、取引回数、ドローダウン、プロフィットファクターなど)を用いておこないます。選択された列の番号はメソッドパラメータiloc[]として指定します。クラスタリング後は、データフレームの行を各クラスタごとにグループ化し、正規化された平均年利の値が最も高いクラスタの行だけを残します。
# Run clustering on some columns of the dataframe kmeans = KMeans(n_clusters=n_clusters, n_init='auto', random_state=42).fit(df.iloc[:, [7, 8, 9, 24, 29, 30, 31, 32, 33, 36, 45, 46]]) # Add cluster numbers to the dataframe df['cluster'] = kmeans.labels_ # Set the current task ID df['id_task'] = id_task # Sort the dataframe by clusters and normalized profit df = df.sort_values(['cluster', 'custom_ontester']) # Let's look at the dataframe print(df) # Group the lines by cluster and take one line at a time # with the highest normalized profit from each cluster df = df.groupby('cluster').agg('last').reset_index()
その後、結果を保存するテーブル用に、データフレームにはid_task、id_pass、clusterの3つの列だけを残します。id_taskは、同じタスクIDでプログラムを再実行した際に、以前のクラスタリング結果を削除できるように残してあります。
# Let's leave only id_task, id_pass and cluster columns in the dataframe df = df.iloc[:, [2, 1, 0]] # Let's look at the dataframe print(df)
データフレームを既存のテーブルにデータを追加するモードで保存し、タスクの完了をマークしてから、データベースへの接続を閉じます。
# Save the dataframe to the passes_clusters table (replacing the existing one)
df.to_sql('passes_clusters', connection, if_exists='append', index=False)
# Mark the task completion
cursor.execute(f'''UPDATE tasks SET status='Done' WHERE id_task={id_task};''')
connection.commit()
# Close the connection
connection.close()
現在のフォルダに、ClusteringStage1.pyファイルの変更内容を保存します。
第2ステージEA
第1ステージの最適化結果をクラスタリングするプログラムができたので、あとはその結果を第2ステージのEAで活用できるように実装するだけです。なるべく手間をかけずにおこないましょう。
以前は別のEAを使っていましたが、今回は事前クラスタリングをおこなわない場合も、クラスタリング結果を使う場合も、同じEAで第2ステージを実行できるようにします。そのために、useClusters_という論理パラメータを追加します。このパラメータは、第1ステージで得られた取引戦略の単一インスタンス群からグループを選択する際に、クラスタリング結果を使用するかどうかを制御します。
クラスタリング結果を使う場合は、単一インスタンスのリストを取得するSQLクエリに、passes_clustersテーブルをパスIDで結合するだけで済みます。これにより、クエリ結果として各クラスタから1つのパスのみが得られます。
さらに、EAの入力パラメータとして、正規化された平均年利、取引回数、シャープレシオによるパス選択の追加条件を設定できるよう、いくつかのパラメータを追加します。
あとは、入力パラメータリストとCreateTaskDB関数の修正をおこなうだけです。
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput int idTask_ = 0; // - Optimization task ID sinput string fileName_ = "db.sqlite"; // - Main database file input group "::: Selection for the group" input int idParentJob_ = 1; // - Parent job ID input bool useClusters_ = true; // - Use clustering input double minCustomOntester_ = 0; // - Min normalized profit input int minTrades_ = 40; // - Min number of trades input double minSharpeRatio_ = 0.7; // - Min Sharpe ratio input int count_ = 16; // - Number of strategies in the group (1 .. 16) ... //+------------------------------------------------------------------+ //| Creating a database for a separate stage task | //+------------------------------------------------------------------+ void CreateTaskDB(const string fileName, const int idParentJob) { // Create a new database for the current optimization task DB::Connect(PARAMS_FILE, 0); DB::Execute("DROP TABLE IF EXISTS passes;"); DB::Execute("CREATE TABLE passes (id_pass INTEGER PRIMARY KEY AUTOINCREMENT, params TEXT);"); DB::Close(); // Connect to the main database DB::Connect(fileName); // Clustering string clusterJoin = ""; if(useClusters_) { clusterJoin = "JOIN passes_clusters pc ON pc.id_pass = p.id_pass"; } // Request to obtain the required information from the main database string query = StringFormat("SELECT DISTINCT p.params" " FROM passes p" " JOIN " " tasks t ON p.id_task = t.id_task " " JOIN " " jobs j ON t.id_job = j.id_job " " %s " "WHERE (j.id_job = %d AND " " p.custom_ontester >= %.2f AND " " trades >= %d AND " " p.sharpe_ratio >= %.2f) " "ORDER BY p.custom_ontester DESC;", clusterJoin, idParentJob_, minCustomOntester_, minTrades_, minSharpeRatio_); // Execute the request ... }
現在のフォルダに、SimpleVolumesStage2.mq5ファイルの変更内容を保存します。
テスト
プロジェクトのために、データベース内に「First」、「Clustering passes from first stage」、「Second」、「Second with clustering」の4つのステージを作成しましょう。各ステージについて、EURGBPとGBPUSDの2つの通貨ペア、時間軸はH1で、それぞれ2つのジョブを作成します。第一ステージでは、異なる条件(複合基準、最大利益、カスタム)で3つの最適化タスクを作成します。残りのジョブでは、それぞれ1つのタスクを作成します。最適化期間は2018年から2023年までとし、各ジョブには正しい入力値を設定します。
その結果、以下のクエリから得られるような情報がデータベースに登録されているはずです。
SELECT t.id_task,
t.optimization_criterion,
s.name AS stage_name,
s.expert AS stage_expert,
j.id_job,
j.symbol AS job_symbol,
j.period AS job_period,
j.tester_inputs AS job_tester_inputs
FROM tasks t
JOIN
jobs j ON j.id_job = t.id_job
JOIN
stages s ON s.id_stage = j.id_stage
WHERE t.id_task > 0;
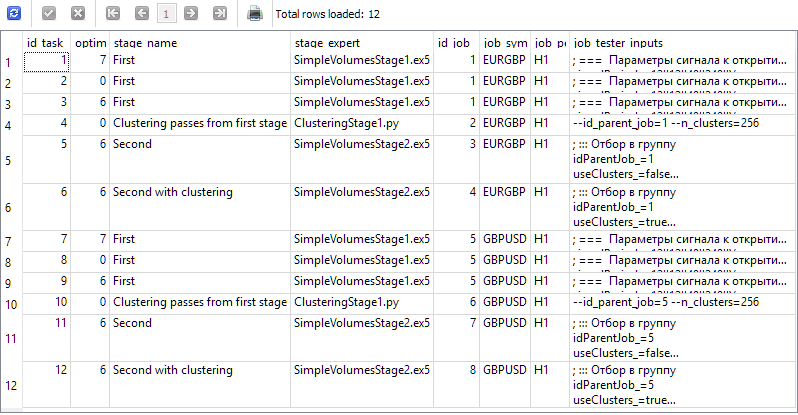
端末のチャート上でOptimization.ex5 EAを起動し、すべてのタスクが完了するのを待ちます。今回の計算量では、33のエージェントで全ステージを完了するのに約17時間かかりました。
EURGBPについては、クラスタリングをおこなわなかった場合とクラスタリングを使用した場合で、正規化された平均年利はほぼ同じで、約USD 4060でした。しかし、GBPUSDでは、最適化の第2ステージの実行方法によって、結果により明確な差が見られました。クラスタリングなしでは正規化平均年利はUSD 4500、クラスタリングを使った場合はUSD 7500でした。
この2つの銘柄で結果の差が大きいのは少し奇妙に感じるかもしれませんが、十分起こり得ることです。こうした差の原因を今すぐ深掘りするのではなく、今後より多くの銘柄や時間軸を使った自動最適化を行うときに改めて検討することにします。
以下が、両銘柄で得られた「ベストグループ」の結果です。
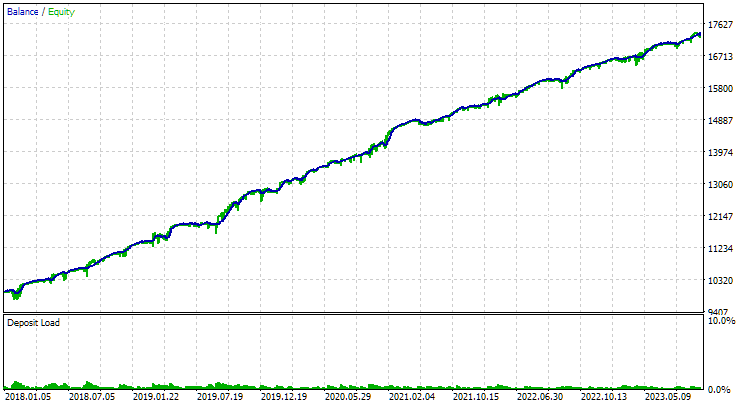
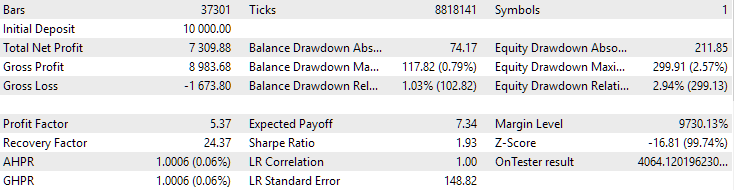
図1:EURGBP H1における、クラスタリングを用いた第2ステージのベストグループの結果
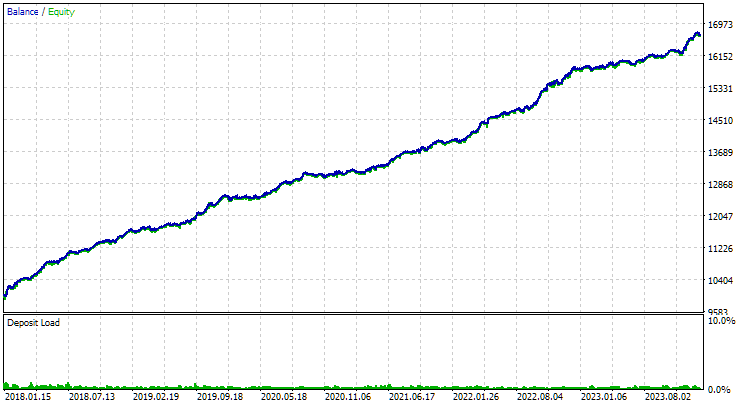
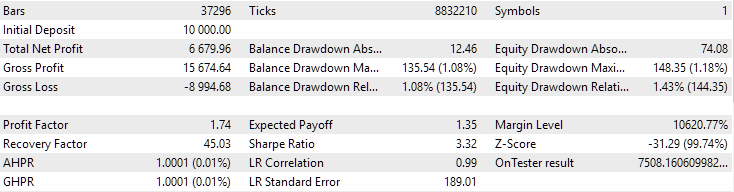
図2:GBPUSD H1における、クラスタリングを用いた第2ステージのベストグループの結果
もうひとつ興味深い疑問を提起したいと思います。私たちはクラスタリングをおこない、各クラスタから最も優れた単一インスタンス(テスターパス)を1つずつ取り出しています。このようにして「良好な候補のリスト」が形成され、その中から最適なグループを第二段階で選定するわけです。たとえば、256クラスタでクラスタリングした場合、このリストには256個のインスタンスが含まれます。そして第2ステージの最適化では、その256の中から16個のインスタンスを選んでグループ化しています。第2ステージをスキップして、単に「正規化された平均年利」が最も高い16個のインスタンスを異なるクラスタから直接選ぶだけではいけないのでしょうか。
もしこれが可能であれば、自動最適化にかかる時間を大幅に短縮できます。というのも、第2ステージの最適化では、第1ステージで最適化されていたものを16個同時に組み込んだEAを走らせるため、1回のテスト実行にかかる時間がその分長くなるからです。
本記事で扱った最適化課題のセットにおいても、約6時間の短縮が可能だったはずです。これは、全体で17時間かかった中のかなりの割合を占めます。さらに、今回は比較のために「クラスタリングなしの第2ステージ最適化タスク」を2つ追加しているため、それらを省けば相対的な時間削減効果はより大きくなります。
この疑問に答えるため、第2ステージが始まる前の時点で選ばれる単一インスタンスのリストを取得するクエリ結果を見てみましょう。分かりやすくするために、第2ステージでのインスタンスのインデックス、第1ステージでのインスタンスのパスID、クラスタ番号、正規化された平均年利の値以下の情報を列に追加します。すると、以下のようになります。
