
Del básico al intermedio: Struct (I)

Introducción
En el artículo anterior, "Del básico al intermedio: Plantilla y Typename (V)", hablamos sobre las plantillas y sobre cómo podríamos aprovecharlas para implementar diversos tipos de solución con cada vez menos esfuerzo.
Y, teniendo en cuenta que cuanto menos esfuerzo necesitamos hacer, mayor es la productividad y la agilidad para desarrollar distintas soluciones, creo que, querido y estimado lector, estarás deseando que empecemos a crear cosas para colocar en el gráfico. El objetivo es generar resultados realmente plausibles y no solo mirar información impresa en el terminal, como se ha hecho hasta ahora.
Aunque —y aquí es donde la cosa empieza a tomar forma— todo lo que se mostró y se ha visto hasta ahora nos ha permitido crear una buena base de conocimientos y una base conceptual excelente y amplia. Así, muchas cosas pueden crearse e implementarse con un esfuerzo relativamente pequeño. Sin embargo, aunque esta base conceptual se ha construido y estructurado muy bien, aún no es hora de iniciar una codificación para colocar algo directamente en el gráfico. No por las posibles condiciones de codificación, sino porque, a pesar de que nos permite manipular el código, aún no tenemos forma de estructurar adecuadamente cierta información durante una implementación real.
Por tanto, necesitamos introducir un nuevo concepto. Una vez que esté completamente introducido y explicado, nos permitirá hacer muchas cosas. Tendremos, en verdad, un mecanismo seguro y bastante fiable que nos permitirá hacer las cosas de manera más rápida y exigirá cada vez menos esfuerzo. A medida que vayamos aplicando todo lo que ya se ha visto y lo que aún se mostrará, se evitarán muchos errores básicos y molestos. De este modo, los artículos serán más dinámicos en relación con el tipo de material que podré mostrar y la forma en que deberán realizarse las explicaciones sobre lo que ocurrirá. Esto sí que hará las cosas mucho más interesantes.
Bueno, pues relájate. Ponte cómodo y ven conmigo a explorar y comprender este nuevo concepto que, en mi opinión, es un punto de inflexión. Nos ofrece muchas más posibilidades para programar y entender cómo trabajar con MQL5. Pero empecemos con buen pie, creando un nuevo tema.
Estructuras
Una de las cosas más interesantes que se verán en esta fase inicial y básica de programación en MQL5 son las estructuras. Esto es porque, si las comprendes de forma adecuada, podrás comprender todo lo demás. Y esto es literalmente así. El concepto de estructura se encuentra a medio camino entre una programación básica, en la que simplemente creamos variables y procedimientos, y una programación completamente diferente, en la que organizamos el código en bloques funcionales. Estos bloques son las clases de objeto. Pero eso lo veremos en otro momento. Pero esto se abordará en otro momento, después de haber explorado el concepto de estructura y de haberlo asimilado y comprendido completamente.
Uno de los mayores errores de los programadores principiantes es querer aprender las cosas a la fuerza, imaginando que van a poder hacer algún tipo de implementación sin haber comprendido realmente cómo y por qué esta o aquella herramienta fue, en efecto, necesaria. Ninguna herramienta o recurso presente en un lenguaje de programación surgió solo por ser bonita o atractiva. Está allí por esta razón: los desarrolladores del compilador vieron la necesidad de que esa herramienta o recurso estuviera presente en el lenguaje.
A lo largo de estos artículos, mencionaré recursos que existen en C y C++, pero que no se implementaron en MQL5, a pesar de que MQL5 se basa en gran medida en C y C++. Creo que el motivo por el que estos recursos no se han implementado en MQL5 es precisamente porque no se necesitan. En algunos casos, creo que se debe al grado de dificultad relacionado con el uso correcto de los recursos, principalmente los de C++, que pueden llegar a ser útiles para lo que MQL5 se propone hacer, pero que complican y confunden totalmente el código. Recuerda que MQL5 tiene como objetivo permitirnos construir herramientas para operar en el mercado financiero usando MetaTrader 5, mientras que C++ tiene como objetivo construir cualquier tipo de aplicación, desde sistemas operativos hasta procesos y aplicaciones que se ejecutan de forma autónoma o no.
Un ejemplo de ello es que puedes crear todo con C y C++, incluso una plataforma equivalente a MetaTrader 5, pero el trabajo necesario para hacerlo sería descomunal, por lo que es más simple y práctico utilizar algo que ya existe, como MQL5. Pero, para crear cosas con un grado de complejidad mayor —y esto usando MQL5—, necesitamos recursos y herramientas más avanzados. En este caso, el primer recurso avanzado que utilizaremos son las estructuras. Sin ellas, podríamos producir algo interesante, pero el grado de dificultad sería mucho mayor.
Las estructuras pueden ser muy complejas, mucho más de lo que puedes imaginar, querido lector y entusiasta. Pero empecemos poco a poco, para que puedas ir asimilando y comprendiendo cómo funcionan las estructuras. Créeme, te sorprenderá el nivel de complejidad que pueden alcanzar. Aun así, todavía no logran lidiar con ciertas situaciones. Por esta razón fue necesaria la creación de otro tipo de estructura que, para poder diferenciarlas, recibió una denominación especial: las clases. Pero esto se comprenderá mejor a lo largo de los artículos que se publicarán.
Entonces, empezaremos con una estructura muy simple para familiarizarnos con este nuevo concepto. Este puede observarse a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. struct st_01 07. { 08. short value_01; 09. int value_02; 10. double value_03; 11. }; 12. 13. st_01 Info; 14. 15. Info.value_01 = -8096; 16. Info.value_02 = 78934; 17. Info.value_03 = 1e4 + 0.674; 18. 19. PrintFormat("Result of the sum of all values. %f", Info.value_01 + Info.value_02 + Info.value_03); 20. } 21. //+------------------------------------------------------------------+
Código 01
Este código 01 es muy sencillo y en él empezamos a ver cómo se construye una estructura. Observa que la forma de hacerlo, es decir, de crear una estructura, es muy parecida a la forma de crear una unión. Mas, existe una diferencia entre ambos recursos. Mientras que una unión se crea de manera que todos los elementos presentes en ella pertenezcan a una misma región de la memoria.
Una estructura se crea y se piensa de forma que cada elemento que la compone sea individual. Es decir, una estructura sería como un tipo de variable compleja que puede tener diversos elementos para crear dicha variable. Esta no es una buena definición, pero sirve para explicar qué es una estructura.
Aunque —y es importante que lo entiendas, querido lector— esta primera definición de estructura es una forma adecuada de entenderla, ya que permite comprender otras propiedades. Entonces, por ahora, toma como base este concepto de estructura.
Una estructura es una forma de agrupar diversas variables que, de alguna manera, están correlacionadas entre sí.
A medida que avancemos en el estudio de las estructuras, verás que este concepto se amplía bastante y adopta diversas formas, lo que nos da mucha libertad de creación y hace que sea cada vez más fácil implementar cosas muy complicadas.
Pero volvamos a nuestro código inicial, que se puede ver en el código 01. Bien, fíjate que en la línea seis estamos declarando una estructura. Al igual que en las uniones, en MQL5 no es posible definir una estructura anónima, por lo que es necesario asignarle un nombre. Como es el primer contacto, estoy utilizando algo muy parecido a lo que se hizo cuando expliqué las uniones. Es decir, primero declaramos la estructura y, luego, en otra línea, la variable que la utilizará. En este caso, la declaración de la variable se hace en la línea trece. Como puedes ver, es muy similar a lo que se hacía con las uniones.
En las líneas del quince al diecisiete, asignamos valores a cada elemento de la estructura. Como puedes ver, esto es muy similar a lo que se hacía cuando asignábamos valores a cualquier variable. Es decir, aquí estamos haciendo uso de cosas básicas. En la línea diecinueve, imprimimos un mensaje en el terminal para informar de algo. En este caso, esta línea producirá lo que se ve en la imagen de abajo.

Imagen 01
Como primer contacto, creo que has conseguido comprender muy bien lo que está ocurriendo aquí. Esto se debe a que gran parte de ello ya se ha explicado hace algún tiempo. El hecho de que la línea seis sea como es puede generar algún tipo de desconfianza y temor. Sin embargo, si entendemos que una estructura es equivalente a una unión, en lo que respecta a cómo debe ser declarada, todo lo demás se vuelve mucho más sencillo. Es decir, el conocimiento se va ampliando con el paso del tiempo.
Bueno, este fue fácil. Sin embargo, antes de pasar a algo más elaborado, hay algunas reglas que debemos tener en cuenta cuando utilicemos estructuras. Las iré mostrando y explicando poco a poco, ya que algunas pueden no tener mucho sentido en este momento.
La primera regla es:
En MQL5, una estructura NUNCA puede ser CONSTANTE. Ella SIEMPRE será una variable.
Esto significa que no puedes declarar una estructura —y que quede bien claro, aquí en MQL5— como constante en MQL5. La razón es que primero declaramos la etiqueta que utilizaremos para acceder a los datos dentro de la estructura y solo después podemos acceder a esos mismos datos. Es decir, primero necesitamos que la línea 13 del código 01 exista para poder utilizar la estructura.
Como para declarar una constante necesitamos definir su valor en el momento de la declaración, no es posible crear una estructura constante en MQL5.
La segunda regla es:
La forma en que se declaran los elementos en la estructura define el orden en que se colocarán en la memoria.
Esta regla es muy importante, sobre todo cuando vamos a utilizar estructuras de una forma muy específica. Pero vamos con calma. Entendamos algo antes de aplicar la regla número dos. Cuando definimos una unión, la cantidad de bytes necesarios para contenerla será igual a la del tipo de mayor tamaño presente en ella.
Sin embargo, en lo que respecta a las estructuras, las cosas son un poco diferentes. Para entenderlo, vamos a utilizar el mismo código 01 y ver cuánta memoria necesitamos. Sin embargo, para que quede más claro y entiendas la diferencia entre cómo se ven una estructura y una unión en la memoria, vamos a añadir una unión con los mismos elementos y tipos. Así, surge el código que se ve justo abajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. struct st_01 07. { 08. short value_01; 09. int value_02; 10. double value_03; 11. }; 12. 13. union un_01 14. { 15. short value_01; 16. int value_02; 17. double value_03; 18. }; 19. 20. PrintFormat("Size of struct is: [%d bytes]\nSize of union is: [%d bytes]", sizeof(st_01), sizeof(un_01)); 21. } 22. //+------------------------------------------------------------------+
Código 02
Observa, querido lector, que en este código 02 tenemos dos construcciones diferentes con los mismos elementos y tipos. Sin embargo, a pesar de ello, ocupan espacios diferentes en términos de bytes. Esto se puede observar en el resultado de la imagen 02, justo a continuación.
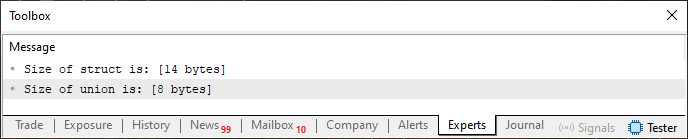
Imagen 02
Observa que la unión necesita ocho bytes, ya que el tipo más grande presente en ella es double, que, como ya sabemos, necesita ocho bytes para ser representado. La estructura, que contiene los mismos elementos, necesita catorce bytes. Esto se debe a que debemos sumar los ocho bytes del tipo double con los cuatro bytes del tipo int y los dos bytes del tipo short, lo que da un total de catorce bytes. Ahora vamos a entender lo que nos dice la regla dos. Para ello, debemos modificar de nuevo el código 02 por el que se ve justo debajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. struct st_01 09. { 10. short value_01; 11. int value_02; 12. double value_03; 13. }; 14. 15. struct st_02 16. { 17. short value_01; 18. int value_02; 19. double value_03; 20. }; 21. 22. union un_01 23. { 24. st_01 data_01; 25. st_02 data_02; 26. }; 27. 28. un_01 Info; 29. 30. ZeroMemory(Info); 31. Info.data_01.value_01 = -18254; 32. 33. PrintX(Info.data_02.value_01); 34. } 35. //+------------------------------------------------------------------+
Código 03
En este código 03 tenemos una construcción que nos permitirá entender la regla 02, así que presta mucha atención, querido lector, porque esto te será de gran ayuda en el futuro. Aquí tenemos dos estructuras que se declaran. Ambas son exactamente IDÉNTICAS, tanto en el número y la cantidad de elementos como en el tipo de dato de cada uno de ellos. Pero lo más importante es que el orden de declaración de los elementos sea exactamente el mismo. Este es el punto más importante.
Para que sea más fácil de comprender, usamos una unión en la línea 22. Esta vincula las estructuras de forma que todos los elementos compartan el mismo espacio de memoria. Obviamente, tú ya debes saber esto, ¿verdad, querido lector? Pues bien, ahora presta atención. En la línea treinta, le indico al compilador que limpie completamente la región de memoria donde se encuentra la unión. Es decir, ahora toda esa región contiene solo ceros.
En la línea 31, asignamos un valor a alguna de las variables presentes en la estructura. Puede ser cualquiera. Pero fíjate que lo estamos haciendo utilizando la unión como punto de apoyo. En este caso, estamos asignando un valor a una variable concreta que está declarada en la estructura definida en la línea ocho. Para comprobar lo que está ocurriendo, en la línea 33 imprimimos el valor de la misma variable. Sin embargo, en este caso, la variable es la que se encuentra en la estructura 02, que se define en la línea 15. Como ambas estructuras comparten el mismo bloque de memoria, el valor será el mismo.
Entonces, ejecutando el código 03, puedes observar lo que se ve justo abajo.
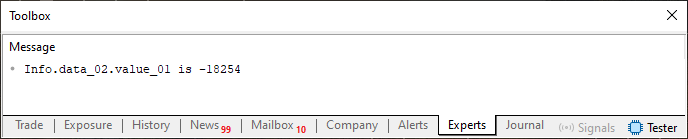
Imagen 03
Hmm... No hay nada anormal, ya que el valor presentado es exactamente el mismo que estamos asignando a la variable en la línea 31. Como todo está correcto, puedes incluso estar preguntándote: «¿Por qué mencionaste la regla número dos, si no hubo ningún tipo de alteración?». Lo que has dicho no tiene ningún sentido ni lógica.
De acuerdo. Estaba equivocado, de hecho no se está generando ningún problema aquí. Pero vamos a hacer otra prueba. Sin embargo, esta vez vamos a usar otro código para poder visualizar todo lo que ocurre en la memoria. Para ello, vamos a modificar el código 03 por otro que se puede ver justo debajo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. struct st_01 09. { 10. short value_01; 11. int value_02; 12. double value_03; 13. }; 14. 15. struct st_02 16. { 17. short value_01; 18. int value_02; 19. double value_03; 20. }; 21. 22. union un_01 23. { 24. st_01 data_01; 25. st_02 data_02; 26. uchar arr[sizeof(st_01)]; 27. }; 28. 29. un_01 Info; 30. 31. ZeroMemory(Info); 32. Info.data_01.value_01 = -18254; 33. 34. ArrayPrint(Info.arr); 35. 36. PrintX(Info.data_02.value_01); 37. } 38. //+------------------------------------------------------------------+
Código 04
Bien, ahora tenemos un código en el que podemos ver realmente lo que ocurre en la memoria de la región indicada por la variable Info. Al ejecutar este código 04, vas a ver la imagen justo abajo.
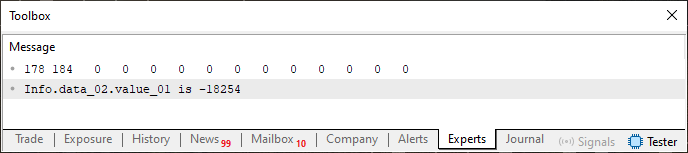
Imagen 04
Y, una vez más, todo está como se esperaba. Como este código 04 hace uso de cosas ya explicadas, no entraré en detalles sobre lo que se está haciendo allí. Pero es ahora cuando la cosa se pone realmente interesante: vamos a modificar un pequeño detalle de este código. Este detalle se muestra en el fragmento de abajo.
. . . 15. struct st_02 16. { 17. int value_02; 18. short value_01; 19. double value_03; 20. }; . . .
Fragmento 01
Ahora, tras realizar la modificación mostrada en el fragmento 01 del código 04, lo compilamos de nuevo y lo ejecutamos en el terminal de MetaTrader 5. Quizás estén pensando: Este cambio no afectará al contenido ni al resultado que obtendremos al ejecutar el código. Pero, ya que insistes, lo probaré solo para demostrarte que estás equivocado y que definitivamente no tienes ni idea. Al ejecutar el código, se obtiene lo que se ve en la imagen 05, justo abajo.
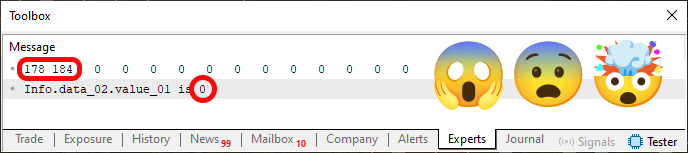
Imagen 05
Ay, Dios mío... ¿Qué es esto? ¿Cómo es posible? Ah, ya sé: es un error. O, mejor dicho, estás manipulando la imagen. Es una broma del bromista, lo que estoy viendo en la imagen 05, y no me vas a engañar. ¿Pensaste que no me iba a dar cuenta? Te equivocaste. No, querido lector, esto no es ninguna broma. Es un hecho real que puede reproducirse perfectamente, siempre y cuando hagas lo que se ha dicho: colocar el fragmento 01 en el código 04. Pero, ¿por qué, si el contenido de la memoria sigue inalterado, obtuvimos un resultado diferente al leer la variable? El motivo es que no estamos leyendo la variable, sino la posición de memoria donde se está utilizando.
Esto puede parecer un tanto extraño e incluso bastante fuera de lo común. En el código 04, tanto la estructura 01 como la estructura 02 tienen los mismos tipos de datos y variables con el mismo nombre. Si asumimos que estamos utilizando una unión para «simular» un movimiento de archivo, no tiene mucho sentido que el valor pudiera llegar a modificarse por el simple hecho de haber cambiado una variable de lugar durante la declaración de la estructura.
Pero —y aquí es donde realmente radica la importancia de la regla número dos— debes ignorar por un momento que estamos ejecutando el código en memoria y comenzar a pensar en él de forma más amplia. Piensa en lo siguiente: cuando grabamos un archivo, almacenamos la información en una secuencia lógica concreta. Sin embargo, a menudo nos interesa guardar y cargar datos en un tipo de estructura lógica.
Esto se puede observar en archivos de imagen, por ejemplo. En este caso, al principio del archivo tenemos algo que se conoce como encabezado. Los datos que hay en él forman parte de una estructura de datos. Sin embargo, puedes leerlos de dos maneras. Una es leerlos uno a uno; la otra es utilizar una estructura especialmente construida para ello.
Para que lo entiendas, vamos a tomar el ejemplo más simple de estructura de datos. El conocido formato BitMap. Cuando una imagen Bitmap se almacena o se lee desde un disco, al inicio del archivo de imagen encontramos una estructura formada por una secuencia de campos. Esta secuencia, que en realidad es una estructura, nos informa sobre cómo está formada la imagen, qué tipo de imagen es, qué tipo de estructura se ha utilizado para modelarla y sus dimensiones, entre otras cosas.
Como la estructura del archivo sigue un formato específico, puedes usar la información contenida en el Bformato BMP para reproducir la imagen como consideres mejor. Del mismo modo que podemos leer la imagen, también podemos manipular los datos que contiene. Pero el punto importante —y de ahí surge la necesidad de entender la regla número dos— es que, si estás implementando alguna aplicación que guarde datos en disco y, pasado un tiempo, cambias la estructura creada inicialmente porque has notado que puede quedar mejor organizada de otra manera, podrías tener problemas al intentar recuperar datos antiguos guardados en el pasado. Esto se debe precisamente a que las posiciones de las variables cambiaron con el tiempo.
Por eso es importante que entiendas que las estructuras deben pensarse en función de su objetivo final. Si la intención es mantener todo en memoria, puede que no sea necesario modificar mucho los datos ni preocuparse por el orden de declaración. Sin embargo, si el objetivo es transferir información entre puntos diferentes o almacenarla para un uso futuro, es recomendable que crees algún tipo de mecanismo para fijar la estructura en una versión concreta. Así, a medida que vayas cambiando las cosas, deberás cambiar también la versión de la estructura que se está creando. Si todo está perfectamente pensado y mantenido, podrás leer datos almacenados hace mucho tiempo con una versión de la estructura mucho más reciente.
Tal vez este tipo de cosas de las que estoy hablando no tengan mucho sentido, sobre todo en este primer momento, ya que antes de pensar en el modelado de datos necesitamos entender y estudiar otros conceptos que están directamente relacionados con la cuestión de las estructuras.
Sin embargo, para que esto resulte más interesante y puedas entender mejor lo que quiero mostrarte, vamos a hacer un pequeño experimento. No es nada complejo. De hecho, es bastante simple. Y, con todos los conceptos vistos hasta ahora, te resultará fácil de entender. Mira el código a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define PrintX(X) Print(#X, " is ", X) 05. //+----------------+ 06. #define def_FileName "Testing.bin" 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. struct st_01 11. { 12. short value_01; 13. int value_02; 14. double value_03; 15. }Info; 16. 17. int handle; 18. 19. ZeroMemory(Info); 20. 21. PrintFormat("Size of struct is %d bytes", sizeof(Info)); 22. 23. if ((handle = FileOpen(def_FileName, FILE_READ | FILE_BIN)) != INVALID_HANDLE) 24. PrintFormat("Reading %d bytes of file data.", FileReadStruct(handle, Info)); 25. else 26. { 27. Info.value_01 = -8096; 28. Info.value_02 = 78934; 29. Info.value_03 = 1e4 + 0.674; 30. 31. PrintFormat("Writing %d bytes of data in the file.", FileWriteStruct(handle = FileOpen(def_FileName, FILE_WRITE | FILE_BIN), Info)); 32. } 33. FileClose(handle); 34. 35. PrintX(Info.value_01); 36. PrintX(Info.value_02); 37. PrintX(Info.value_03); 38. } 39. //+------------------------------------------------------------------+
Código 05
Al ejecutar este código, se mostrará en el terminal lo que se ve justo abajo.
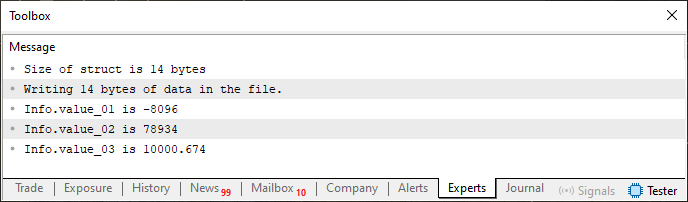
Imagen 06
Notarás que primero escribimos en el archivo, ya que no existía. Si tienes curiosidad, puedes abrir el archivo con un editor hexadecimal. En este caso, podrás ver lo que se muestra en la imagen siguiente.

Imagen 07
Este sería el tipo de contenido que estaría presente en la memoria si vinieras a usar una unión para visualizar la región. Pero olvida esto por ahora, ya que no es importante en este momento. Lo que nos interesa aquí es lo siguiente: cuando ejecutes de nuevo el código 05 —sin modificarlo y sin borrar ni modificar el contenido del archivo, que se puede ver en la imagen 07—, obtendrás en el terminal de MetaTrader 5 lo que se muestra justo debajo.
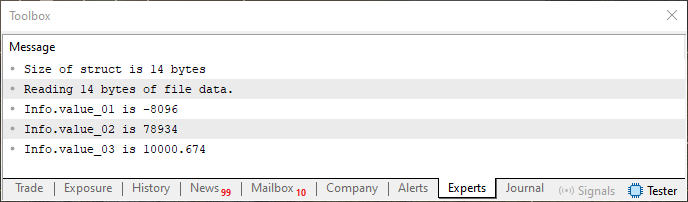
Imagen 08
Claramente, verás que es la misma información. Ahora, te sugiero que cambies solo el orden de las variables de la estructura que se declara en la línea diez del código 05. Sin cambiar nada más, compila de nuevo el código y ejecútalo. Compara los resultados obtenidos anteriormente, que pueden verse en las imágenes anteriores, con el resultado que se observa en el terminal cuando se vuelve a ejecutar el código 05 con los cambios en el orden de declaración de las variables. Piensa en lo que ha ocurrido y compáralo con lo que vimos cuando usábamos la unión para efectuar el mismo tipo de análisis.
Aunque no hayamos hablado aún de la grabación y lectura de archivos, este código 05, que estará disponible en el anexo, es muy simple, práctico y directo, y se puede comprender muy fácilmente basándose en lo explicado hasta ahora. Las únicas partes que pueden generar algún tipo de cuestionamiento se pueden comprender perfectamente leyendo la documentación de las funciones de biblioteca: FileOpen, FileWriteStruct, FileReadStruct y FileClose. Pero incluso estas son bastante fáciles de entender y no necesitan ninguna otra información o comentario adicional para comprender perfectamente lo mostrado aquí.
Consideraciones finales
Este ha sido el primer artículo sobre estructuras en MQL5. Para comenzar con buen pie, necesitamos comprender diversos conceptos que deben aplicarse a las estructuras. Sé que este primer contacto puede que no haya sido tan emocionante. Sin embargo, habrás notado que es necesario entender lo explicado en los artículos anteriores. Sin esos conceptos debidamente comprendidos, lo que comenzamos a hacer aquí resultará mucho más difícil y confuso.
Por esta razón, es necesario practicar y procurar entender lo que se está haciendo y los resultados que se están generando. De todos modos, utiliza los archivos del anexo para practicar este primer contacto y procura entender las dos reglas que se han demostrado en este artículo, ya que serán muy importantes dentro de poco.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15730
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso