
Developing a multi-currency Expert Advisor (Part 19): Creating stages implemented in Python
Introduction
We considered the automation of the selection of a good group of single instances of trading strategies quite a long time ago (in part 6). At that time, we did not yet have a database that would collect the results of all test runs. We used a regular CSV file for this purpose. The main goal of that article was to test the hypothesis that automatic selection of a good group can give better results than manual selection.
We accomplished the task and the hypothesis was confirmed. So, next looked at how we could improve the results of such automatic selection. It turned out that if we split the set of all single instances into a relatively small number of clusters and make sure that instances from the same cluster do not end up in it when selecting a group, then this will help not only improve the trading results of the final EA, but also reduce the time for the selection process itself.
To perform clustering, we used a ready-made library scikit-learn for Python, or, more precisely, the implementation of the K-Means algorithm. This is not the only clustering algorithm, but considering other possible ones, comparing and choosing the best one, as applied to this problem, was beyond the acceptable limits. Therefore, essentially the first algorithm that came to hand was taken, and the results obtained using it turned out to be quite good.
However, using this particular implementation made it necessary to run a small Python program. This was not too much of a hassle when we were doing most of the operations manually. But now that we have made significant progress in automating the entire process of testing and selecting good groups of individual trading strategy instances, having even a simple manual operation in the middle of a pipeline of sequentially executed optimization tasks looks bad.
To fix this, we can take two paths. The first one is to find a ready-made MQL5 implementation of the clustering algorithm or implement it on our own. The second one involves adding the ability to launch not only EAs written in MQL5, but also Python programs at the required stages of the automatic optimization.
After some deliberation, I chose the second option. Let's get started with its implementation.
Mapping out the path
So, let's see how we can run a Python application from an MQL5 program. The most obvious ways would be the following:
- Direct launch. We can use one of the operating system functions that allows us to run an executable file with parameters. The executable file will be the Python interpreter, and the parameters will be the name of the program file and its launch parameters. The downside of this approach is the need to use external functions from DLL, but we already use them to launch the strategy tester.
- Launch via a web request. We can create a simple web server with the necessary API, responsible for running the required Python programs when requests are received from an MQL5 program via calling WebRequest(). To create a web server, we can use, for example, Flask or any other framework. The disadvantage of this approach will be that it is too complex for solving a simple problem.
Despite all the attractiveness of the second method, let's postpone its implementation for later, when the time comes to implement other related things. Ultimately, we will even be able to create a full-fledged web interface for managing the entire process of automatic optimization, turning the current Optimization.ex5 EA into MQL5 service. The service launched together with the terminal will monitor the appearance of projects in the database with the Queued status and, if such appear, will perform all queued optimization tasks for these projects. But for now we will implement the first, simpler launch option.
The next question is how to choose a method for storing the clustering results. In part 6, we placed the cluster number as a new column in the table that originally stored the results of optimization passes of single instances of the trading strategy. Then, in a similar fashion, we can add a new column to the passes table and place cluster numbers into it. But not every optimization stage implies further clustering of the results of its passes. Therefore, the column will store empty values for many rows in the passes table. This is not very good.
To avoid this, let's create a separate table that will store only the pass IDs and the cluster numbers assigned to them. At the beginning of the second stage of optimization, we simply add the data from the new table to the passes one linking them by pass IDs (id_pass) to take into account the completed clustering.
Based on the required sequence of actions during automatic optimization, the clustering stage should be performed between the first and second stages. To avoid further confusion, we will continue to use the names "first" and "second" stages for the same stages that were previously called first and second. The newly added stage will be called the stage of clustering the results of the first stage.
Then we need to do the following:
- Make changes to the Optimization.mq5 EA, so that it can run the steps implemented in Python.
- Write Python code that will accept the required parameters, load information about the passes from the database, cluster them, and save the results to the database.
- Fill the database with three stages, jobs for these stages, for different trading instruments and timeframes, and optimization tasks for these jobs, for one or more optimization criteria.
- Perform automatic optimization and evaluate the results.
Fixes
This time, no critical errors were detected, so we will focus on correcting inaccuracies that do not directly affect the final advisor obtained as a result of automatic optimization, but interfere with tracking the validity of the optimization stages and the results of single passes launched outside the optimization framework.
Let's start by adding triggers to set the start and end dates of the task (task). Now they are modified by SQL queries executed from the Optimization.mq5 EA before and after stopping the optimization in the strategy tester:
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void StartTask(ulong taskId, string setting) { ... // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing', " " start_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); } //+------------------------------------------------------------------+ //| Task completion | //+------------------------------------------------------------------+ void FinishTask(ulong taskId) { PrintFormat(__FUNCTION__" | Task ID = %d", taskId); // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Done', " " finish_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); }
The trigger logic will be simple. If the task status in the tasks table changes to Processing, set the start date (start_date) equal to the current time. If the task status changes to Done, set the end date (finish_date) to the current time. If the task status changes to Queued, then the start and end dates should be cleared. The last mentioned status change operation is not performed from the EA, but by manually modifying the status field value in the tasks table.
Here is what the implementation of these triggers might look like:
CREATE TRIGGER IF NOT EXISTS upd_task_start_date AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Processing' BEGIN UPDATE tasks SET start_date= DATETIME('NOW') WHERE id_task=NEW.id_task; END; CREATE TRIGGER IF NOT EXISTS upd_task_finish_date AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Done' BEGIN UPDATE tasks SET finish_date= DATETIME('NOW') WHERE id_task=NEW.id_task; END; CREATE TRIGGER IF NOT EXISTS reset_task_dates AFTER UPDATE ON tasks WHEN OLD.status <> NEW.status AND NEW.status = 'Queued' BEGIN UPDATE tasks SET start_date= NULL, finish_date=NULL WHERE id_task=NEW.id_task; END;
After creating such triggers, we can remove the start_date and finish_date modification from the EA leaving only the status change there.
Another minor but annoying bug was that when we manually run a single pass of the strategy tester after migrating to a new database, the current optimization task ID value defaults to 0. An attempt to insert an entry to the passes table with such an id_task value may cause an error when checking external keys if we forgot to add a special task with id_task = 0. If it is there, then everything is fine.
Therefore, let's add a trigger for the event of creating a new entry in the projects table. As soon as we create a new project, we need a stage, a job and a task for single passes to be automatically created for it. The implementation of this trigger might look like this:
CREATE TRIGGER IF NOT EXISTS insert_empty_stage AFTER INSERT ON projects BEGIN INSERT INTO stages ( id_project, name, optimization, status ) VALUES ( NEW.id_project, 'Single tester pass', 0, 'Done' ); END; DROP TRIGGER IF EXISTS insert_empty_job; CREATE TRIGGER IF NOT EXISTS insert_empty_job AFTER INSERT ON stages WHEN NEW.name = 'Single tester pass' BEGIN INSERT INTO jobs VALUES ( NULL, NEW.id_stage, NULL, NULL, NULL, 'Done' ); INSERT INTO tasks ( id_job, optimization_criterion, status ) VALUES ( (SELECT id_job FROM jobs WHERE id_stage=NEW.id_stage), -1, 'Done' ); END;
Another inaccuracy was that when we manually run a single pass of the strategy tester, the passes table (namely, the pass_date field) receives the end time of the test interval rather than the current time. This happens because we use the TimeCurrent() function in the SQL query inside the EA to set the time value. But in test mode this function returns not the real current time, but a simulated one. Therefore, if our test interval ends at the end of 2022, the pass is saved in the passes table with the end time coinciding with the end of 2022.
So, why does the passes table receive the correct current end time of all passes performed during the optimization? The answer turned out to be quite simple. The point is that during the optimization process, SQL queries for saving the results of the passes are executed by an instance of the EA launched not in the tester, but on the terminal chart in the data frame collection mode. And since it does not work in the tester, it receives the current (actual and not simulated) time from the TimeCurrent() function.
To fix this, we will add a trigger that is launched after inserting a new entry to the passes table. The trigger will set the current date:
CREATE TRIGGER IF NOT EXISTS upd_pass_date
AFTER INSERT
ON passes
BEGIN
UPDATE passes
SET pass_date = DATETIME('NOW')
WHERE id_pass = NEW.id_pass;
END;
In an SQL query that adds a new row to the passes table from the EA, remove the substitution of the current time calculated by the EA, and simply pass the constant NULL there.
Several other minor additions and corrections have been made to existing classes. In CVirtualOrder, I have added a method for changing the expiration time and a static method for checking an array of virtual orders to see if one of them has been triggered. These methods are not used yet, but may be useful in other trading strategies.
In CFactorable, I have fixed the behavior of the ReadNumber() method, so that it returns NULL when reaching the end of the initialization string, rather than repeating the output of the last number read as many times as necessary. This edit required specifying exactly as many parameters as there should be - 13 instead of 6 - in the risk manager initialization string:
// Prepare the initialization string for the risk manager string riskManagerParams = StringFormat( "class CVirtualRiskManager(\n" " 0,0,0,0,0,0,0,0,0,0,0,0,0" " )", 0 );
In the CDatabase database handling class, we have added a new static method that we will use to switch to the desired database. Basically, inside the method, we just connect to the database with the desired name and location and immediately close the connection:
static void Test(string p_fileName = NULL, int p_common = DATABASE_OPEN_COMMON) { Connect(p_fileName, p_common); Close(); };
After it is called, further calls to the Connect() method without parameters will connect to the required database.
Having finished with this non-core but necessary part, let us proceed to the implementation of the main task.
Optimization.mq5 refactoring
First of all, we will need to make changes to the Optimization.mq5 EA. In the EA, we need to add a check for the name of the file being launched (expert field) in the stages table. If the name ends in ".py", then a Python program will be run at this stage. We can place the necessary parameters for calling it in the tester_inputs field of the jobs table.
However, things do not end there. We need to somehow pass the database name, the current task ID to the Python program, and we need to somehow start it. This will lead to a noticeable increase in the EA code, and it is already quite large. So let's start by distributing the existing program code across several files.
In the main file of the Optimization.mq5 EA, we will leave only the creation of the timer and a new class COptimizer, that does the main work. All we have to do is call the timer method in its Process() handler and take care of the correct creation/deletion of this object during EA initialization/deinitialization.
sinput string fileName_ = "database911.sqlite"; // - File with the main database sinput string pythonPath_ = "C:\\Python\\Python312\\python.exe"; // - Path to Python interpreter COptimizer *optimizer; // Pointer to the optimizer object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Connect to the main database DB::Test(fileName_); // Create an optimizer optimizer = new COptimizer(pythonPath_); // Create the timer and start its handler EventSetTimer(20); OnTimer(); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert timer function | //+------------------------------------------------------------------+ void OnTimer() { // Start the optimizer handling optimizer.Process(); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { EventKillTimer(); // Remove the optimizer if(!!optimizer) { delete optimizer; } }
When creating an optimizer object, we pass a single parameter to its constructor - the full path to the Python interpreter executable file on the computer where the EA is to be launched. We specify the value of this parameter in the pythonPath_ EA input. In the future, we can get rid of this parameter by implementing an auto search for the interpreter inside the optimizer class, but for now we will limit ourselves to this simpler method.
Let's save the changes made to the Optimization.mq5 file in the current folder.
Optimizer class
Let's create the COptimizer class. Of the public methods, it will only have the main Process() handling method and constructor. In the private section, we will add a method to get the number of tasks in the execution queue and a method to get the ID of the next task in the queue. We will transfer all the work related to a specific optimization task one level lower — to the COptimizerTask new class object (optimization task). Then we will need one object of this class in the optimizer.
