
Redes neuronales en el trading: Modelos con transformada de wavelet y atención multitarea (Final)

Introducción
En el artículo anterior, nos familiarizamos con los aspectos teóricos del framework Multitask-Stockformer y comenzamos a implementar los enfoques propuestos utilizando las herramientas MQL5. El Multitask-Stockformer combina dos potentes herramientas: la transformada de wavelet discreta, que posibilita un análisis profundo de la series temporales, y los modelos multitarea Self-Attention, que pueden identificar dependencias complejas en los datos financieros. Esta simbiosis permite crear una herramienta universal de análisis y previsión de series temporales.
El framework se basa en 3 bloques. El módulo de descomposición de series temporales divide los datos analizados en componentes de alta y baja frecuencia. Los componentes de baja frecuencia muestran tendencias globales y ofrecen un análisis de los patrones a largo plazo. Al mismo tiempo, el componente de alta frecuencia capta las fluctuaciones a corto plazo, incluyendo las ráfagas de actividad y las anomalías. La descomposición detallada de los datos mejora su calidad de procesamiento y facilita la extracción de características clave, algo fundamental cuando se trata de series temporales de los mercados financieros.
Tras la descomposición, los datos se introducen en un codificador espaciotemporal de doble frecuencia para su procesamiento. Este bloque combina varios módulos y está diseñado para analizar los componentes de frecuencia seleccionados y sus interdependencias. Las señales de baja frecuencia son procesadas por el mecanismo de atención temporal. Este se centra en las tendencias a largo plazo y sus cambios. Los datos de alta frecuencia, a su vez, pasan por capas convolucionales causales ampliadas que permiten destacar los cambios más minúsculos y su dinámica. A continuación, los módulos de atención integran las señales procesadas en grafos que captan las dependencias espaciotemporales que reflejarán las relaciones entre distintos activos e intervalos temporales. Este proceso produce representaciones de grafos multinivel que se convierten en incorporaciones multidimensionales. Estos últimos se combinan usando mecanismos de adición y atención gráfica, creando una visión holística de los datos para su posterior análisis.
El paso clave del procesamiento será el descodificador de fusión de doble frecuencia, que desempeña un papel crucial en la generación de los resultados predictivos. El descodificador integra los predictores mediante el mecanismo Fusion Attention, que permite la adición de datos de señales de baja y alta frecuencia en una única representación latente que refleja patrones temporales de diferentes escalas, ofreciendo un enfoque global del análisis de datos. En esta fase, el modelo genera representaciones ocultas que son procesadas por capas especializadas completamente conectadas. Estas capas permiten resolver varias tareas a la vez: prever la rentabilidad de los activos, determinar las probabilidades de cambio de tendencia y encontrar otras características clave de las series temporales. El enfoque multitarea hace que el modelo sea flexible y adaptable a diversas condiciones de mercado, lo cual resulta especialmente importante en mercados financieros muy volátiles.
A continuación le mostramos la visualización del framework Multitask-Stockformer realizada por el autor.
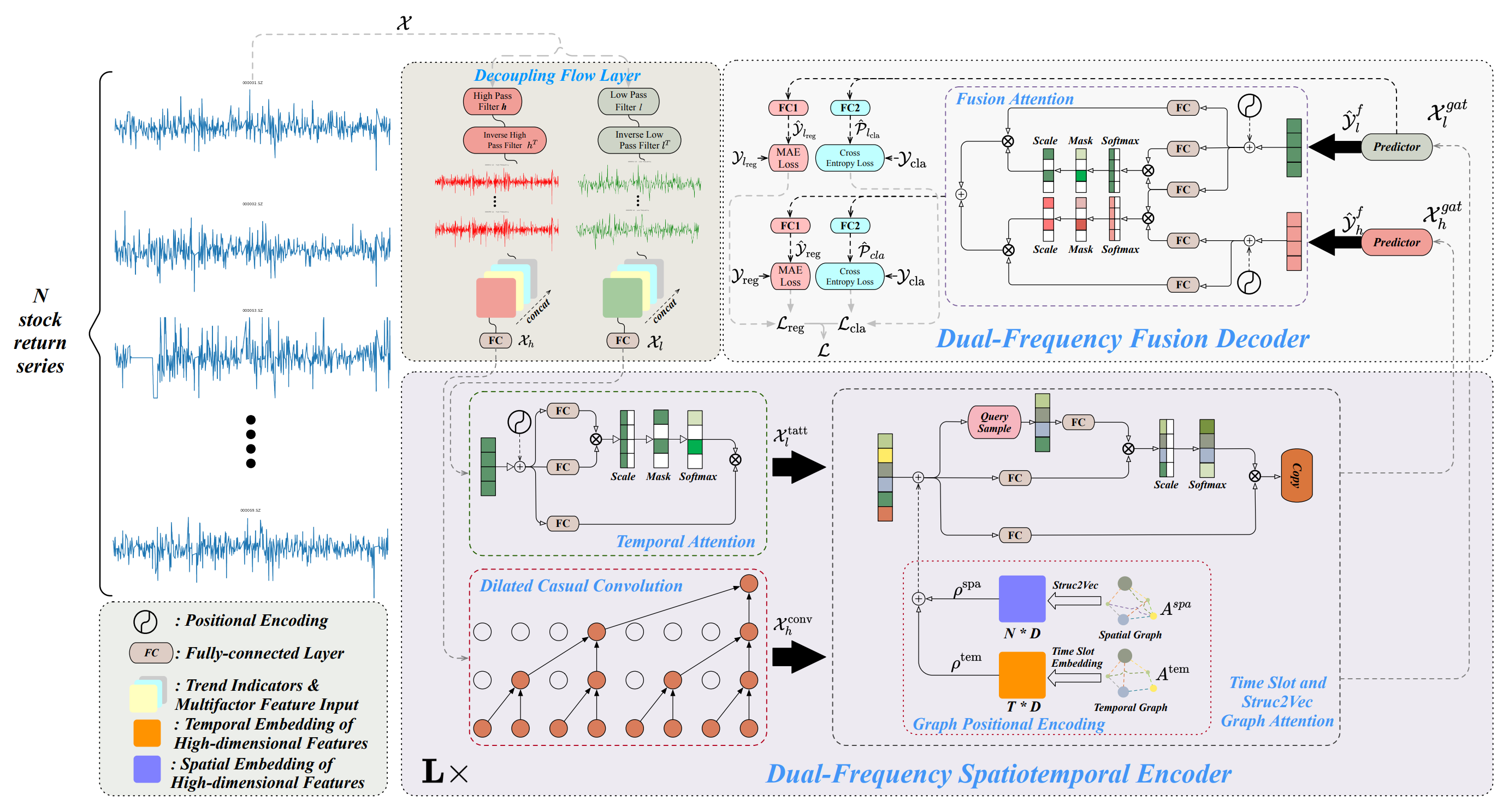
Aplicación del framework Multitask-Stockformer
Continuamos trabajando sobre la aplicación de los enfoques propuestos por los autores del framework Multitask-Stockformer utilizando herramientas MQL5, lo cual presupone la aplicación práctica de los componentes clave del sistema para optimizar el análisis de las series temporales.
Uno de los elementos básicos del framework es el módulo de descomposición de series temporales, que hemos implementado dentro de la clase CNeuronDecouplingFlow. Este componente permite separar los datos de origen en componentes de alta y baja frecuencia, lo que proporciona una base para el análisis posterior. La principal tarea del módulo es identificar las características estructurales clave de las series temporales, considerando su especificidad y las posibles tendencias del mercado. En el artículo anterior, discutimos las características constructivas y las decisiones algorítmicas subyacentes a la construcción de la clase CNeuronDecouplingFlow.
La siguiente etapa del procesamiento de datos consistirá en analizarlos mediante un codificador espaciotemporal de doble frecuencia. Como ya hemos mencionado, los autores del framework proponen una compleja arquitectura de codificador que incluye dos flujos de datos independientes. Al mismo tiempo, cada línea troncal tiene su propia arquitectura.
Los componentes de baja frecuencia se analizan usando un mecanismo de atención temporal basado en la arquitectura Self-Attention. Esta arquitectura ofrece amplias oportunidades para identificar las dependencias a largo plazo y pronosticar las tendencias del mercado mundial. La aplicación de Self-Attention posibilita una comprensión profunda de las estructuras de datos complejas, minimizando los riesgos de omitir relaciones significativas. Para la implementación actual, hemos decidido usar uno de los módulos de atención ya existentes en nuestra biblioteca utilizando el mecanismo de Self-Attention.
Los componentes de alta frecuencia de las series temporales se procesan usando el módulo de convolución causal ampliado, que implementamos dentro de la clase CNeuronDilatedCasualConv. La mejora de los algoritmos permitirá detectar eficazmente las anomalías locales y las ráfagas de actividad. Este componente desempeña un papel esencial en el análisis de la dinámica del mercado a corto plazo, incluidos los periodos de alta volatilidad. La incorporación de este módulo a la arquitectura general del framework ayuda a mejorar su adaptabilidad y rendimiento. Las decisiones de arquitectura y los cambios locales en el framework del autor que utilizamos para construir la clase CNeuronDilatedCasualConv los discutimos en un artículo anterior.
Tras preprocesar los componentes de alta y baja frecuencia de la señal analizada, los datos se dirigen a líneas troncales individuales de la ranura de atención de grafos. El núcleo de este módulo es la creación de dos grafos especializados. El primer grafo modela las dependencias temporales resaltando su estructura secuencial. Este grafo desempeña un papel importante en la identificación de tendencias, la ciclicidad y otras características temporales. El segundo grafo se basa en la matriz de correlaciones de los precios de los activos financieros, lo que posibilita una profunda integración de la información sobre las relaciones entre activos. Esto permite tener en cuenta la influencia de un activo sobre otro, lo que resulta especialmente importante para la elaboración de modelos y previsiones financieras. Juntos, estos grafos forman una estructura multinivel que mejora la precisión del análisis y la interpretación de los datos.
El algoritmo Struct2Vec se usa para convertir la información de los grafos en representaciones analíticamente utilizables. Este algoritmo convierte las propiedades topológicas de los grafos en incorporaciones vectoriales compactas, que luego se optimizan utilizando las capas completamente conectadas entrenadas. Estas incorporaciones permiten integrar eficazmente las características locales y globales de los datos, mejorando la calidad de los análisis de series temporales. A continuación, los datos procesados se envían a las líneas troncales de atención de grafos, donde se siguen explorando mediante mecanismos de atención. Este paso permite identificar las dependencias tanto a corto como a largo plazo.
Los autores del framework Multitask-Stockformer proponen una arquitectura de ranuras de atención de grafos bastante compleja. Y su aplicación requiere importantes recursos informáticos y una cuidadosa preparación de los datos. Al preparar el modelo para este artículo, hemos aplicado algunas simplificaciones destinadas a hacer que el modelo sea más práctico de utilizar, manteniendo al mismo tiempo su alto rendimiento. La primera simplificación consiste en excluir la información temporal sobre el estado del entorno analizado. Este paso se ha dado partiendo de la base de que la información temporal en esta fase, aunque útil, no afecta de forma crítica al rendimiento global de nuestro modelo. En la versión original del framework, la salida es un paquete de acciones generado, mientras que en nuestra aplicación, el objetivo principal es la creación de una representación latente del entorno. Esta representación es utilizada para tomar decisiones comerciales por el modelo del Actor, que adicionalmente recibe los datos de la cuenta y la marca temporal, lo cual posibilita el conocimiento contextual del modelo. De este modo, simplemente desplazamos el punto de transmisión del modelo de componente temporal.
No obstante, la simplificación aplicada al grafo de dependencia temporal no puede trasladarse al grafo de correlación de activos, ya que se perdería información clave. En su lugar, proponemos una solución alternativa sustituyendo la estructura propuesta por una capa entrenable de codificación posicional. Este enfoque permite un entrenamiento eficaz de las incorporaciones, minimizando la complejidad computacional y preservando las relaciones importantes entre activos que el modelo extrae de forma independiente durante el entrenamiento. Esta mejora ofrece una arquitectura más flexible que puede adaptarse a las distintas condiciones del mercado.
Además, lo llevamos un paso más allá sustituyendo las ranuras de atención de grafos por módulos de suavizado de características adaptables a nodos (Node-Adaptive Feature Smoothing — NAFS). Una ventaja importante de este método es la ausencia de parámetros entrenables en los módulos NAFS, lo que no solo reduce la complejidad computacional, sino que también simplifica el ajuste del modelo y el proceso de entrenamiento.
Con el NAFS, el proceso de incorporación se vuelve más flexible y robusto, ya que la técnica de suavizado se adapta a la topología del grafo y a las características de sus nodos. Esto resulta especialmente importante al resolver problemas en los que la estructura de datos puede ser heterogénea o cambiar dinámicamente. Así, la aplicación del NAFS ofrece representaciones de datos de alta calidad que consideran simultáneamente las relaciones locales y globales en el grafo.
La adición de los dos flujos de información se realiza en un descodificador de doble frecuencia que integra distintos aspectos de los datos, proporcionando la base para análisis multivariantes. Y esto permite comprender mejor la dinámica de los cambios de señal. El descodificador de doble frecuencia se basa en el mecanismo de Fusion Attention, que combina dos módulos de atención paralelos. El primero se basa en el mecanismo de Self-Attention y se especializa en el procesamiento profundo del componente de baja frecuencia, destacando las dependencias clave a largo plazo, las tendencias coherentes y los patrones globales. Gracias a este módulo, es posible identificar las características fundamentales de las series temporales que desempeñan un papel crucial en el pronóstico. El segundo módulo usa el mecanismo de Cross-Attention para integrar la información de alta frecuencia, añadiendo al análisis componentes a corto plazo y detallados. Esta integración permite enriquecer enormemente con detalles los datos de baja frecuencia, lo cual resulta especialmente importante para dar cuenta de fluctuaciones pequeñas pero significativas.
Los dos módulos de atención trabajan de forma sincronizada para crear representaciones coherentes y complementarias de los datos. Sus resultados se combinan mediante la suma, transmitiéndose posteriormente para su procesamiento a las capas completamente conectadas (MLP). Este enfoque garantiza que se consideren las características globales y locales de la señal investigada, lo que permite tener en cuenta una amplia gama de interrelaciones e influencias.
La arquitectura de Fusion Attention propuesta puede implementarse fácilmente mediante módulos de Cross-Attention y Self-Attention ya existentes. Además, su aplicación no requiere cambios significativos en los algoritmos básicos.
Por lo tanto, podemos concluir que todos los módulos clave están en su lugar para crear una arquitectura completa para el framework Multitask-Stockformer. Esto crea la base para la transición a la siguiente fase de desarrollo: la formación de un objeto de alto nivel que combinará todos los módulos anteriores en un único algoritmo funcionalmente completo. La principal tarea de esta fase no será solo integrar los componentes, sino también garantizar su funcionamiento sincronizado, considerando las peculiaridades de cada módulo. A continuación le mostramos la estructura del nuevo objeto CNeuronMultitaskStockformer.
class CNeuronMultitaskStockformer : public CNeuronBaseOCL { protected: CNeuronDecouplingFlow cDecouplingFlow; CNeuronBaseOCL cLowFreqSignal; CNeuronBaseOCL cHighFreqSignal; CNeuronRMAT cTemporalAttention; CNeuronDilatedCasualConv cDilatedCasualConvolution; CNeuronLearnabledPE cLowFreqPE; CNeuronLearnabledPE cHighFreqPE; CNeuronNAFS cLowFreqGraphAttention; CNeuronNAFS cHighFreqGraphAttention; CNeuronDMHAttention cLowFreqFusionDecoder; CNeuronCrossDMHAttention cLowHighFreqFusionDecoder; CNeuronBaseOCL cLowHigh; CNeuronConvOCL cProjection; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMultitaskStockformer(void) {}; ~CNeuronMultitaskStockformer(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint neurons_out, uint filters, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMultitaskStockformer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
La estructura presentada incluye muchos objetos internos que reflejan directamente los módulos del framework Multitask-Stockformer anteriormente descritos. Estos componentes están organizados para ofrecer un alto grado de integración funcional y flexibilidad de aplicación. Luego analizaremos con detalle sus algoritmos de interacción, así como los flujos de transferencia de información durante la aplicación de los métodos de objetos de integración.
Todos los objetos internos se declararán estáticamente, lo cual nos permitirá dejar vacíos el constructor y el destructor de la clase, mientras que la inicialización de todos los objetos recién declarados y heredados se realizará en el método Init.
bool CNeuronMultitaskStockformer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint neurons_out, uint filters, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, neurons_out, optimization_type, batch)) return false;
En los parámetros de este método, entre las constantes ya conocidas por nosotros, vemos una nueva: neurons_out. En ella se especifica el valor del vector de representación latente del estado del entorno analizado que el usuario espera recibir a la salida de este bloque Multitask-Stockformer. Precisamente este transmitiremos al llamar al método homónimo de la clase padre, en el que se inicializan las interfaces básicas de intercambio de datos con las capas neuronales externas dentro del modelo.
Una vez ejecutado con éxito el método de la clase padre, inicializaremos los objetos internos. Llevaremos a cabo este proceso, como de costumbre, en el orden en que se utilizan los objetos en la pasada directa. Como ya hemos mencionado, los datos de origen resultantes se separarán primero en componentes de alta y baja frecuencia en el módulo de descomposición de señales CNeuronDecouplingFlow.
uint index = 0; uint wave_window = MathMin(24, units_count); if(!cDecouplingFlow.Init(0, index, OpenCL, wave_window, 2, units_count, filters, window, optimization, iBatch)) return false; cDecouplingFlow.SetActivationFunction(None);
Observe que en los parámetros externos de nuestro método de inicialización del objeto de integración no hemos especificado el tamaño ni el paso de la ventana de la transformada de wavelet discreta. Estableceremos estos parámetros como valores fijos directamente en el método. En el marco del presente artículo, tenemos previsto realizar experimentos con los datos históricos del marco temporal H1. Basándonos en este supuesto, limitaremos el tamaño de la ventana de la transformada de wavelet a un día, lo que equivale a 24 pasos de la secuencia analizada. Al mismo tiempo, añadiremos un control para no superar el tamaño de las series temporales multimodales analizadas. El paso de ventana lo especificaremos igual a 2, lo que se corresponde con la omisión de un elemento de la secuencia.
La salida del módulo de descomposición de datos generará un único tensor que contendrá componentes de alta y baja frecuencia de la señal analizada. Sin embargo, para procesar estos datos, se proporcionan dos flujos paralelos en el codificador espaciotemporal de doble frecuencia, donde cada componente se analiza por separado. Para aplicar este enfoque, dividiremos los datos colocando cada componente en su propio objeto. Esto los hará más cómodos y flexibles para su posterior procesamiento.
//--- Dual-Frequency Spatiotemporal Encoder uint wave_units_out = cDecouplingFlow.GetUnits(); index++; if(!cLowFreqSignal.Init(0, index, OpenCL, cDecouplingFlow.Neurons() / 2, optimization, iBatch)) return false; cLowFreqSignal.SetActivationFunction(None); index++; if(!cHighFreqSignal.Init(0, index, OpenCL, cDecouplingFlow.Neurons() / 2, optimization, iBatch)) return false; cHighFreqSignal.SetActivationFunction(None); index++;
El componente de baja frecuencia se procesará en un módulo de atención temporal basado en el mecanismo de Self-Attention. En la versión original del framework Multitask-Stockformer, los autores sugieren añadir codificación posicional para mejorar el procesamiento de secuencias. Sin embargo, hemos decidido utilizar un módulo de atención con codificación relativa, que incluye un mecanismo integrado para determinar las posiciones relativas de los elementos de la secuencia. Esto hará que la codificación de posición adicional sea redundante, lo cual simplificará la arquitectura al tiempo que mejora su eficiencia.
if(!cTemporalAttention.Init(0, index, OpenCL, filters, window_key, wave_units_out * window, heads, layers, optimization, iBatch)) return false; cTemporalAttention.SetActivationFunction(None); index++;
Cabe señalar que la dimensionalidad del vector que describe un elemento de la secuencia se corresponderá con el número de filtros utilizados en la transformada de wavelet. En este caso, la dimensionalidad de la secuencia analizada abarcará todas las series temporales unitarias. Este enfoque ofrecerá la oportunidad de estudiar las interdependencias de las tendencias en toda la secuencia multimodal, en lugar de limitarse al análisis de sus componentes individuales.
Los análisis de dependencia de alta frecuencia se realizan en el módulo avanzado de convolución causal. Esta vez, en cambio, utilizaremos un tamaño mínimo de ventana de convolución de 2 elementos con un paso similar. Aquí analizaremos exclusivamente dentro de secuencias unitarias, lo cual nos permitirá centrarnos en un estudio detallado de las dependencias locales.
if(!cDilatedCasualConvolution.Init(0, index, OpenCL, 2, 2, filters, wave_units_out, window, layers, optimization, iBatch)) return false; index++;
A continuación, añadiremos la codificación posicional a ambos componentes.
if(!cLowFreqPE.Init(0, index, OpenCL, cTemporalAttention.Neurons(), optimization, iBatch)) return false; index++; if(!cHighFreqPE.Init(0, index, OpenCL, cDilatedCasualConvolution.Neurons(), optimization, iBatch)) return false; index++;
Resulta importante señalar que cada componente recibirá una capa aparte de codificación posicional entrenable. Este enfoque permitirá profundizar en el análisis y la comprensión de la estructura de los componentes de alta y baja frecuencia de forma independiente.
Para completar el codificador de doble frecuencia, inicializaremos los módulos de suavizado de los nodos adaptativos, que se aplicarán por separado a los componentes de alta y baja frecuencia. Ambos módulos recibirán los mismos parámetros, salvo la longitud de la secuencia, pues se espera una reducción del tamaño de la secuencia para el componente de alta frecuencia debido al funcionamiento específico del módulo de convolución causal ampliado.
if(!cLowFreqGraphAttention.Init(0, index, OpenCL, filters, 3, wave_units_out * window, optimization, iBatch)) return false; index++; if(!cHighFreqGraphAttention.Init(0, index, OpenCL, filters, 3, cDilatedCasualConvolution.Neurons()/filters, optimization, iBatch)) return false; index++;
En el siguiente paso, procederemos a inicializar los objetos del descodificador de fusión del flujo de datos. Aquí inicializaremos dos bloques de atención: Un bloque de Self-Attention para el componente de baja frecuencia y un bloque de Cross-Attention para añadir el componente de alta frecuencia.
//--- Dual-Frequency Fusion Decoder if(!cLowFreqFusionDecoder.Init(0, index, OpenCL, filters, window_key, wave_units_out * window, heads, layers, optimization, iBatch)) return false; index++; if(!cLowHighFreqFusionDecoder.Init(0, index, OpenCL, filters, window_key, wave_units_out * window, filters, cDilatedCasualConvolution.Neurons()/filters, heads, layers, optimization, iBatch)) return false; index++;
Como ya hemos dicho, los resultados de los bloques de atención se sumarán. Y para registrar los resultados de la operación, crearemos un objeto de capa neuronal básica.
if(!cLowHigh.Init(0, index, OpenCL, cLowFreqFusionDecoder.Neurons(), optimization, iBatch)) return false; CBufferFloat *grad = cLowFreqFusionDecoder.getGradient(); if(!grad || !cLowHigh.SetGradient(grad, true) || !cLowHighFreqFusionDecoder.SetGradient(grad, true)) return false; index++;
Para evitar operaciones innecesarias de copiado de datos, sincronizaremos los punteros al búfer de gradiente de error de los 3 últimos objetos. Este enfoque reducirá la carga de memoria y aumentará la eficacia general del proceso de entrenamiento.
A continuación, solo nos quedará inicializar los objetos MLP para generar la representación latente del estado del entorno analizado. Aquí utilizaremos una capa convolucional para reducir la dimensionalidad y una capa completamente conectada para generar una representación de un tamaño determinado.
Debemos señalar que al crear el objeto de integración, utilizaremos como objeto padre una capa básica completamente conectada. Esto nos permitirá inicializar solo el objeto de la capa de convolución interna especificando el número necesario de enlaces salientes. Y para implementar la funcionalidad de la capa completamente conectada usaremos los medios heredados de la clase padre.
if(!cProjection.Init(Neurons(), index, OpenCL, filters, filters, 3, wave_units_out, window, optimization, iBatch)) return false; //--- return true; }
Una vez inicializados con éxito todos los objetos internos, finalizaremos el método, devuelto previamente el resultado lógico de las operaciones al programa que realiza la llamada.
Una vez completado el método de inicialización de objetos, construiremos el algoritmo de pasada directa del objeto de integración en el método feedForward.
bool CNeuronMultitaskStockformer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Decoupling Flow if(!cDecouplingFlow.FeedForward(NeuronOCL)) return false;
En los parámetros del método obtendremos el puntero al objeto de datos de origen, que pasaremos directamente al método homónimo del módulo de descomposición de la serie temporal analizada.
Luego dividiremos el tensor total de los componentes de alta y baja frecuencia obtenido a la salida del módulo de descomposición entre los dos objetos para su posterior análisis en líneas troncales independientes.
if(!DeConcat(cLowFreqSignal.getOutput(), cHighFreqSignal.getOutput(), cDecouplingFlow.getOutput(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetUnits()*cDecouplingFlow.GetVariables())) return false;
Como ya hemos dicho, el componente de baja frecuencia se transferirá al módulo de atención temporal. A continuación, le añadiremos la codificación posicional y los datos pasarán al módulo de representación gráfica adaptativa.
//--- Dual-Frequency Spatiotemporal Encoder //--- Low Frequency Encoder if(!cTemporalAttention.FeedForward(cLowFreqSignal.AsObject())) return false; if(!cLowFreqPE.FeedForward(cTemporalAttention.AsObject())) return false; if(!cLowFreqGraphAttention.FeedForward(cLowFreqPE.AsObject())) return false;
El componente de alta frecuencia recorrerá su línea troncal, empezando por el módulo de convolución causal ampliado.
//--- High Frequency Encoder if(!cDilatedCasualConvolution.FeedForward(cHighFreqSignal.AsObject())) return false; if(!cHighFreqPE.FeedForward(cDilatedCasualConvolution.AsObject())) return false; if(!cHighFreqGraphAttention.FeedForward(cHighFreqPE.AsObject())) return false;
Los resultados de las dos líneas troncales se suministrarán a la entrada de un descodificador de fusión de doble frecuencia. Aquí, los datos serán procesados primero por dos módulos de atención. Y sus resultados se sumarán y normalizarán.
//--- Dual-Frequency Fusion Decoder if(!cLowFreqFusionDecoder.FeedForward(cLowFreqGraphAttention.AsObject())) return false; if(!cLowHighFreqFusionDecoder.FeedForward(cLowFreqGraphAttention.AsObject(), cHighFreqGraphAttention.getOutput())) return false; if(!SumAndNormilize(cLowFreqFusionDecoder.getOutput(), cLowHighFreqFusionDecoder.getOutput(), cLowHigh.getOutput(), cLowFreqFusionDecoder.GetWindow(), true, 0, 0, 0, 1)) return false;
Ahora nos quedará comprimir los datos con una capa de proyección convolucional.
if(!cProjection.FeedForward(cLowHigh.AsObject())) return false; //--- return CNeuronBaseOCL::feedForward(cProjection.AsObject()); }
Y pasar el resultado al método homónimo de la clase padre para generar una representación final del estado del entorno analizado.
La siguiente etapa de nuestro trabajo consistirá en organizar los procesos de pasada inversa, que desempeñarán un papel clave en el entrenamiento del modelo. Como siempre, comenzaremos este proceso desarrollando un algoritmo para distribuir el gradiente de error en el método calcInputGradients, donde organizamos el flujo de información respetando plenamente el algoritmo del pasada directa, solo que en sentido contrario.
bool CNeuronMultitaskStockformer::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
En los parámetros del método obtendremos un puntero al objeto de datos de origen, en cuyo búfer deberemos transmitir el gradiente de error según la influencia de los datos de origen en el resultado final del modelo. Y en el cuerpo del método comprobaremos la relevancia del puntero recibido, porque, de lo contrario, la transmisión de datos resultará imposible.
En primer lugar, el gradiente de error se pasará a la capa convolucional de la capa de proyección utilizando la funcionalidad de la clase padre. Y luego se enviará a la capa de suma de los datos recibidos de los dos módulos de atención del decodificador de fusión de doble frecuencia.
if(!CNeuronBaseOCL::calcInputGradients(cProjection.AsObject())) return false; if(!cLowHigh.calcHiddenGradients(cProjection.AsObject())) return false;
Aquí vale la pena recordar que en la inicialización del objeto de integración hemos sustituido los punteros a los búferes de gradiente de error utilizados por los módulos de atención del decodificador y la capa de suma de sus resultados. Esta solución garantizará que el gradiente de error completo transmitido a la capa de suma se transmita íntegramente a los módulos de atención correspondiente, lo cual nos permitirá pasar directamente a la distribución del gradiente a través de los módulos de atención del descodificador.
Nótese, sin embargo, que los datos de los componentes de baja frecuencia se usan simultáneamente en ambos bloques de atención. Y esto conllevará la necesidad de obtener el gradiente de error a partir de los dos flujos de información. Primero realizaremos las operaciones de distribución del gradiente de error a través del módulo de Self-Attention.
//--- Dual-Frequency Fusion Decoder if(!cLowFreqGraphAttention.calcHiddenGradients(cLowFreqFusionDecoder.AsObject())) return false;
A continuación, sustituiremos temporalmente el puntero al búfer de gradiente de error del módulo de Self-Attention por un búfer libre del mismo tamaño y realizaremos las operaciones del método de distribución del gradiente de error del módulo de Cross-Attention.
CBufferFloat *grad = cLowFreqGraphAttention.getGradient(); if(!cLowFreqGraphAttention.SetGradient(cLowFreqGraphAttention.getPrevOutput(), false) || !cLowFreqGraphAttention.calcHiddenGradients(cLowHighFreqFusionDecoder.AsObject(), cHighFreqGraphAttention.getOutput(), cHighFreqGraphAttention.getGradient(), (ENUM_ACTIVATION)cHighFreqGraphAttention.Activation()) || !SumAndNormilize(grad, cLowFreqGraphAttention.getGradient(), grad, 1, false, 0, 0, 0, 1) || !cLowFreqGraphAttention.SetGradient(grad, false)) return false;
Luego sumaremos los datos de los dos flujos de información y retornaremos los punteros a los búferes de datos al estado inicial.
En esta etapa, distribuiremos el gradiente de error a los componentes de alta y baja frecuencia al nivel de los resultados del codificador espaciotemporal de doble frecuencia. Y luego distribuiremos secuencialmente el gradiente entre los objetos de las dos líneas troncales independientes. Primero la de baja frecuencia.
//--- Dual-Frequency Spatiotemporal Encoder //--- Low Frequency Encoder if(!cLowFreqPE.calcHiddenGradients(cLowFreqGraphAttention.AsObject())) return false; if(!cTemporalAttention.calcHiddenGradients(cLowFreqPE.AsObject())) return false; if(!cLowFreqSignal.calcHiddenGradients(cTemporalAttention.AsObject())) return false;
Y luego la de alta frecuencia.
//--- High Frequency Encoder if(!cHighFreqPE.calcHiddenGradients(cHighFreqGraphAttention.AsObject())) return false; if(!cDilatedCasualConvolution.calcHiddenGradients(cHighFreqPE.AsObject())) return false; if(!cHighFreqSignal.calcHiddenGradients(cDilatedCasualConvolution.AsObject())) return false;
Después concatenaremos los gradientes de error obtenidos de las dos líneas troncales en un único tensor del búfer de gradiente del módulo de descomposición de los datos analizados.
//--- Decoupling Flow if(!Concat(cLowFreqSignal.getGradient(), cHighFreqSignal.getGradient(), cDecouplingFlow.getGradient(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetUnits()*cDecouplingFlow.GetVariables())) return false; if(!prevLayer.calcHiddenGradients(cDecouplingFlow.AsObject())) return false; //--- return true; }
Y lo haremos descender hasta el nivel de los datos de origen llamando al método homónimo del módulo de descomposición de datos. Después finalizaremos el método transmitiendo el resultado lógico de las operaciones al programa que realiza la llamada.
Y luego realizaremos las operaciones del método updateInputWeights de optimización de los parámetros del modelo en el mismo orden, solo que para los objetos que contienen los parámetros entrenados. Por lo tanto, le propongo dejar el método anterior para su estudio individual. Encontrará el código completo del objeto de integración y todos sus métodos en el archivo adjunto.
Ya hemos concluido nuestro análisis de los algoritmos para implementar el framework Multitask-Stockformer, así que podemos pasar a la siguiente etapa de nuestro trabajo: la implementación de los enfoques implementados en la arquitectura de modelos entrenados.
Arquitectura de los modelos
Implementaremos los planteamientos del framework Multitask-Stockformer antes expuesto en un modelo de codificador del estado del entorno. Hay que decir que debido al uso de un objeto complejo de la implementación del framework Multitask-Stockformer la arquitectura del modelo resultó ser bastante corta y contiene solo 3 capas. En primer lugar, tradicionalmente utilizamos una capa de datos de origen y normalización por lotes.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } //--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
En estas se preprocesan los datos "brutos" de entrada procedentes del entorno. Y a estos les sigue una nueva capa de implementación de los enfoques del framework Multitask-Stockformer.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultitaskStockformer; //--- Windows { int temp[] = {BarDescr, 10, LatentCount}; //Window, Filters, Output if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.layers = 3; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
En nuestro experimento hemos utilizado 10 filtros wavelet. Y cada módulo de atención usará 4 cabezas y contendrá 3 capas internas.
Los resultados del codificador del estado del entorno serán utilizados por los modelos del Actor para tomar una decisión comercial y por el Crítico, que evaluará las operaciones generadas por el Actor. La arquitectura de estos modelos la hemos tomado prestada de trabajos anteriores. También tomaremos prestados de allí la interacción del entorno y los programas de entrenamiento del modelo. La descripción completa de la arquitectura de los modelos y el código de los programas usados en la redacción del artículo figuran en el anexo. Ahora pasaremos a la fase final: la prueba de la eficacia de las soluciones aplicadas con datos históricos reales.
Simulación
A lo largo de los dos artículos, hemos trabajado mucho para implementar los enfoques propuestos por los autores del framework Multitask-Stockformer mediante MQL5. Y ha llegado el momento de la fase más emocionante: probar la eficacia de los enfoques aplicados con datos históricos reales.
Debe quedar claro que lo que estamos evaluando son los enfoques *implementados*, no el framework Multitask-Stockformer tal y como lo presenta el autor, dado que el algoritmo del framework original se ha modificado durante la aplicación.
En el transcurso de las pruebas, el modelo se ha entrenado con datos históricos para todo el año 2023 del instrumento financiero EURUSD, y el marco temporal H1. Todos los parámetros de los indicadores analizados se han usado con los ajustes por defecto.
Para la primera fase de entrenamiento, hemos utilizado una muestra de entrenamiento recogida de estudios anteriores. A partir de entonces, la muestra de entrenamiento se ha actualizado periódicamente para adaptarla a las políticas actuales del Actor. Tras varias rondas de entrenamiento y actualización de la muestra, hemos obtenido una política que muestra rentabilidad tanto en la muestra de entrenamiento como en la de prueba.
Las pruebas de la política entrenada se han realizado con datos históricos de enero de 2024, manteniendo intactos todos los demás parámetros. A continuación le presentamos los resultados de las pruebas.
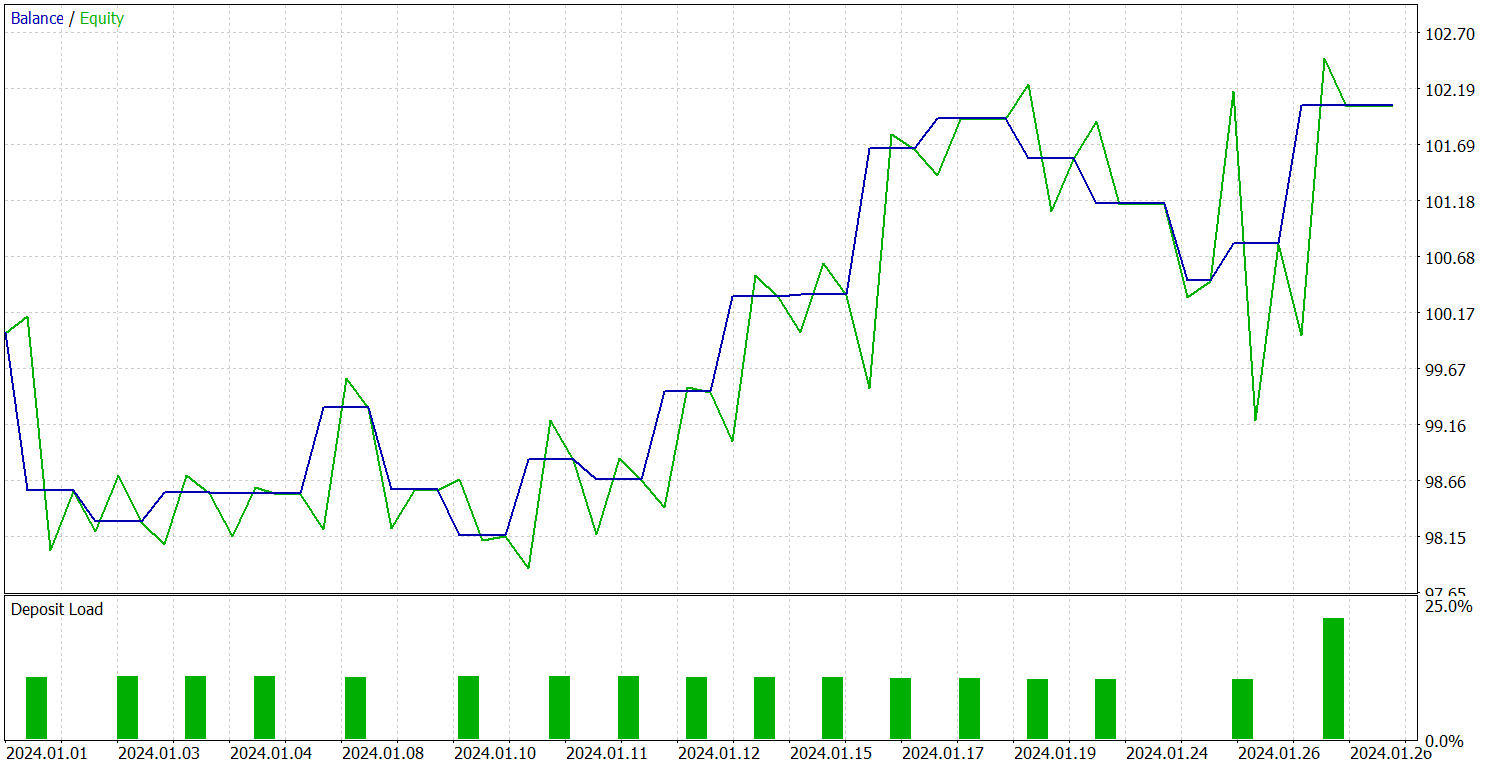
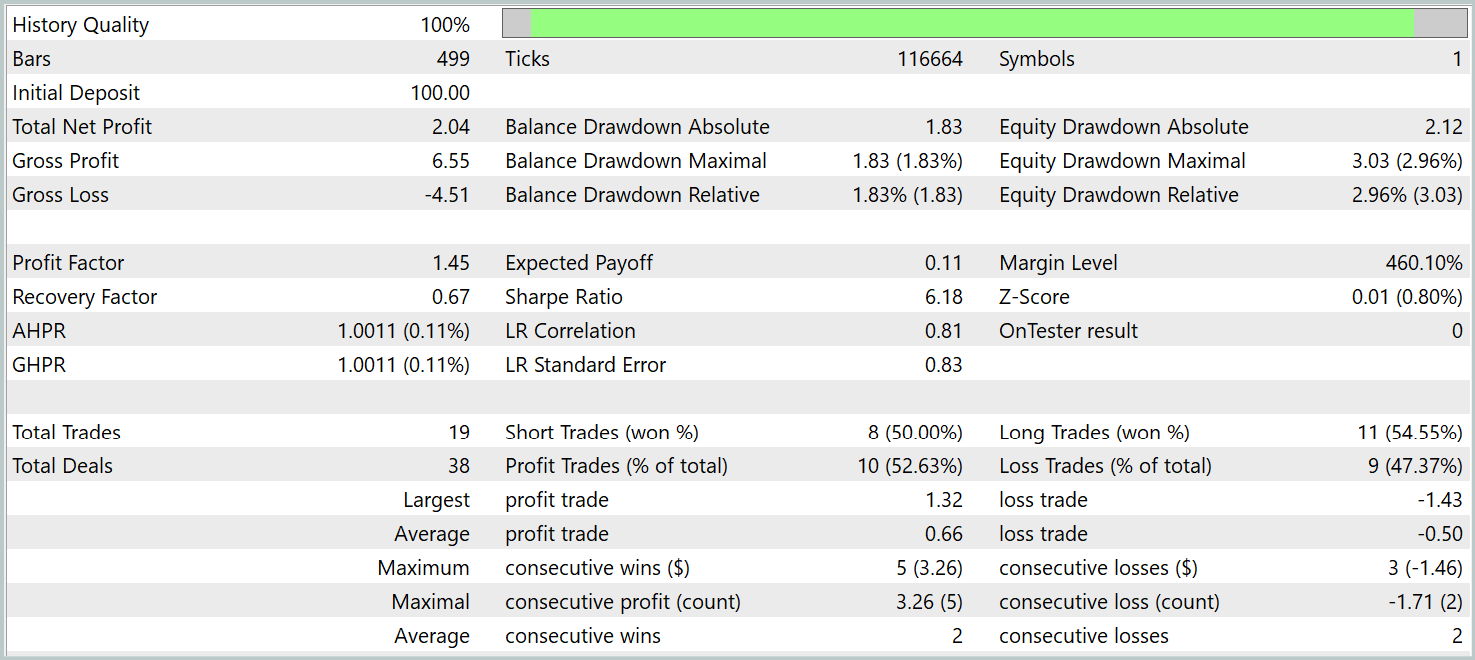
Durante el periodo de prueba, el modelo ha realizado 19 transacciones comerciales, 10 de las cuales se han cerrado con beneficios. Eso es algo más del 50%. Sin embargo, a que el promedio de transacciones rentables supera el indicador similar de las posiciones perdedoras, el modelo ha cerrado el periodo de prueba con beneficios, fijado el factor de beneficio a un nivel de 1,45.
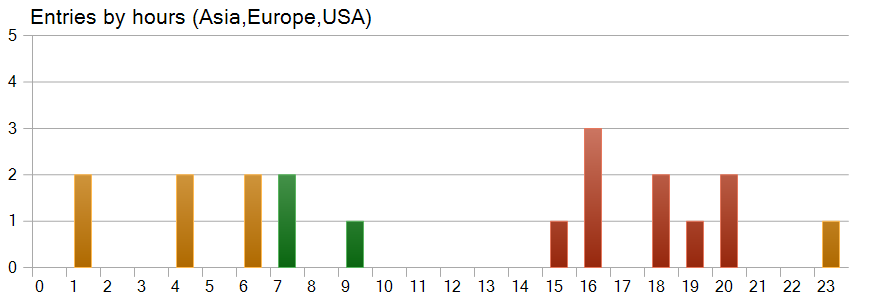
También resulta bastante interesante el gráfico de horas de apertura de las posiciones. Aquí vemos que casi la mitad de las posiciones se han abierto en la sesión americana. Y que prácticamente no se han realizado transacciones durante el periodo de mayor volatilidad del instrumento.
Conclusión
Hoy nos hemos familiarizado con el framework Multitask-Stockformer, que supone un innovador modelo de selección de valores que combina la transformada de wavelet discreta con módulos multitarea de Self-Attention. Este enfoque integrado permite identificar las características temporales y frecuenciales de los datos de mercado, al tiempo que posibilita una modelización precisa de las complejas interacciones entre los factores analizados.
En la parte práctica, hemos implementado nuestra propia visión de los enfoques framework utilizando las herramientas MQL5. Asimismo, hemos introducido los enfoques implementados en modelos y los hemos entrenado con datos históricos reales. Los modelos entrenados se han probado en el simulador de estrategias de MetaTrader 5. Los resultados de nuestros experimentos demuestran el potencial de las soluciones aplicadas. Sin embargo, antes de usar las soluciones presentadas en el comercio real, deberemos entrenar el modelo con una muestra de entrenamiento más representativa, seguida de pruebas exhaustivas.
Enlaces
- Stockformer: A Price-Volume Factor Stock Selection Model Based on Wavelet Transform and Multi-Task Self-Attention Networks
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de la descripción del estado del sistema y la arquitectura del modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16757
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso