
Von der Grundstufe bis zur Mittelstufe: Struct (I)

Einführung
Im vorigen Artikel, Von der Grundstufe zur Mittelstufe: Template und Typenname (V), haben wir über Templates (Vorlagen) gesprochen und darüber, wie wir sie nutzen können, um verschiedene Arten von Lösungen mit immer weniger Aufwand zu realisieren.
Je weniger Aufwand wir betreiben müssen, desto produktiver werden wir bei der Entwicklung verschiedener Lösungen. Ich glaube, Sie, liebe Leserin, lieber Leser, sind sicher begierig darauf, Dinge zu erschaffen, die auf der Chart platziert werden sollen. Wir wollen sichtbare Ergebnisse erzielen und nicht nur zusehen, wie die Informationen im Terminal ausgedruckt werden, wie wir es bisher getan haben.
Aber (und hier beginnen die Dinge Gestalt anzunehmen) alles, was wir bisher gesehen haben, hat es uns ermöglicht, ein solides Fundament an Wissen zu schaffen. Dadurch ist gewährleistet, dass viele Dinge mit relativ geringem Aufwand erstellt und umgesetzt werden können. Aber auch wenn diese konzeptionelle Grundlage geschaffen und gut strukturiert ist, ist es meiner Meinung nach noch nicht an der Zeit, mit der Programmierung von Dingen zu beginnen, die direkt mit dem Chart interagieren. Nicht wegen möglicher Kodierungsbedingungen, sondern weil uns noch die Mittel fehlen, um bestimmte Informationen in einer realen Implementierung richtig zu strukturieren.
Wir müssen also ein neues Konzept einführen. Und mit diesem Konzept können wir eine ganze Menge erreichen. Wir werden über einen sicheren und zuverlässigen Mechanismus verfügen, der es uns ermöglicht, schneller und mit weniger Aufwand zu arbeiten. Wenn wir alles anwenden, was wir bisher gelernt haben – und was wir bald erforschen werden – werden wir viele grundlegende und ärgerliche Fehler vermeiden. Dadurch werden die Artikel in Bezug auf das Material und die Erläuterungen dynamischer. Und das wird die Dinge in der Tat sehr viel interessanter machen.
Machen Sie es sich also bequem und begleiten Sie mich, wenn wir dieses neue Konzept erforschen und verstehen. Meiner Meinung nach ist es ein Wendepunkt, da es uns viel mehr Möglichkeiten für die Programmierung und ein besseres Verständnis für die Arbeit mit MQL5 gibt. Beginnen wir richtig mit der Einführung eines neuen Themas.
Strukturen
Eines der interessantesten Dinge, die wir in dieser ersten, grundlegenden Phase der MQL5-Programmierung erkunden werden, sind Strukturen. Wenn man sie richtig versteht, kann man auch alles andere verstehen. Wörtlich. Das Konzept einer Struktur liegt in etwa auf halbem Weg zwischen der einfachen Programmierung, bei der wir lediglich Variablen und Prozeduren erstellen, und einem völlig anderen Paradigma, bei dem wir Code in voll funktionsfähige Blöcke organisieren. Diese Blöcke sind Objektklassen. Aber darauf werden wir später eingehen, wenn wir das Konzept der Strukturen erforscht und verstanden haben.
Einer der größten Fehler von Programmieranfängern ist, dass sie versuchen, Dinge auf die harte Tour zu lernen. Sie stellen sich vor, dass sie etwas implementieren können, ohne wirklich zu verstehen, wie und warum eine bestimmte Funktion oder ein bestimmtes Werkzeug notwendig ist. Kein Werkzeug und keine Funktion in einer Programmiersprache existiert nur, weil es gut oder attraktiv aussieht. Sie sind vorhanden, weil die Compiler-Entwickler einen Bedarf für dieses Werkzeug oder diese Funktion in der Sprache sahen.
In diesen Artikeln werde ich Funktionen erwähnen, die in C und C++ existieren, aber nicht in MQL5 implementiert wurden, obwohl MQL5 weitgehend auf beiden basiert. Ich glaube, der Grund, warum diese Funktionen nicht in MQL5 aufgenommen wurden, ist einfach, dass sie nicht notwendig sind. In einigen Fällen kann es auch an der Komplexität liegen, die mit der korrekten Verwendung bestimmter Funktionen verbunden ist, insbesondere in C++, die den Code weit mehr verwirren und verkomplizieren, als dass sie im Rahmen dessen, was MQL5 tun soll, hilfreich sind. Denken Sie daran, dass MQL5 für die Entwicklung von Werkzeugen für Finanzmarktoperationen mit MetaTrader 5 konzipiert ist, während C++ die Entwicklung jeder Art von Anwendung unterstützen soll: von Betriebssystemen bis hin zu autonomen oder nicht autonomen Prozessen und Anwendungen.
Sie können zum Beispiel alles mit C und C++ erstellen, sogar eine Plattform, die dem MetaTrader 5 entspricht. Der dafür erforderliche Arbeitsaufwand wäre jedoch enorm. Es ist viel einfacher und praktischer, etwas zu verwenden, das bereits existiert, wie z. B. MQL5. Aber um mit MQL5 komplexere Dinge zu erstellen, brauchen wir fortgeschrittenere Werkzeuge und Funktionen. Die erste dieser fortgeschrittenen Ressourcen, die wir verwenden werden, sind Strukturen. Ohne sie könnten wir zwar immer noch etwas Interessantes produzieren, aber der Schwierigkeitsgrad wäre deutlich höher.
Strukturen können ein sehr hohes Maß an Komplexität annehmen und enthalten – viel mehr, als Sie sich vielleicht vorstellen können. Wir werden jedoch langsam beginnen und die Dinge Schritt für Schritt zeigen, damit Sie verstehen, wie die Strukturen tatsächlich funktionieren. Glauben Sie mir, Sie werden überrascht sein, welchen Grad an Komplexität sie erreichen können. Und trotzdem können sie bestimmte Situationen nicht bewältigen. Aus diesem Grund wurde ein weiterer Strukturtyp geschaffen, der zur Unterscheidung von regulären Strukturen einen besonderen Namen erhielt: Klassen. Dies wird jedoch in künftigen Artikeln ausführlicher behandelt werden.
Lassen Sie uns also mit einer sehr einfachen und grundlegenden Struktur beginnen. Dieses erste Beispiel ist unten zu sehen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. struct st_01 07. { 08. short value_01; 09. int value_02; 10. double value_03; 11. }; 12. 13. st_01 Info; 14. 15. Info.value_01 = -8096; 16. Info.value_02 = 78934; 17. Info.value_03 = 1e4 + 0.674; 18. 19. PrintFormat("Result of the sum of all values. %f", Info.value_01 + Info.value_02 + Info.value_03); 20. } 21. //+------------------------------------------------------------------+
Code 01
Code 01 ist ein sehr einfaches Stück Code, das uns zeigt, wie eine Struktur aufgebaut ist. Beachten Sie, dass die Art und Weise, wie wir eine Struktur erstellen, der Art und Weise, wie wir eine Union erstellen, sehr ähnlich ist. Es gibt jedoch einen großen Unterschied zwischen den beiden. Eine Union wird so erstellt, dass alle Elemente in ihr denselben Speicherbereich belegen.
Eine Struktur hingegen ist so angelegt und gestaltet, dass jedes Element darin individuell ist. Mit anderen Worten, eine Struktur verhält sich ähnlich wie ein komplexer Variablentyp, der mehrere Elemente enthalten kann, um diese Variable zu bilden. Dies ist keine perfekte Definition dessen, was eine Struktur wirklich ist.
Allerdings – und das ist wichtig für Sie, liebe Leserin, lieber Leser – ist diese anfängliche Definition oder Konzeptualisierung einer Struktur in der Tat ein geeigneter Weg, um über sie nachzudenken, da sie das Verständnis vieler ihrer Eigenschaften vereinfacht. Nehmen Sie dies also als Ihr Arbeitskonzept für eine Struktur:
Eine Struktur ist eine Möglichkeit, mehrere Variablen, die in irgendeiner Weise miteinander korreliert sind, zu gruppieren.
Im Laufe unseres Studiums der Strukturen werden Sie verstehen, dass sich dieses Konzept beträchtlich ausdehnt und verschiedene „Persönlichkeiten" annimmt, was uns eine große kreative Freiheit gewährt und es immer einfacher macht, sehr komplizierte Dinge umzusetzen.
Doch kehren wir zu unserem ursprünglichen Code zurück, der in Code 01 zu sehen ist. Beachten Sie, dass wir in Zeile sechs eine Struktur deklarieren. Genau wie bei Unions ist es in MQL5 nicht möglich, eine anonyme Struktur zu definieren, also müssen wir ihr einen Namen geben. Da dies unser erster Kontakt mit dem Konzept ist, verwende ich einen ähnlichen Ansatz wie bei der Erklärung der Gewerkschaften. Das heißt, wir deklarieren die Struktur in einer Zeile und später die Variable, die diese Struktur verwenden wird, in einer anderen Zeile. In diesem Fall befindet sich die Variablendeklaration in Zeile 13. Beachten Sie die Ähnlichkeit mit den Beispielen der Gewerkschaft.
In den Zeilen 15 bis 17 weisen wir dann jedem Element der Struktur Werte zu. Wie Sie sehen, ist dies sehr ähnlich wie die Zuweisung von Werten an eine gewöhnliche Variable. Dies sind alles grundlegende Elemente. Dann, in Zeile 19, geben wir eine Meldung auf dem Terminal aus. Diese Zeile führt zu dem in der folgenden Abbildung gezeigten Ergebnis.

Abbildung 01
Ich glaube, als Erstkontakt konnten Sie sehr gut verstehen, was hier passiert. Das meiste wurde bereits erklärt. Lediglich die Zeile 06 könnte Zweifel und Bedenken hervorrufen. Wenn Sie jedoch einmal verstanden haben, dass eine Struktur in Bezug auf ihre Deklaration im Wesentlichen einer Union entspricht, wird alles andere viel einfacher zu verstehen. Das Wissen erweitert sich mit der Zeit.
Na gut, das war einfach. Bevor wir jedoch zu etwas Ausführlicherem übergehen, müssen wir bei der Verwendung von Strukturen einige Regeln beachten. Ich werde sie nach und nach erläutern, da einige von ihnen im Moment vielleicht noch nicht viel Sinn ergeben.
Die erste Regel lautet:
In MQL5 kann eine Struktur NIEMALS KONSTANT sein. Es wird IMMER eine Variable sein.
Das bedeutet, dass Sie eine Struktur in MQL5 nicht als Konstante deklarieren können. Der Grund dafür ist, dass wir zuerst die Kennzeichnung deklarieren müssen, das wir für den Zugriff auf die Daten innerhalb der Struktur verwenden werden, bevor wir auf diese Daten zugreifen können. Das heißt, die Zeile 13 in Code 01 muss vorhanden sein, bevor wir die Struktur in irgendeiner Weise verwenden können.
Da die Deklaration einer Konstante voraussetzt, dass ihr Wert zum Zeitpunkt der Deklaration definiert ist, ist es in MQL5 nicht möglich, eine Konstantenstruktur zu erstellen.
Die zweite Regel lautet:
Die Reihenfolge, in der die Elemente innerhalb einer Struktur deklariert werden, bestimmt ihre Reihenfolge im Speicher.
Diese Regel ist sehr wichtig, insbesondere bei der Verwendung von Strukturen in einer bestimmten Weise. Aber lassen Sie es uns langsam angehen. Bevor wir Regel Nummer zwei anwenden, müssen wir zunächst etwas verstehen. Wenn wir eine Union definieren, entspricht die Menge an Bytes, die für ihre Speicherung erforderlich ist, der Größe ihres größten Mitglieds.
Bei den Strukturen liegen die Dinge jedoch etwas anders. Um dies zu verstehen, wollen wir Code 01 wiederverwenden und untersuchen, wie viel Speicher wir benötigen. Zur Verdeutlichung und zum besseren Verständnis des Unterschieds zwischen einer Struktur und einer Union im Speicher fügen wir eine Union mit denselben Elementen und Typen hinzu. Daraus ergibt sich der unten stehende Code.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. struct st_01 07. { 08. short value_01; 09. int value_02; 10. double value_03; 11. }; 12. 13. union un_01 14. { 15. short value_01; 16. int value_02; 17. double value_03; 18. }; 19. 20. PrintFormat("Size of struct is: [%d bytes]\nSize of union is: [%d bytes]", sizeof(st_01), sizeof(un_01)); 21. } 22. //+------------------------------------------------------------------+
Code 02
Beachten Sie, dass es sich bei Code 02 um zwei unterschiedliche Konstruktionen handelt, die jedoch die gleichen Elemente und Typen enthalten. Trotzdem belegen beide unterschiedliche Mengen an Speicherplatz in Form von Bytes. Dies wird durch das in Abbildung 02 gezeigte Ergebnis verdeutlicht.
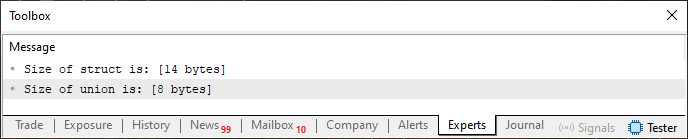
Abbildung 02
Beachten Sie, dass die Union acht Bytes benötigt, da der größte Typ in ihr der Typ double ist, der (wie wir bereits wissen) 8 Bytes zur Darstellung benötigt. Die Struktur, die dieselben Elemente enthält, benötigt jedoch vierzehn Bytes. Das liegt daran, dass wir die acht Bytes des Typs double mit den vier Bytes des Typs int und den zwei Bytes des Typs short zusammenzählen müssen, was insgesamt vierzehn Bytes ergibt. Aber jetzt wollen wir verstehen, was uns die zweite Regel sagt. Zu diesem Zweck müssen wir Code 02 erneut ändern, was zu dem folgenden Code führt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. struct st_01 09. { 10. short value_01; 11. int value_02; 12. double value_03; 13. }; 14. 15. struct st_02 16. { 17. short value_01; 18. int value_02; 19. double value_03; 20. }; 21. 22. union un_01 23. { 24. st_01 data_01; 25. st_02 data_02; 26. }; 27. 28. un_01 Info; 29. 30. ZeroMemory(Info); 31. Info.data_01.value_01 = -18254; 32. 33. PrintX(Info.data_02.value_01); 34. } 35. //+------------------------------------------------------------------+
Code 03
Hier in Code 03 haben wir eine Konstruktion, die es uns ermöglicht, Regel 02 zu verstehen. Achten Sie sehr genau darauf, was hier getan wird, liebe Leserin, lieber Leser, denn das wird Ihnen in Zukunft ungemein helfen. In diesem Beispiel werden zwei Strukturen deklariert. Beide sind genau IDENTISCH sowohl in der Anzahl und Menge der Elemente als auch im Datentyp der einzelnen Elemente. Wichtig ist jedoch, dass die Reihenfolge der Deklaration der Elemente genau die gleiche ist. Dies ist der wichtigste Punkt in diesem Zusammenhang.
Um die Dinge verständlich zu machen, verwenden wir in Zeile 22 eine Vereinigung. Diese Union verbindet die beiden Strukturen, sodass alle Elemente denselben Speicherplatz teilen. Das wissen Sie bereits, nicht wahr, liebe Leserin, lieber Leser? Und jetzt aufgepasst. In Zeile 30 weise ich den Compiler an, den Speicherbereich, in dem sich die Union befindet, vollständig zu löschen. Mit anderen Worten: Die gesamte Region enthält nur noch Nullen.
In Zeile 31 weisen wir einer der in der Struktur vorhandenen Variablen einen Wert zu. Das kann jeder sein. Aber beachten Sie, dass wir dies tun, indem wir die Gewerkschaft als Referenzpunkt verwenden. In unserem Fall weisen wir einer Variablen, die in der in Zeile 08 definierten Struktur deklariert ist, einen Wert zu. Um zu testen, was passiert, verwenden wir Zeile 33, um den Wert der gleichen Variablen zu drucken. In diesem Fall ist die Variable, die wir lesen, diejenige, die sich in der Struktur 02 befindet, die in Zeile 15 definiert ist. Da sich beide Strukturen denselben Speicherblock teilen, sollte der Wert natürlich derselbe sein.
Wenn Sie also Code 03 ausführen, erhalten Sie das unten gezeigte Ergebnis.
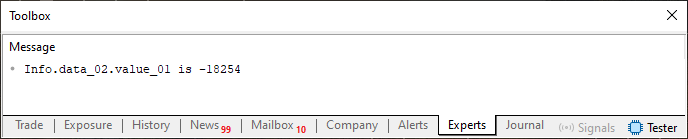
Abbildung 03
Hm. Dies ist nichts Ungewöhnliches, da der angezeigte Wert genau dem entspricht, den wir der Variablen in Zeile 31 zuweisen. Alles scheint korrekt zu sein. Vielleicht stellen Sie mich sogar in Frage: Warum haben Sie Regel Nummer zwei erwähnt, wenn es überhaupt keine Änderung gab? Was Sie gesagt haben, ergibt überhaupt keinen Sinn.
Nun, ich habe mich geirrt – es wird hier tatsächlich kein Problem geschaffen. Doch nun wollen wir einen weiteren Test durchführen. Diesmal werden wir einen anderen Code verwenden, damit wir alles, was im Speicher passiert, visualisieren können. Ändern wir dazu den Code 03 in eine andere Version, wie unten dargestellt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. struct st_01 09. { 10. short value_01; 11. int value_02; 12. double value_03; 13. }; 14. 15. struct st_02 16. { 17. short value_01; 18. int value_02; 19. double value_03; 20. }; 21. 22. union un_01 23. { 24. st_01 data_01; 25. st_02 data_02; 26. uchar arr[sizeof(st_01)]; 27. }; 28. 29. un_01 Info; 30. 31. ZeroMemory(Info); 32. Info.data_01.value_01 = -18254; 33. 34. ArrayPrint(Info.arr); 35. 36. PrintX(Info.data_02.value_01); 37. } 38. //+------------------------------------------------------------------+
Code 04
Großartig. Jetzt haben wir einen Code, mit dem wir tatsächlich sehen können, was in dem Speicherbereich passiert, auf den die Variable Info verweist. Wenn Sie den Code 04 ausführen, sehen Sie das folgende Bild.
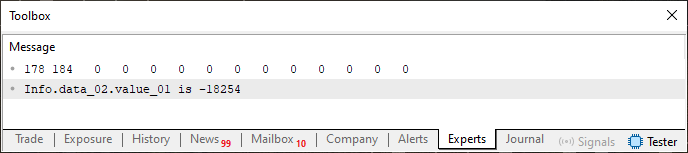
Abbildung 04
Und wieder verhält sich alles wie erwartet. Da Code 04 auf bereits erläuterte Konzepte zurückgreift, werde ich nicht näher darauf eingehen, was dort gemacht wird. Aber – und hier wird es wirklich interessant – wir werden Code 04 nehmen und ein einziges, winziges Detail ändern. Dieses Detail ist in dem nachstehenden Fragment dargestellt.
. . . 15. struct st_02 16. { 17. int value_02; 18. short value_01; 19. double value_03; 20. }; . . .
Fragment 01
Nachdem wir die in Fragment 01 gezeigte Änderung an Code 04 vorgenommen haben, kompilieren wir ihn erneut und führen ihn im MetaTrader 5 Terminal aus. Man könnte meinen, dass sich diese Änderung auf nichts auswirkt – weder auf den Inhalt noch auf das Ergebnis, wenn wir den Code ausführen. Aber da du darauf bestehst, werde ich es versuchen, nur um dir das Gegenteil zu beweisen. Sie führen den Code aus und erhalten das in Abbildung 05 gezeigte Ergebnis.
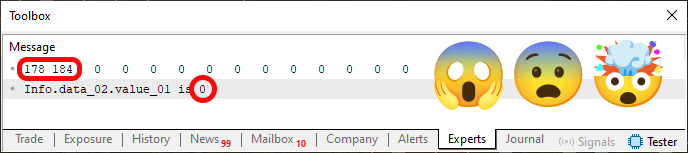
Abbildung 05
Was ist das für eine seltsame Sache? Wie ist das überhaupt möglich? Oh, ich weiß: Es ist ein Fehler. Oder besser gesagt, Sie manipulieren das Bild. Das ist eine Art Streich in der Abbildung 05, du versuchst, mich auszutricksen. Dachten Sie, ich würde es nicht bemerken? Falsch! Nun, mein lieber Leser, dies ist KEIN Streich. Sie können dies leicht nachvollziehen, indem Sie Fragment 01 in Code 04 einfügen. Aber warum erhalten wir beim Lesen der Variablen einen anderen Wert, obwohl der Speicherinhalt unverändert bleibt? Der Grund dafür ist, dass wir NICHT die Variable selbst lesen, sondern die Speicherposition, an der sie interpretiert wird.
Dies mag etwas seltsam und sogar kontraintuitiv erscheinen. Schließlich haben in Code 04 sowohl Struktur 01 als auch Struktur 02 die gleichen Datentypen und Variablen mit den gleichen Namen. Da wir eine Union verwenden, um einen Bereich zu „simulieren", der einer Datei zugeordnet ist, macht es keinen Sinn, dass sich der Wert einfach durch Verschieben einer Variablen innerhalb der Strukturdeklaration ändern könnte.
Allerdings – und hier liegt die eigentliche Bedeutung von Regel Nummer zwei – müssen Sie vorübergehend die Tatsache ignorieren, dass wir den Code im Speicher ausführen. Sie müssen anfangen, darüber in einem größeren Rahmen nachzudenken. Bedenken Sie Folgendes: Wenn wir eine Datei speichern, speichern wir Informationen in einer bestimmten logischen Reihenfolge. Aber oft ist es in unserem Interesse, Daten nach einer logischen Struktur zu speichern und zu laden.
Dies ist zum Beispiel bei Bilddateiformaten zu beobachten. Am Anfang einer solchen Datei steht ein so genannter Header. Die dort vorhandenen Daten gehören zu einer Datenstruktur. Sie können diese Daten auf zwei Arten lesen: einen Wert nach dem anderen oder mit Hilfe einer speziell für diesen Zweck entwickelten Struktur.
Um das zu verstehen, nehmen wir das einfachste Beispiel einer Datenstruktur: das bekannte Bitmap-Format. Wenn ein Bitmap-Bild gespeichert wird oder von der Festplatte gelesen werden muss, enthält der Anfang der Datei eine Struktur, die aus einer Reihe von Feldern besteht. Diese Sequenz, die eigentlich eine Struktur ist, gibt Aufschluss darüber, wie das Bild aufgebaut ist, welche Art von Bild es enthält, welche Struktur zur Modellierung des Bildes verwendet wird, wie groß es ist und vieles mehr.
Da das Dateiformat einem bestimmten Layout folgt, können Sie die Informationen in der Spezifikation des Dateiformats BMP verwenden, um das Bild nach Belieben zu reproduzieren. Ebenso können Sie die dort gespeicherten Daten manipulieren. Aber der wichtige Punkt und der Grund, warum das Verständnis von Regel Nummer zwei so wichtig ist, ist folgender: Wenn Sie eine Anwendung implementieren, die Daten auf der Festplatte speichert, und später beschließen, die ursprünglich erstellte Struktur zu ändern, weil Sie denken, dass sie auf eine andere Art und Weise besser organisiert sein könnte, können Sie Probleme bekommen, wenn Sie versuchen, zuvor gespeicherte Daten wiederherzustellen. Dies geschieht, weil sich die Positionen der Variablen im Laufe der Zeit verändert haben.
Aus diesem Grund ist es wichtig, dass Sie das Konzept verstehen, dass Strukturen mit Blick auf ihren endgültigen Zweck entworfen werden müssen. Wenn die Absicht besteht, alles nur im Speicher zu halten, müssen Sie die Daten vielleicht nicht ändern und sich nicht um die Reihenfolge der Deklarationen kümmern. Wenn das Ziel jedoch darin besteht, Informationen zwischen verschiedenen Punkten zu übertragen oder Informationen für eine spätere Verwendung zu speichern, dann sollten Sie einen Mechanismus zur Versionierung Ihrer Struktur schaffen. Wenn Sie also etwas ändern, ändern Sie auch die Version der Struktur. Wenn alles gut geplant und gewartet wird, können Sie auch sehr alte gespeicherte Daten mit einer viel neueren Strukturversion lesen.
Vielleicht ist das, was ich hier erkläre, in diesem frühen Stadium noch nicht sehr sinnvoll. Bevor wir über die Datenmodellierung nachdenken, müssen wir noch andere Konzepte verstehen und studieren, die direkt mit Strukturen zusammenhängen.
Aber um die Sache ein wenig interessanter zu machen und damit Sie wirklich verstehen, was ich zu zeigen versuche, lassen Sie uns ein kleines Experiment durchführen. Sie ist nicht komplex. Eigentlich ist es ganz einfach. Und mit all den Konzepten, die wir bisher behandelt haben, werden Sie in der Lage sein, sie ohne Schwierigkeiten zu verstehen. Sehen Sie sich den nachstehenden Code an.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+----------------+ 06. #define def_FileName "Testing.bin" 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. struct st_01 11. { 12. short value_01; 13. int value_02; 14. double value_03; 15. }Info; 16. 17. int handle; 18. 19. ZeroMemory(Info); 20. 21. PrintFormat("Size of struct is %d bytes", sizeof(Info)); 22. 23. if ((handle = FileOpen(def_FileName, FILE_READ | FILE_BIN)) != INVALID_HANDLE) 24. PrintFormat("Reading %d bytes of file data.", FileReadStruct(handle, Info)); 25. else 26. { 27. Info.value_01 = -8096; 28. Info.value_02 = 78934; 29. Info.value_03 = 1e4 + 0.674; 30. 31. PrintFormat("Writing %d bytes of data in the file.", FileWriteStruct(handle = FileOpen(def_FileName, FILE_WRITE | FILE_BIN), Info)); 32. } 33. FileClose(handle); 34. 35. PrintX(Info.value_01); 36. PrintX(Info.value_02); 37. PrintX(Info.value_03); 38. } 39. //+------------------------------------------------------------------+
Code 05
Wenn der Code ausgeführt wird, zeigt das Terminal das untenstehende Ergebnis an.
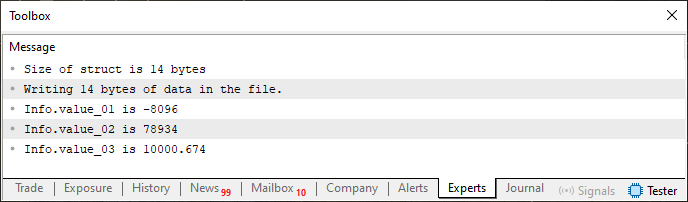
Abbildung 06
Sie können sehen, dass wir hier zuerst in die Datei schreiben, da sie vorher nicht existierte. Wenn Sie neugierig sind, können Sie die Datei mit einem Hexadezimal-Editor öffnen. In diesem Fall werden Sie sehen, was in der nächsten Abbildung dargestellt ist.

Abbildung 07
Dies ist die gleiche Art von Inhalt, die im Speicher vorhanden wäre, wenn Sie eine Union zur Überprüfung der Region verwenden würden. Aber vergessen Sie das erst einmal, denn es ist im Moment nicht besonders wichtig. Hier geht es um Folgendes: Wenn Sie Code 05 erneut ausführen, ohne ihn zu modifizieren oder den Inhalt der in Abbildung 07 gezeigten Datei zu löschen oder zu verändern, erhalten Sie im MetaTrader 5-Terminal das unten abgebildete Ergebnis.
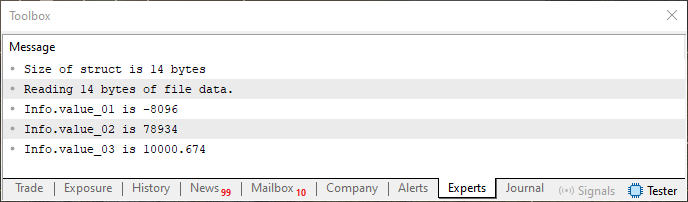
Abbildung 08
Sie sehen also, dass es sich um dieselben Informationen handelt. Jetzt schlage ich vor, dass Sie einfach die Reihenfolge der Variablen in der in Zeile 10 von Code 05 deklarierten Struktur ändern. Kompilieren Sie den Code neu und führen Sie ihn aus, ohne etwas anderes zu verändern. Vergleichen Sie die vorherigen Ergebnisse, die in früheren Bildern gezeigt wurden, mit dem Ergebnis, das im Terminal angezeigt wird, wenn Code 05 erneut mit der geänderten Variablenreihenfolge ausgeführt wird. Überlegen Sie, was passiert ist, und vergleichen Sie es mit dem, was wir beobachtet haben, als wir die gleiche Art von Analyse mit einer Gewerkschaft durchgeführt haben.
Obwohl wir noch nicht offiziell über das Lesen und Schreiben von Dateien gesprochen haben, ist der Code 05, der im Anhang zu finden sein wird, sehr einfach. Es ist leicht zu verstehen, wenn man sich die bisherigen Ausführungen in diesen Artikeln vor Augen führt. Die einzigen Teile, die Fragen aufwerfen könnten, können durch Lesen der Dokumentation, insbesondere der Bibliotheksfunktionen, perfekt geklärt werden: FileOpen, FileWriteStruct, FileReadStruct und FileClose. Aber auch diese sind leicht zu verstehen und bedürfen keines zusätzlichen Kommentars, um das hier Gezeigte vollständig zu verstehen.
Abschließende Überlegungen
Dies war unser erster Artikel über Strukturen in MQL5. Um richtig zu beginnen, müssen wir verschiedene Konzepte verstehen, die für Strukturen gelten. Ich weiß, dass dieser erste Kontakt vielleicht nicht besonders aufregend war. Sie werden jedoch bemerkt haben, dass es absolut notwendig ist, zu verstehen, was in den vorherigen Artikeln erklärt wurde. Ohne diese Konzepte richtig verinnerlicht zu haben, wäre das Verständnis dessen, was wir hier zu tun beginnen, viel schwieriger und verwirrender.
Aus diesem Grund ist es wichtig, zu üben und sich zu bemühen, zu verstehen, was getan wird und welche Ergebnisse erzielt werden. Verwenden Sie auf jeden Fall die beigefügten Dateien, um diesen ersten Kontakt zu üben, und konzentrieren Sie sich dabei auf das Verständnis der beiden in diesem Artikel vorgestellten Regeln. Sie werden schon sehr bald sehr wichtig sein.
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15730
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.