Обсуждение статьи "Разрабатываем мультивалютный советник (Часть 19): Создаём этапы, реализованные на Python"
Hello,
we start Python by executing shell command in this code:
//+------------------------------------------------------------------+ //| Запуск задачи | //+------------------------------------------------------------------+ void COptimizerTask::Start() { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", m_id, m_setting); // Если это задача на оптимизацию советника if(m_type == TASK_TYPE_EX5) { // Запускаем новую задачу оптимизации в тестере MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(m_setting); MTTESTER::ClickStart(); // Обновляем статус задачи в базе данных DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing' " " WHERE id_task=%d", m_id); DB::Execute(query); DB::Close(); // If it is task for executing Python-program } else if (m_type == TASK_TYPE_PY) { PrintFormat(__FUNCTION__" | SHELL EXEC: %s", m_pythonPath); // Call function from operation system (Windows) for executing shell command ShellExecuteW(NULL, NULL, m_pythonPath, m_setting, NULL, 1); } }
Where:
- m_pythonPath is a path to Python on current computer;
- m_setting is string with name of executed Python-program and its command-line arguments
hello
first i optimize satge 1 and complete
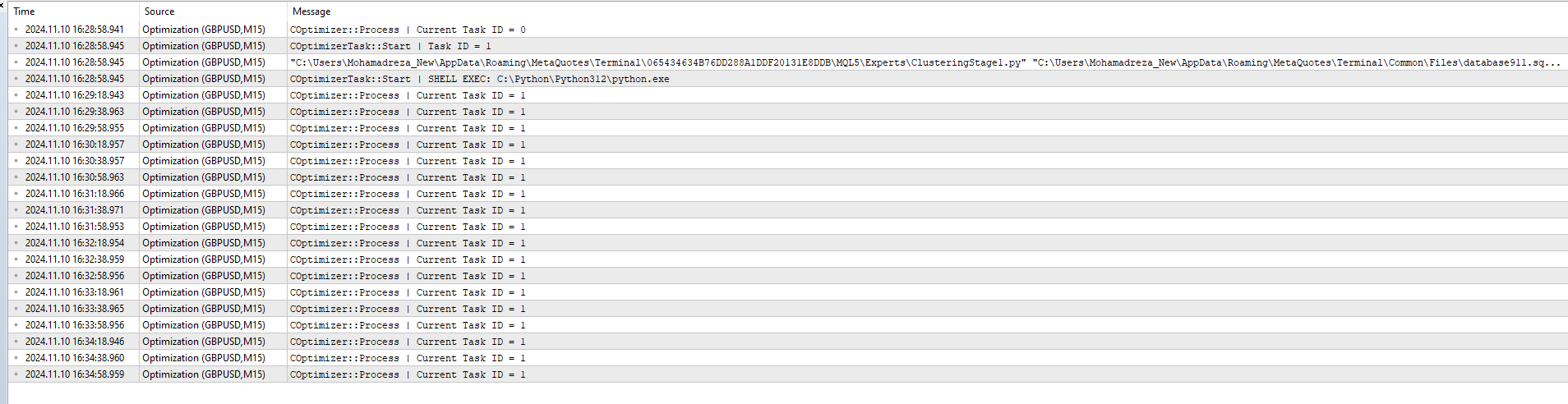
then I added ClusteringStage1.py and task and job to database and Optimize Again But not worked just this message :
2024.11.10 16:35:18.952 Optimization ( GBPUSD ,M15) COptimizer::Process | Current Task ID = 1
{kind=link}
hello
first i optimize satge 1 and complete
then I added ClusteringStage1.py and task and job to database and Optimize Again But not worked just this message :
2024.11.10 16:35:18.952 Optimization ( GBPUSD ,M15) COptimizer::Process | Current Task ID = 1
Hello
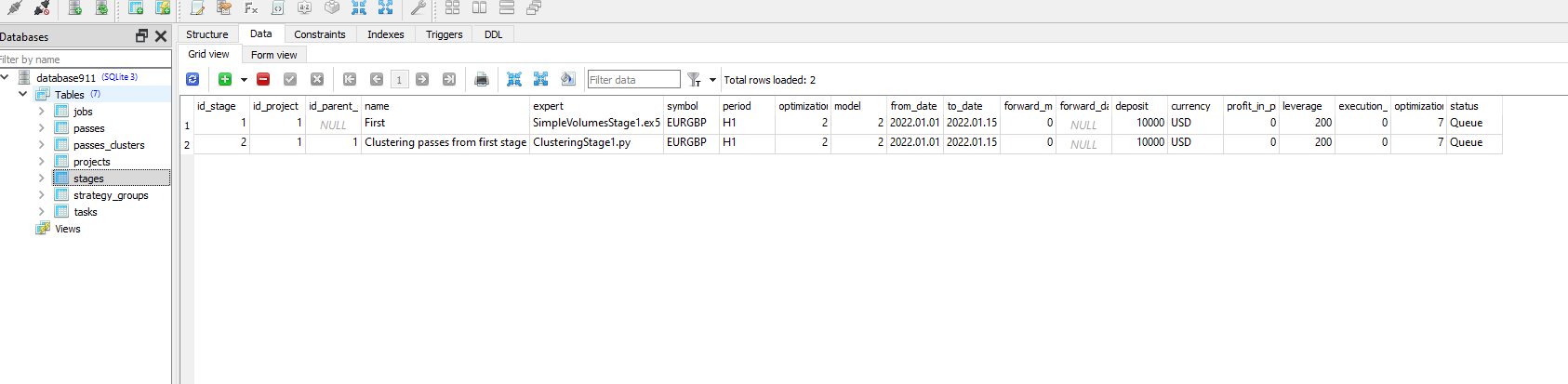
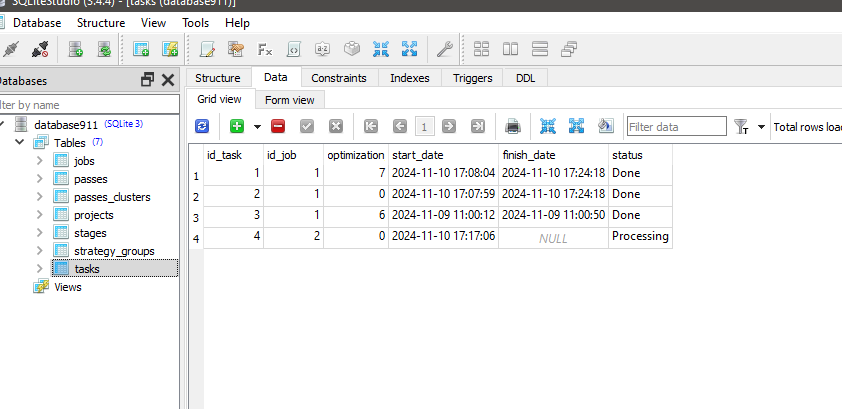
It seems that running Python-program doesn't change status for task with id_task=1.
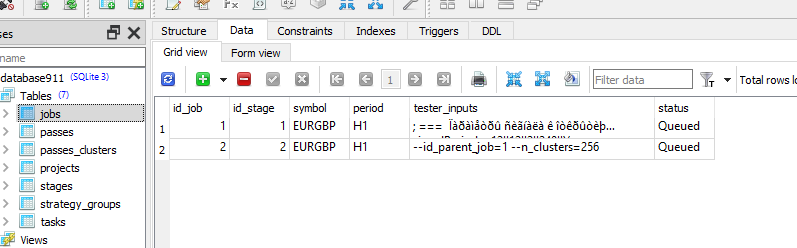
Check that in job for this task you have correct values in [tester_inputs] column. There are:
--id_parent_job=1 --n_clusters=256
where 1 is id_job for job of first stage. In your case it may be other number value.
You can also try to run Python-program with actually parameters manually from command line and then you'll can see possible error-messages from it
Hello
It seems that running Python-program doesn't change status for task with id_task =1.
Check that in job for this task you have correct values in [tester_inputs] column. There are:
where 1 is id_job for job of first stage. In your case it may be other number value.
You can also try to run Python-program with actually parameters manually from command line and then you'll can see possible error-messages from it
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
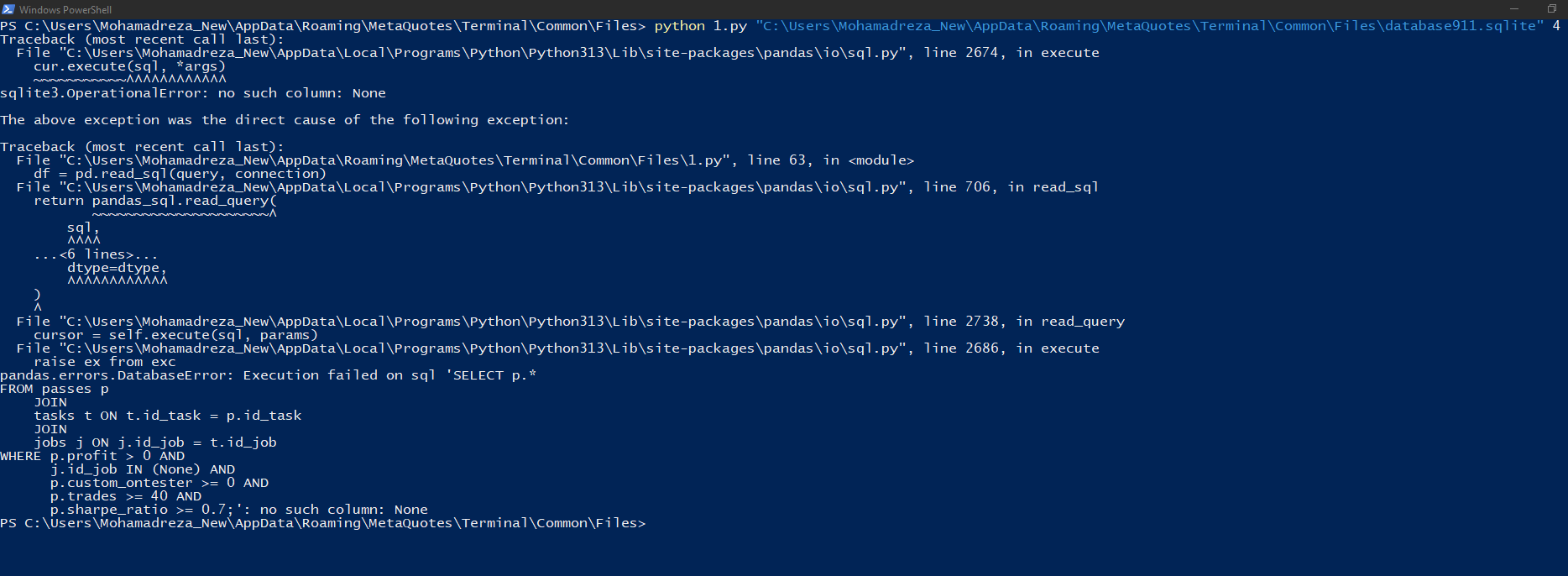
i run in powershell and see this
Try run it like this:
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" usage: ClusteringStage1.py [-h] [--id_parent_job ID_PARENT_JOB] [--n_clusters N_CLUSTERS] [--min_custom_ontester MIN_CUSTOM_ONTESTER] [--min_trades MIN_TRADES] [--min_sharpe_ratio MIN_SHARPE_RATIO] db_path id_task ClusteringStage1.py: error: the following arguments are required: db_path, id_task
We need to set the arguments: db_path, id_task. Then we have got error message as you posted:
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" "C:\Users\Antekov\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 Traceback (most recent call last): File "C:\Python\Python312\Lib\site-packages\pandas\io\sql.py", line 2674, in execute cur.execute(sql, *args) sqlite3.OperationalError: no such column: None The above exception was the direct cause of the following exception: Traceback (most recent call last): ... File "C:\Python\Python312\Lib\site-packages\pandas\io\sql.py", line 2686, in execute raise ex from exc pandas.errors.DatabaseError: Execution failed on sql 'SELECT p.* FROM passes p JOIN tasks t ON t.id_task = p.id_task JOIN jobs j ON j.id_job = t.id_job WHERE p.profit > 0 AND j.id_job IN (None) AND p.custom_ontester >= 0 AND p.trades >= 40 AND p.sharpe_ratio >= 0.7;': no such column: None
We need also set two arguments: --id_parent_job=1 --n_clusters=256
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" "C:\Users\Antekov\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
What will you get?
I run this
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
and get this error
ValueError: n_samples=150 should be >= n_clusters=256.
then i change n_clusters=150 and run
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=150
and i think worked. but in database not any change
after that i try optimize with n_samples=150 but dont worked
Интересная статья! Почитаю всю серию, потом.
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
Почему отказались от функционала библиотеки AlgLib?
#include <Math\Alglib\alglib.mqh> Минус только в скорости, но в основном от того, что питон распараллеливает на все ядра вычисления.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована статья Разрабатываем мультивалютный советник (Часть 19): Создаём этапы, реализованные на Python:
Пока что мы рассматривали автоматизацию запуска последовательных процедур оптимизации советников исключительно в штатном тестере стратегий. Но что делать, если между такими запусками нам хотелось бы выполнить некоторую обработку уже полученных данных, используя другие средства? Попробуем добавить возможность создания новых этапов оптимизации, выполняемых программами, написанными на Python.
Для проведения кластеризации мы воспользовались готовой библиотекой scikit-learn для Python, а точнее реализацией алгоритма K-Means. Это не единственный алгоритм кластеризации, но рассмотрение других возможных, сравнение и выбор наилучшего, применительно к данной задаче, выходило за допустимые рамки. Поэтому был взят, по сути, первый попавшийся алгоритм, и результаты, полученные с его использованием, оказались достаточно хорошими.
Однако использование именно этой реализации делало необходимым запуск небольшой программы на Python. Когда мы большую часть операций всё равно выполняли вручную, то это не составляло проблемы. Но теперь, когда мы уже сильно продвинулись по пути автоматизации всего процесса тестирования и отбора хороших групп отдельных экземпляров торговых стратегий, наличие даже простой операции, запускаемой вручную посреди конвейера последовательно выполняемых задач оптимизации, выглядит плоховато.
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
Автор: Yuriy Bykov