
Redes neuronales en el trading: Framework comercial híbrido con codificación predictiva (Final)

Introducción
En el artículo anterior, examinamos con detalle los aspectos teóricos del sistema comercial híbrido StockFormer, que combina codificación predictiva y algoritmos de aprendizaje por refuerzo para pronosticar las tendencias del mercado y la dinámica de los activos financieros. El StockFormer es un framework híbrido que combina varias tecnologías y enfoques clave para resolver problemas complejos en los mercados financieros. La principal característica es el uso de tres ramas del Transformer modificadas, cada una de las cuales es responsable de estudiar diferentes aspectos de la dinámica del mercado. La primera rama del modelo se dedica a extraer interdependencias ocultas entre los activos, mientras que la segunda y la tercera rama se centran en la previsión a corto y largo plazo, lo que permite al sistema considerar las tendencias actuales y futuras del mercado.
La integración de estas ramas se produce mediante una cascada de mecanismos de atención que mejora la capacidad del modelo para aprender usando bloques multicabeza, mejorando su procesamiento y la detección de patrones ocultos en los datos. Como resultado, el sistema no solo puede analizar y predecir tendencias basándose en datos históricos, sino que también puede considerar las relaciones dinámicas entre diferentes activos, lo que resulta especialmente importante para desarrollar estrategias comerciales que puedan adaptarse a las condiciones del mercado que cambian rápidamente.
A continuación presentamos la visualización del autor del framework StockFormer.
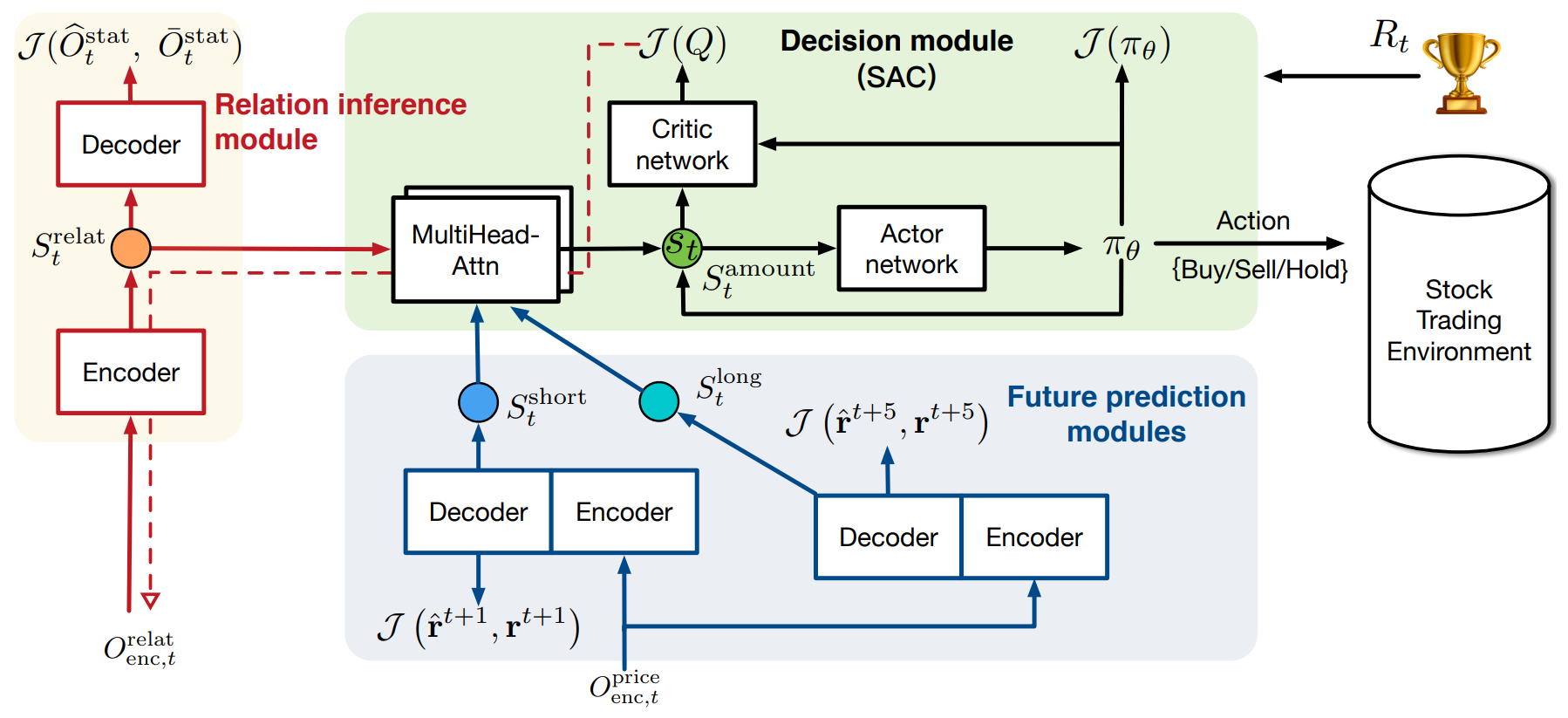
En la parte práctica del artículo anterior implementamos los algoritmos del módulo Diversified Multi-Head Attention (DMH-Attn), que sirve como base para mejorar el mecanismo de atención estándar en el modelo del Transformer. El DMH-Attn permite mejorar significativamente la eficiencia en la identificación de diversos patrones e interdependencias en series temporales financieras, lo que resulta especialmente importante al trabajar con datos ruidosos y altamente volátiles.
En este artículo continuaremos el trabajo iniciado y nos centraremos en la arquitectura de las distintas partes del modelo, así como en sus mecanismos de interacción para crear un único espacio de estados. Además, analizaremos el proceso de entrenamiento de la política de comportamiento del Agente para la toma de decisiones comerciales.
Modelos de codificación predictiva
Iniciaremos nuestro trabajo con los modelos de codificación predictiva. Los autores del framework Stockformer proponen utilizar tres modelos predictivos. Uno de ellos se ha diseñado para detectar las dependencias entre los datos que describen la dinámica de los activos financieros analizados, mientras que los otros dos han sido entrenados para predecir el próximo movimiento de la serie temporal multimodal considerada con diferentes horizontes de planificación.
Los tres modelos se han construido sobre la arquitectura del Codificador-Decodificador del Transformer utilizando módulos DMH-Attn modificados. En nuestra implementación, crearemos el Codificador y el Decodificador como modelos separados.
Modelos para encontrar interdependencias
La arquitectura de modelos para la búsqueda de interdependencias en las series temporales de los activos financieros analizados se presenta en el método CreateRelationDescriptions.
bool CreateRelationDescriptions(CArrayObj *&encoder, CArrayObj *&decoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; }
En los parámetros del método obtendremos los punteros a los dos arrays dinámicos a los que deberemos transmitir la descripción de la arquitectura del Codificador y Decodificador. En el cuerpo del método, verificaremos la relevancia de los punteros obtenidos y, de ser necesario, crearemos nuevas instancias de objetos de arrays dinámicos.
Como primera capa del Сodificador, usaremos, como viene siendo habitual, una capa completamente conectada de tamaño suficiente que debería admitir todos los datos del tensor de datos de origen.
Permítame recordarle que suministraremos a la entrada del Сodificador datos históricos para toda la profundidad de la historia analizada.
//--- Encoder encoder.Clear(); //--- if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Como datos iniciales usaremos la información “bruta” recibida desde el terminal. Como podrá suponer, los datos de las series temporales multimodales resultantes, que contienen información de los indicadores analizados y posiblemente de varios instrumentos financieros, pertenecerán a distribuciones diferentes. Por consiguiente, realizaremos el procesamiento primario de los datos de origen en la capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Los autores del framework StockFormer proponen enmascarar aleatoriamente hasta el 50% de los datos de origen durante el entrenamiento de los modelos de búsqueda de relaciones. Y el modelo deberá reconstruir ya los datos enmascarados a partir de la información restante. La capa Dropout se encargará del enmascaramiento de los datos de origen en nuestro Codificador.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; descr.probability = 0.5f; if(!encoder.Add(descr)) { delete descr; return false; }
Detrás de dicha capa añadiremos una capa de codificación posicional entrenable.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLearnabledPE; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
El Codificador se completará con un módulo de atención multicabeza diversificado con 3 capas anidadas.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDMHAttention; descr.window = BarDescr; descr.window_out = 32; descr.count = HistoryBars; descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
La misma serie temporal multimodal, con enmascaramiento y codificación posicional similares, se introducirá en la entrada del Decodificador del modelo para buscar relaciones entre las secuencias analizadas. Por lo tanto, en su mayor parte, la arquitectura del Сodificador y del Decodificador son idénticas. Simplemente reemplazaremos el módulo de atención multicabeza diversificado con un módulo de atención cruzada similar que comparará los datos de las líneas troncales del Decodificador y el Codificador.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; //--- Windows { int temp[] = {BarDescr, BarDescr}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = 32; //--- Units { int temp[] = {prev_count/descr.windows[0], HistoryBars}; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Y como compararemos los resultados del trabajo del Decodificador con los datos de origen, complementaremos el modelo con una capa de normalización inversa.
//--- layer 5 prev_count = descr.units[0] * descr.windows[0]; if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count; descr.layers = 1; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; } //--- return true; }
Modelos de pronóstico
Ambos modelos de previsión, a pesar de tener diferentes horizontes de planificación, poseen la misma arquitectura, presentada en el método CreatePredictionDescriptions. Y hay que decir que planeamos suministrar a la entrada del Сodificador la misma serie temporal multimodal que fue analizada por el modelo anteriormente analizado para buscar interdependencias. Por lo tanto, transferiremos al completo la arquitectura al Codificador excluyendo solo la capa Dropout, ya que en este caso no se utilizará el enmascaramiento de los datos de origen en el proceso de entrenamiento del modelo.
El Decodificador del modelo de predicción obtendrá como entrada únicamente el vector de descripción de la última barra, cuyos valores se transferirán a la capa completamente conectada.
//--- Decoder decoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr); descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
A continuación, al igual que en los modelos anteriores, vendrá una capa de normalización por lotes, que utilizaremos para el procesamiento primario de los datos de origen “sin procesar”.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
En este artículo, planeamos entrenar un modelo para analizar los datos históricos de un instrumento financiero. Teniendo esto en cuenta, la presencia de un solo vector de descripción de barras en los datos de origen minimizará la eficiencia de la capa de codificación posicional. Por lo tanto, en este caso no lo utilizaremos. Sin embargo, al analizar más de un instrumento financiero, le recomendaría agregar codificación posicional a los datos de origen.
A continuación encontraremos un módulo de atención cruzada multicabeza diversificada de tres capas, que utilizará como segunda fuente de datos la salida del Codificador correspondiente.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; //--- Windows { int temp[] = {BarDescr, BarDescr}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = 32; //--- Units { int temp[] = {1, HistoryBars}; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Y a la salida del modelo, agregaremos una capa de proyección de datos completamente conectada sin función de activación.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = BarDescr; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; } //--- return true; }
Aquí quisiera llamar la atención sobre dos puntos. En primer lugar, a diferencia de los modelos considerados anteriormente para pronosticar los valores esperados de continuación de las series temporales analizadas, los autores del framework StockFormer proponen pronosticar los coeficientes de cambio en los indicadores. De esta forma, el tamaño del vector de resultados será igual al tensor de datos iniciales del decodificador, independientemente del horizonte de planificación. Y este enfoque nos permitirá abandonar la capa de normalización inversa en la salida del decodificador. Además, en este tipo de pronóstico, la capa de normalización inversa se vuelve redundante. Después de todo, el coeficiente de cambio y los indicadores de los datos de origen se refieren a distribuciones distintas.
El segundo punto que merece la pena mencionar es el uso de una capa completamente conectada en la salida del decodificador. En este caso, como hemos mencionado anteriormente, planeamos analizar una serie temporal multimodal de un instrumento financiero. Y esperamos que todas las secuencias unitarias analizadas tengan correlaciones mutuas de diversos grados. Por lo tanto, sus coeficientes de cambio deberán ser consistentes. Y aquí el uso de una capa completamente conectada resultará bastante apropiado. Si planea realizar un análisis paralelo de varios instrumentos financieros, entonces le recomendaría reemplazar la capa completamente conectada por una capa convolucional con pronóstico independiente de los coeficientes de cambio en los indicadores de activos individuales.
Con esto concluirá nuestra discusión sobre la arquitectura de los modelos de codificación predictiva. Encontrará una descripción completa de su arquitectura en el archivo adjunto.
Entrenamiento de modelos de codificación predictiva
En el framework StockFormer, el entrenamiento de modelos de codificación predictiva supone un paso aparte. Así que le propongo que, después de considerar la arquitectura de los modelos de codificación predictiva, pasemos a construir un asesor para su entrenamiento. Los métodos básicos del asesor se tomarán prestados en gran medida de los programas similares discutidos en los artículos anteriores de esta serie. Por lo tanto, en el marco de este artículo, analizaremos únicamente el algoritmo de entrenamiento directo de modelos, organizado en el método Train.
Primero, realizaremos un pequeño trabajo preparatorio, durante el cual formaremos un vector de probabilidades para seleccionar las pasadas del búfer de reproducción de experiencias, asignando una mayor probabilidad a las pasadas con máxima rentabilidad. De esta manera, desplazaremos el proceso de aprendizaje hacia pasadas provechosas, llenando el entrenamiento de ejemplos positivos.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; matrix<float> predict; bool Stop = false; //--- uint ticks = GetTickCount();
En esta etapa, también declararemos las variables locales necesarias que se usarán para almacenar los datos intermedios durante el proceso de entrenamiento. Y después de completar el trabajo preparatorio, organizaremos un ciclo de iteraciones de entrenamiento. El número total de iteraciones se especificará en los parámetros externos del asesor.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter --; continue; } if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter --; continue; } if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize((NForecast + 1)*BarDescr) || MathAbs(state).Sum() == 0) { iter --; continue; }
En el cuerpo del ciclo, tomaremos una muestra de una trayectoria del búfer de reproducción de experiencias y el estado inicial del entorno en ella. Y verificaremos obligatoriamente la disponibilidad de datos históricos para el análisis en el estado seleccionado, así como la disponibilidad de datos reales para el horizonte de planificación dado. Si el bloque de control se transmite con éxito, transferiremos los valores históricos a la profundidad de análisis especificada en el búfer de datos correspondiente y realizaremos una pasada directa de todos los modelos predictivos.
//--- Feed Forward if(!RelateEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !RelateDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(RelateEncoder)) || !ShortEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !ShortDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(ShortEncoder)) || !LongEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !LongDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(LongEncoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Tenga en cuenta que a pesar de tener la misma arquitectura, cada modelo predictivo posee su propio Codificador. Este enfoque aumenta el número de modelos entrenados y, al mismo tiempo, los costes de entrenamiento y operación de los modelos. Pero al mismo tiempo, permite que cada modelo determine las dependencias relevantes para resolver un problema específico.
Además, debemos mencionar el uso del tensor de datos de origen de la línea principal del Decodificador. Al considerar la arquitectura de los modelos, dijimos que solo los datos de la última barra se suministran a la entrada del decodificador de los modelos de pronóstico. Aquí vemos el uso de un búfer de datos históricos para lograr una profundidad de análisis completa en todos los casos. Y aquí deberíamos recurrir al formato de registro del estado del entorno en el búfer de reproducción de experiencias: podemos representarlo como una matriz. Las filas se corresponden con las barras, mientras que las columnas se corresponde con las características (indicadores de precios y valores de indicadores). La primera línea contiene información sobre la última barra. Por consiguiente, al transmitir un tensor de datos históricos cuyo tamaño exceda la cantidad de elementos en la capa de datos de origen, el modelo solo tomará los primeros datos del tamaño de la capa de datos de origen. Esto es exactamente lo que necesitamos. Por ello, podemos evitar desperdiciar recursos en la creación de un búfer adicional y el copiado innecesario de datos.
Después de completar con éxito la pasada directa, prepararemos los objetivos y realizaremos las operaciones de pasada inversa. Para los modelos de detección de interdependencias en las series temporales unitarias de las series temporales analizadas, los valores objetivo serán las series temporales multimodales que estamos analizando. Por lo tanto, podremos realizar inmediatamente la pasada inversa del Decodificador con el gradiente de error transmitido al Codificador. Y según el gradiente obtenido, ajustaremos los parámetros del Codificador.
//--- Relation if(!RelateDecoder.backProp(GetPointer(bState), (CNet *)GetPointer(RelateEncoder)) || !RelateEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Pero para los modelos de pronóstico necesitaremos definir los valores objetivo. Como ya hemos mencionado antes, en este caso se utilizarán como valores objetivo los coeficientes de cambio de los parámetros analizados. Partiremos del supuesto de que el horizonte de planificación es menor que la profundidad del análisis de datos históricos. Por tanto, para calcular los valores objetivo, podemos tomar del búfer de reproducción de experiencias un estado de la descripción del entorno registrado con posterioridad al que se analiza para un horizonte de planificación de pasos dado. Y transformar el tensor resultante en una matriz, cuyas filas representarán barras individuales.
//--- Prediction if(!predict.Resize(1, state.Size()) || !predict.Row(state, 0) || !predict.Reshape(NForecast + 1, BarDescr) ) { iter --; continue; }
Como ya hemos mencionado anteriormente, las primeras filas de dicha matriz contendrán las barras posteriores. Para determinar los valores objetivo, tomaremos 1 línea más que el horizonte de planificación. De esta forma, la última fila de la matriz truncada contendrá la información sobre la barra que estamos analizando.
Aquí deberemos recordar que el búfer de reproducción de experiencias almacena datos no normalizados. Y, para obtener los coeficientes de cambio de precios en un rango adecuado de datos, tomaremos como base los valores máximos absolutos para cada parámetro individual en nuestra matriz de valores futuros. En este caso, esperamos obtener los coeficientes de cambio de parámetros en el rango {-2.0, 2.0}.
result = MathAbs(predict).Max(0);
Los autores del framework proponen usar el coeficiente de cambio del parámetro en la siguiente barra como valores objetivo del modelo de pronóstico a corto plazo. Para calcular dicho coeficiente, tomaremos la diferencia de las últimas 2 filas de nuestra matriz de valores predichos y las dividiremos por el vector de valores máximos. Y escribiremos el resultado obtenido en el búfer correspondiente.
target = (predict.Row(NForecast - 1) - predict.Row(NForecast)) / result; if(!bShort.AssignArray(target)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Para el modelo de planificación a largo plazo, sumaremos los coeficientes de cambio de precio en cada barra, considerando el factor de descuento.
for(int i = 0; i < NForecast - 1; i++) target += (predict.Row(i) - predict.Row(i + 1)) / result * MathPow(DiscFactor, NForecast - i - 1); if(!bLong.AssignArray(target)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Ahora que hemos definido un conjunto completo de valores objetivo, podremos actualizar los parámetros de los modelos de pronóstico para minimizar el error de pronóstico. Para ello, primero realizaremos una pasada inversa del Decodificador y Codificador del modelo de predicción a corto plazo, y luego en el modelo a largo plazo.
//--- Short prediction if(!ShortDecoder.backProp(GetPointer(bShort), (CNet *)GetPointer(ShortEncoder)) || !ShortEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
//--- Long prediction if(!LongDecoder.backProp(GetPointer(bLong), (CNet *)GetPointer(LongEncoder)) || !LongEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Después de ajustar los parámetros de todos los modelos entrenados en esta etapa, solo nos quedará informar al usuario sobre el progreso de las operaciones y pasar a la siguiente iteración del ciclo de entrenamiento del modelo predictivo.
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Relate", percent, RelateDecoder.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Short", percent, ShortDecoder.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Long", percent, LongDecoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Una vez completadas con éxito todas las iteraciones del ciclo de entrenamiento del modelo predictivo, eliminaremos el campo de comentarios del gráfico donde previamente informamos al usuario sobre el progreso del entrenamiento del modelo.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Relate", RelateDecoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Short", ShortDecoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Long", LongDecoder.getRecentAverageError()); ExpertRemove(); //--- }
Después enviaremos los resultados del entrenamiento del modelo al registro e inicializaremos el proceso de detención del funcionamiento de nuestro asesor.
Encontrará el código completo del experto para entrenar los modelos predictivos en el archivo adjunto al artículo (archivo "...\MQL5\Experts\StockFormer\Study1.mq5").
Aquí cabe señalar que, en el contexto de los modelos de entrenamiento, al preparar este artículo, utilizamos la estructura de los datos de origen que usamos en trabajos anteriores. En este caso, solo se usarán los estados del entorno que sean independientes de las acciones del Agente para entrenar modelos predictivos. Por lo tanto, iniciaremos el proceso de entrenamiento de los modelos predictivos basados en la muestra de entrenamiento previamente recolectada. Y mientras tanto, pasaremos a la siguiente etapa de nuestro trabajo.
Entrenamiento de la política
Y mientras el entrenamiento de los modelos predictivos está en marcha, nos prepararemos para la siguiente etapa: el entrenamiento de la política de comportamiento del Agente.
Arquitectura de los modelos
Comenzaremos nuestro trabajo preparando la arquitectura de los modelos que se entrenarán en esta etapa, presentados en el método CreateDescriptions. Sin embargo, merece la pena señalar que en el framework del Stockformer, el Actor y el Crítico utilizan como entrada los resultados de los modelos predictivos combinados en un solo subespacio, utilizando para ello una cascada de módulos de atención. Nuestra biblioteca ofrece la posibilidad de construir modelos con dos fuentes de datos. Por lo tanto, dividiremos la cascada de módulos de atención en 2 modelos. En el primer modelo, compararemos los datos de los dos horizontes de planificación. Aquí los autores del framework proponen usar los datos de planificación a largo plazo en la línea troncal principal, ya que es menos susceptible a la influencia del ruido.
La arquitectura del modelo para comparar los dos horizontes de planificación resulta bastante simple. En ella crearemos solo 2 capas:
- La capa de datos de origen completamente conectada.
- El módulo de atención cruzada diversificado con 3 capas internas.
//--- Long to Short predict long_short.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr); descr.activation = None; descr.optimization = ADAM; if(!long_short.Add(descr)) { delete descr; return false; } //--- Layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; //--- Windows { int temp[] = {BarDescr, BarDescr}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = 32; //--- Units { int temp[] = {1, 1}; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!long_short.Add(descr)) { delete descr; return false; }
En este caso, no utilizaremos una capa de normalización de datos, ya que no estamos suministrando a la entrada del modelo datos brutos, sino el resultado del trabajo de los modelos de pronóstico previamente analizados.
Los resultados de la comparación de los dos horizontes de planificación se enriquecerán aún más con la información sobre el estado actual del entorno, que tomaremos en la salida del Codificador del modelo para buscar interdependencias en los datos de origen.
Tenga en cuenta que el entrenamiento del modelo para buscar interdependencias en secuencias unitarias de los datos de origen se ha realizado con el objetivo de restaurar la parte enmascarada de los datos de origen. Por lo tanto, en esta etapa esperamos que la representación del modelo contenga algún estado predictivo de cada serie temporal unitaria formada sobre la base de las secuencias unitarias restantes. Esto significa que en la salida del Codificador del modelo de análisis de dependencias esperamos obtener un tensor con la descripción inicial del estado del entorno, libre de ruido. Después de todo, los valores atípicos que no se ajusten a las expectativas del modelo serán compensados por los indicadores estadísticos promedio formados sobre la base de datos de otras series unitarias.
La arquitectura del modelo de enriquecimiento de los valores pronosticados de la información sobre el estado del entorno repite casi por completo el modelo de comparación de los dos horizontes de planificación presentado anteriormente. Simplemente cambiaremos el tamaño de la secuencia en la segunda fuente de datos.
//--- Predict to Relate predict_relate.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr); descr.activation = None; descr.optimization = ADAM; if(!predict_relate.Add(descr)) { delete descr; return false; } //--- Layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; //--- Windows { int temp[] = {BarDescr, BarDescr}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = 32; //--- Units { int temp[] = {1, HistoryBars}; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!predict_relate.Add(descr)) { delete descr; return false; }
Después de construir una cascada de módulos de atención que combinan los resultados de los tres modelos predictivos en un único subespacio, pasaremos a construir la arquitectura de nuestro Actor. A la entrada del modelo, introduciremos los resultados de la cascada de atención descrita.
//--- Actor actor.Clear(); //--- Input Layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Luego combinaremos las expectativas predictivas obtenidas con la información sobre el estado actual de la cuenta.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
La información combinada la pasaremos a través de un bloque de toma de decisiones representado como un MLP con cabeza estocástica.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Y en la salida del modelo, coordinaremos los parámetros de las transacciones en direcciones individuales utilizando una capa convolucional con una función de activación sigmoidea.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; }
El modelo del Crítico tiene una arquitectura similar, solo que en lugar del estado de la cuenta analizará las acciones del Agente y en la salida del modelo no utilizaremos una cabeza estocástica. Podrá familiarizarse con la arquitectura completa de todos los modelos utilizados en el archivo adjunto.
Programa de entrenamiento de la política
Tras construir la arquitectura de los modelos, pasaremos a organizar los algoritmos para su entrenamiento. En la segunda etapa del entrenamiento del modelo, se realizará la búsqueda de la estrategia óptima de comportamiento del Agente para lograr la máxima rentabilidad minimizando los riesgos.
Al igual que antes, al comienzo del método de entrenamiento realizaremos un pequeño trabajo preparatorio. Así, generaremos un vector de probabilidades para seleccionar las pasadas del búfer de reproducción de experiencias dependiendo de su efectividad y declararemos las variables locales.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
A continuación, organizaremos un ciclo de entrenamiento del modelo, cuyo número de iteraciones estará determinado por los parámetros externos del asesor.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter --; continue; } if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter --; continue; }
En el cuerpo del ciclo, tomaremos una muestra de la pasada y su estado para la iteración de entrenamiento actual. Y no nos olvidaremos de comprobar la disponibilidad de los datos necesarios en el estado seleccionado.
A diferencia de los modelos predictivos, necesitaremos más datos de entrada para entrenar la política. Y después de extraer la descripción del estado del entorno, recopilaremos la información sobre el balance y las posiciones abiertas en el momento analizado a partir de los datos del búfer de reproducción de experiencias.
//--- Account bAccount.Clear(); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); //--- double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!!bAccount.GetOpenCL()) { if(!bAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Añadiremos una marca temporal sobre el estado analizado a la información del estado de la cuenta.
Usando como base la información recopilada, realizaremos una pasada directa de los modelos de codificación predictiva, así como una cascada de módulos de atención, para transformar así los resultados de la codificación predictiva en un solo subespacio.
//--- Generate Latent state if(!RelateEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !ShortEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !ShortDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(ShortEncoder)) || !LongEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !LongDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(LongEncoder)) || !LongShort.feedForward(GetPointer(LongDecoder), -1, GetPointer(ShortDecoder), -1) || !PredictRelate.feedForward(GetPointer(LongShort), -1, GetPointer(RelateEncoder), -1) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Tenga en cuenta que en esta etapa no realizaremos la pasada directa del Decodificador del modelo de búsqueda de interdependencias, ya que este modelo no se utilizará durante el entrenamiento de políticas ni durante la explotación del modelo.
A continuación, optimizaremos los parámetros del Crítico para minimizar el error en la evaluación de las acciones del Agente. Para ello, tomaremos de la base de reproducción de experiencias las acciones reales del Agente en el estado seleccionado y realizaremos una pasada directa del Crítico.
//--- Critic target.Assign(Buffer[tr].States[i].action); target.Clip(0, 1); bActions.AssignArray(target); if(!!bActions.GetOpenCL()) if(!bActions.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } Critic.TrainMode(true); if(!Critic.feedForward(GetPointer(PredictRelate), -1, (CBufferFloat*)GetPointer(bActions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A partir de los resultados de la pasada directa del Crítico, obtendremos una valoración de las acciones, que en la etapa inicial será prácticamente un valor aleatorio. Sin embargo, para las acciones reales realizadas por el Agente mientras recopila trayectorias, la recompensa real recibida del entorno se almacenará en el búfer de reproducción de experiencias. Por lo tanto, podemos entrenar al Crítico minimizando el error entre la recompensa prevista y la real.
Luego extraeremos la recompensa real del búfer de reproducción de experiencias y realizaremos una pasada inversa del Crítico.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CBufferFloat *)GetPointer(bActions), (CBufferFloat *)GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A continuación pasaremos directamente al entrenamiento de la política de comportamiento del Actor. Usando como base los datos de entrada recopilados, realizaremos una pasada directa en el Actor para generar un tensor de acción dentro de la política actual.
//--- Actor Policy if(!Actor.feedForward(GetPointer(PredictRelate), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Y luego evaluaremos directamente las acciones formadas con la ayuda del Crítico.
Critic.TrainMode(false); if(!Critic.feedForward(GetPointer(PredictRelate), -1, (CNet*)GetPointer(Actor), -1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Tenga en cuenta que en el proceso de optimización de la política de comportamiento del Actor, deshabilitaremos el modo de aprendizaje para el Crítico. Esto nos permitirá pasar el gradiente de error al Actor sin cambiar los parámetros del Crítico para datos irrelevantes.
El entrenamiento de la política del Actor lo realizaremos en dos etapas. En la primera, verificaremos la efectividad de las acciones reales desde el búfer de reproducción de experiencias. Y al recibir una recompensa positiva, minimizaremos el error entre el tensor de acción previsto y el real. De esta manera enseñaremos políticas rentables en un estilo de aprendizaje supervisado.
if(result.Sum() >= 0) if(!Actor.backProp(GetPointer(bActions), (CBufferFloat*)GetPointer(bAccount), GetPointer(bGradient)) || !PredictRelate.backPropGradient(GetPointer(RelateEncoder), -1, -1, false) || !LongShort.backPropGradient(GetPointer(ShortDecoder), -1, -1, false) || !ShortDecoder.backPropGradient((CNet *)GetPointer(ShortEncoder), -1, -1, false) || !ShortEncoder.backPropGradient((CBufferFloat*)NULL) || !LongDecoder.backPropGradient((CNet *)GetPointer(LongEncoder), -1, -1, false) || !LongEncoder.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Tenga en cuenta que al entrenar la política de Actor, propagaremos el gradiente de error hasta el nivel de los modelos de predicción. De esta manera, estos se afinarán para resolver el problema real de optimización de la política de comportamiento del Actor.
En la segunda etapa, la política de comportamiento del Actor se optimizará propagando el gradiente de error desde el Crítico. Aquí realizaremos ajustes a la política, independientemente de la efectividad de las acciones reales del Agente durante la interacción con el entorno, ya que nos basaremos en la evaluación del Crítico de las acciones de la política de comportamiento actual. Para ello, tomaremos la puntuación de la acción y la mejoraremos en un 1%.
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); }
Pasaremos la recompensa ajustada de esta manera al Crítico como objetivo y realizaremos su pasada inversa con el gradiente de error transmitido al Actor. Como resultado de esta operación, esperamos obtener al nivel de los resultados del modelo Actor un gradiente de error dirigido a aumentar la rentabilidad de las acciones.
if(!Critic.backProp(Result, (CNet *)GetPointer(Actor), LatentLayer) || !Actor.backPropGradient((CBufferFloat*)GetPointer(bAccount), GetPointer(bGradient)) || !PredictRelate.backPropGradient(GetPointer(RelateEncoder), -1, -1, false) || !LongShort.backPropGradient(GetPointer(ShortDecoder), -1, -1, false) || !ShortDecoder.backPropGradient((CNet *)GetPointer(ShortEncoder), -1, -1, false) || !ShortEncoder.backPropGradient((CBufferFloat*)NULL) || !LongDecoder.backPropGradient((CNet *)GetPointer(LongEncoder), -1, -1, false) || !LongEncoder.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
El gradiente de error resultante se distribuirá entre todos los modelos, de forma similar a la primera etapa del entrenamiento.
A continuación, solo necesitaremos informar al usuario sobre el progreso del proceso de entrenamiento y pasar a la siguiente iteración del ciclo.
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Después de completar todas las iteraciones del ciclo de entrenamiento, al igual que en la primera etapa del mismo, eliminaremos el campo de comentarios en el gráfico del instrumento, enviaremos los resultados del entrenamiento al registro e inicializaremos el proceso de finalización del programa.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Cabe decir que el ajuste de los algoritmos de los programas ha influido no solo en los asesores de entrenamiento de modelos, sino también en los expertos de interacción con el entorno. Sin embargo, el volumen de ajustes del algoritmo de los programas de interacción con el entorno será en muchos aspectos idéntico a la implementación de la pasada directa del Actor presentada anteriormente. Por lo tanto, no nos detendremos ahora en un análisis detallado de los algoritmos de estos programas. Le sugiero que los estudie por su cuenta. El código completo de todos los programas usados en la preparación de este artículo se presenta en el archivo adjunto al artículo.
Simulación
Hoy hemos finalizado un camino bastante largo en la implementación de los enfoques del framework StockFormer utilizando MQL5. Y hemos llegado a la etapa final de nuestro trabajo: el entrenamiento de los modelos y la evaluación de los resultados obtenidos en datos históricos reales.
Ya mencionamos antes que para la primera etapa de entrenamiento de los modelos predictivos hemos utilizado una muestra de entrenamiento recopilada en el marco de trabajos anteriores. Permítame recordarle que la muestra de entrenamiento utilizada contiene pasadas de datos históricos reales del instrumento EURUSD para todo el año 2023 y el marco temporal H1. Los parámetros de todos los indicadores analizados se han usado por defecto.
En la etapa de entrenamiento de modelos predictivos, solo se utilizan datos históricos que describen el estado del entorno que no dependan del comportamiento del Agente. Esto nos permite entrenar los modelos especificados sin tener que actualizar el conjunto de entrenamiento. El proceso de entrenamiento de modelos se repetirá hasta que se corrijan los errores dentro de un rango estrecho.
La segunda etapa del entrenamiento (la optimización de la política de comportamiento del Actor) se realizará de forma iterativa, con la actualización periódica de la muestra de entrenamiento para actualizarla en el área de la política de comportamiento actual.
Probaremos el rendimiento del modelo entrenado en el simulador de estrategias MetaTrade 5 utilizando datos históricos de enero de 2024. El periodo inmediatamente posterior a los datos de la muestra de entrenamiento. Ahora le presentamos los resultados de las pruebas.
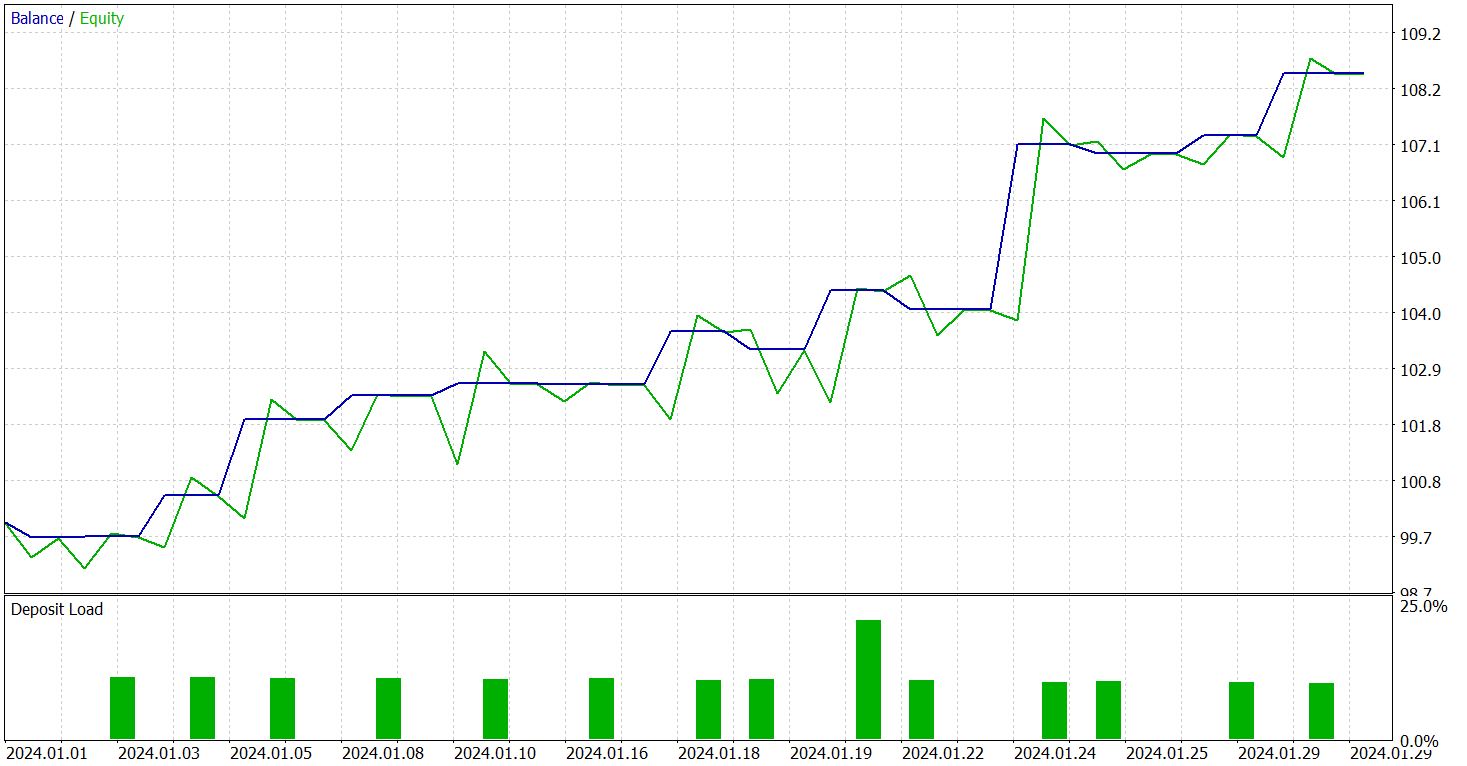
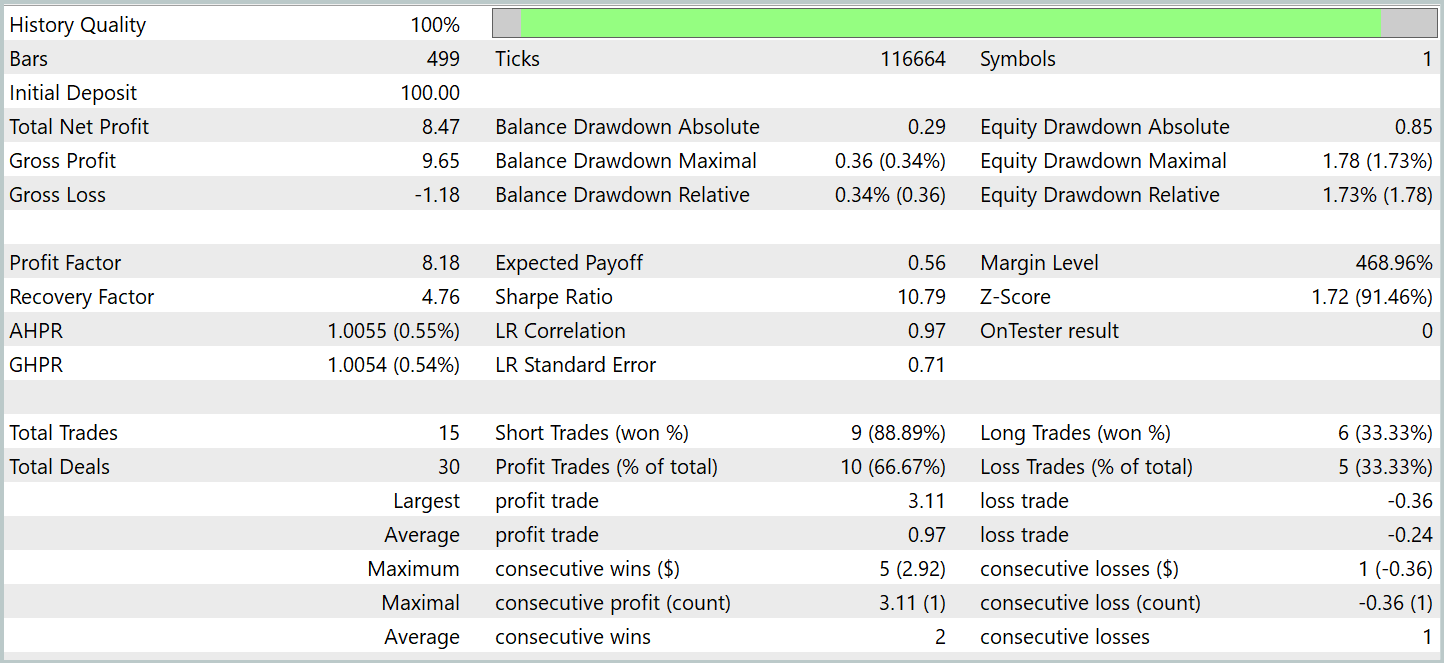
Como se desprende de los datos presentados, durante el periodo de prueba el modelo ha realizado 15 transacciones comerciales. Y 10 de ellas se han cerrado con un beneficio que ha ascendido a más del 66%. No es un mal resultado Especialmente considerando que la transacción rentable promedio es 4 veces mayor que la transacción perdedora promedio. Como resultado, vemos una clara tendencia hacia el crecimiento de los depósitos en el gráfico de balance.
Conclusión
En estos dos artículos hemos analizado el framework StockFormer, que ofrece un enfoque innovador para enseñar estrategias comerciales en los mercados financieros. El StockFormer combina codificación predictiva y técnicas de aprendizaje de refuerzo profundo para realizar el entrenamiento de políticas altamente flexibles que consideran las dependencias dinámicas entre múltiples activos y predicen su comportamiento tanto a corto como a largo plazo.
La codificación predictiva de las tres ramas del StockFormer permite la extracción de representaciones latentes que reflejen las tendencias a corto plazo, los cambios a largo plazo y las relaciones entre activos. La integración de estas representaciones se logra a través de un mecanismo de atención multicabeza en cascada, que asegura la creación de un único espacio de estados para optimizar las decisiones comerciales.
En la parte práctica hemos implementado los componentes clave del framework utilizando MQL5. Luego hemos entrenado los modelos y los hemos probado con datos históricos reales. Los resultados experimentales confirman la eficacia de los enfoques propuestos. Sin embargo, para aplicar los modelos en el comercio real, deberemos entrenarlos con una muestra más grande de datos históricos y someterlos a pruebas más exhaustivas.
Enlaces
Programas utilizados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study1.mq5 | Asesor | Asesor de entrenamiento de aprendizaje predictivo |
| 4 | Study2.mq5 | Asesor | Asesor de entrenamiento de políticas |
| 5 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 6 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura de los modelos |
| 7 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16713
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso