Discusión sobre el artículo "Desarrollamos un asesor experto multidivisa (Parte 19): Creando las etapas implementadas en Python"
Hola,
iniciamos Python ejecutando el comando shell en este código:
//+------------------------------------------------------------------+ //| Iniciar una tarea| //+------------------------------------------------------------------+ void COptimizerTask::Start() { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", m_id, m_setting); // Si se trata de una tarea de optimización de EA if(m_type == TASK_TYPE_EX5) { // Iniciar una nueva tarea de optimización en el comprobador MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(m_setting); MTTESTER::ClickStart(); // Actualizar el estado de la tarea en la base de datos DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing' " " WHERE id_task=%d", m_id); DB::Execute(query); DB::Close(); // Si es tarea para ejecutar programa Python } else if (m_type == TASK_TYPE_PY) { PrintFormat(__FUNCTION__" | SHELL EXEC: %s", m_pythonPath); // Función de llamada desde el sistema operativo (Windows) para ejecutar el comando shell ShellExecuteW(NULL, NULL, m_pythonPath, m_setting, NULL, 1); } }
Donde
- m_pythonPath es una ruta a Python en el ordenador actual;
- m_setting es una cadena con el nombre del programa Python ejecutado y sus argumentos de línea de comandos
hola
primero optimizo satge 1 y completo
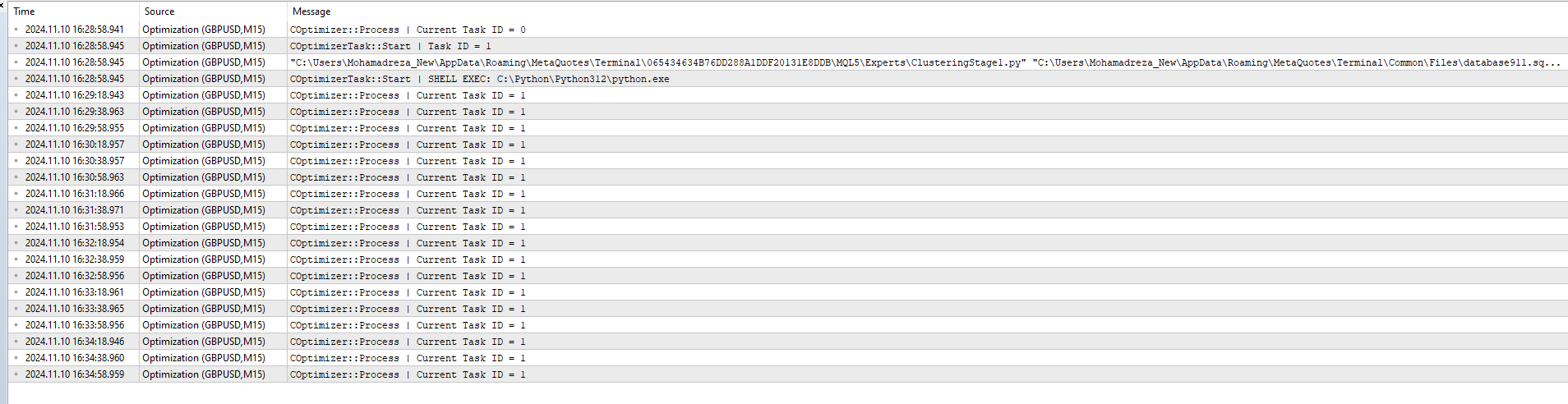
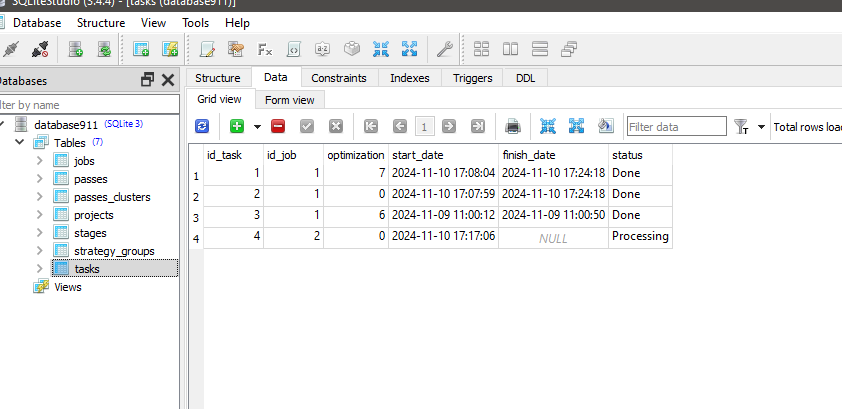
entonces he añadido ClusteringStage1.py y la tarea y el trabajo a la base de datos y optimizar de nuevo, pero no funcionó sólo este mensaje :
2024.11.10 16:35:18.952 Optimización ( GBPUSD , M15) COptimizer::Process | ID de tarea actual = 1
{kind=link}
Hola
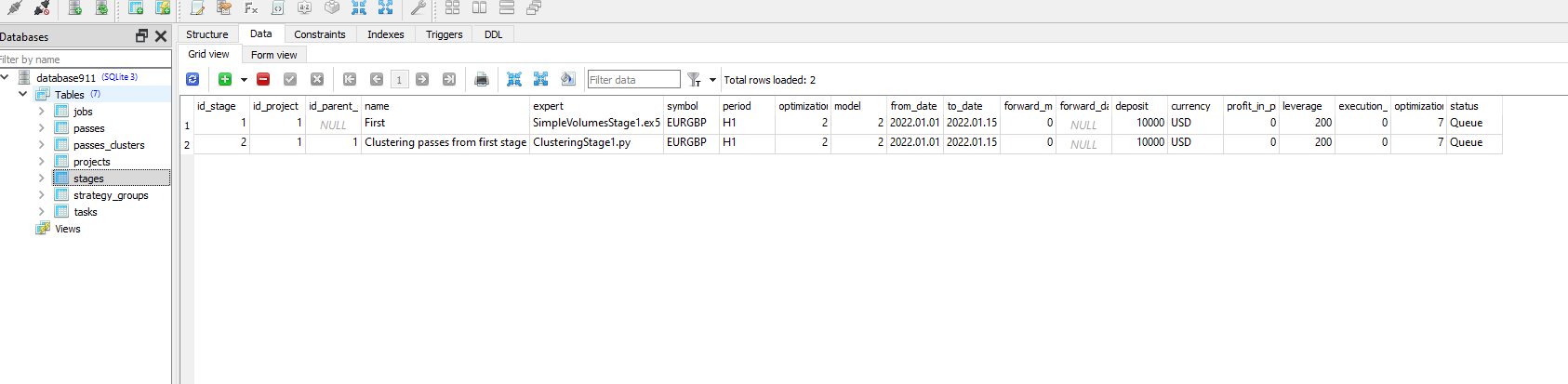
Parece que la ejecución del programa Python no cambia el estado de la tarea con id_task=1.
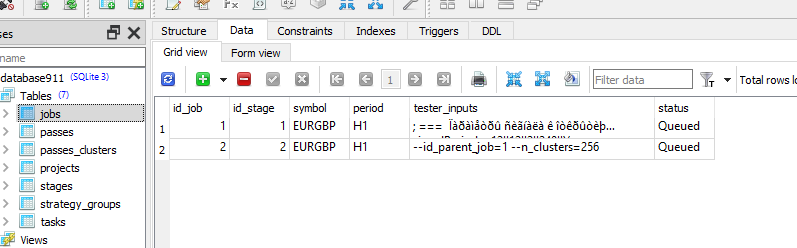
Compruebe que en el trabajo para esta tarea tiene los valores correctos en la columna [tester_inputs]. Estos son:
--id_parent_job=1 --n_clusters=256
donde 1 es id_job para el trabajo de la primera etapa. En tu caso puede ser otro valor numérico.
También puede intentar ejecutar el programa Python con los parámetros reales manualmente desde la línea de comandos y entonces usted será capaz de ver los posibles mensajes de error de la misma
Hola
Parece que la ejecución del programa Python no cambia el estado de la tarea con id_task =1.
Comprueba que en el trabajo para esta tarea tienes los valores correctos en la columna [tester_inputs]. Hay:
donde 1 es id_job para el trabajo de la primera etapa. En su caso puede ser otro valor numérico.
También puede intentar ejecutar el programa Python con los parámetros reales manualmente desde la línea de comandos y entonces usted será capaz de ver los posibles mensajes de error de la misma
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
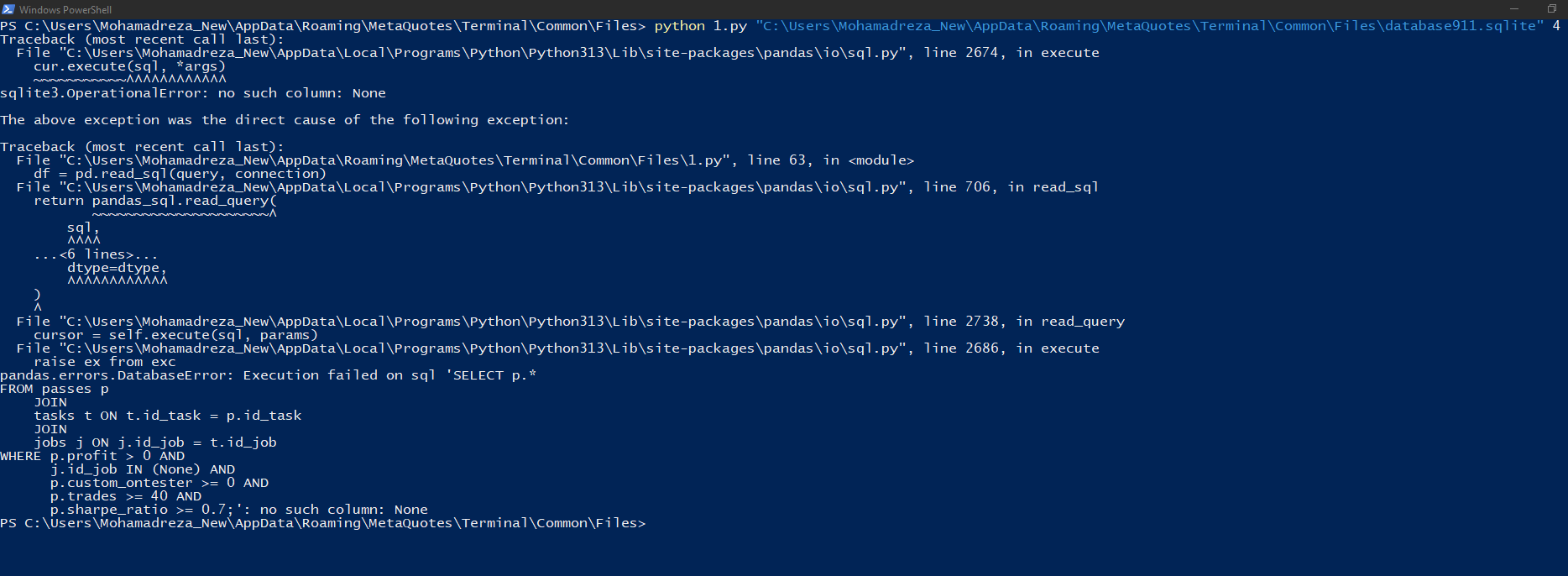
lo ejecuto en powershell y veo esto
Intenta ejecutarlo así:
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" usage: ClusteringStage1.py [-h] [--id_parent_job ID_PARENT_JOB] [--n_clusters N_CLUSTERS] [--min_custom_ontester MIN_CUSTOM_ONTESTER] [--min_trades MIN_TRADES] [--min_sharpe_ratio MIN_SHARPE_RATIO] db_path id_task ClusteringStage1.py: error: the following arguments are required: db_path, id_task
Tenemos que establecer los argumentos: db_path, id_task. Entonces tenemos un mensaje de error como el que has publicado:
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" "C:\Users\Antekov\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 Traceback (most recent call last): File "C:\Python\Python312\Lib\site-packages\pandas\io\sql.py", line 2674, in execute cur.execute(sql, *args) sqlite3.OperationalError: no such column: None The above exception was the direct cause of the following exception: Traceback (most recent call last): ... File "C:\Python\Python312\Lib\site-packages\pandas\io\sql.py", line 2686, in execute raise ex from exc pandas.errors.DatabaseError: Execution failed on sql 'SELECT p.* FROM passes p JOIN tasks t ON t.id_task = p.id_task JOIN jobs j ON j.id_job = t.id_job WHERE p.profit > 0 AND j.id_job IN (None) AND p.custom_ontester >= 0 AND p.trades >= 40 AND p.sharpe_ratio >= 0.7;': no such column: None
También necesitamos establecer dos argumentos: --id_parent_job=1 --n_clusters=256
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" "C:\Users\Antekov\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
¿Qué obtendrá?
Ejecuto esto
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1. py.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
y obtengo este error
ValueError: n_samples=150 debería ser >= n_clusters=256.
entonces cambio n_clusters=150 y ejecuto
python -u "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Users\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=150
y creo que funcionó. pero en la base de datos no hay ningun cambio
despues de eso intente optimizar con n_samples=150 pero no funciono
¡Interesante artículo! Leeré toda la serie.
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
¿Por qué abandonaron la funcionalidad de la biblioteca AlgLib?
#include <Math\Alglib\alglib.mqh> Menos sólo en velocidad, pero sobre todo porque python paraleliza los cálculos en todos los núcleos.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Desarrollamos un asesor experto multidivisa (Parte 19): Creando las etapas implementadas en Python:
Para realizar el clusterización, utilizaremos la biblioteca scikit-learn para Python ya lista, más concretamente una implementación del algoritmo K-Means. Este no es el único algoritmo de clusterización, pero considerar otros posibles, así como comparar y seleccionar el mejor aplicado a esta tarea, superaba los límites aceptables. Por consiguiente, tomamos esencialmente el primer algoritmo que encontramos, y los resultados obtenidos tras su uso resultaron ser bastante buenos.
Sin embargo, el uso de esta implementación en particular hizo necesario ejecutar un pequeño programa en Python. De todas formas, cuando realizábamos la mayoría de las operaciones a mano, no era un problema. Pero ahora que vamos camino de automatizar el proceso completo de pruebas y selección de buenos grupos de instancias de estrategias comerciales individuales, la presencia incluso de una simple operación manual ejecutada en medio de un pipeline de tareas de optimización ejecutadas secuencialmente tiene mala pinta.
Para corregir esta desafortunada incongruencia, podemos tomar dos caminos. El primero consiste en encontrar una implementación lista del algoritmo de clusterización escrita en MQL5 o escribirla uno mismo, si la búsqueda no da buenos resultados. La segunda forma implica añadir la posibilidad de ejecutar no solo asesores expertos escritos en MQL5, sino también programas Python en las etapas necesarias del proceso de optimización automática.
Autor: Yuriy Bykov