SELECT DISTINCT ROW_NUMBER() OVER (ORDER BY custom_ontester DESC) AS [index], p.id_pass, pc.cluster, p.custom_ontester, p.params FROM passes p JOIN tasks t ON p.id_task = t.id_task JOIN jobs j ON t.id_job = j.id_job JOIN passes_clusters pc ON pc.id_pass = p.id_pass WHERE (j.id_job = 5 AND p.custom_ontester >= 0 AND trades >= 40 AND p.sharpe_ratio >= 0.7) ORDER BY p.custom_ontester DESC;
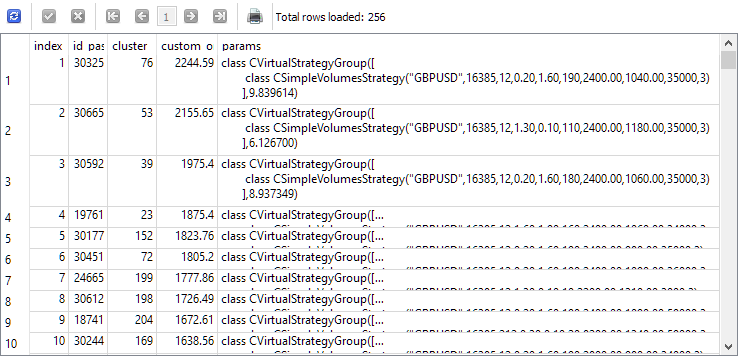
ご覧の通り、正規化された平均年利が最も高い単一インスタンスは、インデックスの値が小さいものになっています。したがって、インデックスが1から16のインスタンスをグループとして選べば、第2ステージの最適化によって得られた「ベストグループ」と比較するために意図していたグループを、そのまま得ることができます。
それでは、第2ステージのEAを使用し、インスタンスのインデックスを1〜16に設定して実行してみましょう。すると、次のような結果が得られます。
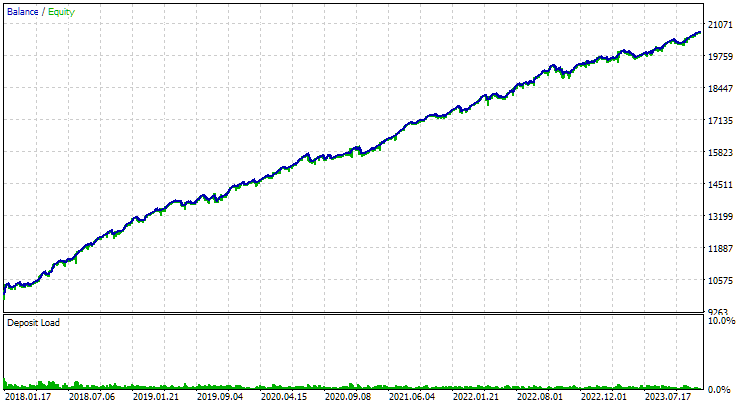
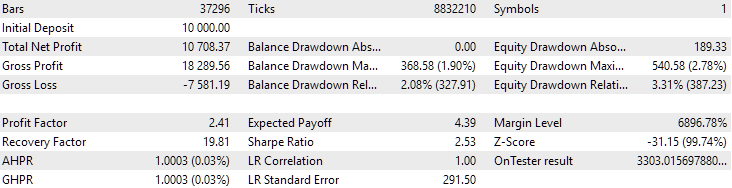
図3:GBPUSD H1における、正規化された平均年利が最も高い上位16個のサンプルの結果
このグラフは図2のグラフと性質は似ていますが、正規化された平均年利の値は半分以下に下がっており、USD 7500 → USD 3300になっています。これは、図2のベストグループと比べて、今回のグループではドローダウンが大きくなっているためです。EURGBPでも同様の傾向が見られ、こちらでは下落幅はやや小さいものの、それでも有意な差が生じています。
つまり、この方法では第2ステージの最適化をスキップして時間を節約することはできなさそうです。
最後に、見つかった2つのベストグループを組み合わせた結果を見てみましょう。
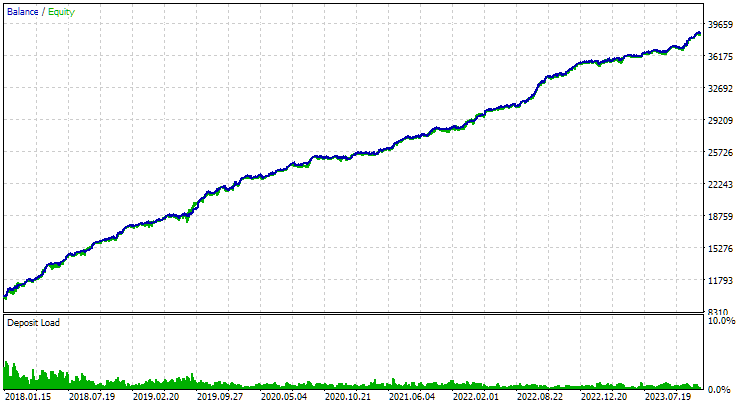
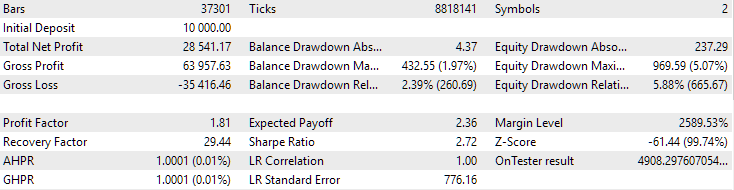
図4:EURGBP H1とGBPUSD H1における、2つのベストグループを組み合わせた運用結果
ご覧の通り、すべてのパラメータは個別グループの値の中間的な水準に収まりました。たとえば、正規化された平均年利はUSD 4900で、これはEURGBP H1グループよりは高いものの、GBPUSD H1グループよりは低い値です。
結論
今回の取り組みで得られた成果を振り返ってみましょう。まず、自動最適化のステップに外部プログラム(今回はPythonプログラム)を実行できる機能を追加しました。これにより、必要であれば他のスクリプト言語やコンパイル済みの外部プログラムも、最小限の追加作業で実行できるようになります。
今回の例では、この新機能を使って、第1ステージの最適化で得られた戦略インスタンスをクラスタリングし、第2ステージで使用する数を絞り込むことを実現しました。クラスタ数を限定し、各クラスタから代表的な1インスタンスのみを選ぶことで、第2ステージにかかる時間をある程度削減することができました。その上、結果の精度は落ちるどころか、むしろ改善される場合もありました。この意味で、今回の作業は無駄ではなかったと言えます。
とはいえ、まだまだ改善の余地はあります。たとえば、クラスタ数がインスタンス数より多い場合にエラーとなる現状の仕様を改善する必要があります。これによってエラーが発生します。また、より多様なトレーディング戦略への対応や、自動最適化プロジェクトの管理をより柔軟かつ便利にする機能も今後の課題として挙げられます。次回その点について詳しく触れます。
ご精読ありがとうございました。またすぐにお会いしましょう。
この記事および連載のこれまでのすべての記事で提示された結果は、過去のテストデータのみに基づいており、将来の利益を保証するものではありません。このプロジェクトでの作業は研究的な性質のものであり、公開された結果はすべて、自己責任で使用されるべきです。
アーカイブ内容
| # | 名前 | バージョン | 詳細 | 最近の変更 |
|---|---|---|---|---|
| MQL5/Experts/Article.15911 | ||||
| 1 | Advisor.mqh | 1.04 | EA基本クラス | 第10回 |
| 2 | ClusteringStage1.py | 1.00 | 最適化の第1ステージの結果をクラスタリングするプログラム | 第19回 |
| 3 | Database.mqh | 1.07 | データベースを扱うクラス | 第19回 |
| 4 | database.sqlite.schema.sql | - | データベース構造 | 第19回 |
| 5 | ExpertHistory.mqh | 1.00 | 取引履歴をファイルにエクスポートするクラス | 第16回 |
| 6 | ExportedGroupsLibrary.mqh | - | 戦略グループ名とその初期化文字列の配列をリストした生成されたファイル | 第17回 |
| 7 | Factorable.mqh | 1.02 | 文字列から作成されたオブジェクトの基本クラス | 第19回 |
| 8 | GroupsLibrary.mqh | 1.01 | 選択された戦略グループのライブラリを操作するためのクラス | 第18回 |
| 9 | HistoryReceiverExpert.mq5 | 1.00 | リスクマネージャーとの取引履歴を再生するためのEA | 第16回 |
| 10 | HistoryStrategy.mqh | 1.00 | 取引履歴を再生するための取引戦略のクラス | 第16回 |
| 11 | Interface.mqh | 1.00 | さまざまなオブジェクトを視覚化するための基本クラス | 第4回 |
| 12 | LibraryExport.mq5 | 1.01 | 選択したパスの初期化文字列をライブラリからExportedGroupsLibrary.mqhファイルに保存するEA | 第18回 |
| 13 | Macros.mqh | 1.02 | 配列操作に便利なマクロ | 第16回 |
| 14 | Money.mqh | 1.01 | 基本的なお金の管理クラス | 第12回 |
| 15 | NewBarEvent.mqh | 1.00 | 特定の銘柄の新しいバーを定義するクラス | 第8回 |
| 16 | Optimization.mq5 | 1.03 | 最適化タスクの起動を管理するEA | 第19回 |
| 17 | Optimizer.mqh | 1.00 | プロジェクト自動最適化マネージャーのクラス | 第19回 |
| 18 | OptimizerTask.mqh | 1.00 | 最適化タスククラス | 第19回 |
| 19 | Receiver.mqh | 1.04 | オープンボリュームを市場ポジションに変換するための基本クラス | 第12回 |
| 20 | SimpleHistoryReceiverExpert.mq5 | 1.00 | 取引履歴を再生するための簡易EA | 第16回 |
| 21 | SimpleVolumesExpert.mq5 | 1.20 | 複数のモデル戦略グループを並列操作するためのEA。パラメータは組み込みのグループライブラリから取得されます。 | 第17回 |
| 22 | SimpleVolumesStage1.mq5 | 1.18 | 取引戦略単一インスタンス最適化EA(第1ステージ) | 第19回 |
| 23 | SimpleVolumesStage2.mq5 | 1.02 | 取引戦略単一インスタンス最適化EA(第2ステージ) | 第19回 |
| 24 | SimpleVolumesStage3.mq5 | 1.01 | 生成された標準化された戦略グループを、指定された名前のグループのライブラリに保存するEA。 | 第18回 |
| 25 | SimpleVolumesStrategy.mqh | 1.09 | ティックボリュームを使用した取引戦略のクラス | 第15回 |
| 26 | Strategy.mqh | 1.04 | 取引戦略基本クラス | 第10回 |
| 27 | TesterHandler.mqh | 1.05 | 最適化イベント処理クラス | 第19回 |
| 28 | VirtualAdvisor.mqh | 1.07 | 仮想ポジション(注文)を扱うEAのクラス | 第18回 |
| 29 | VirtualChartOrder.mqh | 1.01 | グラフィカル仮想位置クラス | 第18回 |
| 30 | VirtualFactory.mqh | 1.04 | オブジェクトファクトリクラス | 第16回 |
| 31 | VirtualHistoryAdvisor.mqh | 1.00 | トレード履歴再生EAクラス | 第16回 |
| 32 | VirtualInterface.mqh | 1.00 | EAGUIクラス | 第4回 |
| 33 | VirtualOrder.mqh | 1.07 | 仮想注文とポジションのクラス | 第19回 |
| 34 | VirtualReceiver.mqh | 1.03 | オープンボリュームを市場ポジションに変換するクラス(レシーバー) | 第12回 |
| 35 | VirtualRiskManager.mqh | 1.02 | リスクマネジメントクラス(リスクマネージャー) | 第15回 |
| 36 | VirtualStrategy.mqh | 1.05 | 仮想ポジションを使った取引戦略のクラス | 第15回 |
| 37 | VirtualStrategyGroup.mqh | 1.00 | 取引戦略グループのクラス | 第11回 |
| 38 | VirtualSymbolReceiver.mqh | 1.00 | 銘柄レシーバークラス | 第3回 |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15911
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
私はこれを実行する
python -u "C:\UsersMohamadreza_NewAppDataRoamingMetaQuotesTerminal4B1CE69F577705455263BD980C39A82CMQL5ExpertsClusteringStage1.py.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\CommonFiles\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
以下のエラーが発生する
ValueError: n_samples=150 should be >= n_clusters=256.
そこで、 n_clusters=150に変更して、次のように実行しました 。
python -u "C: \UsersMohamadreza_NewAppDataRoaming\MetaQuotesTerminalpy" "C: \Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\CommonFiles\database911.sqlite" 4 --id_parent_job=1 --n_clusters=150
で、うまくいったと思う。しかし、データベースには変化がない。
その後、 n_samples=150で 最適化を 試したが、うまくいかなかった
私はこれを実行する
...
うまくいったと思う。しかし、データベースには何の変化もない。
データベースにpass_clusters テーブルがない?
データベースに新しいテーブル passes_clustersが ありませんか?
正常に動作しました。
エラーはデータベースに関連していました。
データベースを修正した後、Pythonコードとステージ2はうまくいきました。
ありがとうございました。
興味深い記事だ!では、シリーズを全部読んでみよう。
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
なぜAlgLibライブラリの機能を捨てたのでしょうか?
#include <Math\Alglib\alglib.mqh>スピードの面ではマイナスだが、パイソンがすべてのコアで計算を並列化するからだ。