
Desarrollamos un asesor experto multidivisa (Parte 11): Comenzamos a automatizar el proceso de optimización
Introducción
En el último artículo, sentamos las bases para usar fácilmente los resultados obtenidos de la optimización en la construcción de un EA listo para usar con múltiples instancias de estrategias comerciales trabajando juntas. Ahora no tendremos que escribir manualmente los parámetros de todas las instancias que usamos en el código o en las variables de entrada del EA. Bastará con guardar la cadena de inicialización en un determinado formato en un archivo, o insertarla como texto en el código fuente para que el asesor experto la utilice.
Hasta ahora, la formación de la cadena de inicialización se ha hecho de forma manual. Ahora, finalmente, ha llegado el momento de poner en marcha el proceso de formación automática de la cadena de inicialización del EA partiendo de los resultados de optimización obtenidos. Resulta más que posible que no logremos aún una solución totalmente automatizada en el ámbito de este artículo, pero al menos deberíamos avanzar significativamente en la dirección prevista.
Planteamiento de la tarea
En términos generales, nuestros deseos pueden formularse de la forma siguiente: queremos un asesor experto que se ejecute en el terminal y realice la optimización del EA con una única instancia de estrategia comercial en varios símbolos y marcos temporales. Vamos a suponer que usaremos los símbolos EURGBP, EURUSD, GBPUSD y los marcos temporales H1, M30, M15. Entre los resultados de cada pasada de optimización almacenados en la base de datos, necesitaremos poder seleccionar aquellos que se aplicarán a un símbolo y un marco temporal concretos (y más adelante a algunas otras combinaciones de parámetros de prueba).
De cada grupo de resultados para la misma combinación de símbolo y marco temporal, seleccionaremos algunos de los mejores según diferentes criterios. Luego pondremos todas las instancias seleccionadas en un (por ahora) grupo de instancias. A continuación, deberemos determinar el multiplicador del grupo. Esto lo gestionará un EA independiente en el futuro, pero ahora podemos hacerlo manualmente.
Basándonos en el grupo y el multiplicador seleccionados, formaremos la cadena de inicialización que se utilizará en el EA final.
Conceptos
Ahora introduciremos algunos conceptos adicionales para su futuro uso:
- Asesor experto universal — asesor experto al que le transmitiremos la cadena de inicialización, tras lo cual estará listo para trabajar en una cuenta comercial. Podemos hacer que lea la cadena de inicialización de un archivo con el nombre especificado en los parámetros de entrada, o la obtenga de la base de datos según el nombre del proyecto y la versión.
- Asesor experto optimizador — asesor experto que se encargará de realizar todas las actividades de optimización del proyecto. Al ejecutarlo en un gráfico, encontrará información en la base de datos sobre las acciones de optimización necesarias y las ejecutará de forma coherente. El resultado final de su trabajo será una cadena de inicialización guardada para el asesor experto universal.
- Asesores expertos de etapa — asesores expertos que se optimizarán directamente en el simulador. Habrá varios, según el número de etapas implementadas. El EA optimizador ejecutará estos asesores expertos para su optimización y supervisará su finalización.
En el marco de este artículo, nos limitaremos a una etapa: optimizaremos los parámetros de una única instancia de estrategia comercial. La segunda etapa (la combinación de varias de las mejores instancias en un grupo y su normalización) la realizaremos manualmente por ahora.
Por el momento, crearemos un EA que pueda construir la cadena de inicialización por sí mismo seleccionando información sobre las instancias de estrategias comerciales adecuadas de una base de datos.
La información sobre las acciones de optimización necesarias deberá almacenarse en la base de datos de forma práctica. Deberíamos poder crear este tipo de información con relativa facilidad. Por ahora, dejaremos de lado la cuestión sobre cómo llegará esta información a la base de datos. Más adelante podremos implantar una interfaz fácil de usar. Lo principal ahora es comprender la estructura de esta información y crear la estructura de tablas correspondiente para ella en la base de datos.
Empezaremos destacando las entidades más generales y descenderemos gradualmente a entidades cada vez más simples. Al final, deberíamos llegar a la entidad creada anteriormente que representa la información de una pasada única del simulador.
Proyecto
En el nivel superior, tendremos la entidad "Proyecto". Será de una entidad compuesta: el proyecto constará de varias etapas. Más adelante hablaremos de la entidad "Etapa". El proyecto se caracterizará por su nombre y versión. También podrá tener alguna descripción. Un proyecto podrá encontrarse en varios estados: "creado", "en cola de inicio", "iniciado" y "finalizado". También en esta entidad sería lógico almacenar la cadena de inicialización del asesor experto universal obtenida tras la ejecución del proyecto.
Para facilitar el uso de la información de la base de datos en los programas MQL5, implementaremos un ORM sencillo, es decir, crearemos clases MQL5 que representarán todas las entidades que almacenaremos en la base de datos.
Los objetos de clase para la entidad "Proyecto" tendrán lo siguiente almacenado en la base de datos:
- id_project – identificador del proyecto.
- name – nombre del proyecto, se utilizará en el asesor experto universal para encontrar la cadena inicializadora.
- version – versión del proyecto, estará determinada, por ejemplo, por las versiones de las instancias de estrategia comercial.
- description – descripción del proyecto; se trata de un texto arbitrario que contendrá algunos detalles importantes sobre el proyecto. Podría estar vacío.
- params – cadena de inicialización para el asesor experto universal; se rellenará al finalizar este proyecto. Inicialmente tendrá un valor vacío.
- status – estado (state) del proyecto; podrá tomar cuatro valores posibles: Created, Queued, Processing, Done. Inicialmente se creará un proyecto con el estado Created.
Esta lista de campos podría ampliarse en el futuro, pero por ahora será suficiente.
Cuando un proyecto esté listo para iniciarse, pasará al estado Queued. De momento, este cambio se realizará manualmente. Nuestro asesor de optimización buscará proyectos con este estado y los trasladará al estado Processing.
Al principio y al final de cada etapa, comprobaremos si es necesario actualizar el estado del proyecto. Si se inicia la primera etapa, el proyecto entrará en el estado Processing. Cuando se complete la última etapa, el proyecto pasará al estado Done. En este punto, se rellenará el valor del campo params, es decir, una vez finalizado el proyecto, obtendremos una cadena de inicialización que se podrá transmitir al asesor experto universal.
Etapa
Como ya hemos dicho, la ejecución de cada proyecto se dividirá en varias etapas. La característica principal de la etapa será un asesor experto que se ejecutará dentro de esta etapa para su optimización en el simulador (asesor experto de la etapa). También se establecerá el intervalo de prueba de la etapa. Este intervalo será el mismo para todas las optimizaciones realizadas en esta etapa. También contemplaremos el almacenamiento de otra información sobre la optimización (depósito inicial, modo de simulación de ticks, etc.).
Una etapa podría tener especificada una etapa padre (anterior). En este caso, la ejecución de la etapa solo se iniciará una vez finalizada la etapa padre.
Los objetos de esta clase almacenarán lo siguiente en la base de datos:
- id_stage – identificador de la etapa.
- id_project – identificador del proyecto al que pertenece esta etapa.
- id_parent_stage – identificador de la etapa padre (anterior).
- name – nombre de la etapa.
- expert – nombre del asesor experto que se iniciará para la optimización en esta etapa.
- from_date – fecha de inicio del periodo de optimización.
- to_date – fecha final del periodo de optimización.
- forward_date – fecha de inicio del periodo forward de optimización. Podría estar vacío, en cuyo caso no se utilizará el modo forward.
- otros campos con parámetros de optimización (depósito inicial, modo de simulación de ticks, etc.); contendrán los valores por defecto que no tendremos que modificar en la mayoría de los casos
- status - estatus (estado) de la etapa, puede tomar tres valores posibles: Queued, Processing, Done. Inicialmente, se creará una etapa con el estado Queued.
Cada etapa, a su vez, constará de una o varias actividades. Al iniciarse el primer trabajo, la etapa pasará al estado Processing. Cuando todo el trabajo se haya completado, la etapa entrará en el estado Done.
Funcionamiento
La ejecución de cada etapa consiste en la ejecución secuencial de todas las actividades que la componen. Las principales características del trabajo serán el símbolo, el marco temporal y los parámetros de entrada del EA, que se optimizará en la etapa que contiene este trabajo.
Los objetos de esta clase almacenarán lo siguiente en la base de datos:
- id_job – identificador del trabajo.
- id_stage – identificador de la etapa a la que pertenece este trabajo.
- symbol – símbolo (instrumento comercial) de la prueba.
- period – marco temporal de prueba.
- tester_inputs – configuración de los parámetros de entrada del asesor experto para la optimización.
- status – estado (state) del trabajo, puede tomar tres valores posibles: Queued, Processing, Done. Inicialmente, se creará un trabajo con el estado Queued.
Cada trabajo constará de uno o varios problemas de optimización. Al iniciarse la primera tarea de optimización, el trabajo pasará al estado Processing. Cuando se completen todas las tareas de optimización, el trabajo pasará al estado Done.
Tarea de optimización
La ejecución de cada trabajo consistirá en completar secuencialmente todas las tareas incluidas en él. La principal característica de la tarea será el criterio de optimización. El resto de la configuración de la tarea del simulador se heredará del trabajo.
Los objetos de este tipo tendrán este tipo almacenado en la base de datos:
- id_task – identificador de la tarea.
- id_job – identificador del trabajo dentro del cual se realiza esta tarea.
- optimisation_criterion – criterio de optimización para esta tarea.
- start_date – hora de inicio de la ejecución de la tarea de optimización.
- finish_date – hora a la que finalizará la tarea de optimización.
- status – estatus (estado) de la tarea de optimización; podría tomar tres valores posibles: Queued, Processing, Done. Inicialmente, se creará una tarea de optimización con el estado Queued.
Cada tarea constará de varias pasadas de optimización. Cuando se inicie la primera pasada de optimización, la tarea de optimización pasará al estado Processing. Cuando se completen todas las pasadas de optimización, la tarea de optimización pasará al estado Done.
Pasada de optimización
Ya nos hemos familiarizado con ellas en el artículo anterior, en el que añadimos el guardado automático de los resultados de todas las pasadas al optimizar en el simulador de estrategias. Ahora añadiremos un nuevo campo a la entidad, "Pasada de Optimización", que contendrá el identificador de la tarea dentro de la cual se ha realizado esta pasada.
Así, los objetos de este tipo tendrán almacenado en la base de datos lo siguiente:
- id_pass –- identificador de la pasada.
- id_task – identificador de la tarea dentro de la cual se ejecuta esta pasada.
- campos de resultado de las pasadas – grupo de campos para todas las estadísticas de pasadas disponibles (número de pasadas, número de transacciones, factor de beneficio, etc.).
- params – cadena de inicialización con los parámetros de las instancias de estrategias utilizadas en esta pasada.
- inputs – valores de los parámetros de entrada de la pasada.
- pass_date. Fecha y hora de la pasada.
En comparación con la implementación anterior, cambiaremos la composición de la información almacenada sobre los parámetros de las estrategias utilizadas en cada pasada. En el caso más general, necesitaremos almacenar información sobre un grupo de estrategias. Por lo tanto, haremos que también para una estrategia se conserve el grupo de estrategias que la incluye.
Una pasada no tendrá un campo de estado, porque los registros de esta tabla se añadirán solo después de que se realice la pasada, no antes de que comience. Por lo tanto, la mera presencia de un registro ya significará que esta pasada está completa.
Como nuestra base de datos ya ha enriquecido notablemente su estructura, vamos a realizar cambios en el código del programa responsable de crear y trabajar con la base de datos.
Creación de la base de datos y trabajo con la misma
Durante el proceso de desarrollo, tendremos que volver a crear la base de datos varias veces con la estructura actualizada. Así que crearemos un simple script auxiliar que realizará una sola acción: la creación de una nueva base de datos y su rellenado con los datos iniciales necesarios. Más adelante veremos cuáles son exactamente los datos iniciales con los que hay que llenar una base de datos vacía.
#include "Database.mqh" int OnStart() { DB::Open(); // Open the database // Execute requests for table creation and filling initial data DB::Create(); DB::Close(); // Close the database return INIT_SUCCEEDED; }
Guardaremos este código en el archivo CleanDatabase.mq5 de la carpeta actual.
El método de creación de tablas CDatabase::Create() contenía anteriormente un array de filas con consultas SQL que realizaban una única recreación de la tabla. Ahora tendremos más tablas, por lo que será incómodo almacenar las consultas SQL directamente en el código fuente. Le propongo sacar el texto de todas las consultas SQL a un archivo separado, desde el cual serán cargadas para su ejecución dentro del método Create().
Para ello, necesitaremos un método que, según nombre de archivo, lea todas las solicitudes del archivo y las ejecute:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { ... public: ... // Make a request to the database from the file static bool ExecuteFile(string p_fileName); }; ... //+------------------------------------------------------------------+ //| Making a request to the database from the file | //+------------------------------------------------------------------+ bool CDatabase::ExecuteFile(string p_fileName) { // Array for reading characters from the file uchar bytes[]; // Number of characters read long len = 0; // If the file exists in the data folder, then if(FileIsExist(p_fileName)) { // load it from there len = FileLoad(p_fileName, bytes); } else if(FileIsExist(p_fileName, FILE_COMMON)) { // otherwise, if it is in the common data folder, load it from there len = FileLoad(p_fileName, bytes, FILE_COMMON); } else { PrintFormat(__FUNCTION__" | ERROR: File %s is not exists", p_fileName); } // If the file has been loaded, then if(len > 0) { // Convert the array to a query string string query = CharArrayToString(bytes); // Return the query execution result return Execute(query); } return false; }
Ahora vamos a introducir algunos cambios en el método Create(). Vamos a ponernos de acuerdo en que el archivo con el esquema de la base de datos y los datos iniciales tendrá un nombre fijo: la cadena ".schema.sql" se añadirá al nombre de la base de datos:
//+------------------------------------------------------------------+ //| Create an empty DB | //+------------------------------------------------------------------+ void CDatabase::Create() { string schemaFileName = s_fileName + ".schema.sql"; bool res = ExecuteFile(schemaFileName); if(res) { PrintFormat(__FUNCTION__" | Database successfully created from %s", schemaFileName); } }
Ahora podremos utilizar cualquier entorno de base de datos SQLite para crear todas las tablas en él y poblarlas con los datos iniciales. Después de eso, podremos exportar la base de datos obtenida como un conjunto de consultas SQL a un archivo y utilizar este archivo en nuestros programas MQL5.
El último cambio que tendremos que hacer en esta etapa a la clase CDatabase será la necesidad de realizar consultas no solo para insertar datos, sino también para recuperar datos de las tablas. Además, todo el código responsable de recuperar los datos deberá distribuirse en clases separadas que trabajen con entidades individuales almacenadas en la base de datos. Pero hasta que tengamos esas clases, nos conformaremos con medidas temporales.
La lectura de datos usando los medios ofrecidos por MQL5 es una tarea más compleja que la inserción. Para obtener las filas de los resultados de la consulta, tendremos que crear un nuevo tipo de datos (estructura) en MQL5, diseñado para obtener los datos para esta consulta en particular. A continuación, deberemos enviar la consulta y obtener el mango resultado. Este manejador se podrá utilizar en un ciclo para obtener una línea de los resultados de la consulta en la variable de la estructura creada anteriormente.
Así que dentro de la clase CDababase, la escritura de un método universal que lea los resultados de consultas aleatorias extrayendo los datos de las tablas no será fácilmente realizable. Así que haremos lo más sencillo: no escribiremos esta implementación, sino que se la entregaremos a un nivel superior. Para ello, solo tendremos que proporcionar a la capa anterior el manejador de conexión a la base de datos, que se almacenará en el campo s_db:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { ... public: static int Id(); // Database connection handle ... }; ... //+------------------------------------------------------------------+ //| Database connection handle | //+------------------------------------------------------------------+ int CDatabase::Id() { return s_db; }
Guardaremos el código obtenido en el archivo Database.mqh de la carpeta actual.
Asesor de optimización
Ahora podemos empezar a crear un EA de optimización. En primer lugar, necesitaremos la biblioteca para trabajar con el simulador de fxsaber, más concretamente, este archivo de inclusión:
#include <fxsaber/MultiTester/MTTester.mqh> // https://www.mql5.com/ru/code/26132
El principal trabajo de nuestro asesor experto de optimización se realizará periódicamente, según un temporizador. Por lo tanto, en la función de inicialización, crearemos un temporizador e iniciaremos directamente su manejador para que se ejecute. Como, por regla general, las tareas de optimización duran decenas de minutos, la activación del temporizador una vez cada cinco segundos parece suficiente:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Create the timer and start its handler EventSetTimer(5); OnTimer(); return(INIT_SUCCEEDED); }
En el manejador del temporizador comprobaremos si el simulador está libre en ese momento. En caso afirmativo, si hay una tarea en curso, se deberán realizar las acciones necesarias para completarla. A continuación, obtendremos el identificador y los parámetros de optimización de entrada para la siguiente tarea de la base de datos y la iniciaremos para su ejecución llamando a la función StartTask():
//+------------------------------------------------------------------+ //| Expert timer function | //+------------------------------------------------------------------+ void OnTimer() { PrintFormat(__FUNCTION__" | Current Task ID = %d", currentTaskId); // If the EA is stopped, remove the timer and the EA itself from the chart if (IsStopped()) { EventKillTimer(); ExpertRemove(); return; } // If the tester is not in use if (MTTESTER::IsReady()) { // If the current task is not empty, if(currentTaskId) { // Complete the current task FinishTask(currentTaskId); } // Get the number of tasks in the queue totalTasks = TotalTasks(); // If there are tasks, then if(totalTasks) { // Get the ID of the next current task currentTaskId = GetNextTask(currentSetting); // Launch the current task StartTask(currentTaskId, currentSetting); Comment(StringFormat( "Total tasks in queue: %d\n" "Current Task ID: %d", totalTasks, currentTaskId)); } else { // If there are no tasks, remove the EA from the chart PrintFormat(__FUNCTION__" | Finish.", 0); ExpertRemove(); } } }
En la función de inicio de la tarea, utilizaremos los métodos de la clase MTTESTER para cargar los parámetros de entrada en el simulador e iniciar este en modo de optimización. También actualizaremos la información en la base de datos, guardando la hora de inicio de la tarea actual y su estado:
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void StartTask(ulong taskId, string setting) { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", taskId, setting); // Launch a new optimization task in the tester MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(setting); MTTESTER::ClickStart(); // Update the task status in the database DB::Open(); string query = StringFormat( "UPDATE tasks SET " " status='Processing', " " start_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); }
La función de recuperación de la siguiente tarea de la base de datos también será bastante sencilla. Básicamente, en ella organizaremos la ejecución de una única consulta SQL y obtendremos sus resultados. Observe que esta función retornará como resultado el identificador de la siguiente tarea, mientras que escribirá la cadena con los parámetros de entrada de la optimización en la variable setting, que se transmitirá a la función como argumento por referencia:
//+------------------------------------------------------------------+ //| Get the next optimization task from the queue | //+------------------------------------------------------------------+ ulong GetNextTask(string &setting) { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT s.expert," " s.from_date," " s.to_date," " j.symbol," " j.period," " j.tester_inputs," " t.id_task," " t.optimization_criterion" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status = 'Queued'" " ORDER BY s.id_stage, j.id_job LIMIT 1;"; // Open the database DB::Open(); if(DB::IsOpen()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string expert; string from_date; string to_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { setting = StringFormat( "[Tester]\r\n" "Expert=Articles\\2024-04-15.14741\\%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=2\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=0\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d||0||0||0||N\r\n" "%s\r\n", row.expert, row.symbol, row.period, row.from_date, row.to_date, row.optimization_criterion, row.id_task, row.tester_inputs ); res = row.id_task; } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } return res; }
Por ahora, hemos especificado los valores de algunos de los parámetros de optimización directamente en el código, para mayor simplicidad. Así, por ejemplo, siempre se utilizará un depósito de 10 000$, un apalancamiento de 1:200, la divisa USD, etc. En el futuro, de ser necesario, los valores de estos parámetros también podrán tomarse de la base de datos.
El código de la función TotalTasks(), que retorna el número de tareas en la cola, será muy similar al código de la función anterior, por lo que no lo mostraremos aquí.
Guardaremos el código obtenido en el archivo Optimisation.mq5 de la carpeta actual. Ahora tendremos que hacer algunas pequeñas modificaciones más en los archivos creados anteriormente para conseguir un sistema mínimamente autosuficiente.
CVirtualStrategy y CSimpleVolumesStrategy
En estas clases, eliminaremos la posibilidad de establecer el valor del balance normalizado de la estrategia y haremos que siempre tenga un valor inicial de 10 000. Ahora solo cambiará cuando una estrategia se incluya en un grupo con un factor de normalización determinado. Incluso si queremos ejecutar una única instancia de la estrategia, tendremos que añadirla sola al grupo.
Así que estableceremos un nuevo valor en el constructor de objetos de la clase CVirtualStrategy:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualStrategy::CVirtualStrategy() : m_fittedBalance(10000), m_fixedLot(0.01), m_ordersTotal(0) {}
Ahora eliminaremos la lectura del último parámetro de la cadena de inicialización en el constructor de la clase CSimpleVolumesStrategy:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(string p_params) { // Save the initialization string m_params = p_params; // Read the parameters from the initialization string m_symbol = ReadString(p_params); m_timeframe = (ENUM_TIMEFRAMES) ReadLong(p_params); m_signalPeriod = (int) ReadLong(p_params); m_signalDeviation = ReadDouble(p_params); m_signaAddlDeviation = ReadDouble(p_params); m_openDistance = (int) ReadLong(p_params); m_stopLevel = ReadDouble(p_params); m_takeLevel = ReadDouble(p_params); m_ordersExpiration = (int) ReadLong(p_params); m_maxCountOfOrders = (int) ReadLong(p_params); m_fittedBalance = ReadDouble(p_params); // If there are no read errors, if(IsValid()) { ... } }
Guardaremos los cambios realizados en los archivos VirtualStrategy.mqh y CSimpleVolumesStrategy.mqh en la carpeta actual.
CVirtualStrategyGroup
En esta clase, hemos añadido un nuevo método que retornará la cadena de inicialización del grupo actual con otro valor sustituido de multiplicador normalizador. Este valor solo se determinará al final de la pasada del simulador, por lo que no podremos crear directamente un grupo con el multiplicador correcto. En esencia, solo sustituiremos el número transmitido como argumento en la cadena de inicialización antes del corchete de cierre:
//+------------------------------------------------------------------+ //| Class of trading strategies group(s) | //+------------------------------------------------------------------+ class CVirtualStrategyGroup : public CFactorable { ... public: ... string ToStringNorm(double p_scale); }; ... //+------------------------------------------------------------------+ //| Convert an object to a string with normalization | //+------------------------------------------------------------------+ string CVirtualStrategyGroup::ToStringNorm(double p_scale) { return StringFormat("%s([%s],%f)", typename(this), ReadArrayString(m_params), p_scale); }
Guardaremos los cambios realizados en los archivos VirtualStrategyGroup.mqh en la carpeta actual.
CTesterHandler
En la clase de guardado de los resultados de las pasadas de optimización añadiremos la propiedad estática s_idTask a la que asignaremos el identificador de la tarea de optimización actual. En el método para procesar los frames de datos entrantes, lo añadiremos a los valores transmitidos a la consulta SQL para guardar los resultados en la base de datos:
//+------------------------------------------------------------------+ //| Optimization event handling class | //+------------------------------------------------------------------+ class CTesterHandler { ... public: ... static ulong s_idTask; }; ... ulong CTesterHandler::s_idTask = 0; ... //+------------------------------------------------------------------+ //| Handling incoming frames | //+------------------------------------------------------------------+ void CTesterHandler::ProcessFrames(void) { // Open the database DB::Open(); ... // Go through frames and read data from them while(FrameNext(pass, name, id, value, data)) { ... // Form an SQL query from the received data query = StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %d, %s,\n'%s',\n'%s');", s_idTask, pass, values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); // Add it to the SQL query array APPEND(queries, query); } // Execute all requests DB::ExecuteTransaction(queries); ... }
Guardaremos el código obtenido en el archivo TesterHandler.mqh en la carpeta actual.
CVirtualAdvisor
Y finalmente, una última corrección. En la clase asesor experto, añadiremos la normalización automática de la estrategia o grupo de estrategias que se ha utilizado en el asesor experto durante esta pasada de optimización. Para ello, crearemos nuevamente el grupo de estrategias utilizadas desde la cadena de inicialización del asesor experto y, a continuación, formaremos la cadena de inicialización de este grupo con un multiplicador normalizador diferente calculado justo ahora según los resultados de la reducción actual de la pasada:
//+------------------------------------------------------------------+ //| OnTester event handler | //+------------------------------------------------------------------+ double CVirtualAdvisor::Tester() { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = CMoney::FixedBalance() * 0.1 / balanceDrawdown; // Calculate the profit in annual terms long totalSeconds = TimeCurrent() - m_fromDate; double fittedProfit = profit * coeff * 365 * 24 * 3600 / totalSeconds ; // Re-create the group of used strategies for subsequent normalization CVirtualStrategyGroup* group = NEW(ReadObject(m_params)); // Perform data frame generation on the test agent CTesterHandler::Tester(fittedProfit, // Normalized profit group.ToStringNorm(coeff) // Normalized group initialization string ); delete group; return fittedProfit; }
Guardaremos los cambios en el archivo VirtualAdvisor.mqh de la carpeta actual.
Inicio de la optimización
Todo está listo para ejecutar la optimización. En la base de datos crearemos un total de 81 tareas (3 símbolos * 3 marco temporales * 9 criterios). Al principio, elegíamos un intervalo de optimización pequeño, de solo 5 meses, y pocas combinaciones posibles de parámetros optimizados, ya que nos interesaba más la operatividad del proceso automático de prueba que los resultados en forma de combinaciones encontradas de parámetros de entrada de instancias de la estrategia de trabajo. Tras hacer unas cuantas pruebas y corregir los pequeños fallos que hemos encontrado, hemos conseguido lo que queríamos. La tabla de pasadas se ha rellenado con todos los resultados de las pasadas con filas de inicialización rellenas de grupos normalizados con una instancia de estrategias.
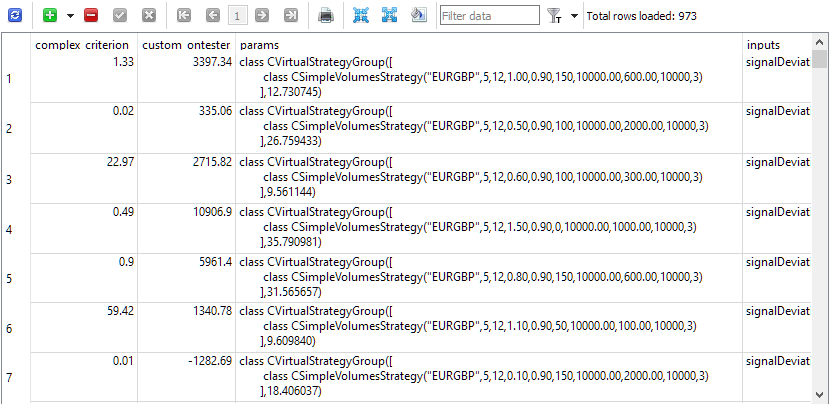
Fig. 1. Tabla passes con los resultados de las pasadas
Cuando el esquema haya confirmado su operatividad, podremos encomendarle una tarea más difícil. Vamos a ejecutar la misma tarea 81 durante un intervalo más largo y con muchas más combinaciones de parámetros. En este caso, tendremos que esperar un poco: 20 agentes realizan una única tarea de optimización durante aproximadamente una hora. Así, con un funcionamiento 24/7, se tardarán unos 3 días en completar todas las tareas.
A continuación, seleccionaremos manualmente los mejores pasadas de entre las miles de pasadas obtenidas formando la consulta SQL correspondiente que seleccione dichas pasadas. Por ahora, la selección solo se basará en un ratio de Sharpe superior a 5. Luego crearemos un nuevo asesor experto que desempeñará el papel de asesor experto universal en esta etapa. La parte principal será la función de inicialización. En él extraemos parámetros de las mejores pasadas seleccionadas de la base de datos, formaremos la cadena de inicialización del asesor experto usando estas como base y la creamos.
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" sinput double expectedDrawdown_ = 10; // - Maximum risk (%) sinput double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency sinput double scale_ = 1.00; // - Group scaling multiplier input group "::: Selection for the group" input int count_ = 1000; // - Number of strategies in the group input group "::: Other parameters" sinput ulong magic_ = 27183; // - Magic input bool useOnlyNewBars_ = true; // - Work only at bar opening CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); string query = StringFormat( "SELECT DISTINCT p.custom_ontester, p.params, j.id_job " " FROM passes p JOIN" " tasks t ON p.id_task = t.id_task" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE p.custom_ontester > 0 AND " " trades > 20 AND " " p.sharpe_ratio > 5" " ORDER BY s.id_stage ASC," " j.id_job ASC," " p.custom_ontester DESC LIMIT %d;", count_); DB::Open(); int request = DatabasePrepare(DB::Id(), query); if(request == INVALID_HANDLE) { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); DB::Close(); return 0; } struct Row { double custom_ontester; string params; int id_job; } row; string strategiesParams = ""; while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } // Prepare the initialization string for an EA with a group of several strategies string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
Para la optimización, elegiremos un intervalo de dos años completos: 2021 y 2022. Así veremos cómo es el resultado del asesor experto universal en este intervalo. Para igualar la reducción máxima con el valor del 10%, elegiremos el valor correspondiente del multiplicador scale_. Los resultados de la prueba del asesor experto universal en este intervalo serán los siguientes:
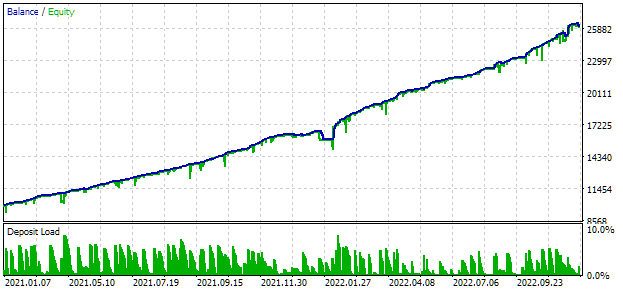
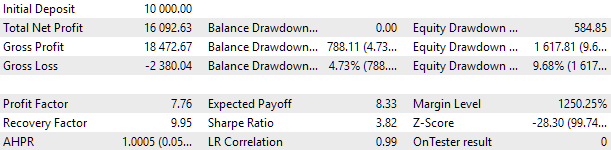
Fig. 2. Resultados de las pruebas del asesor experto universal para 2021-2022 (scale_ = 2)
En este EA han participado aproximadamente mil instancias de estrategias. Estos resultados solo deberán considerarse provisionales, ya que aún no hemos realizado muchas de las acciones para mejorar el resultado que se han comentado anteriormente. En particular, el número de instancias de estrategias para EURUSD ha sido notablemente superior al de EURGBP, por lo que las ventajas de la multidivisa se han aprovechado poco hasta ahora. Así que hay esperanzas de que el potencial de mejora siga ahí. Haremos realidad este potencial en el futuro.
Conclusión
Así pues, hoy hemos dado otro paso importante hacia el objetivo previsto. Hemos logrado automatizar el proceso de optimización de instancias de estrategias comerciales en distintos símbolos, marco temporales y otros parámetros. Ahora ya no tendremos que estar pendientes del final de un proceso de optimización en marcha para cambiar los parámetros e iniciar el siguiente.
El almacenamiento de todos los resultados en la base de datos nos permitirá no preocuparnos por un posible reinicio del asesor experto optimizador. Si por alguna razón el asesor experto en optimización ha interrumpido su trabajo, continuará su funcionamiento en el siguiente inicio, comenzando con la siguiente tarea en la cola. También tendremos una imagen completa de todos los pasadas de los simuladores durante el proceso de optimización.
Sin embargo, aún queda mucho por hacer. Aún no hemos implementado las actualizaciones de estado para las etapas y proyectos, solo hemos implementado actualizaciones del estado de las tareas. No hemos tenido en cuenta la optimización de proyectos que constan de varias etapas. Tampoco ha quedado claro cuál es la mejor manera de implementar el procesamiento intermedio de estos pasos si se requiere, por ejemplo, la clusterización de datos. Intentaremos hablar de ello en los siguientes artículos.
Gracias a los que han leído hasta el final, ¡hasta pronto!
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14741
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Sí, yo tampoco esperaba que fuera tan sencillo. Al principio estudié Validate, pensé que tendría que escribir algo propio basado en él, pero luego me di cuenta de que me vendría bien una implementación más sencilla.
Gracias de nuevo por esta gran biblioteca.
Hola Yuriy,
Estoy tratando de reblicar la Parte 11. He creado un SQL con CleanDatabase que lo creó en User\Roaming\AppData... Sin embargo cuando traté de usar el Optimizador, recibí el error: IPC server not started. ¿Puede usted , o alguien, proporcionar una referencia fácil para iniciarlo?
Además, yo uso el interruptor /portable en Terminal y MetaEditor con todas mis instalaciones MQL ubicadas en C:\"Forex Archivos de Programa" ¿esto causará algún problema?
Durante mi desarrollo MQ4 y teesting EAs, he creado directorios para todos los pares que estaba interesado en probar. Utilicé el comando JOIN para redirigir los subdirectorios apropiados de cada directorio de prueba a mi directorio común para iniciar los probramas y recibir datos de cotización para asegurar que todas las pruebas separadas estuvieran utilizando los mismos datos y ejecutables. Además, cada prueba escribió un archivo CVS para cada ejecución y utilicé una versión de las funciones File para leer los archivos CVS de cada directorio Files y consolidarlos en un archivo CVS común. Si esto es de interés para usted en su uso de archivos CVS en lugar del acceso SQL, hágamelo saber.
En el ínterin, voy a descargar la Parte 20 y muddle a través de los ejemplos.
CapeCoddah