
Do básico ao intermediário: Struct (I)

Introdução
No artigo anterior Do básico ao intermediário: Template e Typename (V), falamos sobre templates e como poderíamos tirar proveito deles a fim de conseguir implementar diversos tipos de solução, com um esforço cada vez menor.
E considerando, que quanto menos esforço precisamos de fato fazer, significa mais produtividade e agilidade em desenvolver soluções diversas. Acredito que você, meu caro e estimado leitor, deva estar ansioso para começarmos a criar coisas voltadas a serem colocadas no gráfico. Isto a fim de gerar resultados realmente plausíveis. E não apenas ficar olhando informações sendo impressas no terminal. Como está sendo feito até este momento.
Porém, e é aqui onde a coisa começa a tomar corpo. Tudo que foi mostrado e visto até este momento. De fato, nos permitiu criar uma boa base de conhecimento e uma excelente e ampla base conceitual. Isto para que muitas coisas possam de fato serem criadas e implementadas com um esforço relativamente pequeno. Entretanto, mesmo com esta base conceitual, de fato ter sido construída e muito bem estruturada. Ainda assim, não vejo que é hora de iniciarmos uma codificação, a fim de colocar algo diretamente no gráfico. Não pelas possíveis condições de codificação. Mas sim, pelo fato, de que, apesar de tudo que foi mostrado nos permitir uma boa manipulação do código. Ainda não temos como estrutura adequadamente certas informações durante uma implementação real.
Precisamos assim, introduzir um novo conceito. E este de fato, uma vez completamente introduzido e explicado, nos possibilitará uma enorme quantidade de coisas. Visto que, teremos de fato, um mecanismo seguro, e bastante confiável. Que nos permitirá fazer as coisas de maneira mais rápida, ao mesmo tempo que nos exigirá cada vez menos esforço. Já que conforme formos aplicando tudo que já foi visto, mais o que ainda será mostrado. Evitará muitos erros básicos e chatos. Tornando assim, os artigos mais dinâmicos com relação ao tipo de material que poderei mostrar. E como deverá ser feita as explicações sobre o que estará ocorrendo. Isto sim, deixará as coisas bem mais interessantes.
Ok, então relaxe. Se acomode confortavelmente, e venha comigo, explorar e compreender este novo conceito. Que ao meu ver, é um divisor de águas. Já que ele nos dá muito mais possibilidades de programar e entender melhor como trabalhar com o MQL5. Mas vamos começar as coisas de maneira adequada. Iniciando um novo tópico.
Estruturas
Uma das coisas que ao meu ver, é a mais interessante, que será vista nesta fase inicial e básica de programação em MQL5. São as estruturas. Isto por que, se você de fato as compreender de maneira adequada, irá conseguir compreender todo o resto. E isto, literalmente. Já que o conceito de estrutura, fica mais ou menos no meio do caminho, entre uma programação básica e modesta. Onde simplesmente criamos variáveis e procedimentos. E uma programação completamente diferente. Onde organizamos o código em blocos completamente funcionais. Estes blocos são as classes de objeto. Mas isto será visto em outro momento. Depois que de fato, tivermos explorado, e o conceito de estrutura, esteja completamente sido assimilado e compreendido por você, meu caro leitor.
Um dos maiores erros de programadores iniciantes, é querer aprender as coisas na marra. Imaginando que vão conseguir fazer algum tipo de implementação, sem se fato, ter compreendido, como e por que, esta ou aquela ferramenta foi de fato necessária. Nenhuma ferramenta ou recurso presente em uma linguagem de programação, surgiu só por ser bonita ou atraente. Ela está ali, por conta que os desenvolvedores do compilador, viram a necessidade de que aquela ferramenta ou recurso, de fato estivesse presente na linguagem.
Durante o decorrer destes artigos, irei mencionar, recursos que existem no C e C++. Porém não foram implementados no MQL5, apesar de que o MQL5 se basear em grande parte no C e C++. Acredito, que o motivo, para que estes recursos não tenham sido implantados no MQL5, é justamente a não necessidade dos mesmos. Enquanto em alguns casos, acredito, que seja o grau de dificuldade relacionado a correta utilização de recursos presentes, principalmente em C++. Que mais confundem e complicam totalmente o código, do que realmente podem vir a serem uteis, para o que o MQL5, se propõem a fazer. Lembre-se de que o MQL5, tem como objetivo, nos permitir construir ferramentas para operações no mercado financeiro, usando para isto o MetaTrader 5. Já o C++, tem como objetivo, construir qualquer tipo de aplicação. Desde sistemas operacionais, até mesmo processos e aplicativos que irão ser executados de maneira autônoma ou não.
Um exemplo disto, é que você pode criar tudo usando C e C++. Até mesmo uma plataforma equivalente ao MetaTrader 5. No entanto, o trabalho necessário para se fazer isto, seria descomunal. Sendo mais simples e prático, utilizar algo que já existe, que no caso seria o MQL5. Mas para que possamos criar coisas com um grau de complexidade, realmente maior. E isto, usando o MQL5, precisamos de recursos e ferramentas mais avançadas. No caso o primeiro destes recursos, mais avançados que utilizaremos são as estruturas. Sem elas, até conseguiríamos produzir algo interessante. Porém, o grau de dificuldade seria assombrosamente muito maior.
Estruturas, podem assumir e conter um nível de complexidade muito grande. Muito maior do que você, meu caro leitor e entusiasta pode estar imaginando. Porém, vamos começar devagar. Mostrando as coisas aos poucos, para que você possa conseguir, ir assimilando e compreendendo como de fato estruturas funcionam. Acredite, você irá se surpreender com o nível de complexidade que elas podem assumir. E mesmo assim, elas ainda não conseguem lidar com certas situações. E por conta disto, é que foi necessário a criação de um outro tipo de estrutura, que para que possamos diferenciar entre elas. Acabou recebendo uma denominação especial, que são as classes. Mas isto será melhor compreendido, no decorrer dos artigos que serão postados.
Então vamos começar com uma estrutura bem simples e básica. Apenas para que possamos tocar nossos pés neste novo conceito. Este primeiro pode ser observado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. struct st_01 07. { 08. short value_01; 09. int value_02; 10. double value_03; 11. }; 12. 13. st_01 Info; 14. 15. Info.value_01 = -8096; 16. Info.value_02 = 78934; 17. Info.value_03 = 1e4 + 0.674; 18. 19. PrintFormat("Result of the sum of all values. %f", Info.value_01 + Info.value_02 + Info.value_03); 20. } 21. //+------------------------------------------------------------------+
Código 01
Este código 01, é um código muito, mas muito simples. Onde começamos a ver como uma estrutura é construída. Observe que a forma de ser fazer isto, ou seja, de se criar uma estrutura, é muito semelhante a forma de se criar uma união. Porém, aqui existe uma diferença entre ambos os recursos. Enquanto uma união, é criada de forma a tornar todos elementos presentes nela, pertencentes a uma mesma região da memória.
Uma estrutura é criada e pensada de forma que cada elemento presente nela, seja individual. Ou seja, uma estrutura seria como se fosse um tipo de variável complexa, podendo ter diversos elementos a fim de criar tal variável. Esta não é uma boa definição ou conceito. Isto para dizer o que de fato seria uma estrutura.
Porém, e é importante que você entenda isto, meu caro leitor. Esta primeira definição ou conceito, sobre estrutura, é sim uma forma adequada de pensar nas mesmas. Visto que torna mais simples entender outras propriedades da mesma. Então, neste primeiro instante, tome como base este conceito sobre estrutura.
Uma estrutura, seria uma forma de agrupar diversas variáveis, que estão de alguma forma correlacionadas entre si.
Conforme formos avançando nos estudos sobre estruturas, você entenderá que este conceito, se estende bastante. Assumindo diversas personalidades, o que acaba nos dando muita liberdade de criação. Ao mesmo tempo que torna cada vez mais simples de implementar coisas muito complicadas.
Mas vamos voltar ao nosso código inicial. Que pode ser visto em código 01. Bem, observe, que na linha seis estamos declarando uma estrutura. Assim como uniões, aqui no MQL5, não é possível definimos uma estrutura anônima. Sendo necessário, que venhamos a nomear a mesma. Como este é o primeiro contato. Estou fazendo, uso de algo muito parecido que foi feito, quando expliquei uniões. Ou seja, declaramos a estrutura em uma linha, e depois em outra linha declaramos a variável que irá utilizar a estrutura, propriamente dita. No caso estamos fazendo a declaração da variável, na linha treze. Note que é muito parecido com o que era feito nas uniões.
Já nas linhas quinze até dezessete, atribuímos valores a cada elemento da estrutura. Isto, como você pode notar, é muito similar ao que era feito, quando atribuímos valores a uma variável qualquer. Ou seja, aqui estamos fazendo uso de coisas básicas. Já na linha dezenove, imprimimos uma mensagem no terminal, informando algo. No caso, esta linha, irá produzir o que podemos ver na imagem logo abaixo.

Imagem 01
Como primeiro contato, acredito, que você tenha conseguido compreender muito bem, o que está acontecendo aqui. Isto por que, grande parte, já vem sendo explicado já a algum tempo. Somente o fato da linha seis, ser como é, que pode gerar algum tipo de desconfiança e receito. Porém, entendendo que, uma estrutura, seria o equivalente a uma união, no quesito de como deveria ser declarada. Todo o resto, fica muito mais simples de ser entendido. Ou seja, o conhecimento, vai se ampliando com o passar do tempo.
Ok, este foi fácil. No entanto, antes de passarmos para algo um tanto quanto mais elaborado. Existem algumas regras a serem observadas quando formos utilizar estruturas. Irei mostrar e explicar estas regras aos poucos, já que algumas podem não fazer muito sentido neste exato momento.
A primeira regra é:
Em MQL5 uma estrutura NUNCA pode ser CONSTANTE. Ela SEMPRE será uma variável.
Isto significa, que você não pode declarar uma estrutura, e que fique bem claro, aqui no MQL5, como sendo uma constante. Isto pelo simples motivo, de que, primeiro declaramos qual será o rotulo que utilizaremos como forma de acessar os dados dentro da estrutura, para somente depois, poder acessar estes mesmos dados. Ou seja, primeiro precisamos que a linha 13 vista no código 01, venha a existir. Para somente depois podermos fazer uso de alguma forma da estrutura.
Como para declarar uma constante, precisamos que o valor venha a ser definido, no momento em que a estamos declarando. Não é possível criar uma estrutura constante aqui no MQL5.
A segunda regra é:
A forma como as coisas são declaradas na estrutura, define a ordem que elas serão colocadas na memória.
Esta regra é muito importante. Ainda mais quando vamos utilizar estruturas de uma forma bem específica. Mas vamos com calma. Primeiro vamos entender uma coisa aqui, antes de aplicarmos esta regra número dois. Quando definimos uma união, a quantidade de bytes que serão necessários para comportar a união, será igual a quantidade do maior tipo presente dentro da própria união.
Porém, em se falando de estruturas, as coisas são um pouco quanto diferentes, por assim dizer. Para entender isto, vamos utilizar o mesmo código 01, e ver quanto de memória precisamos ali. Porém, para tornar as coisas mais claras e para que você entenda a diferença entre como uma estrutura e uma união, são vistas na memória. Vamos adicionar uma união com os mesmos elementos e tipos. Assim, surge o código visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. struct st_01 07. { 08. short value_01; 09. int value_02; 10. double value_03; 11. }; 12. 13. union un_01 14. { 15. short value_01; 16. int value_02; 17. double value_03; 18. }; 19. 20. PrintFormat("Size of struct is: [%d bytes]\nSize of union is: [%d bytes]", sizeof(st_01), sizeof(un_01)); 21. } 22. //+------------------------------------------------------------------+
Código 02
Observe aqui, meu caro leitor, que neste código 02, temos duas construções diferentes. Porém com os mesmos elementos e tipos. No entanto, apesar disto, ambas ocupam espaços diferentes, em termos de bytes. E isto pode ser notado olhando o resultado visto na imagem 02 logo na sequência.
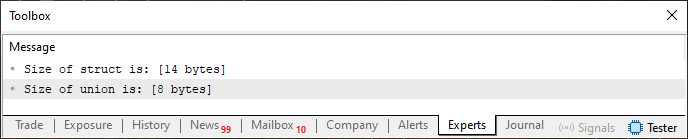
Imagem 02
Observe que a união necessita de oito bytes, já que o maior tipo presente nela é o tipo double. Que como já sabemos precisa de 8 bytes para ser representado. Já a estrutura, que contém os mesmos elementos, necessita de quatorze bytes. Isto por que, precisamos somar os oito bytes do tipo double, com quatro bytes do tipo int e mais dois do tipo short, totalizando assim os quatorze bytes que podemos ver. Porém vamos agora entender o que a regra dois está nos dizendo. Para isto, precisamos modificar novamente o código 02, para um outro código, que é visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. struct st_01 09. { 10. short value_01; 11. int value_02; 12. double value_03; 13. }; 14. 15. struct st_02 16. { 17. short value_01; 18. int value_02; 19. double value_03; 20. }; 21. 22. union un_01 23. { 24. st_01 data_01; 25. st_02 data_02; 26. }; 27. 28. un_01 Info; 29. 30. ZeroMemory(Info); 31. Info.data_01.value_01 = -18254; 32. 33. PrintX(Info.data_02.value_01); 34. } 35. //+------------------------------------------------------------------+
Código 03
Aqui neste código 03, temos uma construção que irá nos permitir entender a regra 02. Preste muita atenção ao que será feito aqui meu caro leitor. Pois isto poderá lhe ajudar imensamente no futuro. Aqui temos duas estruturas sendo declaradas. Ambas são exatamente IDENTICAS, tanto em número e quantidade de elementos. Assim como também o tipo de dado de cada um dos elementos. Porém a parte importante, além isto que estou dizendo, é o fato de que a ordem de declaração dos elementos, ser exatamente a mesma. E este é o ponto mais importante aqui.
Para tornar as coisas possíveis de serem compreendidas. Usamos uma união na linha 22. Esta estará ligando, as estruturas de forma que todos elementos estejam compartilhando o mesmo espaço de memória. Você obviamente já deve saber disto, não é mesmo meu caro leitor? Pois bem, agora preste atenção. Na linha trinta, estou dizendo para o compilador limpar completamente a região de memória onde a união se encontra. Ou seja, agora toda aquela região contém apenas zeros.
Ok, na linha 31 atribuímos um valor a alguma das variáveis presentes na estrutura. Pode ser qualquer uma. Mas note que estamos fazendo isto, utilizando a união como ponto de apoio. E no caso estamos atribuindo um valor a uma dada variável que está declarada na estrutura definida na linha oito. Com forma de testar o que estará acontecendo, usamos a linha 33 para imprimir o valor da mesma variável. Porém, neste caso, a variável, é a que se encontra presente na estrutura 02, que está sendo definida na linha 15. Como ambas estruturas estão compartilhando o mesmo bloco de memória. Obviamente o valor deverá ser o mesmo.
Então executando o código 03, você pode observar o que é visto logo abaixo.
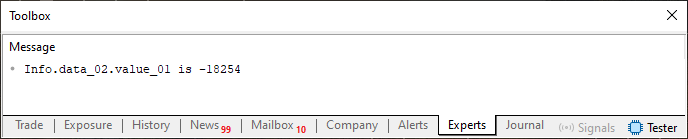
Imagem 03
Hum. Na de anormal aqui. Já que o valor apresentado é exatamente o mesmo que estamos atribuindo a variável, na linha 31. Como está tudo certo, você pode até estar me questionando: Por que você mencionou está regra número dois? Já que não houve nenhum tipo de alteração ali? Isto que você disse não faz o menor sentido. E não tem nenhum cabimento.
Ok. Eu estava equivocado, de fato não existe nenhum problema sendo criado aqui. Mas vamos fazer um outro teste. Porém desta vez vamos usar um outro código, de modo a visualizar tudo que está acontecendo na memória. Para isto, vamos modificar o código 03, para um outro, que pode ser visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. struct st_01 09. { 10. short value_01; 11. int value_02; 12. double value_03; 13. }; 14. 15. struct st_02 16. { 17. short value_01; 18. int value_02; 19. double value_03; 20. }; 21. 22. union un_01 23. { 24. st_01 data_01; 25. st_02 data_02; 26. uchar arr[sizeof(st_01)]; 27. }; 28. 29. un_01 Info; 30. 31. ZeroMemory(Info); 32. Info.data_01.value_01 = -18254; 33. 34. ArrayPrint(Info.arr); 35. 36. PrintX(Info.data_02.value_01); 37. } 38. //+------------------------------------------------------------------+
Código 04
Beleza, agora temos um código onde realmente podemos visualizar o que está acontecendo na memória da região indicada pela variável Info. Ao executar este código 04, você nota que podemos ver a imagem logo abaixo.
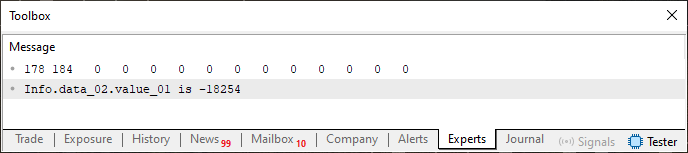
Imagem 04
E novamente está tudo como o esperado. Como este código 04, está fazendo uso de coisas já explicadas. Não vou entrar em detalhes sobre o que está sendo feito ali. Mas, e é agora que a coisa fica de fato interessante. Vamos pegar este código 04 e mudar um simples e misero detalhe nele. Este detalhe é mostrado no fragmento logo abaixo.
. . . 15. struct st_02 16. { 17. int value_02; 18. short value_01; 19. double value_03; 20. }; . . .
Fragmento 01
Agora, tendo feito esta modificação mostrada no fragmento 01, no código 04. Compilamos o mesmo novamente, e o executamos no terminal do MetaTrader 5. E você, deve estar pensando: Mas esta mudança não irá afetar em nada o conteúdo. Tão pouco irá afetar o resultado que iremos obter ao executar o código. Mas já que você insiste, vou experimentar só para provar que você está errado. E que definitivamente não sabe o que está falando. Então ao executar o código você obtém o que é visto na imagem 05, logo abaixo.
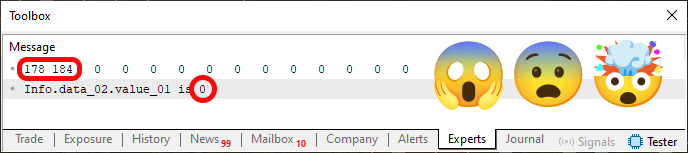
Imagem 05
Ai meu DEUS. O que é isto daqui? Como isto é possível? Há, já sei, é um bug. Ou melhor, você está manipulando a imagem. É uma pegadinha do malandro isto que estou vendo na imagem 05. E você não vai me enganar. Achou que eu não iria perceber? Achou errado. Bem, meu caro leitor, isto NÃO É nenhuma pegadinha. É um fato real, e que pode ser perfeitamente reproduzido. Desde que você faça o que foi dito. Que é colocar o fragmento 01 no código 04. Mas porque, apesar do conteúdo da memória continuar inalterado, tivemos um retorno diferente, ao lermos a variável? Bem, o motivo é que estamos lendo NÃO a variável, e sim a posição de memória onde ela está sendo utilizada.
Isto pode parecer um tanto quanto estranho. E até mesmo bem fora do que seria o consenso comum. Já que no código 04, tanto a estrutura 01, quanto a estrutura 02, possuem os mesmos tipos de dados. Assim como também, possui variáveis com o mesmo nome. Assumindo que estamos utilizando uma união para "simular" um movimento de arquivo. Não faz muito sentido, que o valor pudesse vir a ser modificado, pelo simples fato de termos mudado uma variável de lugar, durante a declaração da estrutura.
Porém, e é aqui onde realmente mora a importância da regra número dois. Você, deve por um instante ignora o fato de que estamos executando o código em memória. E deve começar a pensar nele, como algo um pouco maior. Pense no seguinte fato, quando gravamos um arquivo, armazenamos as informações em uma dada sequência lógica. Porém, muitas vezes, nos é de interesse, guardar e carregar dados em um tipo de estrutura lógica.
Você pode ver isto, sendo feito em arquivos de imagem por exemplo. Neste caso, temos no começo do arquivo, algo que é conhecido como cabeçalho. Os dados presentes ali, fazem parte de uma estrutura de dados. No entanto, você pode basicamente os ler de duas maneiras. Uma é um valor de cada vez. A outra é fazendo uso de uma estrutura especialmente construída para isto.
Para que você entenda vamos pegar o exemplo mais simples de estrutura de dados. O conhecido padrão BitMap. Quando uma imagem bitmap é armazenada ou precisa ser lida de um disco. Temos no começo do arquivo de imagem, uma estrutura que formada por uma sequência de campos. Esta sequência, que na verdade é uma estrutura, nos informa: Como a imagem está formada. Que tipo de imagem existe ali. Que tipo de estrutura está sendo utilizada para modelar a imagem. As dimensões da imagem, entre diversas outras coisas.
Como a estrutura do arquivo segue um formato específico. Você pode usar as informações contidas em BMP File Format, para conseguir reproduzir a imagem da maneira como você assim achar melhor. Da mesma forma que podemos ler a imagem, também podemos manipular os dados presentes ali. Mas o ponto importante, e é daí que surge a necessidade de entender a regra número dois. Se você, meu caro leitor, estiver implementado alguma aplicação, que vier a salvar dados em disco. Daí, passado um tempo, venha a mudar a estrutura criada inicialmente, por ter notado que ela pode ficar melhor, se organizada de uma outra maneira. Poderá ter problemas, ao tentar reaver antigos dados gravados no passado. Isto justamente por conta que a posições das variáveis, simplesmente mudou com o tempo.
Por isto é importante, que você, consiga entender este conceito. De que estruturas devem ser pensadas, quanto ao seu objetivo final. Já que se a intenção é manter tudo apenas em memória. Pode ser que você não precise mexer muito nos dados, e que não venha a precisar se preocupar com a ordem de declaração das coisas. No entanto, se o objetivo, é transferir informações entre pontos diferentes. Ou mesmo armazenar as informações para um uso futuro. É bom que você crie algum tipo de mecanismo, para fixar a estrutura em algum tipo de versão. Assim, conforme você for mudando as coisas, deverá mudar também a versão da estrutura que estará sendo criada. Se tudo for perfeitamente pensado e mantido, você conseguirá ler dados armazenados de maneira muito antiga. Com uma versão de estrutura muito mais recente.
Talvez este tipo de coisa, da qual eu esteja falando, pode não fazer muito sentido, ainda mais neste primeiro momento. Já que, antes de pensarmos em modelagem de dados, precisamos entender e estudar outros conceitos, que estão diretamente ligados a questão das estruturas.
Porém para deixar as coisas um tanto mais interessante, e para que você de fato entenda o que estou querendo mostrar. Vamos fazer uma pequena brincadeira. Não é algo complexo. Na verdade é até bem simples. E com todos os conceitos vistos até aqui, será algo que você conseguirá entender sem muita dificuldade. Veja o código abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+----------------+ 06. #define def_FileName "Testing.bin" 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. struct st_01 11. { 12. short value_01; 13. int value_02; 14. double value_03; 15. }Info; 16. 17. int handle; 18. 19. ZeroMemory(Info); 20. 21. PrintFormat("Size of struct is %d bytes", sizeof(Info)); 22. 23. if ((handle = FileOpen(def_FileName, FILE_READ | FILE_BIN)) != INVALID_HANDLE) 24. PrintFormat("Reading %d bytes of file data.", FileReadStruct(handle, Info)); 25. else 26. { 27. Info.value_01 = -8096; 28. Info.value_02 = 78934; 29. Info.value_03 = 1e4 + 0.674; 30. 31. PrintFormat("Writing %d bytes of data in the file.", FileWriteStruct(handle = FileOpen(def_FileName, FILE_WRITE | FILE_BIN), Info)); 32. } 33. FileClose(handle); 34. 35. PrintX(Info.value_01); 36. PrintX(Info.value_02); 37. PrintX(Info.value_03); 38. } 39. //+------------------------------------------------------------------+
Código 05
Quando executamos este código 05, será mostrado no terminal o que é visto logo abaixo.
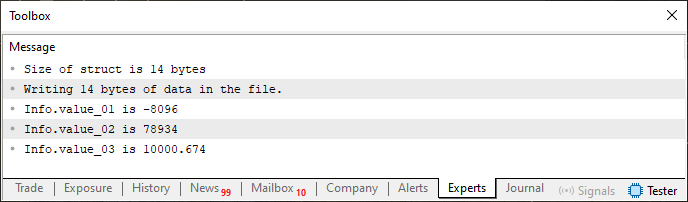
Imagem 06
Você nota que aqui, estamos primeiramente escrevendo no arquivo. Já que o mesmo não existia. Caso você esteja curioso, pode abrir o arquivo, usando algum editor hexadecimal. E neste caso, você poderá visualizar o que é visto na imagem logo na sequência.

Imagem 07
Isto seria o mesmo tipo de conteúdo que estaria presente na memória, caso você viesse a usar uma união para visualizar a região. Mas esqueça isto por hora. Já que isto não é de fato importante neste exato momento. O que nos interessa aqui é o seguinte: Quando você vier a executar novamente o código 05, e isto sem o modificar, ou mesmo deletar ou modificar o conteúdo do arquivo, que pode ser visto na imagem 07. Irá obter no terminal do MetaTrader 5, o que é visualizado logo abaixo.
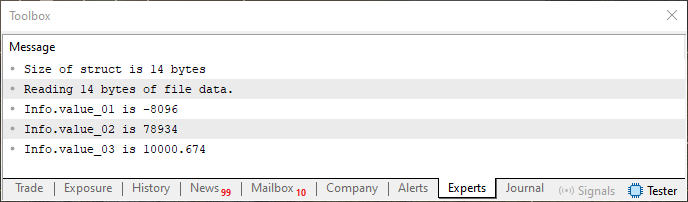
Imagem 08
Claramente você nota que é a mesma informação. Agora, e sugiro que você apenas mude a ordem das variáveis da estrutura, que está sendo declarada na linha dez do código 05. E sem mexer em mais nada compile novamente o código, e o execute. Compare os resultados obtido anteriormente, que podem ser visualizados nas imagens anteriores. Com o resultado visto no terminal, quando o código 05 é novamente executado com as mudanças na ordem de declaração das variáveis. Pense a respeito do que aconteceu e compare com o que foi visto, quando usávamos a união para efetuar o mesmo tipo de análise.
Apesar de não termos ainda falando sobre gravação e leitura de arquivos. Este código 05, que estará disponível no anexo. É muito simples, prático e direto. Podendo ser muito facilmente compreendido, com base no que foi explicado até este presente artigo. Sendo que as únicas partes que podem gerar algum questionamento, pode perfeitamente ser compreendido, lendo a documentação. Que são as funções de biblioteca: FileOpen, FileWriteStruct, FileReadStruct e FileClose. Mas mesmo estas são bem fáceis de entender. Não necessitando assim de nenhuma outra informação ou comentário adicional, para uma perfeita compreensão do que foi mostrado aqui.
Considerações finais
Este daqui foi o primeiro artigo a respeito de estruturas no MQL5. Para começar da maneira correta, precisamos compreender diversos conceitos que precisam ser aplicados a estruturas. Sei que este primeiro contato, pode não ter sido assim tão emocionante. Porém, você deve ter notado, que é de fato necessário entender o que foi explicado nos artigos anteriores. Sem aqueles conceitos, devidamente compreendidos. Entender o que começamos a fazer aqui, será algo muito mais difícil e confuso.
Por conta disto é necessário praticar e procurar entender o que está sendo feito, e os resultados que estão sendo gerados. De qualquer forma, faça uso dos arquivos presentes no anexo, para praticar este primeiro conta. Procurando entender as duas regras que forma demonstradas aqui neste artigo. Pois as mesmas serão muito importantes em breve.
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Aprendendo MQL5 do iniciante ao profissional (Parte V): Principais operadores de redirecionamento do fluxo de comandos
Aprendendo MQL5 do iniciante ao profissional (Parte V): Principais operadores de redirecionamento do fluxo de comandos
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso