
MQL5-Assistenz-Techniken, die Sie kennen sollten (Teil 07): Dendrogramme
Einführung
Dieser Artikel, der Teil einer Serie über die Verwendung des MQL5-Assistenten ist, befasst sich mit Dendrogramm. Wir haben bereits einige Ideen in Betracht gezogen, die für Händler über den MQL5-Assistenten nützlich sein können, wie zum Beispiel Lineare Diskriminanzanalyse, Markov-Ketten, Fourier-Transformation und einige andere, und dieser Artikel zielt darauf ab, dieses Unterfangen weiterzuführen, indem er Möglichkeiten aufzeigt, wie man den umfangreichen ALGLIB-Code, wie er von MetaQuotes übersetzt wurde, zusammen mit der Verwendung des eingebauten MQL5-Assistenten nutzen kann, um neue Ideen kompetent zu testen und zu entwickeln.
Die Zusammenfassung durch eine hierarchische Clusteranalyse klingt nach einem langen Wort, ist aber eigentlich ganz einfach. Vereinfacht ausgedrückt handelt es sich um ein Mittel, um verschiedene Teile eines Datensatzes miteinander in Beziehung zu setzen, indem man zunächst die grundlegende einzelne Hierarchische Clusteranalyse betrachtet und sie dann systematisch Schritt für Schritt gruppiert, bis der gesamte Datensatz als eine einzige sortierte Einheit betrachtet werden kann. Das Ergebnis dieses Prozesses ist ein hierarchisches Diagramm, das gemeinhin als Dendrogramm bezeichnet wird.
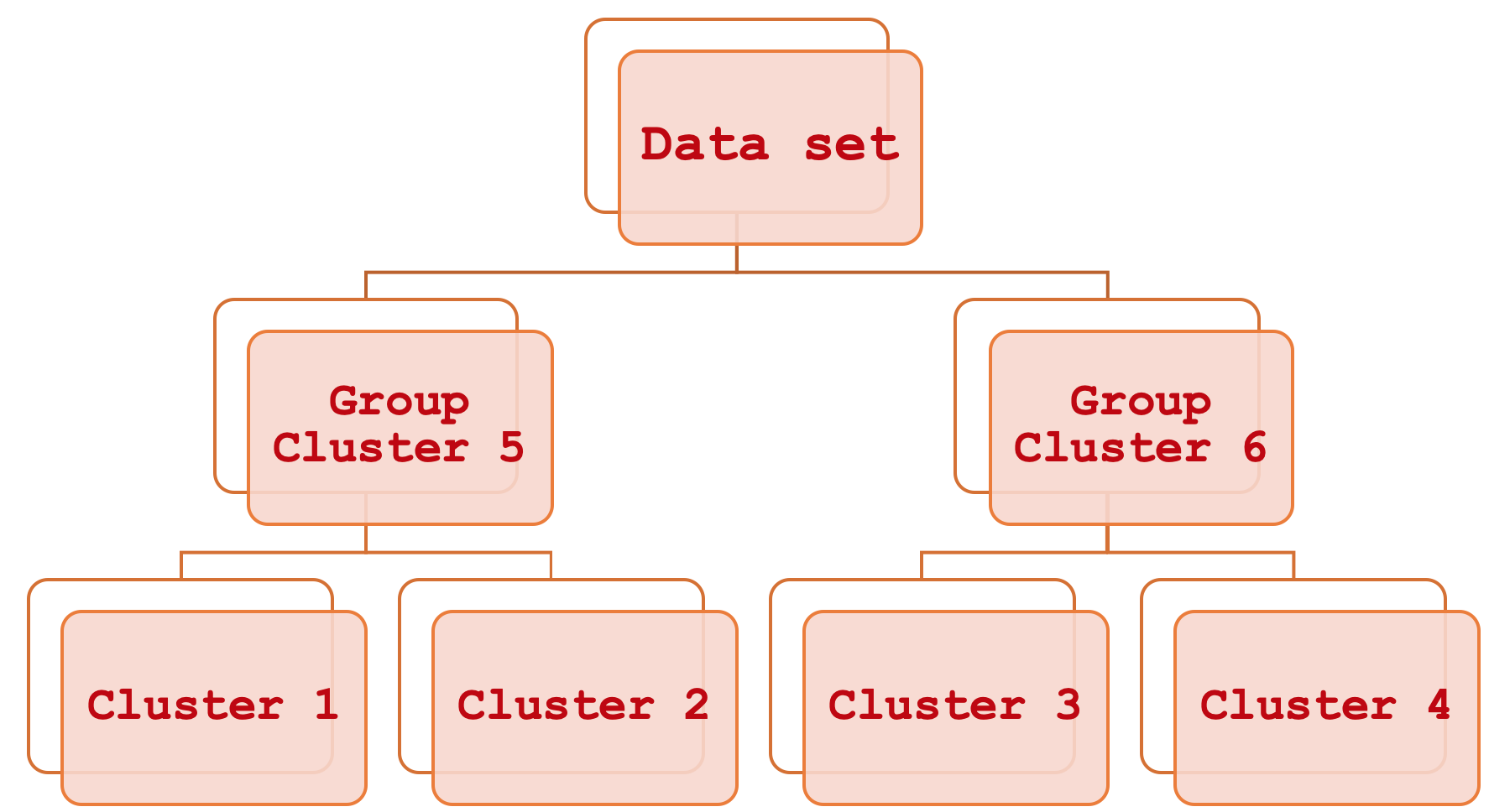
Dieser Artikel wird sich darauf konzentrieren, wie diese konstituierenden Cluster bei der Bewertung und somit bei der Vorhersage der Preisspanne verwendet werden können, aber anders als in der Vergangenheit, wo wir dies taten, um bei der Anpassung des Trailing-Stops zu helfen, werden wir es hier zu Zwecken des Money Managements oder der Positionsgrößenbestimmung betrachten. In diesem Artikel wird davon ausgegangen, dass der Leser relativ neu auf der MetaTrader-Plattform und in der Programmiersprache MQL5 ist, und daher werden wir uns mit einigen Themen und Bereichen befassen, die für erfahrenere Händler uninteressant sind.
Die Bedeutung genauer Preisspannenprognosen ist weitgehend subjektiv. Der Grund dafür ist, dass seine Bedeutung hauptsächlich von der Strategie des Händlers und seinem allgemeinen Handelsansatz abhängt. Wann wäre es nicht mehr wichtig? Dies könnte zum Beispiel der Fall sein, wenn Sie bei Ihren Handelsplänen nur minimale bis gar keine Hebelwirkung einsetzen, einen definitiven Stop-Loss haben, Positionen über längere Zeiträume halten, die sich über Monate erstrecken können, und wenn Sie eine feste Margin-Positionsgröße (oder sogar einen festen Lot-Ansatz) haben. In diesem Fall kann die Volatilität der Kursbalken in den Hintergrund treten, während Sie sich auf die Suche nach Ein- und Ausstiegssignalen konzentrieren. Wenn Sie hingegen ein Intraday-Händler sind, oder jemand, der eine erhebliche Menge an Leverage einsetzt, oder jemand, der keine Handelspositionen über das Wochenende hält, oder jemand mit einem mittleren bis kurzen Zeithorizont, wenn es um das Engagement an den Märkten geht, dann ist die Preisspanne sicherlich etwas, worauf Sie achten sollten. Wir sehen uns an, wie dies bei der Geldverwaltung von Nutzen sein kann, indem wir eine nutzerdefinierte Instanz der Klasse „ExpertMoney“ erstellen, aber die Anwendungen könnten über die Geldverwaltung hinausgehen und sogar das Risiko umfassen, wenn man bedenkt, dass die Fähigkeit, die Preisspanne zu verstehen und vernünftig vorherzusagen, bei der Entscheidung helfen könnte, wann man offene Positionen aufstocken und wann man sie reduzieren sollte.
Volatilität
Die Preisspanne (mit der wir in diesem Artikel die Volatilität quantifizieren) ist im Zusammenhang mit dem Handel die Differenz zwischen dem Höchst- und Tiefstkurs eines gehandelten Symbols innerhalb eines bestimmten Zeitrahmens. Wenn wir also, sagen wir, den täglichen Zeitrahmen nehmen und der Preis für ein gehandeltes Symbol an einem Tag bis zu H steigt und nicht über H und bis zu L fällt und wiederum nicht unter L, dann ist unsere Spanne für die Zwecke dieses Artikels:
H – L;
Die Beachtung der Volatilität ist wohl deshalb von Bedeutung, weil sie oft als Volatilitäts-Clustering bezeichnet wird. Dies ist das Phänomen, dass auf Zeiten hoher Volatilität tendenziell eine höhere Volatilität folgt und umgekehrt auf Zeiten niedriger Volatilität auch eine niedrigere Volatilität folgt. Die Bedeutung dieses Punktes ist, wie oben erwähnt, subjektiv, aber für die meisten Händler (meiner Meinung nach auch für alle Anfänger) kann das Wissen, wie man mit Hebelwirkung handelt, langfristig von Vorteil sein, da die meisten Händler wissen, dass hohe Volatilitätsschübe Konten zum Erliegen bringen können, nicht weil das Einstiegssignal falsch war, sondern weil die Volatilität zu hoch war. Und die meisten würden auch verstehen, dass, selbst wenn Sie einen anständigen Stop-Loss-Kurs für Ihre Position hatten, es Zeiten gibt, in denen der Stop-Loss-Kurs nicht verfügbar ist, wie z. B. beim Schweizer Franken-Debakel im Januar 2015. In diesem Fall würde Ihre Position vom Broker zum nächstbesten verfügbaren Kurs geschlossen, der oft schlechter ist als Ihr Stop-Loss. Dies liegt daran, dass nur Limit-Aufträge eine Preisgarantie bieten, Stop-Aufträge und Stop-Loss-Aufträge hingegen nicht.
Die Preisspannen geben also nicht nur einen Gesamteindruck vom Marktumfeld, sondern können auch bei der Festlegung von Einstiegs- und sogar Ausstiegskursen helfen. Auch hier gilt, dass je nach Ihrer Strategie, wenn Sie z. B. auf ein bestimmtes Symbol setzen, das Ausmaß Ihrer Preisspannenprognose (das, was Sie vorhersagen) leicht bestimmen oder zumindest bestimmen kann, wo Sie Ihren Einstiegskurs und sogar Ihren Take-Profit platzieren.
Auch auf die Gefahr hin, banal zu klingen, kann es hilfreich sein, einige der grundlegenden Preiskerzentypen hervorzuheben und ihre jeweiligen Spannen zu veranschaulichen. Die wohl bekanntesten Typen sind bearish, bullish, hammer, gravestone, long-legged, und dragonfly. Es gibt sicherlich noch mehr Typen, aber diese decken wohl das ab, was man am ehesten bei einem Preischart antreffen würde. In all diesen Fällen, wie in den nachstehenden Charts dargestellt, ist die Preisspanne einfach der Höchstpreis abzüglich des Tiefstpreises.
Agglomerative Hierarchische Klassifikation
Die agglomerative hierarchische Klassifikation (AHC) ist eine Methode zur Klassifizierung von Daten in eine vorgegebene Anzahl von Clustern und zur anschließenden systematischen hierarchischen Verknüpfung dieser Cluster durch ein sogenanntes Dendrogramm. Die Vorteile dieser Methode ergeben sich vor allem aus der Tatsache, dass die zu klassifizierenden Daten oft mehrdimensional sind und daher die Notwendigkeit, die vielen Variablen innerhalb eines einzigen Datenpunktes zu berücksichtigen, etwas ist, das man bei Vergleichen nicht so leicht in den Griff bekommen kann. Beispielsweise könnte ein Unternehmen, das seine Kunden auf der Grundlage der ihm vorliegenden Informationen einstufen möchte, dies nutzen, da diese Informationen zwangsläufig verschiedene Aspekte des Lebens der Kunden abdecken, wie z. B. frühere Ausgabengewohnheiten, Alter, Geschlecht, Adresse usw. Durch die Quantifizierung all dieser Variablen für jeden Kunden erstellt AHC Cluster aus den scheinbaren Mittelpunkten der einzelnen Datenpunkte. Aber darüber hinaus werden diese Cluster in einer Hierarchie für systematische Beziehungen gruppiert. Wenn also eine Klassifikation z.B. 5 Cluster erfordert, dann würde AHC diese 5 Cluster in einem sortierten Format zur Verfügung stellen, d.h. man kann ableiten, welche Cluster sich ähnlicher und welche unterschiedlicher sind. Dieser sekundäre Clustervergleich kann sich als nützlich erweisen, wenn Sie mehr als einen Datenpunkt vergleichen müssen und sich herausstellt, dass sie sich in verschiedenen Clustern befinden. Das Cluster-Ranking würde Aufschluss darüber geben, wie weit die beiden Punkte voneinander entfernt sind, indem die Größe des Abstands zwischen ihren jeweiligen Clustern verwendet wird.
Die AHC-Klassifizierung ist eine Form des unüberwachtes Lernens, d.h. sie kann für Prognosen unter verschiedenen Klassifikatoren verwendet werden. In unserem Fall prognostizieren wir Preisbalkenbereiche, jemand anderes mit denselben trainierten Clustern könnte sie zur Vorhersage von Schlusskursänderungen oder einem anderen für seinen Handel relevanten Aspekt verwenden. Dies ermöglicht eine größere Flexibilität, als wenn das Modell eines überwachten Lernens mit einem bestimmten Klassifikator trainiert würde, denn in diesem Fall würde das Modell nur für Vorhersagen in dem Bereich verwendet werden, in dem es klassifiziert wurde.
Tools und Bibliotheken
Die MQL5-Plattform ermöglicht mit Hilfe ihrer IDE erwartungsgemäß die Entwicklung nutzerdefinierter Expert Advisors von Grund auf, und um zu zeigen, was hier geteilt wird, könnten wir diesen Weg hypothetisch gehen. Diese Option würde jedoch bedeuten, dass viele Entscheidungen bezüglich des Handelssystems getroffen werden müssten, die ein anderer Händler bei der Umsetzung desselben Konzepts anders hätte treffen können. Außerdem könnte der Code einer solchen Implementierung zu sehr auf den Kunden zugeschnitten und fehleranfällig sein, sodass er nicht ohne weiteres für verschiedene Situationen angepasst werden kann. Deshalb ist die Integration unserer Idee in andere „Standard“-Expert Advisor-Klassen, die vom MQL5-Assistenten bereitgestellt werden, ein überzeugendes Argument. Nicht nur, dass wir weniger Fehlersuche betreiben müssen (selbst in den eingebauten Klassen von MQL5 gibt es gelegentlich Fehler, aber nicht sehr viele), sondern indem wir sie als Instanz einer der Standardklassen speichern, kann sie verwendet und mit der Vielzahl anderer Klassen im MQL5-Assistenten kombiniert werden, um verschiedene Expert Advisors zu erstellen, was eine umfassendere Testumgebung bietet.
Der Bibliothekscode von MQL5 stellt Klassen von AlgLib zur Verfügung, auf die in früheren Artikeln dieser Reihe verwiesen wurde und die auch in diesem Artikel verwendet werden. In der Datei „DATAANALYSIS.MQH“ werden wir uns insbesondere auf die Klasse „CClustering“ und einige andere verwandte Klassen stützen, um eine AHC-Klassifikation für unsere Preisreihendaten zu erstellen. Da wir uns in erster Linie für die Preisspannen interessieren, bestehen unsere Trainingsdaten aus den Preisspannen früherer Perioden. Bei der Verwendung von Daten-Trainingsklassen aus der Datenanalyse-Include-Datei werden diese Daten in der Regel in einer „XY“-Matrix abgelegt, wobei das X für die unabhängigen Variablen steht und das Y die Klassifikatoren oder die „Labels“ darstellt, auf die das Modell trainiert wird. Beide werden in der Regel in der gleichen Matrix eingerichtet.
Vorbereiten der Trainingsdaten
Da wir in diesem Artikel jedoch ein unbeaufsichtigtes Training durchführen, bestehen unsere Eingabedaten nur aus den X unabhängigen Variablen. Dabei handelt es sich um historische Preisspannen. Gleichzeitig möchten wir aber auch Prognosen erstellen, indem wir einen anderen Datenstrom berücksichtigen, nämlich die mögliche Preisspanne. Dies entspräche dem oben erwähnten Y. Um diese beiden Datensätze unter Beibehaltung der Flexibilität des unüberwachten Lernens zu vereinen, können wir die nachstehende Datenstruktur übernehmen:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class CMoneyAHC : public CExpertMoney { protected: double m_decrease_factor; int m_clusters; // clusters int m_training_points; // training points int m_point_featues; // point featues ... public: CMoneyAHC(void); ~CMoneyAHC(void); virtual bool ValidationSettings(void); //--- virtual double CheckOpenLong(double price,double sl); virtual double CheckOpenShort(double price,double sl); //--- void DecreaseFactor(double decrease_factor) { m_decrease_factor=decrease_factor; } void Clusters(int value) { m_clusters=value; } void TrainingPoints(int value) { m_training_points=value; } void PointFeatures(int value) { m_point_featues=value; } protected: double Optimize(double lots); double GetOutput(); CClusterizerState m_state; CAHCReport m_report; struct Sdata { CMatrixDouble x; CRowDouble y; Sdata(){}; ~Sdata(){}; }; Sdata m_data; CClustering m_clustering; CRowInt m_clustering_index; CRowInt m_clustering_z; };
Die historischen Preisbalkenbereiche werden also bei jedem neuen Balken als neuer Stapel gesammelt. Die vom MQL5-Assistenten generierten Experten neigen dazu, Handelsentscheidungen bei jedem neuen Balken auszuführen, und für unsere Testzwecke ist dies ausreichend. Es gibt in der Tat alternative Ansätze, wie z. B. die Beschaffung eines großen Stapels, der sich über viele Monate oder sogar Jahre erstreckt, und die anschließende Prüfung, wie gut die Cluster des Modells eventuelle Preisbalken mit niedriger Volatilität von solchen mit hoher Volatilität trennen können. Denken Sie auch daran, dass wir nur 3 Cluster verwenden, wobei ein extremes Cluster für sehr volatile Balken, eines für sehr geringe Volatilität und eines für mittlere Volatilität steht. Auch hier könnte man zum Beispiel mit 5 Clustern arbeiten, aber das Prinzip wäre für unsere Zwecke dasselbe. Ordnen Sie die Cluster in der Reihenfolge der höchsten möglichen Volatilität bis zur geringsten möglichen Volatilität und ermitteln Sie, in welchem Cluster der aktuelle Datenpunkt liegt.
Füllen von Daten
Der Code zum Abrufen der Bereiche der neuesten Balken bei jedem neuen Balken und zum Auffüllen unserer nutzerdefinierten Struktur sieht wie folgt aus:
m_data.x.Resize(m_training_points,m_point_featues); m_data.y.Resize(m_training_points-1); m_high.Refresh(-1); m_low.Refresh(-1); for(int i=0;i<m_training_points;i++) { for(int ii=0;ii<m_point_featues;ii++) { m_data.x.Set(i,ii,m_high.GetData(StartIndex()+ii+i)-m_low.GetData(StartIndex()+ii+i)); } }
Die Anzahl der Trainingspunkte bestimmt, wie groß unser Trainingsdatensatz ist. Dies ist ein anpassbarer Eingabeparameter und damit der Parameter für die Datenpunkteigenschaften. Dieser Parameter bestimmt jedoch die Anzahl der „Dimensionen“, die jeder Datenpunkt hat. In unserem Fall haben wir also standardmäßig 4, aber das bedeutet einfach, dass wir die letzten 4 Kursbalkenbereiche verwenden, um einen beliebigen Datenpunkt zu definieren. Sie ist mit einem Vektor vergleichbar.
Erzeugen von Clustern
Sobald wir also Daten in unserer nutzerdefinierten Struktur haben, besteht der nächste Schritt darin, sie mit dem AlgLib AHC-Modellgenerator zu modellieren. Dieses Modell wird im Code-Listing als „state“ bezeichnet, und zu diesem Zweck wird unser Modell „m_state“ genannt. Dies ist ein zweistufiger Prozess. Zunächst müssen wir auf der Grundlage der bereitgestellten Trainingsdaten Modellpunkte erzeugen und dann den AHC-Generator starten. Das Setzen der Punkte kann als Initialisierung des Modells betrachtet werden und stellt sicher, dass alle wichtigen Parameter gut definiert sind. Dies wird in unserem Code wie folgt aufgerufen:
m_clustering.ClusterizerSetPoints(m_state, m_data.x, m_training_points, m_point_featues, 20);
Der zweite wichtige Schritt besteht darin, das Modell laufen zu lassen, um die Cluster für jeden der bereitgestellten Datenpunkte innerhalb des Trainingsdatensatzes zu definieren. Dies geschieht durch den Aufruf der Funktion „ClusterizerRunAHC“ wie unten aufgeführt:
m_clustering.ClusterizerRunAHC(m_state, m_report);
Von Seiten der AlgLib ist dies das A und O der Erzeugung der benötigten Cluster. Diese Funktion führt einige kurze Vorverarbeitungen durch und ruft dann die geschützte (private) Funktion „ClusterizerRunAHCInternal“ auf, die die Hauptarbeit leistet. Der gesamte Quellcode befindet sich in der Datei „include\math\AlgLib\dataanalysis.mqh“, die ab der Zeile sichtbar ist: 22463. Bemerkenswert ist hier die Erzeugung des Dendrogramms im Output-Array „cidx“. Dieses Array fasst auf geschickte Weise viele Clusterinformationen in einem einzigen Array zusammen. Zuvor muss eine Abstandsmatrix für alle Trainingsdatenpunkte unter Verwendung ihrer Mittelpunkte erstellt werden. Die Zuordnung der Werte der Distanzmatrix zu den Clusterindizes wird durch dieses Array erfasst, wobei die ersten Werte bis zur Gesamtzahl der Trainingspunkte den Cluster jedes Punktes darstellen und die nachfolgenden Indizes die Zusammenführung dieser Cluster zur Bildung des Dendrogramms repräsentieren.
Ebenso bemerkenswert ist vielleicht die Art der Entfernung, die bei der Erstellung der Abstandsmatrix verwendet wird. Es stehen neun Optionen zur Verfügung, von der Tschebyscheff-Distanz über die Euklidische Distanz bis hin zur Spearman-Rangkorrelation. Jeder dieser Alternativen wird ein Index zugewiesen, den wir festlegen, wenn wir die oben erwähnte Funktion der Sollwerte aufrufen. Die Wahl des Abstandstyps hängt zwangsläufig sehr stark von der Art und dem Typ der erzeugten Cluster ab, sodass darauf geachtet werden sollte. Die Verwendung des euklidischen Abstands (dessen Index 2 ist) ermöglicht mehr Flexibilität bei der Implementierung des AHC-Algorithmus, da die Ward-Methode im Gegensatz zu anderen Abstandstypen verwendet werden kann.
Abrufen von Clustern
Das Abrufen der Cluster ist ebenso einfach wie ihre Erstellung. Wir rufen einfach eine Funktion „ClusterizerGetKClusters“ auf, die zwei Arrays aus dem Ausgabebericht der Clustergenerierungsfunktion abruft, die wir zuvor aufgerufen haben (AHC ausführen). Bei den Arrays handelt es sich um das Cluster-Index-Array und das Cluster-Z-Array. Sie bestimmen nicht nur, wie die Cluster definiert werden, sondern auch, wie das Dendrogramm aus ihnen gebildet werden kann. Der Aufruf dieser Funktion ist einfach, wie unten angegeben:
m_clustering.ClusterizerGetKClusters(m_report, m_clusters, m_clustering_index, m_clustering_z);
Die Struktur der resultierenden Cluster ist sehr einfach, da wir in unserem Fall unseren Trainingsdatensatz nur 3 Clustern zugeordnet haben. Das bedeutet, dass wir innerhalb des Dendrogramms nicht mehr als drei Ebenen der Zusammenführung haben. Hätten wir mehr Cluster verwendet, wäre unser Dendrogramm sicherlich komplexer gewesen und hätte möglicherweise n-1 Verschmelzungsebenen gehabt, wobei n die Anzahl der vom Modell verwendeten Cluster ist.
Beschriftung von Datenpunkten
Danach folgt die Nachetikettierung der Trainingsdatenpunkte zur Unterstützung der Vorhersage. Wir sind nicht daran interessiert, Datensätze einfach nur zu klassifizieren, sondern wir wollen sie nutzen, und deshalb werden unsere „Etiketten“ die eventuelle Preisspanne nach jedem Trainingsdatenpunkt sein. Bei jedem neuen Balken wird ein neuer Datensatz abgerufen, der den aktuellen Datenpunkt enthält, dessen eventuelle Volatilität unbekannt ist. Deshalb lassen wir bei der Kennzeichnung den Datenpunkt mit dem Index 0 aus, wie in unserem Code unten gezeigt:
for(int i=0;i<m_training_points;i++) { if(i>0)//assign classifier only for data points for which eventual bar range is known { m_data.y.Set(i-1,m_high.GetData(StartIndex()+i-1)-m_low.GetData(StartIndex()+i-1)); } }
Natürlich sind auch andere Umsetzungen dieses Kennzeichnungsverfahrens denkbar. Anstatt sich zum Beispiel nur auf die Preisspanne des nächsten Balkens zu konzentrieren, hätten wir eine Makro-Sichtweise einnehmen können, indem wir die Spanne der nächsten 5 oder 10 Balken betrachtet hätten, indem wir die Gesamtspanne dieser Balken als unseren y-Wert verwendet hätten. Dieser Ansatz könnte zu „genaueren“ und weniger erratischen Werten führen, und in der Tat könnte derselbe Ausblick verwendet werden, wenn unsere Kennzeichnungen für die Preisrichtung (Veränderung des Schlusskurses) gelten, wobei wir versuchen würden, viele weitere Balken im Voraus zu prognostizieren, anstatt nur einen. In jedem Fall würden wir, da wir den ersten Index übersprungen haben, weil wir seinen eventuellen Wert nicht kannten, n Balken überspringen (wobei n die vorausliegenden Balken sind, die wir hochrechnen wollen). Dieser langfristige Ansatz würde zu einer beträchtlichen Verzögerung führen, wenn n größer wird, obwohl die großen Verzögerungen einen sicheren Vergleich mit der Projektion ermöglichen würden, da die Verzögerung nur einen Balken vor dem y-Zielwert liegt.
Vorhersage der Volatilität
Sobald wir die „Kennzeichnung“ des trainierten Datensatzes abgeschlossen haben, können wir damit fortfahren, festzustellen, zu welchem Cluster unser aktueller Datenpunkt unter den im Modell definierten Clustern gehört. Dies geschieht durch einfaches Iterieren durch die Ausgabe-Arrays des Modellierungsberichts und Vergleichen des Cluster-Index des aktuellen Datenpunkts mit dem anderer Trainingsdatenpunkte. Wenn sie übereinstimmen, gehören sie zu demselben Cluster. Hier ist die einfache Auflistung:
if(m_report.m_terminationtype==1) { int _clusters_by_index[]; if(m_clustering_index.ToArray(_clusters_by_index)) { int _output_count=0; for(int i=1;i<m_training_points;i++) { //get mean target bar range of matching cluster if(_clusters_by_index[0]==_clusters_by_index[i]) { _output+=(m_data.y[i-1]); _output_count++; } } // if(_output_count>0){ _output/=_output_count; } } }
Sobald eine Übereinstimmung gefunden wurde, würden wir gleichzeitig den durchschnittlichen Y-Wert aller Trainingsdatenpunkte innerhalb dieses Clusters berechnen. Die Ermittlung des Durchschnitts könnte als grob angesehen werden, aber sie ist eine Möglichkeit. Eine andere Möglichkeit wäre, den Median oder den Modus zu ermitteln. Unabhängig davon, welche Option gewählt wird, gilt das gleiche Prinzip, den Y-Wert des aktuellen Punktes nur aus anderen Datenpunkten innerhalb seiner Gruppe zu ermitteln.
Verwenden der Dendrogramme
Was wir bisher mit gemeinsamem Quellcode gezeigt haben, ist, wie die erstellten einzelnen Cluster zur Klassifizierung und für Projektionen verwendet werden können. Welche Rolle spielt dann ein Dendrogramm? Warum sollte es wichtig sein, zu quantifizieren, um wie viel sich die einzelnen Cluster voneinander unterscheiden? Um diese Frage zu beantworten, könnten wir zwei Trainingsdatenpunkte vergleichen, anstatt nur einen zu klassifizieren, wie wir es getan haben. In diesem Szenario könnten wir einen Datenpunkt aus der Geschichte an einem wichtigen Wendepunkt in Bezug auf die Volatilität erhalten (dies könnte ein Schlüsselfraktal in den Preisschwankungen sein, wenn Sie die Preisrichtung prognostizieren, aber wir betrachten in diesem Artikel die Volatilität). Da wir die Cluster der beiden Punkte haben, würde uns der Abstand zwischen ihnen sagen, wie nahe unser aktueller Datenpunkt am vergangenen Wendepunkt liegt.
Fallstudien
Einige Tests wurden mit einem von einem Assistenten zusammengestellten Expert Advisor durchgeführt, der eine angepasste Instanz der Geldmanagementklasse verwendet. Unsere Signalklasse basierte auf dem von der Bibliothek zur Verfügung gestellten Awesome Oszillator, den wir für das Symbol EURUSD auf dem 4-Stunden-Zeitrahmen von 2022.10.01 bis 2023.10.01 laufen ließen und der einen Bericht wie folgt ergab:

Zur Kontrolle haben wir auch Tests mit den gleichen Bedingungen wie oben durchgeführt, mit der Ausnahme, dass als Geldmanagement die von der Bibliothek bereitgestellte Option mit fester Marge verwendet wurde, was zu dem folgenden Bericht führte:

Unsere kurzen Tests mit diesen beiden Berichten haben ergeben, dass es möglich ist, unser Volumen an die vorherrschende Volatilität eines Symbols anzupassen. Die Einstellungen, die für unseren Expert Advisor und die Kontrolle verwendet werden, sind ebenfalls unten aufgeführt.

Und

Wie man sieht, wurden meist ähnliche Einstellungen verwendet, mit der einzigen Ausnahme unseres Expert Advisors, wo wir mehr für das nutzerdefinierte Geldmanagement verwenden mussten.
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass wir untersucht haben, wie die agglomerative hierarchische Klassifizierung mit Hilfe ihres Dendrogramms dazu beitragen kann, verschiedene Datensätze zu identifizieren und einzugrenzen, und wie diese Klassifizierung bei der Erstellung von Projektionen verwendet werden kann. Mehr zu diesem Thema finden Sie hier, und wie immer dienen die Ideen und der gemeinsame Quellcode dazu, Ideen zu testen, insbesondere wenn sie mit anderen Ansätzen kombiniert werden. Aus diesem Grund wird das Codeformat für MQL5-Assistenten-Klassen übernommen.
Anmerkungen zu den Anhängen
Der beigefügte Code soll mit dem MQL5-Assistenten als Teil einer Baugruppe assembliert werden, die eine Signalklassendatei und eine Trailing-Klassendatei enthält. Für diesen Artikel war die Signaldatei der Awesome Oszillator (SignalAO.mqh). Weitere Informationen über die Verwendung des Assistenten finden Sie hier.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/13630
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
 Integrieren Sie Ihr eigenes LLM in EA (Teil 2): Beispiel für den Einsatz in einer Umgebung
Integrieren Sie Ihr eigenes LLM in EA (Teil 2): Beispiel für den Einsatz in einer Umgebung
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Es ist sehr gut, dass Sie die Funktionalität der AlgLib-Bibliothek behandeln - sie kann nützlich sein!
Der Code für die Visualisierung von Dendrogrammen fehlt in dem Artikel sehr.