
Desarrollamos un asesor experto multidivisa (Parte 18): Automatización de la selección de grupos considerando el periodo forward
Introducción
En un artículo anterior de esta serie (en la parte 7), analizamos la selección de un grupo de instancias individuales de estrategias comerciales para mejorar el rendimiento cuando estas trabajan juntas. Para la selección, utilizamos dos métodos. En el primer enfoque, la selección de grupos se realizó usando los resultados de optimización obtenidos durante todo el intervalo temporal de optimización. En el grupo tratamos de tomar aquellas instancias únicas que mostraban los mejores resultados en el intervalo de optimización. En el segundo enfoque, extrajimos un pequeño fragmento del intervalo temporal de optimización, en el que no se realizó ninguna optimización de instancia única. El fragmento seleccionado del intervalo temporal se utilizó entonces en la selección de grupos: intentamos incluir en el grupo aquellas instancias individuales que mostraban buenos resultados (pero no los mejores) en el intervalo de optimización y que, al mismo tiempo, mostraban aproximadamente los mismos resultados en el fragmento seleccionado del intervalo temporal.
Al final, los resultados fueron los siguientes:
- No observamos una ventaja clara de la selección con el primer método sobre el segundo. Esto puede deberse al corto intervalo temporal de la historia en el que comparamos los resultados de ambos métodos. Aun así, tres meses no es tiempo suficiente para evaluar una estrategia que pueda tener periodos más largos de estancamiento.
- El segundo método ha demostrado que en el fragmento de intervalo temporal seleccionado los resultados son mejores si aplicamos la selección en un grupo según el algoritmo de búsqueda de instancias únicas de estrategias comerciales que estén próximas entre sí en cuanto a los resultados. Si los seleccionamos simplemente según el mejor rendimiento posible en el intervalo de optimización (como en el primer método, pero solo en un intervalo más corto), los resultados del grupo seleccionado resultan notablemente peores.
- Podemos combinar ambos métodos, es decir, construir dos grupos seleccionados con métodos diferentes y luego combinar los dos grupos obtenidos en uno solo.
En la parte 13, implementamos la automatización de la segunda etapa de optimización, que implicaba la selección de instancias individuales de estrategias comerciales obtenidas en la primera etapa en un grupo. Para ello, aplicamos una búsqueda simple utilizando el algoritmo genético del optimizador interno en el simulador de estrategias. Aún no hemos realizado ninguna clasificación previa de instancias individuales (tema tratado en la parte 6). De esta forma, hemos automatizado la selección de grupos de la primera manera. Por ahora no habíamos llegado a la aplicación de la selección de grupos de la segunda manera, pero ahora es el momento de volver a este tema. En el marco de este artículo trataremos de implementar la selección automatizada de instancias individuales de estrategias comerciales en grupos, teniendo en cuenta su comportamiento en el periodo forward.
Trazando el camino
Como siempre, primero veremos lo que ya tenemos y lo que nos falta para la tarea a realizar. Podemos fijarnos la tarea de optimizar una estrategia comercial en cualquier intervalo temporal que deseemos. Las palabras "fijarnos la tarea" deben tomarse al pie de la letra: para ello, crearemos las entradas necesarias en la tabla (tasks) de nuestra base de datos. En consecuencia, realizar hacer primero la optimización en un intervalo temporal (por ejemplo, de 2018 a 2022, ambos inclusive) y después en otro intervalo (por ejemplo, para 2023).
Pero con este planteamiento no podremos utilizar los resultados de la forma deseada. En cada uno de los dos intervalos temporales, la optimización se realizará de forma independiente, por lo que no habrá nada que comparar entre ellas: las pasadas de la segunda optimización no repetirán las pasadas de la primera en cuanto a los valores de los parámetros de entrada. Y lo anterior resulta válido para la optimización genética que utilizaremos. Está claro que esto no es cierto para la optimización completa, pero nunca la hemos usado y probablemente no la utilizaremos en el futuro debido al gran número de combinaciones de parámetros optimizados.
Por ello, tendremos que implicar la ejecución del proceso de optimización con el periodo forward especificado. En este caso, el simulador usará las mismas combinaciones de parámetros de entrada en el periodo anterior que en el periodo principal. Pero aún no hemos probado a ejecutar la optimización automática con un periodo forward, y no sabemos cómo llegarán estos resultados a nuestra base de datos. ¿Podremos distinguir entonces entre pasadas dentro del periodo principal y pasadas en el periodo anterior? Tendremos que comprobarlo.
Una vez estemos seguros de que disponemos en la base de datos de toda la información necesaria sobre las pasadas tanto para el periodo principal como para el periodo forward, podremos pasar a la siguiente etapa. En la parte 7, una vez obtenidos estos resultados, los analizaremos y cribaremos manualmente utilizando Excel para ello. Sin embargo, en el contexto de la automatización, su uso parece ineficiente. Aun así, intentaremos evitar cualquier manipulación manual de los datos durante la obtención del EA final. Afortunadamente, todas las acciones que efectuamos en Excel (recálculo de algunos resultados, cálculo de relaciones de indicadores para diferentes periodos de prueba, búsqueda de la puntuación final para cada grupo de estrategias y clasificación según esta) se pueden realizar en el programa MQL5 usando consultas SQL a nuestra base de datos o ejecutando un script en Python.
Una vez clasificados según la puntuación final, solo tomaremos el grupo más alto en el EA final. Realizaremos acciones similares para todas las combinaciones de símbolos y marcos temporales seleccionados. Tras normalizar el grupo global para incluir los mejores grupos para todos los pares símbolo-marco temporal, el EA final estará listo.
Vamos a comenzar con la implementación, pero primero corregiremos un error que hemos descubierto.
Solucionamos un error de almacenamiento
Al desarrollar el EA para automatizar la primera etapa (optimización de instancias individuales de estrategias comerciales), usamos una sola base de datos. Así que no había duda de qué base de datos debíamos recuperar o en qué base guardar los datos. En la segunda fase de optimización, añadimos una nueva base de datos auxiliar que contenía el mínimo necesario de esencia de la base de datos principal. Esta versión reducida de la base de datos se envió a los agentes de pruebas en el marco de la segunda fase de optimización.
Pero debido al enfoque ya elegido al implementar la clase de base de datos estática, tuvimos que utilizar una solución algo incómoda que nos permitiera cambiar el nombre de la base de datos si fuera necesario. Después de cambiar el nombre, todas las llamadas posteriores al método de conexión a la base de datos utilizaban el nuevo nombre. De ahí el error al sumar los resultados de la pasada en la segunda y la tercera etapa. La razón era la falta de conmutación de regreso a la base principal en todos los lugares donde era necesario.
Para solucionarlo, hemos añadido a cada asesor de etapas y al asesor de optimización automática de proyectos un parámetro de entrada adicional que especifica el nombre de la base de datos principal. Además de eliminar el error, esto resulta útil porque podemos separar mejor las bases de datos que se utilizan en diferentes artículos. Por ejemplo, en esta parte se utilizaba una nueva base de datos maestra porque decidimos reducir la composición de los problemas de optimización, pero no queríamos limpiar la base de datos existente:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput string fileName_ = "database683.sqlite"; // - File with the main database
En la función OnInit() del asesor experto de la segunda etapa SimpleVolumesStage2.mq5, dentro de la llamada de la función LoadParams() había una conexión a la base de datos auxiliar, porque los datos sobre los parámetros de entrada de las instancias individuales de estrategias comerciales para la conexión al grupo deben tomarse de ella. Tras finalización la pasada, se llamaba a la función OnTester(), en la que se debía realizar el guardado de los resultados de la pasada del grupo ya en la base de datos principal. Pero como no se volvía a la base de datos principal, los resultados completos de la pasada (48 columnas) intentaban insertarse en una tabla de la base de datos auxiliar (2 columnas).
