
От начального до среднего уровня: Struct (I)

Введение
В предыдущей статье "От начального до среднего уровня: Шаблон и Typename (V)", мы говорили о шаблонах и о том, как с их помощью можно реализовать различные типы решений с наименьшим усилием.
И, учитывая, что чем меньше усилий нам нужно приложить, тем выше производительность и гибкость в разработке различных решений, я считаю, что вы с нетерпением будете ждать, когда мы начнем создавать то, что можно поместить на график. Наша цель состоит в том, чтобы генерировать действительно правдоподобные результаты, а не просто просматривать распечатанную информацию на терминале, как это делалось до этих пор.
Хотя именно здесь всё начинает обретать форму, то, что было показано и рассмотрено до этого момента, позволило нам создать хорошую базу знаний и отличную и широкую концептуальную основу. Таким образом, мы можем создавать и реализовывать многие вещи с относительно небольшими усилиями. Однако, несмотря на то, что концептуальная основа построена и структурирована, еще не время начинать написание кода, чтобы нанести что-то непосредственно на график. Это не связано с возможными условиями написания кода, а с тем, что нам позволено манипулировать кодом, но при этом у нас всё равно нет возможности правильно структурировать определенную информацию во время настоящей реализации.
Поэтому нам необходимо ввести новую концепцию. Как только мы полностью представим и объясним, она позволит нам сделать многое. Мы действительно получим безопасный и надежный механизм, который позволит нам делать всё быстрее и каждый раз будет требовать всё меньше усилий. Если мы будем применять уже увиденное, и то, что еще будет показано, то мы сможем избежать многих базовых и досадных ошибок. Это сделает статьи более динамичными с точки зрения вида материала, который я смогу показать, и того, как нужно будет объяснять происходящее. И кроме того, это сделает всё намного интереснее.
Так что, можно успокоиться. Устраивайтесь поудобнее: сегодня изучим эту новую концепцию, которая, на мой взгляд, является переломным моментом. Она предлагает нам гораздо больше возможностей для программирования и понимания того, как работать с MQL5. Но для начала, создадим новую тему.
Структуры
Один из самых интересных элементов, которые можно увидеть на начальном и базовом этапе программирования на MQL5, - это структуры. Потому что, если вы поймете их правильно, то сможете понять и всё остальное. Это буквально так. Концепция структуры находится на полпути между базовым программированием, где мы просто создаем переменные и процедуры, и совершенно другим видом программирования, где мы организуем код в функциональные блоки. Данные блоки представляют собой классы объектов. Но об этом мы поговорим в другой раз, после изучения и полного усвоения концепции структуры.
Одна из самых больших ошибок начинающих программистов - это желание научиться всему на собственном опыте, воображая, что они смогут осуществить ту или иную реализацию, не разобравшись в том, как и зачем на самом деле нужен один из инструментов. Ни один инструмент или ресурс в языке программирования не появился только от того, что он красив или привлекателен. Этот инструмент существует, потому что разработчики компилятора почувствовали необходимость присутствия в языке такого инструмента или ресурса.
В этой серии статьей мы упомянем ресурсы, которые существуют в C и C++, но не были реализованы в MQL5, хотя MQL5 во многом основан на C и C++. Я думаю, что причина их не-реализации в MQL5 заключается именно в том, что они не нужны. В некоторых случаях, как мне кажется, это связано со степенью сложности, связанной с правильным использованием ресурсов, в основном C++, которые могут быть полезны для функциональности MQL5, но которые полностью усложняют и запутывают код. Помните, что MQL5 предназначен для создания инструментов для торговли на финансовом рынке с помощью MetaTrader 5, в то время как C++ - предназначен для создания приложений любого типа: от операционных систем до процессов и приложений, работающих автономно или неавтономно.
Например, на C и C++ можно создать всё, что угодно, даже платформу, эквивалентную MetaTrader 5, но работа для этого потребуется огромная, поэтому проще и практичнее использовать что-то уже существующее, например MQL5. Но для создания более сложных вещей - и это при использовании MQL5 - нам нужны более продвинутые ресурсы и инструменты. В этом случае первый продвинутый ресурс, который мы будем использовать, - это структуры. Без них мы могли бы создать что-то интересное, но степень сложности была бы гораздо выше.
Структуры могут быть очень сложными, гораздо сложнее, чем можно себе представить. Но давайте начнем без спешки, чтобы вы могли усвоить, как работают эти структуры. Поверьте, вы удивитесь уровню сложности, которого они могут достичь. Несмотря на это, они всё равно не могут справиться с некоторыми ситуациями. Поэтому пришлось создать еще один тип структур, который, чтобы различать их, получил специальное название: классы. Но это мы рассмотрим в следующих статьях.
Итак, для ознакомления с этой новой концепцией, мы начнем с очень простой структуры. Это можно увидеть ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. struct st_01 07. { 08. short value_01; 09. int value_02; 10. double value_03; 11. }; 12. 13. st_01 Info; 14. 15. Info.value_01 = -8096; 16. Info.value_02 = 78934; 17. Info.value_03 = 1e4 + 0.674; 18. 19. PrintFormat("Result of the sum of all values. %f", Info.value_01 + Info.value_02 + Info.value_03); 20. } 21. //+------------------------------------------------------------------+
Код 01
Код 01 очень прост, и мы начинаем понимать, как построить структуру. Прошу заметить, что способ создания структуры очень похож на способ создания объединения. Однако между этими двумя ресурсами есть разница. В то время как объединение создается таким образом, что все элементы, присутствующие в нем, принадлежат к одной и той же области памяти.
Структура создается и проектируется таким образом, чтобы каждый ее элемент был индивидуален. То есть структура - это тип сложной переменной, у которой может быть несколько элементов для ее создания. Это не самое удачное определение, но оно позволяет объяснить, что такое структура.
Дорогие читатели, очень важно, чтобы вы это поняли: это первое определение структуры является адекватным способом ее понимания, поскольку позволяет нам понять другие свойства. Пока возьмем за основу концепцию структуры.
Структура - это способ сгруппировать несколько переменных, которые определенным образом коррелируют друг с другом.
По мере изучения структур вы увидите, что данная концепция значительно расширяется и приобретает различные формы, что дает нам большую свободу творчества и позволяет всё легче и легче реализовывать очень сложные вещи.
Но давайте вернемся к нашему исходному коду из кода 01. Обратите внимание, что в строке 06 мы объявляем структуру. Как и в случае с объединениями, в MQL5 невозможно определить анонимную структуру, поэтому необходимо присвоить ей название. Поскольку это первое знакомство, я использую что-то очень похожее на то, что было сделано, когда объяснялась тема объединений. То есть сначала мы объявляем структуру, а затем, в другой строке, переменную, которая будет ее использовать. В данном случае объявление переменной находится в строке 13. Как видите, это очень похоже на то, что было сделано с объединениями.
В строках с 15 по 17 мы присваиваем значения каждому элементу структуры. Как видите, это очень похоже на то, что мы делали, присваивая значения любой переменной. Другими словами, мы используем базовые элементы. В строке 19 мы выводим сообщение на терминал, чтобы сообщить о чем-то. В данном случае эта строка приведет к тому, что мы видим на изображении ниже.

Изображение 01
В качестве первого знакомства, я думаю, вы очень хорошо понимаете, что здесь происходит. Потому что многое из этого уже объяснялось некоторое время назад. Тот факт, что строка 06 такая, какая она есть, может вызвать недоверие. Однако, если мы понимаем, что структура эквивалентна объединению с точки зрения ее объявления, всё остальное станет намного проще. Другими словами, знания расширяются со временем.
Хорошо, это было просто. Однако прежде, чем переходить к чему-то более сложному, следует помнить о некоторых правилах использования структур. Я буду объяснять их понемногу, так как некоторые из них могут быть не очень понятны на данный момент.
Первое правило гласит:
В MQL5 структура НИКОГДА НЕ может быть КОНСТАНТОЙ. Она ВСЕГДА будет переменной.
Это означает, что нельзя объявить структуру - чтобы было понятно, речь идет именно о MQL5 - как константу в MQL5. Причина в том, что сначала мы объявляем метку, которую будем использовать для доступа к данным в структуре, и только потом можем получить доступ к этим данным. То есть, чтобы использовать структуру, нам сначала нужно, чтобы существовала строка 13 из кода 01.
Поскольку для объявления константы необходимо определить ее значение в момент объявления, в MQL5 нет возможности создать структуру константы.
Второе правило гласит:
То, как элементы объявлены в структуре, определяет порядок их размещения в памяти.
Это правило очень важно, особенно, когда мы собираемся использовать структуры конкретным образом. Но давайте не будем торопиться. Прежде, чем применить правило номер два, давайте кое в чем разберемся. При определении объединения, количество байтов, необходимых для его содержания, будет равно количеству байтов самого большого типа, присутствующего в нем.
Однако, когда речь идет о структурах, всё обстоит несколько иначе. Чтобы понять это, давайте воспользуемся тем же кодом 01 и посмотрим, сколько памяти нам нужно. Однако, чтобы было понятнее, как выглядят в памяти структура и объединение, добавим объединение с теми же элементами и типами. Таким образом, появляется такой код:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. struct st_01 07. { 08. short value_01; 09. int value_02; 10. double value_03; 11. }; 12. 13. union un_01 14. { 15. short value_01; 16. int value_02; 17. double value_03; 18. }; 19. 20. PrintFormat("Size of struct is: [%d bytes]\nSize of union is: [%d bytes]", sizeof(st_01), sizeof(un_01)); 21. } 22. //+------------------------------------------------------------------+
Код 02
Прошу заметить, что в коде 02 мы имеем две разные конструкции с одинаковыми элементами и типами. Но, несмотря на это, они занимают разные места в байтах. Это видно из результата на изображении 02 ниже.
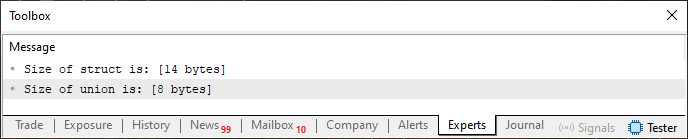
Изображение 02
Обратите внимание, что объединение требует восемь байт, поскольку самый большой тип, присутствующий в нем, - double, и для его представления, как мы уже знаем, требуется восемь байт. Структура, содержащая те же элементы, занимает четырнадцать байт. Это происходит так, потому что мы должны добавить восемь байт типа double к четырем байтам типа int и двум байтам типа short, что в сумме дает нам четырнадцать байт. Теперь давайте разберемся, о чем говорит нам второе правило. Для этого нужно снова изменить код 02 на тот, который показан ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. struct st_01 09. { 10. short value_01; 11. int value_02; 12. double value_03; 13. }; 14. 15. struct st_02 16. { 17. short value_01; 18. int value_02; 19. double value_03; 20. }; 21. 22. union un_01 23. { 24. st_01 data_01; 25. st_02 data_02; 26. }; 27. 28. un_01 Info; 29. 30. ZeroMemory(Info); 31. Info.data_01.value_01 = -18254; 32. 33. PrintX(Info.data_02.value_01); 34. } 35. //+------------------------------------------------------------------+
Код 03
В коде 03 есть конструкция, которая позволит нам понять правило 02, так что будьте внимательны, потому что это очень поможет вам в будущем. Здесь у нас есть две объявленные структуры. Они обе точно ИДЕНТИЧНЫ как по количеству и числу элементов, так и по типу данных. Но самое главное, что порядок объявления элементов абсолютно одинаков, это самый важный момент.
Чтобы было еще проще понять, в строке 22 мы используем объединение. Это привязывает структуры таким образом, что все элементы занимают одно и то же пространство памяти. Естественно, вы уже знаете об этом, не так ли? Ну, а теперь внимание. В строке 30 мы указываем компилятору полностью очистить область памяти, в которой находится объединение. То есть вся область теперь содержит только нули.
В строке 31 мы присваиваем значение одной из переменных, которые присутствуют в структуре. Это может быть какое угодно. Но прошу заметить, что мы делаем это, используя объединение как точку опоры. В данном случае мы присваиваем значение той переменной, которая объявлена в структуре, определенной в строке 08. Чтобы проверить, что происходит, в строке 33 мы распечатаем значение той же переменной. Однако в данном случае переменная находится в структуре 02, определяемой в строке 15. Поскольку обе структуры используют один и тот же блок памяти, значение будет одинаковым.
Затем, после выполнения кода 03, мы увидим то, что показано ниже.
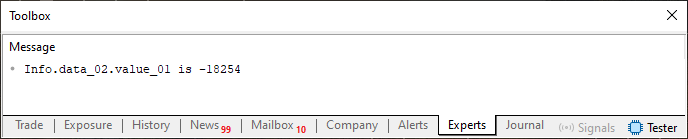
Изображение 03
Хм... В этом нет ничего аномального, поскольку представленное значение точно такое же, как и то, которое мы присваиваем переменной в строке 31. Поскольку всё правильно, вы можете даже спросить себя: «Почему вы упомянули правило номер два, если не было никаких изменений? То, что вы сказали, не имеет никакой логики».
Хорошо, я ошибался, на самом деле здесь нет никакой проблемы. Давайте проведем еще один тест. Но на этот раз мы будем использовать другой код, чтобы иметь возможность визуализировать всё, что происходит в памяти. Для этого мы изменим код 03 на другой, который можно увидеть ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. struct st_01 09. { 10. short value_01; 11. int value_02; 12. double value_03; 13. }; 14. 15. struct st_02 16. { 17. short value_01; 18. int value_02; 19. double value_03; 20. }; 21. 22. union un_01 23. { 24. st_01 data_01; 25. st_02 data_02; 26. uchar arr[sizeof(st_01)]; 27. }; 28. 29. un_01 Info; 30. 31. ZeroMemory(Info); 32. Info.data_01.value_01 = -18254; 33. 34. ArrayPrint(Info.arr); 35. 36. PrintX(Info.data_02.value_01); 37. } 38. //+------------------------------------------------------------------+
Код 04
Теперь у нас есть код, в котором мы можем увидеть, что происходит в памяти в той области, которая обозначена переменной Info. Запустив код 04, мы увидим изображение ниже.
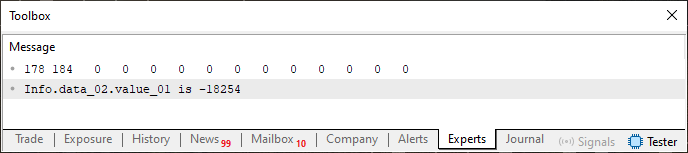
Изображение 04
И снова всё так, как и ожидалось. Поскольку в коде 04 используются элементы, которые уже были описаны, я не буду вдаваться в подробности того, что там происходит. Но именно здесь становится по-настоящему интересно: мы собираемся изменить небольшую деталь данного кода. Мы ее показываем в приведенном ниже фрагменте.
. . . 15. struct st_02 16. { 17. int value_02; 18. short value_01; 19. double value_03; 20. }; . . .
Фрагмент 01
Теперь, сделав модификацию из фрагмента 01 в коде 04, мы снова компилируем его и запускаем в терминале MetaTrader 5. Вы можете подумать: «Это изменение не повлияет на содержание или результат, который мы получим при выполнении кода. Но раз уж вы настаиваете, я докажу это, чтобы показать вам, что вы ошибаетесь. Запустив код, мы получим то, что показано ниже на изображении 05.
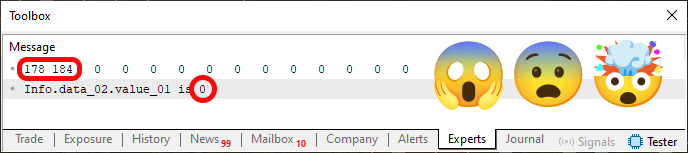
Изображение 05
Что это? Как такое возможно? О, я знаю: это ошибка. Вернее, ты манипулировал изображением. То, что я вижу на картинке 05, - это розыгрыш и у тебя не получится меня обмануть. Думал, я не замечу? Ты ошибся». Да, дорогой читатель, такое возможно. Это факт, который можно прекрасно воспроизвести, если осуществить то, что было сказано: поместить фрагмент 01 в код 04. «Но почему, если содержимое памяти осталось неизменным, мы получили другой результат при чтении переменной?» Причина в том, что мы читаем не переменную, а область памяти, в которой она используется.
Это может показаться немного странным и даже необычным. В коде 04, как структура 01, так и структура 02 имеют одинаковые типы данных и переменные с одинаковыми названиями. Если предположить, что мы используем объединение для "моделирования" перемещения файла, то нет особого смысла в том, что значение может быть изменено только потому, что переменная была перемещена во время объявления структуры.
Но - и именно здесь кроется важность правила номер два - мы должны на мгновение забыть о том, что мы выполняем код в памяти, и начать думать об этом шире. Подумайте об этом: когда мы записываем файл, мы храним информацию в определенной логической последовательности. Однако зачастую мы заинтересованы в хранении и загрузке данных в логической структуре.
Это можно увидеть, например, в файлах изображений. В этом случае в начале файла находится так называемый заголовок. Данные в нем являются частью структуры данных, однако их можно читать двумя способами. Первый способ - читать их по-очереди, а второй - использовать специально созданную структуру.
Чтобы было понятнее, давайте рассмотрим простейший пример структуры данных, хорошо известный формат BitMap. Когда изображение BitMap сохраняется или считывается с диска, в начале файла изображения находится структура, состоящая из последовательности полей. Данная последовательность, которая на самом деле является структурой, говорит нам о том, как формируется изображение, что это за изображение, какая структура была использована для его моделирования и каковы его размеры, а также о многом другом.
Поскольку структура файла соответствует определенному формату, можно использовать информацию, которая содержится в формате BMP, для воспроизведения изображения по нашему усмотрению. Так же как мы можем читать изображение, мы можем и манипулировать данными, которые оно содержит. Но важный момент, из которого следует необходимость понять правило номер два: если мы реализуем приложение, сохраняющее данные на диск, и через некоторое время изменяем первоначально созданную структуру, потому что заметим, что она может быть лучше организована по-другому, то могут возникнуть проблемы при попытке извлечь сохраненные в прошлом старые данные. Это объясняется тем, что положение переменных менялось с течением времени.
Именно поэтому важно понимать, что структуры должны рассматриваться с точки зрения их конечной цели. Если мы предполагаем хранить всё в памяти, то, возможно, нет необходимости сильно изменять данные или беспокоиться о порядке их объявления. Однако, если целью является передача информации между различными точками или ее хранение для дальнейшего использования, рекомендуем создать некий механизм фиксации структуры в определенной версии. Поэтому при внесении изменений нам придется менять версию создаваемой структуры. Если всё идеально продумать и поддерживать, можно будет читать данные, которые сохраняются давным-давно, с помощью гораздо более новой версии структуры.
Возможно, все эти вещи, о которых мы говорим, не имеют особого смысла, особенно на этом раннем этапе, потому что, прежде чем думать о моделировании данных, нам нужно понять и изучить другие концепции, которые напрямую связаны с вопросом о структурах.
Но, чтобы сделать всё это более интересным и дать вам лучшее понимание того, что мы хотим показать, давайте проведем небольшой эксперимент. Это совсем не сложно. На самом деле, всё очень просто. И, учитывая все рассмотренные до этого момента концепции, вам будет легко разобраться в ней. Давайте посмотрим на код ниже.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+----------------+ 06. #define def_FileName "Testing.bin" 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. struct st_01 11. { 12. short value_01; 13. int value_02; 14. double value_03; 15. }Info; 16. 17. int handle; 18. 19. ZeroMemory(Info); 20. 21. PrintFormat("Size of struct is %d bytes", sizeof(Info)); 22. 23. if ((handle = FileOpen(def_FileName, FILE_READ | FILE_BIN)) != INVALID_HANDLE) 24. PrintFormat("Reading %d bytes of file data.", FileReadStruct(handle, Info)); 25. else 26. { 27. Info.value_01 = -8096; 28. Info.value_02 = 78934; 29. Info.value_03 = 1e4 + 0.674; 30. 31. PrintFormat("Writing %d bytes of data in the file.", FileWriteStruct(handle = FileOpen(def_FileName, FILE_WRITE | FILE_BIN), Info)); 32. } 33. FileClose(handle); 34. 35. PrintX(Info.value_01); 36. PrintX(Info.value_02); 37. PrintX(Info.value_03); 38. } 39. //+------------------------------------------------------------------+
Код 05
Когда код будет выполнен, в терминале появится то, что видим ниже.
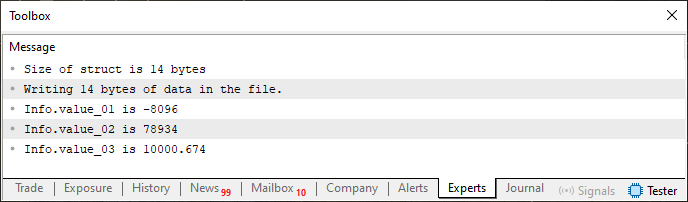
Изображение 06
Наверное вы заметили, что сначала мы записываем в файл, поскольку он не существовал. Если вам интересно, можно открыть файл с помощью шестнадцатеричного редактора. В этом случае вы увидите то, что показано на изображении ниже.

Изображение 07
Это тот тип содержания, который будет присутствовать в памяти, если будем использовать объединение для визуализации области. Но пока забудьте об этом, поскольку в данный момент это не имеет значения. Нас интересует следующее: если снова запустить код 05 - не изменяя его, не удаляя и не модифицируя содержимое файла, который можно увидеть на изображении 07, - то в терминале MetaTrader 5 мы получим то, что показано ниже.
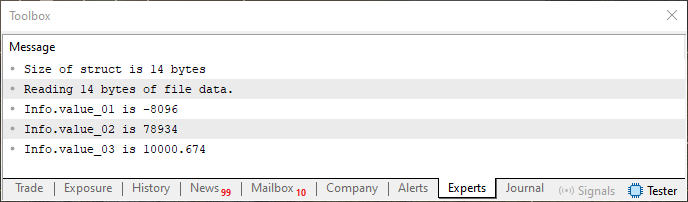
Изображение 08
Естественно, вы увидите, что это одна и та же информация. Теперь я вам предлагаю изменить только порядок переменных в структуре, объявленной в строке 10 из кода 05. Не меняя ничего, перекомпилируем код и запустим его. Сравните полученные ранее результаты, которые можно увидеть на изображениях выше, с результатом, который можно увидеть на терминале при повторном выполнении кода 05 с изменением порядка объявления переменных. Подумайте о том, что произошло, и сравните это с тем, что мы видели, когда использовали объединение для проведения такого же анализа.
Хотя мы еще не обсуждали запись и чтение файлов, код 05, который будет доступен в приложении, очень прост, практичен и понятен, и его можно легко понять на основе того, что было объяснено до этих пор. Единственные части, которые могут вызвать вопросы, можно полностью понять, прочитав документацию по функциям библиотеки: FileOpen, FileWriteStruct, FileReadStruct и FileClose. Но даже они достаточно просты для понимания и не нуждаются в дополнительных комментариях для того, чтобы полностью понять их.
Заключительные идеи
Это была первая статья о структурах в MQL5. Для начала нам нужно понять ряд понятий, которые необходимо применять к структурам. Я знаю, что первое знакомство могло быть не таким уж захватывающим. Однако вы, наверное, заметили, что для этого необходимо понять, о чем шла речь в предыдущих статьях. Без правильного понимания этих понятий то, что мы начнем здесь делать, будет гораздо сложнее и запутаннее.
Поэтому необходимо практиковаться и стремиться понять, что вы хотите делать и какие результаты желаете получать. В любом случае, используйте файлы в приложении для отработки этого первого знакомства и постарайтесь понять два правила, которые были продемонстрированы в этой статье, поскольку они будут очень важны в ближайшем будущем.
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/15730
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования