
开发多币种 EA 交易(第 18 部分):考虑远期的自动化组选择
概述
在第 7 部分中,我考虑了选择一组单独的交易策略实例,目的是改善它们协同工作时的结果。我使用了两种方法进行选择。在第一种方法中,使用在整个优化时间间隔内获得的优化结果进行组选择。我尝试将那些在优化区间内显示最佳结果的单个实例纳入组中。在第二种方法中,从优化时间间隔中分配一小块,在该时间间隔上不进行单个实例的优化。分配的时间间隔随后用于组选择:我尝试将那些在优化区间内显示良好(但不是最好)结果,同时在所选时间区间内显示大致相同结果的单个实例纳入组中。
结果如下:
- 我没有看到使用第一种方法比第二种方法进行选择有任何明显的优势。这可能是由于我们比较这两种方法的结果的历史时间较短。三个月不足以评估一个可能有长时间平稳运动的策略。
- 第二种方法表明,在选定的时间间隔内,如果我们根据文章中描述的算法将选择应用于一个组,以找到具有相似结果的交易策略的单个实例,结果会更好。如果我们只是根据优化区间内的最佳结果来选择它们(如第一种方法,但仅在较短的区间内),那么所选组的结果明显较差。
- 可以将这两种方法结合起来,即构建以不同方式选择的两个组,然后将两个结果组组合成一个。
在第 13 部分中,我们实现了第二阶段优化的自动化。在其框架内,将第一阶段获得的交易策略的单个副本选入一组。我们在策略测试器中使用了标准优化器的遗传算法进行简单搜索。尚未对单个实例进行预聚类(第 6 部分中探讨过了)。因此,我们以第一种方式自动选择组。当时,不可能使用第二种方法来实施组选择,但现在是时候回到这个问题上了。在本文中,我们将尝试实现自动将交易策略的单个实例分组的能力,同时考虑到它们在远期的行为。
规划路径
一如既往,让我们先看看我们已经拥有了什么,还缺少什么来解决问题。我们可以设置在任何所需时间间隔内优化交易策略的任务。“设置任务”这句话应该按字面意思理解:为了做到这一点,我们在数据库的 tasks 表中创建必要的条目。因此,我们可以首先对一个时间间隔(例如,从 2018 年到 2022 年)进行优化,然后再对另一个时间间隔(例如,2023 年)进行优化。
但是,使用这种方法,我们无法以所需的方式使用所获得的结果。在两个时间间隔中的每一个,优化都将独立执行,因此没有什么可比较的:就输入参数的值而言,第二次优化的过程不会重复第一次优化的步骤。我们使用的遗传优化也是如此。很明显,对于完全优化来说,这是不正确的,但我们从未使用过它,而且由于优化参数的大量组合,很可能将来也不会使用它。
因此,有必要使用具有指定远期的优化启动。在这种情况下,测试器将在远期使用与主期间段相同的输入参数组合。但我们还没有尝试过在远期内运行自动优化,我们不知道这些结果将如何进入我们的数据库。那么我们能否区分主期间段内的运行和远期内的运行?我们应该检查一下。
一旦我们确信数据库包含了主期间段和远期阶段的所有必要信息,我们就可以进入下一阶段。在第 7 部分中,收到这些结果后,我使用 Excel 手动执行了分析和选择。然而,在自动化的背景下,它的使用似乎效率低下。在获取最终 EA 时,我们尽量避免对数据进行任何手动操作。幸运的是,我们在 Excel 中执行的所有操作(重新计算一些结果、计算不同测试期间的通过率、找到每个策略组的最终得分并按其排序)都可以在 MQL5 程序中通过对我们的数据库进行 SQL 查询或运行 Python 脚本来执行。
根据最终评估进行排序后,我们将只将最优秀的组纳入最终 EA。我们将针对所选交易品种和时间范围的所有组合执行类似的操作。在对整个组进行标准化之后,包括所有交易品种时间范围对的最佳组,最终的 EA 就准备好了。
让我们开始实现,但首先让我们修复发现的错误。
修复存储错误
当我开发 EA 来自动化第一阶段(优化交易策略的单个实例)时,我只使用了一个数据库。因此,我们应该从哪个数据库接收数据或将数据保存到哪个数据库是毫无疑问的。在优化的第二阶段,添加了一个新的辅助数据库,其中包含从主数据库中提取的最小必要内容。正是这个简化版本的数据库被发送给测试代理,作为优化第二阶段的一部分。
但由于我在实现处理数据库的静态类时已经选择了这种方法,我不得不使用一种有点不方便的解决方案,允许在必要时更改数据库名称。更改名称后,对数据库连接方法的所有后续调用都使用了新名称。这就是在第二和第三阶段添加通过结果时发生错误的地方。 原因是在所有需要切换回主数据库的地方都缺乏切换。
为了解决这个问题,我为每个阶段的 EA 和项目自动优化 EA 添加了额外的输入参数。此输入参数指定主数据库的名称。除了修复错误外,这也很有用,因为我们可以更好地分离不同文章中使用的数据库。例如,在这一部分中,使用了一个新的主数据库,因为我们决定减少优化任务的组成,但不想清除现有的数据库:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ sinput string fileName_ = "database683.sqlite"; // - File with the main database
在第二阶段 EA SimpleVolumesStage2.mq5 的OnInit() 的函数中,在 LoadParams() 函数调用内部,建立了与辅助数据库的连接,因为要加入某个组的交易策略单个实例的输入数据应从中获取。通过完成后,调用 OnTester() 函数。在该函数中,必须在主数据库中保存组通过的结果。但由于没有切换回主数据库,因此尝试将传递的完整结果(共 48 列)插入到辅助数据库(共 2 列)中的表中。
因此,我们在第二阶段 EA SimpleVolumesStage2.mq5 的 OnInit() 函数中添加了主数据库缺失的开关:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ... // Load strategy parameter sets string strategiesParams = LoadParams(indexes); // Connect to the main database DB::Connect(fileName_); DB::Close(); ... // Create an EA handling virtual positions expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
在第一阶段和第三阶段优化 EA 中,不使用辅助数据库,我们将从 EA 的新输入参数中获取的数据库名称添加到数据库连接方法的第一次调用中:
DB::Connect(fileName_)
我发现的另一种错误发生在完成后,我想单独运行其中一个运行时。通过运行并执行正常,但其结果未输入数据库。原因是,在这种启动的情况下,任务 ID 保持等于 0,而在数据库中, passes 表仅接受具有 tasks 表中现有任务的 ID 的字符串。
这可以通过使任务 ID 从 EA 输入中获取值(在优化期间从中获取)或将 ID 为 0 的虚拟任务添加到数据库中来解决。我最终选择了第二个选项,这样我手动启动的单次通过就不会被视为任何特定优化任务中执行的通过。对于添加的虚拟任务,需要指定任意现有流程的 ID,以免违反外键约束和完成状态,从而使得该任务不会在自动优化期间启动。
完成这些修正后,我们将回到手头的主要任务。
准备代码和数据库
让我们复制现有的数据库并清除其中的 passes、tasks 和 jobs 数据。然后,我们通过添加远期的开始日期来修改第一阶段的数据。我们可以从 stages 表中删除第二阶段。在 jobs 表中为第一阶段创建一个条目,指定交易品种和周期(EURGBP H1),以及策略测试器参数。其中仅包含单个参数的优化,因此通过数较少。这将使我们能够更快地获得结果。对于 jobs 表中创建的作业,添加一个具有复杂优化标准的任务。
通过在输入参数中指定创建的数据库来启动项目自动优化 EA。首次启动后,事实证明,自动优化 EA 需要改进,因为它没有从数据库中收到有关使用远期必要性的信息。添加后,从数据库中获取下一个优化任务的函数代码如下(添加的字符串以颜色突出显示):
//+------------------------------------------------------------------+ //| Get the next optimization task from the queue | //+------------------------------------------------------------------+ ulong GetNextTask(string &setting) { // Result ulong res = 0; // Request to get the next optimization task from the queue string query = "SELECT s.expert," " s.optimization," " s.from_date," " s.to_date," " s.forward_mode," " s.forward_date," " j.symbol," " j.period," " j.tester_inputs," " t.id_task," " t.optimization_criterion" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status IN ('Queued', 'Processing')" " ORDER BY s.id_stage, j.id_job, t.status LIMIT 1;"; // Open the database if(DB::Connect()) { // Execute the request int request = DatabasePrepare(DB::Id(), query); // If there is no error if(request != INVALID_HANDLE) { // Data structure for reading a single string of a query result struct Row { string expert; int optimization; string from_date; string to_date; int forward_mode; string forward_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } row; // Read data from the first result string if(DatabaseReadBind(request, row)) { setting = StringFormat( "[Tester]\r\n" "Expert=%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=%d\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=%d\r\n" "ForwardDate=%s\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d\r\n" "fileName_=%s\r\n" "%s\r\n", GetProgramPath(row.expert), row.symbol, row.period, row.optimization, row.from_date, row.to_date, row.forward_mode, row.forward_date, row.optimization_criterion, row.id_task, fileName_, row.tester_inputs ); res = row.id_task; } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Report an error if necessary PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Close the database DB::Close(); } return res; }
我们还添加了一个函数,用于从当前文件夹(相对于终端 EA 的根文件夹)获取优化 EA 的文件路径:
//+------------------------------------------------------------------+ //| Getting the path to the file of the optimized EA from the current| //| folders relative to the root folder of terminal EAs | //+------------------------------------------------------------------+ string GetProgramPath(string name) { string path = MQLInfoString(MQL_PROGRAM_PATH); string programName = MQLInfoString(MQL_PROGRAM_NAME) + ".ex5"; string terminalPath = TerminalInfoString(TERMINAL_DATA_PATH) + "\\MQL5\\Experts\\"; path = StringSubstr(path, StringLen(terminalPath), StringLen(path) - (StringLen(terminalPath) + StringLen(programName))); return path + name; }
这允许数据库在阶段表中仅指定优化 EA 的文件名,而无需列出相对于根 EA 文件夹 \MQL5\Experts\ 嵌套的文件夹的名称。
自动项目优化 EA 的后续运行表明,前向通过的结果已与常规通过的结果一起成功添加到 passes 表中。然而,在完成该阶段之后,很难区分哪些通过属于哪个期间(主期间或远期)。当然,我们可以利用远期通过总是在常规期间通过之后这一事实,但如果 passes 表中出现了几个具有远期的优化问题的结果,则此方法将停止工作。因此,让我们将 is_forward 列添加到 passes 表中,以区分常规通过和远期通过。我们还将添加 is_optimzation 列,以便轻松区分常规通过和作为优化一部分执行的通过。
在此过程中,我们发现了一个不准确之处:在形成用于插入传递结果数据的 SQL 查询字符串时,我们使用 %d 说明符将通过号替换为有符号整数。但是,通过号是一个无符号长整数,因此为了正确地将其值替换到字符串中,我们应该使用 %I64u 说明符。
我们将确定远期标志的相应函数的值添加到生成插入通过数据的 SQL 查询的代码中:
string CTesterHandler::GetInsertQuery(string values, string inputs, ulong pass) { return StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %I64u, %d, %s,\n'%s',\n'%s') RETURNING rowid;", s_idTask, pass, (int) MQLInfoInteger(MQL_FORWARD), values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); }
然而,事实证明这并不会像预期的那样有效。重点是,该函数是在数据帧收集模式下从主终端启动的 EA 调用的。因此,MQLInfoInteger(MQL_FORWARD) 调用结果总是返回 false 。
因此,远期指示应在测试代理上运行的代码中获得,而不是在图表上的主终端中获得,即在测试通过完成事件处理程序中获得。附近还添加了优化标志。
//+------------------------------------------------------------------+ //| Handling completion of tester pass for agent | //+------------------------------------------------------------------+ void CTesterHandler::Tester(double custom, // Custom criteria string params // Description of EA parameters in the current pass ) { ... // Generate a string with pass data data = StringFormat("%d, %d, %s,'%s'", MQLInfoInteger(MQL_OPTIMIZATION), MQLInfoInteger(MQL_FORWARD), data, params); ... }
完成这些编辑并重新启动自动优化 EA 后,我们终于在通过表中看到了所需的图片:
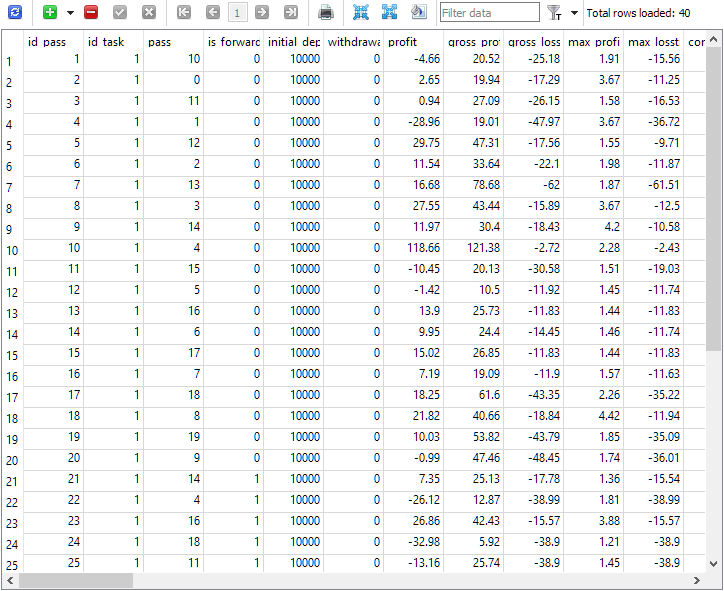
图 1.完成远期优化任务后的 passes 表
可以看出,在id_task = 1 的优化任务上下文中仅执行了 40 次通过。其中 20 次是常规的(前 20 个字符串的is_forward = 0),而其余 20 次是在远期的通过( is_forward = 1)。通过列中的测试程序通过 pass 取值范围为 1 至 20,每个编号恰好出现 2 次(一次为主期间,第二次为远期)。
准备全面优化运行
在验证使用远期进行的通过结果现已正确输入数据库后,我们将进行更接近真实情况的自动优化测试。为此,我们将向干净的数据库中添加两个阶段。第一个将优化交易策略的单个实例,但仅限于 2018 年至 2023 年期间的一个交易品种和周期(EURGBP H1)。此阶段不会使用远期。第二阶段将对第一阶段得到的一组好的单个实例进行优化。现在远期已经被使用:整个 2023 年都已分配给它。

图 2.包含两个阶段的阶段表
对于 jobs 表中的每个阶段,创建要在此阶段内执行的作业。在此表中,除了交易品种和周期之外,还标明了优化 EA 的范围和步长变化的输入。
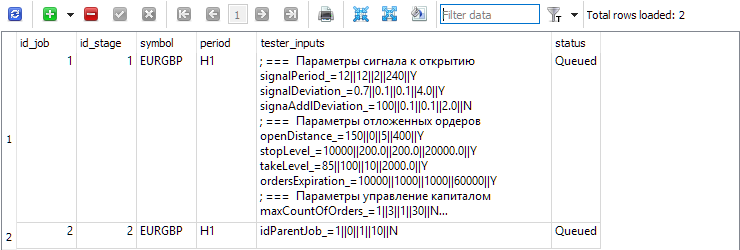
图 3. jobs 表包含第一和第二阶段的两个作业
对于第一个( id_job = 1),创建几个不同的优化问题 优化标准值( optimization_criterion = 0 ...7)。让我们依次检查所有标准,并使用两次复杂标准:在第一个作业的开始和结束时( optimization_criterion =7) 。对于第二个作业( id_job = 2)中执行的任务,我们将使用自定义优化标准( optimization_criterion = 6)
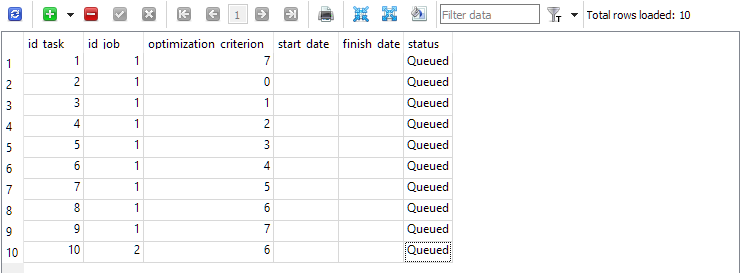
图4.包含第一个作业和第二个作业任务的 tasks 表
让我们在任意终端图表上启动自动优化 EA,并等待所有分配的任务完成。通过现有的代理,整个过程总共需要大约 4 个小时。
结果初步分析
在已完成的自动优化中,我们只有一个使用远期的优化任务。它的优化标准是我们自定义的标准,它计算给定通过的标准化平均年利润。让我们看一下主周期内该标准值的点云。
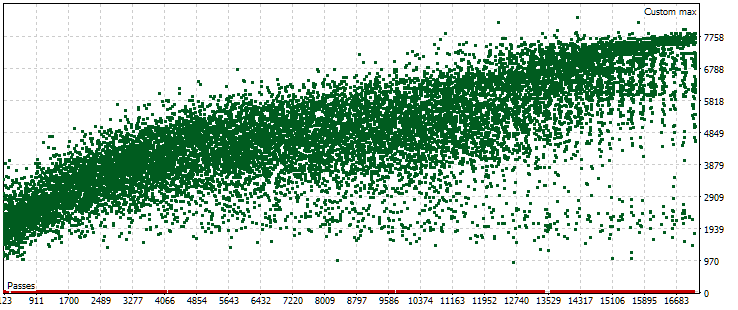
图 5.主期间内不同通过标准化年平均利润值的点云
图表显示,我们的标准值在 1000 美元到 8000 美元范围内。出现与 0 对应的红点是因为输入参数中的某些单个实例索引组合导致了重复的值。此类输入参数被视为无效策略组,并且不会产生任何结果。后期通过的标准化年平均利润总体呈增加趋势,这一点显而易见。平均而言,所取得的最佳结果大约是第一次通过结果的两倍,其中参数几乎是随机选择的。
现在让我们看一下远期通过结果的点云。由于在主要阶段淘汰的参数组合被认定为不正确,因此数量会减少(约为 13,000 个,而不是 17,000 个)。
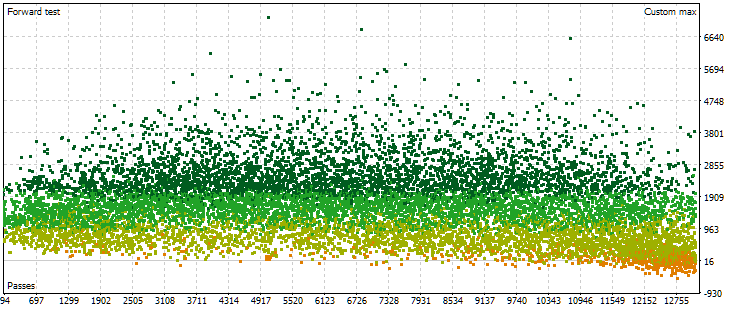
图 6.远期不同阶段的标准化年平均利润值的点云
这里点位置的图片已经不同了。随着通过数的增加,获得的结果并没有显著增加。相反,我们看到随着通过次数的增加,结果首先达到比开始时更高的值,然后趋势转向相反的方向。随着通过次数的进一步增加,其平均结果开始下降,并且当我们接近数字的右边界时,下降的速度会加快。
然而,事实证明,情况并非总是如此。在优化过程中迭代参数范围的其他设置后,主期间和远期的通过点云可能看起来像这样:
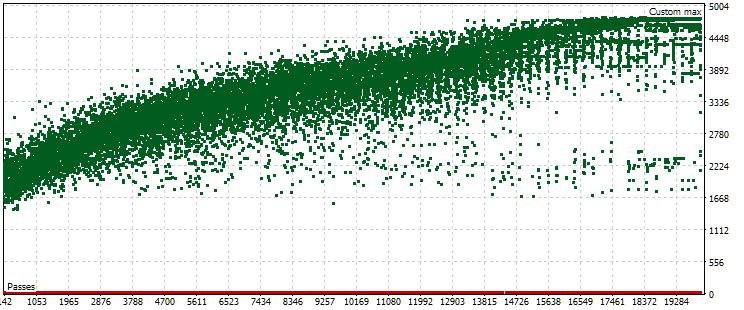
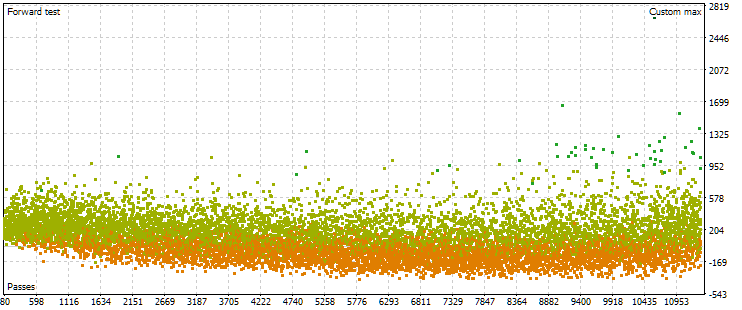
图 7.在其他优化设置的情况下,主期间和远期标准化平均年利润值的点云
我们可以看到,在主期间内,情况大致相同,只有标准范围现在略有不同:从 1500 美元到 5000 美元。然而,在远期阶段,云的性质则完全不同。最大值不是在优化过程中大约中间发生的通过中实现的,而是在接近结束时实现的。此外,平均而言,远期内的标准值大约小 10 倍,而不是像第一个优化过程那样小 3 倍。
直觉告诉我们,为了增加不同时期所得结果的稳定性,我们需要选择一个主期间和远期结果大致相同的组。然而,所获得的结果让我强烈怀疑我们能否通过这种方式获得任何有用的东西。尤其是在远期标准的最大值与主期间标准的平庸值相比明显较小的情况下。无论如何,我们尝试一下吧。让我们寻找主期间和远期中有条件的“关闭”通过,并查看它们在主期间、远期和 2024 年的结果。
选择通过
让我们回忆一下,我们在第七部分中是如何根据远期的结果选择最佳组的。以下是经过细微调整的算法摘要:
- 让我们调整远期通过的标准化年平均利润值,并计算两个值中的最大回撤:主期间和远期期间。我们得到了 OOS_ForwardResultCorrected 的值。
- 在 2018 到 2022 年(主期间)和 2023 年(远期)的优化结果合并表中,计算所有参数在主期间和远期的数值之比。
例如,对于交易数量: TradesRatio = OOS_Trades / IS_Trades,而对于标准化的年平均利润: ResultRatio = OOS_ForwardResultCorrected /IS_BackResult。
这些比率越接近1,表明这两个期间内这些指标的值越相同。 - 让我们计算一下所有这些关系的偏离统一值的总和。这一数值将用来衡量各组在主要时间段和前向时间段的结果之间的差异:
SumDiff = |1 -ResultRatio| + ... + |1 -TradesRatio|。 -
此外,还要考虑到在主要时间段和前向时间段,每个通过的回撤情况可能不同。选择两个时期的最大回撤率,并用它来计算为达到 10%的标准化回撤率而建立的仓位规模的比例系数:
Scale = 10 / MAX(OOS_EquityDD, IS_EquityDD) 。
-
现在我们要选择SumDiff 不如 Scale 普遍的集合。为此,请计算最后一个参数:
Res = Scale / SumDiff.
-
让我们按照上一步计算出的 Res 值按降序对所有组进行排序。在这种情况下,主期间和远期的结果比较相似,而且两个时期的回撤幅度都较小的组位居榜首。
接下来,我们建议多次重复选择组,首先删除那些包含已包含在所选组中的交易策略单副本数量的组。但这一步将与单个实例的初步聚类相关,以便不同的索引对应于结果不同的实例。由于我们在自动优化过程中还没有达到聚类,我们将跳过这一步。
相反,我们可以为每个交易品种添加按不同时间范围的第二级分组,并为不同交易品种添加第三级分组。
我们将稍微修改给定的算法。让我们从这样一个事实开始:本质上,我们想要了解在维度等于比较结果(特征)数量的空间中,通过的两组结果相差多远。为此,我们使用带有缩放因子的一阶范数来找到与具有单位坐标的固定点的比较结果的比率的坐标点的距离。然而,在这些关系中,既可以有接近 1 的关系,也可以有非常遥远的关系。后者可能会不合理地降低总体距离估计。因此,让我们尝试用计算两个结果向量之间的常用欧几里德距离来代替之前提出的选项,为此我们将首先应用最小最大缩放。
我们最终需要编写一个相当复杂的 SQL 查询(尽管可能有更复杂的查询)。让我们仔细看看创建所需查询的过程。我们将从简单的查询开始,逐渐使其变得更加复杂。我们将把一些结果放入临时表中,这些表将用于进一步的查询。在每个请求之后,我们将显示其结果。
因此,我们需要获取的源数据主要在 passes 表中。让我们确保它们确实存在,并立即仅选择在所需优化任务框架内执行的那些通过。在我们的特定情况下,对应于 EURGBP H1 第二阶段优化的任务标识符 id_task 的值为 10。因此,我们将在请求文本中使用它:
-- Request 1
SELECT *
FROM passes p0
WHERE p0.id_task = 10;
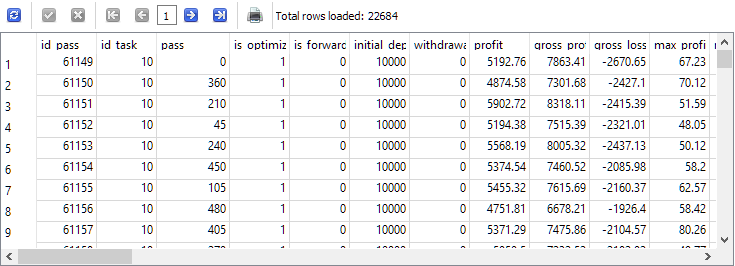
我们可以看到,对于 id_task =10 的这个任务, passes 表中的条目数量超过了 22,000 条。
下一步是将此数据集的两行结果组合成一个字符串,对应于相同的测试次数,但不同的期间段:主期间和远期。我们将暂时限制结果中显示的列数。我们将只留下那些可用于检查字符串选择有效性的字符串。让我们根据以下规则命名结果列:在主期间(样本内)的列名中添加前缀“I_”,在远期(样本外)的列名中添加前缀“O_”:
-- Request 2 SELECT p0.id_pass AS I_id_pass, p0.is_forward AS I_is_forward, p0.custom_ontester AS I_custom_ontester, p1.id_pass AS O_id_pass, p1.is_forward AS O_is_forward, p1.custom_ontester AS O_custom_ontester FROM passes p0 JOIN passes p1 ON p0.pass = p1.pass AND p0.is_forward = 0 AND p1.is_forward = 1 WHERE p0.id_task = 10 AND p1.id_task = 10
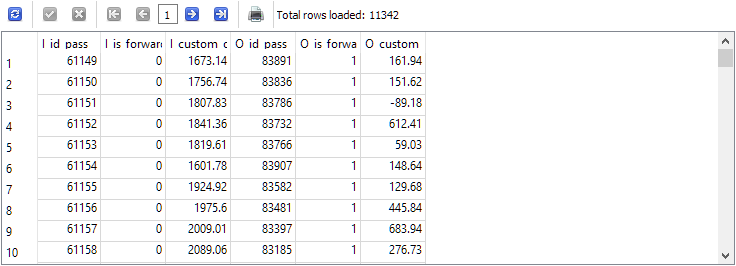
结果是行数正好减少了一半,也就是说,对于 passes 表中主期间的每个通过,远期正好有一个通过,反之亦然。
现在让我们回到第一个执行规范化的请求。如果我们将规范化留到稍后,当我们已经在主要和远期中为同一参数设置了单独的列时,我们将更难以同时计算两者的最小值和最大值。我们首先选择少量参数,通过这些参数我们将评估主期间和远期结果之间的“距离”。例如,我们首先练习计算三个参数的距离: custom_ontester 、 equity_dd_relative 、 profit_factor 。
我们需要将具有这些参数值的列转换为值在 0 到 1 之间的列。让我们使用窗口函数来获取查询中列的最小值和最大值。对于具有缩放值的列名,在原始列名中添加前缀 “s_”。 根据此查询返回的结果,我们将使用以下命令创建并填充新表:
CREATE TABLE ... AS SELECT ... ;
让我们看看创建和填充的新表的内容:
-- Request 3
DROP TABLE IF EXISTS t0;
CREATE TABLE t0 AS
SELECT id_pass,
pass,
is_forward,
custom_ontester,
(custom_ontester - MIN(custom_ontester) OVER () ) / (MAX(custom_ontester) OVER () - MIN(custom_ontester) OVER () ) AS s_custom_ontester,
equity_dd_relative,
(equity_dd_relative - MIN(equity_dd_relative) OVER () ) / (MAX(equity_dd_relative) OVER () - MIN(equity_dd_relative) OVER () ) AS s_equity_dd_relative,
profit_factor,
(profit_factor - MIN(profit_factor) OVER () ) / (MAX(profit_factor) OVER () - MIN(profit_factor) OVER () ) AS s_profit_factor
FROM passes
WHERE id_task=10;
SELECT * FROM t0;
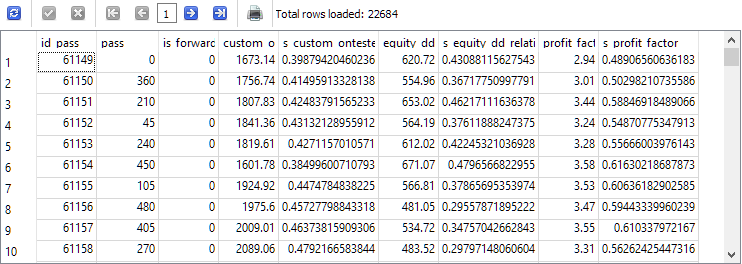
如您所见,在每个估计参数旁边,都会出现一个新列,其中包含该参数的值,范围缩小到 0 到 1。
现在让我们稍微修改一下第二个查询的文本,以便它从新表 t0 中获取数据,而不是 passes 并将结果放入新表 t1 中。为了方便起见,我们将取已经缩放的值并四舍五入。我们只保留主期间和远期期间标准化利润值为正的字符串:
-- Request 4 DROP TABLE IF EXISTS t1; CREATE TABLE t1 AS SELECT p0.id_pass AS I_id_pass, p0.is_forward AS I_is_forward, ROUND(p0.s_custom_ontester, 4) AS I_custom_ontester, ROUND(p0.s_equity_dd_relative, 4) AS I_equity_dd_relative, ROUND(p0.s_profit_factor, 4) AS I_profit_factor, p1.id_pass AS O_id_pass, p1.is_forward AS O_is_forward, ROUND(p1.s_custom_ontester, 4) AS O_custom_ontester, ROUND(p1.s_equity_dd_relative, 4) AS O_equity_dd_relative, ROUND(p1.s_profit_factor, 4) AS O_profit_factor FROM t0 p0 JOIN t0 p1 ON p0.pass = p1.pass AND p0.is_forward = 0 AND p1.is_forward = 1 AND p0.custom_ontester > 0 AND p1.custom_ontester > 0; SELECT * FROM t1;
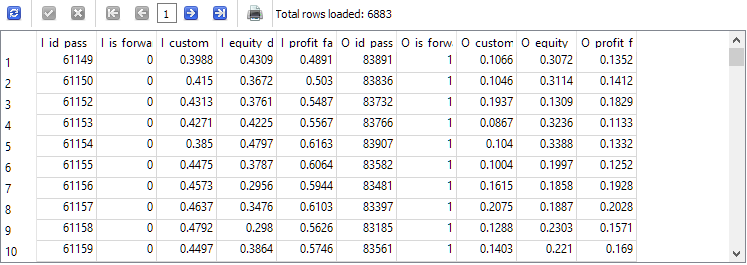
与第二个查询相比,行数减少了约三分之一,但现在我们只剩下主期间和远期都实现盈利的那些运行。
我们终于到达了查询开发过程的最后一步。剩下的就是计算每个 t1 表行中主期间和远期周期的参数组合之间的距离,并按照距离增加的顺序对它们进行排序:
-- Request 5 SELECT ROUND(POW((I_custom_ontester - O_custom_ontester), 2) + POW( (I_equity_dd_relative - O_equity_dd_relative), 2) + POW( (I_profit_factor - O_profit_factor), 2), 4) AS dist, * FROM t1 ORDER BY dist ASC;
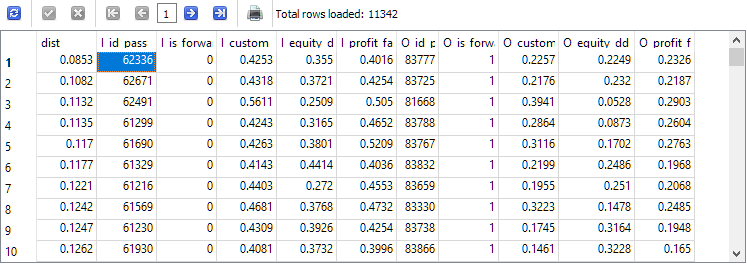
所获结果顶部字符串中的 I_id_pass 通过 ID 将对应于主期间和远期结果值之间距离最小的通行证。
我们将其与主期间内实现正常利润的最佳通过的 ID 进行比较。它们不匹配,所以我们将按照上一篇文章中描述的那样为最终的 EA 制作一个参数库。我们必须对上一篇文章中添加的文件进行一些小的编辑,以便能够在创建和导出参数集库时指定特定的数据库。
结果
因此,我们在库中有两个设置选项。第一个称为“"Best for dist(IS, OS) (2018-2023)” — 参数值之间距离最小的最佳优化过程。第二个选项称为 “Best on IS (2018-2022)” — 2018 年至 2022 年主要期间内标准化利润的最佳优化过程。
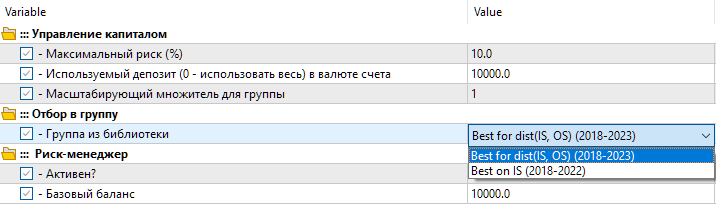
图 8.在最终 EA 中从库中选择一组设置
我们来看看这两个组在2018年至2023年期间全面参与优化的结果。
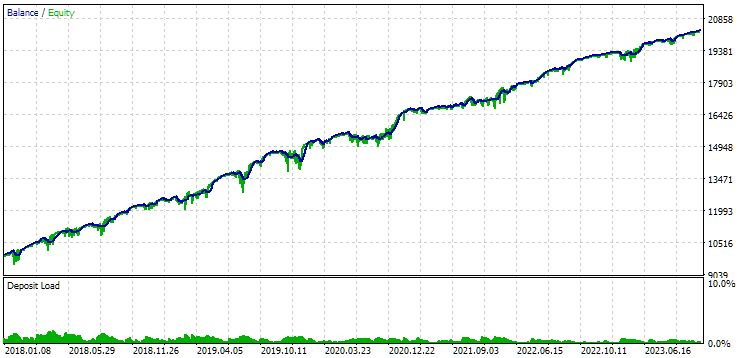
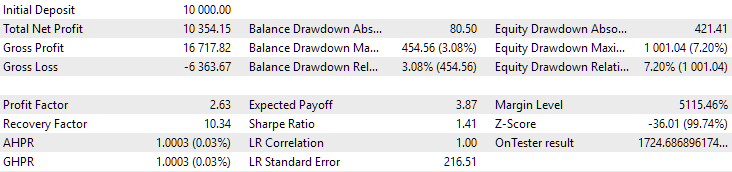
图 9.2018 年至 2023 年期间第一组(距离最佳)的结果
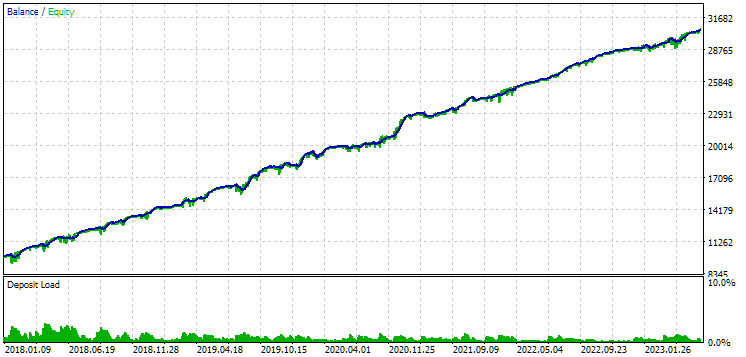
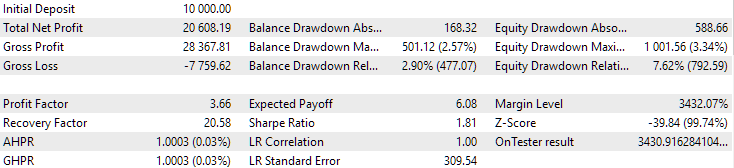
图 10.第二组(利润最好)2018年至2023年期间的结果
我们看到,这两组在这段时间内都得到了很好的规范(两种情况下的最大亏损都是 1000 美元)。然而,第一组的平均年利润大约比第二组少两倍(1724 美元对 3430 美元)。第一组的优势在这里还不明显。
现在我们看一下这两组未参与优化的 2024 年(10 月之前)的结果。
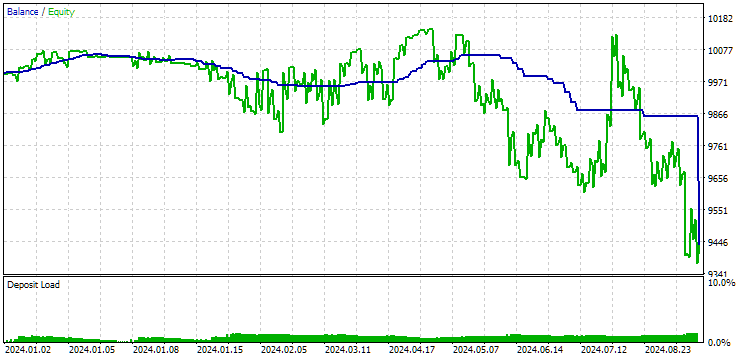
图 11.2024 年第一组(距离最好)的成绩
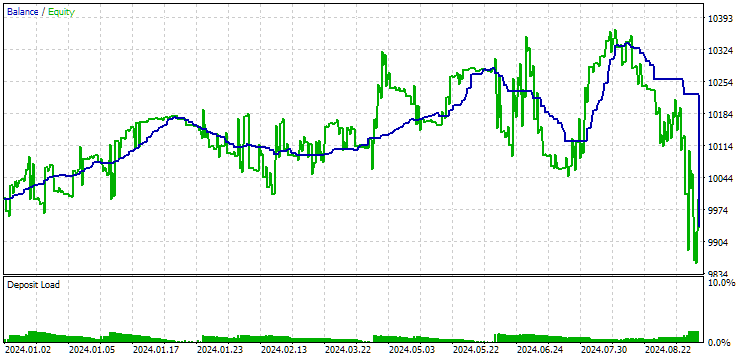
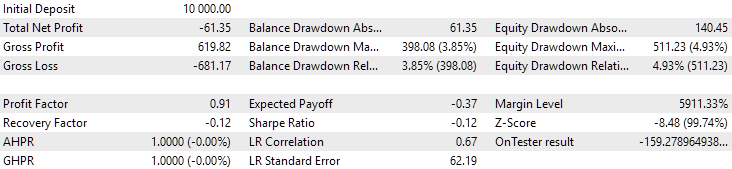
图 12。第二组(利润最佳)2024 年业绩
此时两个结果都是负面的,但第二个结果看起来仍然比第一个好。值得注意的是,此期间的最大回撤始终低于 1000 美元。
由于 2024 年对于这个交易品种来说并不是特别成功的一年,让我们看看优化期之前而不是之后的结果。既然有这样的机会,我们就把时间拉长一点吧(2015年到2017年,三年)。
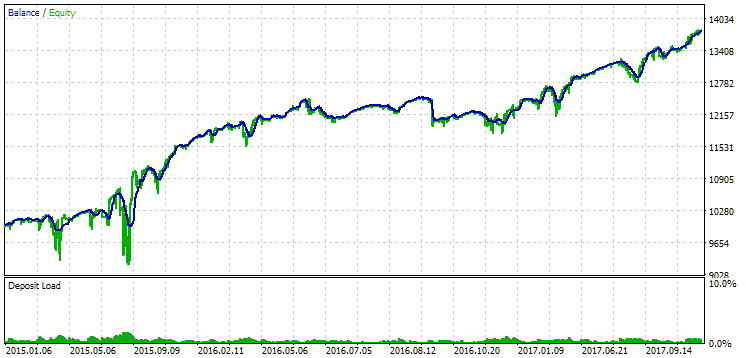
图 13.2015 年至 2017 年期间第一组(距离最佳)的结果
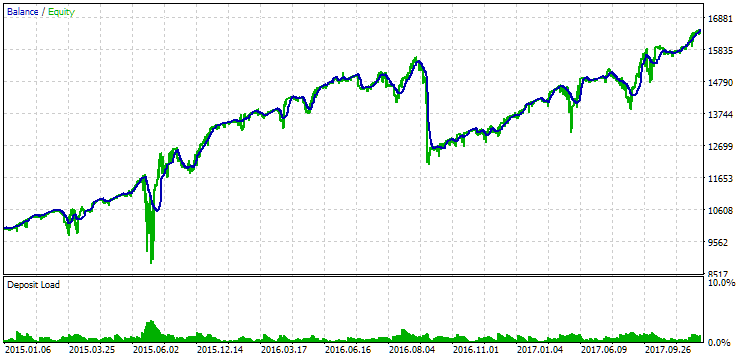
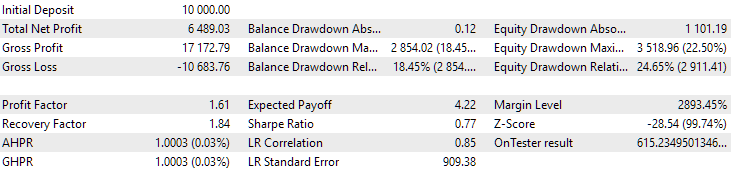
图 14.第二组(利润最好)2015年至2017年期间的结果
在此期间,回撤已经超过了允许的计算值。在第一个版本中,它大约大 1.5 倍,而在第二个版本中,它大约大 3.5 倍。从这一点来看,第一种选择稍微好一些,因为超额回撤明显小于第二种选择,而且总体来说不是很大。此外,在第一个版本中,图表中间没有出现明显的下降,就像在第二个版本中一样。此外,在第一个版本中,中间的图形没有像第二个版本中那样明显的下降。不过,就标准化的年平均利润而言,这两个选项之间的差异并不大(857 美元对 615 美元)。很遗憾,我们无法在未知的时间段内提前计算此值。
因此,在此期间,人们仍将倾向于第一种选择。让我们总结一下。
结论
我们已经利用远期实现了第二阶段优化的自动化。再次,没有发现明显的优势。事实证明,这项任务比我们最初预期的要广泛得多,而且需要更多的时间。在这个过程中,出现了许多新的问题,这些问题仍在等待解决。
我们能够看到,如果远期落在 EA 工作不成功的时期,那么我们似乎无法使用它来选择良好的参数组合。
如果交易持续时间很长,则在主期间和远期边界处中断的通过结果可能与连续通过的结果有很大不同。这也对以这种形式使用远期的合理性提出了质疑——不是一般意义上的远期,而是具体地作为一种自动选择更有可能在未来显示可比结果的参数的方式。
这里我们使用了一种简单的方法来计算传球结果之间的距离。使该方法更加复杂可能会改善结果。我们还尚未开始编写自动选择最佳通行证的实现,以便将其纳入针对不同交易品种和时间范围的集合组中。几乎所有事情都已准备就绪,可以实现了。从 EA 调用我们开发的 SQL 查询就足够了。但是,由于肯定仍会对它们进行更改,我们将在未来推迟这种自动化。
感谢您的关注!再见!
重要警告
本文和本系列之前的所有文章中的所有结果仅基于历史测试数据,并不保证未来会有任何利润。该项目中的工作具有研究性质。所有已发表的结果都可以由任何人使用,风险自负。
存档内容
| # | 名称 | 版本 | 描述 | 最近修改 |
|---|---|---|---|---|
| MQL5/Experts/Article.15683 | ||||
| 1 | Advisor.mqh | 1.04 | EA 基类 | 第 10 部分 |
| 2 | Database.mqh | 1.05 | 处理数据库的类 | 第 18 部分 |
| 3 | database.sqlite.schema.sql | — | 数据库结构 | 第 18 部分 |
| 4 | ExpertHistory.mqh | 1.00 | 用于将交易历史记录导出到文件的类 | 第 16 部分 |
| 5 | ExportedGroupsLibrary.mqh | — | 生成的文件列出了策略组名称及其初始化字符串数组 | 第 17 部分 |
| 6 | Factorable.mqh | 1.01 | 从字符串创建的对象的基类 | 第 10 部分 |
| 7 | GroupsLibrary.mqh | 1.01 | 用于处理选定策略组库的类 | 第 18 部分 |
| 8 | HistoryReceiverExpert.mq5 | 1.00 | 用于与风险管理器回放交易历史的 EA | 第 16 部分 |
| 9 | HistoryStrategy.mqh | 1.00 | 用于回放交易历史的交易策略类 | 第 16 部分 |
| 10 | Interface.mqh | 1.00 | 可视化各种对象的基类 | 第 4 部分 |
| 11 | LibraryExport.mq5 | 1.01 | EA 将库中选定通过的初始化字符串保存到 ExportedGroupsLibrary.mqh 文件 | 第 18 部分 |
| 12 | Macros.mqh | 1.02 | 用于数组操作的有用的宏 | 第 16 部分 |
| 13 | Money.mqh | 1.01 | 资金管理基类 | 第 12 部分 |
| 14 | NewBarEvent.mqh | 1.00 | 用于定义特定交易品种的新柱形的类 | 第 8 部分 |
| 15 | Optimization.mq5 | 1.02 | EA 管理优化任务的启动 | 第 18 部分 |
| 16 | Receiver.mqh | 1.04 | 将未平仓交易量转换为市场仓位的基类 | 第 12 部分 |
| 17 | SimpleHistoryReceiverExpert.mq5 | 1.00 | 简化的EA,用于回放交易历史 | 第 16 部分 |
| 18 | SimpleVolumesExpert.mq5 | 1.20 | 用于多组模型策略并行运行的 EA。参数将从内置组库中获取。 | 第 17 部分 |
| 19 | SimpleVolumesStage1.mq5 | 1.17 | 交易策略单实例优化EA(第一阶段) | 第 18 部分 |
| 20 | SimpleVolumesStage2.mq5 | 1.01 | 交易策略实例组优化EA(第二阶段) | 第 18 部分 |
| 21 | SimpleVolumesStage3.mq5 | 1.01 | 将生成的标准化策略组保存到具有给定名称的组库中的 EA。 | 第 18 部分 |
| 22 | SimpleVolumesStrategy.mqh | 1.09 | 使用分时交易量的交易策略类 | 第 15 部分 |
| 23 | Strategy.mqh | 1.04 | 交易策略基类 | 第 10 部分 |
| 24 | TesterHandler.mqh | 1.04 | 优化事件处理类 | 第 18 部分 |
| 25 | VirtualAdvisor.mqh | 1.07 | 处理虚拟仓位(订单)的 EA 类 | 第 18 部分 |
| 26 | VirtualChartOrder.mqh | 1.01 | 图形虚拟仓位类 | 第 18 部分 |
| 27 | VirtualFactory.mqh | 1.04 | 对象工厂类 | 第 16 部分 |
| 28 | VirtualHistoryAdvisor.mqh | 1.00 | 交易历史回放 EA 类 | 第 16 部分 |
| 29 | VirtualInterface.mqh | 1.00 | EA GUI 类 | 第 4 部分 |
| 30 | VirtualOrder.mqh | 1.04 | 虚拟订单和仓位类 | 第 8 部分 |
| 31 | VirtualReceiver.mqh | 1.03 | 将未平仓交易量转换为市场仓位的类(接收方) | 第 12 部分 |
| 32 | VirtualRiskManager.mqh | 1.02 | 风险管理类(风险管理器) | 第 15 部分 |
| 33 | VirtualStrategy.mqh | 1.05 | 具有虚拟仓位的交易策略类 | 第 15 部分 |
| 34 | VirtualStrategyGroup.mqh | 1.00 | 交易策略组类 | 第 11 部分 |
| 35 | VirtualSymbolReceiver.mqh | 1.00 | 交易品种接收器类 | 第 3 部分 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/15683
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
新文章 开发多币种 EA 交易(第 18 部分):考虑远期的自动化组选择已发布:
作者:Yuriy Bykov