Por lo tanto, añadimos el interruptor faltante a la base de datos principal en la función OnInit() del EA de la segunda etapa SimpleVolumesStage2.mq5:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ... // Load strategy parameter sets string strategiesParams = LoadParams(indexes); // Connect to the main database DB::Connect(fileName_); DB::Close(); ... // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
En los asesores expertos de optimización de la primera y la tercera etapa que no utilizan la base de datos auxiliar, añadimos a la primera llamada del método de conexión a la base de datos el nombre de la base de datos tomado del nuevo parámetro de entrada del asesor experto:
DB::Connect(fileName_)
Otro tipo de error que encontramos se producía cuando, una vez terminada, queríamos ejecutar una de nuestras pasadas favoritas por separado. La pasada se iniciaba y ejecutaba con normalidad, pero sus resultados no se introducían en la base de datos. La razón era que en ese inicio el identificador de la tarea seguía siendo igual a 0, mientras que en la base de datos solo se puede escribir en la tabla passes una fila con el identificador de una tarea existente en la tabla tasks.
Esto puede corregirse haciendo que el ID de la tarea tome un valor de los parámetros de entrada del asesor experto (de donde proviene cuando se optimiza), o añadiendo una tarea ficticia con un ID 0 a la base de datos. Al final, hemos elegido la segunda opción para que nuestras pasadas individuales ejecutadas manualmente no se contabilicen como pasadas realizadas como parte de una tarea de optimización concreta. Para la tarea ficticia añadida, ha sido necesario especificar cualquier ID de una tarea existente para no violar las restricciones de las claves externas y el estado "Done" para que esta tarea no se ejecutara durante la optimización automática.
Una vez hechas estas correcciones, podemos volver a la tarea principal.
Preparación del código y la base de datos
Tomaremos una copia de una base de datos existente y la limpiaremos de datos sobre pasadas, tareas y trabajos. A continuación, modificaremos los datos de la primera etapa añadiendo la fecha de inicio del periodo forward. La segunda etapa de la tabla (stages) podemos eliminarla. Ahora crearemos una entrada en la tabla tasks para la primera etapa, especificando el símbolo y el periodo (EURGBP H1) y los parámetros para el simulador de estrategias. En ellos incluiremos la optimización sobre un solo parámetro para que el número de pasadas sea pequeño. Esto nos permitirá obtener resultados de forma más rápida. Para el trabajo creado, añadiremos una tarea con un criterio de optimización complejo a la tabla tasks.
Ahora vamos a ejecutar el asesor experto para la optimización automática de proyectos especificando la base de datos creada en el parámetro de entrada. Después de la primera ejecución, resulta que el asesor experto de optimización automática necesita mejoras, ya que no recibe información de la base de datos sobre la necesidad de utilizar el periodo forward. Tras realizar las adiciones, el código de la función de obtención de la siguiente tarea de optimización de la base de datos se verá así (las líneas añadidas están resaltadas):
//+------------------------------------------------------------------+ //| Get the next optimization task from the queue | //+------------------------------------------------------------------+ ulong GetNextTask(string &setting) { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT s.expert," " s.optimization," " s.from_date," " s.to_date," " s.forward_mode," " s.forward_date," " j.symbol," " j.period," " j.tester_inputs," " t.id_task," " t.optimization_criterion" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status IN ('Queued', 'Processing')" " ORDER BY s.id_stage, j.id_job, t.status LIMIT 1;"; // Open the database if(DB::Connect()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string expert; int optimization; string from_date; string to_date; int forward_mode; string forward_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { setting = StringFormat( "[Tester]\r\n" "Expert=%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=%d\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=%d\r\n" "ForwardDate=%s\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d\r\n" "fileName_=%s\r\n" "%s\r\n", GetProgramPath(row.expert), row.symbol, row.period, row.optimization, row.from_date, row.to_date, row.forward_mode, row.forward_date, row.optimization_criterion, row.id_task, fileName_, row.tester_inputs ); res = row.id_task; } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } return res; }
También hemos añadido una función para obtener la ruta del archivo del asesor experto optimizado desde la carpeta actual relativa a la carpeta raíz de los asesores expertos del terminal:
//+------------------------------------------------------------------+ //| Getting the path to the file of the optimized EA from the current| //| folders relative to the root folder of terminal EAs | //+------------------------------------------------------------------+ string GetProgramPath(string name) { string path = MQLInfoString(MQL_PROGRAM_PATH); string programName = MQLInfoString(MQL_PROGRAM_NAME) + ".ex5"; string terminalPath = TerminalInfoString(TERMINAL_DATA_PATH) + "\\MQL5\\Experts\\"; path = StringSubstr(path, StringLen(terminalPath), StringLen(path) - (StringLen(terminalPath) + StringLen(programName))); return path + name; }
Esto ha permitido a la base de datos especificar solo el nombre de archivo del asesor experto optimizado en la tabla de etapas sin enumerar los nombres de las carpetas en las que se adjunta en relación con la carpeta raíz de asesores expertos\MQL5\Expertos\.
Las siguientes ejecuciones del asesor automatizado de optimización de proyectos han mostrado que los resultados de las pasadas forward se añaden correctamente a la tabla de pasadas junto con los resultados de las pasadas normales. Sin embargo, una vez terminada la etapa, resulta difícil distinguir qué pasadas pertenecen a cada periodo (principal o forward). Obviamente, podemos aprovechar el hecho de que las pasadas de periodos anteriores siempre vienen después de las pasadas normales, pero esto deja de funcionar si los resultados de varios problemas de optimización de periodos anteriores aparecen en la tabla passes. Por lo tanto, vamos a añadir una columna is_forward a la tabla passes para distinguir las pasadas normales de las pasadas forward. Y para facilitar la distinción entre pasadas normales y pasadas realizadas en el marco de la optimización, añadiremos al mismo tiempo la columna is_optimzation.
De paso, hemos descubierto una imprecisión: al formar la cadena de consulta SQL para insertar los datos con los resultados de una pasada, hemos sustituido el número de pasada como un entero con señal utilizando el especificador %d. Sin embargo, el número de pasada será un entero largo sin señal, por lo que deberá utilizarse el especificador %I64u para sustituir correctamente su valor en la cadena.
Luego añadiremos el valor de la función correspondiente de definición de la señal del periodo forward al código de formación de la consulta SQL para incorporar los datos de la pasada:
string CTesterHandler::GetInsertQuery(string values, string inputs, ulong pass) { return StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %I64u, %d, %s,\n'%s',\n'%s') RETURNING rowid;", s_idTask, pass, (int) MQLInfoInteger(MQL_FORWARD), values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); }
Sin embargo, resulta que no funciona tan bien como nos hubiera gustado. La cuestión es que esta función se llama desde el asesor experto que se ejecuta en el terminal principal en el modo de recogida de frames de datos. Por ello, el resultado de la llamada MQLInfoInteger(MQL_FORWARD) para ella siempre retornará false.
Por consiguiente, la señal del periodo forward deberá obtenerse en el código que se ejecuta en los agentes de prueba y no en el terminal principal del gráfico, es decir, en el manejador del evento de finalización de la pasada de prueba. Junto a ella, también hemos añadido una señal de optimización.
//+------------------------------------------------------------------+ //| Handling completion of tester pass for agent | //+------------------------------------------------------------------+ void CTesterHandler::Tester(double custom, // Custom criteria string params // Description of EA parameters in the current pass ) { ... // Generate a string with pass data data = StringFormat("%d, %d, %s,'%s'", MQLInfoInteger(MQL_OPTIMIZATION), MQLInfoInteger(MQL_FORWARD), data, params); ... }
Tras realizar estas modificaciones y reiniciar el asesor de autooptimización, por fin vemos la imagen deseada en la tabla de pasadas:
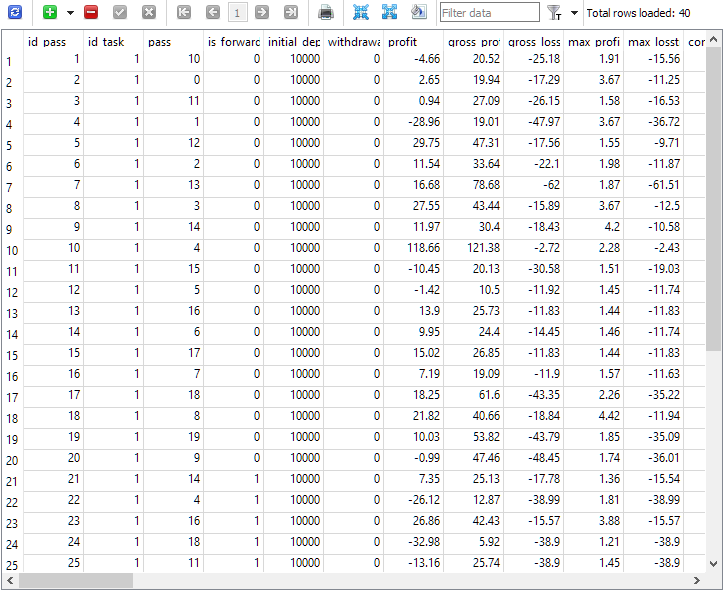
Fig. 1. Tabla passes tras la ejecución de la tarea de optimización con periodo forward
Como podemos ver, la tarea de optimización con id_task = 1 ha tenido 40 pasadas. De ellas, 20 han sido normales (las 20 primeras líneas con is_forward = 0) y las 20 restantes han sido pasadas de periodo forward (is_forward = 1). El número de pasadas del simulador en la columna passes toma valores de 1 a 20 y cada uno ocurre exactamente 2 veces (una vez para el periodo principal, la segunda vez, para el periodo forward).
Preparando el inicio de la optimización completa
Una vez hemos comprobado que la base de datos recibe ahora correctamente los resultados de las pasadas realizadas utilizando el periodo forward, realizaremos una prueba más realista de la optimización automática. Para ello, añadiremos ya dos etapas a la base de datos limpia. La primera optimizará una única instancia de estrategia comercial, pero solo en un símbolo y un periodo (EURGBP H1) en el marco temporal 2018 - 2023. En esta fase no se usará el periodo forward. La segunda etapa optimizará un grupo de buenas instancias individuales obtenidas en la primera etapa. Ahora ya se usará el periodo forward: se dedicará el año 2023 por completo.

Fig. 2. Tabla de etapas stages con dos etapas
Para cada etapa en la tabla jobs, crearemos los trabajos que se realizarán dentro de esa etapa. En esta tabla, además del símbolo y el periodo, se especificarán los parámetros de entrada para los asesores expertos optimizados con el rango y el paso de cambio.
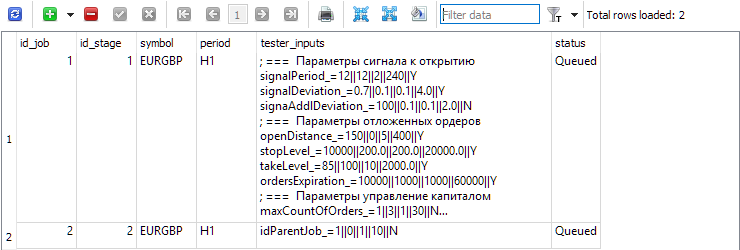
Fig. 3. Tabla jobs con dos trabajos para la primera y segunda etapa, respectivamente
Para el primer trabajo (id_job = 1), crearemos varias tareas de optimización que se diferenciarán en el valor del criterio de optimización (optimization_criterion = 0 ... 7) . Iteraremos todos los criterios uno por uno, y utilizaremos el criterio complejo dos veces: al principio y al final del primer trabajo (optimization_criterion = 7). Para la tarea realizada en el segundo trabajo (id_job = 2), utilizaremos un criterio de optimización personalizado (optimization_criterion = 6)
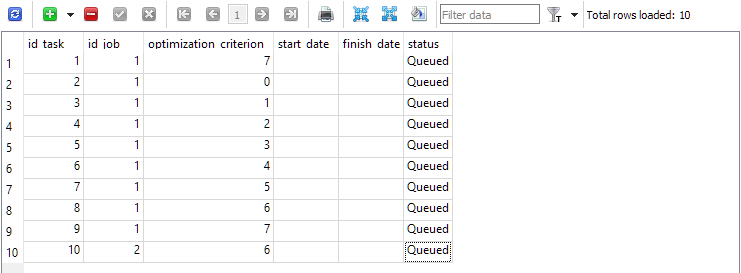
Fig. 4. Tabla de tareas tasks con las tareas para el primer y el segundo trabajo
Ahora ejecutaremos el asesor experto de optimización automática en cualquier gráfico del terminal y esperaremos a que finalicen todas las tareas. Con los agentes disponibles, el proceso ha durado en total unas 4 horas.
Análisis preliminar de los resultados
En la anterior optimización automática, solo teníamos un problema de optimización que utilizaba un periodo forward. Como criterio de optimización en ella actuaba nuestro criterio personalizado que calculaba el beneficio medio anual normalizado para una pasada determinada. Echemos un vistazo ahora a la nube de puntos con los valores de este criterio en el periodo principal.
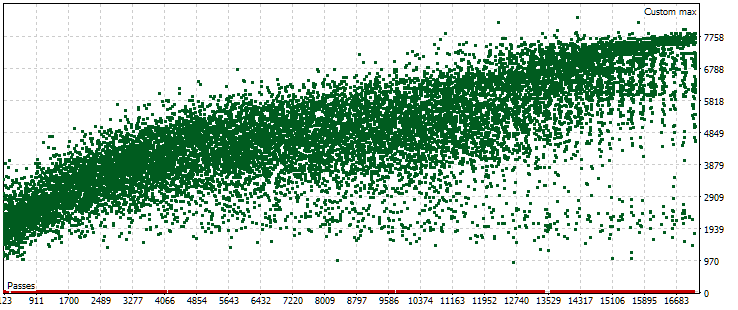
Fig. 5. Nube de puntos con los valores del beneficio medio anual normalizado para diferentes pasadas del periodo principal
El gráfico muestra que el valor de nuestro criterio oscila entre 1 000$ y 8 000$. Los puntos rojos correspondientes con un valor 0 aparecen porque algunas combinaciones de índices de instancia única en los parámetros de entrada tienen valores repetidos. Estos parámetros de entrada se consideran grupos de estrategias incorrectos, por lo que no tendremos resultados de estas pasadas. Podemos observar una tendencia general a que el beneficio medio anual normalizado aumente en las últimas pasadas. Por término medio, los mejores resultados obtenidos duplican aproximadamente los de las primeras pasadas, en las que los parámetros se seleccionan casi al azar.
Veamos ahora la nube de puntos con los resultados de las pasadas del periodo anterior. Habrá menos (unos 13 000 en lugar de 17 000) debido a las combinaciones de parámetros eliminadas en la fase principal que se consideraron incorrectas.
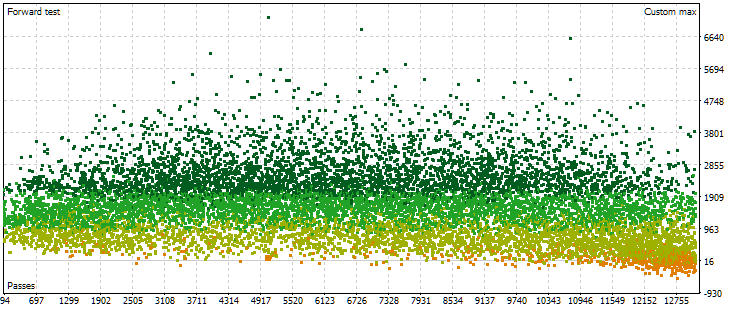
Fig. 6. Nube de puntos con los valores de beneficio medio anual normalizado para diferentes pasadas sobre el periodo forward
Aquí, la imagen de la disposición de los puntos ya es distinta. No se observa un aumento pronunciado de los resultados obtenidos al incrementar el número de pasadas. Por el contrario, podemos ver que al aumentar el número de pasadas, los resultados alcanzan primero valores más altos que al principio, y luego la tendencia se invertirá. A medida que aumenta el número de pasadas, sus resultados empiezan a disminuir por término medio, y la tasa de disminución aumenta a medida que nos acercamos al límite derecho de los números.
No obstante, resulta que esta imagen no siempre será así. Con otros ajustes en los rangos de los parámetros que deben buscarse durante la optimización, las nubes de puntos para las pasadas en los periodos principal y forward pueden tener este aspecto:
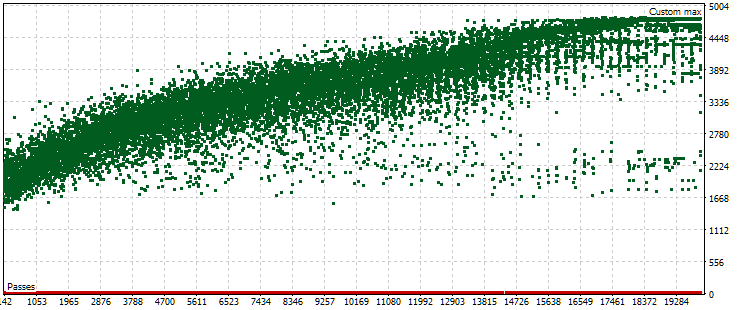
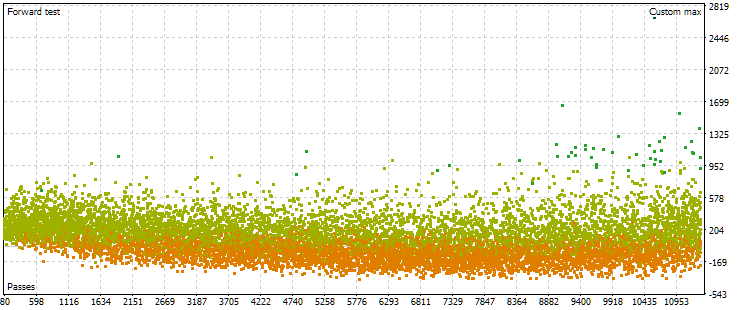
Fig. 7. Nube de puntos con valores del beneficio medio anual normalizado en los periodos básico y forward con otras configuraciones de optimización
Como podemos ver, la imagen es más o menos la misma en el periodo principal, solo que el rango del criterio es ahora un poco diferente: de 1 500$ a 5 000$. Sin embargo, en el periodo forward, la naturaleza de la nube es muy diferente. Los valores máximos no se alcanzan en las pasadas que se encuentran hacia la mitad del proceso de optimización, sino solo cerca del final. Además, por término medio, los valores del criterio en el periodo anterior son menores en un factor de aproximadamente 10 en lugar de 3 veces como en el primer proceso de optimización.
La intuición nos decía que, para aumentar la estabilidad de los resultados obtenidos a lo largo de distintos periodos, debíamos elegir un grupo que tuviera aproximadamente los mismos resultados en los periodos principal y forward. Sin embargo, los resultados obtenidos nos hicieron dudar mucho de que pudiéramos conseguir algo útil de esta manera. Especialmente cuando incluso el valor máximo del criterio en el periodo forward es notablemente menor que valores no especialmente buenos del criterio en el periodo principal. No obstante, vamos a intentarlo. Buscaremos pasadas convencionalmente "cercanas" en los periodos base y forward y observaremos sus resultados en el periodo base, forward y 2024.
Selección de pasadas
Recordemos cómo elegimos el mejor grupo basándonos en los resultados en el periodo forward en la parte 7. He aquí un resumen del algoritmo con algunos pequeños retoques:
- Ahora ajustaremos el valor del beneficio medio anual normalizado para las pasadas forward tomando la reducción máxima de dos valores para el cálculo: en el periodo principal y en el periodo forward. Obtendremos el valor OOS_ForwardResultCorrected.
- En la tabla combinada de resultados de optimización para 2018-2022 (periodo principal) y para 2023 (periodo forward), calcularemos para todos los indicadores la relación entre sus valores en los periodos principal y forward.
Por ejemplo, para el número de transacciones: TradesRatio = OOS_Trades / IS_Trades, y para el beneficio medio anual normalizado: ResultRatio = OOS_ForwardResultCorrected / IS_BackResult.
Cuanto más cercanas a 1 sean estas relaciones, más similares serán los valores de estos indicadores en los dos periodos. - Luego calcularemos para todas estas relaciones la suma de sus desviaciones respecto a la unidad. Este valor supondrá nuestra medida de la diferencia entre los resultados de cada grupo en los periodos principal y forward:
SumDiff = |1 - ResultRatio| + ... + |1 - TradesRatio|. -
Debemos tener en cuenta que en el periodo principal y en el forward para cada pasada la reducción podría ser diferente. Después elegiremos la reducción máxima de dos periodos y la utilizaremos para calcular el factor de escala de las posiciones abiertas para lograr una reducción normalizada del 10%:
Scale = 10 / MAX(OOS_EquityDD, IS_EquityDD).
-
Ahora elegiremos preferentemente conjuntos en los que SumDiff sea menor y Scale sea mayor. Para ello, calcularemos el último indicador:
Res = Scale / SumDiff.
-
Vamos a clasificar todos los grupos según el valor Res calculado en el paso anterior en orden descendente. A continuación, en la parte superior de la tabla se encontrarán aquellos grupos cuyos resultados en los periodos principal y forward hayan sido más semejantes, siendo además menor la reducción en ambos periodos.
Además, sugerimos repetir la selección de grupos varias veces, eliminando aquellos que contengan el número de instancias únicas de estrategias comerciales ya incluidas en los grupos. Pero este paso resultará relevante cuando se agrupen instancias individuales de antemano, de modo que índices diferentes se correspondan con instancias disímiles en los resultados. Como aún no hemos llegado a la clusterización en la optimización automática, nos saltaremos este paso.
En su lugar, podemos añadir un segundo nivel de agrupación según diferentes marcos temporales para cada símbolo y un tercer nivel según diferentes símbolos.
Vamos a mejorar un poco el algoritmo anterior. Para empezar, lo que queremos saber es a qué distancia se hallan dos conjuntos de resultados de una pasada en un espacio con una dimensionalidad igual al número de resultados (características) comparados. Para ello, utilizaremos una norma de primer orden con algún factor de escala para hallar la distancia de un punto con las coordenadas de las relaciones de los resultados comparados hasta un punto fijo con coordenadas unitarias. No obstante, entre estas relaciones puede haber cercanas a 1 o muy distantes. Y esto último puede empeorar la estimación global de la distancia. Por lo tanto, intentaremos sustituir la variante propuesta anteriormente calculando la distancia euclidiana habitual entre dos vectores de resultados a los que aplicaremos primero el escalado min-max.
Al final tendremos que escribir una consulta SQL bastante compleja (aunque puede haber consultas mucho más complicadas). Ahora veremos con más detalle el proceso de creación de la consulta necesaria. Empezaremos con consultas sencillas y progresivamente las iremos haciendo más complicadas. Pondremos algunos de los resultados en tablas temporales que se usarán en consultas posteriores. Después de cada consulta, le mostraremos cómo son los resultados.
Así, los datos de origen de los que necesitamos sacar algo estarán básicamente en la tabla passes. Ahora no aseguraremos de que realmente estén ahí, y haremos una selección inmediata solo de aquellas pasadas que se han realizado como parte de la tarea de optimización deseada. En nuestro caso particular, el identificador id_task correspondiente a la segunda etapa de optimización para EURGBP H1 tenía un valor de 10. Por consiguiente, lo utilizaremos en el texto de la consulta:
-- Request 1
SELECT *
FROM passes p0
WHERE p0.id_task = 10;

Podemos ver que en la tabla passes hay más de 22 mil registros para esta tarea con id_task=10.
El siguiente paso consistirá en combinar en una sola línea los resultados de las dos líneas de este conjunto de datos que correspondan al mismo número de pasadas del simulador, pero a periodos distintos: el periodo principal y el periodo forward. Limitaremos temporalmente el número de columnas mostradas en el resultado, dejando solo aquellas por las que podemos comprobar la corrección de la selección de las cadenas. Nombraremos las columnas resultantes según la siguiente regla: al nombre de la columna le añadiremos el prefijo "I_" para el periodo principal (In-Sample) y el prefijo "O_" para el periodo forward (Out-Of-Sample):
-- Request 2 SELECT p0.id_pass AS I_id_pass, p0.is_forward AS I_is_forward, p0.custom_ontester AS I_custom_ontester, p1.id_pass AS O_id_pass, p1.is_forward AS O_is_forward, p1.custom_ontester AS O_custom_ontester FROM passes p0 JOIN passes p1 ON p0.pass = p1.pass AND p0.is_forward = 0 AND p1.is_forward = 1 WHERE p0.id_task = 10 AND p1.id_task = 10
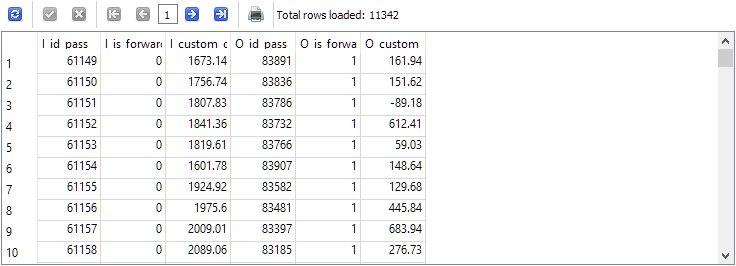
Como resultado, el número de filas ha disminuido exactamente dos veces, es decir, por cada pasada sobre el periodo principal en la tabla passes ha habido exactamente una pasada sobre el periodo forward y viceversa.
Ahora volveremos a la primera consulta para realizar la normalización. Si dejamos la normalización para más adelante, cuando ya tengamos columnas separadas para el mismo parámetro en los periodos principal y forward, será más difícil calcular los valores mínimo y máximo de ambos a la vez. En primer lugar, elegiremos un pequeño número de parámetros con los que estimaremos la "distancia" entre los resultados del periodo principal y del periodo forward. Por ejemplo, practicaremos primero el cálculo de la distancia para tres parámetros: custom_ontester, equity_dd_relative, profit_factor.
Tendremos que convertir las columnas con los valores de estos parámetros en columnas con valores que vayan de 0 a 1. Utilizaremos las funciones de ventana para obtener los valores mínimo y máximo de las columnas de la consulta. Para los nombres de columna escalados, añadiremos el prefijo "s_" a los nombres de columna originales. Basándonos en los resultados retornados por esta consulta, crearemos y rellenaremos una nueva tabla utilizando el comando
CREATE TABLE ... AS SELECT ... ;
Y veremos el contenido de la nueva tabla creada y rellenada:
-- Request 3
DROP TABLE IF EXISTS t0;
CREATE TABLE t0 AS
SELECT id_pass,
pass,
is_forward,
custom_ontester,
(custom_ontester - MIN(custom_ontester) OVER () ) / (MAX(custom_ontester) OVER () - MIN(custom_ontester) OVER () ) AS s_custom_ontester,
equity_dd_relative,
(equity_dd_relative - MIN(equity_dd_relative) OVER () ) / (MAX(equity_dd_relative) OVER () - MIN(equity_dd_relative) OVER () ) AS s_equity_dd_relative,
profit_factor,
(profit_factor - MIN(profit_factor) OVER () ) / (MAX(profit_factor) OVER () - MIN(profit_factor) OVER () ) AS s_profit_factor
FROM passes
WHERE id_task=10;
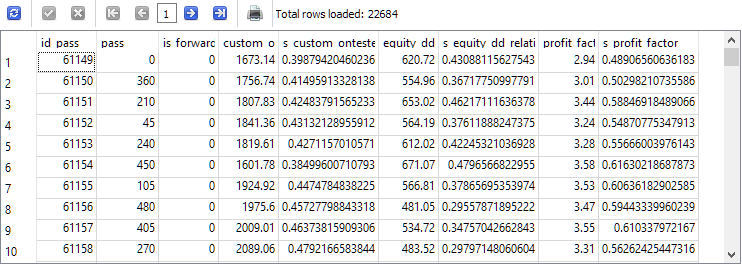
Como podemos ver, junto a cada parámetro evaluado aparecía una nueva columna con el valor de este parámetro, reducido al intervalo de 0 a 1.
Ahora reformaremos el texto de la segunda consulta para que tome los datos de la nueva tabla t0 en lugar de passes y ponga los resultados en la nueva tabla t1. Tomaremos los valores ya escalados y los redondearemos por comodidad. También dejaremos solo las filas en las que los valores del beneficio normalizado en los periodos principal y forward sean positivos:
SELECT * FROM t0;
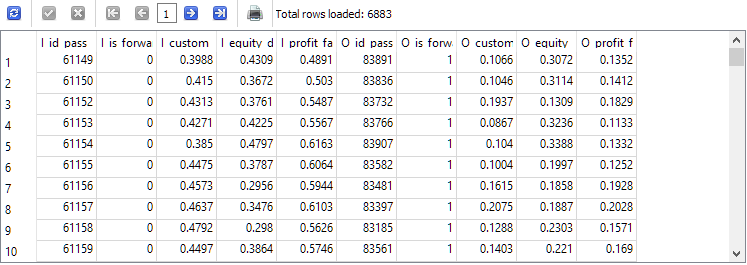
El número de filas se ha reducido aproximadamente un tercio en comparación con la segunda consulta, pero ahora solo nos quedan las pasadas en las que tanto el periodo principal como el forward han obtenido beneficios.
Finalmente, hemos llegado al último paso del proceso de desarrollo de consultas. Lo único que queda por hacer es calcular la distancia entre las combinaciones de parámetros para los periodos principal y forward en cada fila de la tabla t1 y clasificarlas en orden ascendente de distancia:
-- Request 4 DROP TABLE IF EXISTS t1; CREATE TABLE t1 AS SELECT p0.id_pass AS I_id_pass, p0.is_forward AS I_is_forward, ROUND(p0.s_custom_ontester, 4) AS I_custom_ontester, ROUND(p0.s_equity_dd_relative, 4) AS I_equity_dd_relative, ROUND(p0.s_profit_factor, 4) AS I_profit_factor, p1.id_pass AS O_id_pass, p1.is_forward AS O_is_forward, ROUND(p1.s_custom_ontester, 4) AS O_custom_ontester, ROUND(p1.s_equity_dd_relative, 4) AS O_equity_dd_relative, ROUND(p1.s_profit_factor, 4) AS O_profit_factor FROM t0 p0 JOIN t0 p1 ON p0.pass = p1.pass AND p0.is_forward = 0 AND p1.is_forward = 1 AND p0.custom_ontester > 0 AND p1.custom_ontester > 0; SELECT * FROM t1;
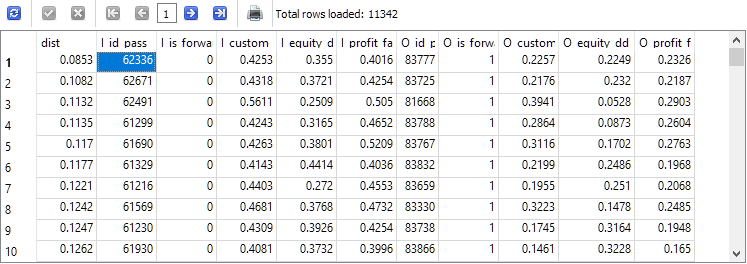
El identificador de pasada I_id_pass de la fila superior de los resultados obtenidos corresponderá a la pasada con la menor distancia entre los valores de los resultados en el periodo principal y en el periodo forward.
Vamos a tomar esta y el identificador de la mejor pasada de beneficio normalizado en el periodo principal. No coinciden, así que vamos a convertirlas en una biblioteca de parámetros para el EA final, como se describe en el último artículo. Hemos tenido que hacer pequeñas modificaciones en los archivos añadidos en el último artículo para asegurarnos de poder especificar una base de datos concreta al crear y exportar la biblioteca de conjuntos de parámetros.
Resultados
Así que tendremos dos opciones de configuración en la biblioteca. La primera variante se denominará "Best for dist(IS, OS) (2018-2023)" , y será la mejor pasada de optimización con la menor distancia entre los valores de los parámetros. La segunda opción se denominará "Best on IS (2018-2022)", y será la mejor pasada de optimización sobre el beneficio normalizado para el periodo básico de 2018 a 2022.
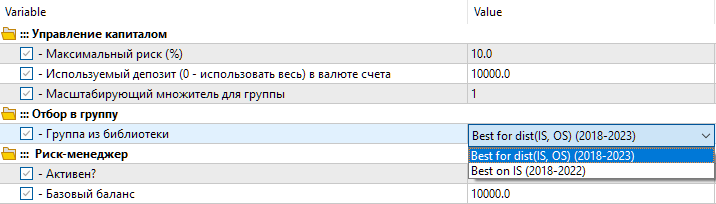
Fig. 8. Selección de un grupo de ajustes de la biblioteca en el EA final
Veamos los resultados de estos dos grupos para el periodo 2018-2023, que ha participado al completo en la optimización.
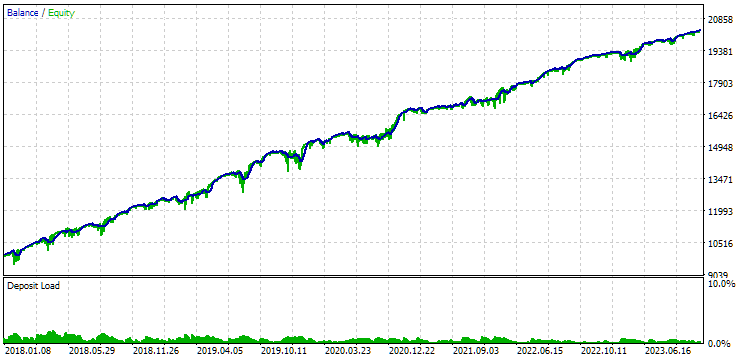
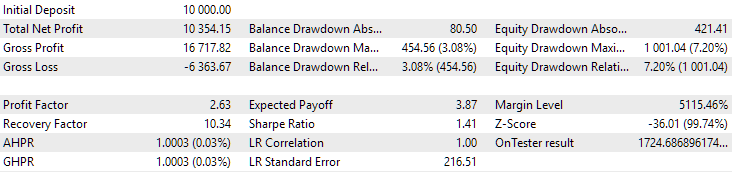
Fig. 9. Resultados del primer grupo (mejores según la distancia) para el periodo 2018-2023
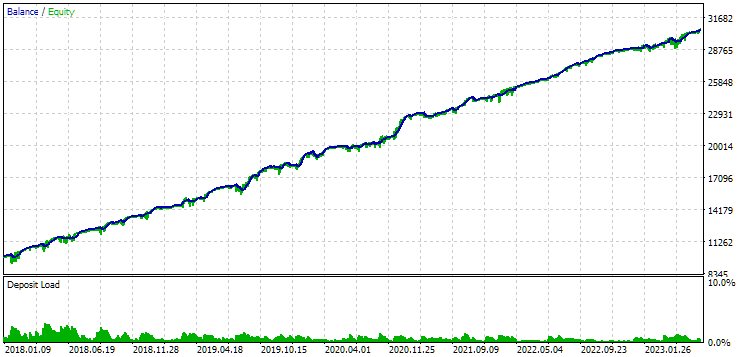
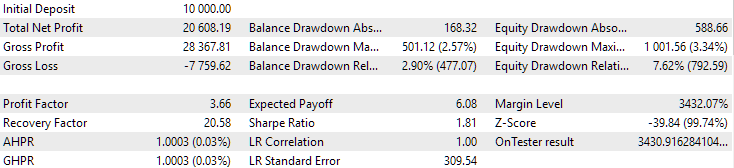
Fig. 10. Resultados del segundo grupo (mejor beneficio) para el periodo 2018-2023
Podemos ver que ambos grupos están bien normalizados durante este periodo temporal (la reducción máxima es de 1 000$ en ambos casos). Sin embargo, el primero tiene un beneficio medio anual de aproximadamente la mitad que el segundo (1 724$ frente a 3 430$). Aquí las ventajas del primer grupo aún no resultan evidentes.
Veamos ahora los resultados de estos dos grupos en 2024 (hasta octubre), que no ha participado en la optimización.
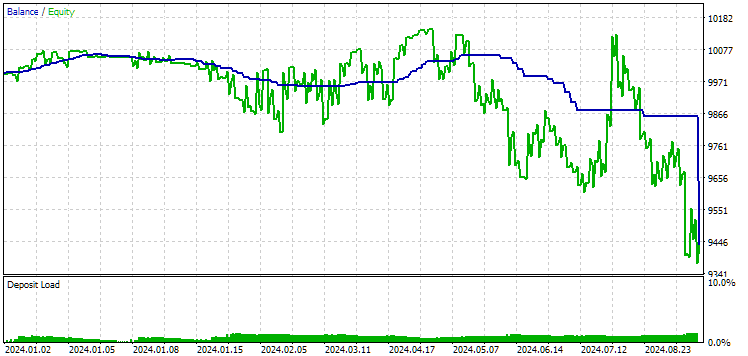
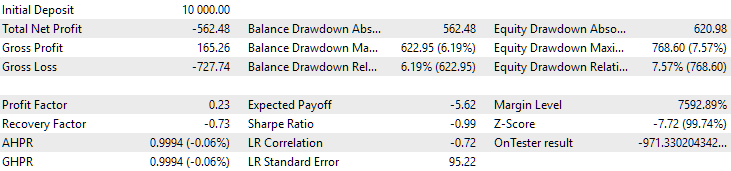
Fig. 11. Resultados del primer grupo (mejor según la distancia) para el periodo 2024
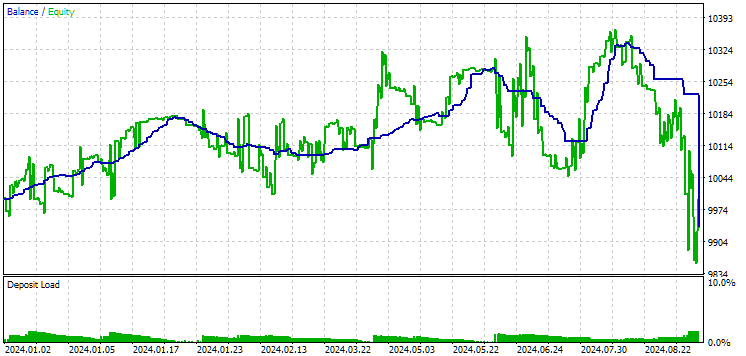
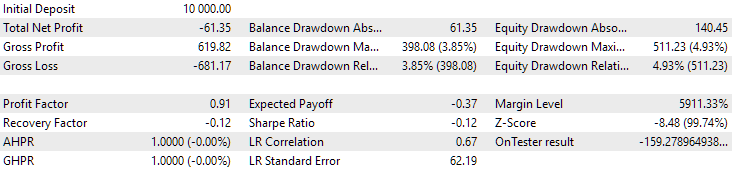
Fig. 12. Resultados del segundo grupo (mejor según el beneficio) para el periodo 2024
Ambos resultados son negativos en este periodo, pero el segundo sigue pareciendo mejor que el primero. Debemos señalar que la reducción máxima para este periodo ha sido siempre inferior a 1 000$.
Pues bien, dado que 2024 no ha sido un año muy fructífero para este símbolo, veamos cuáles serán los resultados del periodo situado no después, sino antes del periodo de optimización. Tomaremos un periodo aún más largo, ya que tenemos esa opción (tres años de 2015 a 2017).
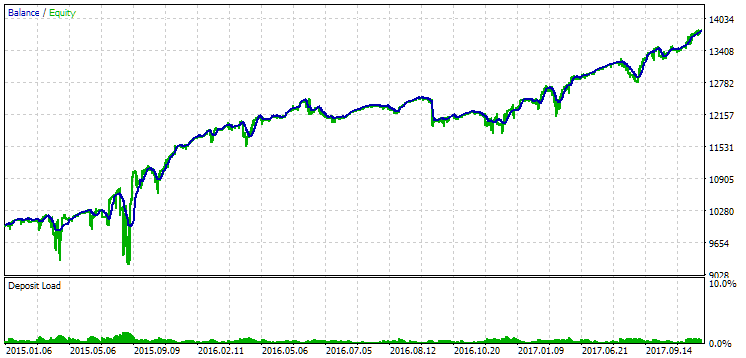
Fig. 13. Resultados del primer grupo (mejor según la distancia) en el periodo 2015-2017
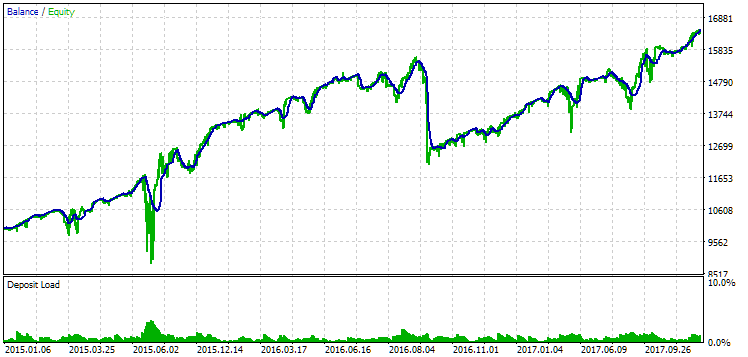

Fig. 14. Resultados del segundo grupo (mejor según el beneficio) en el periodo 2015-2017
Durante este periodo, la reducción ya ha superado la reducción calculada admisible. Ha sido aproximadamente 1,5 veces mayor en la primera versión y unas 3,5 veces mayor en la segunda. En este sentido, la primera opción es ligeramente mejor, ya que el exceso de reducción resulta notablemente menor que en la segunda y, en general, no es muy grande. Además, la primera opción no tiene un notable hundimiento del gráfico en el centro, como la segunda. Es decir, la primera opción ha mostrado una mayor adaptabilidad a un periodo desconocido de la historia en comparación con la segunda opción. Sin embargo, en términos de ingresos medios anuales normalizados, la diferencia entre las dos opciones no es tan grande (857$ frente a 615$). Desgraciadamente, no podemos calcular este valor para un periodo desconocido de antemano.
Por consiguiente, en esta fase se seguirá favoreciendo la primera opción. Resumamos.
Conclusión
Bien, hoy hemos implementado la automatización de la segunda etapa de optimización utilizando el periodo forward. Tampoco esta vez se han identificado ventajas claras. La tarea ha resultado mucho más amplia y laboriosa de lo que habíamos previsto en un principio. En el proceso de trabajo han surgido muchas preguntas nuevas que aún esperan respuesta.
Hemos podido comprobar que si el periodo forward cae por suerte en un periodo fallido de trabajo del EA, parece que no podremos utilizarlo para seleccionar buenas combinaciones de parámetros.
Si la duración de las transacciones es larga, los resultados de una pasada con una interrupción en el límite de los periodos principal y forward pueden diferir notablemente de los resultados de una pasada continua. Esto también pone en duda la conveniencia de usar el periodo forward de esta manera, no el periodo forward en general, sino específicamente una forma de seleccionar automáticamente los parámetros que tienen más probabilidades de mostrar resultados comparables en el futuro.
Ahora hemos utilizado una forma sencilla de calcular la distancia entre los resultados de las pasadas. Es posible que si complicamos este método, los resultados mejoren. Además, aún no hemos escrito una implementación que permita seleccionar automáticamente la mejor pasada para incluir en un grupo de conjuntos para diferentes símbolos y marcos temporales. Casi todo está listo para ello: lo único que necesitamos hacer es llamar a las consultas SQL que hemos desarrollado desde el EA. Pero como aún es probable que las modifiquemos, pospondremos esta automatización para el futuro.
Gracias por su atención, ¡hasta pronto!
Advertencia importante
Todos los resultados expuestos en este artículo y en todos los artículos anteriores de la serie se basan únicamente en datos de pruebas históricas y no ofrecen ninguna garantía de lograr beneficios en el futuro. El trabajo de este proyecto es de carácter exploratorio. Todos los resultados publicados pueden ser usados por cualquiera bajo su propia responsabilidad.
Contenido del archivo
| # | Nombre | Versión | Descripción | Cambios recientes |
|---|---|---|---|---|
| MQL5/Experts/Article.15683 | ||||
| 1 | Advisor.mqh | 1.04. | Clase básica del experto | Parte 10 |
| 2 | Database.mqh | 1.05 | Clase para trabajar con bases de datos | Parte 18 |
| 3 | database.sqlite.schema.sql | — | Esquema de la base de datos | Parte 18 |
| 4 | ExpertHistory.mqh | 1.00 | Clase para exportar la historia de transacciones a un archivo | Parte 16 |
| 5 | ExportedGroupsLibrary.mqh | — | Archivo generado con los nombres de los grupos de estrategias y un array con sus cadenas de inicialización | Parte 17 |
| 6 | Factorable.mqh | 1.01 | Clase básica de objetos creados a partir de una cadena | Parte 10 |
| 7 | GroupsLibrary.mqh | 1.01 | Clase para trabajar con una biblioteca de grupos estratégicos seleccionados | Parte 18 |
| 8 | HistoryReceiverExpert.mq5 | 1.00 | Asesor experto para reproducir la historia de transacciones con el gestor de riesgos | Parte 16 |
| 9 | HistoryStrategy.mqh | 1.00 | Clase de estrategia comercial para reproducir la historia de transacciones | Parte 16 |
| 10 | Interface.mqh | 1.00 | Clase básica de visualización de diversos objetos | Parte 4 |
| 11 | LibraryExport.mq5 | 1.01 | Asesor que guarda las cadenas de inicialización de las pasadas seleccionadas de la biblioteca en el archivo ExportedGroupsLibrary.mqh | Parte 18 |
| 12 | Macros.mqh | 1.02 | Macros útiles para operaciones con arrays | Parte 16 |
| 13 | Money.mqh | 1.01 | Clase básica de gestión de capital | Parte 12 |
| 14 | NewBarEvent.mqh | 1.00 | Clase de definición de una nueva barra para un símbolo específico | Parte 8 |
| 15 | Optimization.mq5 | 1.02 | Asesor que gestiona el inicio de tareas de optimización | Parte 18 |
| 16 | Receiver.mqh | 1.04. | Clase básica de transferencia de volúmenes abiertos a posiciones de mercado | Parte 12 |
| 17 | SimpleHistoryReceiverExpert.mq5 | 1.00 | Asesor experto simplificado para reproducir la historia de transacciones | Parte 16 |
| 18 | SimpleVolumesExpert.mq5 | 1.20 | Asesor experto para el trabajo en paralelo de varios grupos de estrategias modelo. Los parámetros se tomarán de la biblioteca de grupos incorporada. | Parte 17 |
| 19 | SimpleVolumesStage1.mq5 | 1.17 | Asesor experto para optimizar una única instancia de una estrategia comercial (Etapa 1) | Parte 18 |
| 20 | SimpleVolumesStage2.mq5 | 1.01 | Asesor experto que optimiza un grupo de instancias de estrategias comerciales (Etapa 2) | Parte 18 |
| 21 | SimpleVolumesStage3.mq5 | 1.01 | Asesor experto que guarda un grupo normalizado generado de estrategias en una biblioteca de grupos con un nombre especificado. | Parte 18 |
| 22 | SimpleVolumesStrategy.mqh | 1.09 | Clase de estrategia comercial con uso de volúmenes de ticks | Parte 15 |
| 23 | Strategy.mqh | 1.04. | Clase básica de estrategia comercial | Parte 10 |
| 24 | TesterHandler.mqh | 1.04. | Clase para gestionar los eventos de optimización | Parte 18 |
| 25 | VirtualAdvisor.mqh | 1.07 | Clase del asesor experto que trabaja con posiciones (órdenes) virtuales | Parte 18 |
| 26 | VirtualChartOrder.mqh | 1.01 | Clase de posición virtual gráfica | Parte 18 |
| 27 | VirtualFactory.mqh | 1.04. | Clase de fábrica de objetos | Parte 16 |
| 28 | VirtualHistoryAdvisor.mqh | 1.00 | Clase experta para reproducir la historia de transacciones | Parte 16 |
| 29 | VirtualInterface.mqh | 1.00 | Clase de GUI del asesor | Parte 4 |
| 30 | VirtualOrder.mqh | 1.04. | Clase de órdenes y posiciones virtuales | Parte 8 |
| 31 | VirtualReceiver.mqh | 1.03 | Clase de transferencia de volúmenes abiertos a posiciones de mercado (receptor) | Parte 12 |
| 32 | VirtualRiskManager.mqh | 1.02 | Clase de gestión de riesgos (gestor de riesgos) | Parte 15 |
| 33 | VirtualStrategy.mqh | 1.05 | Clase de estrategia comercial con posiciones virtuales | Parte 15 |
| 34 | VirtualStrategyGroup.mqh | 1.00 | Clase de grupo o grupos de estrategias comerciales | Parte 11 |
| 35 | VirtualSymbolReceiver.mqh | 1.00 | Clase de receptor simbólico | Parte 3 |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/15683
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Se ha publicado un nuevo artículo Desarrollo de operaciones de EA multidivisa (parte 18): consideración de la selección automatizada de grupos para forwards:
Por Yuriy Bykov