//+------------------------------------------------------------------+ //| Class for the project auto optimization manager | //+------------------------------------------------------------------+ class COptimizer { // Current optimization task COptimizerTask m_task; // Get the number of tasks with a given status in the queue int TotalTasks(string status = "Queued"); // Get the ID of the next optimization task from the queue ulong GetNextTaskId(); public: COptimizer(string p_pythonPath = NULL); // Constructor void Process(); // Main processing method };
I took the code of the TotalTasks() and GetNextTaskId() methods from the appropriate functions of the previous version of the Optimization.mq5 EA almost without changes. The same can be said about the Process() method the code migrated to from the OnTimer() function. But it still had to be changed more significantly, since we introduced a new class for the optimization task. Overall, the code for this method has become even clearer:
//+------------------------------------------------------------------+ //| Main handling method | //+------------------------------------------------------------------+ void COptimizer::Process() { PrintFormat(__FUNCTION__" | Current Task ID = %d", m_task.Id()); // If the EA is stopped, remove the timer and the EA itself from the chart if (IsStopped()) { EventKillTimer(); ExpertRemove(); return; } // If the current task is completed, if (m_task.IsDone()) { // If the current task is not empty, if(m_task.Id()) { // Complete the current task m_task.Finish(); } // Get the number of tasks in the queue int totalTasks = TotalTasks("Processing") + TotalTasks("Queued"); // If there are tasks, then if(totalTasks) { // Get the ID of the next current task ulong taskId = GetNextTaskId(); // Load the optimization task parameters from the database m_task.Load(taskId); // Launch the current task m_task.Start(); // Display the number of remaining tasks and the current task on the chart Comment(StringFormat( "Total tasks in queue: %d\n" "Current Task ID: %d", totalTasks, m_task.Id())); } else { // If there are no tasks, remove the EA from the chart PrintFormat(__FUNCTION__" | Finish.", 0); ExpertRemove(); } } }
As you can see, at this level of abstraction it makes no difference what kind of task needs to be performed next time - running the optimization of some EA in the tester or a program in Python. The sequence of actions will be the same: while there are tasks in the queue, we load the parameters of the next task, launch it for execution and wait until it is completed. After completion, repeat the above steps until the task queue is empty.
Let's save the changes made to the COptimizer.mqh file in the current folder.
Optimization task class
We have left the most interesting thing for the COptimizerTask class. It is in this directory that the Python interpreter will be directly launched and the written Python program will be passed to it for execution. So at the beginning of the file with this class we import the system function for running files:
// Function to launch an executable file in the operating system #import "shell32.dll" int ShellExecuteW(int hwnd, string lpOperation, string lpFile, string lpParameters, string lpDirectory, int nShowCmd); #import
In the class itself, we will have several fields to store the necessary parameters of the optimization task, such as type, ID, EA, optimization interval, symbol, timeframe, and others.
//+------------------------------------------------------------------+ //| Optimization task class | //+------------------------------------------------------------------+ class COptimizerTask { enum { TASK_TYPE_UNKNOWN, TASK_TYPE_EX5, TASK_TYPE_PY } m_type; // Task type (MQL5 or Python) ulong m_id; // Task ID string m_setting; // String for initializing the EA parameters for the current task string m_pythonPath; // Full path to the Python interpreter // Data structure for reading a single string of a query result struct params { string expert; int optimization; string from_date; string to_date; int forward_mode; string forward_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } m_params; // Get the full or relative path to a given file in the current folder string GetProgramPath(string name, bool rel = true); // Get initialization string from task parameters void Parse(); // Get task type from task parameters void ParseType(); public: // Constructor COptimizerTask() : m_id(0) {} // Task ID ulong Id() { return m_id; } // Set the full path to the Python interpreter void PythonPath(string p_pythonPath) { m_pythonPath = p_pythonPath; } // Main method void Process(); // Load task parameters from the database void Load(ulong p_id); // Start the task void Start(); // Complete the task void Finish(); // Task completed? bool IsDone(); };
That part of the parameters, that we will receive directly from the database using the Load() method, is to be stored in the m_params structure. Based on these values, we will determine the task type using the ParseType() method by checking the ending of the file name:
//+------------------------------------------------------------------+ //| Get task type from task parameters | //+------------------------------------------------------------------+ void COptimizerTask::ParseType() { string ext = StringSubstr(m_params.expert, StringLen(m_params.expert) - 3); if(ext == ".py") { m_type = TASK_TYPE_PY; } else if (ext == "ex5") { m_type = TASK_TYPE_EX5; } else { m_type = TASK_TYPE_UNKNOWN; } }
We will also generate a string for initializing testing or running a Python program using the Parse() method. In this string, we will form a parameter string either for the strategy tester, or for running a Python program depending on the specific task type:
//+------------------------------------------------------------------+ //| Get initialization string from task parameters | //+------------------------------------------------------------------+ void COptimizerTask::Parse() { // Get the task type from the task parameters ParseType(); // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Generate a parameter string for the tester m_setting = StringFormat( "[Tester]\r\n" "Expert=%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=%d\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=%d\r\n" "ForwardDate=%s\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d\r\n" "fileName_=%s\r\n" "%s\r\n", GetProgramPath(m_params.expert), m_params.symbol, m_params.period, m_params.optimization, m_params.from_date, m_params.to_date, m_params.forward_mode, m_params.forward_date, m_params.optimization_criterion, m_params.id_task, DB::FileName(), m_params.tester_inputs ); // If this is a task to launch a Python program } else if (m_type == TASK_TYPE_PY) { // Form a program launch string on Python with parameters m_setting = StringFormat("\"%s\" \"%s\" %I64u %s", GetProgramPath(m_params.expert, false), // Python program file DB::FileName(true), // Path to the database file m_id, // Task ID m_params.tester_inputs // Launch parameters ); } }
The Start() method is responsible for starting the task. In the method, we again look at the task type and, depending on it, either run optimization in the tester or run the Python program by calling the ShellExecuteW() system:
//+------------------------------------------------------------------+ //| Start task | //+------------------------------------------------------------------+ void COptimizerTask::Start() { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", m_id, m_setting); // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Launch a new optimization task in the tester MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(m_setting); MTTESTER::ClickStart(); // Update the task status in the database DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing' " " WHERE id_task=%d", m_id); DB::Execute(query); DB::Close(); // If this is a task to launch a Python program } else if (m_type == TASK_TYPE_PY) { PrintFormat(__FUNCTION__" | SHELL EXEC: %s", m_pythonPath); // Call the system function to launch the program with parameters ShellExecuteW(NULL, NULL, m_pythonPath, m_setting, NULL, 1); } }
Checking the execution of a task comes down to either checking the state of the strategy tester (stopped or not), or checking the status of the task in the database by the current ID:
//+------------------------------------------------------------------+ //| Task completed? | //+------------------------------------------------------------------+ bool COptimizerTask::IsDone() { // If there is no current task, then everything is done if(m_id == 0) { return true; } // Result bool res = false; // If this is the EA optimization task if(m_type == TASK_TYPE_EX5) { // Check if the strategy tester has finished its work res = MTTESTER::IsReady(); // If this is a task to run a Python program, then } else if(m_type == TASK_TYPE_PY) { // Request to get the status of the current task string query = StringFormat("SELECT status " " FROM tasks" " WHERE id_task=%I64u;", m_id); // Open the database if(DB::Connect()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string status; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { // Check if the status is Done res = (row.status == "Done"); } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } } else { res = true; } return res; }
Save the changes made to the COptimizerTask.mqh file in the current folder.
Clustering program
Now it is time for that very Python program I have already mentioned many times. In general, the part of it that does the main work has already been developed in Part 6. Let's take a look at it:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df = df.sort_values(['cluster', 'Sharpe Ratio']).groupby('cluster').agg('last').reset_index()
clusters = df.cluster
df = df.iloc[:, 1:]
df['cluster'] = clusters
df.to_csv('Params_SV_EURGBP_H1-one_cluster.csv', index=False
We need to change the following in it:
- add the ability to pass clarifying parameters via command line arguments (database name, task ID, number of clusters, etc.);
- use information from the passes table instead of a CSV file;
- add setting the start and end status of the task execution in the database;
- change the composition of the fields used for clustering, since we do not have separate columns for each EA input parameter in the passes table;
- reduce the number of fields in the final table, since we essentially only need to know the relationship between the cluster number and the pass ID;
- save the results to a new database table instead of saving the results to another file.
To implement all of the above, we will need to connect additional modules - argparse and sqlite3:
import pandas as pd
from sklearn.cluster import KMeans
import sqlite3
import argparse
The ArgumentParser class object is to parse the inputs passed via command line arguments. We will save the read values in separate variables for ease of further use:
# Setting up the command line argument parser parser = argparse.ArgumentParser(description='Clustering passes for previous job(s)') parser.add_argument('db_path', type=str, help='Path to database file') parser.add_argument('id_task', type=int, help='ID of current task') parser.add_argument('--id_parent_job', type=str, help='ID of parent job(s)') parser.add_argument('--n_clusters', type=int, default=256, help='Number of clusters') parser.add_argument('--min_custom_ontester', type=float, default=0, help='Min value for `custom_ontester`') parser.add_argument('--min_trades', type=float, default=40, help='Min value for `trades`') parser.add_argument('--min_sharpe_ratio', type=float, default=0.7, help='Min value for `sharpe_ratio`') # Read the values of command line arguments into variables args = parser.parse_args() db_path = args.db_path id_task = args.id_task id_parent_job = args.id_parent_job n_clusters = args.n_clusters min_custom_ontester = args.min_custom_ontester min_trades = args.min_trades min_sharpe_ratio = args.min_sharpe_ratio
Next, we will connect to the database, mark the current task as running, and create (if not available) a new table to save the clustering results. If this task is run again, you need to take care to clear previously saved results:
# Establishing a connection to the database
connection = sqlite3.connect(db_path)
cursor = connection.cursor()
# Mark the start of the task
cursor.execute(f'''UPDATE tasks SET status='Processing' WHERE id_task={id_task};''')
connection.commit()
# Create a table for clustering results if there is none
cursor.execute('''CREATE TABLE IF NOT EXISTS passes_clusters (
id_task INTEGER,
id_pass INTEGER,
cluster INTEGER
);''')
# Clear the results table from previously obtained results
cursor.execute(f'''DELETE FROM passes_clusters WHERE id_task={id_task};''')
Then we form an SQL query to obtain data on the required optimization passes and load them from the database directly into the dataframe:
# Load data about parent job passes for this task into the dataframe
query = f'''SELECT p.*
FROM passes p
JOIN
tasks t ON t.id_task = p.id_task
JOIN
jobs j ON j.id_job = t.id_job
WHERE p.profit > 0 AND
j.id_job IN ({id_parent_job}) AND
p.custom_ontester >= {min_custom_ontester} AND
p.trades >= {min_trades} AND
p.sharpe_ratio >= {min_sharpe_ratio};'''
df = pd.read_sql(query, connection)
# Let's look at the dataframe
print(df)
# List of dataframe columns
print(*enumerate(df.columns), sep='\n')
Having seen the list of columns in the dataframe, we will select some of them for clustering. Since we do not have separate columns for inputs of trading strategy instances, we will perform clustering by various statistical results of passes (profit, number of transactions, drawdown, profit factor, etc.). The numbers of the selected columns will be specified in the iloc[] method parameters. After clustering, we group the dataframe rows by each cluster and leave only one row for the cluster with the highest value of normalized average annual profit:
# Run clustering on some columns of the dataframe kmeans = KMeans(n_clusters=n_clusters, n_init='auto', random_state=42).fit(df.iloc[:, [7, 8, 9, 24, 29, 30, 31, 32, 33, 36, 45, 46]]) # Add cluster numbers to the dataframe df['cluster'] = kmeans.labels_ # Set the current task ID df['id_task'] = id_task # Sort the dataframe by clusters and normalized profit df = df.sort_values(['cluster', 'custom_ontester']) # Let's look at the dataframe print(df) # Group the lines by cluster and take one line at a time # with the highest normalized profit from each cluster df = df.groupby('cluster').agg('last').reset_index()
After this, we leave only three columns in the dataframe, for which we created the results table: id_task, id_pass and cluster. We left the first one so that we could clear previous clustering results when running the program again with the same id_task value.
# Let's leave only id_task, id_pass and cluster columns in the dataframe df = df.iloc[:, [2, 1, 0]] # Let's look at the dataframe print(df)
We save the dataframe in the mode of adding data to an existing table, mark the completion of the task, and close the connection to the database:
# Save the dataframe to the passes_clusters table (replacing the existing one)
df.to_sql('passes_clusters', connection, if_exists='append', index=False)
# Mark the task completion
cursor.execute(f'''UPDATE tasks SET status='Done' WHERE id_task={id_task};''')
connection.commit()
# Close the connection
connection.close()
Save the changes made to the ClusteringStage1.py file in the current folder.
Second stage EA
Now that we have a program for clustering the results of the first stage of optimization, all that remains is to implement support for using the obtained results by the optimization second stage EA. We will try to do this with minimal costs.
Previously, we used a separate EA, but now we will make it so that the second stage can be carried out without preliminary clustering and with clustering using the same EA. Let's add the useClusters_ logical parameter, which answers the question of whether it is necessary to use the clustering results when selecting groups from single instances of trading strategies obtained at the first stage.
If the clustering results need to be used, we simply add joining the passes_clusters table by pass IDs to the SQL query that receives the list of single instances of trading strategies. In this case, we will get only one pass for each cluster as a result of the query.
Along the way, we will add several more parameters as inputs of the EA, in which we will be able to set additional conditions for selecting passes by normalized average annual profit, number of transactions and Sharpe ratio.
Then we only need to make changes to the list of inputs and the CreateTaskDB() function:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput int idTask_ = 0; // - Optimization task ID sinput string fileName_ = "db.sqlite"; // - Main database file input group "::: Selection for the group" input int idParentJob_ = 1; // - Parent job ID input bool useClusters_ = true; // - Use clustering input double minCustomOntester_ = 0; // - Min normalized profit input int minTrades_ = 40; // - Min number of trades input double minSharpeRatio_ = 0.7; // - Min Sharpe ratio input int count_ = 16; // - Number of strategies in the group (1 .. 16) ... //+------------------------------------------------------------------+ //| Creating a database for a separate stage task | //+------------------------------------------------------------------+ void CreateTaskDB(const string fileName, const int idParentJob) { // Create a new database for the current optimization task DB::Connect(PARAMS_FILE, 0); DB::Execute("DROP TABLE IF EXISTS passes;"); DB::Execute("CREATE TABLE passes (id_pass INTEGER PRIMARY KEY AUTOINCREMENT, params TEXT);"); DB::Close(); // Connect to the main database DB::Connect(fileName); // Clustering string clusterJoin = ""; if(useClusters_) { clusterJoin = "JOIN passes_clusters pc ON pc.id_pass = p.id_pass"; } // Request to obtain the required information from the main database string query = StringFormat("SELECT DISTINCT p.params" " FROM passes p" " JOIN " " tasks t ON p.id_task = t.id_task " " JOIN " " jobs j ON t.id_job = j.id_job " " %s " "WHERE (j.id_job = %d AND " " p.custom_ontester >= %.2f AND " " trades >= %d AND " " p.sharpe_ratio >= %.2f) " "ORDER BY p.custom_ontester DESC;", clusterJoin, idParentJob_, minCustomOntester_, minTrades_, minSharpeRatio_); // Execute the request ... }
Save the changes made to the SimpleVolumesStage2.mq5 file in the current folder and launch the test.
Test
Let's create four stages in the database for our project with the names "First", "Clustering passes from first stage", "Second" and "Second with clustering". For each stage, we will create two jobs for the EURGBP and GBPUSD symbols on the H1 timeframe. For the first stage, we will create three optimization tasks with different criteria (complex, maximum profit and custom). For the remaining jobs, we will create one task each. We will take the period from 2018 to 2023 as the optimization interval. For each job, we will indicate the correct input values.
As a result, we should have information in our database that generates the following results from the query below:
SELECT t.id_task,
t.optimization_criterion,
s.name AS stage_name,
s.expert AS stage_expert,
j.id_job,
j.symbol AS job_symbol,
j.period AS job_period,
j.tester_inputs AS job_tester_inputs
FROM tasks t
JOIN
jobs j ON j.id_job = t.id_job
JOIN
stages s ON s.id_stage = j.id_stage
WHERE t.id_task > 0;
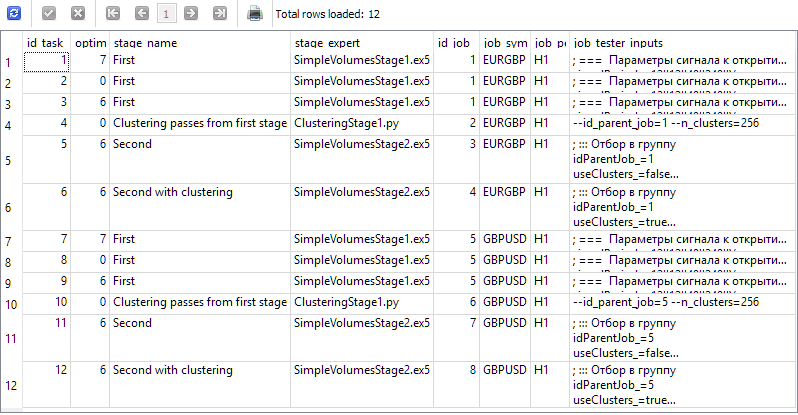
Launch the Optimization.ex5 EA on the terminal chart and wait until all tasks are completed. For this amount of computation, 33 agents completed all stages in about 17 hours.
For EURGBP, the best group found without clustering had roughly the same normalized average annual return as when clustering was used (approximately USD 4060). But for GBPUSD, the difference between these two options for conducting the second stage of optimization turned out to be more noticeable. Without clustering, the obtained value of normalized average annual profit was USD 4500, and with clustering - USD 7500.
This difference in results for two different symbols seems a bit strange, but quite possible. We will not delve into the search for the reasons for such a difference now, instead leaving it for a later time, when we will use a larger number of symbols and timeframes in auto optimization.
Here is what the best group results look like for both symbols:
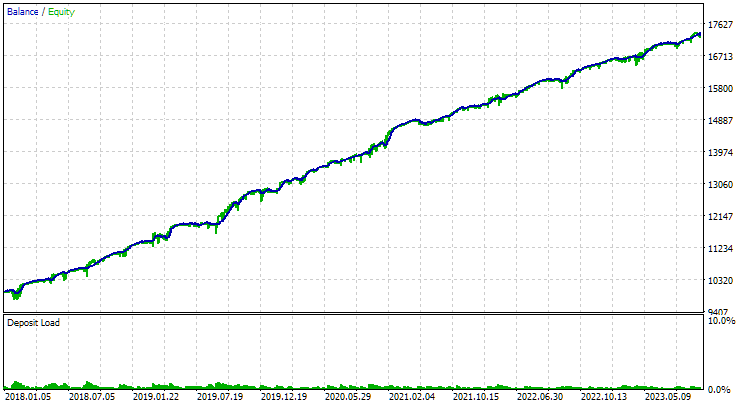
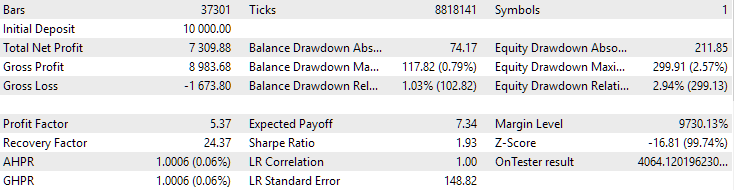
Fig. 1. Results of the best group in the second stage with clustering for EURGBP H1
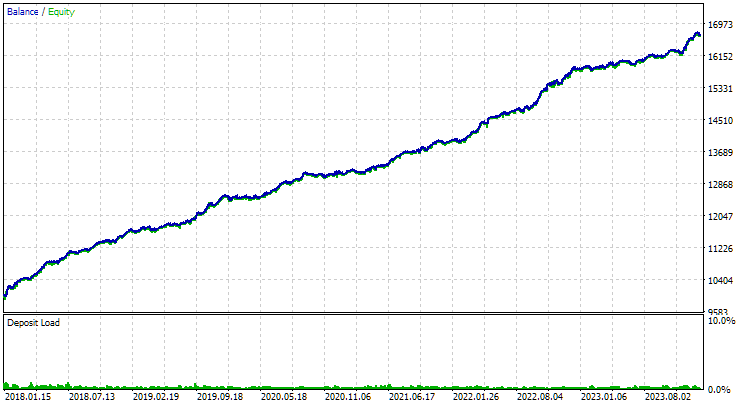
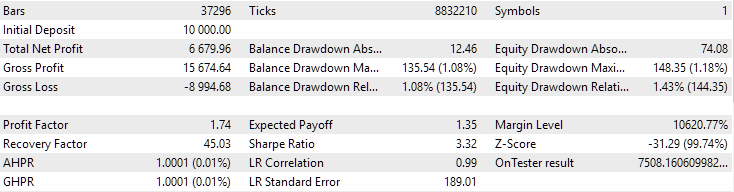
Fig. 2. Results of the best group in the second stage with clustering for GBPUSD H1
There is yet another interesting question I want to raise. We perform clustering and from each cluster we take one best single instance of the trading strategy (tester pass). In this way, we form a list of good specimens, from which we will select the best group. If we did clustering for 256 clusters, then this list will include 256 instances. In the second stage of optimization, we will select some 16 instances out of 256 to combine into one group. Is it possible to skip the second stage and just take 16 single copies of the trading strategy from different clusters with the highest normalized average annual profit?
If this can be done, it will significantly reduce the time spent on auto optimization. After all, during optimization at the second stage, we launch an EA with 16 copies of what is being optimized at the first stage. Therefore, one test run takes proportionally more time.
For the set of optimization problems considered in this article, we could reduce the time by approximately 6 hours. This is a significant proportion of the 17 hours spent. And if we take into account that we added two second-stage optimization tasks without clustering just to compare their results with the results of the second stage with clustering, then the relative reduction in time will be even more significant.
To answer this question, let's look at the results of a query that selects single instances for the second stage before it starts. For clarity, we will add the index, under which each instance will be taken in the second stage, the ID of the passage of this instance in the first stage, the cluster number and the value of the normalized average annual profit to the list of columns. We get the following:
SELECT DISTINCT ROW_NUMBER() OVER (ORDER BY custom_ontester DESC) AS [index], p.id_pass, pc.cluster, p.custom_ontester, p.params FROM passes p JOIN tasks t ON p.id_task = t.id_task JOIN jobs j ON t.id_job = j.id_job JOIN passes_clusters pc ON pc.id_pass = p.id_pass WHERE (j.id_job = 5 AND p.custom_ontester >= 0 AND trades >= 40 AND p.sharpe_ratio >= 0.7) ORDER BY p.custom_ontester DESC;
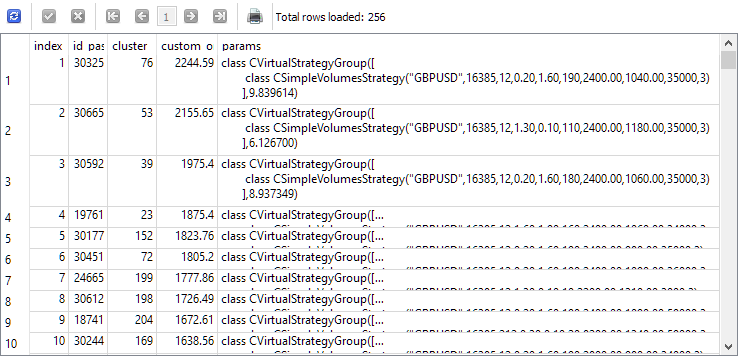
As we can see, the single instances with the highest normalized average annual profit have the smallest index values. Therefore, if we take a group of single instances with indices from 1 to 16, we will get exactly the group that we wanted to collect for comparison with the best group obtained as a result of the second optimization stage.
Let's use the second stage EA, specifying numbers from 1 to 16 in the input parameters of instance indices. We get the following picture:
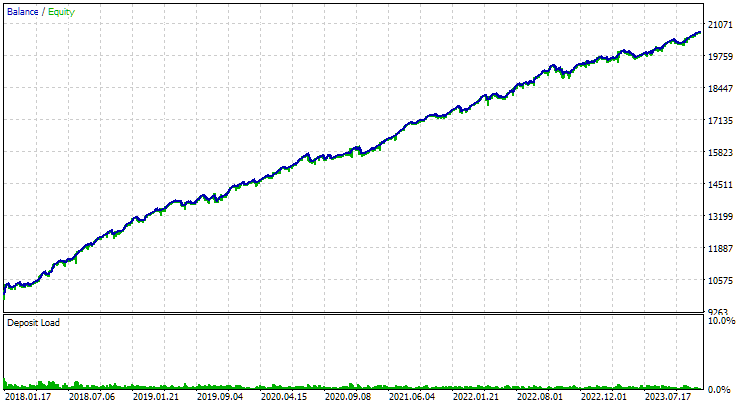
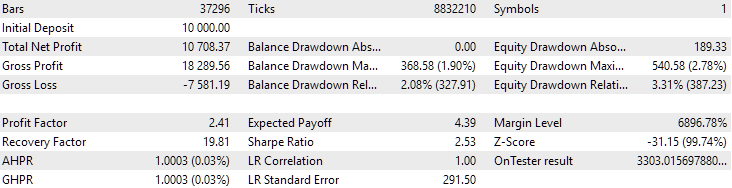
Fig. 3. Results of the top 16 samples with the highest normalized average annual return for GBPUSD H1
The graph looks similar in nature to the graph in Figure 2, but the value of the normalized average annual profit has become more than two times smaller: USD 3300 versus USD 7500. This is due to the much larger drawdown observed for this group compared to the drawdown of the best group in Figure 2. A similar situation is observed for EURGBP, although for this symbol the decrease in the normalized average annual profit was somewhat smaller, but still significant.
So it looks like we will not be able to save time on the second stage optimization this way.
Finally, let's look at the results of combining the two best groups found:
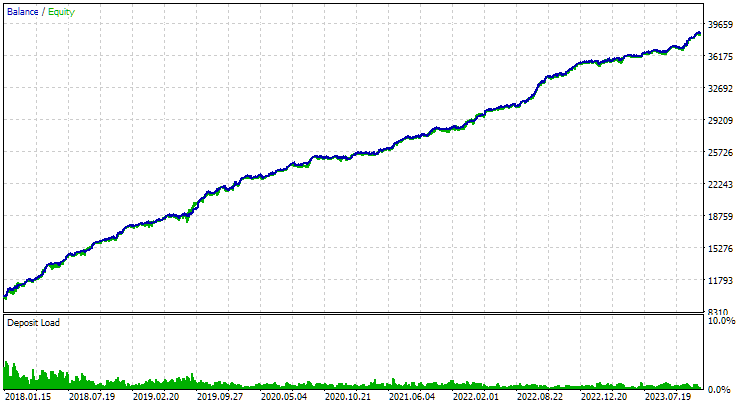
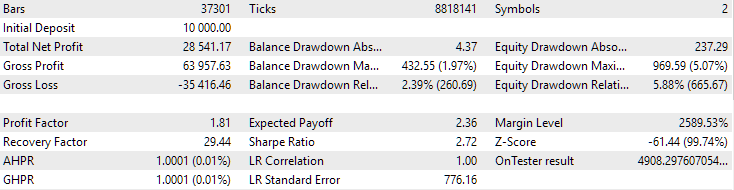
Fig. 4. Results of the joint work of the two best groups for EURGBP H1 and GBPUSD H1
As we can see, all the resulting parameters turned out to be somewhere between the parameter values for individual groups. For example, the normalized average annual profit was USD 4900, which is more than the value of this parameter for the EURGBP H1 group, but less than for the GBPUSD H1 group.
Conclusion
So, let's look at what we got. We have added the ability to create auto optimization steps that can run third-party applications, namely Python programs. However, if necessary, we can now, with minimal effort, add support for running programs in other interpreted languages, or simply any compiled programs.
So far, we have used this feature to reduce the number of single instances of trading strategies from the first stage of optimization that participate in the second stage. To do this, we divided all the instances into a relatively small number of clusters and took only one instance from each cluster. Reducing the number of copies somewhat reduced the time required to complete the second stage, and the results either did not deteriorate or became significantly better. So the work was not in vain.
However, there is still room for further progress. Improvement of the clustering program may consist in correct handling of situations when the number of clusters selected for single instances is less than the number of clusters. Now this will cause to an error. We can also look towards expanding the range of trading strategies and convenient organization of auto optimization projects. But more about that next time.
Thank you for your attention! See you soon!
All results presented in this article and all previous articles in the series are based only on historical testing data and are not a guarantee of any profit in the future. The work within this project is of a research nature. All published results can be used by anyone at their own risk.
Archive contents
| # | Name | Version | Description | Recent changes |
|---|---|---|---|---|
| MQL5/Experts/Article.15911 | ||||
| 1 | Advisor.mqh | 1.04 | EA base class | Part 10 |
| 2 | ClusteringStage1.py | 1.00 | Program for clustering the results of the first stage of optimization | Part 19 |
| 3 | Database.mqh | 1.07 | Class for handling the database | Part 19 |
| 4 | database.sqlite.schema.sql | — | Database structure | Part 19 |
| 5 | ExpertHistory.mqh | 1.00 | Class for exporting trade history to file | Part 16 |
| 6 | ExportedGroupsLibrary.mqh | — | Generated file listing strategy group names and the array of their initialization strings | Part 17 |
| 7 | Factorable.mqh | 1.02 | Base class of objects created from a string | Part 19 |
| 8 | GroupsLibrary.mqh | 1.01 | Class for working with a library of selected strategy groups | Part 18 |
| 9 | HistoryReceiverExpert.mq5 | 1.00 | EA for replaying the history of deals with the risk manager | Part 16 |
| 10 | HistoryStrategy.mqh | 1.00 | Class of the trading strategy for replaying the history of deals | Part 16 |
| 11 | Interface.mqh | 1.00 | Basic class for visualizing various objects | Part 4 |
| 12 | LibraryExport.mq5 | 1.01 | EA that saves initialization strings of selected passes from the library to the ExportedGroupsLibrary.mqh file | Part 18 |
| 13 | Macros.mqh | 1.02 | Useful macros for array operations | Part 16 |
| 14 | Money.mqh | 1.01 | Basic money management class | Part 12 |
| 15 | NewBarEvent.mqh | 1.00 | Class for defining a new bar for a specific symbol | Part 8 |
| 16 | Optimization.mq5 | 1.03 | EA managing the launch of optimization tasks | Part 19 |
| 17 | Optimizer.mqh | 1.00 | Class for the project auto optimization manager | Part 19 |
| 18 | OptimizerTask.mqh | 1.00 | Optimization task class | Part 19 |
| 19 | Receiver.mqh | 1.04 | Base class for converting open volumes into market positions | Part 12 |
| 20 | SimpleHistoryReceiverExpert.mq5 | 1.00 | Simplified EA for replaying the history of deals | Part 16 |
| 21 | SimpleVolumesExpert.mq5 | 1.20 | EA for parallel operation of several groups of model strategies. The parameters will be taken from the built-in group library. | Part 17 |
| 22 | SimpleVolumesStage1.mq5 | 1.18 | Trading strategy single instance optimization EA (stage 1) | Part 19 |
| 23 | SimpleVolumesStage2.mq5 | 1.02 | Trading strategies instances group optimization EA (stage 2) | Part 19 |
| 24 | SimpleVolumesStage3.mq5 | 1.01 | The EA that saves a generated standardized group of strategies to a library of groups with a given name. | Part 18 |
| 25 | SimpleVolumesStrategy.mqh | 1.09 | Class of trading strategy using tick volumes | Part 15 |
| 26 | Strategy.mqh | 1.04 | Trading strategy base class | Part 10 |
| 27 | TesterHandler.mqh | 1.05 | Optimization event handling class | Part 19 |
| 28 | VirtualAdvisor.mqh | 1.07 | Class of the EA handling virtual positions (orders) | Part 18 |
| 29 | VirtualChartOrder.mqh | 1.01 | Graphical virtual position class | Part 18 |
| 30 | VirtualFactory.mqh | 1.04 | Object factory class | Part 16 |
| 31 | VirtualHistoryAdvisor.mqh | 1.00 | Trade history replay EA class | Part 16 |
| 32 | VirtualInterface.mqh | 1.00 | EA GUI class | Part 4 |
| 33 | VirtualOrder.mqh | 1.07 | Class of virtual orders and positions | Part 19 |
| 34 | VirtualReceiver.mqh | 1.03 | Class for converting open volumes to market positions (receiver) | Part 12 |
| 35 | VirtualRiskManager.mqh | 1.02 | Risk management class (risk manager) | Part 15 |
| 36 | VirtualStrategy.mqh | 1.05 | Class of a trading strategy with virtual positions | Part 15 |
| 37 | VirtualStrategyGroup.mqh | 1.00 | Class of trading strategies group(s) | Part 11 |
| 38 | VirtualSymbolReceiver.mqh | 1.00 | Symbol receiver class | Part 3 |
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/15911
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
I run this
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1. py.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
and get this error
ValueError: n_samples=150 should be >= n_clusters=256.
then i change n_clusters=150 and run
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=150
and i think worked. but in database not any change
after that i try optimize with n_samples=150 but dont worked
I run this
...
and i think worked. but in database not any change
There is no new table passes_clusters in database?
There is no new table passes_clusters in database?
It worked correctly.
The error was related to the database.
After correcting the database, the Python code and Stage 2 worked well.
Thank you for your help.
Interesting article! I'll read the whole series, then.
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
Why did they abandon the functionality of the AlgLib library?
#include <Math\Alglib\alglib.mqh>Minus only in speed, but mainly because python parallelises calculations on all cores.