
Cambiando a MQL5 Algo Forge (Parte 4): Trabajamos con versiones y lanzamientos
Introducción
Nuestra transición a MQL5 Algo Forge está en curso, y después de establecer un flujo de trabajo con nuestros propios repositorios, abordaremos una de las principales razones de esta transición: la capacidad de utilizar fácilmente los códigos de la comunidad. En la Parte 3, vimos cómo añadir una biblioteca pública del repositorio de otra persona a nuestro propio proyecto.
El experimento con la conexión de la biblioteca SmartATR al asesor experto SimpleCandles ha demostrado claramente que la forma directa (clonación simple) no siempre resulta conveniente, especialmente si el código requiere modificaciones. Asimismo, elaboramos detalladamente el flujo de trabajo correcto mediante la creación de una bifurcación que se convirtió en nuestra copia personal del repositorio de otra persona para corregir errores y realizar modificaciones, con la posibilidad de ofrecer esos cambios al autor mediante Pull Request en el futuro.
A pesar de que existen algunas limitaciones en la interfaz del MetaEditor, la combinación con la interfaz web del repositorio MQL5 Algo Forge permitió realizar con éxito toda la cadena de acciones desde la clonación hasta el commit de las ediciones y la conexión final del proyecto con la biblioteca externa. Así, no solo resolvimos un problema específico, sino que también consideramos un patrón de acción universal para integrar cualquier componente de terceros.
En el artículo de hoy, nos detendremos en la fase de publicación en el repositorio de las ediciones realizadas, cuyo conjunto forma una solución completa, ya se trate de añadir una nueva funcionalidad al proyecto o de corregir un error anteriormente detectado. Estamos hablando de la corrección o el lanzamiento de una nueva versión de un producto. Veamos cómo se puede organizar este proceso y qué características nos ofrece MQL5 Algo Forge en este repositorio.
Búsqueda de ramas
En artículos anteriores, recomendamos usar una rama aparte del repositorio para hacer un conjunto de ediciones que resuelvan un problema específico. Sin embargo, una vez completado el trabajo en esta, resulta preferible fusionar la rama con otra (principal) y eliminarla. De lo contrario, el repositorio puede convertirse en una maraña en la que incluso el propietario del repositorio puede perderse fácilmente. Por ello, las ramas finalizadas deben eliminarse. No obstante, a veces es necesario devolver el código al estado en el que se encontraba justo antes de eliminar una rama determinada. ¿Cómo podemos hacer esto?
En primer lugar, dejaremos claro que una rama es simplemente una secuencia de commits ordenados por tiempo. Técnicamente, una rama es un puntero a un commit que se considera el último de una cadena de commits consecutivos. Por consiguiente, la eliminación de una rama no borrará los commits. En el peor de los casos, podrían empezar a considerarse como pertenecientes a una rama diferente, o incluso fusionarse en un commit conjunto, pero seguirán existiendo en el repositorio de una forma u otra (salvo raras excepciones). Así que poder retornar al estado "antes de la eliminación de la rama" es como volver a uno de los commits situados en alguna rama existente. La cuestión es cómo encontrar el commit adecuado.
Echemos un vistazo al estado del repositorio SimpleCandles después de hacer las modificaciones mencionadas en la parte 3:
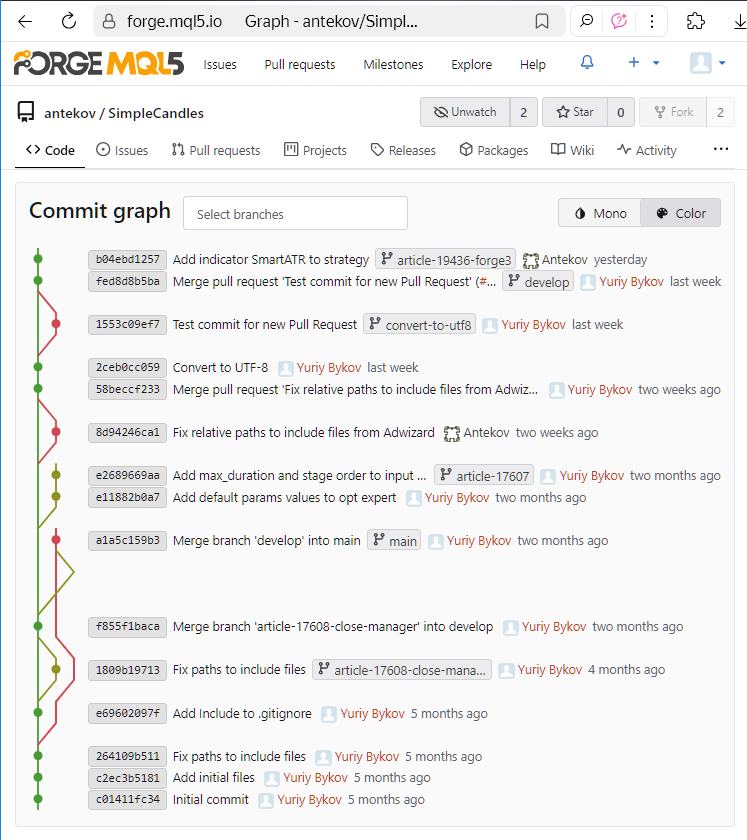
Vemos una historia de los commits realizados y una visualización en color de las interrelaciones de las distintas ramas a la izquierda. Cada commit se muestra con su hash (o, mejor dicho, con parte de su hash), un número único por el que puede distinguirse de todas las demás. Para reducir la longitud de su registro, este número se muestra en hexadecimal (por ejemplo, b04ebd1257).
Tal árbol de commits para cada repositorio se puede ver en la página aparte del repositorio de la interfaz web del almacenamiento MQL5 Algo Forge. Esta captura de pantalla fue tomada hace algún tiempo, así que si va a esta página ahora, verá una imagen ligeramente diferente: habrá nuevos commits en el árbol de commits, y el entrelazamiento de ramas también será diferente, debido a los commits de fusión añadidos.
También podemos ver los nombres de las ramas frente a algunos commits. Estos se muestran en los commits más recientes de cada rama. En la captura de pantalla anterior, podemos contar seis ramas diferentes: main, develop, convert-to-utf8, article-17608-close-manager, article-17607 y article-19436-forge3. La última rama mencionada es la rama de los cambios realizados al escribir la Parte 3, es decir, la anterior. Pero al trabajar en la Parte 2, también creamos una rama aparte para los cambios previstos. Se llamaba article-17698-forge2, y ahora se ha eliminado, por lo que ningún commit junto a él tiene ese nombre de rama. ¿Dónde podemos encontrarla, entonces?
Si mira el comentario completo del commit 58beccf233, en este se menciona el nombre de esta rama y dice que se fusionó con la rama develop:

Por lo tanto, hemos encontrado el commit necesario, pero localizarlo de esta manera resulta incómodo. Además, si no utilizáramos el mecanismo Pull Request para fusionar ramas, sino que las ejecutáramos mediante los comandos de consola de git merge, podríamos especificar nuestro propio comentario aleatorio en el commit de la fusión. Entonces sería aún más difícil encontrar ese commit, ya que el nombre de la rama podría no haber sido incluido en su comentario.
Ahora tenemos la opción de alternar a este commit, llevando nuestro repositorio local al estado de después de este commit. Para ello, podemos usar el hash del commit deseado en el comando git chekout. Sin embargo, existen aquí ciertos matices. Si intentamos alternar a este commit en el MetaEditor seleccionándolo de la historia que se abre pulsando en el elemento del menú contextual del proyecto "Git Log":
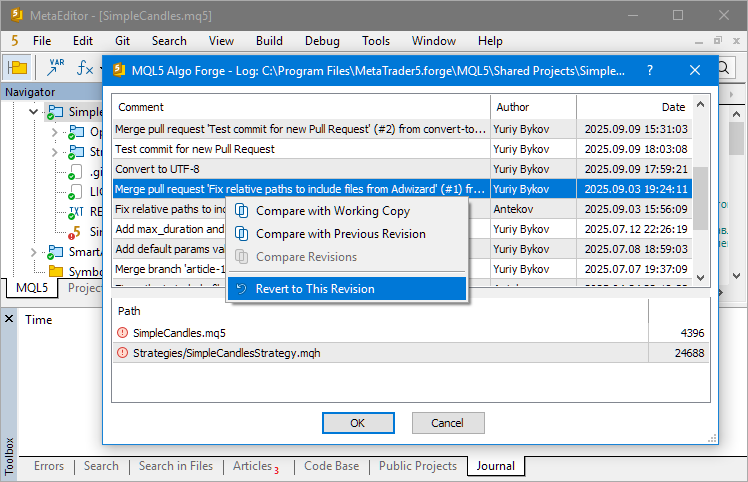
... obtendremos un mensaje de error:

Quizá haya un motivo para ello. Vamos a analizar mejor lo que ocurre. Empezaremos por introducir los nuevos conceptos de "tag" y "puntero HEAD".
¿Qué son los tags?
Un tag en el sistema de control de versiones Git es un nombre opcional asignado a un commit. También se puede llamar tag un puntero o referencia a una versión particular de código en el repositorio, ya que apunta a un commit en particular. El uso de tags permite volver al estado del código correspondiente a un commit dado con el tag en cualquier momento. Los tags le ayudan a marcar puntos importantes en el desarrollo de un proyecto, como el lanzamiento de una versión, una fase de finalización o una versión estable. En la interfaz web del repositorio MQL5 Algo Forge, los tags del repositorio seleccionado se pueden ver en una página aparte.
Existen dos tipos de tags en Git: tags ligeros y tags anotados. Los tags ligeros solo tienen un nombre, mientras que los tags anotados pueden contener información adicional: autor, fecha, comentarios e incluso una firma. En la mayoría de los casos, se utilizan tags ligeros.
Para crear un tag a través de la interfaz web, puede ir a cualquier página de commit (por ejemplo, de este) y, haciendo clic en Operations, seleccionar "Create tag":
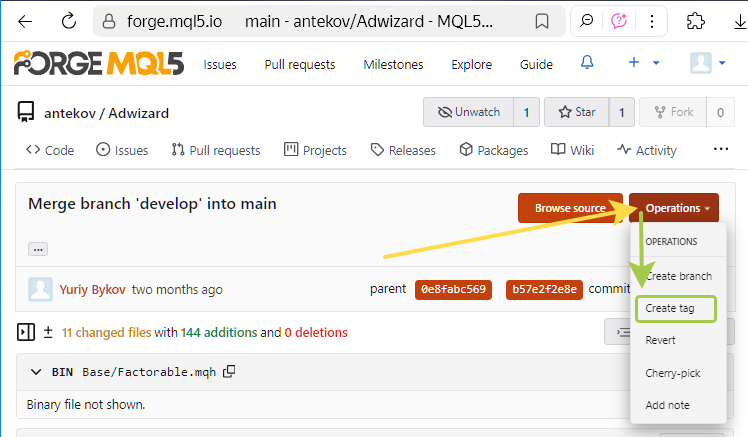
Pero no lo vamos a hacer por ahora, volveremos a la creación del tag más tarde.
Para crear un tag mediante comandos de la consola Git, se utiliza el comando git tag. Para crear un tag ligero, solo deberemos especificar un parámetro: el nombre del tag creado:
git tag <nombre del tag>
# Por ejemplo
tag git v1.0
Para crear un tag anotado, deberemos especificar parámetros adicionales:
git tag -a <nombre del tag> -m "Descripción del tag"
# Por ejemplo:
git tag -a v1.0 -m "Release version 1.0"
Además de para marcar versiones de código destinadas a su publicación o lanzamiento (releases), los tags se utilizan para indicar a los pipelines de CI/CD que deben realizarse algunas acciones predefinidas cuando aparece un commit con un determinado tipo de tag, o para marcar etapas significativas en el desarrollo del proyecto (por ejemplo, la finalización de características importantes, la corrección de errores críticos), pero sin señalar el lanzamiento de una nueva versión.
Puntero HEAD
Tras habla de los tags, debemos mencionar el puntero HEAD. En comportamiento es similar a un tag con un nombre fijo HEAD, que se mueve automáticamente al último commit en la rama extraída actual. HEAD también puede denominarse "marcador de rama actual" o "puntero a rama activa". Responde a la pregunta: "¿en qué punto de nuestro repositorio nos encontramos en este momento?". Pero no es un tag como tal.
Físicamente, este puntero se almacena en el archivo .git/HEAD en el repositorio. El contenido de HEAD puede contener un enlace simbólico (tag, nombre de rama) o un hash de commit. Al cambiar de rama, el puntero HEAD se actualiza de forma automática para apuntar al último commit de la rama actual. Cuando añadimos un nuevo commit, Git no solo crea el objeto de commit, sino que también mueve el puntero HEAD a él.
Así, en los comandos de la consola de Git se puede usar el nombre "HEAD" en lugar del hash del último commit o el nombre de la rama actual, y utilizando los caracteres especiales '~' y '^' se puede hacer referencia a commits posteriores al último. Por ejemplo, "HEAD~2" indicaría un commit que está dos commits por detrás (es decir, antes) del último commit. Pero no entraremos ahora en esas sutilezas.
Para continuar, deberemos mencionar otros dos posibles estados en los que puede encontrarse un repositorio de código. El estado normal se denomina "attached HEAD" y significa que los nuevos commits creados se producirán antes del último commit de la rama actual. En este estado, todas las ediciones se añaden a la rama de forma coherente y sin conflictos.
Otro estado llamado "detached HEAD" se produce cuando el puntero HEAD empieza a apuntar a un commit que no es el último de ninguna rama. Esto puede ocurrir, por ejemplo:- al cambiar el repositorio a un commit pasado específico (por ejemplo, con el comando git checkout <commit-hash>);
- al cambiar el repositorio según el nombre del tag (por ejemplo, git checkout tags/<tag-name>);
- al cambiar el repositorio a una rama que aún está presente en el repositorio upstream pero que ya ha sido eliminada en el repositorio local (por ejemplo, git checkout origin/<branch-name>).
Este estado deberá evitarse si es posible, ya que cualquier cambio realizado en este estado no estará relacionado con ninguna rama y puede perderse al cambiar a otra. Pero si no pensamos hacer cambios en este estado, no hay nada malo en ello.
Aún no hay tags
Volvamos ahora al intento de cambiar nuestro repositorio local a un commit específico que en su día fue el último de la rama eliminada article-17698-forge2.
La cuestión es que cambiar un repositorio al estado de un commit pasado concreto no es algo rutinario en Git. En funcionamiento normal, no necesitamos realizar dicha operación. Pero si decidimos hacer esto, el repositorio cambiado a un commit en particular pasará al estado "detached HEAD" mencionado anteriormente según el hash. Ahora está incrustado en la rama develop, y ya hay otros commits más recientes en esa rama después de él, lo que significa que este commit no es el último commit en la rama.
No obstante, si usamos comandos de consola para realizar dicha operación de conmutación, se obtendrá el resultado. Sin embargo, Git avisará del estado "detached HEAD":
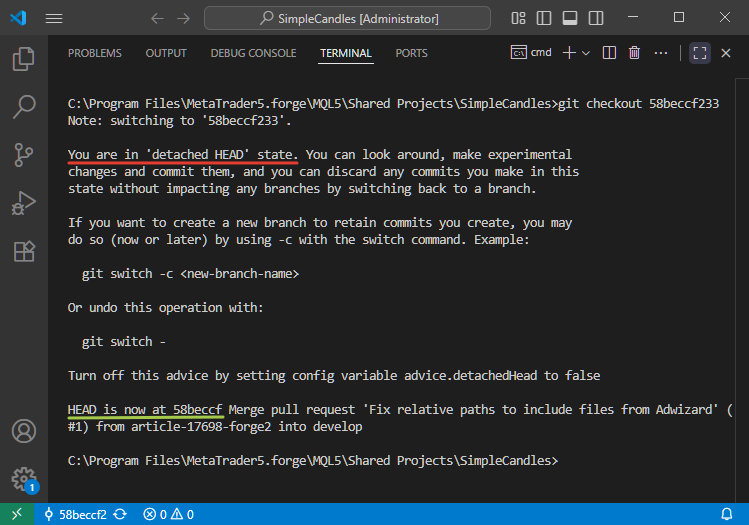
Los lectores atentos pueden notar que en la última captura de pantalla cambiamos al commit con hash 58beccf233, y como resultado Git muestra que el puntero HEAD está en el commit con hash 58beccf. ¿Dónde han ido a parar los tres últimos dígitos? No se preocupe, no se han ido a ninguna parte. Es solo que Git puede entender correctamente en comandos no solo el hash completo, sino también parte del mismo. Por ello, en diferentes interfaces de Git, podemos ver hashes reducidos a diferente cantidad de caracteres (normalmente entre 4 y 10).
Si queremos, siempre podemos ver el hash completo del commit, por ejemplo ejecutando el comando git log. Contendrá 40 dígitos:
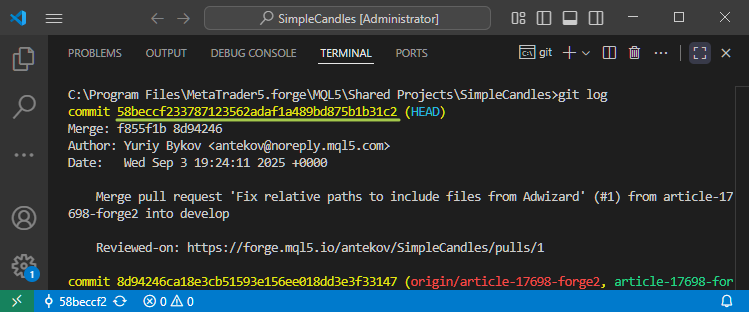
Pero gracias a la generación aleatoria de hash para cada nuevo commit, incluso los primeros dígitos del registro de ese número tienen una probabilidad muy alta de no repetirse en el repositorio . Por lo tanto, especificar solo una pequeña parte del hash resulta suficiente para que Git entienda correctamente a qué commit nos estamos refiriendo en un comando ejecutable.
Uso de la codificación UTF-8
Vamos a mencionar otro aspecto interesante. En versiones anteriores, el MetaEditor usaba la codificación UTF-16LE para guardar los códigos fuente. Pero los archivos escritos en esta codificación eran, por alguna razón, considerados por Git como archivos binarios, no archivos de texto. Por eso no podíamos ver en el commit qué líneas de código se habían cambiado (aunque sí podíamos conseguirlo en Visual Studio Code). Lo máximo que se mostraba era el tamaño de los archivos antes y después de las ediciones dentro de un commit concreto.
Así es como se ve en la interfaz web del repositorio MQL5 Algo Forge:
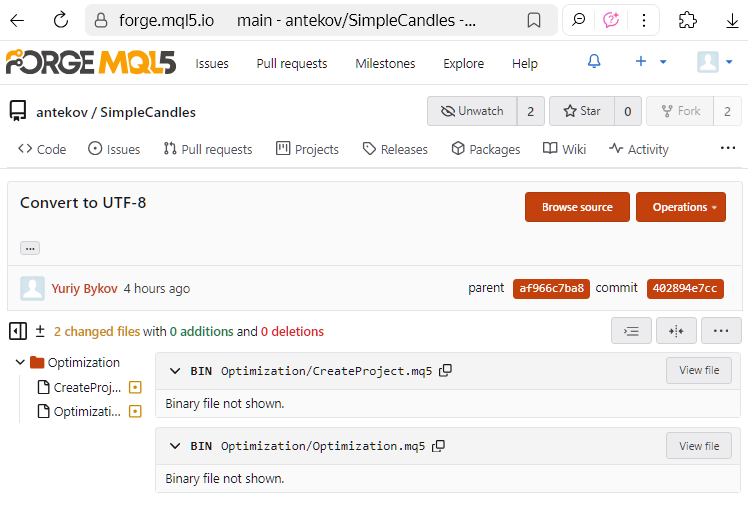
Ahora los nuevos archivos creados en el MetaEditior se guardan en codificación UTF-8, e incluso el uso de caracteres del alfabeto nacional no cambia automáticamente a la codificación UTF-16LE. Por eso tiene sentido convertir los archivos antiguos que han migrado al nuevo almacenamiento desde tiempos algo más antiguos, a la codificación UTF-8. Tras realizar dicha conversión, podremos ver las cadenas y caracteres específicos modificados a partir del siguiente commit. Por ejemplo, en la interfaz web del repositorio MQL5 Algo Forge, podría tener este aspecto:
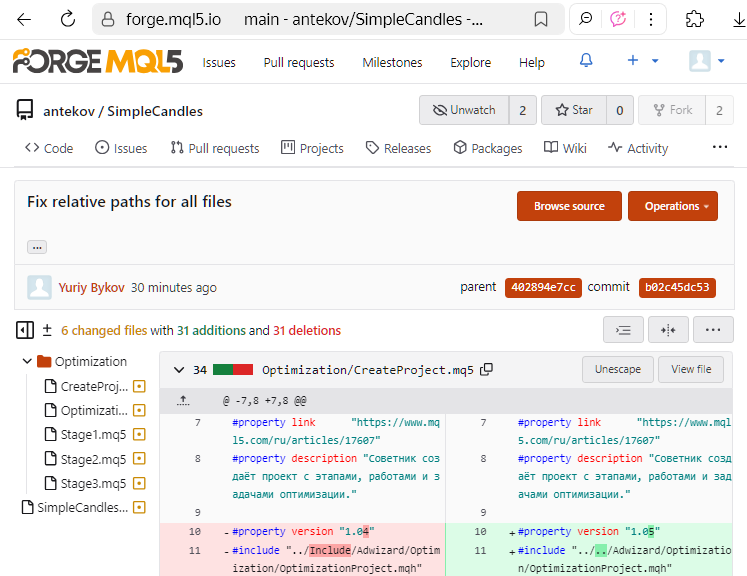
Pero eso ha sido solo una digresión, volvamos a la discusión de la publicación de una nueva versión del código en el repositorio.
Volvemos a la tarea principal.
Así, entre las ramas de nuestro repositorio, destacaremos dos: article-17608-close-manager y article-17607. Los cambios realizados en ellas aún no se han introducido en la rama develop, ya que el trabajo en las tareas relacionadas con la rama aún no ha finalizado. Es decir, estas ramas aún se desarrollarán, por lo que es demasiado pronto para introducir ediciones desde las mismas en develop. Queremos continuar una de ellas (article-17607), llevarla a una conclusión lógica y luego fusionarla con la rama develop. El estado alcanzado del código se marcará con un tag con el número de versión.
Para ello, primero deberemos preparar la rama seleccionada para nuevas ediciones, ya que otras ramas se han editado en paralelo durante su existencia. Estas modificaciones ya se han trasladado a la rama develop. Así que deberemos asegurarnos de que estas ediciones de develop lleguen a nuestra rama seleccionada tan pronto como sea posible.
Podemos introducir ediciones de develop en article-17607 de varias maneras. Por ejemplo, podemos crear un Pull Request a través de la interfaz web y repetir el proceso de fusión que describimos en el último artículo. Pero se debe hacer esto cuando queremos introducir código nuevo y no verificado en una rama que contiene código verificado en funcionamiento. Ahora la situación es la contraria: queremos mover una edición de una rama con código verificado y en funcionamiento a una rama con código nuevo, aún no probado. Por lo tanto, es perfectamente aceptable usar comandos de la consola de Git para realizar la fusión. Vamos a usar la consola y a controlar el proceso en Visual Studio Code.
En primer lugar, comprobaremos el estado actual del repositorio. En la sección del sistema de control de versiones, podemos ver la historia de commits con los nombres de las ramas. La rama actual es ahora article-19436-forge3, donde se han realizado las últimas modificaciones. En la parte derecha del terminal, podemos ver el resultado del comando de consola git status:
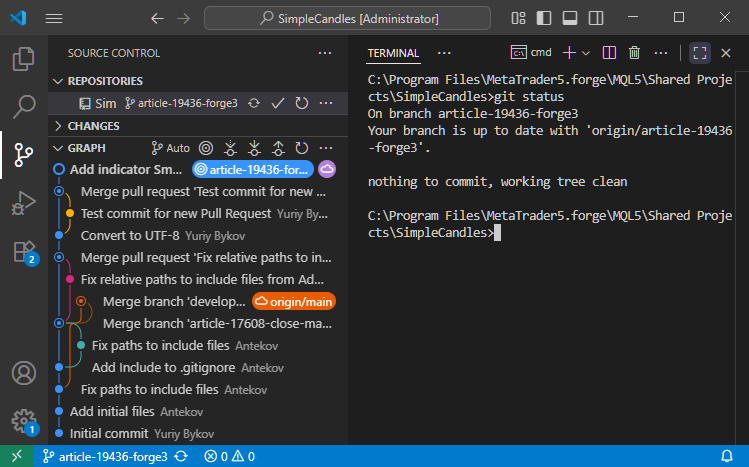
El resultado del comando confirma que nuestro repositorio está ahora efectivamente en la rama article-19436-forge3 y que su estado está sincronizado con la rama homónima en el repositorio anterior.
Ahora cambiamos a la rama article-17607 utilizando el comando git checkout article-17607:
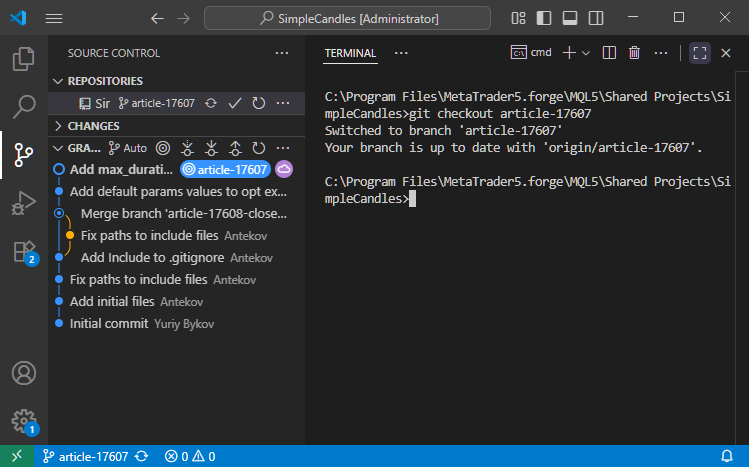
Y el siguiente comando git merge develop fusionará la rama actual con la rama develop:
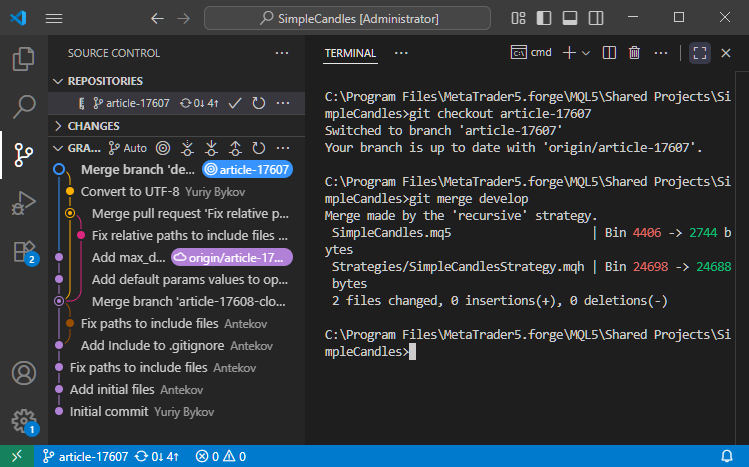
Como los cambios externos ha afectado a aquellos lugares del código que no cambiamos al trabajar en la rama article-17607, no se han dado conflictos durante la fusión. Como resultado, se ha creado un nuevo commit de fusión de ramas.
Vamos a ejecutar el comando git push para enviar la información de los cambios al repositorio superior:
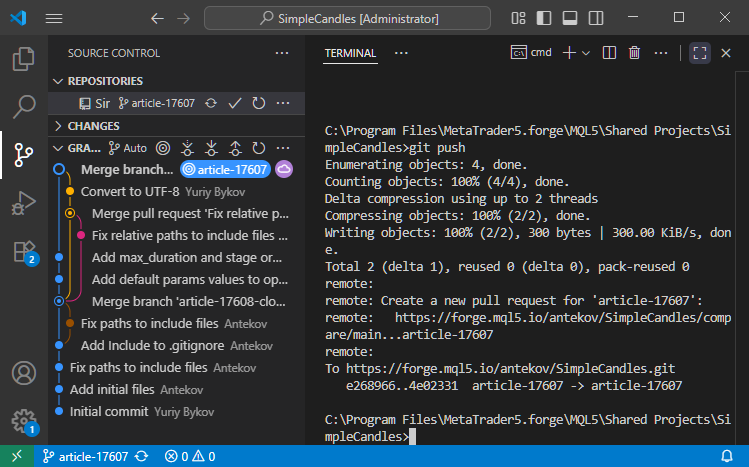
Ahora comprobaremos el repositorio MQL5 Algo Forge y ver que los pasos que hemos hecho para fusionar ramas se han trasladado de forma segura al repositorio superior:
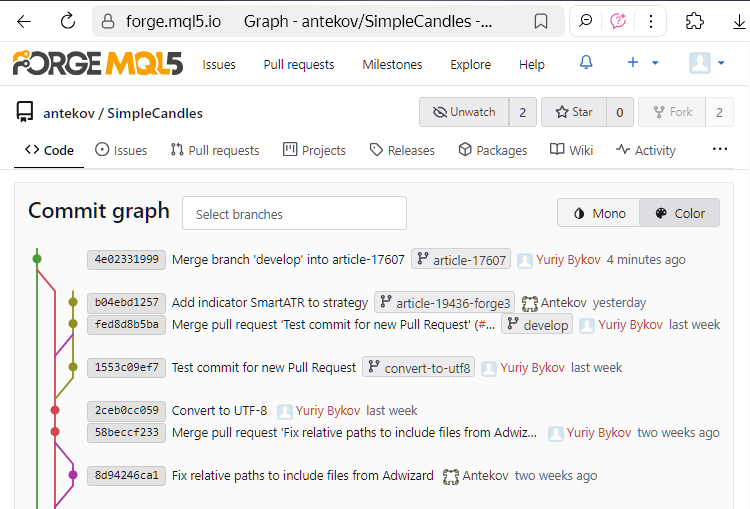
El último commit de la captura de pantalla es un commit de fusión de las ramas develop y article-17607.
Fíjese también en el extremo libre de la rama article-19436-forge3, que no está conectado a ninguna otra. Las ediciones de esta rama aún no se han introducido en la rama develop, ya que aún no están finalizadas. Así que vamos a ignorarlas ahora, cuando llegue el momento podremos continuar esta rama.
Con esto completamos la preparación para continuar el desarrollo en la rama article-17607 y podemos pasar a trabajar en el código. La solución al problema por el que hemos creado esta rama se expone en otro artículo. Aquí no nos repetiremos e iremos directamente a la descripción de las acciones para arreglar el estado del código conseguido tras solucionar el problema.
Ejecutamos la fusión
Antes de publicar algún estado del código, necesitaremos moverlo a la rama principal. Nuestra rama principal es main. Las ediciones de la rama de desarrollo develop se introducirán en ella, mientras que la rama de desarrollo se fundirá con las ediciones de las ramas de las tareas de desarrollo individuales. Aún no estamos listos para mover el nuevo código a la rama main, así que nos limitaremos a mover las ediciones solo a la rama develop. Para demostrar las capacidades de este mecanismo, no será tan importante la elección de una rama concreta que desempeñe el papel de rama principal.
Vamos a echar un vistazo al estado del repositorio SimpleCandles, donde acabó tras completarse la tarea seleccionada:
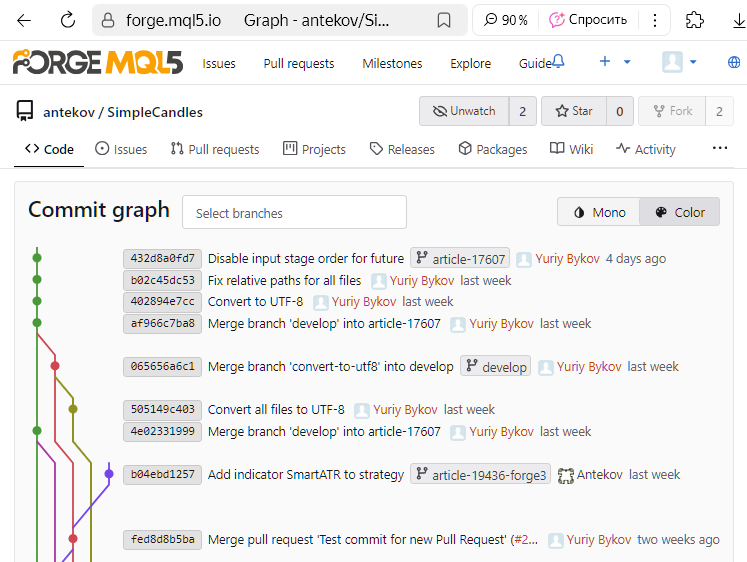
Como puede ver, el commit más reciente está en la rama article-17607. Vamos a crear un Pull Request para fusionar esta rama en la rama develop a través de la interfaz web del repositorio MQL5 Algo Forge, como hemos descrito antes:
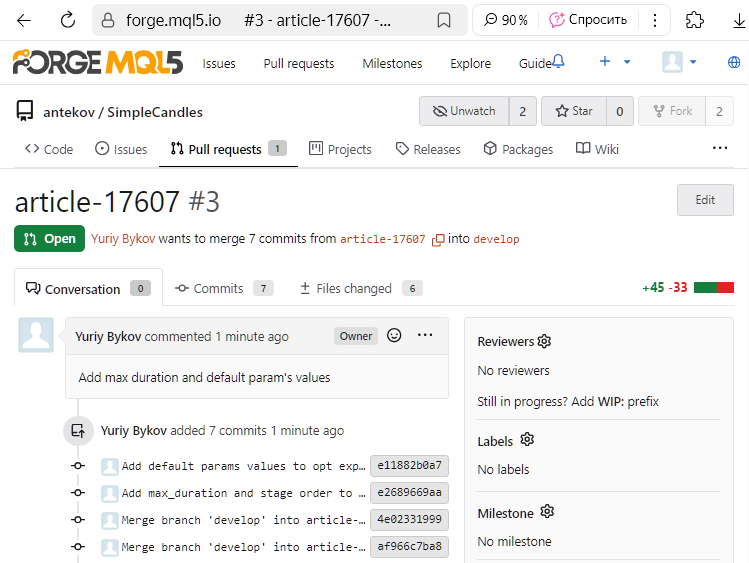
Vamos a comprobar que todo haya funcionado según lo previsto. Podemos ver nuevamente la página de la historia de commits con el árbol de ramas:
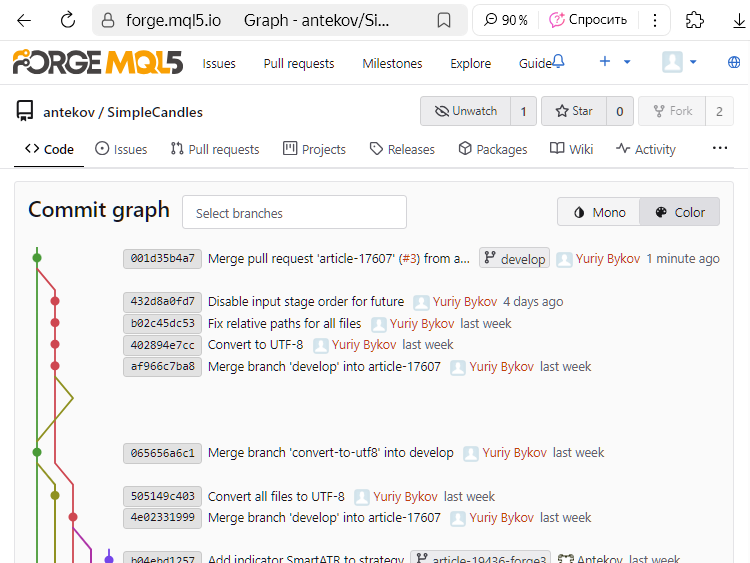
Vemos que el commit con el hash 432d8a0fd7 ya no está marcado como el último commit en la rama article-17607. Pero antes había un nuevo commit con hash 001d35b4a7, que está marcado como el último en la rama develop. Como este commit fija la fusión de dos ramas, a partir de ahora nos referiremos a él como commit de fusión.
Ahora entraremos en la página del commit y crearemos un nuevo tag. Al principio de este artículo, ya mostramos dónde podemos hacerlo, y ahora es el momento de poner en práctica la creación:
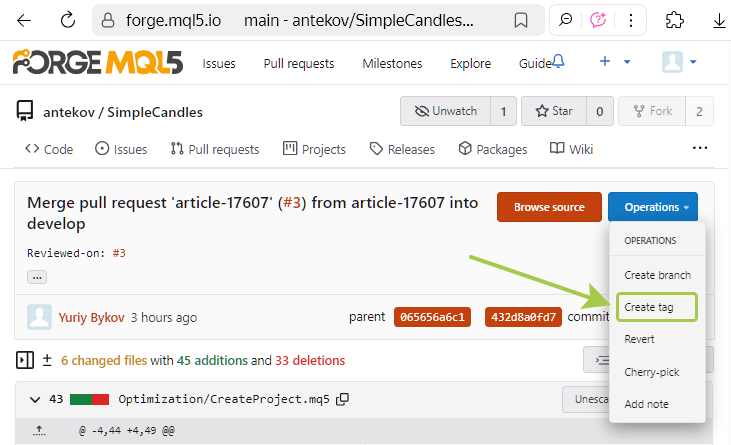
En la ventana que aparecerá, introducimos el nombre "v0.1", porque aún no es la versión definitiva. Aún no sabemos cuántas incorporaciones se harán a este proyecto, pero esperamos que bastantes. Así que un número de versión tan pequeño supone más un recordatorio para nosotros mismos de que hay más trabajo por hacer. Por cierto, no parece que la interfaz web del repositorio permita crear tags anotados.
Por lo tanto, el tag se ha creado correctamente, podemos ver el resultado en la página siguiente:
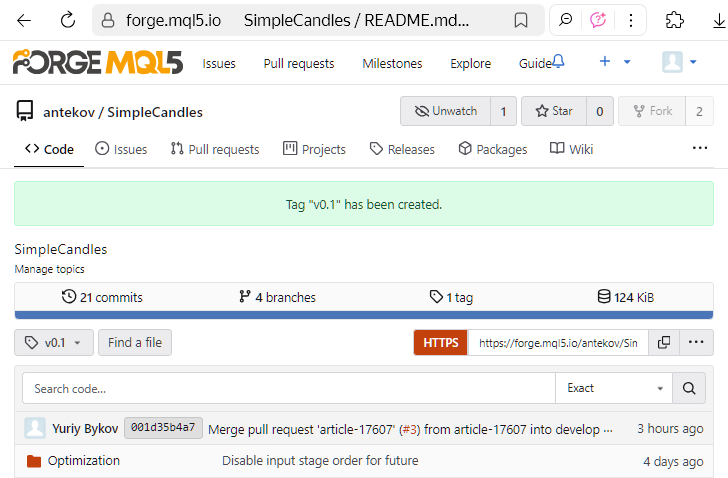
o en una página aparte del repositorio de tags
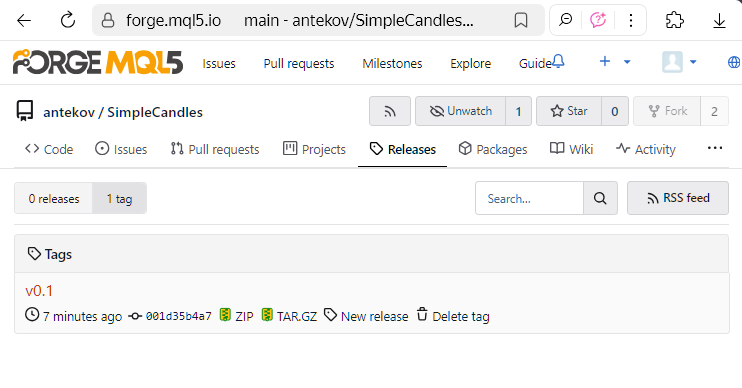
Si ejecutamos el comando para actualizar el repositorio local (git pull), el tag creado aparecerá en él. Sin embargo, no hay ningún lugar para ver los tags de repositorio en la interfaz del MetaEditor, así que vamos a mostrar cómo se verán en Visual Studio Code. Si pasamos el ratón por encima de la commit deseado en el árbol de commits, aparecerá un tag de color con el nombre del tag vinculado:
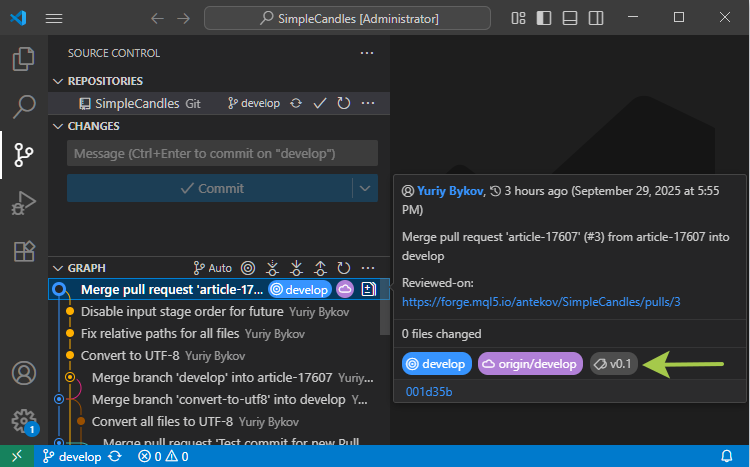
Ahora que el tag ha sido creado, podemos estar tranquilos y utilizar ese nombre en el comando git checkout para saltar a ese estado de código en particular, o podemos ir más allá y crear una versión basada en ese estado.
Creación de un lanzamiento
Las versiones son un mecanismo para marcar y distribuir versiones específicas de nuestro software, independientemente del lenguaje de programación utilizado. Mientras que los commits y las ramas suponen el "flujo de trabajo" del desarrollo, las versiones son los "resultados oficiales" que queremos publicar. Los principales objetivos de la utilización de este mecanismo son los siguientes:
- Control de versiones. Marcamos estados específicos del código en el repositorio indicando que poseen cierta estabilidad, es decir, que no tienen errores (al menos explícitos) con la funcionalidad implementada. Otros usuarios podrán usar solo esas versiones del código.
- Distribución de archivos binarios. Los archivos compilados y de otro tipo (.ex5, .dll, .zip) pueden adjuntarse a las versiones, lo cual evita a los usuarios tener que compilarlos ellos mismos si no lo necesitan.
- Información de los usuarios. Resulta conveniente añadir una descripción a la versión que suele incluir una lista de los cambios realizados, las nuevas funciones, los errores corregidos y otra información relativa al lanzamiento de esa versión en concreto. El objetivo principal de la descripción es que el usuario sepa si merece la pena actualizarse a esta versión.
Un lanzamiento se crea a partir de un tag existente, o bien se crea un nuevo tag al mismo tiempo durante el proceso de creación del lanzamiento. Ya hemos creado el tag, así que crearemos una nueva versión basada en él. Para ello, en la página de tags del repositorio, haremos clic en la opción "New release" del tag deseado:

- nombre de la versión, rama y tag de esa rama (nueva o previamente seleccionada);
- descripción del lanzamiento (Release notes): novedades, correcciones y resolución de problemas conocidos;
- archivos adjuntos, como programas compilados, documentación o enlaces a fuentes externas.
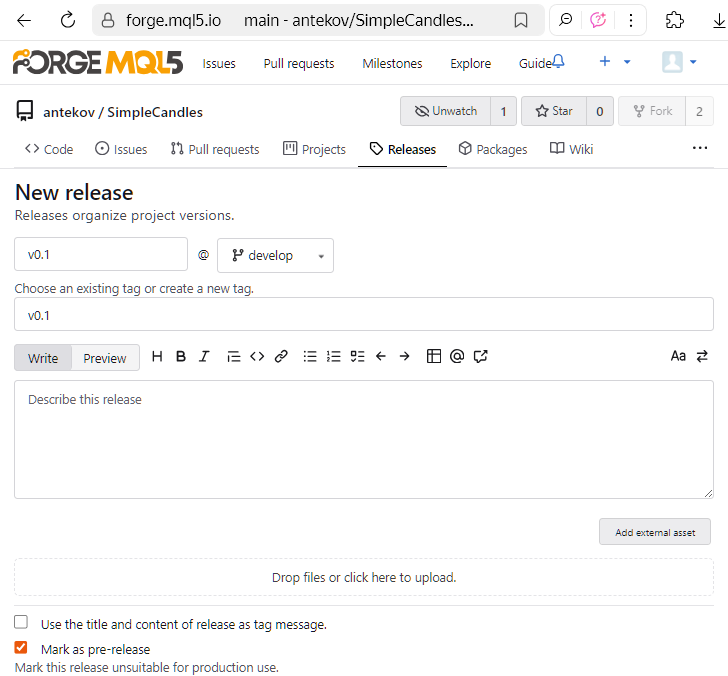
Podemos guardar el lanzamiento como borrador y modificar sus propiedades más tarde, o publicarlo inmediatamente. La publicación no impedirá que se hagan más correcciones o adiciones, por ejemplo, a la descripción de la versión. Después de eso, nosotros y todos los demás usuarios podremos ver la versión publicada en la página de lanzamientos de nuestro repositorio:
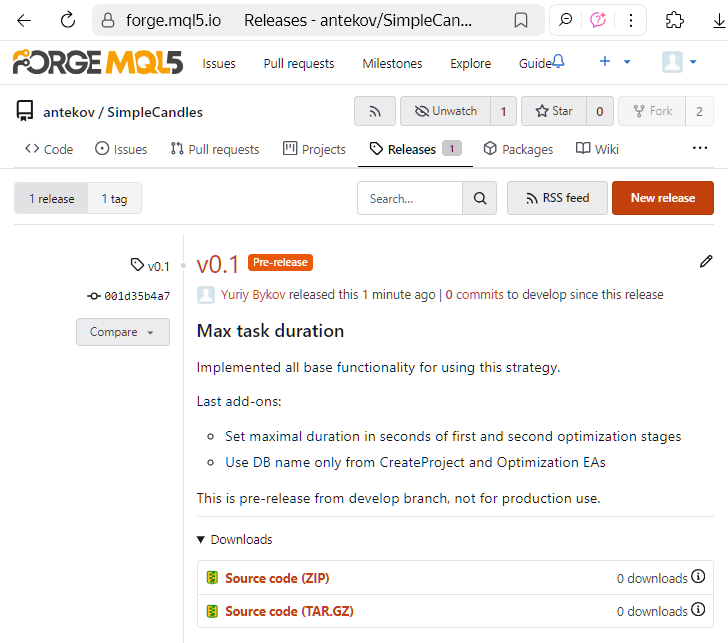
¡Y ya está! La nueva versión está publicada y lista para su uso. Un poco más tarde editaremos el nombre de la versión, que no tiene por qué coincidir con el tag utilizado, y añadiremos un enlace al artículo mencionado anteriormente en el que se describe la solución al problema.
Conclusión
Vamos a detenernos aquí un momento y echar un vistazo al trabajo realizado. Hoy no nos hemos limitado a aprender los aspectos técnicos del trabajo con el sistema de control de versiones, sino que hemos recorrido un camino de transformación completa: de ediciones dispares a un proceso de gestión del código holístico y estructurado. De especial importancia resulta la fase final, que ya dominamos: la formalización de los trabajos terminados en forma de versiones oficiales de un producto completo listo para su presentación a los usuarios. Es posible que nuestro repositorio en concreto aún no haya alcanzado este nivel de madurez, pero hemos hecho todo lo posible para estar preparados para dicha transición.
El planteamiento analizado cambia fundamentalmente la percepción del proyecto. De un simple conjunto de archivos fuente pasa a un sistema organizado con una historia clara de cambios y correcciones de los estados de funcionamiento del sistema, lo que permite volver a una versión estable en cualquier momento. Esto resulta útil para todos, tanto para los desarrolladores como para los usuarios de soluciones estándar.
Así, el dominio de las herramientas descritas lleva el trabajo con el repositorio MQL5 Algo Forge a un nivel cualitativamente nuevo, descubriendo oportunidades para proyectos más complejos y a gran escala en el futuro.
Gracias por su atención, ¡hasta la próxima!
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/19623
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
 Dominando los registros (Parte 2): Formateo de registros
Dominando los registros (Parte 2): Formateo de registros
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso