
初級から中級まで:構造体(I)

はじめに
前回の「初級から中級まで:テンプレートとtypename (V)」では、テンプレートについて解説し、それらを用いて、より少ない労力でさまざまな解決策を実装できることを説明しました。
投入する労力が少なくなればなるほど、私たちはより多くの成果を、より高い生産性で生み出せるようになります。そのため、読者の皆さんも、いよいよチャート上に配置される何かを作り始めたいと感じているのではないでしょうか。これまでのように、ターミナルに情報が出力されるのを眺めるだけではなく、目に見える結果を生成したいと考えるのは自然なことです。
しかしながら(ここから話が具体化していきますが)、これまでに学んできた内容は、あくまで確固たる知識の基盤を築くためのものでした。この基盤があるからこそ、比較的少ない労力で多くのものを作成し、実装できるようになります。とはいえ、この概念的な土台が十分に整ってきたとはいえ、まだチャートと直接やり取りするコードを書き始める段階には至っていないと私は考えています。これは、潜在的なコーディング上の制約が理由なのではなく、実際の実装において特定の情報を適切に構造化するための手段が、まだ不足しているためです。
そのため、新しい概念を導入する必要があります。この概念は、非常に多くのことを実現可能にしてくれます。安全で信頼性の高い実際の仕組みを得ることで、より少ない労力で、より高速に作業できるようになります。これまでに学んできたすべての内容に、これから探求する要素を加えることで、基本的で煩わしいエラーの多くを回避できるようになるでしょう。その結果、記事の内容や説明はより動的なものとなり、学習体験そのものも、はるかに興味深いものになります。
それでは、腰を落ち着けて、この新しい概念を一緒に探求し、理解していきましょう。私の見解では、これは転換点となるものであり、プログラミングにおける可能性を大きく広げ、MQL5の扱い方に対する理解をさらに深めてくれます。それでは、新しいトピックの導入から、正式に始めていきます。
構造体
MQL5プログラミングの初期かつ基礎的な段階で学ぶ内容の中でも、最も興味深いもののひとつが構造体です。これを正しく、そして本質的に理解できれば、他のすべての概念も理解できるようになります。文字どおりです。構造体という概念は、単に変数や手続きを作成するだけのシンプルなプログラミングと、コードを完全に機能するブロックとして整理するまったく別のパラダイムとの中間に位置しています。その後者のブロックが、オブジェクトクラスです。ただし、クラスについては、構造体の概念を十分に理解した後で取り上げます。
初心者プログラマーが犯しがちな最大の誤りのひとつは、物事を遠回りな方法で学ぼうとすることです。彼らは、ある機能やツールがなぜ必要なのか、どのような理由で存在しているのかを本当に理解しないまま、何かを実装できると考えてしまいます。しかし、プログラミング言語におけるツールや機能は、見た目が良いから、あるいは魅力的だから存在しているわけではありません。コンパイラの開発者が、その機能やツールが言語に必要であると判断したからこそ、そこに存在しているのです。
これらの記事を通じて、私はCやC++には存在するものの、MQL5には実装されていない機能について言及することがあります。MQL5は、これらの言語を大きく基盤としているにもかかわらずです。私の考えでは、これらの機能がMQL5に含まれていない理由は、単純に「必要ない」からです。場合によっては、特定の機能を正しく使用するために伴う複雑さ、特にC++における複雑さが、MQL5の目的においては利点よりも混乱や複雑化を招いてしまうため、あえて採用されていないのだと思われます。MQL5は、MetaTrader 5を用いて金融市場向けのツールを構築するために設計されています。一方でC++は、オペレーティングシステムから自律型・非自律型のプロセスやアプリケーションに至るまで、あらゆる種類のソフトウェアを構築することを目的としています。
たとえば、CやC++を使えば、MetaTrader 5に相当するプラットフォームさえも構築することが可能です。しかし、そのために必要となる作業量は膨大なものになります。既に存在するMQL5のようなものを利用する方が、はるかに簡単で実用的です。ただし、MQL5でより高度な複雑性を持つものを作成しようとする場合には、より進んだツールや機能が必要になります。その最初の高度なリソースが、構造体です。構造体がなければ、何か興味深いものを作ることは可能かもしれませんが、その難易度は圧倒的に高くなってしまいます。
構造体は、皆さんが想像している以上に、高いレベルの複雑性を持つことができます。しかし、ここでは急がず、ひとつひとつ段階的に説明していき、構造体が実際にどのように機能するのかを理解できるようにします。信じていただければと思いますが、構造体が到達し得る複雑さのレベルには、きっと驚かされるはずです。それでもなお、構造体だけでは対応できない状況も存在します。そのため、別の種類の構造が作られ、通常の構造体と区別するために特別な名称が与えられました。それが「クラス」です。ただし、これについては今後の記事で詳しく扱います。
それでは、シンプルで基本的な構造体から始めていきましょう。最初の例を、以下に示します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. struct st_01 07. { 08. short value_01; 09. int value_02; 10. double value_03; 11. }; 12. 13. st_01 Info; 14. 15. Info.value_01 = -8096; 16. Info.value_02 = 78934; 17. Info.value_03 = 1e4 + 0.674; 18. 19. PrintFormat("Result of the sum of all values. %f", Info.value_01 + Info.value_02 + Info.value_03); 20. } 21. //+------------------------------------------------------------------+
コード01
コード01は、構造体がどのように構築されるのかを理解し始めるための、非常にシンプルなコード例です。ご覧のとおり、構造体の作成方法は共用体の作成方法と非常によく似ています。ただし、この2つの間には重要な違いがあります。共用体は、その内部に含まれるすべての要素が、同一のメモリ領域を共有するように作成されます。
一方、構造体は、内部の各要素がそれぞれ独立したものとして扱われるように作成され、設計されています。言い換えると、構造体は複数の要素を保持できる複合的な変数型のように振る舞います。ただし、これは構造体の本質を完全に表した定義ではありません。
しかしながら、ここは特に理解していただきたい点ですが、構造体を最初に捉える概念としては、この考え方は正しいものです。このように理解することで、構造体が持つ多くの特性を簡単に把握できるようになります。したがって、現時点では次の定義を、構造体に対する作業上の概念として受け取ってください。
構造体とは、何らかの関連性を持つ複数の変数をひとつにまとめる方法です。
構造体の学習を進めていくにつれて、この概念が大きく拡張され、さまざまな「性格」を持つようになることが理解できるでしょう。それにより、非常に複雑なものを、ますます簡単に実装できるようになり、同時に高い創造性も得られるようになります。
コード01に示された最初のコードに戻りましょう。6行目では、構造体を宣言しています。共用体と同様に、MQL5では無名の構造体を定義することはできないため、必ず名前を付ける必要があります。今回は、構造体という概念に初めて触れる段階であるため、共用体を説明したときと同じアプローチを採用しています。つまり、まず1行で構造体を宣言し、その後、別の行でその構造体を使用する変数を宣言しています。この例では、変数の宣言は13行目にあります。共用体の例と非常によく似ていることが分かるでしょう。
続いて、15行目から17行目にかけて、構造体の各要素に値を代入しています。ご覧のとおり、これは通常の変数に値を代入する場合とほとんど同じです。これらはすべて基本的な要素です。そして19行目では、ターミナルにメッセージを出力しています。この行を実行すると、以下の画像に示されている結果が表示されます。

図01
初めて触れる内容としては、ここで何が起きているのかを十分に理解できたのではないかと思います。内容の大部分は、すでに前回までに説明してきたものです。唯一、06行目については、その性質上、多少の疑問や戸惑いを感じたかもしれません。しかし、構造体は宣言方法という点において基本的に共用体と同等である、と理解できれば、それ以外の部分は非常に分かりやすくなります。知識というものは、時間とともに少しずつ広がっていくものです。
さて、ここまでは非常に簡単でした。ただし、もう少し踏み込んだ内容に進む前に、構造体を使用する際に必ず守らなければならないいくつかのルールがあります。これらのルールの中には、現時点ではあまり意味が分からないものもあるかもしれませんので、段階的に説明していきます。
最初のルールは次のとおりです。
MQL5では、構造体を定数として定義することは決してできません。構造体は常に変数になります。
これは、MQL5において構造体を定数として宣言することができない、という意味です。その理由は、構造体内のデータにアクセスするためには、まずその構造体を参照するための識別子を宣言する必要があるということです。つまり、コード01で示した13行目の宣言が存在しなければ、構造体をいかなる形でも使用することはできません。
一方、定数を宣言する場合には、その宣言時点で値が確定していなければなりません。そのため、MQL5では構造体を定数として作成することは不可能なのです。
2番目のルールは次のとおりです。
構造体の内部で要素を宣言する順序によって、メモリ上での配置順序が決まります。
このルールは、特定の方法で構造体を使用する場合に特に重要になります。ただし、焦らず順を追って見ていきましょう。まず、ルール02を適用する前に、次の点を理解しておく必要があります。共用体を定義した場合、それを格納するために必要なバイト数は、その共用体に含まれる最大サイズのメンバの大きさと等しくなります。
しかし、構造体の場合は事情が少し異なります。これを理解するために、コード01を再び利用し、どれだけのメモリが必要になるのかを確認してみましょう。構造体と共用体がメモリ上でどのように配置されるかの違いをより明確に理解するために、同じ要素と型を持つ共用体を追加します。これにより、次に示すコードが得られます。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. struct st_01 07. { 08. short value_01; 09. int value_02; 10. double value_03; 11. }; 12. 13. union un_01 14. { 15. short value_01; 16. int value_02; 17. double value_03; 18. }; 19. 20. PrintFormat("Size of struct is: [%d bytes]\nSize of union is: [%d bytes]", sizeof(st_01), sizeof(un_01)); 21. } 22. //+------------------------------------------------------------------+
コード02
ここで注目していただきたいのは、コード02には2つの異なる構造が存在しているにもかかわらず、含まれている要素と型はまったく同じであるという点です。それにもかかわらず、両者が使用するメモリ量(バイト数)は異なっています。このことは、下に示す図02の結果を見ることで確認できます。
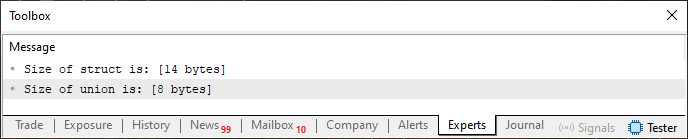
図02
ご覧のとおり、共用体は8バイトを必要としています。これは、共用体内で最も大きな型がdouble型であり、double型は(すでにご存じのとおり)表現に8バイトを必要とするためです。一方、同じ要素を含んでいる構造体は14バイトを必要とします。これは、double型の8バイトに加え、int型の4バイト、さらにshort型の2バイトを合計した結果であり、図に示されている14バイトという値になります。では次に、ルール02が何を意味しているのかを理解していきましょう。そのために、コード02をさらに修正し、次に示すコードへと変更します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. struct st_01 09. { 10. short value_01; 11. int value_02; 12. double value_03; 13. }; 14. 15. struct st_02 16. { 17. short value_01; 18. int value_02; 19. double value_03; 20. }; 21. 22. union un_01 23. { 24. st_01 data_01; 25. st_02 data_02; 26. }; 27. 28. un_01 Info; 29. 30. ZeroMemory(Info); 31. Info.data_01.value_01 = -18254; 32. 33. PrintX(Info.data_02.value_01); 34. } 35. //+------------------------------------------------------------------+
コード03
ここでコード03では、ルール02を理解するのに役立つ構造体を示します。ここでおこなわれることに十分注意してください。これは将来、大いに役立ちます。この例では、2つの構造体が宣言されています。両方とも同一であり、要素の数や量、各要素のデータ型も同じです。しかし重要なのは、要素の宣言順序がまったく同じであることです。ここが最も重要なポイントです。
理解を容易にするため、22行目で共用体を使用しています。この共用体は2つの構造体を結びつけ、すべての要素が同じメモリ空間を共有するようにします。これについては既にご存知だと思います。では注目してください。30行目で、コンパイラに共用体が配置されているメモリ領域全体を完全にクリアするよう指示しています。言い換えれば、その領域は今やすべてゼロで埋め尽くされました。
31行目では、構造体内の変数のひとつに値を代入します。どの変数でも構いません。しかし注目すべきは、共用体を参照点として値を代入していることです。今回の場合、08行目で定義された構造体の変数に値を代入しています。動作確認のため、33行目で同じ変数の値を出力します。ただし、この場合読み出す変数は、15行目で定義された構造体02のものです。両方の構造体が同じメモリ領域を共有しているため、当然値は同じであるはずです。
したがって、コード03を実行すると、以下に示す結果を確認できます。
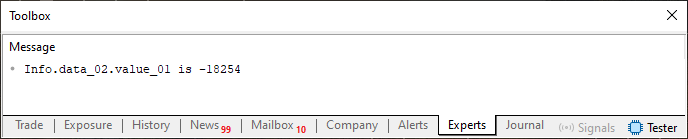
図03
ここでは特に異常は見られません。表示される値は31行目で代入した値とまったく同じです。すべて正しいように見えます。こう疑問に思うかもしれません。「ルール02に触れると言っていたのに、何も変化がなかったではないか。意味が分からない」と。
ええ、私の説明が間違っていました。確かに、ここでは問題は発生していません。しかし、次に別のテストをおこないましょう。今回はメモリ上で起こっていることをすべて視覚化できるよう、コード03を別バージョンに変更します。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. struct st_01 09. { 10. short value_01; 11. int value_02; 12. double value_03; 13. }; 14. 15. struct st_02 16. { 17. short value_01; 18. int value_02; 19. double value_03; 20. }; 21. 22. union un_01 23. { 24. st_01 data_01; 25. st_02 data_02; 26. uchar arr[sizeof(st_01)]; 27. }; 28. 29. un_01 Info; 30. 31. ZeroMemory(Info); 32. Info.data_01.value_01 = -18254; 33. 34. ArrayPrint(Info.arr); 35. 36. PrintX(Info.data_02.value_01); 37. } 38. //+------------------------------------------------------------------+
コード04
さて、これで変数Infoが参照しているメモリ領域で実際に何が起こっているのかを視覚的に確認できるコードができました。コード04を実行すると、以下の画像が表示されます。
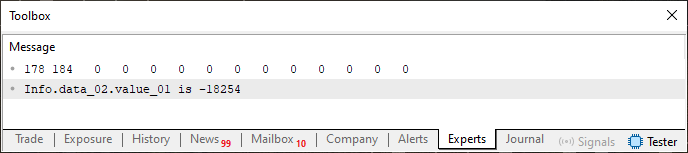
図04
そして、再び、すべてが期待どおりに動作します。コード04では既に説明した概念が使われているため、そこでおこなわれていることについて詳細に触れることはしません。しかし、ここからが本当に興味深いところです。コード04を取り、たったひとつの小さな変更を加えます。この変更は以下のフラグメントに示されています。
. . . 15. struct st_02 16. { 17. int value_02; 18. short value_01; 19. double value_03; 20. }; . . .
フラグメント01
フラグメント01で示された変更をコード04に適用した後、再度コンパイルし、MetaTrader 5ターミナルで実行します。この変更は、内容にも、コード実行時の結果にも、何も影響を与えないと思うかもしれません。しかし、どうしても気になるなら、証明するために試してみましょう。コードを実行すると、以下の画像05の結果が得られます。
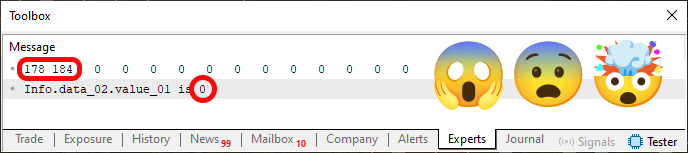
図05
「これは一体どういう奇妙なことなのでしょうか。どうしてこんなことが可能なのでしょうか。ああ、わかりました。これはバグです。それより、図05の画像を操作しているのですね。何かのいたずらで、私を騙そうとしているのですね。私が気づかないと思ったのですか。」違います。しかし、親愛なる読者の皆さん、これはいたずらではありません。フラグメント01をコード04に挿入すれば、簡単に再現できます。しかし、なぜメモリ内容は変わっていないのに、変数を読み取ったときに異なる値が得られたのでしょうか。私たちが変数そのものを読んでいるのではなく、その変数が解釈されるメモリの位置を読んでいるからです。
これは少し奇妙で、直感に反するように思えるかもしれません。結局のところ、コード04では構造体01も構造体02も同じデータ型を持ち、同じ名前の変数があります。共用体を使って「ファイルマップ領域」をシミュレートしているので、構造体内で変数の順序を変えただけで値が変わるのは意味がなさそうに思えます。
ここで、ルール02の重要性が本当に現れるのですが、メモリ上でコードを実行している事実を一時的に無視する必要があります。もっと大きな視点で考え始めなければなりません。次の事実を考えてみてください。ファイルを保存するとき、情報は特定の論理的な順序で保存されます。しかし、多くの場合、データを論理構造に従って保存し、読み込むことが望ましいのです。
たとえば、画像ファイル形式を見てみましょう。そのようなファイルの先頭にはヘッダと呼ばれる領域があります。そこに存在するデータはデータ構造に属しています。このデータを読む方法は2通りあります。一度に1つの値として読むか、またはそれ専用に設計された構造体を使って読むかです。
理解を助けるために、最も単純なデータ構造の例として、よく知られたビットマップ形式を取り上げます。ビットマップ画像をディスクに保存する場合や読み込む必要がある場合、ファイルの先頭にはフィールドの並びで構成された構造体があります。この並びは、実際には構造体であり、画像の形成方法、画像の種類、画像をモデル化するために使用される構造、画像の寸法などを教えてくれます。
ファイル形式は特定のレイアウトに従っているため、BMPファイル形式の仕様に従えば、画像を任意に再現することができます。同様に、そこに保存されたデータを操作することも可能です。しかし重要な点、そしてルール02を理解することが不可欠な理由はここにあります。アプリケーションを作成してデータをディスクに保存し、後になって構造体をより整理された形に変更したいと思った場合、以前に保存されたデータを復元しようとすると問題に直面する可能性があります。これは、変数の位置が時間とともに変わったためです。
だからこそ、構造体は最終目的を考えて設計することが重要です。すべてをメモリ内に保持するだけが目的であれば、データを変更したり宣言順序を気にしたりする必要はないかもしれません。しかし、情報を異なるポイント間で転送したり、将来使用するために保存したりする場合は、構造体のバージョン管理の仕組みを作るべきです。こうすることで、変更があった場合でも構造体のバージョンを更新できます。計画的に管理されていれば、非常に古い保存データも新しい構造体バージョンで読み取ることが可能です。
ここで説明していることは、まだこの段階ではあまり意味が分からないかもしれません。データモデリングについて考える前に、構造体に直接関連する他の概念を理解し、学ぶ必要があります。
しかし、話を少し面白くし、私が伝えようとしていることを本当に理解してもらうために、簡単な実験をしましょう。複雑ではありません。実際、非常に簡単です。そしてこれまでに学んだすべての概念を使えば、問題なく理解できるでしょう。以下のコードを見てください。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+----------------+ 06. #define def_FileName "Testing.bin" 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. struct st_01 11. { 12. short value_01; 13. int value_02; 14. double value_03; 15. }Info; 16. 17. int handle; 18. 19. ZeroMemory(Info); 20. 21. PrintFormat("Size of struct is %d bytes", sizeof(Info)); 22. 23. if ((handle = FileOpen(def_FileName, FILE_READ | FILE_BIN)) != INVALID_HANDLE) 24. PrintFormat("Reading %d bytes of file data.", FileReadStruct(handle, Info)); 25. else 26. { 27. Info.value_01 = -8096; 28. Info.value_02 = 78934; 29. Info.value_03 = 1e4 + 0.674; 30. 31. PrintFormat("Writing %d bytes of data in the file.", FileWriteStruct(handle = FileOpen(def_FileName, FILE_WRITE | FILE_BIN), Info)); 32. } 33. FileClose(handle); 34. 35. PrintX(Info.value_01); 36. PrintX(Info.value_02); 37. PrintX(Info.value_03); 38. } 39. //+------------------------------------------------------------------+
コード05
コードを実行すると、ターミナルには以下のような表示が現れます。
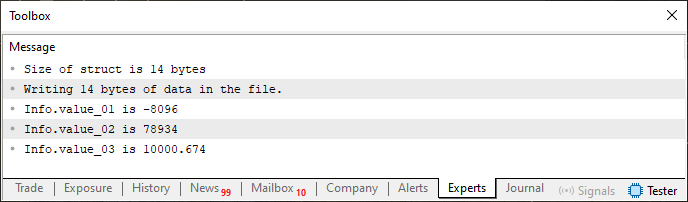
図06
ここでは、最初にファイルを書き込んでいることが分かります。なぜなら、以前はそのファイルが存在しなかったからです。もし興味があれば、ファイルを16進エディタで開くこともできます。その場合、次の画像に示されている内容が確認できるでしょう。

図07
これは、共用体を使ってメモリ領域を調べた場合に存在する内容と同じ種類のデータです。しかし、現時点では特に重要ではないため、これは忘れて構いません。ここで重要なのは、コード05を何も変更せず、ファイルの内容(図07に示されているもの)も削除したり改変したりせずに再度実行すると、MetaTrader 5のターミナルには以下の内容が表示されるということです。
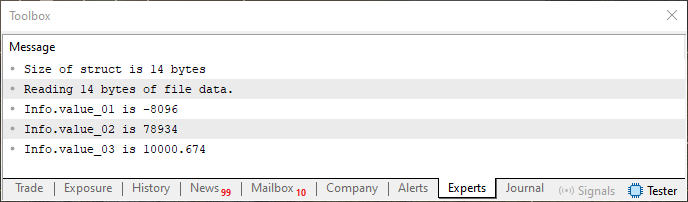
図08
明らかに、同じ情報が表示されていることが分かります。では、次に提案です。コード05の10行目で宣言された構造体内の変数の順序だけを変更してください。他の部分には触れず、コードを再コンパイルして実行します。そして、以前の画像で示した結果と、変数の順序を変更した後にターミナルに表示される結果を比較してください。何が起こったのかを考え、共用体を使って同じ種類の解析を行ったときに観察したことと比較してみてください。
ファイルの読み取りと書き込みについてはまだ正式には説明していませんが、添付ファイルで提供されるコード05は非常に単純です。これまでの記事で説明した内容を理解していれば、簡単に理解できます。疑問が生じるかもしれない部分も、ドキュメント、特にライブラリ関数であるFileOpen、FileWriteStruct、FileReadStruct、FileCloseを読めば十分に明確になります。しかし、これらも理解しやすく、ここで示した内容を完全に理解するために追加の解説は必要ありません。
最終的な考察
これは、MQL5における構造体に関する最初の記事でした。正しく始めるためには、構造体に適用されるさまざまな概念を理解する必要があります。この最初の接触は、特にワクワクするものではなかったかもしれません。しかし、前回の記事で説明された内容を理解することが絶対に必要であることに気づいたはずです。これらの概念を正しく吸収していなければ、ここで始めようとしていることを理解するのははるかに難しく、混乱してしまうでしょう。
このため、実際に手を動かして練習し、おこなわれていることや得られる結果を理解しようと努めることが不可欠です。いずれにせよ、添付ファイルを使ってこの最初の接触を練習し、本記事で示された二つのルールを理解することに重点を置いてください。これらのルールは、非常に近いうちに非常に重要になります。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15730
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索