
From Basic to Intermediate: Struct (I)

Introduction
In the previous article, From Basic to Intermediate: Template and Typename (V), we talked about templates and how we could use them to implement various types of solutions with increasingly less effort.
The less effort we need to put in, the more productive we become when developing different solutions. So, I believe you, my dear reader, must be eager to start creating things that are meant to be placed on the chart. We want to generate visible results, rather than simply watch information being printed in the terminal, as we have been doing up until now.
However (and this is where things begin to take shape) everything that we have seen so far has allowed us to establish a solid foundation of knowledge. This ensures that many things can be created and implemented with relatively small effort. Nevertheless, even though this conceptual foundation has been built and well structured, I still do not believe it is time to start coding things that directly interact with the chart. Not because of potential coding conditions, but because we still lack the means to properly structure certain information in a real implementation.
Thus, we need to introduce a new concept. And this concept will allow us to achieve an enormous number of things. We will have an actual mechanism that is safe and reliable, enabling us to work faster while requiring less effort. As we apply everything we've learned so far - plus what we will soon explore - we will avoid a lot of basic and annoying errors. This will make the articles more dynamic in terms of the material and explanations. And this, indeed, will make things far more interesting.
So, get comfortable and come with me as we explore and understand this new concept. In my view, it is a turning point, as it gives us far more possibilities for programming and a better understanding of how to work with MQL5. Let's begin properly by introducing a new topic.
Structures
One of the most interesting things we will explore in this initial, basic phase of MQL5 programming is structures. If you truly understand them properly, you will be able to understand everything else. Literally. The concept of a structure lies somewhat halfway between simple programming, where we merely create variables and procedures, and a completely different paradigm, where we organize code into fully functional blocks. These blocks are object classes. But that will be discussed later, after we explore and understand the concept of structures.
One of the greatest mistakes beginner programmers make is trying to learn things the hard way. They imagine they can implement something without truly understanding how and why a given feature or tool is necessary. No tool or feature in a programming language exists merely because it looks good or attractive. It is there because the compiler developers saw a need for that tool or feature to exist in the language.
Throughout these articles, I will mention features that exist in C and C++ but were not implemented in MQL5, even though MQL5 is largely based on both. I believe the reason these features were not included in MQL5 is simply that they are not necessary. In some cases, it may also be due to the complexity associated with the correct use of certain features, especially in C++, that confuse and complicate code far more than they help within the scope of what MQL5 is intended to do. Remember that MQL5 is designed to enable us to build tools for financial market operations using MetaTrader 5, whereas C++ aims to support the construction of any type of application: from operating systems to autonomous or non-autonomous processes and applications.
For example, you can build anything using C and C++, even a platform equivalent to MetaTrader 5. However, the amount of work required for that would be enormous. It is far simpler and more practical to use something that already exists, such as MQL5. But to create things with a higher level of complexity using MQL5, we need more advanced tools and features. The first of these advanced resources we will use is structures. Without them, we could still produce something interesting, but the level of difficulty would be overwhelmingly higher.
Structures can take on and contain a very high level of complexity - much greater than you might be imagining. However, we will start slowly, showing things step by step so that you can understand how structures actually work. Believe me, you will be surprised by the level of complexity they can reach. And even so, they still cannot handle certain situations. Because of this, another type of structure was created, and to distinguish it from regular structures, it received a special name: classes. But this will be considered in more detail in future articles.
So, let us start with a very simple and basic structure. This first example can be seen below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. struct st_01 07. { 08. short value_01; 09. int value_02; 10. double value_03; 11. }; 12. 13. st_01 Info; 14. 15. Info.value_01 = -8096; 16. Info.value_02 = 78934; 17. Info.value_03 = 1e4 + 0.674; 18. 19. PrintFormat("Result of the sum of all values. %f", Info.value_01 + Info.value_02 + Info.value_03); 20. } 21. //+------------------------------------------------------------------+
Code 01
Code 01 is a very simple piece of code where we begin to see how a structure is built. Notice that the way we create a structure is quite similar to how we create a union. However, there is a major difference between the two. A union is created such that all elements inside it occupy the same memory region.
A structure, on the other hand, is created and designed so that each element within it is individual. In other words, a structure behaves somewhat like a complex variable type, capable of holding multiple elements to form that variable. This is not a perfect definition of what a structure really is.
However - and this is important for you to understand, my dear reader - this initial definition or conceptualization of a structure is indeed a proper way to think about them, as it simplifies understanding many of their properties. So for now, take this as your working concept of a structure:
A structure is a way of grouping several variables that are somehow correlated with each other.
As we advance through our study of structures, you will understand that this concept extends considerably, taking on different "personalities", which grants us great creative freedom while making it increasingly simple to implement very complicated things.
But let us return to our initial code, seen in Code 01. Observe that on line six we are declaring a structure. Just like unions, here in MQL5 it is not possible to define an anonymous structure, so we must give it a name. Since this is our first contact with the concept, I am using an approach similar to what I did when explaining unions. That is, we declare the structure on one line, and later declare the variable that will use that structure on another line. In this case, the variable declaration is on line 13. Note how similar this is to the union examples.
Then, from lines 15 to 17, we assign values to each element of the structure. As you can see, this is very similar to assigning values to any ordinary variable. These are all basic elements. Then, on line 19, we print a message to the terminal. This line will produce what is shown in the image below.

Figure 01
As a first contact, I believe you were able to understand very well what is happening here. Most of it has already been explained previously. Only line 06, being what it is, might cause some doubt or hesitation. However, once you understand that a structure is essentially equivalent to a union in terms of how it is declared, everything else becomes much easier to understand. Knowledge expands over time.
Alright, that was easy. However, before we move on to something a bit more elaborate, there are some rules we must observe when using structures. I will explain them gradually, since some may not make much sense at this moment.
The first rule is:
In MQL5, a structure can NEVER be CONSTANT. It will ALWAYS be a variable.
This means that you cannot declare a structure as a constant in MQL5. This is because we must first declare the label that we will use to access the data within the structure before we can access that data. That is, the line 13 seen in Code 01 must exist before we can use the structure in any way.
Since declaring a constant requires that its value be defined at the moment of declaration, it is not possible to create a constant structure in MQL5.
The second rule is:
The order in which elements are declared inside a structure determines their order in memory.
This rule is very important, especially when using structures in a specific way. But let us take it slowly. First, let us understand something before applying rule number two. When we define a union, the amount of bytes required to store it equals the size of its largest member.
However, with structures, things are slightly different. To understand this, let us reuse Code 01 and examine how much memory we need. To make things clearer and to help you understand the difference between how a structure and a union are laid out in memory, we will add a union with the same elements and types. This gives us the code shown below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. struct st_01 07. { 08. short value_01; 09. int value_02; 10. double value_03; 11. }; 12. 13. union un_01 14. { 15. short value_01; 16. int value_02; 17. double value_03; 18. }; 19. 20. PrintFormat("Size of struct is: [%d bytes]\nSize of union is: [%d bytes]", sizeof(st_01), sizeof(un_01)); 21. } 22. //+------------------------------------------------------------------+
Code 02
Observe here, that in Code 02 we have two different constructions, yet containing the same elements and types. However, despite this, both occupy different amounts of memory in terms of bytes. And this can be seen by looking at the result shown in Image 02 below.
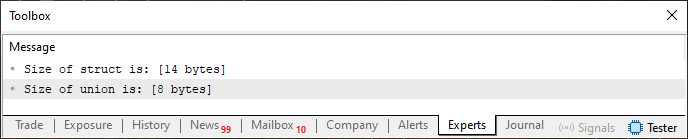
Figure 02
Notice that the union requires eight bytes, since the largest type present in it is the double type, which (as we already know) requires 8 bytes to be represented. The structure, however, which contains the same elements, requires fourteen bytes. This is because we must sum the eight bytes of the double type with the four bytes of the int type and the two bytes of the short type, totaling the fourteen bytes shown. But now let us understand what rule two is telling us. For that, we need to modify Code 02 again, resulting in the next code shown below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. struct st_01 09. { 10. short value_01; 11. int value_02; 12. double value_03; 13. }; 14. 15. struct st_02 16. { 17. short value_01; 18. int value_02; 19. double value_03; 20. }; 21. 22. union un_01 23. { 24. st_01 data_01; 25. st_02 data_02; 26. }; 27. 28. un_01 Info; 29. 30. ZeroMemory(Info); 31. Info.data_01.value_01 = -18254; 32. 33. PrintX(Info.data_02.value_01); 34. } 35. //+------------------------------------------------------------------+
Code 03
Here in Code 03, we have a construction that will allow us to understand rule 02. Pay very close attention to what will be done here, my dear reader, as this will help you immensely in the future. In this example we have two structures being declared. Both are exactly IDENTICAL, both in the number and quantity of elements, as well as the data type of each element. However, the important part is that the declaration order of the elements is exactly the same. This is the most important point here.
To make things understandable, we use a union on line 22. This union links the two structures so that all elements share the same memory space. You already know this, don't you, my dear reader? Now pay attention. On line 30, I instruct the compiler to completely clear the memory region where the union is located. In other words, that entire region now contains only zeros.
On line 31, we assign a value to one of the variables present in the structure. It can be any. But notice that we are doing this by using the union as a reference point. In our case, we are assigning a value to a variable declared in the structure defined on line 08. To test what is happening, we use line 33 to print the value of that same variable. However, in this case, the variable we read is the one found in structure 02, defined on line 15. Since both structures share the same block of memory, obviously the value should be the same.
Thus, executing Code 03, you can observe the result shown below.
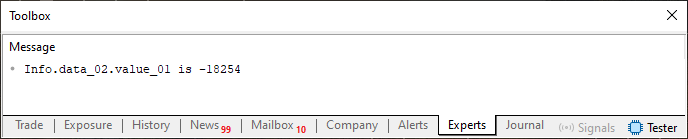
Figure 03
Hmm. Nothing abnormal here, since the displayed value is exactly the same as the one we assign to the variable on line 31. Everything seems correct. You might even be questioning me: Why did you mention rule number two if there was no change at all? What you said makes no sense whatsoever.
Well, I was mistaken - there is indeed no problem being created here. But now let us perform another test. This time we will use a different code so we can visualize everything happening in memory. For this, let us modify Code 03 into another version, shown below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. struct st_01 09. { 10. short value_01; 11. int value_02; 12. double value_03; 13. }; 14. 15. struct st_02 16. { 17. short value_01; 18. int value_02; 19. double value_03; 20. }; 21. 22. union un_01 23. { 24. st_01 data_01; 25. st_02 data_02; 26. uchar arr[sizeof(st_01)]; 27. }; 28. 29. un_01 Info; 30. 31. ZeroMemory(Info); 32. Info.data_01.value_01 = -18254; 33. 34. ArrayPrint(Info.arr); 35. 36. PrintX(Info.data_02.value_01); 37. } 38. //+------------------------------------------------------------------+
Code 04
Great. Now we have a code that lets us actually visualize what is happening in the memory region referenced by the variable Info. When executing Code 04, you will see the image below.
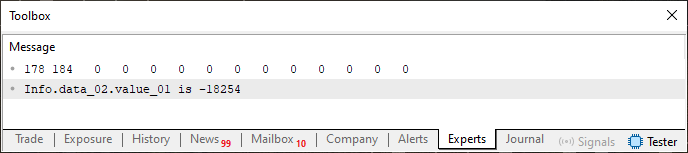
Figure 04
And again, everything behaves as expected. Since Code 04 uses concepts already explained, I will not go into detail regarding what is being done there. But - and here is where things get truly interesting - we will take Code 04 and change one single, tiny detail. This detail is shown in the fragment below.
. . . 15. struct st_02 16. { 17. int value_02; 18. short value_01; 19. double value_03; 20. }; . . .
Fragment 01
Having applied the change shown in Fragment 01 to Code 04, we compile it again and run it in the MetaTrader 5 terminal. You might think that this change wouldn't affect anything - not the content, nor the result when we run the code. But since you insist, I'll try it, just to prove you wrong. So you execute the code and obtain the result shown in Image 05 below.
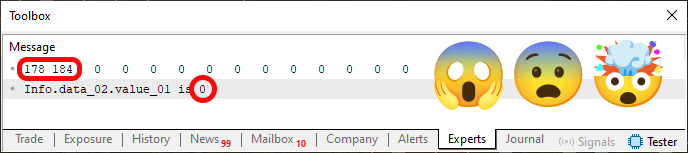
Figure 05
What kind of odd thing is that? How is this even possible? Oh, I know: it's a bug. Or rather, you're manipulating the image. This is some kind of prank in the Figure 05, you're trying to trick me. You thought I wouldn't notice? Wrong. Well, my dear reader, this is NOT a prank. You can easily reproduce this by inserting Fragment 01 into Code 04. But why, despite the memory content remaining unchanged, did we get a different value when reading the variable? The reason is that we are NOT reading the variable itself, but we are reading the memory position where it is being interpreted.
This may seem somewhat strange and even counterintuitive. After all, in Code 04 both Structure 01 and Structure 02 have the same data types, along with variables of the same names. Given that we are using a union to "simulate" a file-mapped region, it makes no sense that the value could change simply by moving a variable within the structure declaration.
However - and here is where the importance of rule number two truly lies - you must temporarily ignore the fact that we are executing code in memory. You must start thinking about this at a larger scale. Consider the following fact: when we save a file, we store information in a specific logical sequence. But often it is in our interest to store and load data according to a logical structure.
You can see this in image file formats, for example. At the beginning of such a file, we have what is known as a header. The data present there belong to a data structure. You can read this data in two ways: one value at a time, or by using a structure specifically designed for this purpose.
To help you understand, let us take the simplest example of a data structure: the well-known Bitmap format. When a bitmap image is stored or must be read from disk, the beginning of the file contains a structure composed of a sequence of fields. This sequence, which is in fact a structure, tells us how the image is formed, what type of image it contains, what structure is being used to model the image, its dimensions, and many other things.
Since the file format follows a specific layout, you can use the information in the BMP File Format specification to reproduce the image however you wish. Likewise, you can manipulate the data stored there. But the important point and the reason understanding rule number two is essential is this: if you are implementing an application that saves data to disk, and later decide to change the structure you originally created, thinking it might be better organized in a different way, you may run into problems when trying to recover previously saved data. This happens because the positions of the variables have changed over time.
This is why it is important for you to understand the concept that structures must be designed with their final purpose in mind. If the intention is to keep everything only in memory, perhaps you will not need to modify the data nor worry about declaration order. However, if the goal is to transfer information between different points or to store information for future use, then you should create some mechanism to version your structure. This way, as you change things, you also change the structure's version. If everything is well planned and maintained, you will still be able to read very old stored data using a much more recent structure version.
Perhaps what I am explaining here may not make much sense at this early stage. Before thinking about data modeling, we still need to understand and study other concepts directly related to structures.
But to make things a bit more interesting, and for you to really understand what I am trying to show, let us perform a small experiment. It is not complex. Actually, it's quite simple. And with all the concepts we've covered so far, you will be able to understand it without difficulty. Look at the code below.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+----------------+ 06. #define def_FileName "Testing.bin" 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. struct st_01 11. { 12. short value_01; 13. int value_02; 14. double value_03; 15. }Info; 16. 17. int handle; 18. 19. ZeroMemory(Info); 20. 21. PrintFormat("Size of struct is %d bytes", sizeof(Info)); 22. 23. if ((handle = FileOpen(def_FileName, FILE_READ | FILE_BIN)) != INVALID_HANDLE) 24. PrintFormat("Reading %d bytes of file data.", FileReadStruct(handle, Info)); 25. else 26. { 27. Info.value_01 = -8096; 28. Info.value_02 = 78934; 29. Info.value_03 = 1e4 + 0.674; 30. 31. PrintFormat("Writing %d bytes of data in the file.", FileWriteStruct(handle = FileOpen(def_FileName, FILE_WRITE | FILE_BIN), Info)); 32. } 33. FileClose(handle); 34. 35. PrintX(Info.value_01); 36. PrintX(Info.value_02); 37. PrintX(Info.value_03); 38. } 39. //+------------------------------------------------------------------+
Code 05
When the code is executed, the terminal will display what we see below.
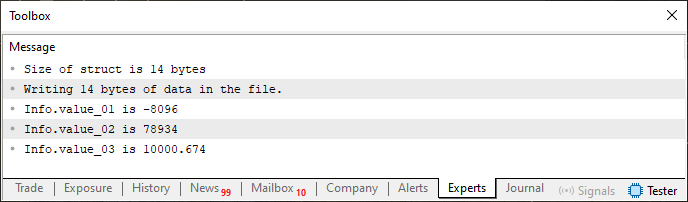
Figure 06
You can see that here we are writing to the file first, since it did not previously exist. If you are curious, you can open the file using a hexadecimal editor. In that case, you will see what is shown in the next image.

Figure 07
This is the same kind of content that would be present in memory if you were using a union to inspect the region. But forget this for now, as it is not particularly important at this exact moment. What matters here is the following: when you execute Code 05 again without modifying it or deleting or altering the file contents shown in Figure 07 - you will obtain in the MetaTrader 5 terminal what is shown below.
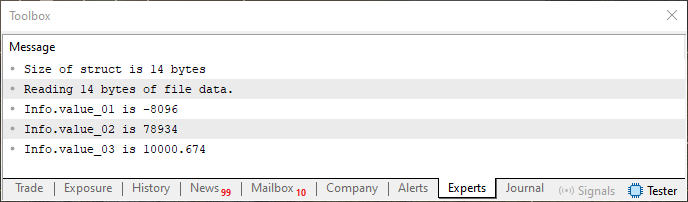
Figure 08
Clearly, you see that it is the same information. Now I suggest you simply change the order of the variables in the structure declared on line ten of Code 05. Without touching anything else, recompile the code and run it. Compare the previous results, shown in earlier images, with the result displayed in the terminal when Code 05 is executed again with the changed variable order. Reflect on what happened and compare it with what we observed when using a union to perform the same type of analysis.
Even though we have not yet formally discussed file reading and writing, Code 05, which will be available in the attachment, is very simple. It can be easily understood based on what has been explained so far in these articles. The only parts that might raise questions can be perfectly clarified by reading the documentation, specifically the library functions: FileOpen, FileWriteStruct, FileReadStruct, and FileClose. But even these are easy to understand, requiring no additional comments for a complete understanding of what was shown here.
Final Thoughts
This was our first article on structures in MQL5. To begin correctly, we must understand various concepts that apply to structures. I know this first contact may not have been particularly exciting. However, you must have noticed that it is absolutely necessary to understand what was explained in previous articles. Without those concepts properly absorbed, understanding what we are beginning to do here would be far more difficult and confusing.
For this reason, it is essential to practice and strive to understand what is being done and the results being produced. In any case, use the attached files to practice this first contact, focusing on understanding the two rules demonstrated in this article. They will be extremely important very soon.
Translated from Portuguese by MetaQuotes Ltd.
Original article: https://www.mql5.com/pt/articles/15730
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use