
从基础到中级:结构(一)

概述
在上一篇文章,从基础到中级:模板和类型名称 (五)中,我们讨论了模板,以及如何使用模板以越来越少的精力来实现各种类型的解决方案。
我们需要付出的努力越少,在开发各种解决方案时效率就越高。所以,我相信,亲爱的读者,你一定渴望开始创造那些应该放在图表上的东西。我们希望生成可见的结果,而不是像我们迄今为止所做的那样,只是看着信息在终端中打印出来。
然而(这就是事情开始成形的地方),到目前为止,我们所看到的一切都让我们建立了坚实的知识基础。这确保了可以用相对较小的努力创建和实现许多东西。然而,尽管这个概念基础已经建立并结构良好,但我仍然认为现在还不是开始编码与图表直接交互的内容的时候。不是因为潜在的编码条件,而是因为我们仍然缺乏在实际实现中正确构建某些信息的方法。
因此,我们需要引入一个新概念。这一概念将使我们能够实现许多目标。我们将拥有一个安全可靠的实际机制,使我们能够更快地工作,同时需要更少的努力。当我们应用到目前为止所学到的一切,以及我们即将探索的内容时,我们将避免许多基本和恼人的错误。这将使文章在材料和解释方面更具活力。事实上,这将使事情变得更加有趣。
所以,请放心,和我一起探索和理解这个新概念。在我看来,这是一个转折点,因为它为我们提供了更多的编程可能性,并让我们更好地理解如何使用 MQL5。让我们正式开始,引入一个新话题。
结构
在 MQL5 编程的初始基本阶段,我们将探索的最有趣的事情之一是结构。如果你真正正确地理解它们,你就能理解其他一切。肯定没问题。结构的概念介于简单编程和完全不同的范式之间,在简单编程中,我们只创建变量和过程,在完全不同的范例中,我们将代码组织成功能齐全的块。这些代码块是对象类。但这将在我们探索和理解结构的概念后进行讨论。
初学者程序员犯的最大错误之一就是试图以艰难的方式学习。他们想象自己可以在不真正理解给定功能或工具是如何以及为什么必要的情况下实现一些东西。编程语言中没有任何工具或功能仅仅因为看起来不错或有吸引力而存在。它之所以存在,是因为编译器开发人员看到了该语言中存在该工具或功能的必要性。
在这些文章中,我将提及 C 和 C++ 中存在,但 MQL5 中没有实现的功能,尽管 MQL5 很大程度上是基于 C 和 C++ 的。我认为 MQL5 没有包含这些功能的原因很简单,就是因为它们没有必要。在某些情况下,这也可能是由于正确使用某些特性(尤其是在 C++ 中)的复杂性造成的,这些特性在 MQL5 的预期范围内,对代码造成的混乱和复杂化远远大于其带来的帮助。请记住,MQL5 旨在使我们能够使用 MetaTrader 5 构建金融市场操作工具,而 C++ 旨在支持构建任何类型的应用程序:从操作系统到自主或非自主进程和应用程序。
例如,您可以使用 C 和 C++ 构建任何东西,甚至是相当于 MetaTrader 5 的平台。然而,这将需要大量的工作。使用已经存在的东西(如 MQL5)要简单得多,也更实用。但是,要使用 MQL5 创建更复杂的东西,我们需要更高级的工具和功能。我们将使用的第一个高级资源是结构。没有它们,我们仍然可以制作出有趣的东西,但难度会高得多。
结构可以包含非常高的复杂性 —— 远超你的想象。但是,我们会循序渐进地进行讲解,一步一步地展示,以便您能够理解这些结构是如何实际工作的。相信我,你会对它们所能达到的复杂程度感到惊讶。即便如此,它们仍然无法处理某些情况。因此,创建了另一种类型的结构,为了将其与常规结构区分开来,它被赋予了一个特殊的名称:类。但我们将在以后的文章中更详细地探讨这个问题。
所以,让我们从一个非常简单和基本的结构开始。第一个例子如下所示。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. struct st_01 07. { 08. short value_01; 09. int value_02; 10. double value_03; 11. }; 12. 13. st_01 Info; 14. 15. Info.value_01 = -8096; 16. Info.value_02 = 78934; 17. Info.value_03 = 1e4 + 0.674; 18. 19. PrintFormat("Result of the sum of all values. %f", Info.value_01 + Info.value_02 + Info.value_03); 20. } 21. //+------------------------------------------------------------------+
代码 01
代码 01 是一段非常简单的代码,我们从中开始了解如何构建一个结构。请注意,我们创建结构的方式与创建联合的方式非常相似。然而,这两者之间存在重大差异。联合是指其中所有元素都占用同一内存区域的结构。
另一方面,结构的建造和设计是为了使其内部的每个元素都是独立的。换句话说,结构在某种程度上类似于复杂的变量类型,能够容纳多个元素来形成该变量。这并非对结构这一概念的完美定义。
然而 —— 这一点对于我亲爱的读者来说很重要 —— 这种对结构的初始定义或概念化确实是思考它们的一种正确方法,因为它简化了对它们许多属性的理解。所以现在,把这当作你的结构工作概念:
结构是一种将多个变量分组的方法,这些变量以某种方式相互关联。
随着我们对结构的研究不断深入,你会明白这个概念有了很大的扩展,呈现出不同的“个性”,这赋予了我们极大的创作自由,同时使实现非常复杂的事情变得越来越简单。
但让我们回到最初的代码,即代码 01。请注意,我们在第 6 行声明了一个结构。与联合一样,MQL5 中无法定义匿名结构,因此我们必须给它一个名称。由于这是我们第一次接触这个概念,我采用了与我解释联合时类似的方法。也就是说,我们在一行中声明结构,然后在另一行中声明将使用该结构的变量。在这个例子中,变量声明位于第 13 行。请注意这与联合示例是多么相似。
然后,从第 15 行到第 17 行,我们为结构的每个元素赋值。如你所见,这与给任何普通变量赋值非常相似。这些都是基本元素。然后,在第 19 行,我们向终端打印一条消息。这行代码会生成下图所示的结果。

图 01
作为初次接触,我相信您能够很好地理解这里发生的事情。其中大部分已经在前面解释过了。只有第 6 行的内容可能会引起一些疑问或犹豫。但是,一旦你理解了结构在声明方式上本质上等同于联合,其他一切都会变得更容易理解。知识随着时间的推移而扩展。
好了,这很简单。然而,在我们继续进行更详细的讨论之前,在使用结构时必须遵守一些规则。我将逐步解释它们,因为目前有些可能没有多大意义。
第一条规则是:
在 MQL5 中,结构体永远不能是常量,它始终是一个变量。
这意味着您不能在 MQL5 中将结构声明为常量。这是因为我们必须首先声明用于访问结构中数据的标签,然后才能访问该数据。也就是说,代码 01 中看到的第 13 行必须存在,我们才能以任何方式使用该结构。
由于声明常量需要在声明时定义其值,因此无法在 MQL5 中创建常量结构。
第二条规则是:
结构体中元素的声明顺序决定了它们在内存中的顺序。
这条规则非常重要,尤其是在以特定方式使用结构时。但让我们慢慢来。首先,在应用第二条规则之前,让我们先了解一些情况。定义联合时,存储它所需的字节数等于其最大成员的大小。
然而,对于结构来说,情况略有不同。为了理解这一点,让我们重用代码 01,并检查我们需要多少内存。为了使事情更清楚,并帮助您理解结构和联合在内存中的布局方式之间的区别,我们将添加一个具有相同元素和类型的联合。这样我们就得到了下面所示的代码。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. struct st_01 07. { 08. short value_01; 09. int value_02; 10. double value_03; 11. }; 12. 13. union un_01 14. { 15. short value_01; 16. int value_02; 17. double value_03; 18. }; 19. 20. PrintFormat("Size of struct is: [%d bytes]\nSize of union is: [%d bytes]", sizeof(st_01), sizeof(un_01)); 21. } 22. //+------------------------------------------------------------------+
代码 02
请注意,在代码 02 中,我们有两种不同的构造,但包含相同的元素和类型。然而,尽管如此,它们在字节数上占用的内存量却不同。通过查看下图 02 所示的结果可以看出这一点。
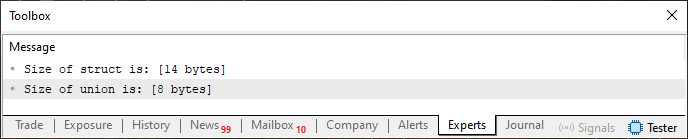
图 02
请注意,该联合需要 8 个字节,因为其中存在的最大类型是 double 类型,而 double 类型(我们已经知道)需要 8 个字节来表示。然而,包含相同元素的结构需要 14 个字节。这是因为我们必须将 double 类型的 8 个字节与 int 类型的 4 个字节和 short 类型的 2 个字节相加,总共得到所示的 14 个字节。但现在让我们了解第二条规则告诉我们什么。为此,我们需要再次修改代码 02,得到下面显示的下一个代码。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. struct st_01 09. { 10. short value_01; 11. int value_02; 12. double value_03; 13. }; 14. 15. struct st_02 16. { 17. short value_01; 18. int value_02; 19. double value_03; 20. }; 21. 22. union un_01 23. { 24. st_01 data_01; 25. st_02 data_02; 26. }; 27. 28. un_01 Info; 29. 30. ZeroMemory(Info); 31. Info.data_01.value_01 = -18254; 32. 33. PrintX(Info.data_02.value_01); 34. } 35. //+------------------------------------------------------------------+
代码 03
在代码 03 中,我们有一个结构,可以帮助我们理解规则 02。亲爱的读者,请密切关注这里将要做的事情,因为这将在未来为你提供极大的帮助。在这个例子中,我们声明了两个结构。两者完全相同,无论是元素的数量和种类,还是每个元素的数据类型。然而,重要的是元素的声明顺序完全相同。这是这里最重要的一点。
为了便于理解,我们在第 22 行使用了联合。这种联合将两个结构连接起来,使所有元素共享相同的内存空间。亲爱的读者,您已经知道这一点了,对吗?现在要注意了,在第 30 行,我指示编译器完全清理联合体所在的内存区域。换句话说,整个区域现在只包含 0。
在第 31 行,我们给结构体中的一个变量赋值。可以是任何一个。但请注意,我们是通过以联合为参考点来实现这一点的。在我们的例子中,我们正在为第 08 行定义的结构中声明的变量赋值。为了测试发生了什么,我们使用第 33 行打印同一变量的值。然而,在这种情况下,我们读取的变量是第 15 行定义的结构 02 中的变量。由于这两个结构共享相同的内存块,因此值显然应该相同。
因此,执行代码 03,您可以观察到如下所示的结果。
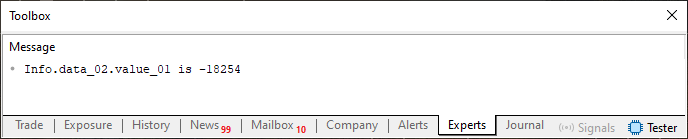
图 03
唔,这里没有异常,因为显示的值与我们在第 31 行分配给变量的值完全相同。一切似乎都是正确的。你甚至可能在质疑我:如果没有任何改变,你为什么还要提到第二条规则?你说的话完全没有道理。
哦,我弄错了 —— 这里确实没有产生任何问题。但现在让我们进行另一个测试。这次我们将使用不同的代码,这样我们就可以看见内存中发生的一切。为此,让我们将代码 03 修改为另一个版本,如下所示。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. struct st_01 09. { 10. short value_01; 11. int value_02; 12. double value_03; 13. }; 14. 15. struct st_02 16. { 17. short value_01; 18. int value_02; 19. double value_03; 20. }; 21. 22. union un_01 23. { 24. st_01 data_01; 25. st_02 data_02; 26. uchar arr[sizeof(st_01)]; 27. }; 28. 29. un_01 Info; 30. 31. ZeroMemory(Info); 32. Info.data_01.value_01 = -18254; 33. 34. ArrayPrint(Info.arr); 35. 36. PrintX(Info.data_02.value_01); 37. } 38. //+------------------------------------------------------------------+
代码 04
好的,现在我们有了一段代码,可以让我们直观地看到变量 Info 引用的内存区域中正在发生的事情。执行代码 04 时,您将看到下图。
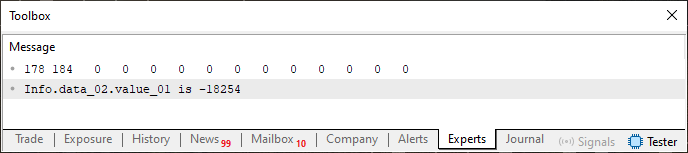
图 04
再一次,一切都按预期进行。由于代码 04 使用了已经解释过的概念,我将不再详细介绍那里正在做什么。但是,这就是事情变得真正有趣的地方,我们将采用代码 04 并更改一个微小的细节。这个细节显示在下面的片段中。
. . . 15. struct st_02 16. { 17. int value_02; 18. short value_01; 19. double value_03; 20. }; . . .
片段 01
将片段 01 中所示的更改应用到代码 04 后,我们再次编译它,并在 MetaTrader 5 终端中运行。你可能会认为这种改变不会影响任何事情 —— 既不会影响内容,也不会影响我们运行代码时的结果。但既然你坚持,我就试试,只是为了证明你错了。因此,您执行代码并获得下图 05 所示的结果。
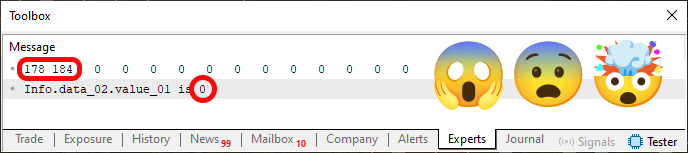
图 05
那是什么怪事?这怎么可能?哦,我知道了:这是个 bug。或者更确切地说,你在操纵图像。图 05 中这是某种恶作剧,你想骗我。你以为我不会注意到吗?错了。亲爱的读者朋友们,这可不是恶作剧。通过将片段 01 插入到代码 04 中,您可以很容易地重现这一点。但是,为什么尽管内存内容保持不变,但在读取变量时我们得到了不同的值呢?原因是我们不是在读取变量本身,而是在读取它被解释的内存位置。
这可能看起来有点奇怪,甚至违反直觉。毕竟,在代码 04 中,结构 01 和结构 02 都具有相同的数据类型,以及相同名称的变量。鉴于我们使用联合体来“模拟”文件映射区域,仅仅通过移动结构声明中的变量就能改变值,这好像不合理。
然而,这就是第二条规则的真正重要性所在,你必须暂时忽略我们正在内存中执行代码的事实。你必须开始在更大的范围内思考这个问题。考虑以下事实:当我们保存文件时,我们按照特定的逻辑顺序存储信息。但通常,根据逻辑结构存储和加载数据符合我们的利益。
例如,您可以在图像文件格式中看到这一点。在这种文件的开头,我们有所谓的文件头。那里的数据属于一个数据结构。您可以通过两种方式读取此数据:一次读取一个值,或者使用专门为此目的设计的结构。
为了帮助您理解,让我们以最简单的数据结构为例:众所周知的位图格式。当存储位图图像或必须从磁盘读取位图图像时,文件的开头包含一个由一系列字段组成的结构。这个序列实际上是一个结构,告诉我们图像是如何形成的,它包含什么类型的图像,什么结构被用来建模图像,它的尺寸,以及许多其他东西。
由于该文件格式遵循特定的布局,您可以根据 BMP 文件格式规范中的信息,以您想要的任何方式重现图像。同样,您可以操纵存储在那里的数据。但重要的是,理解第二条规则至关重要的原因是:如果你正在实现一个将数据保存到磁盘的应用程序,后来决定更改你最初创建的结构,认为它可能以不同的方式组织得更好,那么在尝试恢复以前保存的数据时可能会遇到问题。这是因为变量的位置随着时间的推移而变化。
这就是为什么理解结构设计必须牢记其最终目的的概念对你来说很重要。如果目的是只将所有内容保存在内存中,也许您不需要修改数据,也不必担心声明顺序。但是,如果目标是在不同点之间传输信息或存储信息以供将来使用,那么您应该创建一些机制来对结构进行版本化。这样,当你改变内容时,你也会改变结构的版本。如果一切都经过精心规划和维护,您仍然可以使用更新的结构版本读取非常旧的存储数据。
也许我在这里解释的在这个早期阶段可能没有多大意义。在考虑数据建模之前,我们仍然需要理解和研究与结构直接相关的其他概念。
但为了让事情更有趣,让你真正理解我想展示的内容,让我们做一个小实验。这并不复杂,其实很简单。通过我们到目前为止所涵盖的所有概念,您将能够毫不费力地理解它。请查看以下代码。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+----------------+ 06. #define def_FileName "Testing.bin" 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. struct st_01 11. { 12. short value_01; 13. int value_02; 14. double value_03; 15. }Info; 16. 17. int handle; 18. 19. ZeroMemory(Info); 20. 21. PrintFormat("Size of struct is %d bytes", sizeof(Info)); 22. 23. if ((handle = FileOpen(def_FileName, FILE_READ | FILE_BIN)) != INVALID_HANDLE) 24. PrintFormat("Reading %d bytes of file data.", FileReadStruct(handle, Info)); 25. else 26. { 27. Info.value_01 = -8096; 28. Info.value_02 = 78934; 29. Info.value_03 = 1e4 + 0.674; 30. 31. PrintFormat("Writing %d bytes of data in the file.", FileWriteStruct(handle = FileOpen(def_FileName, FILE_WRITE | FILE_BIN), Info)); 32. } 33. FileClose(handle); 34. 35. PrintX(Info.value_01); 36. PrintX(Info.value_02); 37. PrintX(Info.value_03); 38. } 39. //+------------------------------------------------------------------+
代码 05
代码完成后,终端将显示下面的内容。
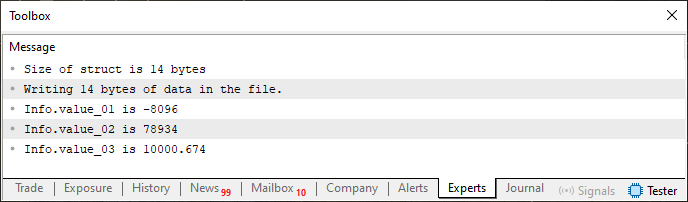
图 06
您可以看到,这里我们首先写入文件,因为它以前不存在。如果你很好奇,可以使用十六进制编辑器打开文件。在这种情况下,您将看到下一张图片中显示的内容。

图 07
如果您使用联合来检查区域,那么内存中将存在与此相同的内容。但现在先别管这件事,因为此刻它并不特别重要。这里重要的是:当您再次执行代码 05 而不修改它或删除或更改图 07 所示的文件内容时,您将在 MetaTrader 5 终端中获得如下所示的内容。
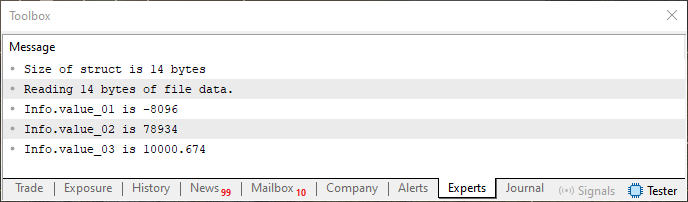
图 08
很明显,你看到的是相同的信息。现在我建议您简单地更改代码 05 第 10 行声明的结构中变量的顺序。不要修改其他任何内容,重新编译代码并运行它。将先前图像中显示的先前结果与以更改的变量顺序再次执行代码 05 时在终端中显示的结果进行比较。反思发生了什么,并将其与我们使用联合执行相同类型分析时观察到的情况进行比较。
尽管我们还没有正式讨论文件读写,但附件中提供的代码 05 非常简单。根据这些文章到目前为止的解释,很容易理解。通过阅读文档,特别是库函数,可以完全澄清可能引发问题的唯一部分:FileOpen、FileWriteStruct、FileReadStruct 和 FileClose。但即使是这些也很容易理解,不需要额外的评论来完全理解这里显示的内容。
最后的探讨
这是我们关于 MQL5 结构的第一篇文章。为了正确地开始,我们必须理解适用于结构的各种概念。我知道第一次接触可能并不特别令人兴奋。然而,你一定注意到,理解前几篇文章中解释的内容是绝对必要的。如果没有正确吸收这些概念,理解我们在这里开始做的事情将变得更加困难和混乱。
因此,至关重要的是要练习并努力理解正在做的事情和正在产生的结果。总之,请使用附件文件练习第一次接触,重点理解本文中演示的两条规则。它们很快就会变得极其重要。
本文由MetaQuotes Ltd译自葡萄牙语
原文地址: https://www.mql5.com/pt/articles/15730
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
