
Desarrollamos un asesor experto multidivisa (Parte 17): preparación adicional para el trading real
Introducción
En uno de los artículos anteriores, ya hemos llamado su atención sobre las modificaciones del EA necesarias para trabajar en cuentas reales. Antes de esto, nuestros esfuerzos se centraban principalmente en obtener resultados aceptables de los EA en el simulador de estrategias. Pero el trabajo para avanzar hacia el comercio real no ha finalizado, aún queda mucho por hacer.
Además de la restauración del trabajo del asesor experto tras reiniciar el terminal, la posibilidad de utilizar nombres ligeramente diferentes de los instrumentos comerciales y la finalización automática de la negociación al alcanzarse los indicadores especificados, también nos enfrentamos al siguiente problema: para formar la cadena de inicialización, utilizamos la información obtenida directamente de la base de datos, que almacena todos los resultados de la optimización de las instancias de estrategias comerciales y sus grupos.
Para ejecutar el asesor experto, deberemos tener un archivo con la base de datos en la carpeta común de los terminales. El tamaño de la base de datos ya es de varios gigabytes y no hará sino crecer en el futuro. Por consiguiente, no sería racional hacer que la base de datos forme parte del EA, ya que solo se necesitará una parte muy pequeña de la información almacenada en ella para ejecutarlo. Por ello, deberemos implementar un mecanismo para extraer y utilizar esta información en el asesor experto.
Trazando el camino
Como recordatorio, hemos revisado y puesto en marcha la automatización de las dos etapas de las pruebas. En la primera etapa, se optimizan los parámetros de una única estrategia comercial (tratamos el tema en la parte 11). La estrategia comercial modelo investigada utiliza solo un instrumento comercial (símbolo) y un marco temporal. Así que la ejecutaremos constantemente en el optimizador, cambiando los símbolos y marcos temporales. En cada combinación de símbolo y marco temporal, la optimización se ha realizado sucesivamente utilizando distintos criterios de optimización. Todos los resultados de las pasadas de optimización se han registrado en la tabla de pasadas de nuestra base de datos.
En el segundo paso, realizamos una optimización para seleccionar el grupo de conjuntos de parámetros obtenidos en el primer paso que ofrezca los mejores resultados al trabajar juntos (analizados en la parte 6 y 13). En un grupo, al igual que en la primera etapa, hemos incluido conjuntos de parámetros que utilizaban el mismo par símbolo-marco temporal. La información sobre los resultados de todos los grupos buscados durante la optimización también se ha almacenado en nuestra base de datos.
En la tercera etapa, ya no hemos utilizado el optimizador interno del simulador de estrategias, por lo que aún no hablaremos de automatizarlo. La tercera etapa consistió en seleccionar el mejor grupo encontrado en la segunda etapa para cada combinación disponible de símbolo y marco temporal. Hemos utilizado la optimización en tres símbolos (EURGBP, EURUSD, GBPUSD) y tres marcos temporales (H1, M30, M15). Así, el resultado de la tercera etapa serán nueve grupos seleccionados. Pero para simplificar y agilizar los cálculos en el simulador, en los últimos artículos nos hemos limitado solo a los tres mejores grupos (con tres símbolos diferentes y el marco temporal H1).
Como resultado de la tercera etapa, hemos obtenido un conjunto de identificadores de fila de la tabla passes, que transmitiremos como parámetro de entrada a nuestro asesor experto final SimpleVolumesExpert.mq5:
input string passes_ = "734469," "736121," "776928"; // - Comma-separated pass IDs
Si lo deseamos, podemos cambiar este parámetro antes de ejecutar la prueba del EA. De este modo, ha resultado posible ejecutar el EA final con cualquier subconjunto de grupos deseado de los muchos disponibles en la base de datos en la tabla passes. Para ser exactos, no exactamente con cualquiera, sino con un conjunto que no supere los 247 caracteres de longitud al escribirse en una cadena delimitada por comas. Se trata de una restricción impuesta por el lenguaje MQL5 a los valores de los parámetros de cadena de entrada. Según la documentación, la longitud máxima de un valor de parámetro de cadena puede oscilar entre 191 y 253 caracteres, dependiendo de la longitud del nombre del parámetro.
Así que si queremos incluir más de, digamos, 40 grupos, no será posible hacerlo de esta manera. Por ejemplo, deberemos hacer que la variable passes_ no sea un parámetro de cadena de entrada, sino solo una variable de cadena, eliminando la palabra input del código. Luego podremos establecer el conjunto necesario de grupos solo en el código fuente. Sin embargo, por ahora no necesitaremos utilizar conjuntos tan grandes. Además, como han demostrado los experimentos de la parte 5, nos resultará más rentable evitar crear un grupo a partir de un gran número de instancias únicas de estrategias comerciales o grupos de estrategias comerciales. Resulta más rentable dividir el número inicial de instancias únicas de estrategias comerciales en varios subgrupos, a partir de los cuales se podrá reunir un número menor de nuevos grupos. Estos nuevos grupos podrán fusionarse en un grupo final o podremos repetir el proceso de agrupación en nuevos subgrupos. Por ello, en cada nivel de combinación, tendremos que tomar un número relativamente pequeño de estrategias o grupos en el mismo grupo.
Cuando el EA tenga acceso a la base de datos con los resultados de todas las pasadas de optimización, bastará con transmitir una lista de identificadores de las pasadas de optimización requeridas a través del parámetro de entrada. El propio asesor experto recibirá de la base de datos las cadenas de inicialización de aquellos grupos de estrategias comerciales que han participado en las pasadas enumeradas. Utilizando las cadenas de inicialización obtenidas de la base de datos, el asesor construirá la cadena de inicialización del objeto de asesor experto, que incluirá todas las estrategias comerciales de los grupos listados. Este EA negociará utilizando todas las instancias de estrategias comerciales introducidas en él.
Cuando no haya acceso a la base de datos, el asesor experto todavía necesitará generar de alguna manera la cadena de inicialización del objeto de asesor experto que contenga la composición requerida de instancias individuales de estrategias comerciales o grupos de estrategias comerciales. Podemos, por ejemplo, guardarla en un archivo y transmitir el nombre del archivo al asesor experto desde donde este cargará la cadena de inicialización. O podemos insertar el contenido de la cadena de inicialización en el código fuente del EA a través de un archivo opcional de la biblioteca mqh. Incluso podemos combinar estos dos métodos: guardando la cadena de inicialización en un archivo y luego importándola con las herramientas de importación de archivos del MetaEditor (Edición → Insertar → Archivo).
Sin embargo, si queremos ofrecer la oportunidad de trabajar con diferentes grupos seleccionados en un asesor experto eligiendo el necesario en los parámetros de entrada, este enfoque mostrará su escasa escalabilidad con bastante rapidez. Nos veremos obligados a hacer mucho trabajo manual monótono. Así que intentaremos formular la tarea de forma un poco distinta: queremos formar una biblioteca de buenas cadenas de inicialización, entre las que podamos elegir una para el inicio actual del EA. La biblioteca deberá ser parte integrante del EA, para que no tengamos que cargar con otro archivo aparte.
Considerando esto, el trabajo a realizar podría desglosarse en los siguientes pasos:
- Selección y almacenamiento. Como parte de este paso, deberemos disponer de una herramienta que nos permita seleccionar grupos y guardar sus cadenas de inicialización para su uso posterior. Probablemente no esté de más ofrecer la posibilidad de guardar alguna información adicional sobre los grupos seleccionados (nombre, descripción breve, composición aproximada, fecha de creación, etc.).
- Formación de bibliotecas. A partir de los grupos seleccionados en el paso anterior, realizaremos una selección final de los que se utilizarán como parte de la biblioteca para una versión concreta del EA y generaremos un archivo de inclusión con toda la información necesaria.
- Creación del asesor final. Modificando el EA de la parte anterior, lo convertiremos en un nuevo EA final usando la biblioteca de grupos creada. Este EA ya no necesitará acceder a nuestra base de datos de optimización, ya que en ella se incluirá toda la información necesaria sobre los grupos de estrategias comerciales utilizados.
Venga, pues manos a la obra.
Recordamos lo que ya hemos hecho
Los pasos anteriores suponen un prototipo de aplicación del paso 8 descrito en la parte 9. Recuerde que en ese artículo enumeramos una serie de pasos cuya realización puede permitirnos obtener un asesor experto listo con un buen rendimiento comercial. La etapa 8 solo significaba que reunimos en un EA final todos los mejores grupos de grupos encontrados para diferentes estrategias comerciales, símbolos, marco temporales y otros parámetros. Sin embargo, aún no hemos examinado con detalle la pregunta: ¿cómo debemos elegir exactamente los mejores grupos?
Por un lado, la respuesta puede resultar elemental. Por ejemplo, simplemente elegimos entre todos los resultados del grupo el mejor según algún parámetro (rentabilidad total, ratio de Sharpe, rentabilidad media anual normalizada). Pero, por otro lado, la respuesta también podría ser mucho más complicada. Por ejemplo, ¿y si obtenemos mejores resultados en las pruebas utilizando un criterio compuesto para seleccionar a los mejores grupos? ¿Y si incluso algunos de los mejores grupos no deben incluirse en absoluto en el EA final, ya que su inclusión degradaría los resultados obtenidos sin ellos? Es probable que este tema requiera su propio análisis exhaustivo.
Otra cuestión que también requerirá un estudio aparte es la partición óptima de los grupos en subgrupos con normalización de subgrupos. En la parte 5, incluso antes de empezar a automatizar las etapas de prueba, ya abordamos esta cuestión. A continuación, seleccionamos manualmente nueve instancias únicas de estrategias comerciales, tres instancias por cada uno de los tres instrumentos comerciales (símbolos) utilizados.
Resultó que si primero hacemos tres grupos normalizados de tres estrategias para cada símbolo y luego los combinamos en un grupo normalizado final, los resultados en las pruebas serán ligeramente mejores en comparación con la combinación de nueve instancias individuales de estrategias comerciales en un grupo normalizado final. Pero no podemos saber con certeza si esta forma concreta de agrupación resultará óptima. ¿Y se vería favorecida por otras estrategias comerciales en comparación con la combinación simple en un solo grupo? De todos modos, aquí también hay terreno para seguir investigando.
Afortunadamente, podemos dejar estas dos cuestiones para más adelante. Para explorarlas, necesitaríamos usar herramientas auxiliares que aún no se han puesto en práctica. Y sin ellas, el trabajo será mucho menos eficiente y nos llevará mucho más tiempo.
Selección y almacenamiento de grupos
Parece que ya tenemos todo lo necesario. Ahora tomaremos el asesor experto existente SimpleVolumesExpert.mq5 de la última parte, especificaremos en el parámetro de entrada passes_ los identificadores de las pasadas separados por comas, ejecutaremos una única pasada del simulador y obtendremos la cadena de inicialización requerida guardada en la base de datos. Solo nos hace falta información adicional. Pero resulta que la información de la pasada no se ha introducido en la base de datos.
La cuestión es que solo tenemos los resultados de las pasadas de optimización cargados en la base de datos. Pero no es posible descargar los resultados de una sola pasada. Recordemos que la carga se realiza dentro del método CTesterHandler::ProcessFrames(), que a nivel superior es llamado desde el manejador OnTesterPass():
//+------------------------------------------------------------------+ //| Handling incoming frames | //+------------------------------------------------------------------+ void CTesterHandler::ProcessFrames(void) { // Open the database DB::Connect(); // Variables for reading data from frames ... // Go through frames and read data from them while(FrameNext(pass, name, id, value, data)) { // Convert the array of characters read from the frame into a string values = CharArrayToString(data); // Form a string with names and values of the pass parameters inputs = GetFrameInputs(pass); // Form an SQL query from the received data query = StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %d, %s,\n'%s',\n'%s');", s_idTask, pass, values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); // Add it to the SQL query array APPEND(queries, query); } // Execute all requests DB::ExecuteTransaction(queries); // Close the database DB::Close(); }
Este manejador no se llama cuando se inicia una pasada única, ya que esto no se contempla en el modelo de eventos de pasada única. Este manejador solo se llama en un EA que se esté ejecutando en el modo de recopilación de frames de datos. El inicio de una instancia del EA en este modo se producirá automáticamente al iniciar la optimización, pero no se producirá al iniciar una sola pasada. Por lo tanto, resulta que la aplicación existente no guardará la información de una sola pasada en la base de datos.
Obviamente, podemos dejar todo como está y crear un asesor experto que se deba ejecutar para la optimización según algún parámetro innecesario. El objetivo de esta optimización sería obtener los resultados de la primera pasada, tras lo cual se detendrá la optimización. De esta forma, la base de datos obtendrá los resultados de la pasada. Pero eso me parece demasiado antiestético, así que iremos por otro camino.
Al iniciarse una sola pasada en un asesor experto, el manejador OnTester() se llamará al final de esta. Por lo tanto, tendremos que insertar el código para guardar los resultados de una sola pasada directamente en el manejador o en uno de los métodos que se llaman desde este manejador. Probablemente el lugar más apropiado para insertarlo sea el método CTesterHandler::Tester(). Sin embargo, deberemos considerar que este método también se llamará cuando el EA complete la pasada de optimización. Ahora, el código que genera y envía los resultados de la pasada de optimización a través del mecanismo del frame de datos ya se encuentra en este método.
Al ejecutar una sola pasada, se seguirán generando los datos para el frame, pero el propio frame de datos, aunque se haya creado, no se podrá utilizar. Si intentamos usar la función de recuperación de frames FrameNext() después de crear un frame con FrameAdd() en un EA que se ejecute en el modo de pasada única, FrameNext() no leerá el frame creado. Se comportará como si no se hubiera creado ningún frame.
Por eso haremos lo siguiente: en el manejador CTesterHandler::Tester() comprobaremos si esta pasada es única o se realiza en el marco de la optimización. Dependiendo del resultado, guardaremos directamente los resultados de la pasada en la base de datos (para una sola pasada), o crearemos un frame de datos para enviarlo al asesor experto principal (para la optimización). Ahora añadiremos un nuevo método llamado para guardar una sola pasada y un método auxiliar adicional que forma una consulta SQL para insertar los datos requeridos en la tabla passes. Necesitaremos esto último porque ahora esta acción se realizará en dos lugares del código en lugar de uno. Por eso lo pondremos en un método aparte.
//+------------------------------------------------------------------+ //| Optimization event handling class | //+------------------------------------------------------------------+ class CTesterHandler { ... static void ProcessFrame(string values); // Handle single pass data // Generate SQL query to insert pass results static string GetInsertQuery(string values, string inputs, ulong pass = 0); public: ... };
La implementación del método GetInsertQuery() ya la tenemos, todo lo que deberemos hacer es transferir el bloque de código del método ProcessFrames() y llamarlo en el lugar necesario del método ProcessFrames():
//+------------------------------------------------------------------+ //| Generate SQL query to insert pass results | //+------------------------------------------------------------------+ string CTesterHandler::GetInsertQuery(string values, string inputs, ulong pass) { return StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %d, %s,\n'%s',\n'%s');", s_idTask, pass, values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); } //+------------------------------------------------------------------+ //| Handling incoming frames | //+------------------------------------------------------------------+ void CTesterHandler::ProcessFrames(void) { ... // Go through frames and read data from them while(FrameNext(pass, name, id, value, data)) { // Convert the array of characters read from the frame into a string values = CharArrayToString(data); // Form a string with names and values of the pass parameters inputs = GetFrameInputs(pass); // Form an SQL query from the received data query = GetInsertQuery(values, inputs, pass); // Add it to the SQL query array APPEND(queries, query); } ... }
Para guardar los datos de una pasada única, llamaremos al nuevo método ProcessFrame(), que adopta como parámetro una línea que es parte de la consulta SQL y contiene los datos sobre la pasada para su incorporación en la tabla passes. Dentro del propio método, simplemente nos conectaremos a la base de datos, generaremos la consulta SQL final y la ejecutaremos:
//+------------------------------------------------------------------+ //| Handle single pass data | //+------------------------------------------------------------------+ void CTesterHandler::ProcessFrame(string values) { // Open the database DB::Connect(); // Form an SQL query from the received data string query = GetInsertQuery(values, "", 0); // Execute the request DB::Execute(query); // Close the database DB::Close(); }
Teniendo en cuenta los métodos añadidos, el manejador de eventos de finalización de la pasada puede modificarse como sigue:
//+------------------------------------------------------------------+ //| Handling completion of tester pass for agent | //+------------------------------------------------------------------+ void CTesterHandler::Tester(double custom, // Custom criteria string params // Description of EA parameters in the current pass ) { ... // Generate a string with pass data data = StringFormat("%s,'%s'", data, params); // If this is a pass within the optimization, if(MQLInfoInteger(MQL_OPTIMIZATION)) { // Open a file to write a frame data int f = FileOpen(s_fileName, FILE_WRITE | FILE_TXT | FILE_ANSI); // Write a description of the EA parameters FileWriteString(f, data); // Close the file FileClose(f); // Create a frame with data from the recorded file and send it to the main terminal if(!FrameAdd("", 0, 0, s_fileName)) { PrintFormat(__FUNCTION__" | ERROR: Frame add error: %d", GetLastError()); } } else { // Otherwise, it is a single pass, call the method to add its results to the database CTesterHandler::ProcessFrame(data); } }
Guardaremos los cambios realizados en el archivo TesterHandler.mqh en la carpeta actual.
Ahora, después de cada pasada, la información sobre sus resultados se introducirá en nuestra base de datos. Para la tarea actual, no nos importan tanto las distintas medidas estadísticas de la pasada. Lo más importante para nosotros es la cadena de inicialización almacenada del grupo normalizado de estrategias usadas en la pasada. Precisamente de eso se trataba este almacenamiento.
Pero la presencia de las cadenas de inicialización requeridas en una de las columnas de la tabla passes no resulta suficiente para su cómoda utilización posterior. También querríamos adjuntar algo de información a la cadena de inicialización. Pero no merece la pena ampliar el conjunto de columnas de la tabla passes porque sí, ya que la gran mayoría de líneas de esta tabla almacenarán información sobre los resultados de las pasadas de optimización para los que no se necesita información adicional.
Así que crearemos una nueva tabla que se utilizará para almacenar los resultados seleccionados. Quizá esto pueda atribuirse ya a la etapa de formación de la biblioteca.
Formación de la biblioteca
No sobrecargaremos la nueva tabla con campos redundantes con información que se puede recuperar de otras tablas de la base de datos. Por ejemplo, si un registro de una tabla nueva tiene una relación de clave externa con un registro de la tabla passes, ya tendrá una fecha de creación. También podemos utilizar el identificador de la pasada para construir una cadena de enlaces y determinar a qué proyecto pertenece la pasada y, por tanto, el grupo de estrategias utilizadas en la misma.
Teniendo esto en cuenta, crearemos una tabla strategy_groups con el siguiente conjunto de campos:
- id_pass. Identificador de pasada de la tabla passes (clave externa)
- name. Nombre del grupo de estrategias que se utilizará para generar las enumeraciones para el parámetro de entrada de selección del grupo de estrategias.
El código SQL para crear la tabla requerida podría ser el siguiente:
-- Table: strategy_groups DROP TABLE IF EXISTS strategy_groups; CREATE TABLE strategy_groups ( id_pass INTEGER REFERENCES passes (id_pass) ON DELETE CASCADE ON UPDATE CASCADE PRIMARY KEY, name TEXT );
Para realizar la mayoría de las siguientes acciones, crearemos la clase auxiliar CGroupsLibrary. Sus tareas incluirán insertar y recuperar información sobre grupos de estrategias de la base de datos, formando un archivo mqh con la biblioteca real de grupos buenos, que será usada por el asesor experto final. Volveremos a ello un poco más tarde, por ahora crearemos un EA que usaremos para formar una biblioteca.
El asesor experto SimpleVolumesExpert.mq5 existente, aunque hace casi todo lo que necesitamos, todavía necesita mejoras. Además, pensábamos utilizarlo como versión definitiva del asesor final. Por lo tanto, lo guardaremos con un nuevo nombre SimpleVolumesStage3.mq5, y realizaremos las adiciones necesarias al nuevo archivo. Nos faltan dos cosas: la posibilidad de especificar el nombre del grupo formado para las pasadas seleccionadas actualmente (en el parámetro passes_) y el almacenamiento de la cadena de inicialización de este grupo en una nueva tabla strategy_groups.
La primera se realizará de forma muy sencilla. Para ello, añadiremos un nuevo parámetro de entrada del asesor experto, cuyo valor se utilizará como el nombre del grupo. Si este parámetro tiene un valor vacío, no se guardará en la biblioteca.
input group "::: Saving to library" input string groupName_ = ""; // - Group name (if empty - no saving)
Pero para la segunda, vamos a tener que trabajar un poco más. La cuestión es que para insertar datos en la tabla strategy_groups , necesitaremos conocer el identificador que se ha asignado al registro de la pasada actual al insertarlo en la tabla passes. Como su valor es asignado automáticamente por la propia base de datos (solo transmitimos NULL en lugar de su valor en la consulta), no existe en el código como valor de ninguna variable. Así que actualmente no podemos usarlo en otros lugares donde sea necesario. Tendremos que definir este valor de alguna manera.
Existen diferentes maneras de hacerlo. Por ejemplo, sabiendo que los identificadores asignados a las nuevas filas forman una secuencia creciente, podremos simplemente seleccionar el valor del identificador máximo actual después de la incorporación. Esto se puede hacer si sabemos con seguridad que no se añadirán nuevas filas a la tabla passes en ese momento. Pero si otra optimización de la primera o la segunda etapa se está ejecutando en paralelo, sus resultados podrían acabar en la misma base de datos. En este caso, ya no podremos estar seguros de que el último identificador sea el que se corresponde con la pasada de formación de la biblioteca que estamos ejecutando. En general, solo podremos hacer así si estamos dispuestos a admitir ciertas limitaciones y ser conscientes de ellas.
Un método mucho más fiable, libre de los posibles errores del anterior, sería el siguiente. Podemos modificar ligeramente la consulta SQL de incorporación de datos convirtiéndola en una consulta que retorne como resultado el ID de la nueva fila de la tabla generada. Para ello, bastará con añadir el operador "RETURNING rowid" al final de la consulta SQL. Haremos esto en el método GetInsertQuery(), que forma una consulta SQL para insertar una nueva fila en la tabla passes. Aunque la columna identificadora de la tabla passes se llama id_pass, podremos llamarla rowid porque tiene el tipo apropiado (INTEGER PRIMARY KEY AUTOINCREMENT) y sustituirá a la columna rowid, que se oculta automáticamente en las tablas SQLite.
//+------------------------------------------------------------------+ //| Generate SQL query to insert pass results | //+------------------------------------------------------------------+ string CTesterHandler::GetInsertQuery(string values, string inputs, ulong pass) { return StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %d, %s,\n'%s',\n'%s') RETURNING rowid;", s_idTask, pass, values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); }
También tendremos que modificar el código MQL5 que envía esta consulta. Ahora usaremos el método DB::Execute(query) para esto, lo cual implicará que la consulta query transmitida no será una consulta que retorne ningún dato.
Así que añadiremos un nuevo método Insert() a la clase CDatabase, que ejecutará la petición de incorporación transmitida y retornará un único valor de resultado de lectura. En su interior, en lugar de DatabaseExecute(), usaremos DatabasePrepare(), que nos permitirá acceder a los resultados de la consulta:
//+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { ... public: ... // Execute a query to the database for insertion with return of the new entry ID static ulong Insert(string query); }; ... //+------------------------------------------------------------------+ //| Execute a query to the database for insertion returning the | //| new entry ID | //+------------------------------------------------------------------+ ulong CDatabase::Insert(string query) { ulong res = 0; // Execute the request int request = DatabasePrepare(s_db, query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { int rowid; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { res = row.rowid; } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Request \n%s\nfailed with code %d", query, GetLastError()); } return res; } //+------------------------------------------------------------------+
No complicaremos este método con comprobaciones adicionales sobre si la consulta transmitida es una consulta INSERT que contiene un identificador de comando de retorno y sobre si el valor devuelto no es compuesto. Desviarse de estas condiciones causará errores al ejecutar este código, pero como este método se utilizará en el único lugar del proyecto hasta ahora, intentaremos transmitirle una consulta correcta.
Luego guardaremos los cambios realizados en el archivo Database.mqh en la carpeta actual.
La siguiente cuestión que ha surgido durante la implementación es cómo transmitir el valor del identificador al nivel del código superior, ya que procesarlo en el punto de recepción provoca la necesidad de dotar a los métodos existentes de funcionalidades extrañas y parámetros transmitidos adicionales. Por eso hemos decidido hacerlo de esta manera: hemos añadido una propiedad estática s_idPass a la clase CTesterHandler. En ella se ha escrito el identificador de la pasada actual. Desde esta ubicación, podemos obtener el valor ya en cualquier punto del programa:
//+------------------------------------------------------------------+ //| Optimization event handling class | //+------------------------------------------------------------------+ class CTesterHandler { ... public: ... static ulong s_idPass; }; ... ulong CTesterHandler::s_idPass = 0; ... //+------------------------------------------------------------------+ //| Handle single pass data | //+------------------------------------------------------------------+ void CTesterHandler::ProcessFrame(string values) { // Open the database DB::Connect(); // Form an SQL query from the received data string query = GetInsertQuery(values, "", 0); // Execute the request s_idPass = DB::Insert(query); // Close the database DB::Close(); }
Guardaremos los cambios realizados en el archivo TesterHandler.mqh en la carpeta actual.
Ahora es el momento de volver a la clase auxiliar declarada CGroupsLibrary. Al final hemos necesitado declarar dos métodos públicos, un método privado y un array estático:
//+------------------------------------------------------------------+ //| Class for working with a library of selected strategy groups | //+------------------------------------------------------------------+ class CGroupsLibrary { private: // Exporting group names and initialization strings extracted from the database as MQL5 code static void ExportParams(string &p_names[], string &p_params[]); public: // Add the pass name and ID to the database static void Add(ulong p_idPass, string p_name); // Export passes to mqh file static void Export(string p_idPasses); // Array to fill with initialization strings from mqh file static string s_params[]; };
En el asesor experto que utilizaremos para formar la biblioteca, solo utilizaremos el método Add(). Se le transmitirá el ID de la pasada y el nombre del grupo que se guardará en la biblioteca. El código del método en sí es muy sencillo: formamos una consulta SQL a partir de los datos de entrada para incorporar un nuevo registro en la tabla strategy_groups y la ejecutamos.
//+------------------------------------------------------------------+ //| Add the pass name and ID to the database | //+------------------------------------------------------------------+ void CGroupsLibrary::Add(ulong p_idPass, string p_name) { string query = StringFormat("INSERT INTO strategy_groups VALUES(%d, '%s')", p_idPass, p_name); // Open the database if(DB::Connect()) { // Execute the request DB::Execute(query); // Close the database DB::Close(); } }
Ahora, para completar el desarrollo de la herramienta de formación de la biblioteca, solo tendremos que añadir al asesor experto SimpleVolumesStage3.mq5 la llamada al método Add() una vez completada la pasada de prueba:
//+------------------------------------------------------------------+ //| Test results | //+------------------------------------------------------------------+ double OnTester(void) { // Handle the completion of the pass in the EA object double res = expert.Tester(); // If the group name is not empty, save the pass to the library if(groupName_ != "") { CGroupsLibrary::Add(CTesterHandler::s_idPass, groupName_); } return res; }
Luego guardaremos los cambios realizados en los archivos SimpleVolumesStage3.mq5 y GroupsLibrary.mqh en la carpeta actual. Si añadimos stubs para otros métodos de la clase CGroupsLibrary, ya podremos utilizar el asesor experto compilado SimpleVolumesStage3.mq5.
Rellenamos la biblioteca
Ahora intentaremos formar una biblioteca a partir de los nueve buenos identificadores de pasada disponibles que hemos seleccionado antes. Para ello, ejecutaremos el asesor experto SimpleVolumesStage3.ex5 en el simulador, indicando en el parámetro de entrada passes_ varias combinaciones seleccionadas de entre nueve identificadores. En el parámetro de entrada groupName_ asignaremos un nombre comprensible que refleje la composición del grupo actual de instancias únicas de estrategias comerciales que se combinan en un grupo.
Después de varias ejecuciones, veremos los resultados en la tabla strategy_groups, añadiendo para mayor informatividad algunos indicadores de las pasadas realizados con diferentes grupos. Por ejemplo, esta consulta SQL nos ayudará en ello:
SELECT sg.id_pass, sg.name, p.custom_ontester, p.sharpe_ratio, p.profit, p.profit_factor, p.equity_dd_relative FROM strategy_groups sg JOIN passes p ON sg.id_pass = p.id_pass;
La consulta da como resultado la siguiente tabla:

Fig. 1. Composición de la biblioteca de grupos
En la columna names vemos los nombres de los grupos que reflejan los instrumentos comerciales (símbolos), los marcos temporales y el número de instancias de estrategias comerciales utilizadas en este grupo. Por ejemplo, la presencia de "EUR-GBP-USD" indica que este grupo incluye instancias de estrategias comerciales que funcionan con tres símbolos: EURGBP, EURUSD y GBPUSD. Si el nombre del grupo empieza por "Only EURGBP", entonces incluirá instancias de estrategias solo para el símbolo EURGBP. Los marcos temporales utilizados se leerán de la misma manera. Al final del nombre figurará el número de instancias de estrategias comerciales. Por ejemplo, "3х16 items" indicará que este grupo combina tres grupos normalizados de 16 estrategias cada uno.
En la columna custom_ontester, podemos ver el beneficio medio anual normalizado de cada grupo. Cabe señalar que la dispersión de los valores de este parámetro ha superado lo esperado, por lo que en el futuro sería necesario comprender las causas de este fenómeno. Por ejemplo, el resultado de los grupos en los que solo se ha utilizado GBPUSD ha resultado notablemente mayor que el de los grupos con símbolos múltiples. El mejor resultado se ha guardado al final en la fila 20. En este grupo incluiremos los subgrupos que han dado los mejores resultados para cada símbolo y uno o más marcos temporales.
Exportación de la biblioteca
El siguiente paso consistirá en transferir la biblioteca de grupos de la base de datos a un archivo mqh que pueda introducirse en el EA final. Para ello, escribiremos en la clase CGroupsLibrary una implementación de métodos responsable de la exportación y otro EA auxiliar que se utilizará para ejecutar dichos métodos.
En el método Export(), recuperaremos los nombres de los grupos de bibliotecas y sus cadenas de inicialización de la base de datos y los añadiremos a los arrays correspondientes. Los arrays generados se transmitirán al siguiente método ExportParams():
//+------------------------------------------------------------------+ //| Exporting passes to mqh file | //+------------------------------------------------------------------+ void CGroupsLibrary::Export(string p_idPasses) { // Array of group names string names[]; // Array of group initialization strings string params[]; // If the connection to the main database is established, if(DB::Connect()) { // Form a request to receive passes with the specified IDs string query = "SELECT sg.id_pass," " sg.name," " p.params" " FROM strategy_groups sg" " JOIN" " passes p ON sg.id_pass = p.id_pass"; query = StringFormat("%s " "WHERE p.id_pass IN (%s);", query, p_idPasses); // Prepare and execute the request int request = DatabasePrepare(DB::Id(), query); // If the request is successful if(request != INVALID_HANDLE) { // Structure for reading results struct Row { ulong idPass; string name; string params; } row; // For all query results, add the name and initialization string to the arrays while(DatabaseReadBind(request, row)) { APPEND(names, row.name); APPEND(params, row.params); } } DB::Close(); // Export to mqh file ExportParams(names, params); } }
En el método ExportParams(), formaremos una cadena con código MQL5 que creará una enumeración (enum) con el nombre dado ENUM_GROUPS_LIBRARY y la rellenará de elementos. A cada elemento se le hará un comentario con el nombre del grupo. A continuación, el código declarará un array estático de cadenas CGroupsLibrary::s_params[], que se rellenará con cadenas de inicialización para los grupos de la biblioteca. Cada cadena de inicialización se preprocesará: todos los caracteres de avance de línea se sustituirán por espacios y se añadirá una barra invertida antes de las comillas dobles. Esto se hace para colocar la cadena de inicialización dentro de las comillas dobles en el código generado.
Después de que el código esté completamente formado en la variable data, crearemos un archivo llamado ExportedGroupsLibrary.mqh y lo guardaremos en él el código resultante.
//+------------------------------------------------------------------+ //| Export group names extracted from the database and | //| initialization strings in the form of MQL5 code | //+------------------------------------------------------------------+ void CGroupsLibrary::ExportParams(string &p_names[], string &p_params[]) { // ENUM_GROUPS_LIBRARY enumeration header string data = "enum ENUM_GROUPS_LIBRARY {\n"; // Fill the enumeration with group names FOREACH(p_names, { data += StringFormat(" GL_PARAMS_%d, // %s\n", i, p_names[i]); }); // Close the enumeration data += "};\n\n"; // Group initialization string array header and its opening bracket data += "string CGroupsLibrary::s_params[] = {"; // Fill the array by replacing invalid characters in the initialization strings string param; FOREACH(p_names, { param = p_params[i]; StringReplace(param, "\r", ""); StringReplace(param, "\n", " "); StringReplace(param, "\"", "\\\""); data += StringFormat("\"%s\",\n", param); }); // Close the array data += "};\n"; // Open the file to write data int f = FileOpen("ExportedGroupsLibrary.mqh", FILE_WRITE | FILE_TXT | FILE_ANSI); // Write the generated code FileWriteString(f, data); // Close the file FileClose(f); }
Y luego viene la parte realmente importante:
// Connecting the exported mqh file. // It will initialize the CGroupsLibrary::s_params[] static variable // and ENUM_GROUPS_LIBRARY enumeration #include "ExportedGroupsLibrary.mqh"
Es decir, el archivo que se obtendrá tras la exportación; conectaremos este directamente dentro del archivo GroupsLibrary.mqh. En este caso, el EA final tendrá que conectar solo este archivo para poder usar la biblioteca exportada. Este enfoque causará un pequeño inconveniente: para poder compilar un EA que exporte la biblioteca, el archivo ExportedGroupsLibrary.mqh que aparecerá solo después de la exportación, ya deberá existir. No obstante, solo importará la presencia de este archivo, no su contenido. Por lo tanto, bastará con crear un archivo vacío con este nombre en la carpeta actual, y la compilación procederá sin errores.
Para ejecutar el método de exportación, necesitaremos un script o EA en el que hacerlo. Podría ser así:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Exporting from library" input string passes_ = "802150,802151,802152,802153,802154," "802155,802156,802157,802158,802159," "802160,802161,802162,802164,802165," "802166,802167,802168,802169,802173"; // - Comma-separated IDs of the saved passes //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Call the group library export method CGroupsLibrary::Export(passes_); // Successful initialization return(INIT_SUCCEEDED); } void OnTick() { ExpertRemove(); }
Usando el cambio del parámetro passes_, podremos elegir la composición y el orden en el que se exportarán los grupos de la biblioteca a la base de datos. Después de ejecutar este EA una vez, el archivo ExportedGroupsLibrary.mqh aparecerá en el gráfico en la carpeta de datos del terminal que debe moverse a la carpeta actual con el código del proyecto.
Creación del asesor final
Bien, ya hemos llegado a la etapa final. Lo único que queda por hacer es introducir pequeñas modificaciones en el asesor experto SimpleVolumesExpert.mq5. En primer lugar, tendremos que conectar el archivo GroupsLibrary.mqh a él:
#include "GroupsLibrary.mqh"
Entonces, en lugar del parámetro de entrada passes_, pondremos un nuevo parámetro de entrada, usando el cual será posible seleccionar un grupo de la biblioteca:
input group "::: Selection for the group" input ENUM_GROUPS_LIBRARY groupId_ = -1; // - Group from the library
En la función OnInit() en lugar de obtener las cadenas de inicialización de la base de datos según los identificadores de pasada (como se hacía antes), ahora solo tomaremos la cadena de inicialización del array CGroupsLibrary::s_params[] con un índice correspondiente al valor seleccionado del parámetro de entrada groupId_:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ... // Initialization string with strategy parameter sets string strategiesParams = NULL; // If the selected strategy group index from the library is valid, then if(groupId_ >= 0 && groupId_ < ArraySize(CGroupsLibrary::s_params)) { // Take the initialization string from the library for the selected group strategiesParams = CGroupsLibrary::s_params[groupId_]; } // If the strategy group from the library is not specified, then we interrupt the operation if(strategiesParams == NULL) { return INIT_FAILED; } ... // Successful initialization return(INIT_SUCCEEDED); }
Guardaremos los cambios realizados en el archivo SimpleVolumesExpert.mq5 en la carpeta actual.
Como hemos añadido comentarios con los nombres a los elementos de la enumeración ENUM_GROUPS_LIBRARY, podremos ver nombres claros (no solo una secuencia de números) en el cuadro de diálogo para seleccionar los parámetros del EA:
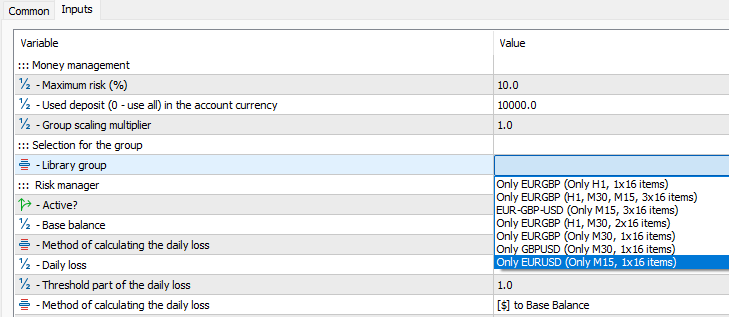
Fig. 2. Selección de un grupo de la biblioteca según su nombre en los parámetros del EA
Ahora ejecutaremos el EA con el último grupo de la lista y veremos el resultado:
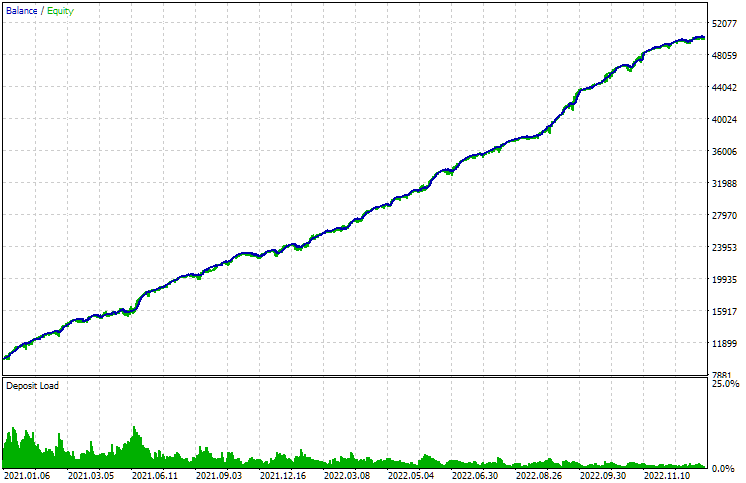
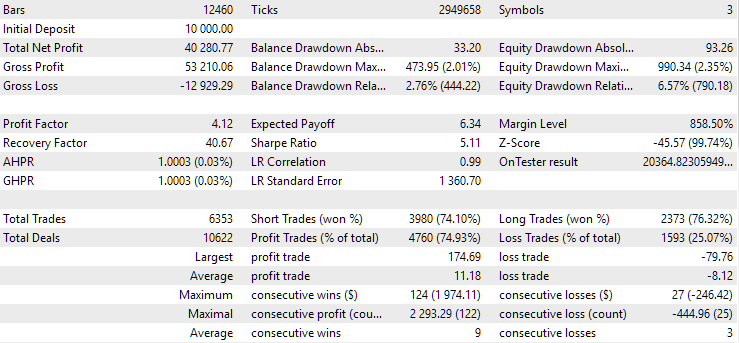
Fig. 3. Resultados de las pruebas del EA final con el grupo más atractivo de la biblioteca
Podemos observar que los resultados de la rentabilidad media anual normalizada se aproximan a los almacenados en la base de datos. Las pequeñas diferencias se deben principalmente a que el asesor experto final ha utilizado un grupo normalizado (podemos observar esto mirando el valor de la reducción relativa máxima, que es aproximadamente el 10% del depósito utilizado). Al generar la cadena de inicialización para este grupo en el asesor experto SimpleVolumesStage3.ex5 durante la pasada, el grupo no se ha normalizado todavía, por lo que la reducción ahí ha sido de aproximadamente 5,4%.
Conclusión
Bien, hemos conseguimos un EA final que puede funcionar independientemente de la base de datos rellenada en el proceso de optimización. Quizá volvamos sobre esta cuestión, ya que la práctica puede introducir sus propias correcciones, y el método propuesto en este artículo resultará menos conveniente que algún otro. Pero en cualquier caso, alcanzar un objetivo supone un paso adelante.
Al trabajar en el código para este artículo, hemos descubierto nuevas circunstancias que requieren más investigación. Por ejemplo, hemos notado que los resultados de las pruebas de este asesor experto son sensibles no solo al servidor de cotizaciones, sino también al símbolo que se selecciona como principal en la configuración del simulador de estrategias. Puede que tengamos que hacer algunos ajustes en la automatización de la optimización en la primera y la segunda etapa, pero eso será en otra ocasión.
Y por último, debemos advertirle sobre algo que ya ha estado implícitamente presente con anterioridad. En ninguna parte de las partes anteriores hemos dicho que seguir la dirección propuesta vaya a producir beneficios garantizados. Por el contrario, en algunos momentos obtenemos resultados decepcionantes. Además, a pesar de los esfuerzos dedicados a la preparación del asesor experto para el comercio real, difícilmente podemos decir en algún momento que hemos hecho todo lo posible e imposible para garantizar el correcto funcionamiento del EA en cuentas reales. Es una especie de ideal al que podemos y debemos aspirar, pero alcanzarlo supone siempre una cuestión de futuro impreciso. Aunque eso no nos impide acercarnos a él.
Todos los resultados expuestos en este artículo y en todos los artículos anteriores de la serie se basan únicamente en datos de pruebas históricas y no suponen ninguna garantía de beneficio en el futuro. El trabajo de este proyecto es de carácter exploratorio. Todos los resultados publicados pueden ser usados por cualquiera bajo su propia responsabilidad.
Gracias por su atención, ¡hasta pronto!
Contenido del archivo
| # | Nombre | Versión | Descripción | Cambios recientes |
|---|---|---|---|---|
| MQL5/Experts/Article.15360 | ||||
| 1 | Asesor.mqh | 1.04. | Clase básica del experto | Parte 10 |
| 2 | Database.mqh | 1.04. | Clase para trabajar con bases de datos | Parte 17 |
| 3 | ExpertHistory.mqh | 1.00 | Clase para exportar la historia de transacciones a un archivo | Parte 16 |
| 4 | ExportedGroupsLibrary.mqh | - | Archivo generado con los nombres de los grupos de estrategias y un array con sus cadenas de inicialización | Parte 17 |
| 5 | Factorable.mqh | 1.01 | Clase básica de objetos creados a partir de una cadena | Parte 10 |
| 6 | GroupsLibrary.mqh | 1.00 | Clase para trabajar con una biblioteca de grupos de estrategias seleccionados | Parte 17 |
| 7 | HistoryReceiverExpert.mq5 | 1.00 | Asesor experto para reproducir la historia de transacciones con el gestor de riesgos | Parte 16 |
| 8 | HistoryStrategy.mqh | 1.00 | Clase de estrategia comercial para reproducir la historia de transacciones | Parte 16 |
| 9 | Interface.mqh | 1.00 | Clase básica de visualización de diversos objetos | Parte 4 |
| 10 | LibraryExport.mq5 | 1.00 | Asesor que guarda las cadenas de inicialización de las pasadas seleccionadas de la biblioteca en el archivo ExportedGroupsLibrary.mqh | Parte 17 |
| 11 | Macros.mqh | 1.02 | Macros útiles para transacciones con arrays | Parte 16 |
| 12 | Money.mqh | 1.01 | Clase básica de gestión de capital | Parte 12 |
| 13 | NewBarEvent.mqh | 1.00 | Clase de definición de una nueva barra para un símbolo específico | Parte 8 |
| 14 | Receiver.mqh | 1.04. | Clase básica de transferencia de volúmenes abiertos a posiciones de mercado | Parte 12 |
| 15 | SimpleHistoryReceiverExpert.mq5 | 1.00 | Asesor experto simplificado para reproducir la historia de transacciones | Parte 16 |
| 16 | SimpleVolumesExpert.mq5 | 1.20 | Asesor experto para el trabajo en paralelo de varios grupos de estrategias modelo. Los parámetros se tomarán de la biblioteca de grupos incorporada. | Parte 17 |
| 17 | SimpleVolumesStage3.mq5 | 1.00 | Asesor experto que guarda un grupo normalizado generado de estrategias en una biblioteca de grupos con un nombre especificado. | Parte 17 |
| 18 | SimpleVolumesStrategy.mqh | 1.09 | Clase de estrategia comercial utilizando volúmenes de ticks | Parte 15 |
| 19 | Strategy.mqh | 1.04. | Clase básica de estrategia comercial | Parte 10 |
| 20 | TesterHandler.mqh | 1.03 | Clase para gestionar los eventos de optimización | Parte 17 |
| 21 | VirtualAdvisor.mqh | 1.06 | Clase del asesor experto que trabaja con posiciones (órdenes) virtuales | Parte 15 |
| 22 | VirtualChartOrder.mqh | 1.00 | Clase de posición virtual gráfica | Parte 4 |
| 23 | VirtualFactory.mqh | 1.04. | Clase de fábrica de objetos | Parte 16 |
| 24 | VirtualHistoryAdvisor.mqh | 1.00 | Clase experta para reproducir la historia de transacciones | Parte 16 |
| 25 | VirtualInterface.mqh | 1.00 | Clase de GUI del asesor | Parte 4 |
| 26 | VirtualOrder.mqh | 1.04. | Clase de órdenes y posiciones virtuales | Parte 8 |
| 27 | VirtualReceiver.mqh | 1.03 | Clase de transferencia de volúmenes abiertos a posiciones de mercado (receptor) | Parte 12 |
| 28 | VirtualRiskManager.mqh | 1.02 | Clase de gestión de riesgos (gestor de riesgos) | Parte 15 |
| 29 | VirtualStrategy.mqh | 1.05 | Clase de estrategia comercial con posiciones virtuales | Parte 15 |
| 30 | VirtualStrategyGroup.mqh | 1.00 | Clase de grupo o grupos de estrategias comerciales | Parte 11 |
| 31 | VirtualSymbolReceiver.mqh | 1.00 | Clase de receptor simbólico | Parte 3 |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/15360
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
El trabajo del Asesor Experto consta de dos partes: apertura de posiciones virtuales y sincronización de las posiciones virtuales abiertas con las reales. El conjunto TF se utiliza sólo en la primera parte para determinar la señal de apertura. Y la sincronización debería realizarse idealmente en cada tick o al menos en cada nueva barra del timeframe mínimo M1, porque en cualquier momento la posición virtual puede alcanzar TP o SL.
En el método VirtualAdvisor::Tick(), al principio se comprueba si se ha producido una nueva barra en todos los símbolos y plazos supervisados, incluido M1. Si no se ha producido, el Asesor Experto no realiza más acciones. Sólo hará algo más cuando se produzca una nueva barra en M1. En este caso, puede optimizar en modo OHLC en M1 y obtener casi los mismos resultados cuando el EA trabaja en el gráfico (donde hay todos los ticks). Y la optimización es mucho más rápida de esta manera. La línea de código que mencionas es sólo una red de seguridad en caso de que no necesitemos rastrear una nueva barra en M1 en la estrategia. De esta forma se garantiza que se rastrea al menos en un símbolo.
Si lo desea, puede, por supuesto, desactivar este modo de funcionamiento a través de la variable useOnlyNewBars_ = false. Entonces el Asesor Experto comprobará y sincronizará las posiciones en cada tick disponible.
Entiendo. Pero, por ejemplo, ¿podemos hacer que la sincronización de posiciones funcione en cada tick, y que la apertura de posiciones virtuales (nuevas) se produzca cuando se produzca una nueva barra en el TF especificado en la estrategia (m15,m30,h1)?
La apertura de una nueva barra M1 puede ocurrir dentro de una barra de un marco de tiempo superior. Tenga en cuenta que SignalForOpen() utiliza el marco de tiempo actual, que suele ser H1, M30 o M15. Por lo tanto, ya no habrá coincidencia de los precios de apertura y cierre del timeframe actual. Además, esta comprobación sólo se produce cuando el volumen de ticks de la barra actual en el marco temporal actual ha superado significativamente el volumen de ticks típico de una barra. Esto no puede ocurrir en el primer tick, cuando el volumen del tick es sólo 1.
No te entiendo un poco aquí. Sí, SignalForOpen() utiliza el TF establecido en la configuración de la instancia de estrategia virtual actual, puedo ver eso. Pero por ejemplo, si quiero que el EA trabaje estrictamente en las últimas barras cerradas, entonces aquí tengo que especificar unidades en lugar de ceros.
¿Debo especificar unidades en lugar de ceros? ¿Lo he entendido bien?
Por ejemplo, ¿podemos hacer que la sincronización de posiciones funcione en cada tick, y que la apertura de posiciones virtuales (nuevas) se produzca cuando se produzca una nueva barra en el TF especificado en la estrategia (m15,m30,h1)?
Sí, este será el caso si useOnlyNewBars_ = false. Esta variable no es utilizada por las estrategias, ellas mismas determinan cuando comprobar si hay una señal de apertura y cuando abrir posiciones cuando se recibe una señal antes. Por ejemplo, sólo cuando se produce una nueva barra en H1. En este caso, entonces debe modificar el código para que la señal recibida en medio de la barra sobreviva hasta el comienzo de la siguiente barra. Ahora la señal recibida se utiliza inmediatamente (da lugar a la apertura de posiciones virtuales), por lo que no se guarda en ningún sitio.
Aquí no te entiendo un poco. Sí, SignalForOpen() utiliza el TF establecido en la configuración de la instancia actual de la estrategia virtual, puedo ver eso. Pero por ejemplo, si quiero que el EA trabaje estrictamente en las últimas barras cerradas, entonces aquí debería especificar unidades en lugar de ceros ? ¿Lo he entendido bien?
Si con las palabras"EA trabajó estrictamente en las últimas barras cerradas" quiere decir que cuando el volumen de ticks supera el valor umbral en la barra actual para determinar la dirección de la señal de apertura, tomaremos la barra anterior y miraremos su dirección, entonces ha entendido todo correctamente.
Hola Yuri. Tengo un error al ejecutar el Asesor Experto SimpleVolumesStage3.mq5 y guardar la información en la base de datos:
¿Qué significa y cómo solucionarlo? La tabla fue añadida a la base de datos usando tu consulta del artículo.
Yuri, he estado revisando tu código y veo que el error se produce un poco antes en la función CDatabase::Insert, el log escribe esto:
No se puede ejecutar
¿Con qué puede estar relacionado? La segunda etapa se pasa y el test en sí se pasa (se cargan las operaciones y pases del Asesor Experto desde la base de datos).
Hola Victor.
Volveré pronto para seguir trabajando en este proyecto e intentaré solucionar los errores que he encontrado. Gracias por encontrarlos. He conseguido reproducir algunos de los errores sobre los que escribiste antes. Resultaron estar relacionados con el hecho de que en partes posteriores se hicieron ediciones que iban dirigidas a una cosa, pero que además tenían un impacto en otras cosas que no se tuvieron en cuenta en el siguiente artículo. Esta influencia creó errores. En el próximo artículo volveremos a repasar todos los pasos de la optimización automatizada, eliminando todos los errores detectados.